初级四:为原型注入 AI 能力
章节导读
1. API 基础概念
前面提到,我们的目标是「把 AI 能力接进来」,让原型不再是静态演示,而是能调用真实 AI 服务的工具。要实现这一点,关键就在于理解并使用 API(应用程序编程接口)。
API 是计算机领域的一个重要抽象概念,我们可以简单理解为:你按对方要求的格式"发一个问题",对方就按同样的格式"回一个结果"。
- 你发出去的内容:通常包括"密钥(API Key)"和"你要生成什么"
- 对方回给你的内容:成功就给结果;失败会告诉你原因(比如"密钥不对""余额不足""参数写错")
具体来说,你需要掌握以下核心要素:
- API Key:你的"通行证",也是"钱包钥匙"。别人拿到它,就可以替你调用接口并产生费用。
- Endpoint(接口路径):API 请求的具体路径,告诉服务器你要访问哪个功能。完整的请求地址通常由"基础 URL + Endpoint路径"构成。例如:
- 文本生成:基础URL (
https://api.service.com) + Endpoint (/v1/chat/completions) = 完整URLhttps://api.service.com/v1/chat/completions - 图像生成:基础URL (
https://api.service.com) + Endpoint (/v1/images/generations) = 完整URLhttps://api.service.com/v1/images/generations
- 文本生成:基础URL (
- 调用/请求:向 AI 服务发送任务并获取结果的过程
- 请求内容:你发给AI的具体内容,比如你想让AI写的文章主题、生成的图片描述等。
- 响应结果:AI处理完后返回给你的内容,比如生成的文章、图片等。
- 错误处理:当出现问题时(如API Key错误、请求太频繁等),知道如何排查解决。
ℹ️ 什么是 API
对于 API 的更深入的解释,请看附录:API 入门。
🔐 API 安全注意事项
API Key 是你请求 AI 服务的「通行证」,它是一串密码字符串,用于身份验证和计费。
由于 API Key 直接关联账户和费用,务必注意:
- 绝对不要分享到群聊、截图上传网络或发布在公开论坛
- 不要硬编码到代码中并提交到 Git 仓库(尤其是公开仓库)
- 如怀疑 Key 已泄露,立即更换新 Key
我们会在下面的内容中直接把 API KEY 粘贴到 AI IDE 中进行操作,在正规的项目里不要这么做!!,由于我们是练习可以这么做。(等你更加熟练后,你能够让 AI 生成一个配置文件,你只需要把 API KEY 放入配置文件即可)
2. 接入文本生成 API:DeepSeek
