12. π₀.7:可引导与组合泛化
先修建议
- 已完成第 9 讲
,理解 VLM Backbone + Action Expert + Flow Matching的基本结构。 - 已完成第 11 讲实时执行和第 12 讲
/ Recap,理解 action chunk、RTC 与 specialist 强化的作用。 - 熟悉机器人数据里常见的质量差异:同一任务可能有快慢不同、策略不同、成功与失败混杂的轨迹。
本节目标
- 理解
的核心变化:从“只告诉模型做什么”扩展到“同时告诉模型怎么做”。 - 看懂
language / metadata / control mode / subgoal image组成的多模态 prompt。 - 解释为什么带有 metadata 的 prompt 能让模型利用低质量示范、失败轨迹和自主策略数据。
- 区分四类能力:灵巧任务 out-of-the-box、语言跟随、跨机体迁移、组合泛化。
- 明确
的边界:它已经显示出组合泛化迹象,但还不是任意任务都稳定成功的通用机器人。
这带来一个很重要的变化:模型不只是学习“这个任务应该做什么动作”,还学习“在什么条件下采用哪种做法”。这就是 steerable 的含义。
1. π₀.7 定位
如何把更多来源、更杂质量的数据放进同一个 VLA,同时还能在推理时精确引导模型做出想要的行为。
前几代模型的侧重点不同:
| 模型 | 核心关注点 | 与 |
|---|---|---|
| 用 VLM 主干和 Action Expert 生成连续动作块 | 提供基础 VLA 架构 | |
| 用高层语言策略拆分长时序任务 | 为 subtask instruction 和 coaching 铺路 | |
| 用 Recap 和 RL specialist 提升任务内鲁棒性与吞吐 | 为 | |
| 用多模态 prompt 统一异构数据,并在运行时可引导 | 当前模型 |
系统分为两个层次:训练时把多种数据和多模态 prompt 一起喂给 VLA;推理时由高层策略产生子任务语言,由 world model 产生视觉子目标,再一起引导底层动作模型。
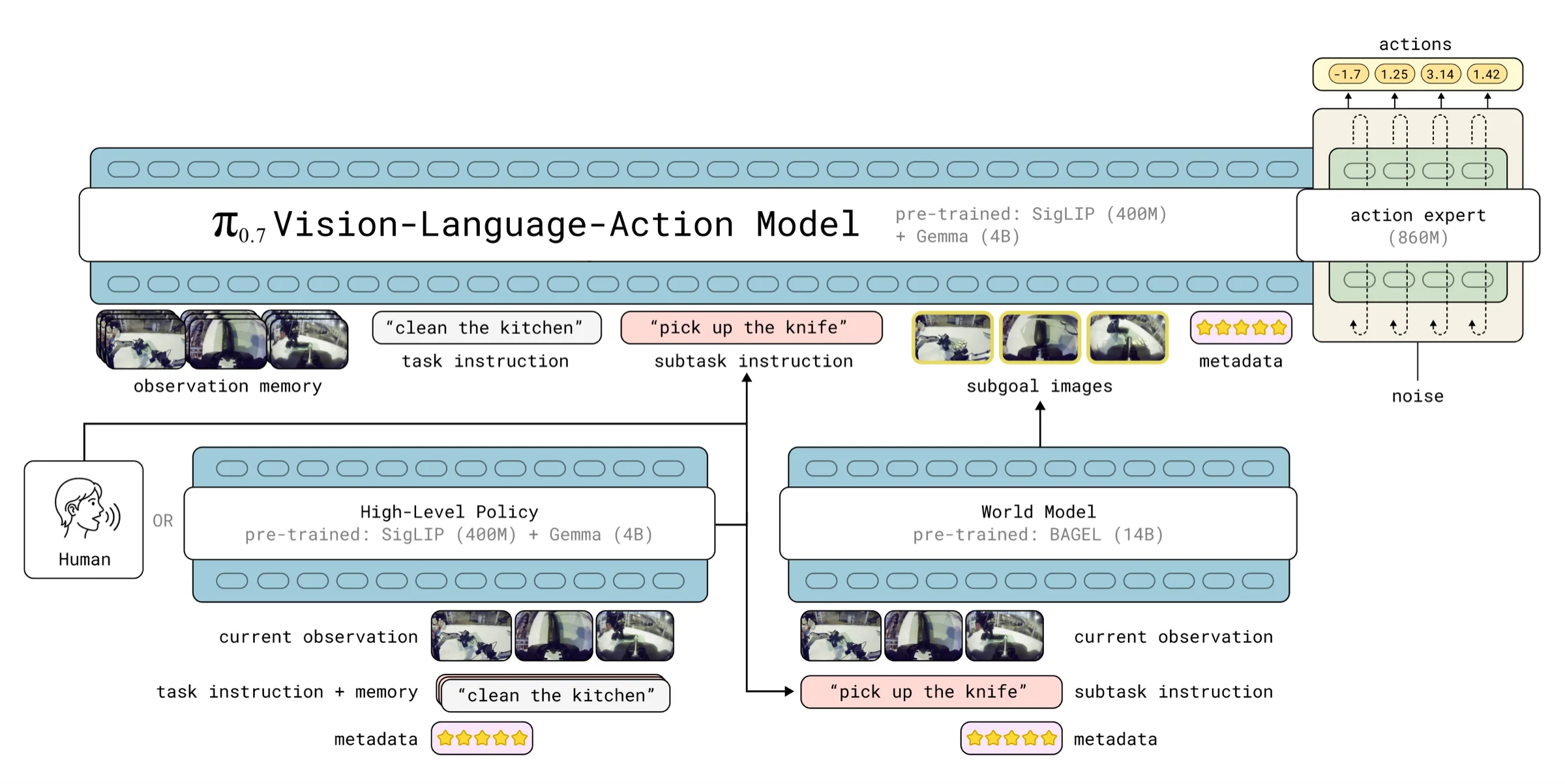
2. π₀.7 在建模什么
其中:
| 符号 | 含义 |
|---|---|
| 最近一段观测历史,包括多视角图像和本体状态 | |
