Chapter 4. Dynamic Programming#
The term dynamic programming (DP) refers to a collection of algorithms that can be used to compute optimal policies given a perfect model of the environment as a Markov decision process (MDP), it therefore requires no interaction with the environment.
DP algorithms are limited in practice because of their assumption of a perfect model and because of their great computational expense. Yet DP provides an essential foundation for the understanding of the methods presented in the rest of this book. In fact, all of these methods can be viewed as attempts to achieve much the same effect as DP, only with less computation and without assuming a perfect model of the environment.
The key idea of DP, and of reinforcement learning generally, is the use of value functions to organize and structure the search for good policies. As we shall see, DP algorithms are obtained by turning Bellman equations such as these into assignments, that is, into update rules for improving approximations of the desired value functions.
4.1 Policy Evaluation (Prediction problem)#
Policy Evaluation: to compute the state-value function \(v_{\pi}\) for an arbitrary policy \(\pi\). (We also refer to this as the \(\textit{prediction problem}\).)
DP assumes the environment’s dynamics are completely known (perfect model of the environment), in this case, we could use Bellman equation to form a simultaneous linear equation system with \(|S|\) equations and \(|S|\) unknowns.
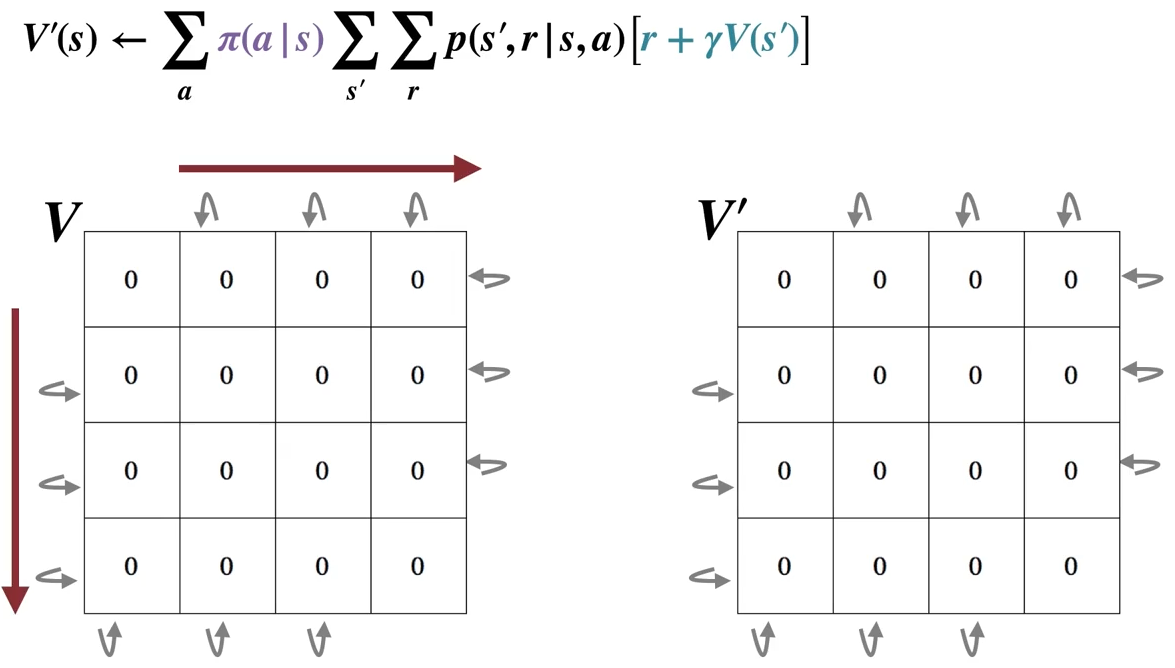
With the initial approximation \(v_0\) chosen arbitrarily (except that the terminal state, if any, must be given value 0):
\[\begin{split} \begin{align*} v_{k+1}(s) &= E_{\pi}[R_{t+1} + \gamma v_{k}(S_{t+1}) | S_t = s] \\ &= \sum_a \pi(a|s) \sum_{s', r}p(s', r|s, a) [r + \gamma v_{k}(s')] \text{ for all } s \in S \end{align*} \end{split}\]The above algorithm is called \(\textit{iterative policy evaluation}\). Letter \(k\) denotes the number of iterations.
All the updates done in DP algorithms are called \(\textit{expected updates}\) because they are based on an expectation over all possible next states rather than on a sample next state.
The updates of all states in one iteration is called a \(\textit{sweep}\) through the state space.
