9. π₀.5:开放世界与分层执行
先修建议
- 已完成第 9 讲
,理解 VLM + Action Expert + Flow Matching的基础骨架。 - 熟悉 action chunking、交叉熵训练与 flow matching 基本概念。
- 对“训练配方影响泛化”有基本直觉。
本节目标
- 理解
为什么采用“先生成子任务文本,再生成低层动作”的两层分解。 - 看懂
MM/ME/CE/HL/WD/VI六类数据如何在两阶段训练中协同。 - 理解 FAST 离散动作 token 与 Flow Matching 连续动作生成各自承担的角色。
- 用论文中的评测与消融结果判断
的能力边界,而非只看演示视频。 - 建立与后续第 11 讲
RTC、第 12 讲的连续认知链路。
下图中的重点不是单个动作是否成功,而是两个条件同时成立:环境来自训练外真实家庭,任务包含多个需要连续决策的阶段。

1. 开放世界问题
同一个 “clean the kitchen” 高层指令,在不同家庭里会对应完全不同的物体、柜子、台面布局和清理顺序。系统需要持续回答三类问题:
- 当前场景下下一步应该做哪一个子任务。
- 这个子任务对应的对象与空间关系是什么。
- 低层动作如何在当前机体约束下稳定完成。
论文给出的整体策略可以概括为三件事:
- 用层级子任务推理把“做什么”与“怎么做”分离。
- 用异构数据共训补足目标移动机器人数据之外的视觉、语义和操作经验。
- 用单向信息流动降低连续动作损失对语言语义路径的干扰。
这里需要区分两个时长口径。论文开篇强调模型可以完成 10-15 分钟级别的长程行为;主体量化评测中的标准任务段落多在 2-5 分钟区间。前者说明系统能力上限,后者是主要可量化对比协议。