虽然 API 涉及这些技术概念,但在原型开发阶段,实际操作可以非常简单高效。核心思路就是:
找到官方示例、拿到 API Key、让 AI IDE 帮你接到按钮上。
掌握了这些概念后,你会发现无论是接入文字模型还是图像模型,其本质流程都是一样的:当用户点击按钮时,前端整理输入并发起请求;接口返回结果后,再把结果展示到页面上。接下来,我们就通过实际操作来验证这一点。
在 1.2 动手做出原型 里,你已经做出了一个可交互的原型。接下来我们要做的,是把原型里“看起来像 AI 的功能”变成真正可用的能力:当用户点击按钮时,原型会向外部的 AI 服务发出请求,并把返回的文字展示出来。
ℹ️ 原理延伸
如果你想了解更多原理相关的内容,请查看附录:大语言模型(LLM)入门。
了解更多:DeepSeek 是什么?
杭州深度求索人工智能基础技术研究有限公司(Hangzhou DeepSeek Artificial Intelligence Basic Technology Research Co., Ltd.),以 DeepSeek 为商号,是一家开发大语言模型(LLMs)的中国人工智能(AI)公司。DeepSeek 总部位于浙江杭州,由中国对冲基金幻方量化(High-Flyer)拥有并资助。DeepSeek 由幻方量化的联合创始人梁文锋于 2023 年 7 月创立,他也同时担任这两家公司的 CEO。该公司于 2025 年 1 月推出了同名聊天机器人及其 DeepSeek-R1 模型。
让我们看看 DeepSeek 在 GPQA 基准排名中与其他顶级模型的表现对比。值得注意的是,DeepSeek 是一个开源(每个人都可以从互联网下载模型)模型,而其他常见模型如 Grok、Google Gemini 和 ChatGPT 都是闭源的。正如我们所见,DeepSeek 已经很大程度上接近了第一梯队的模型。
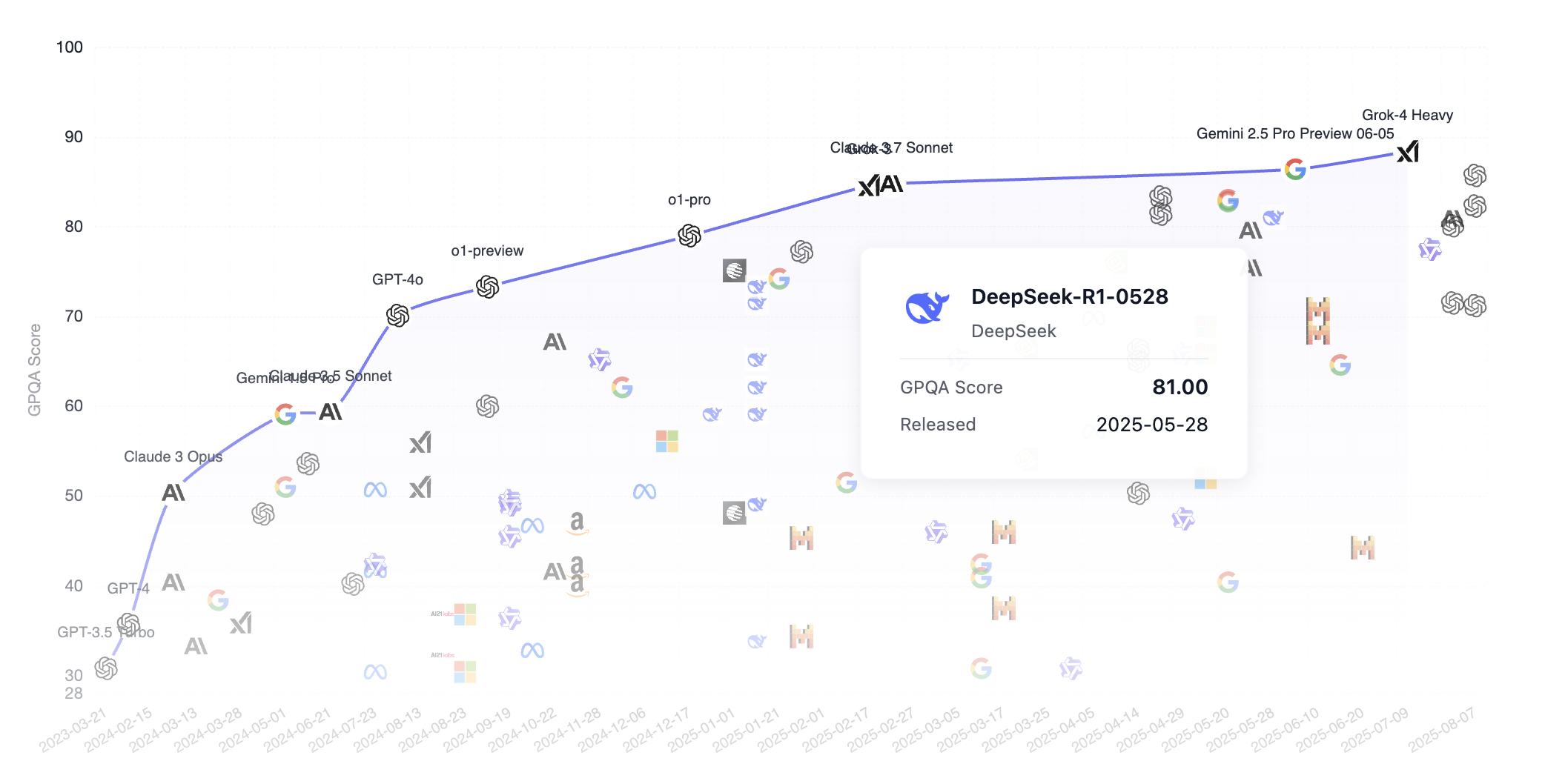
GPQA 是“研究生级 Google-Proof 问答基准”的缩写,这是一个用于科学问答任务的研究生级基准。以下是详细介绍。
GPQA 包含 448 个多项选择题,涵盖生物学、物理学和化学的子领域,如量子力学、有机化学、分子生物学等。这些问题由 61 位持有博士学位或正在攻读博士学位的专家编写,并经过了严格的验证过程。
跟着这 3 步走,就能实现大模型生成 API 的快速集成:
- 在 DeepSeek 平台创建一个 API Key
- 在 DeepSeek 文档中找到文本生成示例(通常有现成代码可直接复制)
- 打开 AI IDE,把 API Key + 官方示例粘贴进去,告诉 AI 要实现什么功能:
帮我接入这个大模型的 API ,支持这个应用的文案生成任务
