两轮足机器人课程预告
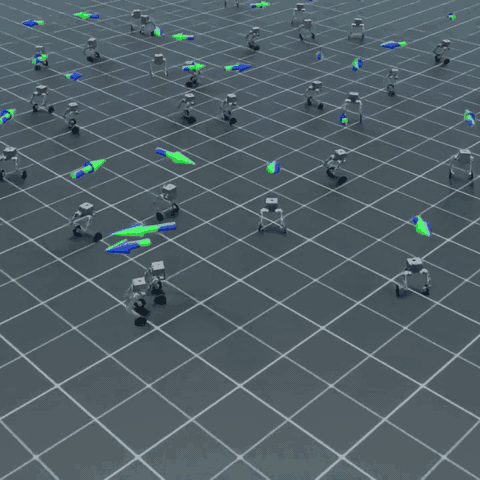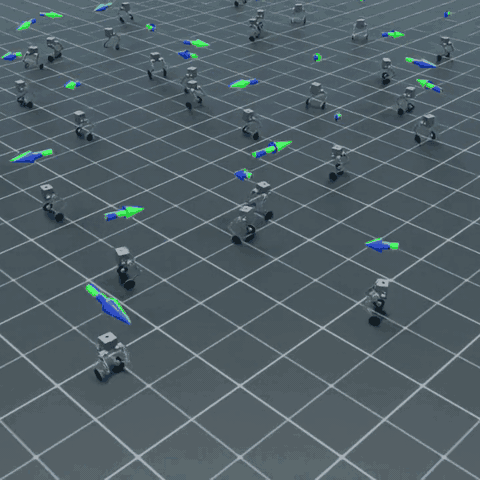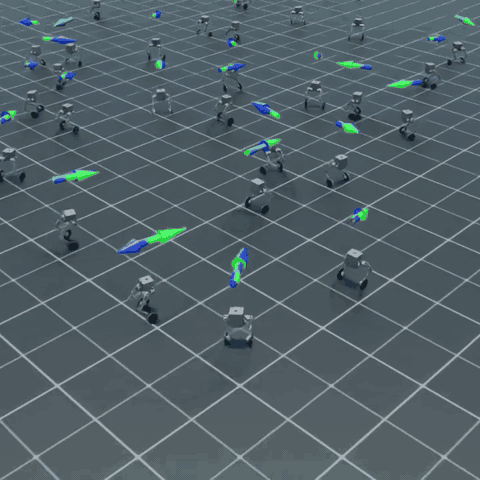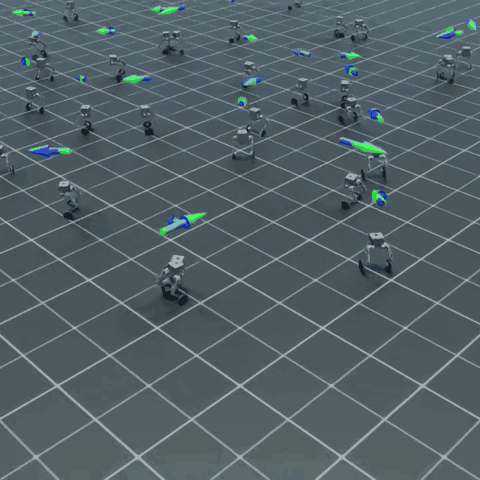
上面是多个 Flamingo 在 Isaac Lab 中同时接受随机速度指令的并行仿真画面。每只机器人独立采样自己的目标速度与转向角速度,靠两个轮子站立、移动、转弯——这就是这门课最终能产出的东西。
本课程基于开源项目 jaykorea/Isaac-RL-Two-wheel-Legged-Bot(作者 @jaykorea,MIT 协议)改编。原仓库是研究 / 训练代码集合;本课程把它重新组织成面向自学和求职的章节化教程,补齐叙事、对照表、约束式 RL 拆解与跨仿真验证流程。
简介
围绕 Flamingo 这台两轮足机器人(两条腿 + 两个轮子,典型 8 自由度),从零搭起一条完整的强化学习训练–部署链路:
- 在 Isaac Lab + rsl_rl 里训练一个能跟踪速度指令、抗扰、保持平衡的策略
- 用 PPO 与约束式强化学习 CaT(Constraints as Termination)做对比
- 把训练好的策略导出成 ONNX,加载到 MuJoCo 里零样本运行(Sim2Sim)
- 在 MuJoCo 端做鲁棒性测试:横向推力、初始姿态扰动、不同地面摩擦
整条链路不依赖任何实体硬件,单卡 NVIDIA GPU(RTX 3060 及以上)就能跑通。
为什么是两轮足
在四足、人形、机械臂这些主流形态之外,两轮足是一个性价比极高的中间样本:
- 欠驱动现象都会出现:轮式倒立摆、腿部摆动、单腿支撑、地面接触切换,CS123 静态四足覆盖不到的物理行为这里都有。
- DoF 少、显存友好:典型 8 自由度,训练时间和资源预算比 humanoid 友好得多。
- 奖励工程难度真实:平衡 + 速度跟踪 + 不摔倒,是把 reward shaping、domain randomization、约束式 RL 讲透的最小完整样本。
- 产品热度足:近几年国内外都有商用两轮足产品落地(Unitree B2-W、Deep Robotics Lynx、Limx TRON1 等),招聘市场对相关栈的需求清晰。
与四足课程的区别
| 维度 | CS123 四足 | 本课程 两轮足 Flamingo |
|---|---|---|
| 本体 | Stanford Pupper(4 腿静稳) | Flamingo(2 腿 + 2 轮,欠驱动) |
| 仿真 | MuJoCo only | Isaac Lab → MuJoCo(Sim2Sim) |