2. 分层策略
论文把联合分布写为:
关键约束是:低层动作分布不直接条件于原始高层指令
| 符号 | 含义 |
|---|---|
| 当前观测(多相机图像 + 本体状态) | |
| 高层任务指令(如“整理厨房”) | |
| 子任务文本(如 “pick up the plate”) | |
| 连续动作块 | |
| 动作 horizon(附录给出 |
把中间变量设计成离散文本 token而不是连续 latent,有两个直接收益:
- 子任务与 VLM 预训练词表、交叉熵监督天然兼容。
- 子任务可读、可调试,也便于人类用语言示教介入。
更重要的是,高层推理和低层动作并不是两个完全分离的模型。论文强调
3. 数据配方

| 缩写 | 阶段 | 数据来源 | 主要补足的能力 |
|---|---|---|---|
MM | pre / post | 移动操作数据,约 400 小时,约 100 个家庭环境 | 与目标评测最接近的家庭移动操作经验 |
ME | pre / post | 多环境非移动机械臂数据 | 更多家庭环境、物体和操作变化 |
CE | pre | 实验室跨机体数据,包含 OXE | 跨机体、跨任务的操作迁移 |
HL | pre / post | 高层子任务文本、相关目标框标注 | 从场景和高层指令预测下一步子任务 |
WD | pre / post | Web 多模态数据,包含 captioning / VQA / detection | 常识物体识别、视觉语义和 OOD 物体理解 |
VI | post | 专家用语言一步步指挥机器人完成任务的数据 | 学习更贴合低层策略能力的高层子任务选择 |