接下来我们进行演示,你可以跟随操作走一遍全流程。首先注册 DeepSeek 账号并创建一个 API Key,并且充值少量费用进行验证。
点击“API KEYS”并在屏幕下方找到“create new API key”。你最终会得到一个像 sk-8573341c39fc44315aadc071c53rh7d2 这样的 API key。
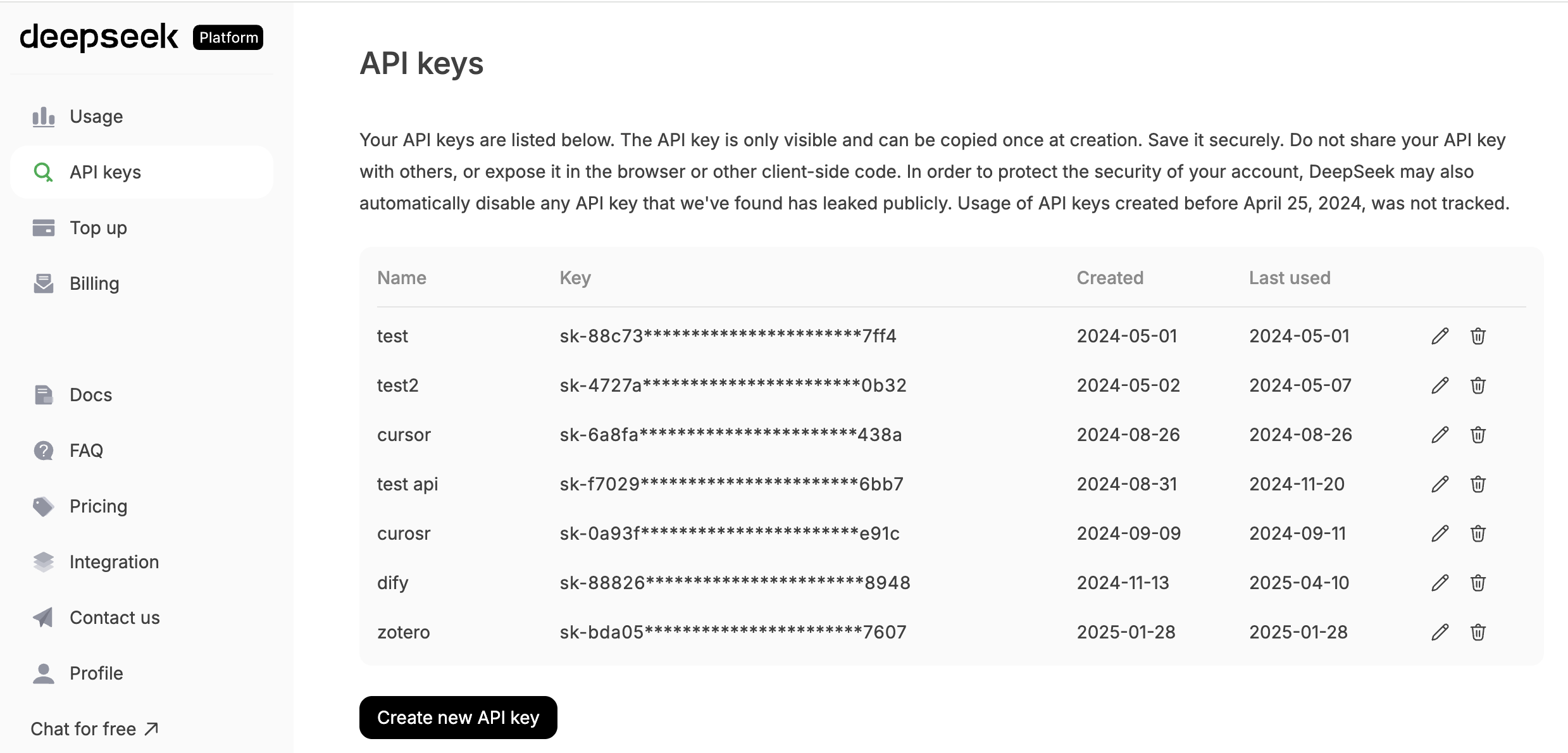
一旦你获得了密钥,你就拥有了调用模型的权限。
此时,你可以直接阅读 API 文档,它通常提供 curl 或 Python 的调用示例。
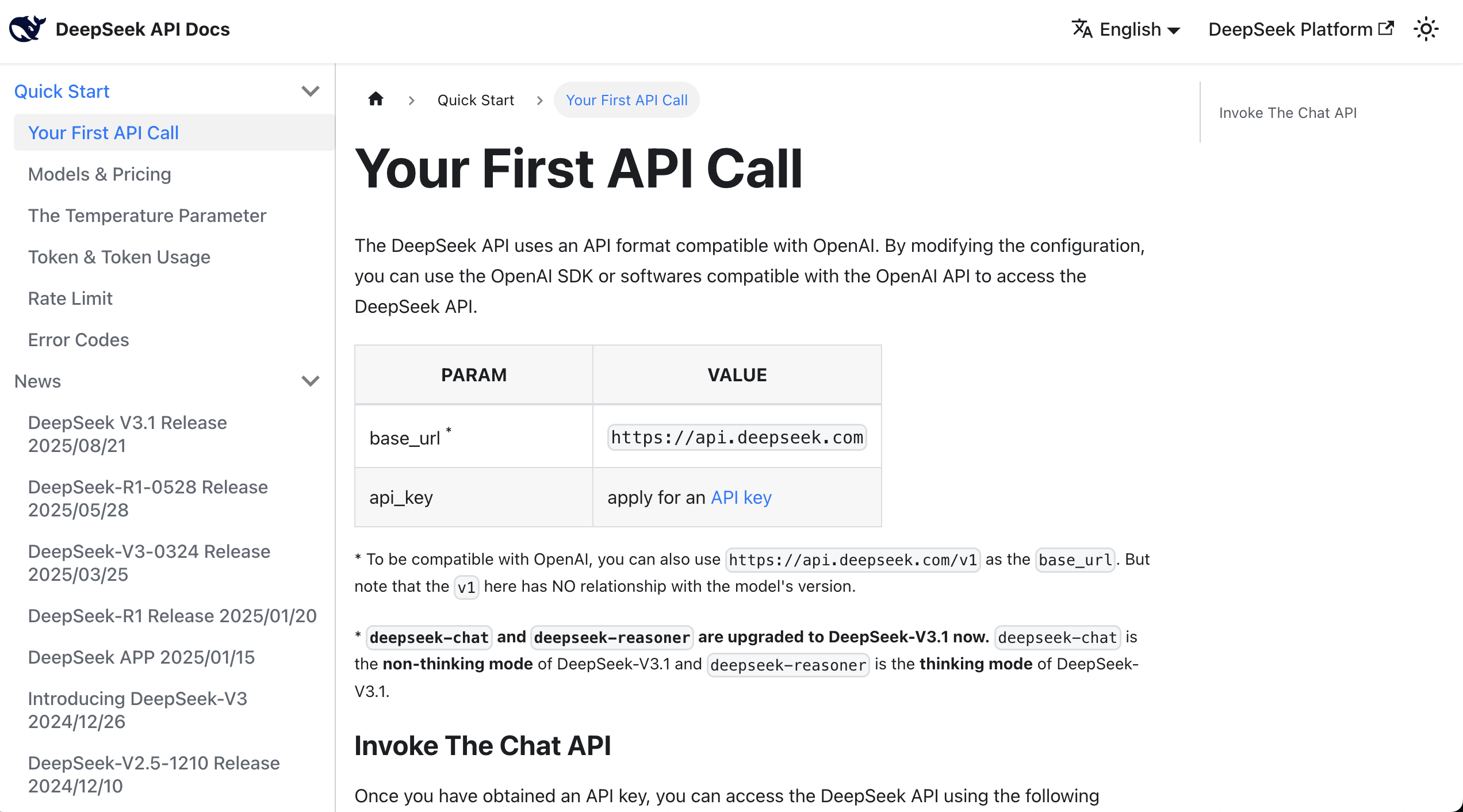
找到示例后,你可以将文档中的所有内容以及密钥复制到 AI IDE 的对话框中,要求它帮你集成大语言模型到之前已经开发的原型中。
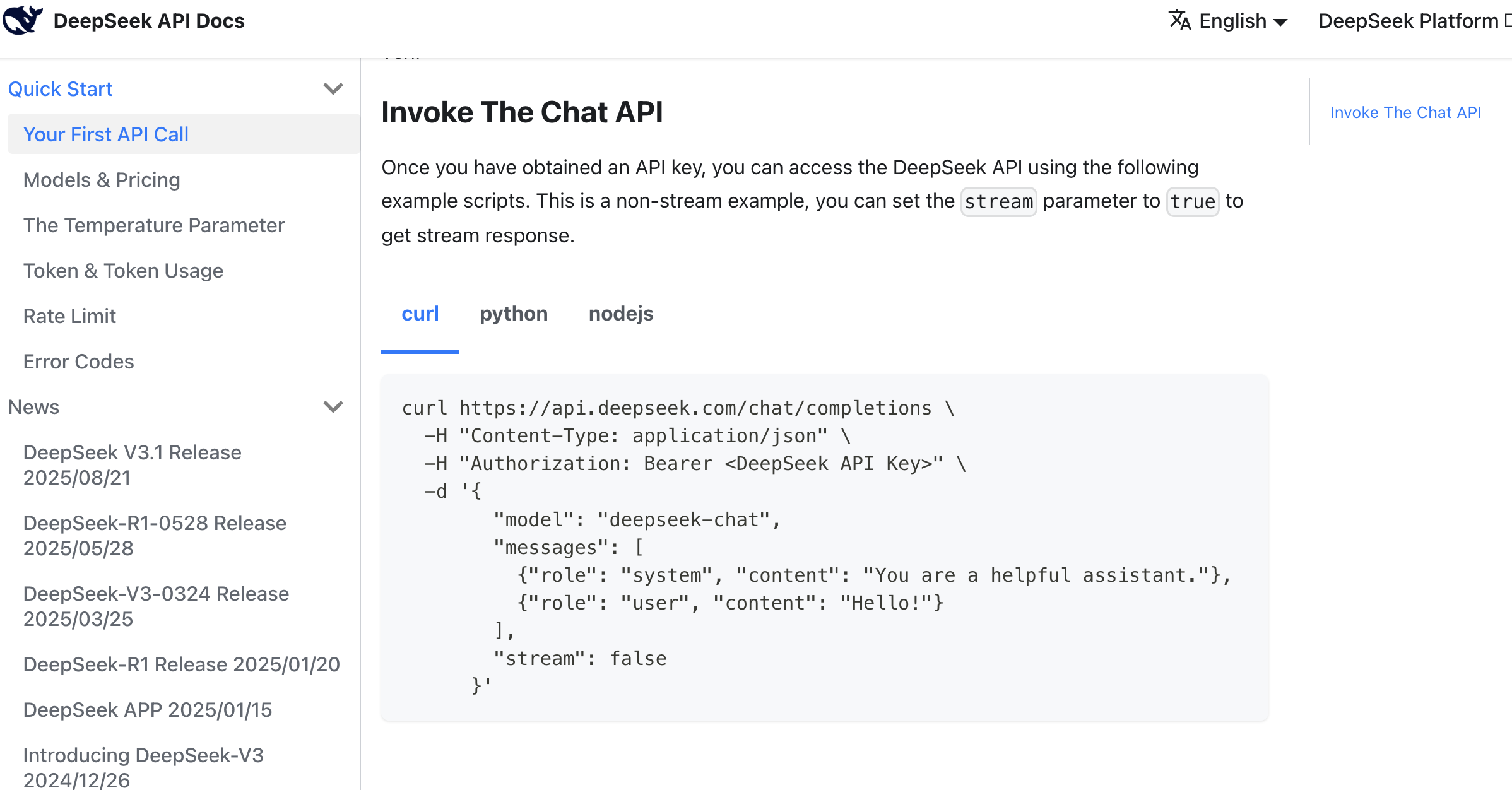
使用提示词参考如下:
参考这个调用方法,帮我支持文案生成功能,可以基于商品信息点击后生成对应抖音电商文案,多种风格。
以下参考资料:
api key:sk-8573341c39aefa1efe
api 请求参考:
curl \
-H "Content-Type: application/json" \
-H "Authorization: Bearer ${DEEPSEEK_API_KEY}" \
-d '{
"model": "deepseek-chat",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello!"}
],
"stream": false
}'经过一段时间的 AI 代码生成,我们很容易得到对应的文案生成按钮进行测试,如果你找不到入口,可以让 AI IDE 告诉你从什么页面可以点到该页面,如果实在找不到,可以让 AI IDE 直接基于你的想法重构改进,得到最后的文案生成结果。
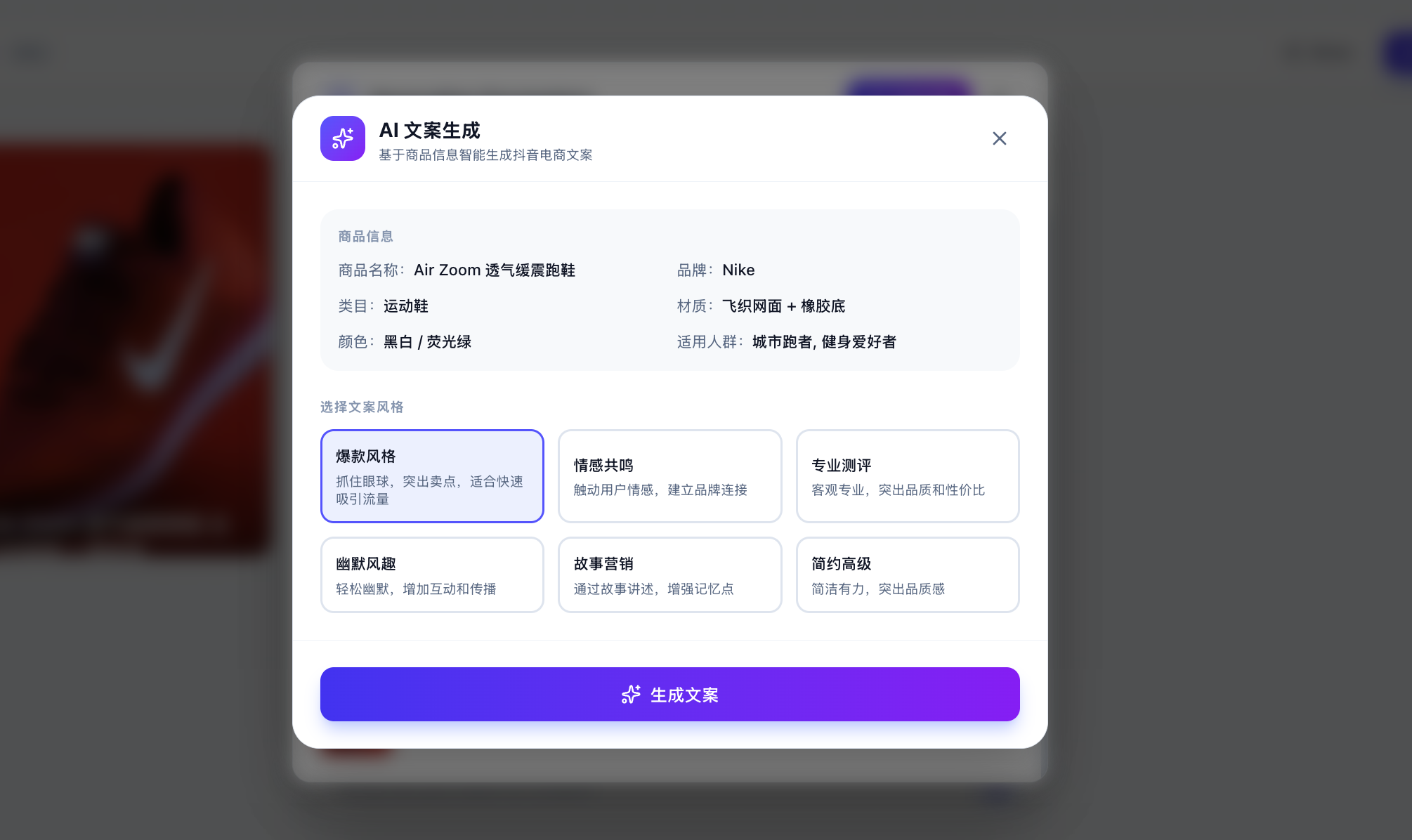
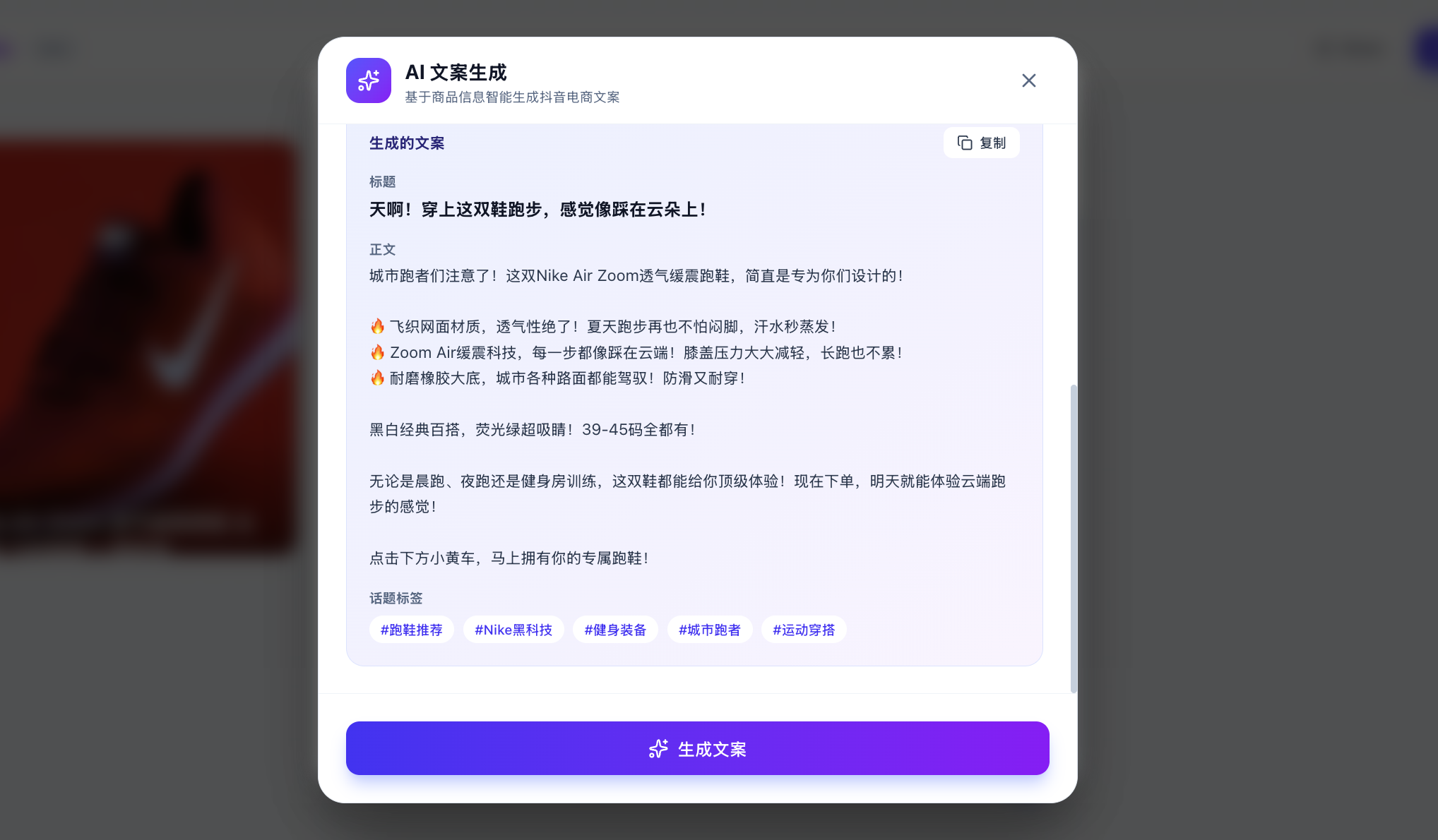
当然,此处你可能想问,我怎么知道真正调用了大模型而不只是内置了固定的回复?你可以输入自定义的文案,让大模型根据你及时指定的自定义分析,生成对应的文案。
如果发现每次不一样并且合乎逻辑,你可以放心认为此时已经正常调用 API 生成。你也可以在 API 使用管理平台查看是否成功调用(虽然可能需要等几分钟才能看到)。
更多文本生成模型选型
除了 DeepSeek 之外,你也可以尝试其他大语言模型。由于大多数模型都提供了 OpenAI 兼容接口,切换起来非常简单——只需要更换 API Key、基础 URL 和模型名称即可。
MiniMax 集成
了解更多:MiniMax 是什么?
