11. π₀.6:在线闭环与优势策略
先修建议
- 已完成第 9 讲
,理解 VLM + Flow Matching Action Expert基础骨架。 - 已完成第 10 讲
,理解“高层子任务文本 -> 低层动作”分层执行。 - 可先了解第 11 讲
RTC中的 action chunk 与延迟问题;它不是的架构前置。
本节目标
- 理解
Recap如何把部署数据转成可训练的优势监督信号。 - 对齐
的模型构型、价值函数训练与优势条件策略提取公式。 - 掌握“采集 -> 估值 -> 提取 -> 重置”在线迭代闭环。
- 建立从
到 的连续能力阶梯。
| 章节 | 解决的核心问题 |
|---|---|
| 跨机体基础骨架如何建立 | |
| 开放世界场景中的分层执行如何落地 | |
RTC(第 11 讲) | 慢模型如何接入实时控制闭环 |
| 部署后如何利用经验持续改进 | |
| 如何可控地组合和指挥新技能 |
1. π₀.6 定位
第 11 讲讨论推理延迟下的实时执行。本节转向与之并列的学习问题:执行结果如何反向进入训练,并引向后续章节中的可控技能组合。
论文中的方法名是 Recap,全称为 RL with Experience and Corrections via Advantage-conditioned Policies。它是一套让 VLA 在部署后继续改进的训练流程:机器人先执行任务,系统再从这批尝试中判断哪些动作值得强化,最后把这些判断重新写回策略训练中。
文中有两个容易混淆的名称:Recap 训练后得到的强化版本。本节主要讨论后者背后的学习闭环,而不是单纯比较模型参数量。
论文没有把 RTC 构建。模型来源更准确地写成
- 在真实任务中运行当前策略,收集自主轨迹与人类纠正轨迹。
- 用任务结果训练价值函数,估计动作优劣。
- 把优劣信号变成策略条件,重新训练下一轮策略。
总览图需要关注三段闭环:部署采集、价值训练、优势条件策略提取。模型规模变化不是本节的主要线索。
