6. 策略训练
上一章的 trot 是我们编程让它走;这一章我们让它学会走。我们会把 Pupper 仿真包成一个 Gymnasium 环境,用 PPO 训练一条能向任意方向走的策略,并和 §5 的开环步态对比。
本章目标
- 能把 MuJoCo 仿真封装成标准
gymnasium.Env - 能读懂并补齐 Lab 6 的 36 × 15 = 540 维栈式观测、12 维 PD 残差动作和 18 项加权奖励
- 能用
stable-baselines3跑完一轮 PPO 训练并解读tensorboard曲线 - 能识别奖励函数里 penalty 项 / tracking 项的两种符号约定,不把它们弄反
前置阅读
- 第 4–5 章
- 强化学习 · 绪论
- 强化学习 · 策略梯度
- 项目 · DDPG Reacher-v5(熟悉连续动作训练)
6.1 为什么能学
§5 的 trot 是把"哪条腿什么时候抬、抬多高、落哪里"全写死的脚本。改地形要重写,改速度要重调,改 Pupper 的腿长要从头来一遍——控制器和机器人是绑死的。
RL 把这件事反过来做:把奖励写下来,让策略自己摸索哪条腿什么时候抬。好处不是 RL 一定比 trot 跑得快(在平地上多半还跑不过手写 trot),而是同一份训练流程可以:
- 换地形(小坡、小石子、有摩擦的地毯)只要重训不改代码;
- 换机器人(Pupper → Go1 → Anymal)只要换 URDF 和动作维度;
- 推扰、负载变化、电池电压抖动这些手写 trot 难以全部覆盖的工况,靠域随机化一并放进训练分布。
类比(来自 CS123 Lab 5 slides):教小孩走路不是手把手安排每一步,而是给一个"看到目标就靠近 + 不摔倒"的内在奖励。但这套基础奖励远远不够——直接训出来的策略往往是"四肢狂甩往前冲"。下面 §6.4 会把这件事拆成"主奖励 + 四类辅助奖励"的标准结构。
代价也清楚:奖励工程要花时间、训练要花算力、sim2real 还要花一轮调参。这章不只讲怎么把策略训出来,也会把这些成本分别出在哪、该怎么处理讲清楚。
6.2 Gymnasium 环境
Pupper 的 RL 环境本质就是 MuJoCo 仿真套一个 Gymnasium 标准接口,重点是把 reset / step / observation_space / action_space 四件套写干净。下面这段和动手实践 lab_6_rl_pupper/envs/pupper_env.py 保持同一套接口,只省略了关节名、IK 站姿求解和若干导入:
import gymnasium as gym
from gymnasium import spaces
import mujoco
import numpy as np
from pathlib import Path
EXERCISES_DIR = Path(__file__).resolve().parents[2]
DEFAULT_XML = str(EXERCISES_DIR / "shared" / "models" / "pupper_v3_floating.xml")
KP, KD = 5.0, 0.25
ACTION_SCALE = 1.0
DEFAULT_POSE = np.array([0.26, 0.0, -0.52, -0.26, 0.0, 0.52,
0.26, 0.0, -0.52, -0.26, 0.0, 0.52])
MAX_STEPS = 1000
N_STACK = 15
OBS_PER_STEP = 36
class PupperEnv(gym.Env):
def __init__(self, xml=DEFAULT_XML, dt=0.02, max_steps=MAX_STEPS):