3.1 预训练
预训练阶段把动作任务统一表示为 next-token prediction。机器人动作使用 FAST tokenizer 变成离散动作 token,文本、目标框、Web 多模态任务也都进入同一套自回归训练框架。
论文主文给出一个关键比例:第一阶段中约 97.6% 的样本并非来自目标移动操作机器人本体,而来自其他机器人、Web 数据和语义监督。这说明
HL 数据还包含一个容易忽略的细节:除了预测下一步子任务文本,论文还标注了当前观测中的相关 bounding boxes,并让模型在预测子任务前学习定位相关对象。这让高层推理不只是语言续写,也和当前视觉场景绑定起来。
3.2 后训练
后训练阶段聚焦移动操作,保留 MM/ME/HL/WD,加入 VI,同时移除 CE。这个阶段的目标有两个:
- 让模型专精到家庭移动操作任务。
- 接入 Action Expert,用 Flow Matching 生成连续动作块。
VI 的构造方式很有启发性:专家不是直接遥操作关节,而是用语言一步步指挥已有低层策略,例如让机器人先“pick up the towel”,再“put it in the laundry basket”。这些语言示教记录了“当前低层策略真正能执行什么样的子任务”,因此对高层策略质量影响很大。
3.3 动作对齐
为保证多源机器人数据能够共训,论文在动作侧做了统一处理:
- 各数据集动作维度按
1%和99%分位数归一化到[-1, 1]。 - 不同机体的动作空间对齐到固定维度,维度不足的机体使用 zero-padding。
- 控制模态通过
<control_mode> joint/end effector <control_mode>这类文本标记写入 prompt。