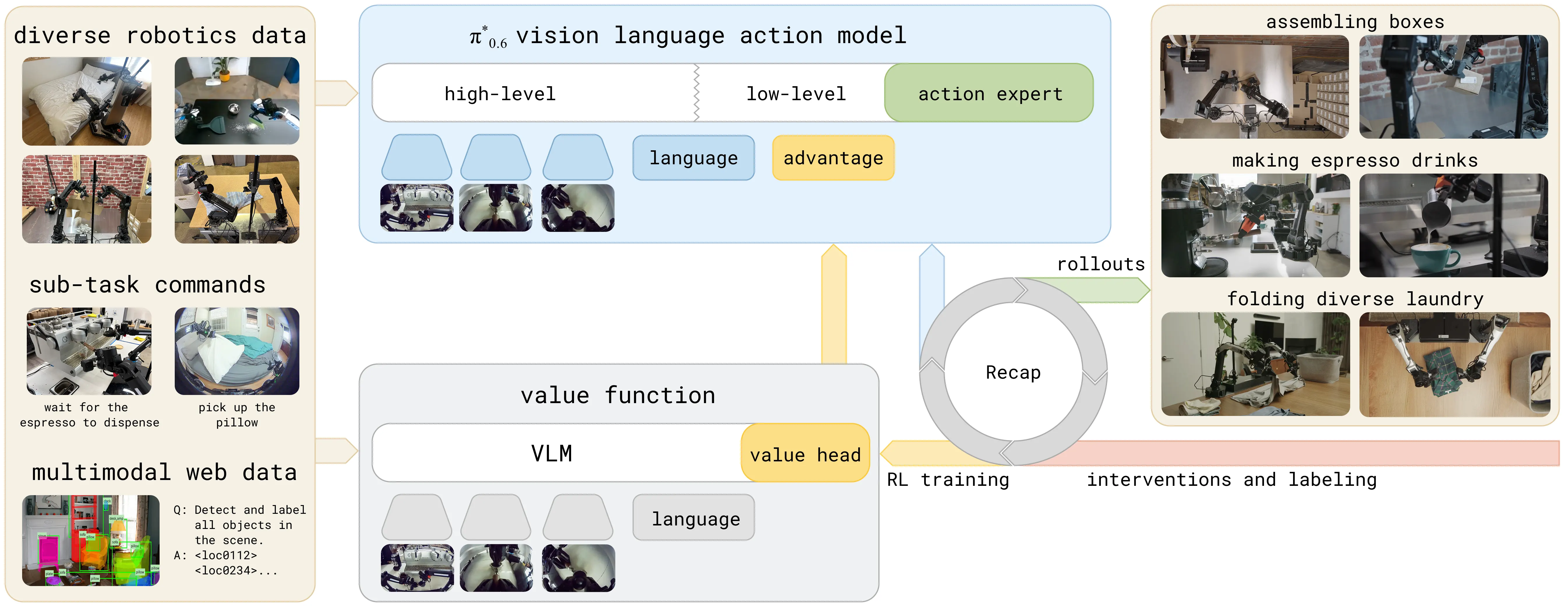
这套闭环针对的是前面章节中常见的限制:训练结束后模型参数基本固定。
2. 任务定义与符号约定
沿用
这些符号可以对应到真实机器人执行过程:一条轨迹是机器人从开始执行到任务结束的一次尝试。成功、失败、耗时、人类是否接管,都会被整理成训练信号。价值函数
论文主文把轨迹写为:
并使用(未加折扣的)回报定义:
策略目标是最大化:
值函数与优势可写为:
| 符号 | 含义 |
|---|---|
| 时刻 | |
| 时刻 | |
| 当前参考策略下的状态价值 | |
| 动作相对状态基线的改进量 | |
| 优势二值指示器(正/负) | |
| 任务相关的优势阈值 |
3. 奖励设计与数据组成
在真实部署任务中,首先需要把 episode 结果映射为统一的奖励监督。
论文采用通用稀疏奖励:
这一定义让价值函数学习“离成功还剩多少步”,并把失败轨迹压到更低值区。实现中把价值按任务最大长度归一化到
数据组成是三类混合:
- 示教数据(demonstrations)。
- 自主执行数据(autonomous rollouts)。
- 人类纠正数据(expert interventions)。
这里的“人类纠正”更接近 human-gated DAgger:机器人自主执行时,专家在明显要失败或已经偏离任务时接管一段动作。纠正数据主要用于避免灾难性失败、帮助探索恢复动作,但并不等价于完美监督;速度、动作流畅性和细微质量仍需要从自主轨迹的奖励反馈中学习。
不同任务每轮数据量并不统一,典型示例包括:
- T-shirt/shorts 任务:每轮约 300 条自主轨迹(4 台机器人)。
- Box assembly:每轮约 600 条自主 + 360 条纠正(3 台机器人)。
- Cafe:单轮约 414 条自主 + 429 条纠正。
因此,“600+360”应理解为特定任务设置,不是所有任务的统一单轮配额。