self.model = mujoco.MjModel.from_xml_path(xml)
self.data = mujoco.MjData(self.model)
self.dt, self.max_steps = dt, max_steps
# 12 维连续动作:每个关节一个 PD 残差(归一化到 [-1, 1])
self.action_space = spaces.Box(-1.0, 1.0, (12,), np.float32)
# 单步 36 维,栈 15 帧 → 540 维;顺序和 _get_obs() 完全一致
# 单步组成:
# 6 + 3 + 3 + 12 + 12 = 36
# IMU cmd desired_z 关节差 last_act
# 其中 IMU = (角速度 3 + 重力方向 3),含 ~1 步随机 latency 与噪声。
self.observation_space = spaces.Box(
-100.0, 100.0, (N_STACK * OBS_PER_STEP,), np.float32,
)
self._joint_qpos_ids, self._joint_qvel_ids = joint_qpos_qvel_ids(
self.model, JOINT_NAMES,
)
self._base_id = mujoco.mj_name2id(self.model, mujoco.mjtObj.mjOBJ_BODY, "base_link")
self._foot_body_ids = [
mujoco.mj_name2id(self.model, mujoco.mjtObj.mjOBJ_BODY, name)
for name in FOOT_BODIES
]
self._setup_pd()
self.last_action = np.zeros(12, np.float32)
self.cmd = np.zeros(3, np.float32)
self.step_count = 0
def _setup_pd(self):
# XML 里用 position actuator;ctrl 写目标角,MuJoCo 内部按 Kp/Kd 产生力矩。
self.model.actuator_gainprm[:, 0] = KP
self.model.actuator_biasprm[:, 1] = -KP
self.model.actuator_biasprm[:, 2] = -KD
def reset(self, *, seed=None, options=None):
super().reset(seed=seed)
mujoco.mj_resetData(self.model, self.data)
# 初始位姿做随机化,迫使策略对绝对位置不敏感
x = self.np_random.uniform(-2.0, 2.0)
y = self.np_random.uniform(-2.0, 2.0)
z = self.np_random.uniform(0.15, 0.20)
yaw = self.np_random.uniform(-np.pi, np.pi)
self.data.qpos[0:3] = [x, y, z]
self.data.qpos[3:7] = [np.cos(yaw / 2), 0.0, 0.0, np.sin(yaw / 2)]
self.data.qpos[self._joint_qpos_ids] = DEFAULT_POSE
self.data.qvel[:] = 0.0
self.data.ctrl[:] = DEFAULT_POSE
mujoco.mj_forward(self.model, self.data)
self.last_action = np.zeros(12, np.float32)