MiniMax 是一家中国人工智能公司,致力于通用人工智能技术的研发。MiniMax 推出了自研的 MiniMax-M2.5 大语言模型系列,在多项基准测试中表现优异,具有极高的性价比。
MiniMax-M2.5 系列的主要特点:
- 超长上下文:支持 204,800 tokens 的上下文窗口,适合处理长文档、多轮对话
- 高性价比:输入 $0.3/M tokens,输出 $1.2/M tokens,价格极具竞争力
- OpenAI 兼容接口:可以直接使用 OpenAI SDK 调用,无需额外学习新的 API 格式
- 两个可用模型:
MiniMax-M2.5:旗舰模型,适合复杂任务MiniMax-M2.5-highspeed:高速版本,保持同样的性能但更快
接入方式与 DeepSeek 一致,只需要三步:
- 前往 MiniMax 开放平台 注册账号并创建 API Key
- 在 MiniMax 文档中找到调用示例
- 把 API Key + 示例粘贴到 AI IDE 中
由于 MiniMax 提供了 OpenAI 兼容接口,你可以直接复制下面的 curl 示例和你的 API Key,发给 AI IDE 进行集成:
curl https://api.minimax.io/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer ${MINIMAX_API_KEY}" \
-d '{
"model": "MiniMax-M2.5",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello!"}
],
"stream": false
}'✅ 提示
MiniMax 的 API 格式与 DeepSeek 几乎完全一致(都是 OpenAI 兼容格式),所以如果你已经成功接入了 DeepSeek,切换到 MiniMax 只需要修改三个地方:
- 基础 URL:改为
https://api.minimax.io/v1 - API Key:使用 MiniMax 的 API Key
- 模型名称:改为
MiniMax-M2.5或MiniMax-M2.5-highspeed
更多信息请参考 MiniMax OpenAI 兼容接口文档。
3. 接入图像转文字 API:Qwen3 VL
ℹ️ 原理延伸
如果你想了解更多原理相关的内容,请查看附录:视觉语言模型(VLM)入门。
了解更多:Qwen3 VL 是什么?
Qwen3 VL 是阿里云通义千问团队推出的多模态视觉语言模型系列中的最新版本。VL 代表「Vision-Language」,即视觉语言模型。它能够理解图像内容,并根据图像生成文字描述、回答关于图像的问题、提取图像信息等。


Qwen3 VL 的主要能力包括:
- 图像理解:能够识别图片中的物体、场景、人物、文字等内容
- 视觉问答:根据用户提问,准确回答关于图像的问题
- 图像描述:生成详细或简洁的图像文字描述
- 多图理解:支持同时处理多张图像,进行对比分析
- 文本提取:从图像中提取文字内容(OCR 能力)
为什么选择 Qwen3 VL?
相比上一代模型,Qwen3 VL 在图像理解准确性上有显著提升,支持更长、更复杂的图像分析任务。它在中文理解方面表现优异,API 调用成本相对较低,性价比较高。此外,它的上下文窗口更大,能处理更复杂的视觉推理任务。
典型应用场景:
- 电商:商品图片自动生成标题、描述、卖点
- 内容创作:根据素材图自动生成文案或配图建议
- 办公:图片内容提取、报表自动识别
- 教育:图片题目自动解析、知识点提取
在前面的部分我们说明了如何接入文字生成 API, 但对于前面的应用场景我们会发现一个问题,我们上传的是一张图片,如果只用大语言模型,它没办法很好的理解图片中的内容,生成的结果很可能会有差别。
我们希望有一个模型能够帮助我们把一个图片变成文字描述,这就需要用到视觉语言模型(VLM)。在案例中,我们将会使用视觉语言模型生成商品的卖点描述,提升用户体验。
为了方便,我们使用云平台 SiliconFlow 提供的 API 接口进行图生文 API 的接入。
了解更多:什么是 Siliconflow
硅基流动(SiliconFlow) 是国内知名的 AI 模型聚合平台,提供多种主流大语言模型和视觉语言模型的 API 接口服务。
平台特点:
- 多模型支持:集成多种主流 AI 模型,包括 DeepSeek、Qwen、Llama 系列等开源模型
- 技术优化:针对开源模型进行推理优化,提供低延迟、高并发的 API 服务
- 接口兼容:提供兼容 OpenAI 格式的 API 接口,便于现有应用集成
- 按需付费:支持按调用量计费的方式使用
SiliconFlow 在开源大模型的推理服务方面较为成熟,是使用国产开源 AI 模型的常见选择之一。