4. 模型构型:从 π₀ 到 π₀.6
相对
从架构来源看,rawtext 子任务文本先生成,低层动作再在它的条件下生成。
- VLM 主干升级为 Gemma 3 4B。
- 动作专家扩展到 860M 参数。
- 在输入序列中增加优势指示器文本(正/负/空条件)。
训练配方也延续了 rawtext、FAST 离散动作 token 监督与 Flow Matching 连续动作块监督,并通过 stop gradient 降低动作专家对 VLM 主干知识的扰动。这里的 FAST token 是训练表示学习信号,不是
与策略并行训练的是独立价值函数网络,采用 670M VLM backbone。策略与价值函数不共享参数更新。
架构图的关键在于策略分支与价值分支的分工:策略网络生成动作,价值函数为动作优劣提供训练信号。
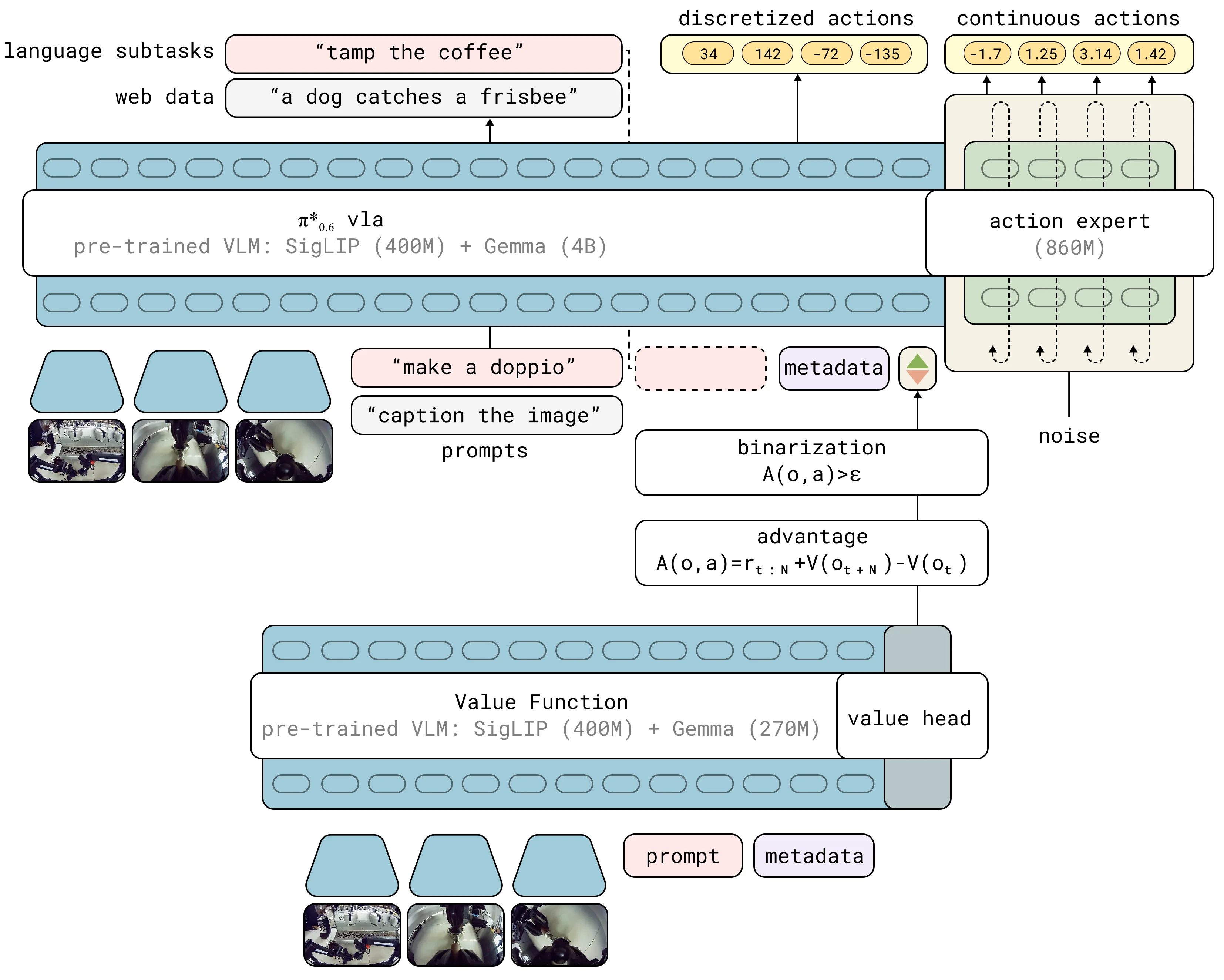
优势指示器的注入位置也很关键:它以文本 token 形式出现于 rawtext 之后、动作输出之前,因此主要调制动作相关 likelihood,而不改任务提示本身的语义输入结构。
5. 分布式价值函数训练
RTC 关注推理延迟下的动作连续性,本节回答“执行结果如何变成稳定价值监督”。
价值函数在这里不是直接预测“成功/失败”二分类,而是预测一个分布:当前状态距离成功大概还有多少剩余代价。这样做的好处是,模型可以区分“还没完成但正在变好”和“已经走向失败”这两种状态。
论文使用多任务分布式价值函数:
核心训练目标是“离散化 empirical return + 交叉熵”:
其中
这个估计比经典 off-policy Q-function 更朴素:它不显式学习所有可能动作的
训练完成后,再由分布恢复连续值:
价值函数可视化展示了成功轨迹与失败轨迹中价值重心随时间的变化趋势。
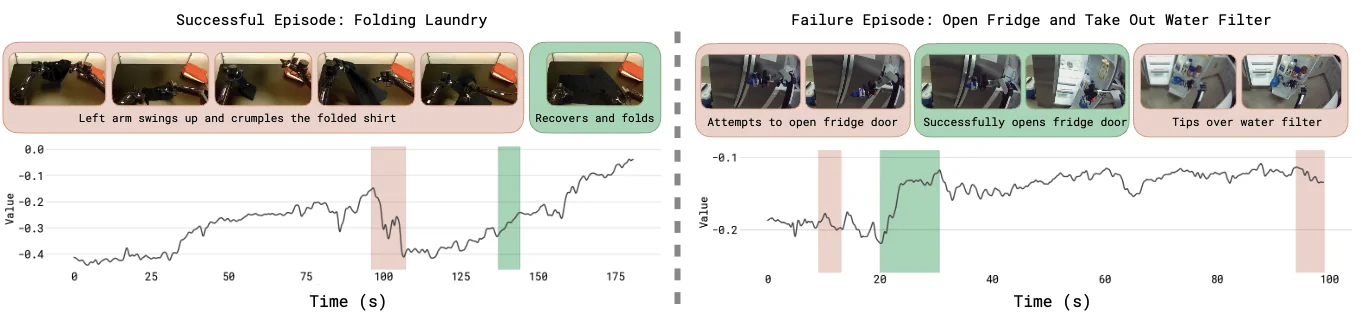
这里可以与 C51 等分布式价值方法做背景类比,但