The Iterative Policy Evaluation algorithm for estimating \(V \approx v_{\pi}\)
Algorithm:

Intuition: \(\Delta\) will be set to 0 at the beginning of each iteration, and is used to record the maximal changes in all state values through state space. So when the maximal change in a sweep is smaller than the threshold \(\theta\), the algorithm stops. We receive an approximate optimal value function \(V \approx v_{\pi_\star}\)
Gridworld Example: watch this lecture video if you find the illustrations of sweeps during policy evaluation too hard to grasp.
Description:
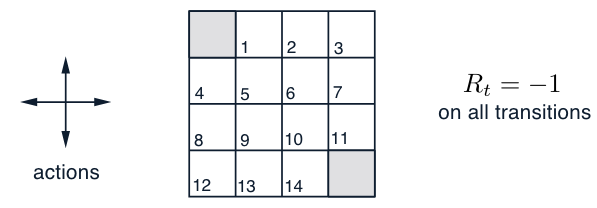
States: the nonterminal states are \(S = {1, 2,...,14}\).
Actions: there are four actions possible in each state, \(A = \{up, down, right, left\}\), which deterministically causes the corresponding state transitions, except that actions that would take the agent off the grid in fact leave the state unchanged.
For instance, \(p(6, -1|5, right) = 1, p(7, -1|7, right) = 1\), and \(p(10,r|5, right) = 0\) for all \(r \in R\).
Reward: this is an undiscounted, episodic task. The reward is \(-1\) on all transitions until the terminal state is reached. The expected reward function is thus \(r(s, a, s')= -1\) for all states \(s, s'\) and actions \(a\).