self.cmd = self._sample_command() # 随机给一个速度命令
self.step_count = 0
return self._get_obs(), {} # _get_obs 内部维护 15 帧栈
def step(self, action):
action = np.asarray(action, dtype=np.float32).clip(-1.0, 1.0)
# 偶发 kick:对 base 速度加 ±0.2 m/s 的扰动(2% 概率),模拟外力冲击
if self.np_random.uniform() < 0.02:
self.data.qvel[0:2] += self.np_random.uniform(-1, 1, 2) * 0.2
target = DEFAULT_POSE + ACTION_SCALE * action
self.data.ctrl[:] = target
n_sub = max(1, int(self.dt / self.model.opt.timestep))
for _ in range(n_sub):
mujoco.mj_step(self.model, self.data)
reward, info = self._compute_reward(action)
self.last_action = action.copy()
self.step_count += 1
terminated = self._is_fallen()
truncated = self.step_count >= self.max_steps
return self._get_obs(), reward, terminated, truncated, info
def _get_obs(self):
# 单步 36 维(本节略去 IMU latency 与高斯噪声的细节,见 envs/pupper_env.py)
local_ang = base_local_angular_vel(self.model, self.data, self._base_id)
gravity = base_local_gravity(self.model, self.data, self._base_id)
joint_dq = self.data.qpos[self._joint_qpos_ids] - DEFAULT_POSE
obs_step = np.concatenate([
local_ang, # 3
gravity, # 3
self.cmd, # 3
self.desired_world_z, # 3
joint_dq, # 12
self.last_action, # 12
]).astype(np.float32)
# 滚动 stack:新帧推到最前
self._obs_history = np.roll(self._obs_history, OBS_PER_STEP)
self._obs_history[:OBS_PER_STEP] = obs_step
return self._obs_history.copy()
几个细节比看起来重要得多:
- 观测里塞"上一步动作"。少了它,策略经常学出高频抖动——因为它无法知道自己刚才输出了什么。
- 观测里用 base 系下的重力方向而不是世界系下的四元数。这样可以让策略对绝对朝向不敏感,转一圈也不会失忆——sim2real 时这个细节救命。
- 15 帧 stack。单步 36 维信息密度低,policy 看不到速度趋势;栈 15 帧给它一个 ~0.3 秒的滑动窗口,足够分辨"正在加速 vs 正在减速"这种关键信号。