6. 优势条件策略
本节与 RTC 不是架构继承关系,而是正交层:RTC 解决实时执行,本节解决策略更新方式。
有了价值函数后,Recap 不直接走常规 on-policy PPO 主路径,而采用优势条件策略提取。核心做法是给数据里的每个动作贴上“正优势”或“负优势”标签。模型训练时同时学习普通动作分布和正优势动作分布,推理时再偏向正优势分布。
先定义二值指示器:
策略优化目标为:
其中关键实践细节包括:
- 人类纠正动作强制设为
。 - 训练时随机 dropout 指示器(30%),以支持有条件/无条件双分布建模。
- 推理可用 CFG 进行条件锐化,但过高
可能导致动作过激,论文建议中等区间(如 )。 - post-training 阶段使用
lookahead 估计优势;pre-training 阶段可用整条 episode 回报近似优势。 是任务相关阈值,而不是固定 0。论文中 pre-training 让约 30% 示教数据成为正优势样本,finetuning 通常让约 40% rollout 成为正优势样本;对 T-shirt/shorts 这类高成功但速度偏慢的任务,会把正优势比例压到约 10%,让模型更偏向快而好的动作。
为什么不把 PPO 作为主路径:
- Flow Matching 模型不直接提供易用的显式 log-likelihood。
- 大模型离线/混合数据训练场景下,传统 on-policy 约束更难稳定扩展。
- 论文实证中,优势条件提取在 throughput 上显著优于对比的 PPO/AWR 方案。
这也是 Recap 与简单 filtered imitation 的差别。AWR 这类加权回归会弱化大量低优势样本;优势条件训练则保留完整数据,同时让模型区分“普通经验”和“更值得执行的经验”。
7. 在线闭环
基于
- 数据采集:运行当前策略,收集自主轨迹与可选人类纠正。
- 价值更新:在累积数据上训练价值函数,重新估计优势并生成
。 - 策略提取:用更新后的