进入到 SiliconFlow 平台的首页,我们可以看到有很多模型可以选择,左上角找到筛选器,点击展开筛选器,选择视觉标签,我们能看到很多图片转文本模型,比如智谱 GLM-4.6V,或者是 Qwen3-VL。
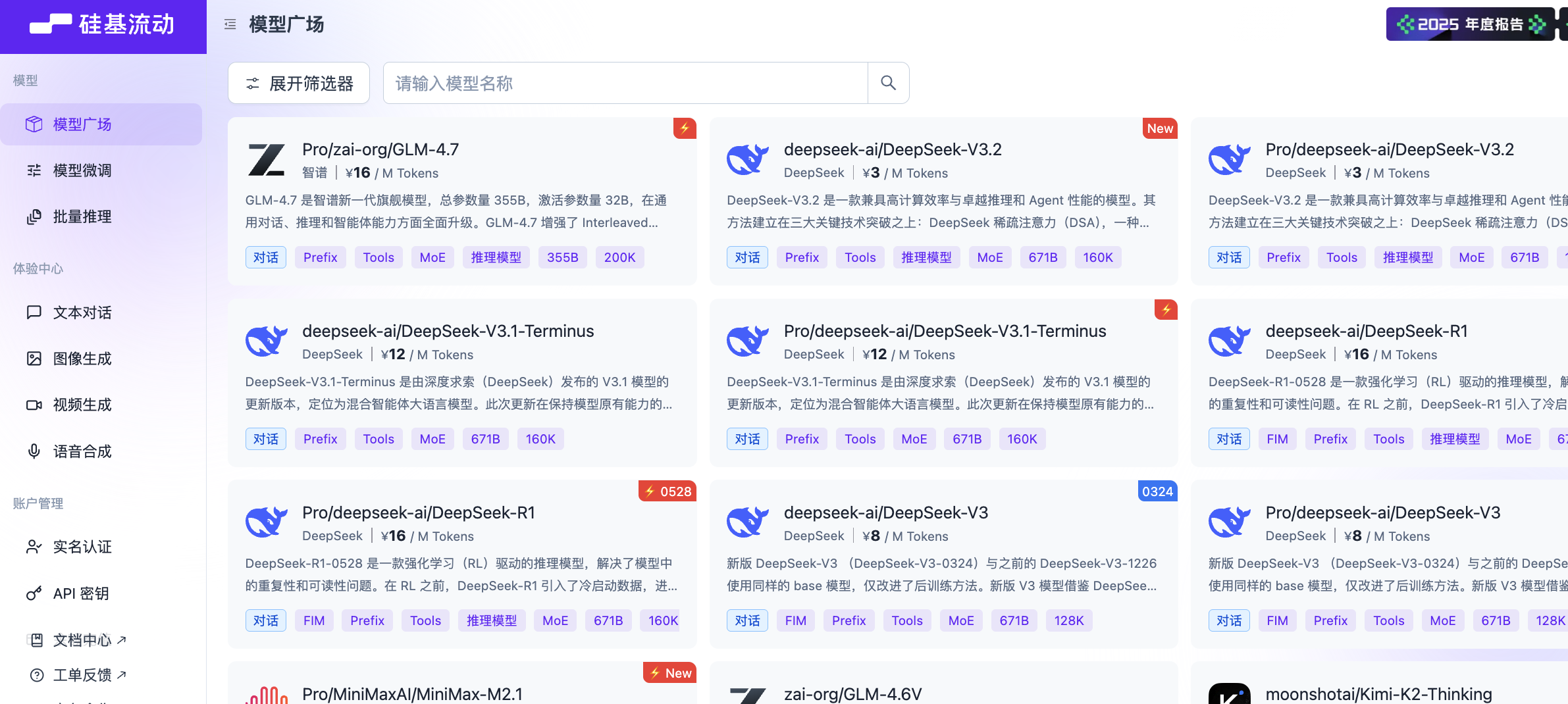
我们可以选择任意一个进行测试,这里以 Qwen/Qwen3-VL-8B-Instruct 为例。
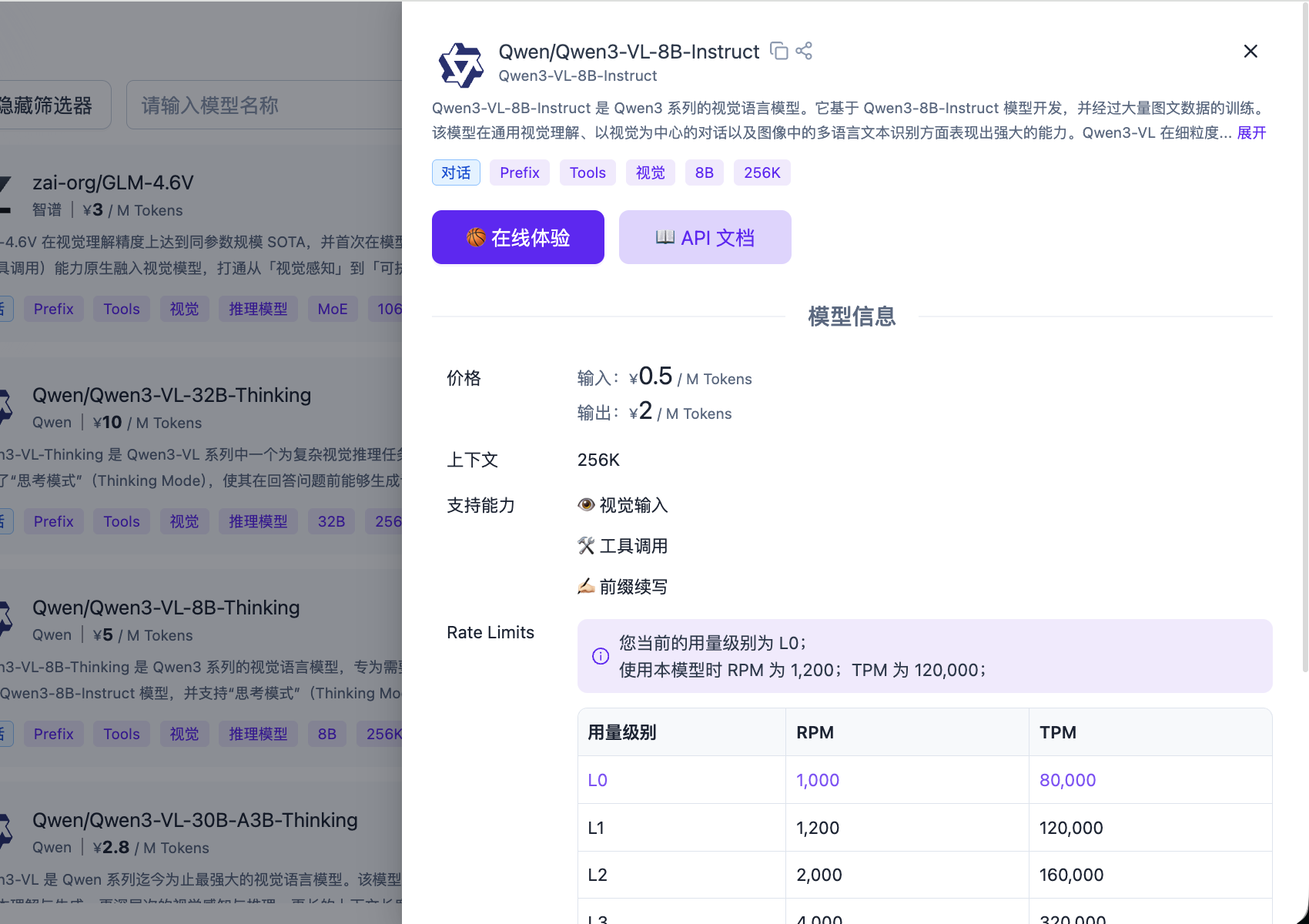
进入 SiliconFlow 平台,在 API 密钥中点击「新建 API 密钥」,创建一个新的 API Key。
你可以直接使用下面的代码作为参考代码,和生成的 API Key 一起,发送给 AI IDE ,进行功能集成。
图片转文字参考代码
from openai import OpenAI
from typing import Dict, Any, List
import base64
import os
SILICONFLOW_API_KEY: str = ""
SILICONFLOW_BASE_URL: str = "https://api.siliconflow.cn/v1/"
MODEL_NAME: str = "Qwen/Qwen3-VL-8B-Instruct"
def encode_image(image_path: str) -> str:
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
def get_vlm_completion(client: OpenAI, messages: List[Dict[str, Any]]) -> str:
response = client.chat.completions.create(
model=MODEL_NAME,
messages=messages,
max_tokens=512,
temperature=0.7,
top_p=0.7,
frequency_penalty=0.5,
stream=False,
n=1
)
return response.choices[0].message.content
def caption_image(image_path: str) -> str:
base64_image = encode_image(image_path)
messages = [
{
"role": "user",
"content": [
{
"type": "text",
"text": "Please describe this image in detail."
},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}"
}
}
]
}
]
client = OpenAI(
api_key=SILICONFLOW_API_KEY,
base_url=SILICONFLOW_BASE_URL
)
return get_vlm_completion(client, messages)
image_path = "images.jpg"
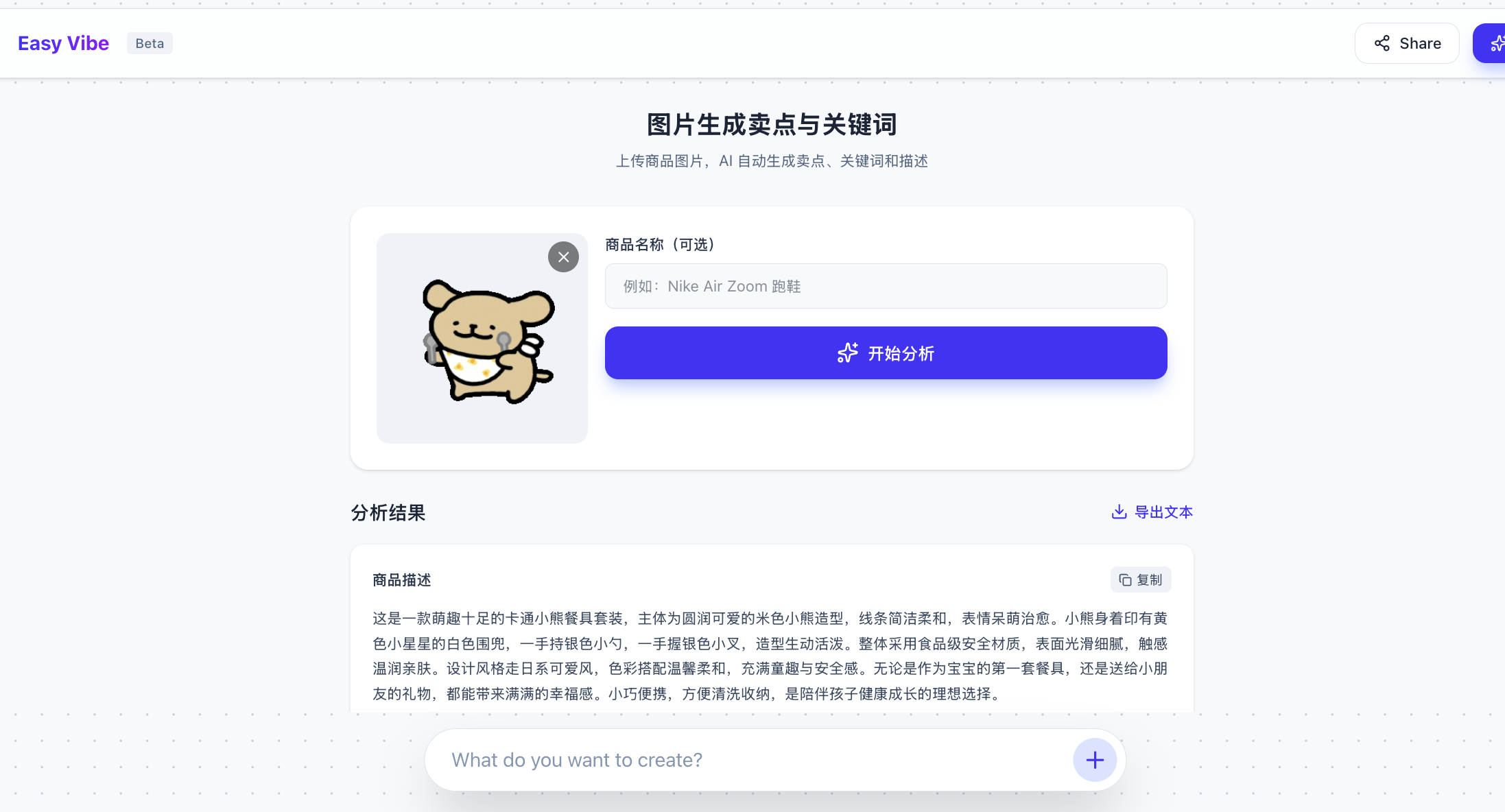
caption = caption_image(image_path)在这个场景中,我们直接尝试让 AI IDE 帮我们实现将上传的图片,自动生成电商卖点文本、关键词的功能,如下所示:
基于下面的图生文接口 API ,帮我们实现将上传的图片,自动生成电商卖点文本、关键词的功能
<此处省略代码,你需要自行粘贴密钥和参考代码>最后得到生成结果: 
4. 接入图像生成 API:Seedream 即梦
在前面的部分我们主要和文本相关的任务打交道,接下来我们将尝试接入图片生成的功能,支持从文字描述生成图片,或者对图片进行修改。
ℹ️ 原理延伸
如果你想了解更多原理相关的内容,请查看附录:图像生成入门。
了解更多:什么是 Seedream 即梦?

也许你已经知道 Nano Banana(Google 开发),但你最好不要错过 Seedream。Seedream 4.5 是字节跳动打造的新一代图像创作模型。它将图像生成和图像编辑能力集成到一个统一的架构中。这使得它能够灵活处理复杂的多模态任务,如基于知识的生成、复杂推理和参考一致性。此外,它的推理速度比前代产品快得多,并且可以生成分辨率高达 4K 的令人惊叹的高清图像。


主要能力:
- 文生图:用文字描述生成图片,支持多种风格(写实、卡通、水墨、赛博朋克等)
- 风格迁移:将一张图片转换成指定的艺术风格
- 图像变体:基于参考图生成相似风格的新图
- 分辨率提升:增强图片清晰度和细节
- 图像编辑:在现有图片上进行编辑和修改,通过自然语言指令
为什么选择 Seedream?