ctrl里写目标角,不是直接写力矩。Lab 6 的 MJCF 用 position actuator,_setup_pd()把KP/KD写进 actuator 参数;力矩仍可从data.qfrc_actuator读出来做能耗惩罚。step里跑多个物理步。仿真器 timestep 4 ms(250 Hz)保证数值稳定,控制环 50 Hz 已够;n_sub = 5。KP=5, KD=0.25比 Lab 4 / 5 的硬件值更软。RL 训练用软 PD 更容易"碰撞鲁棒"——策略偶尔踩到自己也不会瞬间崩到关节限位。
6.3 动作设计
12 维连续动作直接喂给关节 PD 的目标角,写法上有三档:
| 方案 | 公式 | 优点 | 缺点 |
|---|---|---|---|
| 直接目标角 | target = a * scale + offset | 简单直观 | 探索一开始就把腿甩飞 |
| PD 残差(推荐) | target = stand_pose + scale * a | 训练初期就能"站住",从站姿出发学走 | 多一行代码 |
| 增量 | target_t = target_{t-1} + step * a | 平滑 | 容易飘,训练后期会越走越偏 |
scale = 0.3 ~ 0.5 rad 是经验值——大到能学出步态,小到不会一上来就翻。先 stand 再 walk 是这条选择背后真正的动机:环境一上来不"立即崩盘",奖励信号才有梯度可以爬。
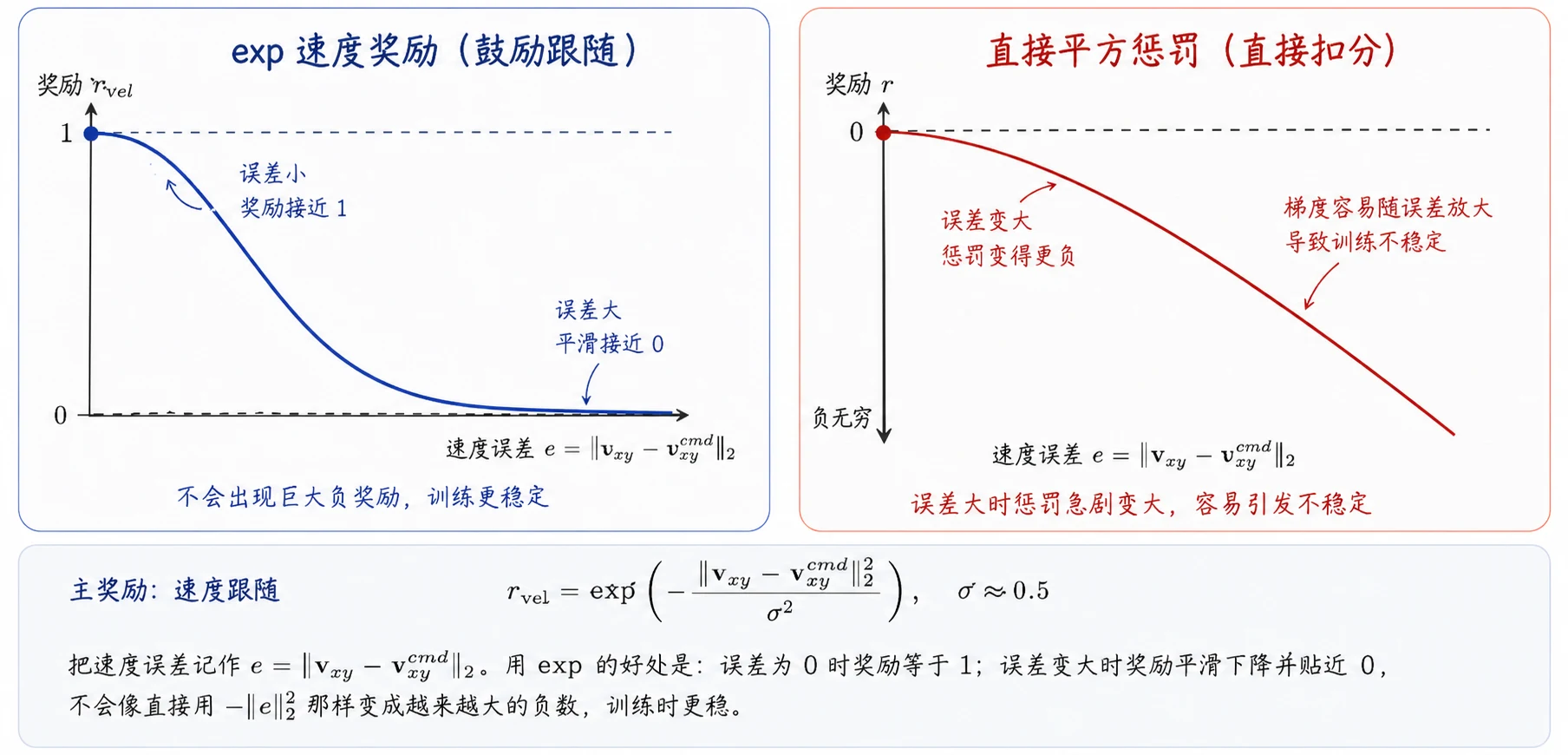
6.4 奖励设计
这一节是整章的核心,也是 CS123 Lab 5 slides 反复强调的一句话:只奖励"跟随速度命令"是远远不够的。直接训出来的策略可能只是让机身前向速度接近命令里的
业内通用的做法是把奖励拆成一个主奖励 + 四类辅助奖励:
主奖励:速度跟随
把速度误差记作 exp 的好处是:误差为 0 时奖励等于 1;误差变大时奖励平滑下降并贴近 0,不会像直接用
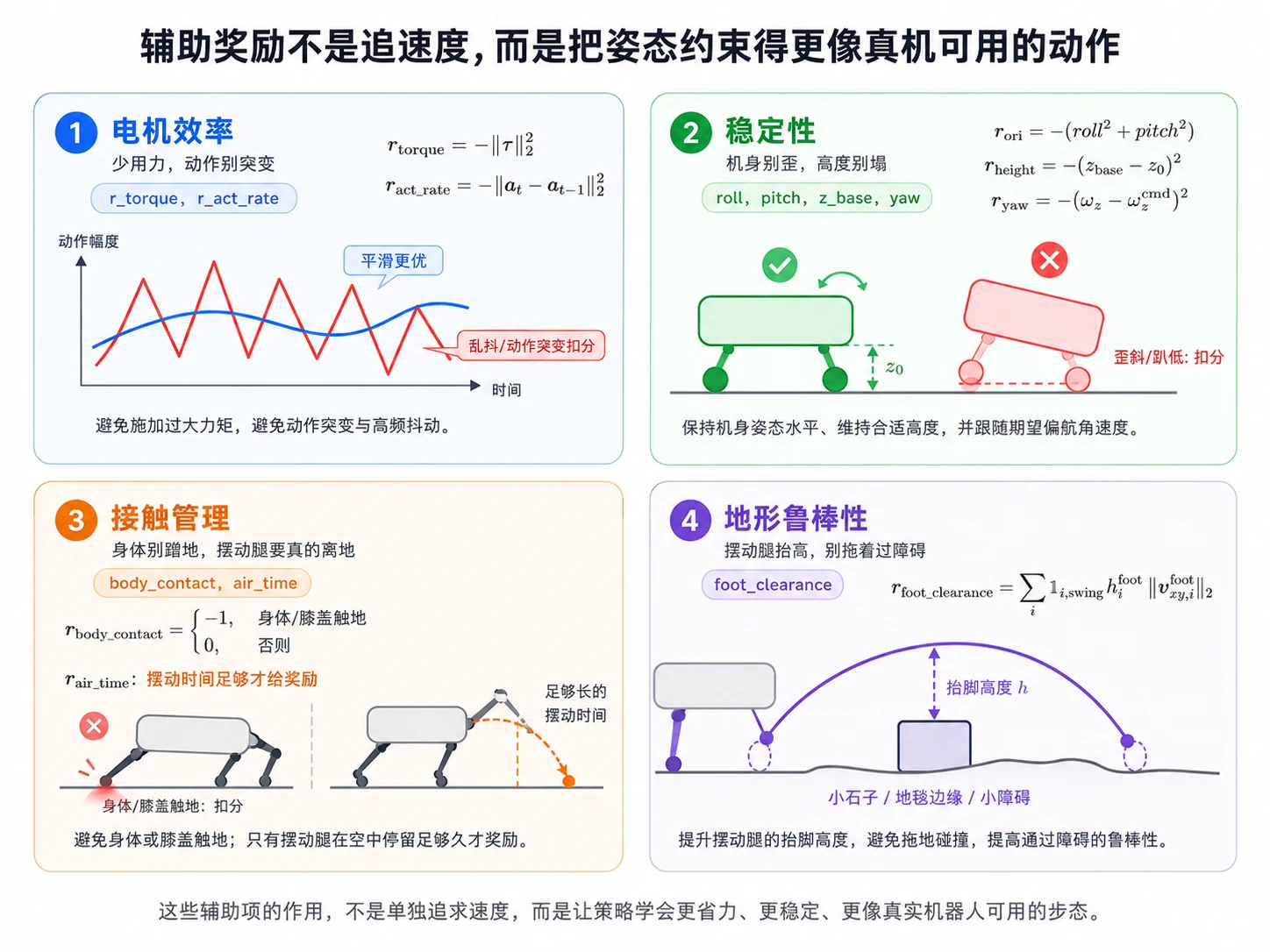
辅助:电机效率
第一项惩罚电机力矩过大,第二项惩罚相邻两步动作变化太猛。它们合起来就是把"少用力、少乱抖"写进奖励里。r_act_rate 是出现优雅步态的关键——没有它,§6.7 那个暴走策略永远收敛不到 §6.8 的 trot。
辅助:稳定性
这组三项约束机身姿态:身体别左右歪、别趴太低,转向速度也要跟随命令。没有这些项,策略可能靠"摔着往前蹭"拿到速度奖励。
辅助:接触管理
身体或膝盖碰地直接扣分;脚重新落地时,如果这条腿刚才有足够长的摆动时间,就给一点奖励。这样能鼓励"抬腿走",而不是四只脚贴着地面乱刮。
辅助:地形鲁棒性
只有摆动腿在水平移动时,足端离地高度才会贡献奖励。这样可以鼓励脚从小石子、地毯边缘这类障碍上方跨过去,而不是在地面上拖过去。
写成一份配置
完整的奖励表把上面四类辅助 + 主奖励统一展开,加上"原地静止"和"早期跌倒"两项,一共 18 项:
REWARD_WEIGHTS = {
# 跟随主奖励 (term ∈ [0, 1],权重正)
"tracking_lin_vel": 1.5,
"tracking_ang_vel": 0.8,
"tracking_orientation": 1.0,
# 机身稳定性 (term ≥ 0,权重负 → 惩罚)
"lin_vel_z": -2.0,
"ang_vel_xy": -0.05,
"orientation": -5.0,
# 能耗 / 平滑度
"torques": -2e-4,
"joint_acceleration": -1e-6,
"mechanical_work": 0.0, # 备用,默认关闭
"action_rate": -0.01,
# 步态形状
"feet_air_time": 0.2,
"stand_still": -0.5,