重新训练策略。
其中一个稳定性关键是:策略与价值函数每轮都从 pre-trained checkpoint 初始化,而不是在上一轮权重上直接续训,用于降低多轮分布漂移风险。
graph LR
A[部署当前策略] --> B[采集自主轨迹与纠正轨迹]
B --> C[训练价值函数\n更新优势与I_t]
C --> D[优势条件策略提取]
D --> E[从预训练ckpt进入下一轮]
E --> A
训练流程还包含一个初始化阶段:先在任务示教数据上做 SFT(此时固定
8. 实验结果分析
Recap 的设计。下面把实验协议、主结果和消融统一放在同一个实验小节中阅读,避免与前面的模型机制并列成过多主章节。
8.1 实验协议
相较
这些任务的共同点是长程、多阶段,并且对失败恢复和执行速度都有要求。


论文的量化评估包含五类任务:
| 任务 | 主要难点 | 成功标准 |
|---|---|---|
| Laundry: T-shirts and shorts | 从篮子取出、摊平、折叠、堆叠,初始状态变化大 | 200 秒内折好并放到桌面右上角 |
| Laundry: diverse items | 11 类衣物混合训练,评测聚焦较难的 button-up shirt | 500 秒内折好目标衣物并放到堆叠区 |
| Laundry: targeted failure removal | 固定橙色 T-shirt,严格考察领口方向 | 200 秒内折叠正确,且领口朝上 |
| Cafe: double shot espresso | portafilter、研磨、压粉、锁入咖啡机、接咖啡、上杯 | 200 秒内完成全流程,不能掉落或洒出 |
| Box assembly | 从扁平纸板到成盒、贴标签、放入 crate,真实工厂部署 | 600 秒内完成组装、贴标和堆放 |
核心指标有两个:
| 指标 | 含义 | 为什么重要 |
|---|---|---|