这些处理看起来是工程细节,但决定了 MM/ME/CE 能否真正被同一个 VLA 消化。
4. FAST+Flow 双通道
这里的 FAST 不是部署时的最终动作输出,也不是
下图展示了论文使用的移动操作平台。系统输入包括四路相机和本体状态,输出包括双臂、夹爪、底盘和躯干升降相关控制量,整体状态与动作空间为 18-19 DoF。

架构层可以概括为三条路径:
- 共享 VLM 主干负责多模态语义表示与文本输出。
- 文本输出路径负责生成高层子任务、Web 任务答案和 FAST 动作 token。
- Action Expert 路径负责通过 flow matching 生成连续动作块。
论文附录给出两项关键结构口径:
- 主干为 PaliGemma 系列初始化,采用 2B 级别 VLM 配置。
- Action Expert 是较小的独立专家,约 300M 参数,宽度和 MLP 维度低于主干。
注意力 mask 的设计是这一节的重点。它要解决的问题是:同一个序列里同时存在 FAST 离散动作 token 和 Flow 连续动作 token,二者不能互相“偷看答案”。
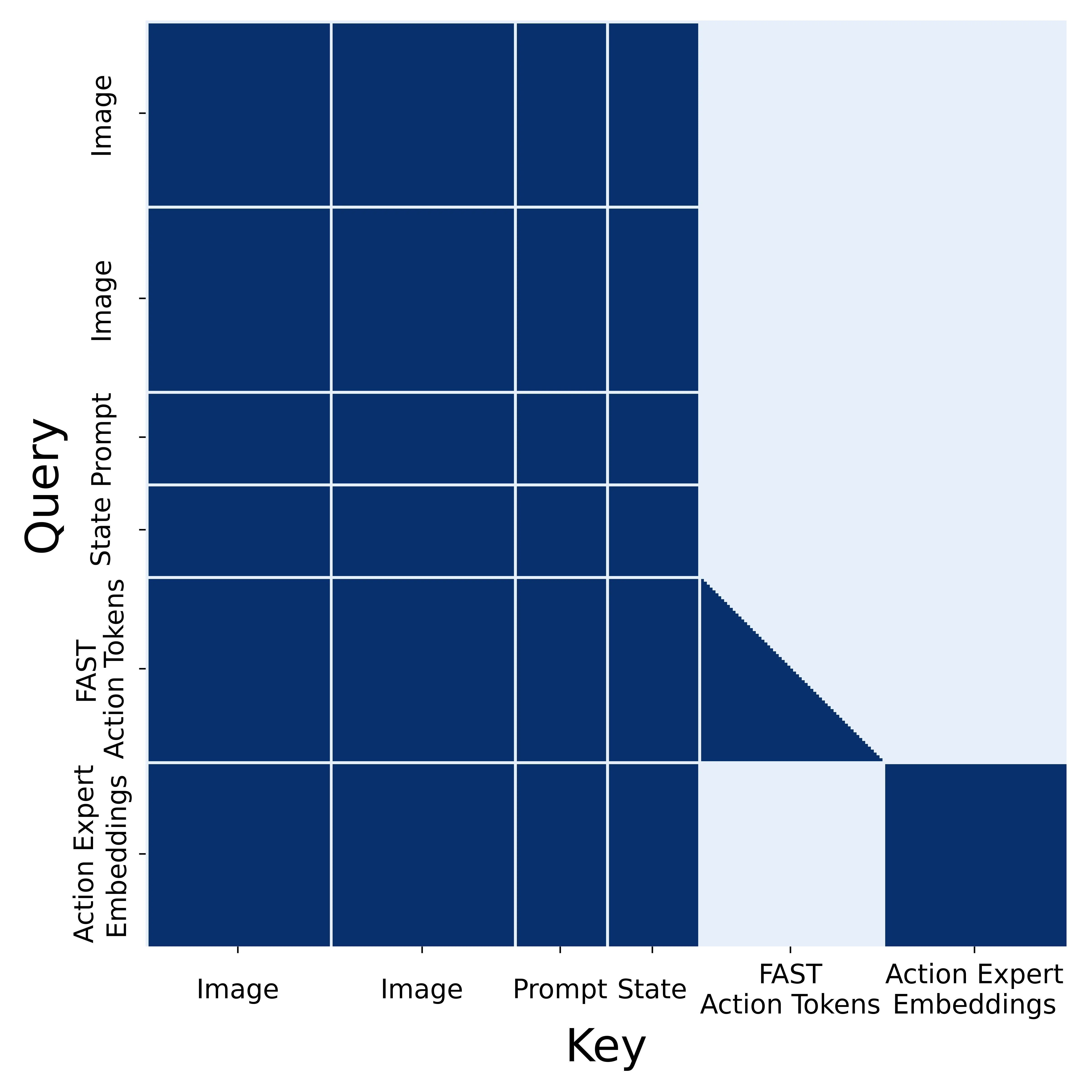
论文附录中的核心规则包括:
- 图像、prompt、本体状态组成 prefix,并采用 full prefix mask。
- FAST 动作 token 可以看 prefix,并按自回归方式看之前的 FAST token。
- Action Expert token 可以看 prefix 和自身 token,但不能看 FAST 动作 token。