"stand_still_joint_velocity": -0.1,
"abduction_angle": -0.1,
# 安全 / 接触
"termination": -100.0, # 在 step 500 前跌倒一次性扣 100
"foot_slip": -0.1,
"knee_collision": -1.0,
"body_collision": -1.0,
}
符号约定:penalty 项(如
torques = Σ τ²)的函数返回正幅值,权重写负数才能起惩罚作用;tracking 项(如tracking_lin_vel = exp(-error²/σ²))的函数返回 [0, 1],权重写正数。把符号弄反等于"奖励翻车"——训练曲线看起来一路涨,行为反而越来越糟。
最终一步的总奖励:
reward = clip(Σ scale[k] × term[k], 0, 10000) × dt。乘dt = 0.02之后单步奖励量级在 0–3,episode(1000 步)总奖励量级在 0–3000。clip 到 0 是为了避免 reset 那一瞬负 reward 把 value loss 拉飞。
调参顺序:实操上别一次塞 18 项。先把
tracking_lin_vel + tracking_ang_vel + tracking_orientation + termination四项训出来——这是"能走 + 不摔倒"的最小集;然后加torques + action_rate + orientation看步态是否变规整(§6.8 实验 2);最后加feet_air_time + stand_still + abduction_angle收尾细节。一次只加一类,否则训练曲线变了也不知道是哪一项的功劳。
6.5 域随机化
策略只在"理想 Pupper"上训练,到真机上必崩——质量误差 5%、地板摩擦 0.6 而不是 0.8、电池电压掉了 10%,这些都会让策略找不到熟悉的状态分布。域随机化(DR) 就是在仿真里把这些参数随机抖一抖,强迫策略对它们不敏感:
def randomize(model):
# 1. 质量在 ±20% 范围抖
for i in range(model.nbody):
model.body_mass[i] *= np.random.uniform(0.8, 1.2)
# 2. 地板摩擦 0.5 ~ 1.2
floor_id = mujoco.mj_name2id(model, mujoco.mjtObj.mjOBJ_GEOM, 'floor')
model.geom_friction[floor_id, 0] = np.random.uniform(0.5, 1.2)
# 3. 初始关节角 ±0.1 rad 抖动 (在 reset 里)
# 4. 每 1~3 秒给 base 一个随机外力 (在 step 里)
DR 加上之后训练会变慢 30%~50%,但 sim2real 几乎是必须的代价。lab_6_rl_pupper/envs/pupper_env.py 默认开启了一组轻量 DR:随机初始位姿(位置 ±2 m、yaw 任意)、2% 概率的 base velocity kick、IMU 与电机角观测噪声、动作 latency 分布。质量 / 摩擦 / KP·KD 这一类"模型层 DR"留给读者 stretch。
6.6 PPO 训练脚本
新手友好的路径是 stable-baselines3。Lab 6 里训练入口是 lab_6_rl_pupper/train_ppo.py,实际调用 starter.train_ppo():
from pathlib import Path
from stable_baselines3 import PPO
from stable_baselines3.common.callbacks import CheckpointCallback