Policy: an equiprobable random policy (all actions are equally likely with probability of \(0.25\))
Policy Evaluation:
The first sweep:
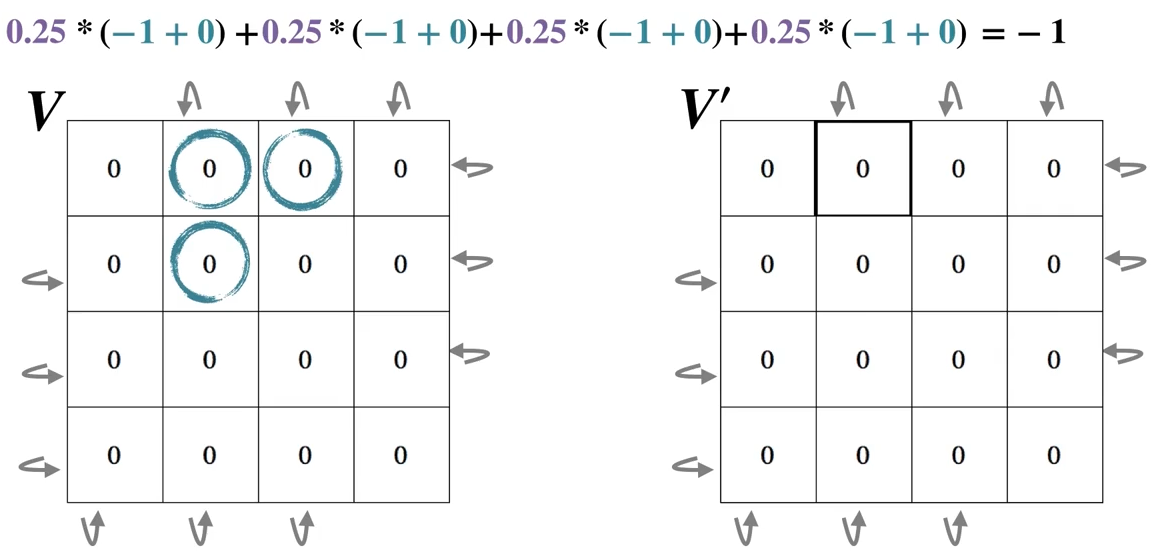
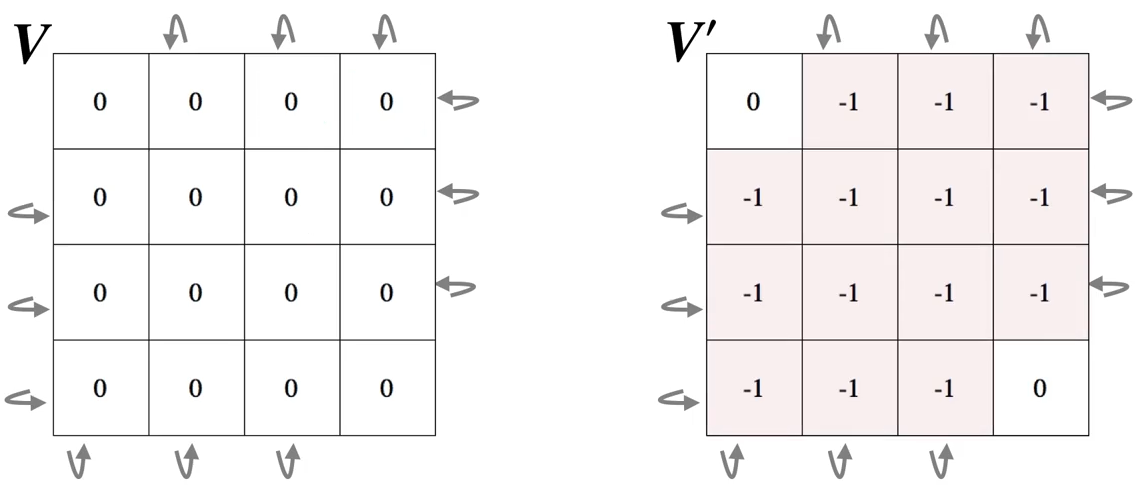
The second sweep:
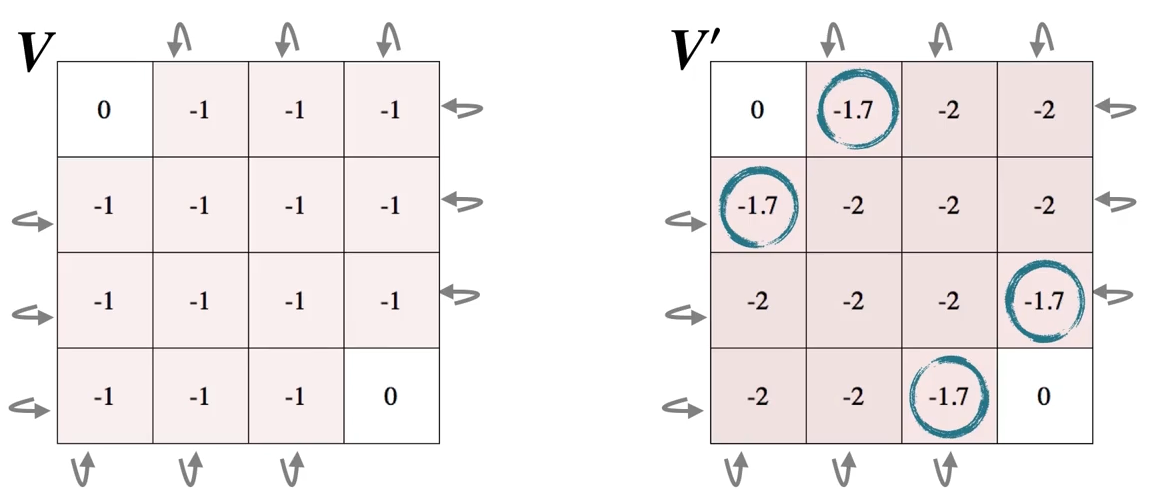
The third sweep:
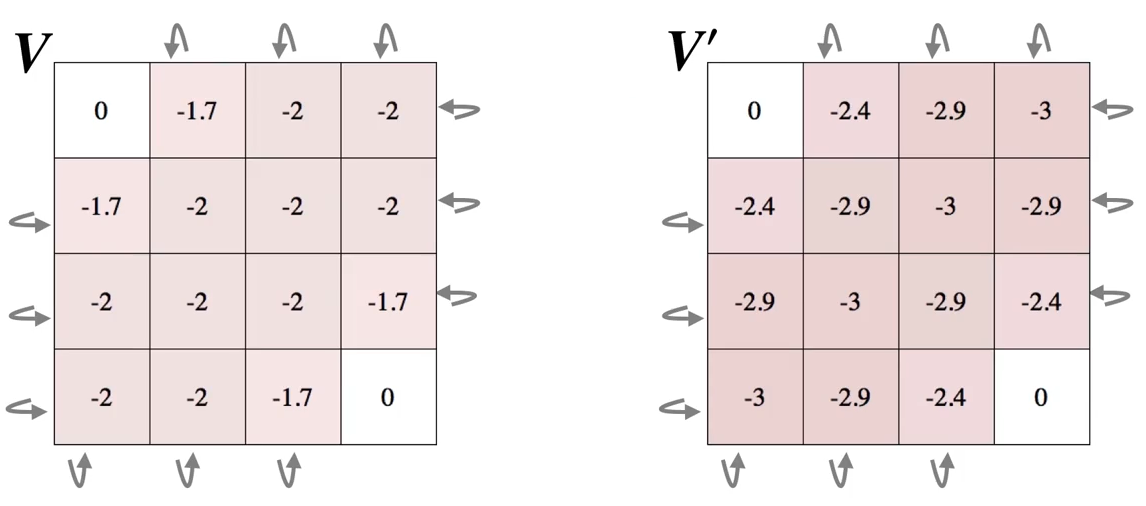
…
The final sweep: \(\Delta = 0\) and is finally smaller than \(\theta\), \(V\) and \(V'\) are both \(V_\pi\)
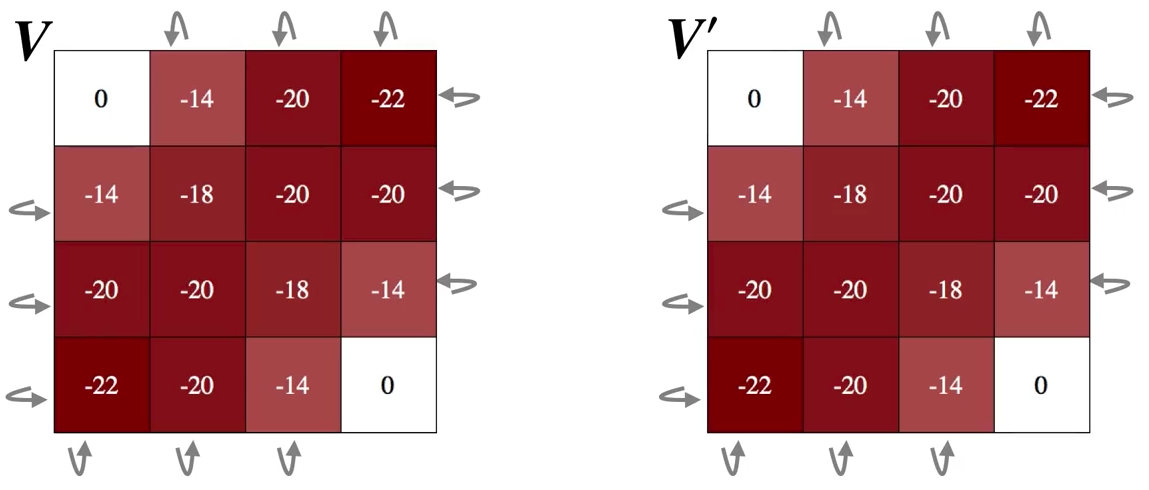
4.2 Policy Improvement#
Policy Improvement Theorem: If \(q_{\pi}(s, \pi'(s)) \ge v_{\pi}(s)\) holds for all \(s \in S\), then the policy \(\pi'\) must be as good as, or better than, \(\pi\). In other words, \(v_{\pi'}(s) \ge v_{\pi}(s)\) for all \(s \in S\) also holds.
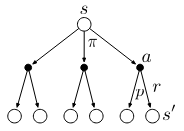
The intuition of the inequality \(q_{\pi}(s, \pi'(s)) \ge v_{\pi}(s)\) is that (recall the backup diagram starting with \(v(s)\) shown below) there exists one (or more) explicit action(s) that could bring more return for state \(s\) than simply calculating the expectation (since \(v(s) = \sum_a \pi(a|s)q(s,a)\))