| 从当前时刻开始的未来动作块 | |
| 动作块长度, | |
| prompt / context,包含语言、metadata、控制方式和可选子目标图 | |
| 训练后的 VLA 策略 |
第 9 讲中的
| 上下文 | 作用 |
|---|---|
| 总任务语言,例如“清理厨房” | |
| 当前子任务语言,例如“打开冰箱门” | |
| 视觉子目标图,描述下一阶段完成后的画面 | |
| episode metadata,描述速度、质量和是否犯错 | |
| control mode,指定 joint 或 end-effector 控制 |
这一定义的关键点是:模型参数不一定改变,但行为可以通过 prompt 改变。
也就是说,
3. 多模态 prompt

3.1 子任务语言
总任务语言通常太粗。例如“清理厨房”并不告诉机器人下一秒该拿杯子、开抽屉,还是关冰箱。
子任务语言有三种来源:
- 数据标注时对轨迹片段做细粒度描述。
- 推理时由人类 supervisor 逐步 coaching。
- coaching 之后,用这些语言序列训练高层策略,让高层策略自动产生下一条子任务指令。
这使得“教机器人新任务”不一定要采集新的低层动作示范。对于复杂新任务,可以先用语言带着模型走几遍,再把这些语言指导数据用于训练高层语言策略。
3.2 子目标图
语言适合表达“打开冰箱门”,但很难精确表达“手应该抓在把手哪个位置、门开到什么角度、物体最后在哪个空间位置”。子目标图就是为了解决这类空间歧义。
子目标图采用 multi-view subgoals:
每个
推理时,子目标图由轻量 world model 生成。这个 world model 基于 BAGEL 14B 图像理解、编辑和生成模型初始化,并使用机器人数据、第一视角人类视频、开放图像编辑数据和视频数据训练。它的作用不是直接控制机器人,而是把“下一步希望看到什么画面”转成 VLA 能用的视觉条件。
3.3 Episode metadata
机器人数据很少天然干净。真实数据里会混有:
- 高质量人工示范。
- 带错误但仍然有学习价值的示范。
- 失败轨迹。
- 旧模型或 RL specialist 运行时产生的自主数据。
如果直接把这些数据混在一起训练,模型容易学到“平均行为”:既不像最优策略那么快,也不像失败轨迹那样明显错误,但整体不够好。