from stable_baselines3.common.vec_env import SubprocVecEnv
LAB_DIR = Path(__file__).resolve().parent
PORTFOLIO_DIR = LAB_DIR / "portfolio"
TB_DIR = LAB_DIR / "tb"
def train_ppo(seed=0, total_timesteps=150_000_000, n_envs=16):
def make_env(rank):
def _thunk():
env = PupperEnv()
env.reset(seed=seed + rank)
return env
return _thunk
vec_env = SubprocVecEnv([make_env(i) for i in range(n_envs)])
checkpoint_cb = CheckpointCallback(
save_freq=max(5_000_000 // n_envs, 1),
save_path=str(PORTFOLIO_DIR),
name_prefix="pupper_ppo",
)
model = PPO(
"MlpPolicy", vec_env,
n_steps=2048, batch_size=256, n_epochs=4,
learning_rate=3e-4, gamma=0.97, gae_lambda=0.95,
clip_range=0.2, ent_coef=0.01,
tensorboard_log=str(TB_DIR), verbose=1,
seed=seed,
)
model.learn(total_timesteps=total_timesteps, callback=checkpoint_cb)
final_path = PORTFOLIO_DIR / "pupper_ppo.zip"
model.save(str(final_path))
vec_env.close()
return final_path
CPU 上 16 路并行约 5-7k env-steps/sec。150M env-step 大约 8 小时走完;先跑 2-5M 步就能看到 ep_rew_mean 和 ep_len_mean 开始爬升,确认配方学得动。
关于步数预算:8192 个并行 env 在 ~149M 步达到峰值,是 GPU 路径的事实。CPU 16-env 同 env-step 数下数据多样性少一个量级,梯度更新更频繁但每次方差更大——两者不等价。经验上 16-env PPO 通常要 2-5× 的 env-steps 才能匹敌 8k-env PPO 的最终性能。所以 150M 是 CPU 起点而不是终点;训完看
ep_len_mean是否仍在涨,再决定续训多少。
几个超参的取舍:gamma=0.97 比经典的 0.99 短视一些,配合 episode_length=1000 让 value head 不必估超过 30 秒的未来;n_epochs=4 + batch_size=256 是 PPO on-policy 的稳健点(每个 rollout 重用 4 次、最小化 KL drift);ent_coef=0.01 比"标准"略大,因为命令分布宽(vx ±0.75、wz ±2.0)需要更长时间的探索。
想再快 10–100 倍 就要换到 GPU 版的 MJX(JAX 版 MuJoCo),CS123 Lab 5 官方就是这条路。MJX 把 4096 个并行 env 跑在一张显卡上,训练时间可以从小时压到分钟级。代价是 JAX 学习曲线 + 没有 SB3 那么多现成轮子,第一次训练建议先用上面的 SB3 路线把整条管线跑通,再切到 MJX 加速。