- VLM token 不 attend Action Expert token。
这个设计让信息主要从 VLM 流向 Action Expert,而不是让连续动作损失反向污染语言语义主路径。
5. 两阶段训练
论文给出的联合目标可写为:
其中第一项覆盖文本、目标框和 FAST 动作 token 等离散输出;第二项训练 Action Expert 预测连续动作的 flow vector field。
阶段切换由
- pre-training:
α=0,只做离散 token 学习,训练280ksteps。 - post-training:
α=10.0,加入连续动作专家训练,继续训练80ksteps。
Action Expert 在 post-training 开始时随机初始化。与此同时,模型仍保留 next-token prediction,以免专精连续控制后丢掉文本和高层子任务能力。
推理时的流程与训练分解一一对应:
- 先自回归解码出子任务文本
。 - 再以该子任务为条件,做
10次 denoising 得到连续动作块。
这就是
6. 控制闭环
- 输入观测与高层指令,生成当前子任务文本。
- 以子任务文本为条件,生成连续动作块。
- 控制器按底层频率执行动作目标。
- 新观测到来后重复上述过程。
与部署强相关的论文口径包括:
- 平台使用四路相机做高层推理。
- 低层推理使用腕部与前视等关键视角。
- 控制目标以
50Hz由 PD 控制器跟踪。 - 动作块 horizon 为 50 步(附录写为
token 索引)。 - 系统没有额外轨迹规划或碰撞检测,导航和操作控制都由学习策略端到端输出。