| metadata | 含义 | 推理时怎么用 |
|---|---|---|
| Overall speed | episode 长度,按 500 timestep 分桶 | 设置为该任务 episode length 的第 15 百分位,鼓励较快完成 |
| Overall quality | 1 到 5 的任务质量评分,5 最高 | 固定设为 5 |
| Mistake | 当前片段是否包含抓取失败、做错子任务等错误 | 固定设为 false |
这相当于告诉模型:训练时可以看低质量数据,但推理时请生成“快、高质量、无错误”的行为模式。
3.4 Control mode
推理时可以按任务选择控制模式。跨机体实验也比较了 joint-space 和 end-effector 控制,结果显示 prior models 上 end-effector 并没有明显优势,因此主实验主要使用 joint-space control。
3.5 Prompt dropout
训练时并不是每条样本都给完整 prompt。模型会随机 drop 一部分上下文,使推理时既能用完整提示,也能在缺少某些提示时工作。几个关键设置是:
- 只有
25%batch 样本加入视觉子目标图。 - 有子目标图时,子任务语言再以
30%概率 drop,因为图像有时可以替代文字说明。 - Episode metadata 整体以
15%概率 drop,每个 metadata 组件再以5%概率单独 drop。 - Control mode 不做 dropout。
这一步很重要。否则模型可能过度依赖某一种提示形式,一旦推理时缺少子目标图或 metadata,就无法稳定运行。
4. 数据与模型结构
4.1 数据来源
- 多机器人、多任务、多环境的人类示范数据。
- 大量 policy evaluation 中产生的自主数据。
- policy rollout 中的人类干预数据。
- 开源机器人数据集。
- 第一视角人类视频。
- Web 辅助数据,例如目标定位、属性预测、VQA、文本预测和视频 caption。
相对经典 VLA 训练管线,最关键的变化是:
这和第 12 讲有直接关系。
4.2 模型架构
| 组件 | 配置 |
|---|---|
| VLM backbone | Gemma3 4B,包括约 400M vision encoder |
