CQL(Conservative Q-Learning)
我们已经知道离线 RL 算法,都是在”无法在线验证策略性能“的前提下,用不同手段保证”策略评估+改进“仍可靠。CQL也不例外,在本节,我们将详细介绍CQL是如何保证”策略评估+改进“的可靠性的。
OOD(Out-of Distribution) Q 值高估问题
离线场景里,策略一旦部署便无法与环境交互,也就永远没机会“打脸”那些过度乐观的 Q 值;误差遂在每次 Bellman 备份中层层叠加,最终让结果一落千丈。
Kumar 等人(2019)用 SAC 在 HalfCheetah-v2 上做了经典演示:
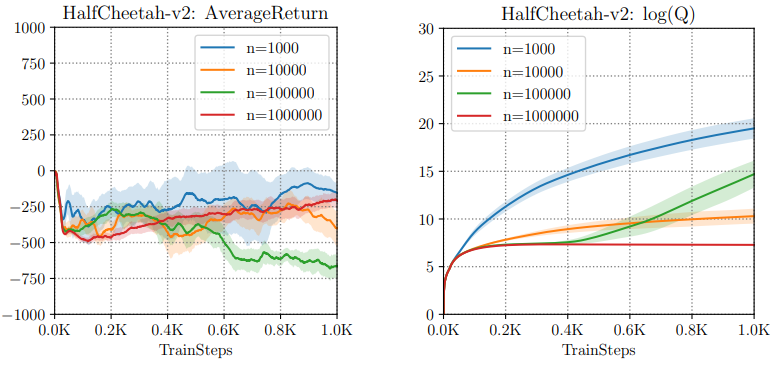
左图中横轴是 Q 网络梯度步数,纵轴是贪婪策略的实际回报。回报先上升,随后随训练持续而急剧下降,形似过拟合,却随样本倍增而依旧出现——说明问题并非传统过拟合,而是 OOD 误差在目标 Q 中持续发酵,最终把整个价值函数拖垮(见右图)。
Conservative Q-Learning(CQL)对症下药:迫使学到的 Q 函数对任意策略都保持“保守”,其期望价值天然低于真实回报。由此,策略即便贪婪,也不会被虚假的 OOD 峰值引入歧途。实现仅需在标准 Bellman 损失外增添一项 Q 值正则,几行代码即可嵌入现有 DQN 或 actor-critic 框架。离散与连续任务实验表明,CQL 最终回报普遍高出先前最佳离线算法 2–5 倍,在复杂多模态数据集上优势尤为显著