| throughput | 每小时成功完成的任务数 | 同时惩罚失败和慢动作,更贴近真实部署效率 |
| success rate | episode 成功比例,由人工质量标注聚合得到 | 衡量策略是否可靠,但不单独反映速度 |
因此,Recap 要证明的是成功率和吞吐都能提升。
8.2 主结果
论文中的对比不是单纯比较“有无 RL”,而是一条逐步增强的基线阶梯:
| 对比对象 | 作用 |
|---|---|
| Pre-trained | 不使用 Recap,作为旧版 VLA 参考 |
| Pre-trained | 更强基础模型,但不含优势指示器 |
| RL pre-trained | 已在预训练阶段加入价值函数与优势条件 |
| 用目标任务示教数据微调后的首轮部署策略 | |
Recap | 加入自主执行与纠正数据后的最终策略 |
| AWR / PPO | 使用相同在线数据,但换成其他策略提取方式 |
8.2.1 吞吐提升
比较 throughput 时,重点是 offline RL + SFT 到最终 Ours 的差距。这个差距代表目标任务上真实部署数据和纠正数据带来的额外收益。
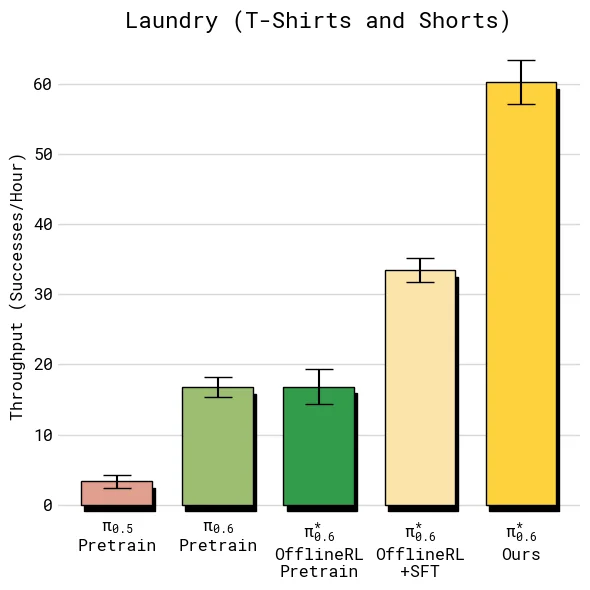
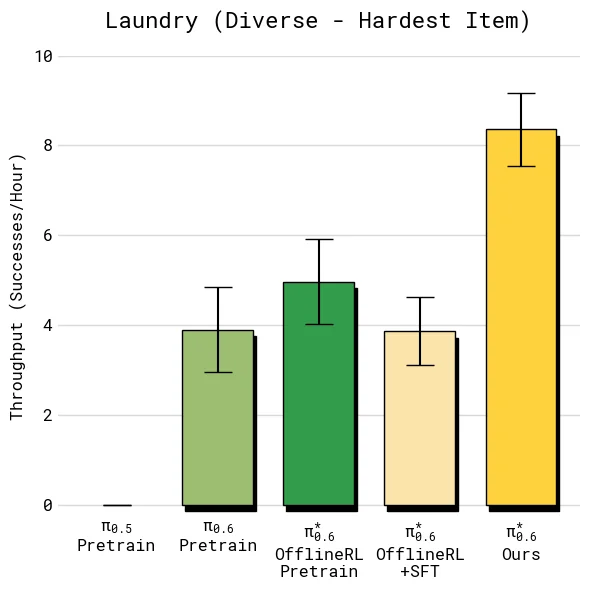
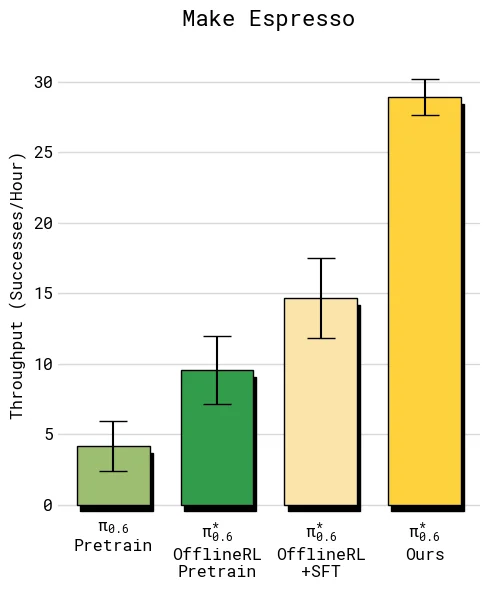
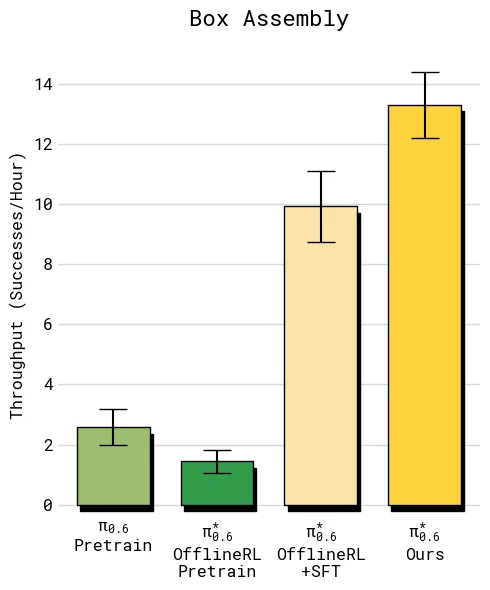
结果显示,在 diverse laundry 和 espresso 这类较难任务上,加入 on-robot 数据后的最终模型让 throughput 超过 offline RL + SFT 的 2 倍;在较容易的 T-shirt/shorts 上,成功率已经接近上限,但吞吐仍继续上升,说明 Recap 学到的不只是“避免失败”,也包括更快、更少犹豫的执行方式。
8.2.2 成功率