Policy Improvement: the process of making a new policy that improves on an original policy, by making it greedy with respect to the value function of the original policy.
Greedification: with \(\pi'\) denoting the greedified policy:
\[\begin{split} \begin{align*} \pi'(s) &= \arg\max_a q_{\pi}(s, a) \\ &= \arg\max_a E_{\pi}[R_{t+1} + \gamma v_{\pi}(S_{t+1}) | S_t=s] \\ &= \arg\max_a \sum_{s', r} p(s', r|s,a)[r + \gamma v_{\pi}(s')] \end{align*} \end{split}\]Policy Improvement will lead to a strictly better policy unless the original policy is already optimal:
suppose the new policy is as good as, but no better than the old policy (the policy can not be any better in the end), meaning \(v_{\pi'}=v_{\pi}\), then:
\[\begin{split} \begin{align*} v_{\pi'} &= \max_a \sum_{s', r} p(s', r|s,a)[r + \gamma v_{\pi}(s')] \\ &= \max_a \sum_{s', r} p(s', r|s,a)[r + \gamma v_{\pi'}(s')] \end{align*} \end{split}\]The above last equation is exactly the Bellman optimality equation, this means that when the policy can not get any better, \(v_{\pi'}\) is \(v_{\star}\), therefore, \(\pi\) and \(\pi'\) are both the optimal policy \(\pi_{\star}\).