训练有没有跑偏,先看 TensorBoard 里的这三条:
rollout/ep_rew_mean:总奖励,应当稳步上升;下跌就是奖励项打架。train/clip_fraction:裁剪比例,长期 < 0.3 算稳;> 0.5 说明 lr 偏大。train/explained_variance:value head 学得好不好,> 0.7 算不错。
6.7 速度奖励实验
只保留跟随类奖励 + 跌倒惩罚,其它项置 0:
REWARD_WEIGHTS = {
'tracking_lin_vel': 1.5,
'tracking_ang_vel': 0.8,
'tracking_orientation': 1.0,
'termination': -100.0,
}
训 5 分钟(约 300k 步)后看视频:
- 前向速度大概率能拉到 0.6 m/s 以上,比 §5 手写 trot 还快;
- 但样子很难看:四条腿不分相位地乱踢,base 上下蹦得像在 pogo stick 上。
- 力矩曲线一路顶到 ctrlrange 上限——这是真机的电机杀手。
这条策略的存在价值只有一个:给 §6.8 做对照组。它说明"只跟随速度 + 不摔倒"不够。
6.8 能量惩罚实验
在实验 1 基础上加上能耗与平滑度的三项:
REWARD_WEIGHTS = {
'tracking_lin_vel': 1.5,
'tracking_ang_vel': 0.8,
'tracking_orientation': 1.0,
'termination': -100.0,
'torques': -2e-4,
'action_rate': -0.01,
'orientation': -5.0,
}
同样训 5 分钟,对照看:
- 视觉上自动出现规整的对角步态——RL 自己"发现"了 trot;
- 速度可能从 0.8 降到 0.5 m/s,但能耗(
mean(τ²))下降 60% 以上; - 训练曲线在前 50k 步上升较慢(先要学会"少抖"),之后追上实验 1。
把两条策略并排录视频做对比,就是 CS123 Lab 5 slides 里那一句"基础奖励不够"最直观的注脚。
进一步想做"接触感强、能跨台阶"的步态,把 §6.4 里稳定性 + 接触管理 + 地形鲁棒性三组奖励一组组加进去重训,每加一组录 30 秒视频归档——这就是动手任务里"对比手写 trot vs RL 步态"的素材库。
6.9 评估与录屏
Lab 6 默认不用 viewer 手录,而是用 offscreen renderer 一次性生成 GIF 和曲线。eval_commands.py 的主流程是:
from shared.viz import gif_utils
from starter import (
GIF_FPS, GIF_WIDTH, PORTFOLIO_DIR,
render_command_demo, render_comparison_gif,
render_velocity_tracking, save_reward_curve, save_velocity_tracking,
)
frames = render_command_demo()
gif_utils.write_gif(
frames,
PORTFOLIO_DIR / "rl_pupper_commands.gif",
fps=GIF_FPS,
max_frames=144,
width=GIF_WIDTH,
palette_colors=12,
)
render_comparison_gif() # ours vs 上游 test_policy.json
save_velocity_tracking(render_velocity_tracking())
save_reward_curve()