CQL 的正则化机制
CQL 在标准的 Bellman 误差损失基础上,添加了两个正则化项:
- 最小化策略动作(包括 OOD)的 Q 值(如下),其中
是策略或某种探索分布(uniform distribution),用于生成 OOD 动作。 - 最大化数据集中动作的 Q 值:
这两个项的组合,使得 Q 函数在数据分布内的动作上保持高值,而在 OOD 动作上被压低,从而防止策略被 OOD 动作吸引。从而确保学习到的 Q 函数是真实 Q 值的下界估计。这意味着:1) OOD 动作的 Q 值被压低,不会被策略误选;2) 数据分布内的动作 Q 值保持较高,策略更稳定。
接下来我们需要考虑策略优化的问题,最直接的想法是:在每一次策略迭代
当我们将
从上式可以看出,我们在实现上是非常便捷的
# 离散动作环境
q_sa = self.critic(obs)
loss = loss + self.cql_alpha * (
torch.logsumexp(q_sa/self.cql_temperature, dim=1)
- q_sa.gather(1, actions.long().view(-1, 1))/ self.cql_temperature
).mean() * self.cql_temperature
CQL算法实现
Algorithm 1 Conservative Q-Learning
- 初始化 Q 函数
,可选地初始化策略函数 。 - 对于步数
执行: - 用
梯度步训练 Q 函数,最小化式 的 CQL 目标
(Q-learning 版本用算子;actor-critic 版本用 ) - (仅 actor-critic 版本) 用
梯度步改进策略 ,采用 SAC 式的熵正则化:
- 用
- 结束循环
具体实现详见CQL-DQN-CartPole-v2 Notebook
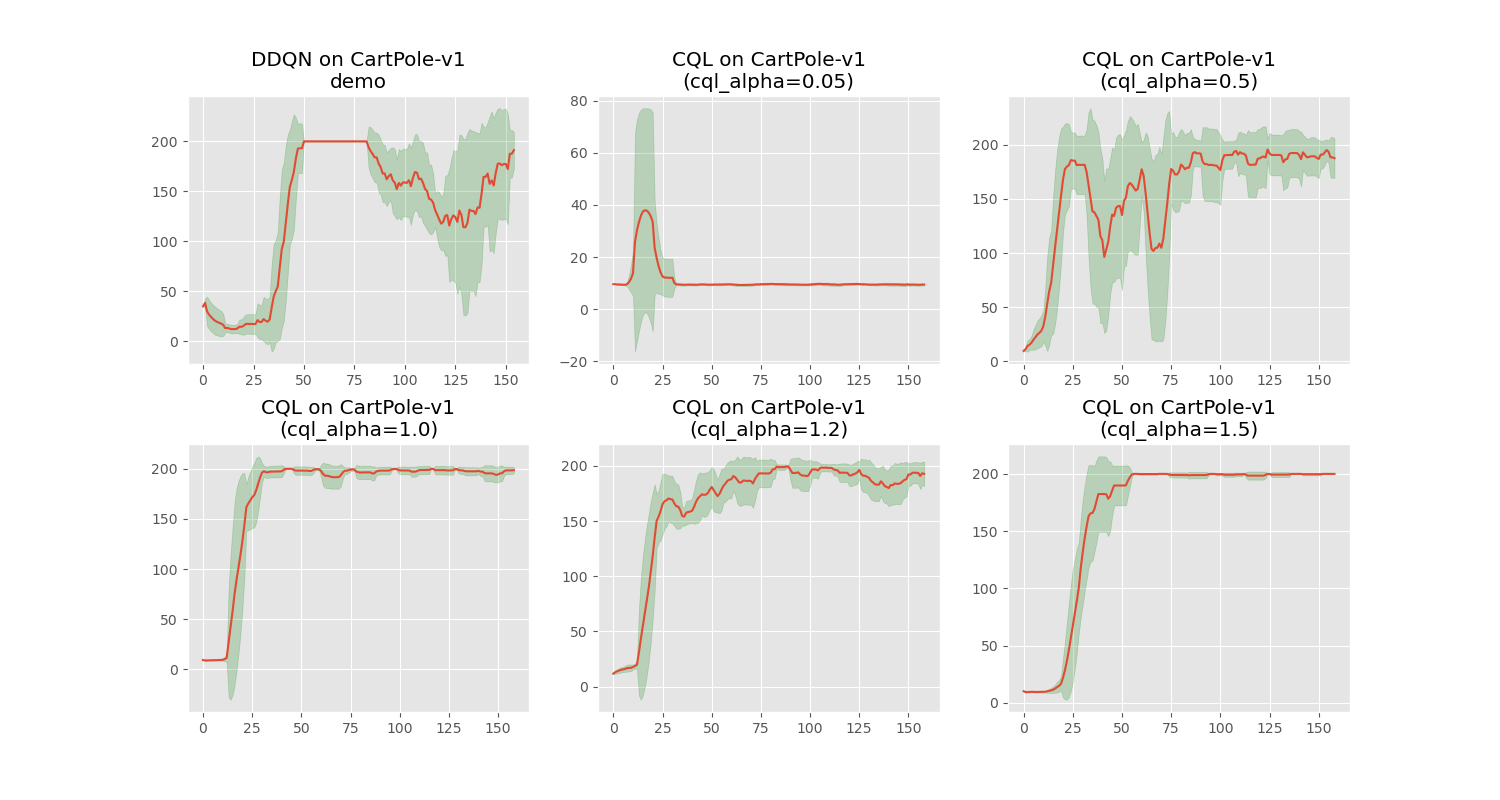
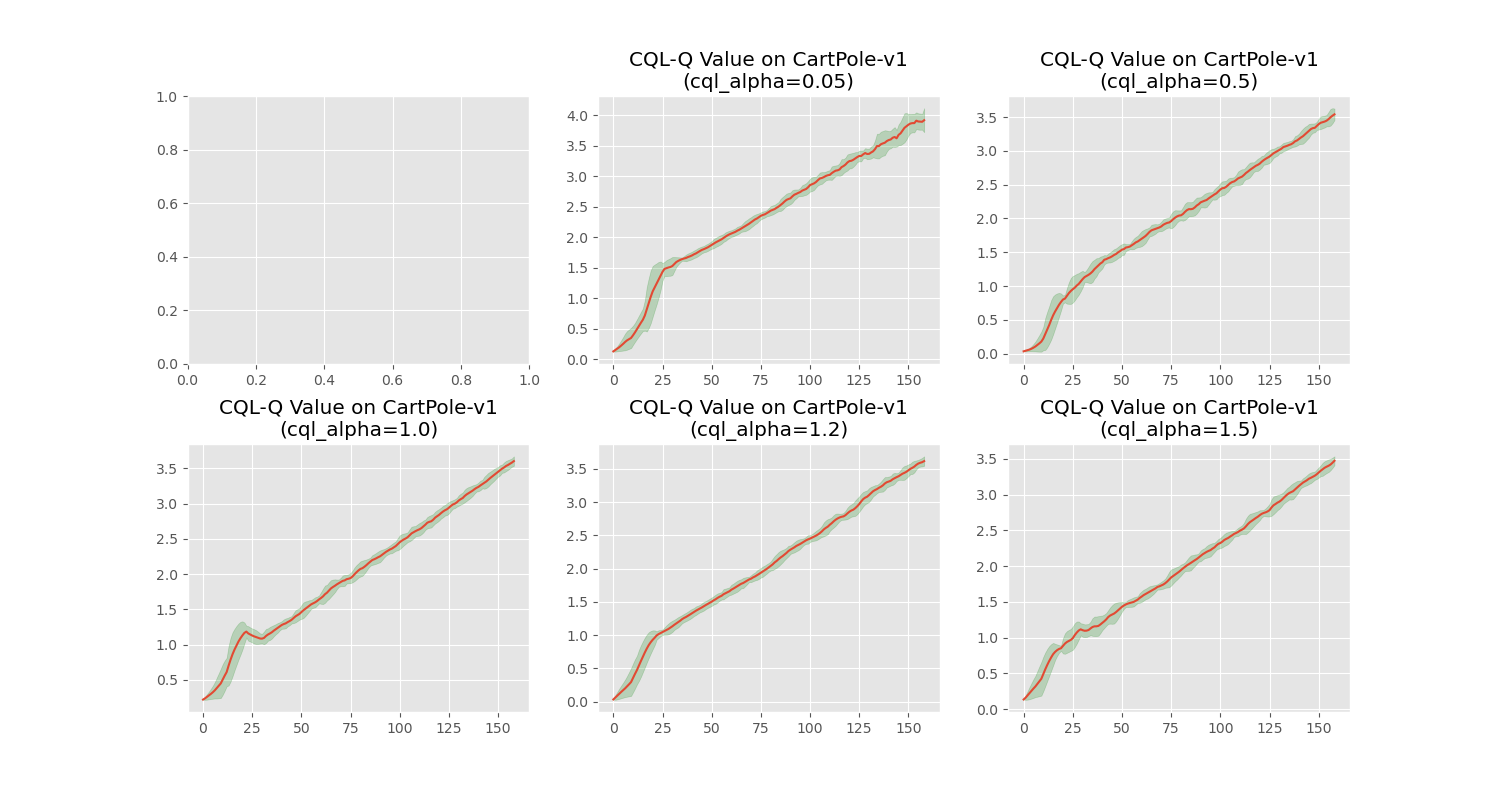
训练及效果展示
当正则化强度趋近于零时,Q 值虽持续攀升,但 episode return 并未同步增长,表明策略质量未获实质改善。在 CartPole-v1 上,将 CQL 保守系数
附录
推导A
把正则项选成 KL 散度
带正则的 policy-optimization 目标
- 约束 s.t.
把 KL 展开并写成 Lagrangian
对
- 线性项:
- 熵项:
解出
所以可以得出