- 国内网络稳定:国内访问速度快,延迟低
- 效果优秀:在电商、素材场景下表现稳定可靠
- 中文优化:对中文提示词理解更准确,适合国内用户
- 速度快:生成效率高,响应时间短
- 质量稳定:生成分辨率高达 4K 的高清图像
典型应用场景:
- 电商:生成主图、详情页配图、促销海报
- 社交媒体:生成头像、表情包、配图
- 设计:快速出概念图、素材图、背景图
- 营销:制作广告图、活动 banner、节日海报
与 Qwen3 VL 的配合:
这两个 API 可以串联使用:先用 Qwen3 VL 分析参考图,理解画面内容;再用 Seedream 基于分析参考图的提示词内容生成新图片。
你可能在抖音、B 站或 YouTube 上看到的很多 "AI 海报 / AI 主图 / AI 角色图",本质上都是用到这部分介绍的技术。你需要做的事情很简单:把用户输入整理成一句话,请求图片 API,然后把返回的图片展示出来。此时用到的模型叫做图片生成 / 图片编辑模型。
我们将逐步演示如何将 Seedream API 集成到你的项目中(通过 AI IDE 辅助完成)。
访问首页页面后,点击登录。
登录后,找到页面右上角的充值选项。
进行充值需要实名认证。
认证成功后,你可以充值 1 元用于测试。
返回初始界面并点击 API 访问。
首先,创建一个 API key,然后点击选择选项。
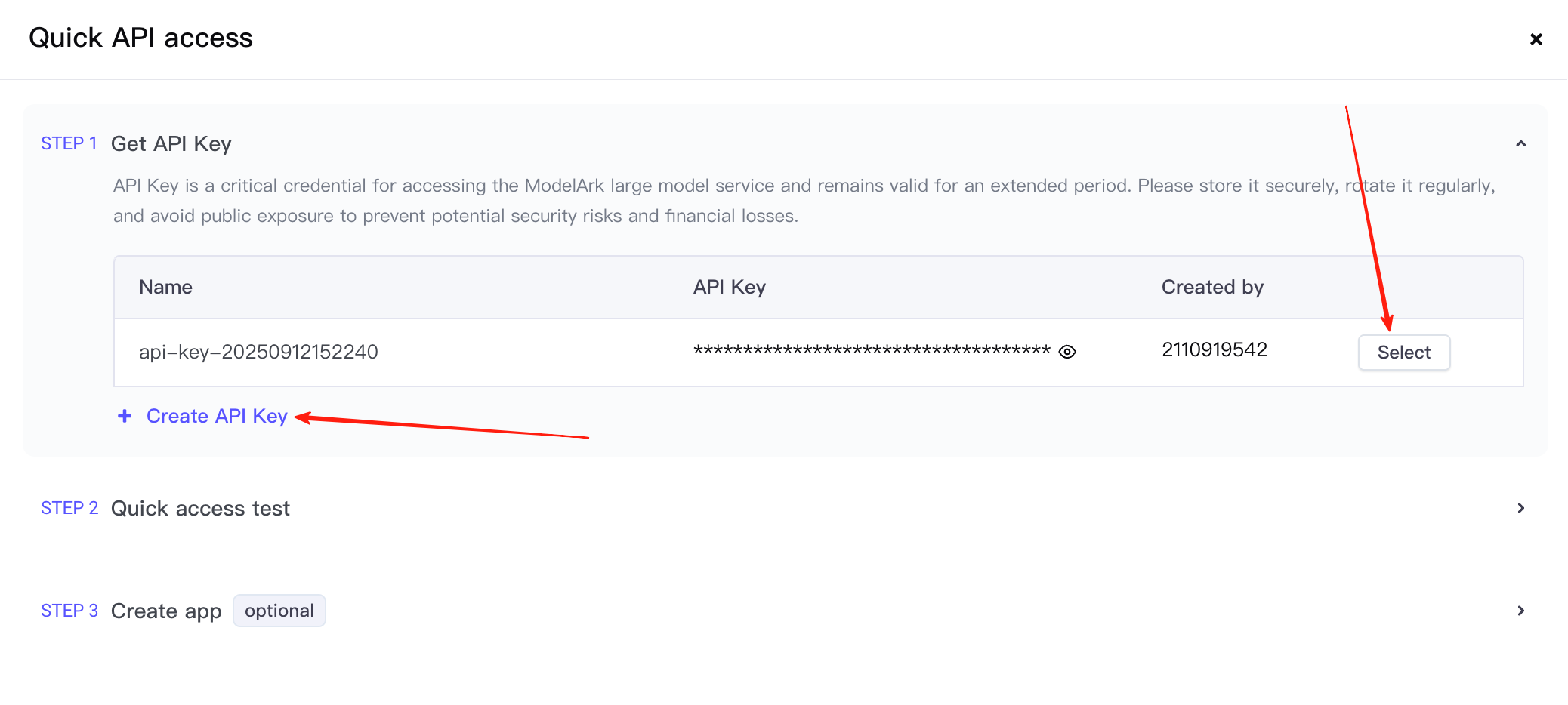
这将带你进入第 2 步。在这里,你需要确认调用的服务是 Seedream 4.5,并复制提供的调用示例。(此处截图时间比较早起,故而模型版本仍然是 4.0)
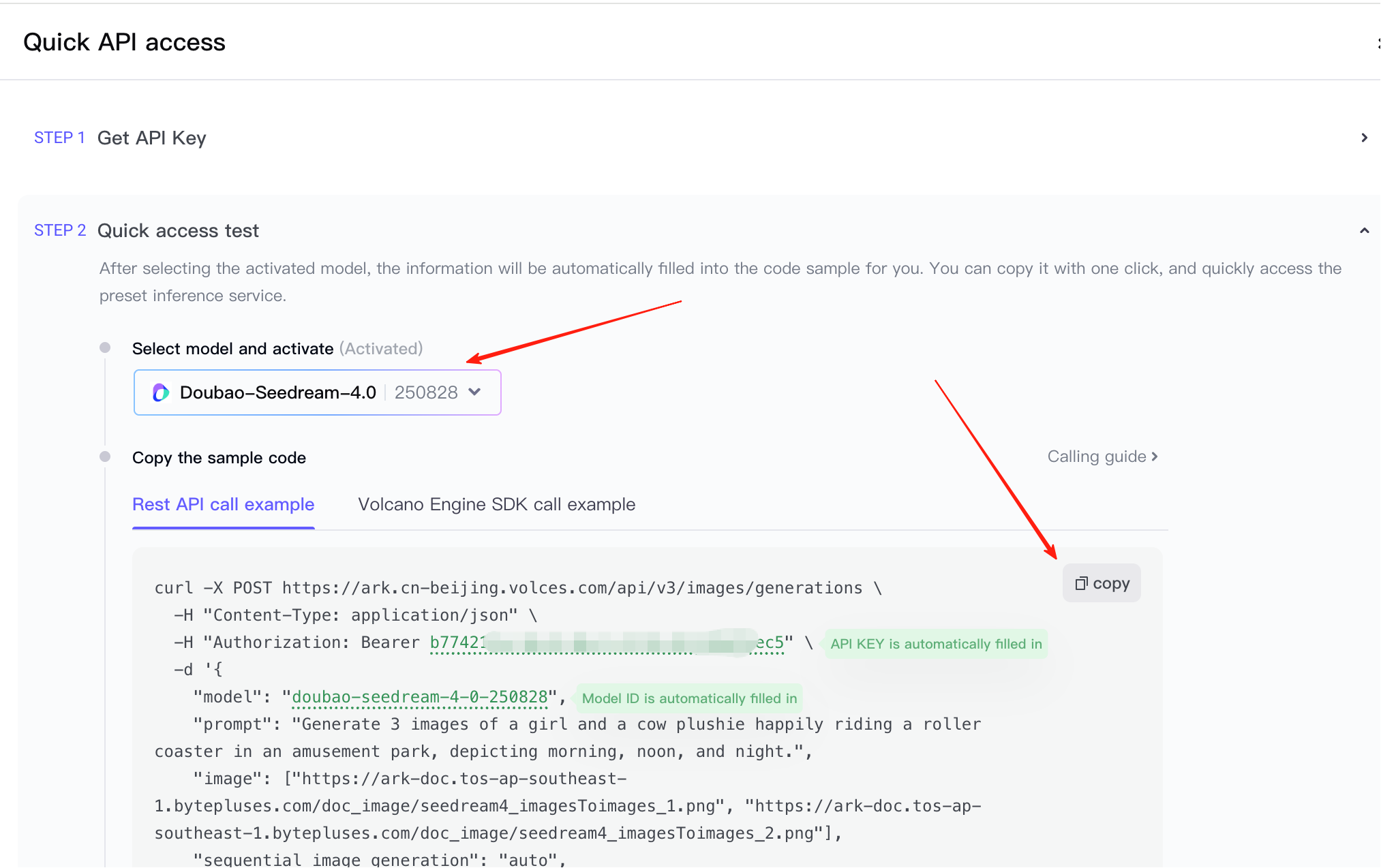
准备好 API Key 和调用示例后,你可以直接将它们粘贴到 AI IDE 中,让它生成前端交互演示或把能力接入现有原型。注意到在图片中可以选择是文生图还是多张图片生成单张图,你需要根据当前的需求进行选择参考代码。
⚠️ 重要提示
这里的默认示例相对复杂。记得禁用 "添加水印" 和 "流式响应",以确保不生成水印且不会发生请求失败。
由于我们之后使用的是参考图生成模式,我们先去的是多张图生成单张图的功能。参考代码复制如下:
curl -X POST https://ark.cn-beijing.volces.com/api/v3/images/generations \
-H "Content-Type: application/json" \
-H "Authorization: Bearer xxxxxxx" \
-d '{
"model": "doubao-seedream-4-5-251128",
"prompt": "将图1的服装换为图2的服装",
"image": ["https://ark-project.tos-cn-beijing.volces.com/doc_image/seedream4_imagesToimage_1.png", "https://ark-project.tos-cn-beijing.volces.com/doc_image/seedream4_imagesToimage_2.png"],
"sequential_image_generation": "disabled",
"response_format": "url",
"size": "2K",
"stream": false,
"watermark": true
}'有了图像参考代码后,我们让 AI IDE 支持电商中常用的图像任务功能:
请你基于下面 API,帮我实现这个工程中,电商业务的常见功能(例如海报生成、抖音电商首图生成等等)