| History encoder | MEM-style video history encoder,对历史图像做时空压缩 |
| Action Expert | 860M Transformer,用 Flow Matching 预测连续动作 |
| 总规模 | 约 5B 参数 |
| 输入图像 | 最多 4 路相机:front、两个 wrist、可选 rear |
| 历史帧 | 每路最多 6 帧,采样间隔 1 秒 |
| 子目标图 | 最多 3 路,通常不包括 rear view |
| 图像分辨率 | 观测和子目标先 resize 到 448x448 |
| 动作块 | 50 个 action tokens |
和
- 历史信息更系统地进入模型:使用 MEM 式视频历史编码器,不只看当前帧。
- 子目标图进入上下文:goal-image tokens 与 observation tokens 采用 block-causal attention,目标图可以看观测,从而把当前状态和期望状态对齐。
Action Expert 仍然是连续动作生成模块。它用 flow matching objective 预测动作块,并通过 adaptive RMSNorm 注入 flow timestep 信息。为了应对实时推理延迟,0-12 个 timestep 的延迟,相当于覆盖 50Hz 机器人上最多 240ms 的推理延迟。
5. 运行时引导
flowchart LR
T["Task Instruction"] --> H["High-Level Policy 或 Human Coaching"]
H --> S["Subtask Instruction"]
S --> W["World Model"]
O["Observation History"] --> W
M["Metadata: fast / quality=5 / mistake=false"] --> W
W --> G["Subgoal Images"]
T --> C["Prompt Context"]
S --> C
G --> C
M --> C
K["Control Mode: joint 或 ee"] --> C
O --> V["π₀.7 VLA"]
C --> V
V --> A["50-step Action Chunk"]
A --> E["Execute 15 或 25 steps"]
默认 runtime 设置如下:
| 项目 | 设置 |
|---|---|
| Control mode | 每个任务都会提供 |
| Overall speed | 设为该任务 episode length 的第 15 百分位 |
| Overall quality | 固定为 5 |
| Mistake | 固定为 false |
| Subtask instruction | 来自高层语言策略或人类 coaching |
| Subgoal refresh | 子任务变化时刷新,或每 4s 刷新一次 |
| Action generation | 5 个 denoising steps 生成 50-step action chunk |
| 执行动作 | 每次执行其中 |
| 推理方式 | 子任务生成、子目标生成和 VLA 动作生成异步运行 |
这个流程说明了“可引导”具体发生在哪里:人类或高层策略不直接输出关节动作,而是输出更高层的子任务语言;world model 把子任务语言变成目标画面;VLA 再把观测、子任务、目标图和 metadata 合成动作。
推理开销也需要关注:最小版本在单张 H100 上可达到约 38ms;启用 MEM 视觉编码器和子目标图后,最坏约 127ms。子目标图生成更重,world model 使用 4 张 H100、8-bit 大矩阵乘、SageAttention 等优化后,25 个 denoising steps 约 1.25s。因此系统采用异步策略,让 VLA 继续执行已有动作,同时 world model 生成下一张子目标图。
6. 实验结果分析
6.1 灵巧任务
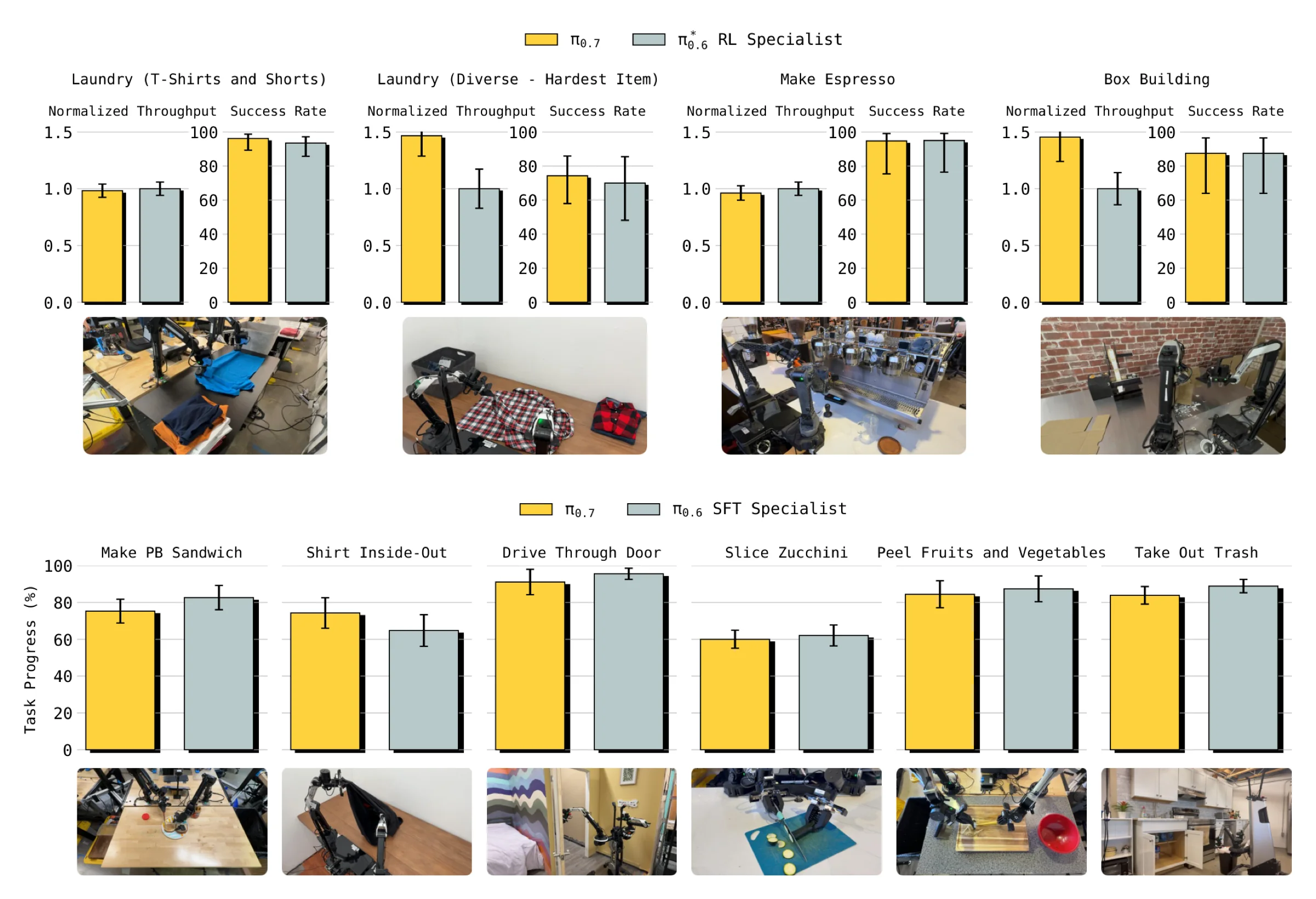
第一组实验验证一个很实际的问题:单个 generalist
评估任务包括:
中的 espresso、box building、laundry folding。 - Robot Olympics 风格任务,如 peanut butter sandwich、shirt inside-out、drive through door。
- 新增灵巧任务,如切 zucchini、削果蔬、换垃圾袋。
结论是:同一个
这不是因为
6.1.1 消融实验
两个重要消融设置如下:
(no metadata):不把 episode metadata 放进上下文。 (no eval data):训练时移除自主评测 episode,因此无法蒸馏强策略 rollout。
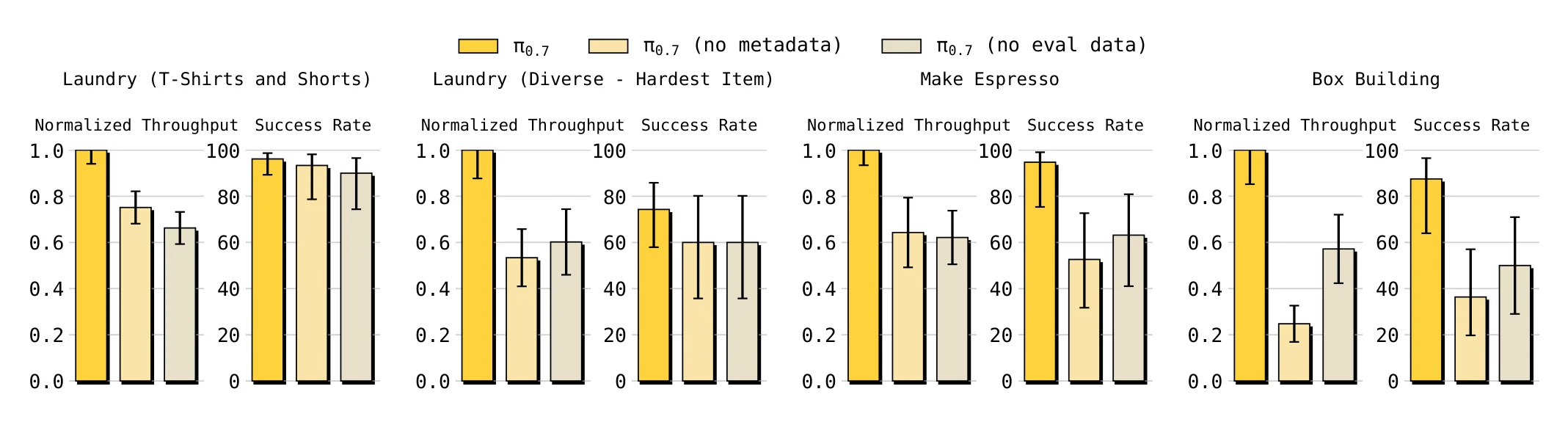
结果显示完整
显式记忆任务包括 Swap 3 Mugs、Find Object、Scoop Coffee、Window Cleaning。
6.2 语言跟随与数据偏置
6.2.1 未见环境中的开放指令
这组评估覆盖 4 个未见厨房、2 个未见卧室和 14 个 instruction-following scenarios。每个场景包含 3-6 步开放指令,例如整理物品、移动家具相关物体、清理洒出的东西。

这组实验想验证的是广度:面对没见过的房间和不固定的语言任务,模型是否还会注意指令。结果显示
6.2.2 复杂指代与反数据偏置
更难的语言测试包括两类:
- 复杂指代:例如“拿起桌上最大的碗”“拿起用来喝汤的物体”“拿起最大盘子上的水果”。
- 反数据偏置:例如平时数据里把垃圾放进垃圾桶、餐具放进 bussing bin;测试时要求反过来做。
反数据偏置实验包括:
Reverse Bussing:把垃圾放进 bussing bin,把餐具放进 trash。Reverse Fridge to Microwave:训练数据常见方向是从冰箱到微波炉,测试时要求从微波炉放回冰箱。
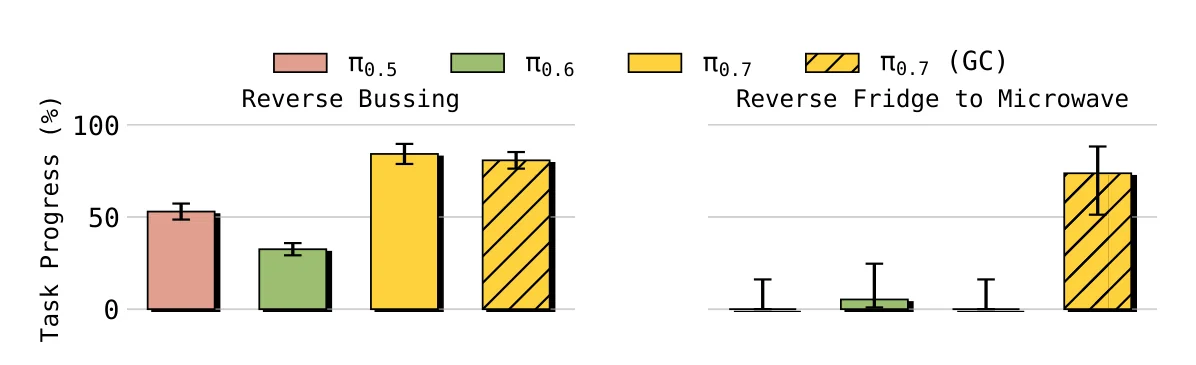
这组实验对理解 steerable 很重要。模型如果只是记住场景中的常见动作,就很难完成反方向任务;
6.3 跨机体迁移
跨机体迁移的问题是:训练数据来自一种机器人,模型能否在另一种机器人上做同一类任务?这比普通场景泛化更难,因为手臂长度、惯量、夹爪位置和可达空间都变了。
实验机器人包括双臂移动操作平台、静态双臂平台和双臂 UR5e。UR5e 更长、更重,放在桌子两侧,操作策略与轻量静态双臂机器人明显不同。
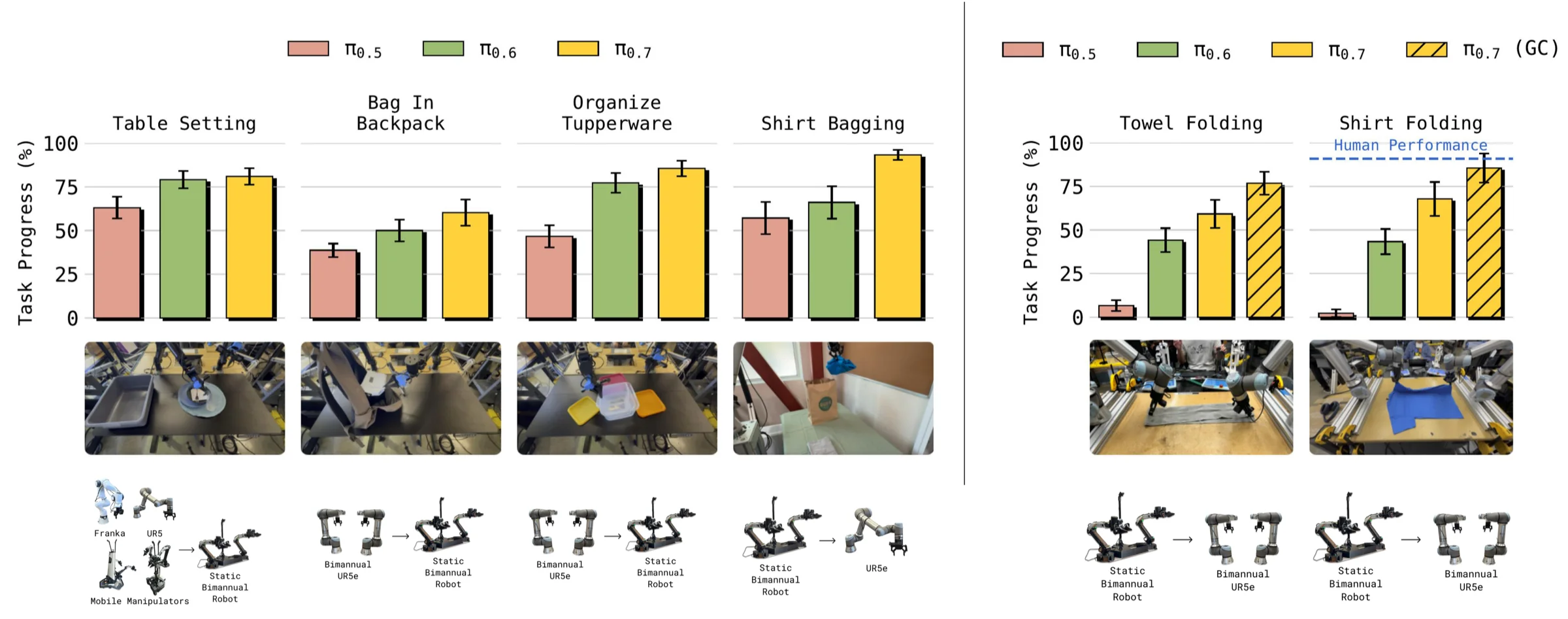
实验分两类:
- 物体重排类任务:Table Setting、Bag In Backpack、Organize Tupperware、Shirt Bagging。
- 灵巧布料任务:towel / t-shirt folding,从轻量静态双臂机器人迁移到双臂 UR5e。
最值得注意的是 shirt folding。训练数据中没有 UR5e 上的 laundry folding,但
更强的基线来自 10 位经验丰富的遥操作员。他们平均有约 375 小时遥操作经验,且都没有在 UR5e 上做过 shirt folding。结果是:
| 对象 | Task progress | Success rate |
|---|---|---|
| 专家遥操作员 | 90.9% | 80.6% |
85.6% | 80% |
这个结果的含义不是“模型全面超过人类专家”,而是说明在这个零样本跨机体设置下,
6.4 组合泛化与 coaching
组合泛化关注的是另一个问题:模型能否把训练中见过的子技能重新组合,用在没有动作级示范的新任务上。
任务可以分成短时序和长时序两类。
6.4.1 短时序任务
- 按下 French press plunger。
- 把米舀进电饭煲。
- 用布擦办公物品。
- 转动带关节的物体,例如 gear set 和 desk fan。
这些任务不是简单的物体标签泛化,而是需要把已有抓取、接触、擦拭、旋转等技能用到新物体和新语义目标上。
6.4.2 长时序任务
对于更长、更复杂的任务,直接一句话 prompt 仍然不够。代表性例子包括:
Loading an Air Fryer:打开空气炸锅,把红薯放进去,再关上。Unloading an Air Fryer:拉出空气炸锅篮,把食物倒到盘子里。Toasting a Bagel:把贝果放入烤箱,启动加热,再取盘子和贝果。
这些任务需要多阶段交互,最长约 5 分钟。训练数据中没有这些任务的动作级示范,但可能存在相似家电、相似物体或相似子动作。

结果显示,
6.4.3 自治高层策略
更关键的一步是:coaching 数据本身可以训练高层语言策略。也就是说,低层动作不需要新遥操作示范;只要收集人类给出的分步语言指导,就能让高层策略学会在运行中自动给
五个未见任务上的比较包括:
(coaching):运行时由人类给分步语言指导。 (autonomous):高层策略自动生成这些分步语言。
结果显示,autonomous 版本大致能接近 live coaching 的表现。这是
6.5 混杂数据
最后一组消融回答一个基础问题:多样但混杂的数据到底是不是有用?
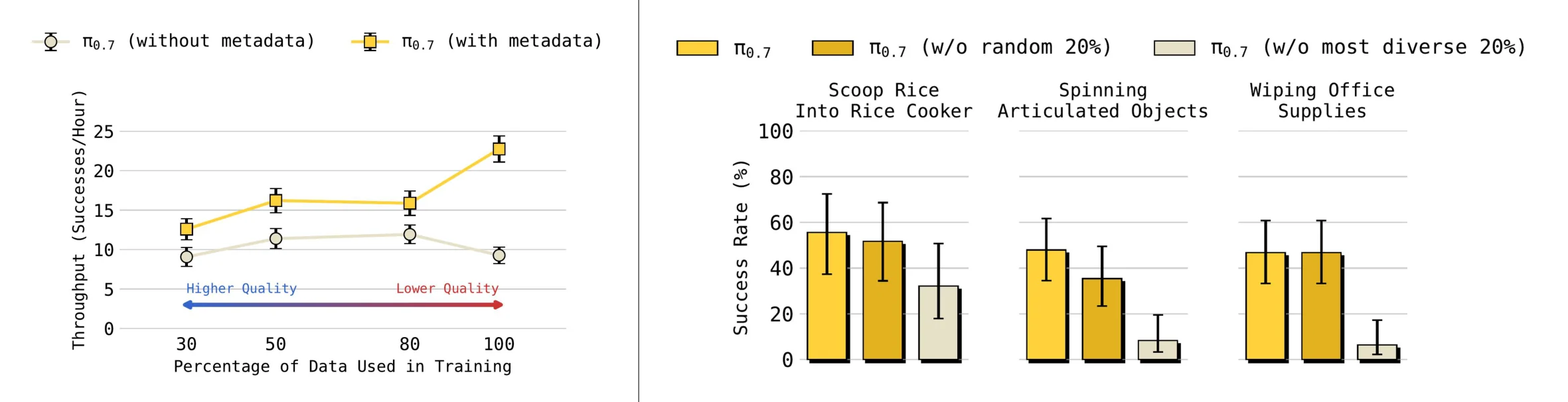
6.5.1 混合质量数据
以 Laundry (T-Shirts and Shorts) 为例,可以根据 fold quality 和 speed 把人工数据分成四个桶:
- 前
30%。 - 前
50%。 - 前
80%。 - 全部数据。
然后训练带 metadata 和不带 metadata 的模型。结果很清楚:
- 不带 metadata:加入更多低质量数据后,性能可能变差。
- 带 metadata:即使平均数据质量下降,模型仍能从更多数据中持续提升。
这说明 metadata 不是装饰项,而是让大规模混杂数据可扩展的关键条件。
6.5.2 高多样性数据
高多样性数据的消融比较了两种移除方式:
- 随机移除
20%数据。 - 移除任务多样性最高的
20%数据。
两者数据量相同,但结果不同。移除最高多样性的 20% 后,新短时序任务表现显著下降;随机移除 20% 的影响较小。这说明任务多样性本身对组合泛化有贡献。
7. 能力边界
第一,零样本泛化仍低于分布内任务。seen tasks 常常有超过 90% 的成功率;unseen tasks 或 unseen task-robot combinations 通常在 60-80% 区间。
第二,“seen / unseen” 很难严格划清。大规模机器人数据中可能包含相关物体、相似动作或相似场景,只是没有同名任务标签。所谓组合泛化可能更多是把已有技能和语义概念重新混合,而不是凭空产生全新能力。
第三,生成子目标图本身仍有成本和质量限制。World model 能引入 web-scale 视觉知识,但它也需要异步推理、多 GPU 优化和高质量分段语言标签;如果子目标图错误,底层策略可能被引向错误状态。
第四,
因此,不应把
8. 小结
- 用多模态 prompt 描述任务、子步骤、速度、质量、错误和目标画面。
- 用 metadata 消除混杂数据里的行为歧义,让低质量示范、失败轨迹、自主策略数据也能被利用。
- 用高层语言策略和 world model 在推理时持续生成可执行上下文。
- 用同一个 generalist 模型接近 specialist 灵巧任务表现,并展示语言跟随、跨机体迁移和组合泛化。
从课程脉络看,Recap 解决了任务内 specialist 强化,