| RL 框架 | stable-baselines3 | rsl_rl / co_rl |
| 算法 | PPO | PPO 与 CaT 约束式 RL 对比 |
| 产出 | 单仿真内 RL trot + LLM 控制 | 跨仿真零样本 + 鲁棒性测试 |
| 主要难点 | 步态生成、模仿学习入门 | 平衡控制、域随机化、跨仿真迁移 |
本课程不重复 CS123 四足课程已经讲过的 PD、正逆解、MuJoCo 基础。前置概念请回 基础教程。
你将做出来的东西
- 一台在 Isaac Lab 仿真里能听从速度指令稳定行驶、被横向推动后能自行恢复的 Flamingo
- 一份导出的 ONNX 策略文件,在 MuJoCo 中无需重训即可加载播放
- 一组 PPO vs CaT 的训练曲线 + 行为对比 GIF
- 一份有清晰技术决策的项目说明
适合谁
- 已经做完 CS123 或等价四足项目,想要第二个更工业向的项目历练的同学
- 投递 legged locomotion 方向岗位,需要 Isaac Lab + rsl_rl 经验的求职者
- 想了解头部具身公司 locomotion 团队当前主流技术栈的工程师
不适合:完全没碰过强化学习、PD 控制、MuJoCo 的同学。请先过一遍基础教程与 CS123 四足课程。
课程章节(规划中)
- 章 1:本体与环境——Flamingo 8 自由度结构、Isaac Lab 工程基础、URDF/USD 资产准备
- 章 2:奖励设计与训练——速度跟踪奖励、姿态稳定项、PPO 训练流程
- 章 3:约束式 RL(CaT)——硬约束与软奖励的取舍、与 PPO 的训练曲线对比
- 章 4:策略导出与 Sim2Sim——ONNX 导出、MuJoCo 端最小推理脚本、零样本播放
- 章 5:鲁棒性与扰动测试——横向推力、初始扰动、地面摩擦随机化下的恢复行为
- 章 6:项目交付——产出物组织、技术决策梳理
具体章节顺序与命名以正式开课为准。
前置环境
| 组件 | 版本 |
|---|---|
| Isaac Sim | 4.5 |
| Isaac Lab | 2.0 或 2.3 |
| Python | 3.10 / 3.11 |
| GPU | NVIDIA RTX 3060 及以上(单卡) |
| MuJoCo | 3.x |
状态
🚧 课程正在开发与验证中。
完整章节预计随后续发布陆续上线,可以先关注本仓库等待更新。
致谢
- jaykorea:Isaac-RL-Two-wheel-Legged-Bot 仓库作者。
- Constraints as Termination (CaT) 作者。
- Datawhale 开源社区。