<此处粘贴 API KEY以及图像编辑代码>实现效果如下:
值得注意的是,由于生成图片可能会经常遇到一些奇怪的问题,建议你需要让 AI IDE 能够显示完整的报错信息,方便复制粘贴进行修改(否则可能会反复显示生成失败但是不知道为什么),例如你可以说:
不要只显示图片生成失败,每次都显示完整的失败原因,比如图片不匹配、请求错误、超时等等!有时候修改后更新并不会应用到网页中,如果你发现修改后网页一直还在报错(反复多次),也可以试试直接对 AI IDE 说:请你重启这个项目。
在电商的业务中,我们可能会想让用户上传的衣服能够自动穿在人物身上,又或者是自动生成商品吸引人的售卖图、海报。这里我们尝试的提示词是让它生成一个电商海报:
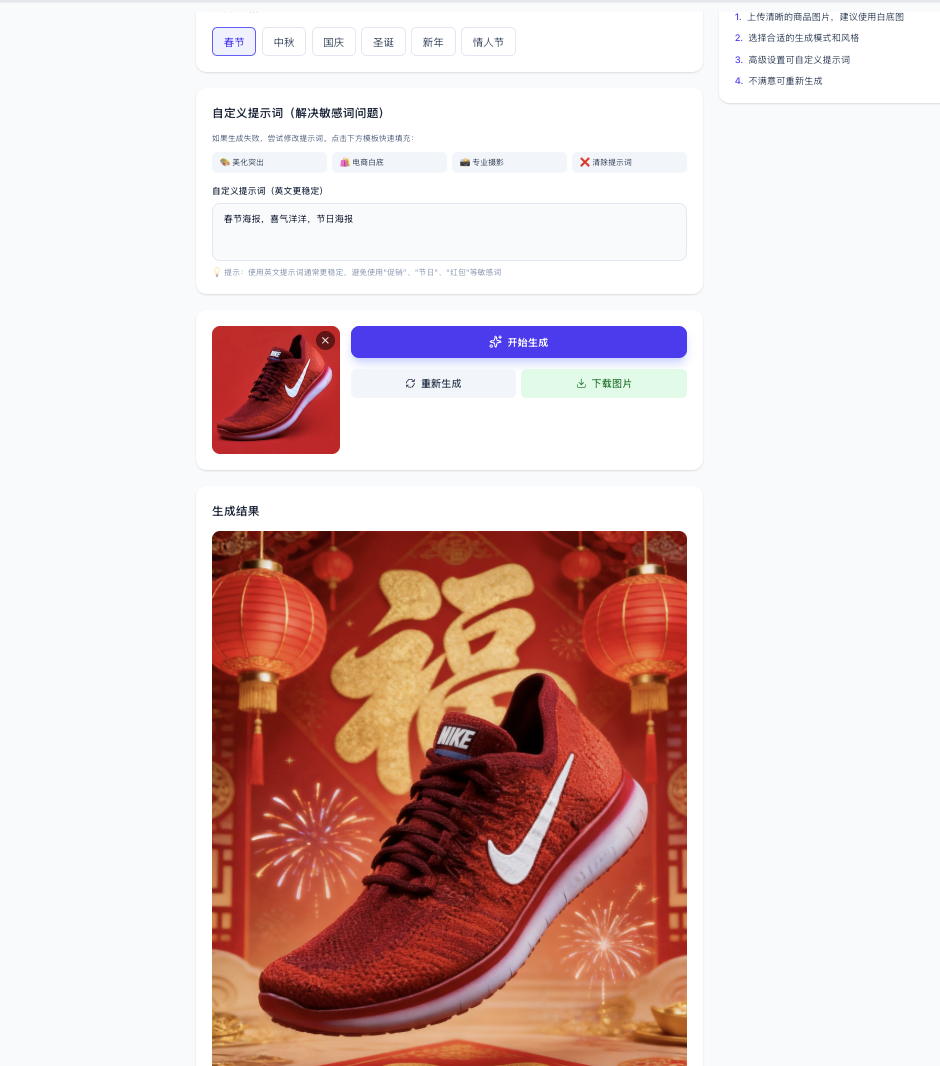
你可以根据自己想象的业务场景,使用文生图或者图生图 API 实现不同的功能。
更多不同图像服务选型
下面给出其他选择。建议你先跑通 Qwen 生图的结果,再根据效果与成本使用下列服务做替换(根据实际使用感受选择)。
Recraft 集成
如果你的原型更偏“设计生产”(例如生成品牌风格插画、营销海报、矢量风格素材),Recraft 往往会更顺手。接入方式与上一节完全一致:拿到 Key + 找到官方示例 + 让 AI IDE 把示例落到你的按钮/页面里。
了解更多:什么是 Recraft?
Recraft 是一款面向设计师、插画师和营销人员的 AI 工具——于 2022 年在美国成立,总部位于伦敦。它帮助生成/迭代视觉效果(图像、矢量艺术、3D 图形),具有高质量输出(任何文本大小/长度)、精确元素定位和品牌一致性设计等优势。受到 200 个国家/地区 300 多万用户(包括奥美、Netflix)的信任,并已创建了 3.5 亿多张图像,其团队旨在使其成为必备的设计师工具,确保创作者能够控制他们的 AI 辅助工作流程。


首先,我们仍然需要找到 API 入口以获取 API Key。
由于这里没有提供免费额度,我们需要自己充值 1,000 积分。这个网站支持支付宝和微信支付,所以很容易获得 1,000 积分(注意:不要充值超过必要的金额)。

之后,我们仍然遵循同样的方法:去官方文档找到相应的请求示例:
Qwen Image / Qwen Image Edit 集成
如果你希望使用更简单的方式接入图像生成服务,可以考虑 Qwen Image(通义万相)。思路同样不变:把它当成一个"图片生成 API",接到你的原型按钮上即可。
了解更多:Qwen Image / Qwen Image Edit 是什么?
Qwen Image(也称通义万相)是阿里云通义团队推出的图像生成模型系列,主要包括两大模型:
1. Qwen Image——文生图(Text-to-Image)模型
根据文字描述生成全新的图片。你输入一段提示词,模型会理解你的意图并生成符合描述的图像。

主要能力:
- 文生图:用文字描述生成图片,支持多种风格(写实、卡通、水墨、赛博朋克等)
- 风格迁移:将一张图片转换成指定的艺术风格
- 图像变体:基于参考图生成相似风格的新图
- 分辨率提升:增强图片清晰度和细节
2. Qwen Image Edit——图生图(Image-to-Image)模型
在现有图片上进行编辑和修改。通过自然语言指令,让模型理解你的修改意图并生成结果。
主要能力:
- 局部替换:替换图片中的某个物体或人物(如「把背景换成海边」)
- 元素移除:去除图片中不需要的元素
- 风格转换:给图片添加滤镜或艺术效果
- 图像扩展:扩展图片边界,生成新内容
- 智能修图:自动美化、调整光影、修复瑕疵



为什么选择 Qwen Image 系列?