吞吐提升如果只来自更激进的动作,可能会牺牲成功率。因此论文同时报告 success rate。
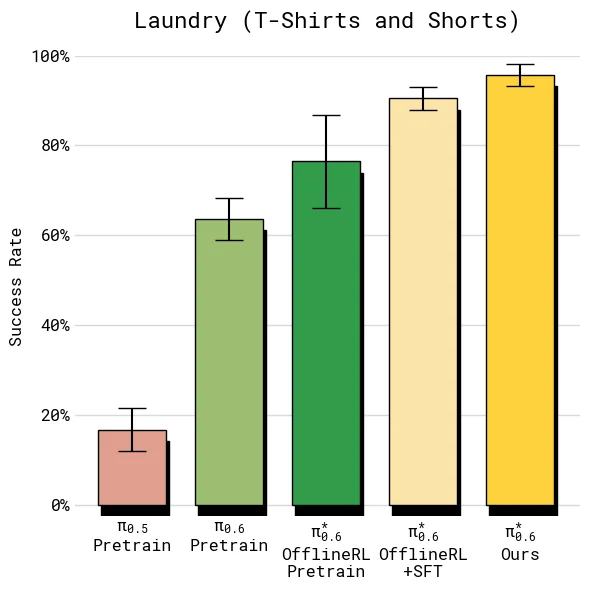
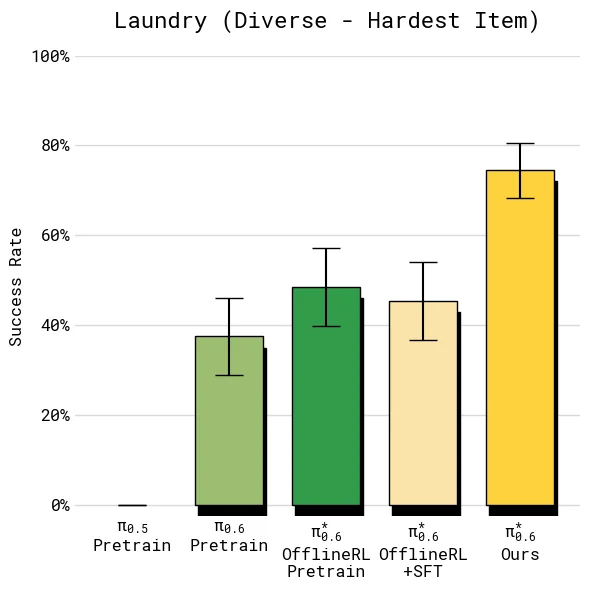

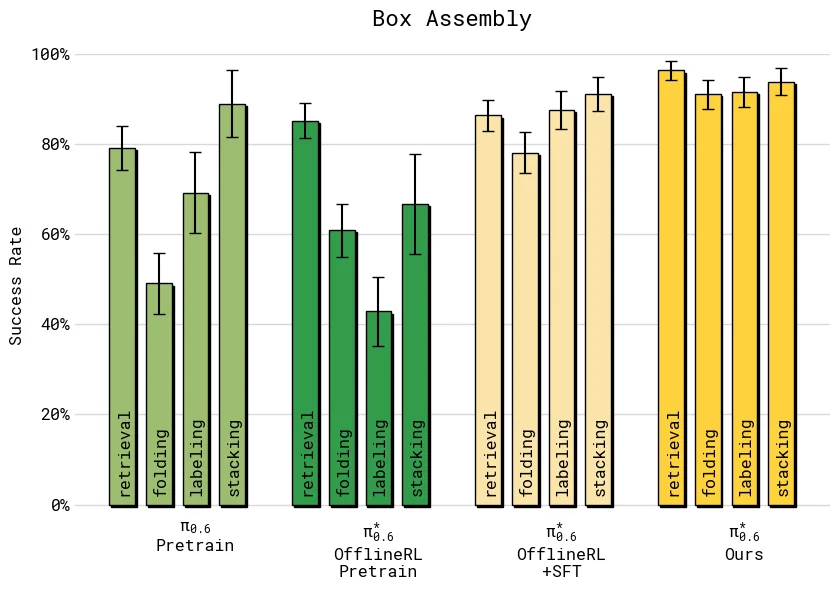
在多数任务上,最终
8.3 多轮迭代
主结果证明“有效”,消融实验回答“为什么是这套方法”。这里有三组最值得保留的证据:多轮迭代、策略提取方法对比、具体失败模式移除。
Recap 的在线闭环可以重复执行。论文在 T-shirt/shorts 和 box assembly 上展示了两轮迭代:
| 任务 | 数据协议 | 观察 |
|---|---|---|
| T-shirt/shorts | 每轮约 300 条自主轨迹,4 个机器人站点,不使用专家纠正 | 第一轮后成功率已经较高,第二轮主要继续提升 throughput |
| Box assembly | 每轮约 600 条自主轨迹 + 360 条纠正轨迹,3 个机器人 | 长程工厂任务需要更多数据,第二轮后 throughput 约达到 2 倍提升 |
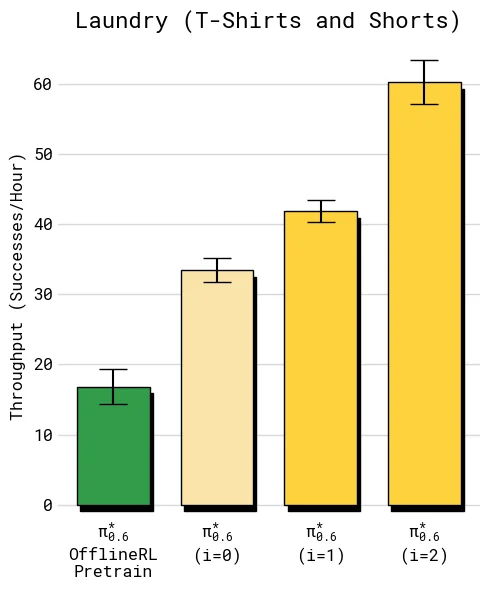
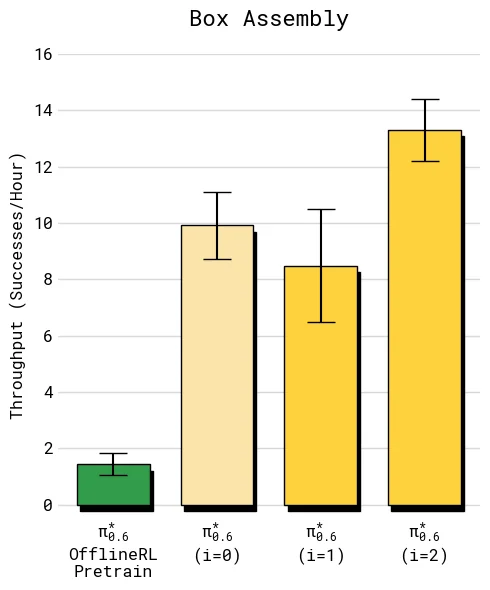
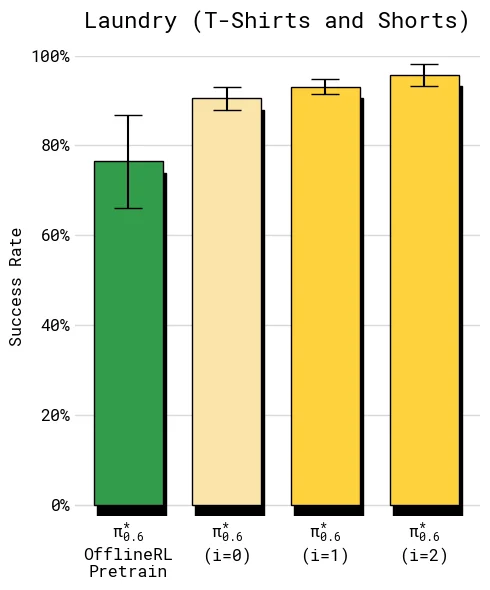
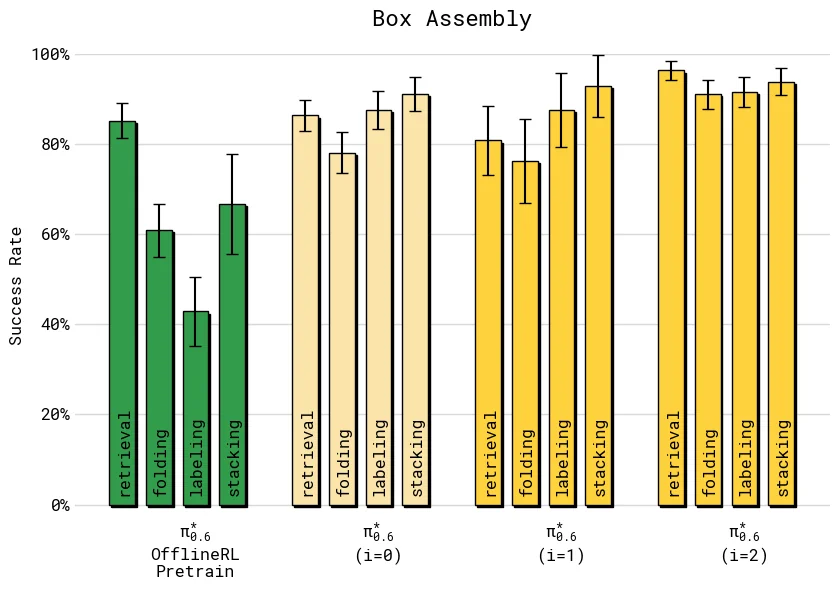
这组结果说明,Recap 不是一次性微调技巧,而是“部署 -> 收集 -> 估值 -> 提取”的迭代系统。更重要的是,不同任务的瓶颈不同:衣物任务可能先到达成功率上限,再通过价值信号学习速度;纸箱任务则需要更多轮数据来减少阶段性失败和超时。
8.4 策略提取
论文还用相同 on-robot 数据比较了三种策略提取方式:
| 方法 | 训练方式 | 主要问题 |