关于“高层更新频率”,论文主文没有给出统一固定值。更稳妥的理解是:高层子任务会随着任务阶段动态重采样,而低层控制通过动作块和 50Hz 控制器持续执行。
7. 实验结果分析
- 能否在训练外真实家庭完成多阶段任务。
- 训练环境数量增加时,泛化是否随之改善。
MM/ME/CE/HL/WD/VI中哪些数据源真正重要。- 相比
和只加入 FAST+Flow 的变体,完整 是否有额外收益。 - 显式高层子任务推理到底有多重要。
7.1 新家庭评测
最终真实家庭评测在训练集中未出现的家庭中进行。论文使用简单高层命令,例如 “place the dishes in the sink”,让模型自己预测中间子任务并执行。

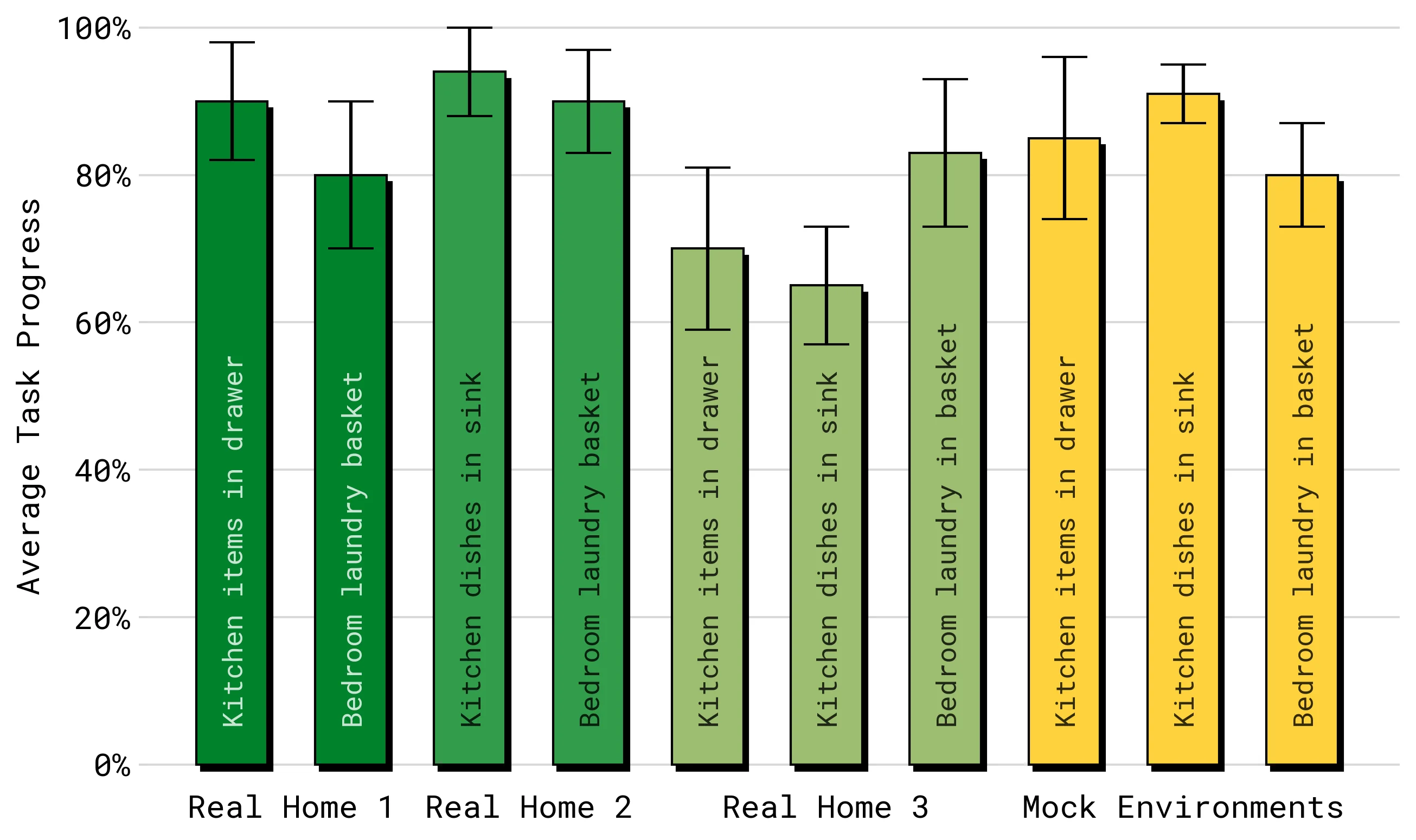
评测口径需要和演示视频区分开:
- 真实家庭评测覆盖厨房与卧室清理任务,例如 items in drawer、dishes in sink、laundry basket。
- 标准量化任务多为
2-5分钟的多阶段流程。 - 论文使用 rubric 计分,不只记录全成败。例如 dishes in sink 按拾起和放入数量给分,items in drawer 按拾取、开抽屉、放入、关抽屉等步骤给分。
- 多数标准比较按每个 policy 和 task 进行多次试验,并交错执行不同策略以降低环境变化带来的偏差。
因此,这组结果更适合理解为“在明确任务集合和评分标准下的开放世界证据”,而不是“任意家庭任务都已解决”。
7.2 场景 scaling
论文把移动操作数据中的训练位置数分为 3 / 12 / 22 / 53 / 82 / 104 桶,并在未见过的 mock homes 中评测。这个实验想看的不是单纯数据量,而是环境多样性:更多家庭位置通常意味着更多物体、背景、柜体、床铺和空间布局。