- 中文优化:对中文提示词理解更准确,适合国内用户
- 成本低:相比国际竞品,价格更实惠
- 速度快:生成效率高,响应时间短
- 质量稳定:在电商、素材场景下表现稳定可靠
- 风格多样:支持多种艺术风格和创意效果
典型应用场景:
- 电商:生成主图、详情页配图、促销海报
- 社交媒体:生成头像、表情包、配图
- 设计:快速出概念图、素材图、背景图
- 营销:制作广告图、活动 banner、节日海报
查看 SiliconFlow 的官网。左侧有一个"Playground"部分,你可以在不进行 API 调用的情况下试用不同的模型。在网页顶部有一个"Filters"按钮;点击它可以筛选右侧的模型列表。
如果你选择"Image",你将只看到当前支持的所有文生图模型。在这种情况下,我们将使用 Qwen/Qwen-Image。
一切设置好后,我们需要参考相应的图像生成 API 文档。你可以在官方文档页面找到任何标记为"API Reference"的部分。点击它,然后导航到图像生成的 API 部分并找到相关的请求示例。
你可以把下列请求示例和 API KEY 一起发给 AI IDE, 即可实现图像生成的功能。
curl --request POST \
--url https://api.siliconflow.cn/v1/images/generations \
--header 'Authorization: Bearer <token>' \
--header 'Content-Type: application/json' \
--data '
{
"model": "Qwen/Qwen-Image-Edit-2509",
"prompt": "an island near sea, with seagulls, moon shining over the sea, light house, boats int he background, fish flying over the sea"
}
'这里的模型可以使用 Qwen/Qwen-Image 或者 Qwen/Qwen-Image-Edit-2509。
图像编辑参考代码
复制下列代码和 key,一起发送给 AI IDE:
import requests
import os
from typing import Dict, Any, Optional
SILICONFLOW_API_KEY: str = ""
SILICONFLOW_BASE_URL: str = "https://api.siliconflow.cn/v1/images/generations"
QWEN_IMAGE_EDIT_MODEL: str = "Qwen/Qwen-Image-Edit-2509"
def generate_image_edit(
prompt: str,
image: Optional[str] = None,
image2: Optional[str] = None,
image3: Optional[str] = None,
negative_prompt: Optional[str] = None,
cfg: Optional[float] = 4.0,
seed: Optional[int] = None
) -> Optional[Dict[str, Any]]:
payload: Dict[str, Any] = {
"model": QWEN_IMAGE_EDIT_MODEL,
"prompt": prompt,
}
if image:
payload["image"] = image
if image2:
payload["image2"] = image2
if image3:
payload["image3"] = image3
if negative_prompt:
payload["negative_prompt"] = negative_prompt
if cfg is not None:
payload["cfg"] = cfg
if seed is not None:
payload["seed"] = seed
headers: Dict[str, str] = {
"Authorization": f"Bearer {SILICONFLOW_API_KEY}",
"Content-Type": "application/json"
}
try:
response = requests.post(SILICONFLOW_BASE_URL, json=payload, headers=headers)
response.raise_for_status()
return response.json()
except requests.exceptions.RequestException as e:
print(f"Error generating image: {e}")
return None
def save_image_from_url(image_url: str, output_path: str = "image.png") -> bool:
try:
response = requests.get(image_url)
response.raise_for_status()
os.makedirs(os.path.dirname(output_path) if os.path.dirname(output_path) else ".", exist_ok=True)
with open(output_path, "wb") as f:
f.write(response.content)
print(f"Image saved successfully to: {output_path}")
return True
except requests.exceptions.RequestException as e:
print(f"Error downloading image: {e}")
return False
except Exception as e:
print(f"Error saving image: {e}")
return False
prompt: str = "让天空变成傍晚,有月亮和星星,梦幻风格"
negative_prompt: str = "模糊, 低质量, 扭曲"
image_url: str = "https://inews.gtimg.com/om_bt/Os3eJ8u3SgB3Kd-zrRRhgfR5hUvdwcVPKUTNO6O7sZfUwAA/641"
image2_url: Optional[str] = None
image3_url: Optional[str] = None
cfg: float = 4.0
seed: int = 12345
output_path: str = "edited_image.png"
print(f"Generating edited image with prompt: {prompt}")
print(f"Input image: {image_url}")
print(f"CFG: {cfg}, Seed: {seed}")
print("-" * 50)
result = generate_image_edit(
prompt=prompt,
image=image_url,
image2=image2_url,
image3=image3_url,
negative_prompt=negative_prompt,
cfg=cfg,
seed=seed
)
if result and "images" in result:
images = result["images"]
if images and len(images) > 0:
image_url_result = images[0]["url"]
print(f"Image edit generated successfully. URL: {image_url_result}")
success = save_image_from_url(image_url_result, output_path)
if success:
print(f"Image saved to: {output_path}")
else:
print("Failed to save image to local file")
else:
print("No images found in response")
else:
print("Image generation failed")
if result:
print(f"Response: {result}")附录:如何找到“当前更强”的 AI 模型
文字模型(也常被叫作“大语言模型”)的发展速度非常快,我们总是需要确保我们用的是表现更好的模型之一。通过以下两个网站,你可以很方便地看到“现在大家常用、评价也更好的模型”。
一般来说,这类网站可以理解为 “模型竞技场”:它会把两个模型的输出放在一起,你投票选你更喜欢的那个。票数高的模型,通常意味着更多人觉得它“更好用”。
此外,你偶尔可能会在这些大模型竞技场中看到神秘的匿名模型(“Unknown Model”)。这通常意味着:有人把“内部测试模型”悄悄放进来做盲测,你可能有机会提前体验到更强的能力。
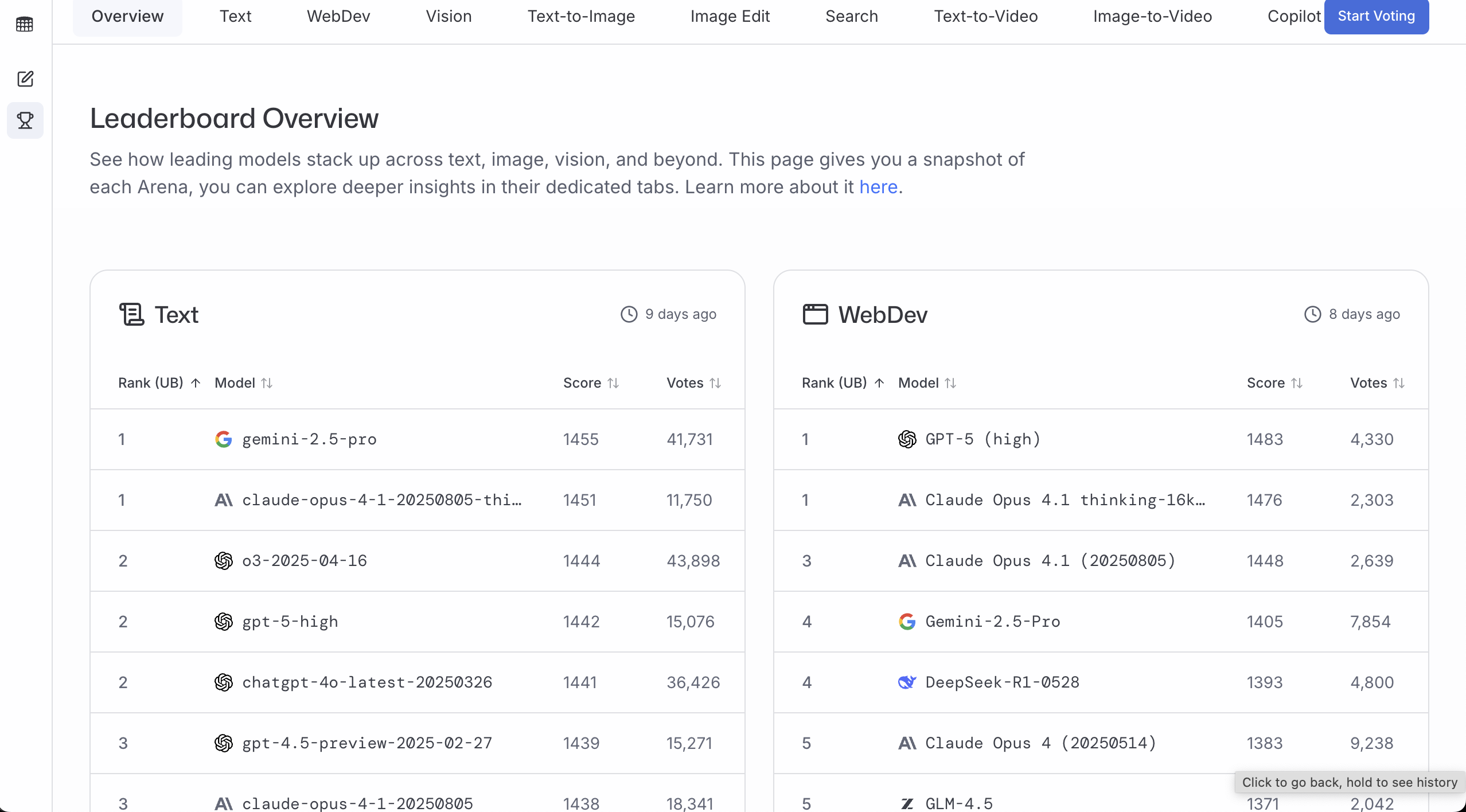
LMArena
LMArena 更适合用来判断“多数人更偏好哪个模型的回答”。投票越多、分数越高,通常意味着它在真实使用场景里更稳。
一个简单的用法是:
- 直接看排行榜(Leaderboard)
- 先选一个你要做的方向(例如通用对话 / 编程 / 视觉)
- 选 Top 3 里你能用的那个(能访问、价格能接受、延迟能接受)
Artificial Analysis
网站:https://artificialanalysis.ai/
Artificial Analysis 更适合把“效果 / 价格 / 速度”放在同一张表里对比,你可以把它当作模型选型的参数表。
常用的用法是:
- 找到你关心的模型类别(文本 / 生图等)
- 看质量指标(Quality)+ 价格(Price)+ 延迟/吞吐(Latency/Throughput)
- 选一个“综合性价比”最符合你产品的
✅ 建议
不要凭感觉争论“哪个更强”。更可靠的做法是:用同一组输入同时测试 2~3 个模型,再结合榜单与价格做决定。
总结
在接入各类 AI 服务时,不必把 API 想象得太复杂。把握住以下几个核心概念,基本就能应对大多数场景:
API 的本质是通信桥梁。它做的事情很简单:把你的请求发送出去,再把模型的响应带回来。你不需要关心背后发生了什么,只需要正确地组织请求格式。
SDK 是对 API 的封装。如果说 API 是 raw 接口,SDK 就是一套现成的工具箱——它把请求签名、错误处理、参数校验这些繁琐的细节都替你做好了。日常开发中,优先选择 SDK 而不是直接调 API,能省去不少麻烦。
阅读文档时,盯住三样东西就够了:服务地址(endpoint)、身份凭证(API key)以及调用参数怎么填。把这三点弄清楚,调通只是时间问题。
剩下的工作,IDE 和现代化的开发工具会帮你完成。专注于你的业务逻辑,底层调用的事交给这些成熟的 SDK 和工具链。
5. 📚 作业:集成你的第一个 AI 能力
参考本节课的提示词和内容,完成一次完整闭环:
- 完整闭环实践
- 选择并接入一个 AI 服务(LLM / 文生图 / 图生图)→ 实现前后端交互 → 整合到你的原型中
- 成果分享
- 截图你的功能页面分享给大家看
- 思考题
- 为下一节"完整项目实践"预留空间,提前思考:你打算如何把这些 AI 能力组合起来,做出什么有意思的功能?
下一步
在下一节中,我们将把这些分散的 AI 能力串联起来,结合实际业务场景做一个完整的产品:
- 把内容策划、商品上架、数据分析等环节串联成一条完整的业务流程
- 将本节课学到的 AI 能力(LLM 文案生成、文生图、图像编辑等)嵌入到实际业务节点中
- 实现一个真正可用的"电商 AI 工作台",而不是孤立的 demo