|---|---|---|
| Recap advantage conditioning | 保留全量数据,同时用 | 能同时利用好经验和坏经验 |
| AWR | 根据优势加权回归 | 容易弱化低优势样本,行为更慢,吞吐不足 |
| PPO | 使用近似 likelihood 和 trust-region 约束 | 在离线/混合数据场景下需要很小约束稳定训练,性能提升有限 |
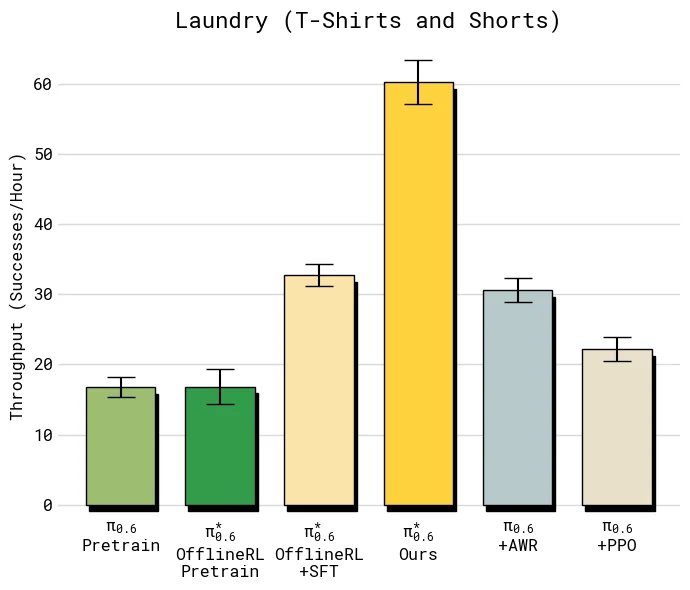
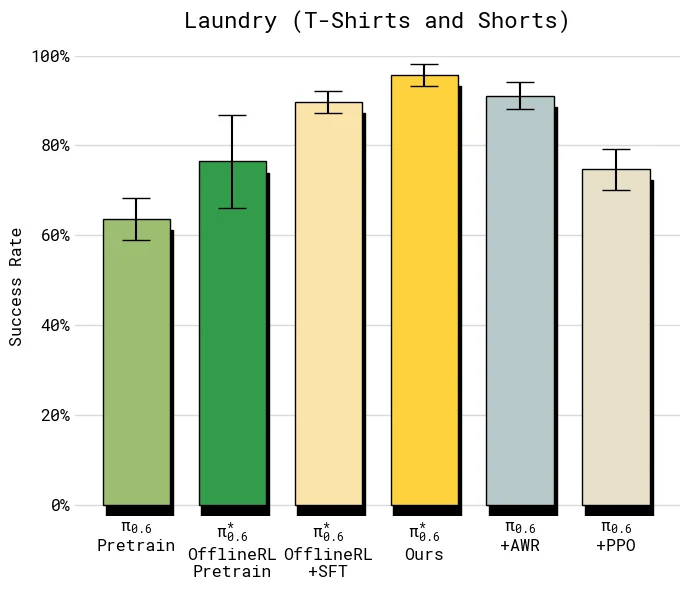
这组消融对应第 6 节的理论动机:Flow Matching Action Expert 不适合直接套标准 PPO,AWR 又更像 filtered imitation。优势条件训练的关键价值在于,它没有把失败和低优势动作简单丢掉,而是让模型学会区分“数据中出现过的普通动作”和“在当前状态下更值得执行的动作”。
8.5 失败模式移除
最后一组实验专门考察“能否移除一个明确失败模式”。任务被设置成固定橙色 T-shirt,严格要求折叠后领口朝上。这个设置比普通成功率更苛刻,因为策略不能只是把衣服大致折起来,还要纠正一个具体偏差。
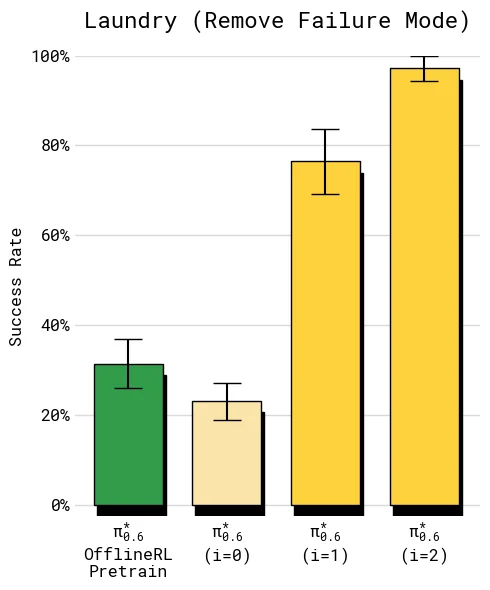
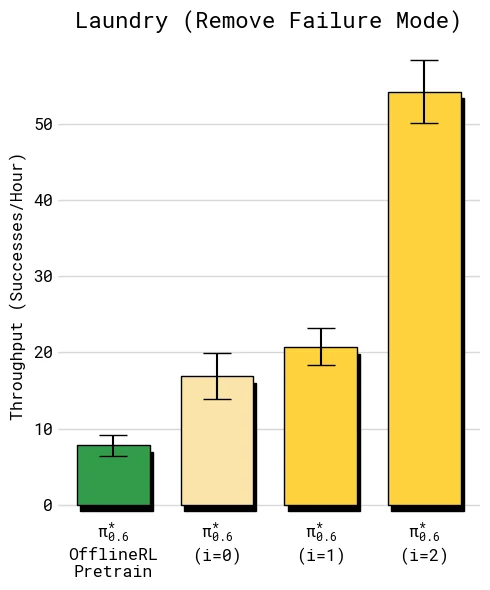
这组实验说明,Recap 不只是提升平均分,还可以把某类部署中反复出现的错误转成奖励和优势信号,再通过策略提取改变后续行为。对真实机器人系统来说,这类“定点修复失败模式”的能力往往比单次 benchmark 分数更有工程价值。
9. 局限
论文 Discussion 明确的限制包括:
- 系统仍依赖人工参与(奖励标注、纠正、场景复位)。
- 探索策略偏朴素,主要依赖策略随机性与人工纠偏。
- 当前是迭代离线更新流程,而非并发实时在线 RL。
因此,