If a policy is already the greedy policy with respect to its own value function, then this policy is the optimal policy
Gridworld Example from section 4.1 (continue, lecture video optional)
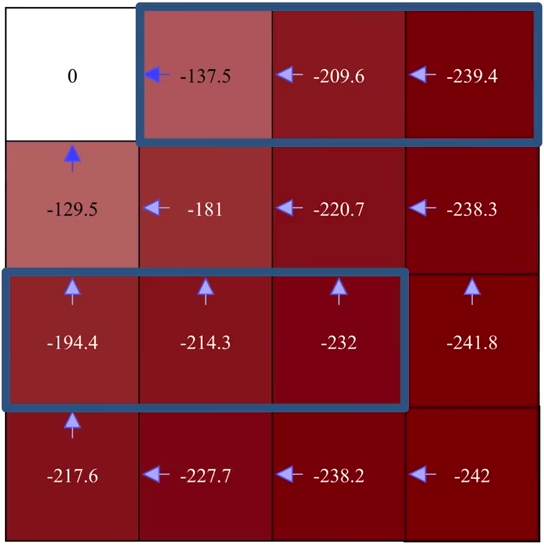
After getting the value function \(v_{\pi}\) of the initial random policy \(\pi\), we perform greedification to get the new policy \(\pi'\) (illustrated by white arrows), which is strictly better than \(\pi\) according to the nature of policy improvement.

In doing so, we now have successfully improved our original policy (for one iteration).
4.3 Policy Iteration (Control)#
Policy iteration: the process of performing policy evaluation and policy improvement iteratively to find the optimal policy.
Because a finite MDP has only a finite number of policies, this process must converge to an optimal policy and optimal value function in a finite number of iterations. With \(E\) stands for evaluation and \(I\) for improvement, the process is:
\[ \pi_0 \xrightarrow{\text{E}} v_{\pi_0} \xrightarrow{\text{I}} \pi_1 \xrightarrow{\text{E}} v_{\pi_1} \xrightarrow{\text{I}} ... \xrightarrow{\text{I}} \pi_{\star} \xrightarrow{\text{E}} v_{\star} \]Algorithm for Policy Iteration:

New Gridworld Example: Again, if you find this all too abstract, watch this lecture video which should give you a more slow and smooth illustration.
Description:
The Gridworld example in section 4.1 actually reaches the optimal policy after only one iteration, we now make the example a bit more complex by eliminating one terminal grid and adding blue states where rewards have much lower value of \(-10\).
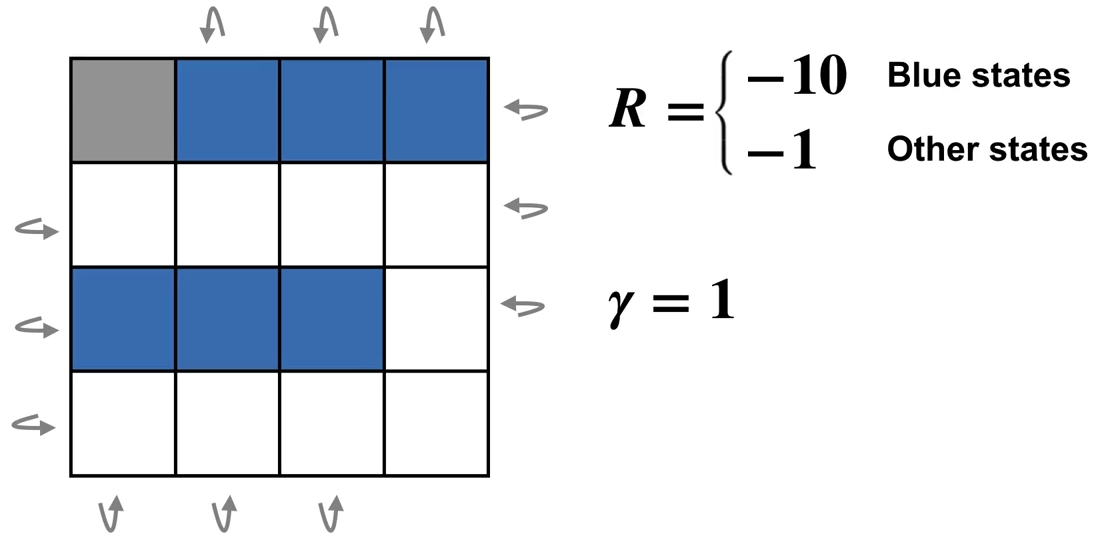
Policy iteration:
The first iteration:
Evaluation
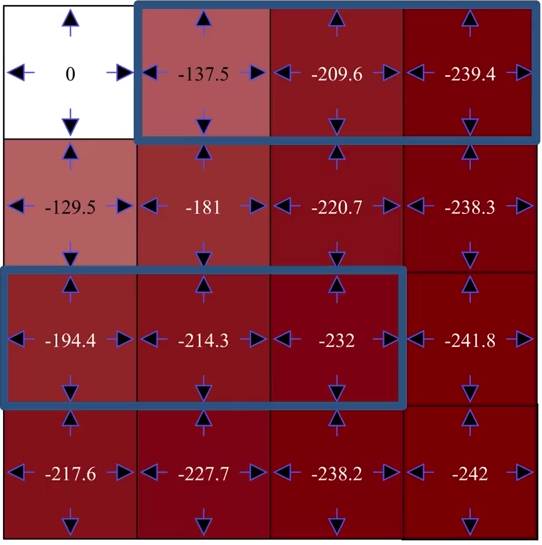
Improvement
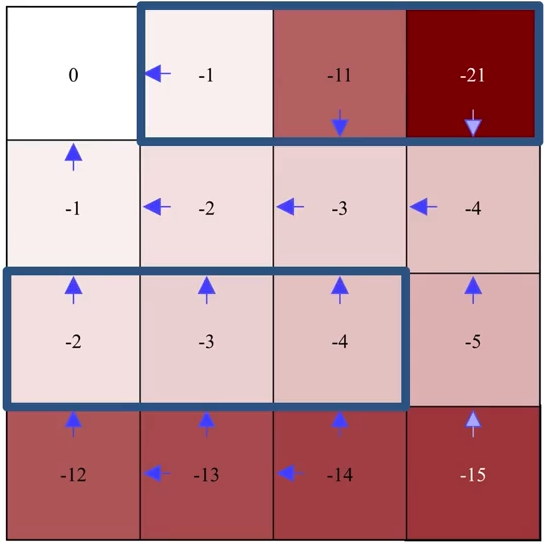
The second iteration:
Pay attention to how exactly the greedification is performed (e.g., the second left grid on the last row).
Remember that \(\pi'(s) = \arg\max_a \sum_{s', r} p(s', r|s,a)[r + \gamma v_{\pi}(s')]\) not \(\pi'(s) = \arg\max_a v(s')\), so don’t just greedify an action towards a state \(s'\) simply because that state has a higher value \(v(s')\).
Evaluation
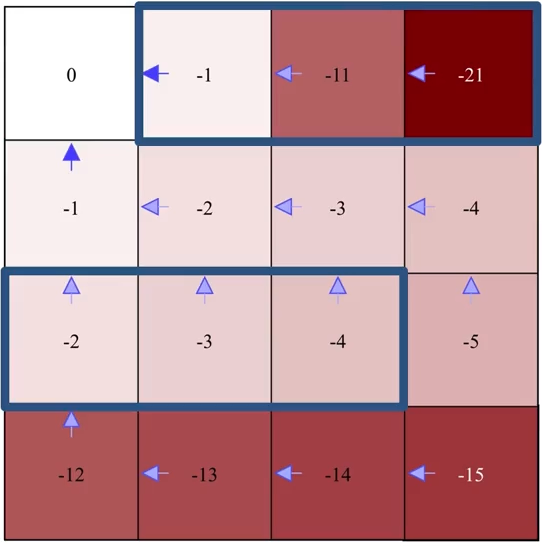
Improvement
…
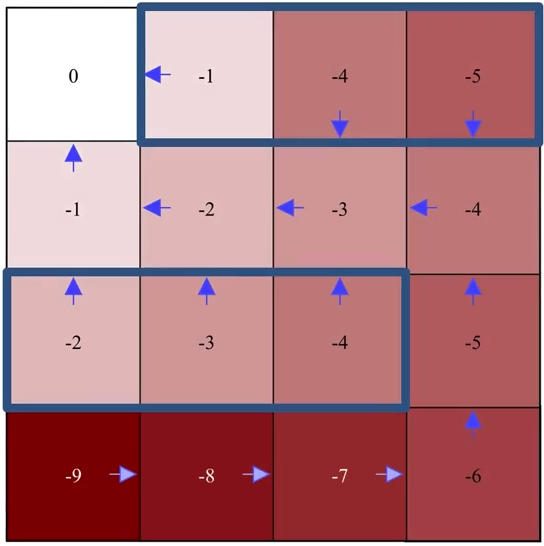
The final iteration
Note that in the final iteration, after policy improvement, the policy remains the same, i.e., the original policy (before improvement) is already the greedy policy with respect to its own value function, the optimal policy is found.
Evaluation
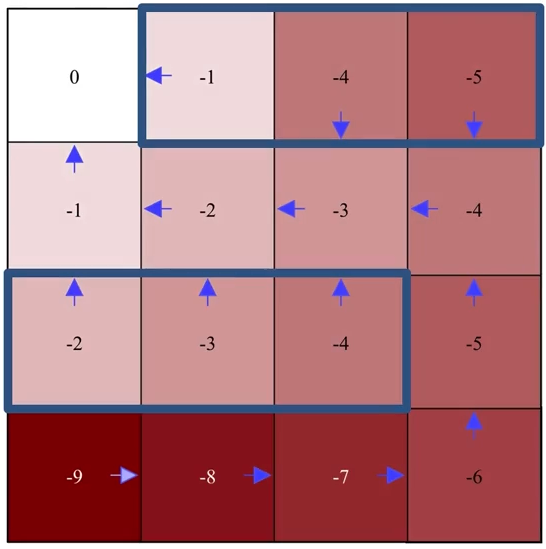
Improvement
4.4 Value Iteration#
Value Iteration: is the special case of Policy Iteration where policy evaluation stops after just one sweep.
Drawback of policy iteration: requires iterative computation, each of its iterations involves policy evaluation, which may itself be a protracted iterative computation requiring multiple sweeps through the state set, and convergence only occurs in the limit, which takes a lot of time.
Value iteration effectively combines, in each of its sweeps, one sweep of policy evaluation and one sweep of policy improvement.
Update rule:
\[\begin{split} \begin{align*} V_{k+1}(s) \ &\dot= \ \max_a q_{k}(s, a) \\ &= \max_a \sum_{s', r} p(s', r|s,a) [r + \gamma V_{k}(s')]\ \text{for all} s \in S \end{align*} \end{split}\]Note that the above equation is obtained simply by turning the Bellman Optimality Equation into an updating rule.
Algorithm for Value Iteration:

4.5 Generalized Policy Iteration (GPI)#
\(\star\) Two types of DP:
Synchronous DP: update all states systematically in a certain order (takes a very long for large state space)
Asynchronous DP: update states without order (can be faster, but also problematic when only a small set of states is being updated constantly)
Generalized policy iteration (GPI): refers to the general idea of letting policy-evaluation and policy improvement processes interact, independent of the granularity and other details of the two processes.
Almost all reinforcement learning methods are well described as GPI. That is, all have identifiable policies and value functions, with the policy always being improved with respect to the value function and the value function always being driven toward the value function for the policy:
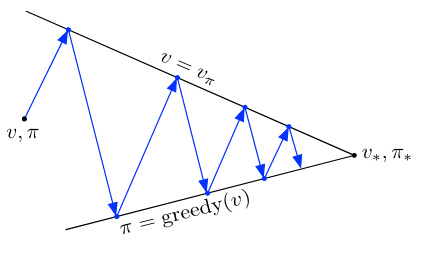
Both processes stabilize only when a policy has been found that is greedy with respect to its own evaluation function (when \(\pi\) itself is the greedy policy of \(v_{\pi}\)). This implies that the Bellman optimality equation for state-value functions holds, and thus that the policy and the value function are optimal.
4.6 Summary#
Classical DP methods operate in sweeps through the state set, performing an \(\textit{expected update}\) operation on each state. The update of states is based on estimates of the values of successor states. That is, estimates are updated on the basis of other estimates. We call this general idea \(\textit{bootstrapping}\) (a very fundamental concept in many RL algorithms, and we will introduce it in depth in Chapter 6) and requires a perfect model of the environment.
In the next chapter we explore Monte Carlo method - a reinforcement learning method that does not require a model and do not bootstrap. But for now, a quick summary:
Mindmap of where we are now:
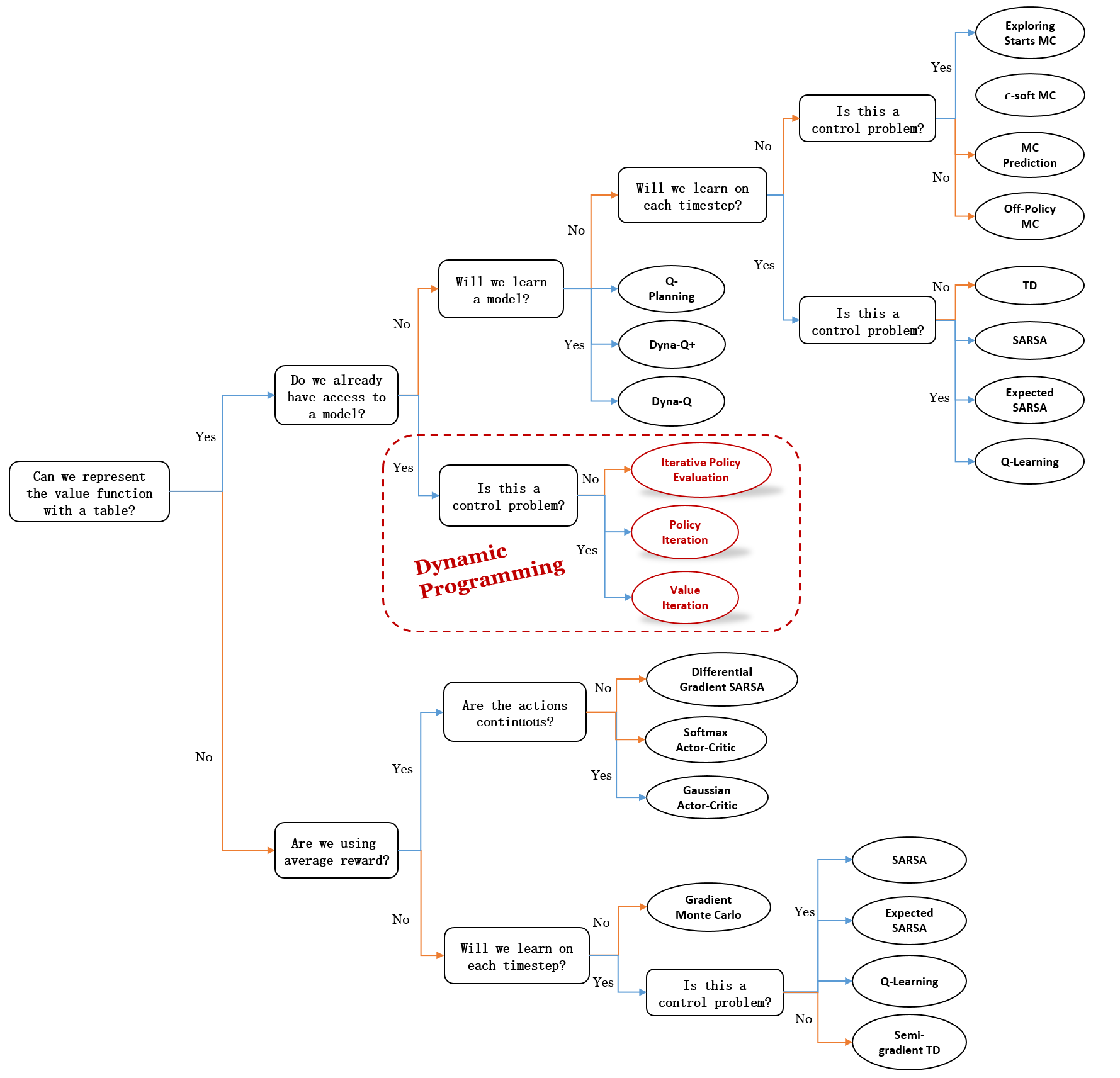
Key Takeaways:
DP Overview:
Computes optimal policies using a perfect model of the environment (MDP).
No interaction with the environment; computationally expensive but foundational for RL.
Core idea is to use value functions and Bellman equations as update rules to improve policies.
Policy Evaluation (Prediction):
Iteratively estimate \(v_\pi\) for a given policy \(\pi\):
\[ v_{k+1}(s) = \sum_a \pi(a|s) \sum_{s', r} p(s', r | s, a) [r + \gamma v_k(s')] \]Stop when changes in \(v(s)\) are smaller than a threshold \(\theta\).
Policy Improvement:
Create a greedy policy \(\pi'\) with respect to \(v_\pi\):
\[ \pi'(s) = \arg\max_a \sum_{s', r} p(s', r | s, a) [r + \gamma v_\pi(s')] \]If no further improvement is possible, \(\pi\) is optimal.
Policy Iteration:
Alternate between policy evaluation and improvement until convergence:
\[ \pi_0 \rightarrow v_{\pi_0} \rightarrow \pi_1 \rightarrow v_{\pi_1} \rightarrow \ldots \rightarrow \pi_* \rightarrow v_* \]
Value Iteration:
Simplified policy iteration with one sweep per iteration:
\[ V_{k+1}(s) = \max_a \sum_{s', r} p(s', r | s, a) [r + \gamma V_k(s')] \]Converges to optimal \(V\) and greedy policy \(\pi_*\).
Generalized Policy Iteration (GPI):
Continuous interaction of policy evaluation and improvement.
Stabilizes when the policy is greedy with respect to its own value function.
Extra lecture video (optional): Warren Powell: Approximate Dynamic Programming for Fleet Management (Long)