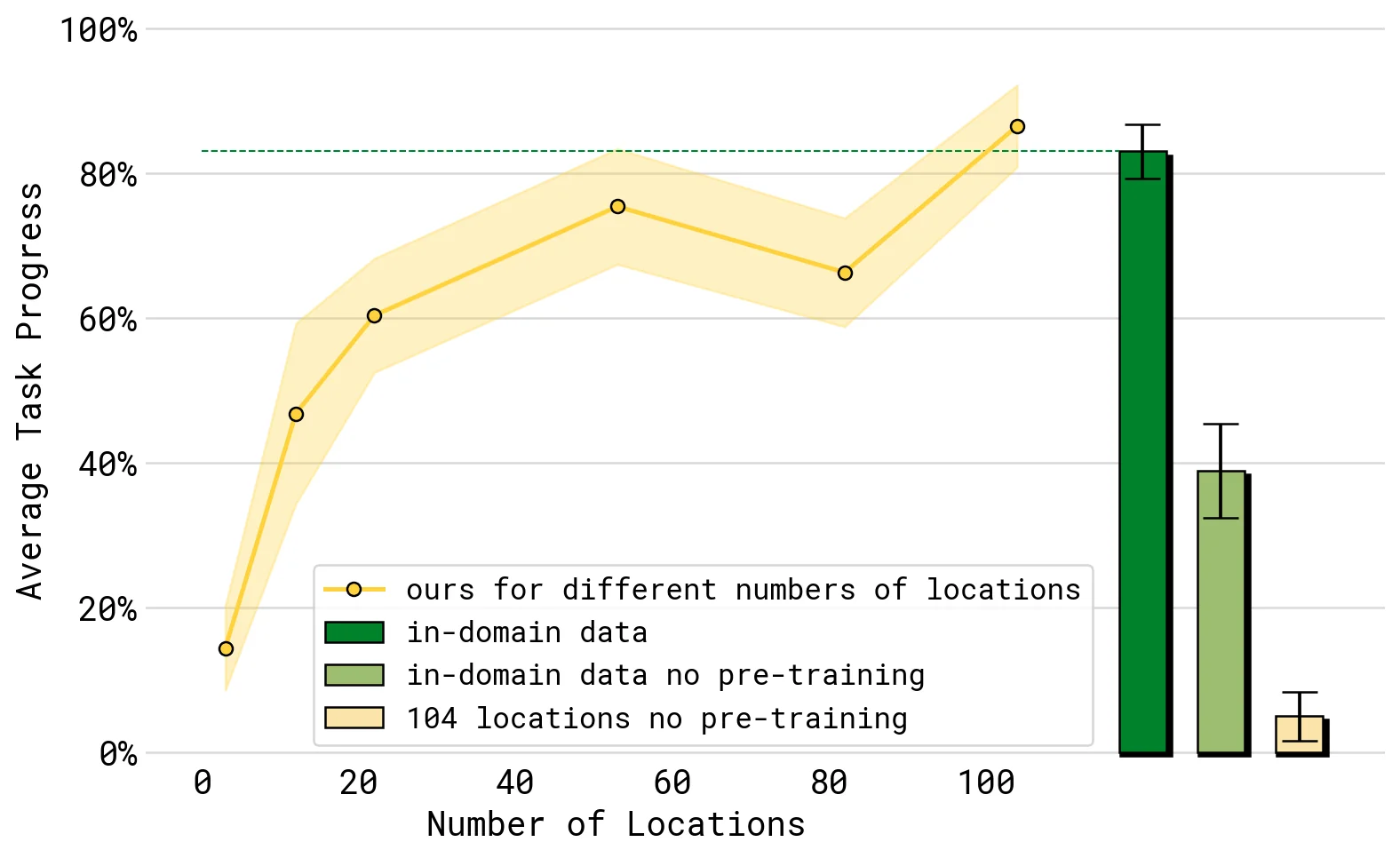
104-location 模型在部分设定下接近“直接在测试家庭训练”的对照表现。不过论文也设置了不使用其他 co-training 数据的对照,结果明显更差。这说明位置数量重要,但完整训练配方同样关键。
语言跟随实验进一步拆开了“选对物体”和“完成放置”两个指标:
这组结果的主要含义是:随着训练环境变多,模型不仅更会执行动作,也更会在新物体和新布局中理解语言指定的目标。OOD 物体提升较慢,但趋势仍然随位置多样性增加而改善。
7.3 数据消融
数据消融回答的是一个更尖锐的问题:如果只保留目标移动机器人数据,或者去掉某类外部数据,性能会怎样。
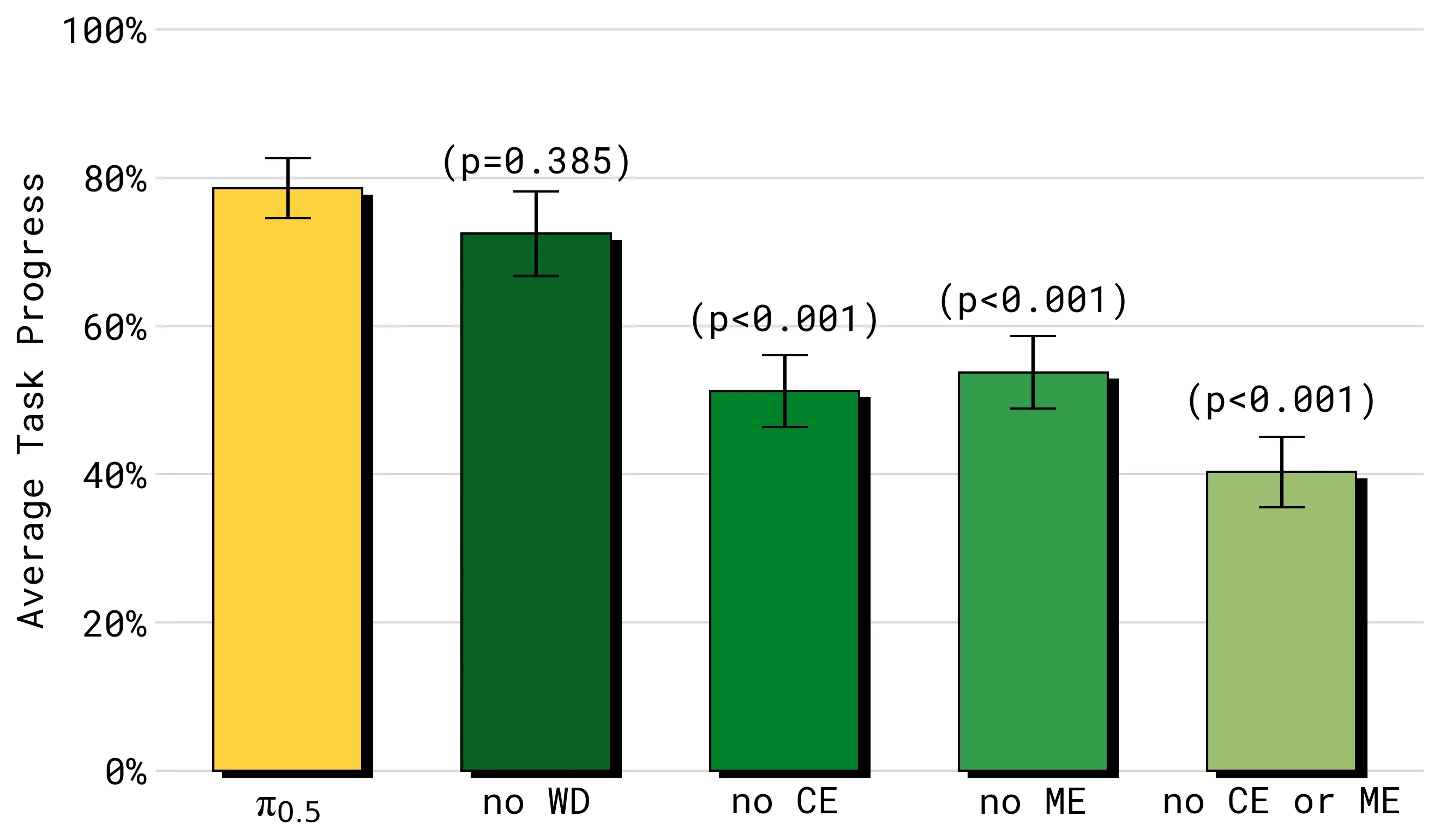
在 mock home 任务中,ME 和 CE 都很重要。去掉任一类跨机体或跨环境机器人数据都会造成明显下降,二者同时移除时下降更大。这说明
WD 在整体 mock home 分数上不一定显著改变结果,但在语言跟随和 OOD 物体上影响更明显:
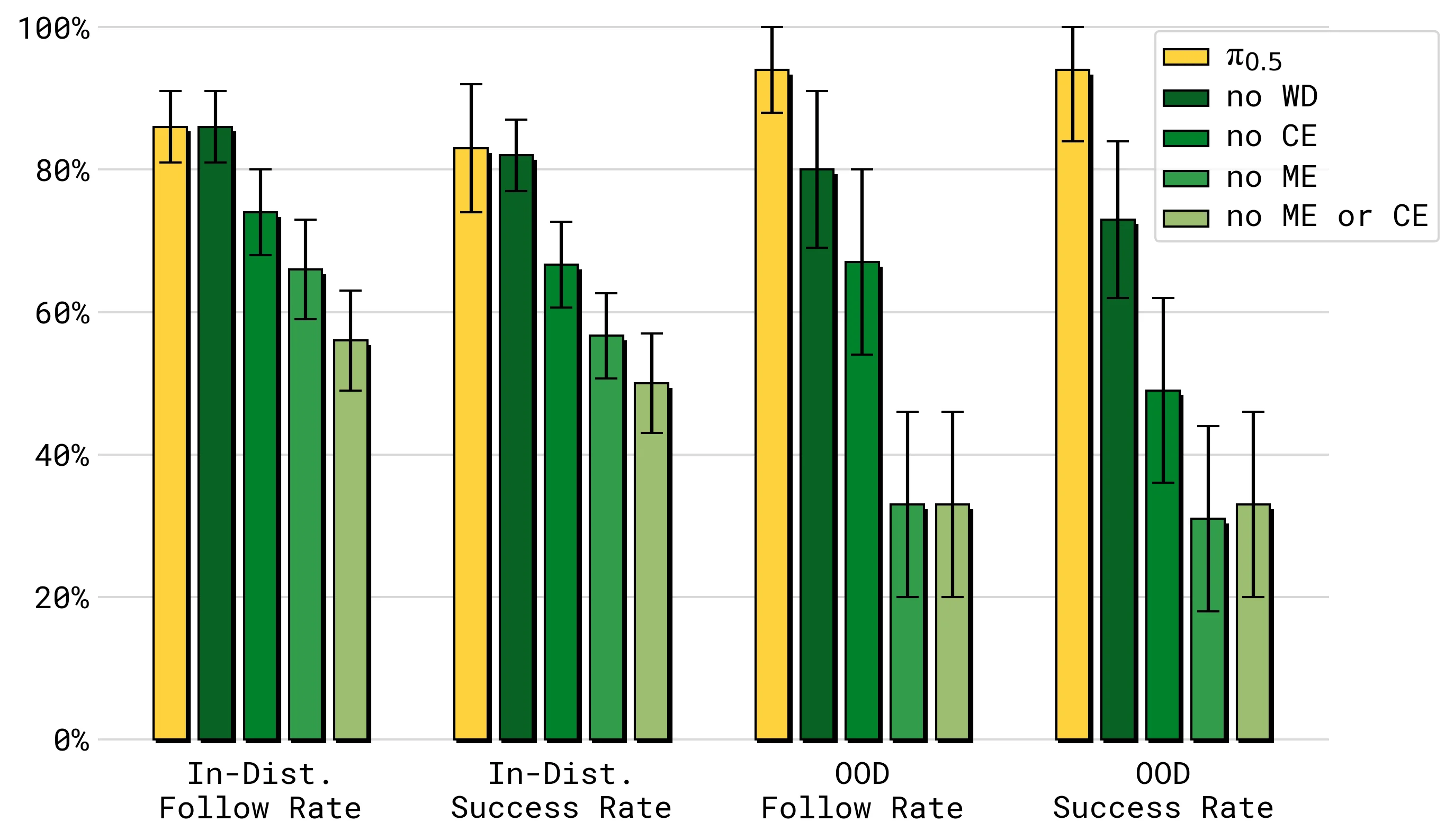
这个差异很合理。把盘子放进水槽这类任务主要依赖操作能力和近似物体经验;识别训练中没见过的 funnel、pill bottle、safety goggles 等物体,则更依赖 Web 多模态数据带来的视觉语义知识。
7.4 模型对比
论文还比较了完整 HL 和 WD,因此不能像
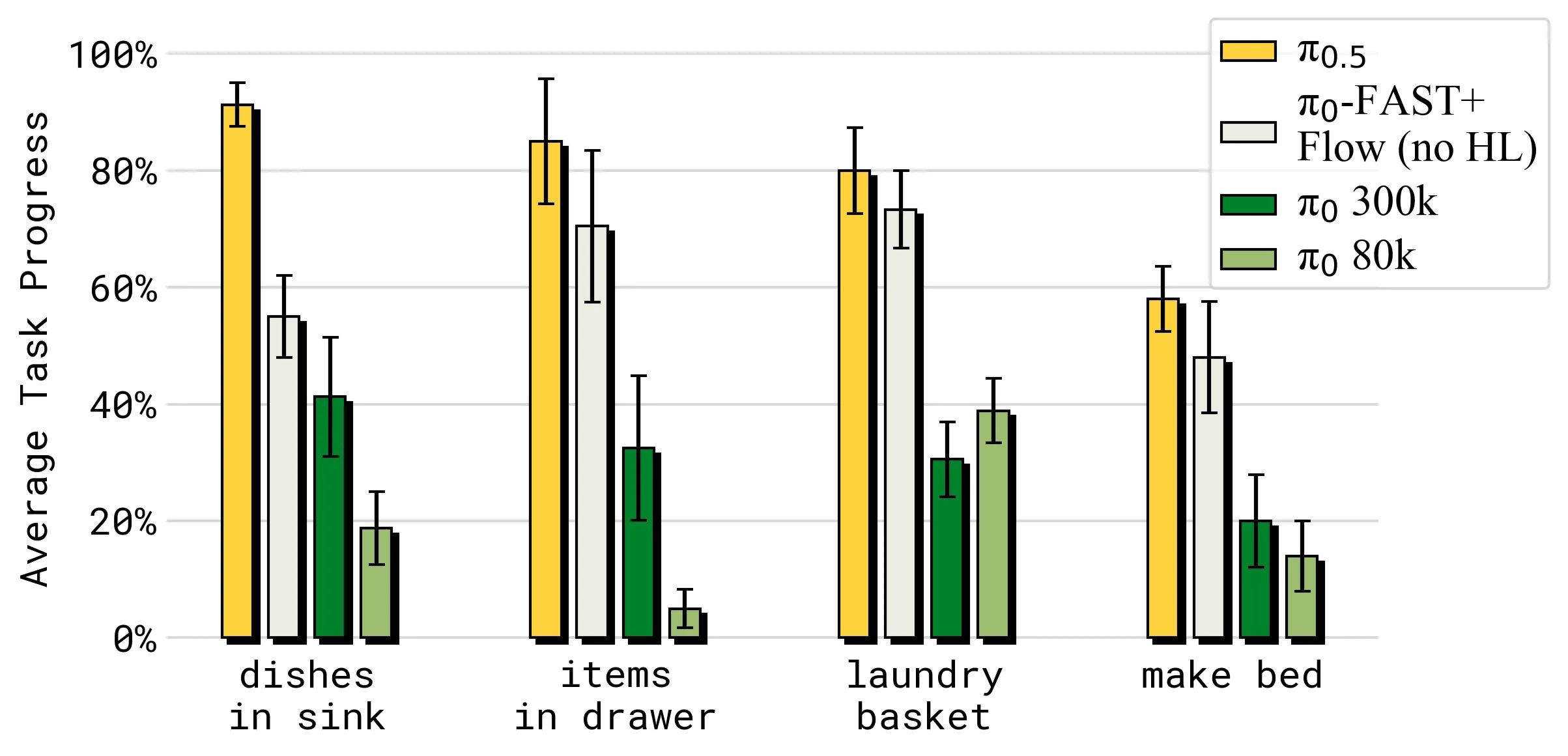