基础评估先看这几项:
- 命令序列 GIF:stand → forward 0.5 m/s → turn left → backward → stand,输出
portfolio/rl_pupper_commands.gif。 - 上游策略对比:同一命令序列下,左边是自己的 SB3 PPO,右边是
shared/rl/policies/test_policy.json(上游用 GPU 训了数十亿步的 RTNeural 策略)。render_upstream_demo用一份独立的 MuJoCo sim 直接喂 RTNeural policy,不经过PupperEnv,所以不受我们这边 obs 设计变更影响。输出portfolio/comparison.gif。 - 直线速度跟踪:在
m/s 三档命令下各跑 8 秒,输出 portfolio/velocity_tracking.png。 - 训练曲线:从 TensorBoard 日志导出
portfolio/reward_curve.png。
能耗对比和 5 N·s 抗扰动可以继续做,但它们属于 Stretch;本次 Lab 6 的主线先保证 checkpoint、GIF 和速度曲线闭环。下一章我们会在 RL 策略上面再架一层 LLM——让 Pupper 听懂自然语言指令。
动手任务
§6.6 跑通了 PPO 训练、§6.7–§6.8 看到了"暴走"和"优雅"两种策略的差异。本章动手任务对应 codes/practices/quadruped/cs123/exercises/lab_6_rl_pupper/:补齐环境 TODO,跑完一次端到端 PPO 训练,输出能跟随变速命令的 checkpoint。
要做的四件事:
- 补
PupperEnv(gymnasium.Env)的 3 个 TODO:_compute_reward()做 18 项加权和(注意 penalty 项权重写负数);_get_obs()拼 36 维单步观测并 stack 15 帧成 540 维;_sample_command()采样vx ∈ [-0.75, 0.75]/vy ∈ [-0.5, 0.5]/wz ∈ [-2.0, 2.0]。 - 跑
uv run python lab_6_rl_pupper/tests.py:确认observation_space.shape == (540,)、action_space.shape == (12,)、reset()观测 finite、18 项r_*符号正确。 - 跑
uv run python lab_6_rl_pupper/train_ppo.py:16 路SubprocVecEnv,默认 150M 步约 8 小时;想先看是否学得动可以--total-steps 5_000_000跑十几分钟看eval/avg_episode_length是否开始爬。 - 首次对比前运行
bash shared/rl/fetch_policies.sh拉取上游test_policy.json(~38 MB,已.gitignore,仅需一次),再跑uv run python lab_6_rl_pupper/eval_commands.py生成rl_pupper_commands.gif、comparison.gif(ours vs 上游)、velocity_tracking.png、reward_curve.png。
完整 starter / 测试 / 交付清单见 exercises/lab_6_rl_pupper/。
参考资料
- CS123 Lab 5: How to Train Your Dog
- Stable-Baselines3 文档
- Margolis et al., "Rapid Locomotion via Reinforcement Learning"