这组对比说明,
语言跟随对比也支持这一点:
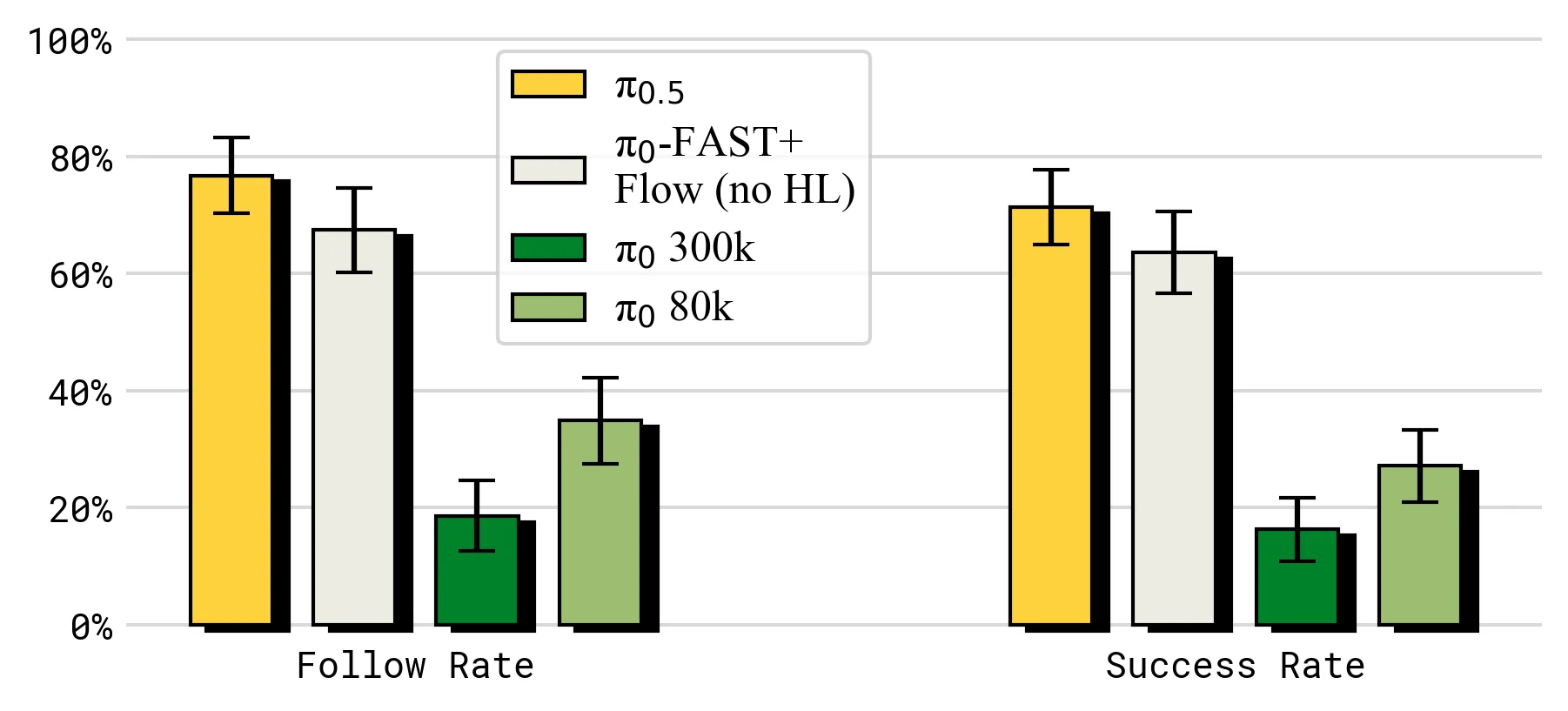
相较原始
7.5 高层消融
高层推理消融比较的是:同一个低层策略搭配不同高层策略时,最终任务表现如何。
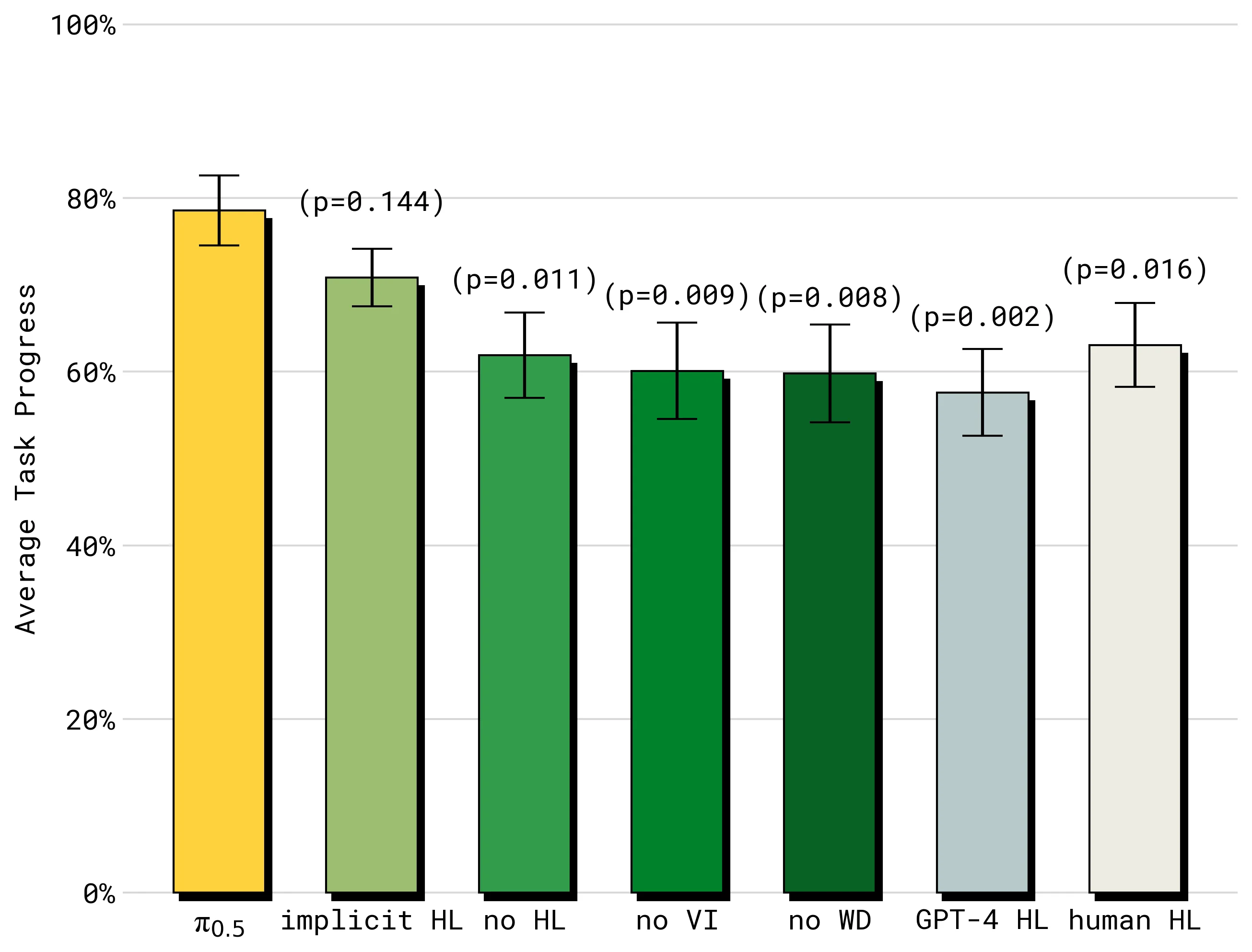
几个结论值得单独记住:
- 完整
表现最好,说明显式生成子任务确实有价值。 implicit HL排名靠前,说明即使推理时不显式生成子任务,只要训练时见过HL子任务预测,模型也能学到不少任务结构。no HL明显更弱,说明高层子任务监督不是可有可无的附加项。- 去掉
VI或WD都会削弱高层策略,其中VI只占高层移动操作样本约11%,但影响很大。 - zero-shot
GPT-4高层策略表现较差,说明通用语言模型即使能写计划,也未必知道当前低层机器人策略最适合执行哪些子任务。
论文中完整
8. 边界与下一步
- 某些物理结构仍容易失败,例如陌生抽屉把手或难以打开的柜门。
- 部分可观测性会造成问题,例如机械臂遮挡了需要擦拭的液体。
- 高层子任务推理可能被场景细节分散注意力,出现重复开关抽屉等行为。
- 当前模型处理的是相对简单的 prompt,更复杂的偏好和约束需要更丰富的标注。
- 上下文和记忆仍较有限,跨房间导航、记住物体存放位置等任务还需要更强的长期记忆机制。
这意味着
- 实时执行路线:如何在高延迟与复杂控制条件下保持稳定闭环,这对应第 11 讲
RTC。 - 在线学习路线:如何把部署期经验回流为策略更新,而不是只靠离线再训练,这对应第 12 讲
。
把 π 系列压缩成一条主线,可以写成: