离线强化学习
在正式展开具体离线强化学习(
什么是离线强化学习
经典强化学习本质是在线闭环:不论是同策略(on-policy)算法还是异策略(off-policy)算法,皆需在环境中持续采样、即时更新。该“边交互边学习”范式与现代大规模深度学习“离线超大规模数据预训练”路线存在结构性错位。 此外,RL 要求环境封闭、规则完全可描述且可重置,导致采样分布即性能上限;智能体的泛化边界被严格圈定在“可交互区域”,难以跨越未见状态空间。
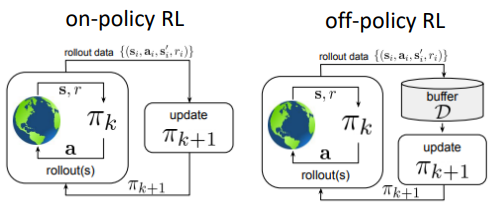
于是人们自然发问:能否像监督学习那样,用海量历史数据先训一遍,即用数据驱动的方式进行RL训练,然后再上线?
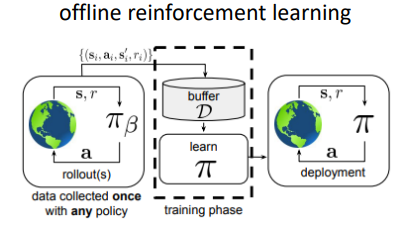
离线强化学习(offline RL)正是这一思路的产物:
其目标是在不与环境交互的情况下,仅通过历史策略(
不过在实际应用中,我们可以先用历史静态数据训练离线强化学习,部署后线上也是可以用同策略(on-policy)算法更新策略
这与人类做事方式如出一辙:面对新任务,我们先调用全部历史经验,形成初步方案;随后通过实践、试错、反馈,持续迭代想法与计划。
离线强化学习(Offline RL)将“用旧经验,做新决策”的能力固化到算法层面。进一步看,诸多真实系统因在线探索成本过高而被禁用:高风险的医疗诊疗、直接影响营收的线上策略、以及电网、物流等关键基础设施。在这些场景下,离线强化学习提供了“零在线交互”的策略迭代途径,使基于学习的控制方法真正可用。
离线强化关键难点
我们已经理清了离线强化学习是什么,来看下离线强化学习的一般形式。 基于历史静态数据
在固定数据集
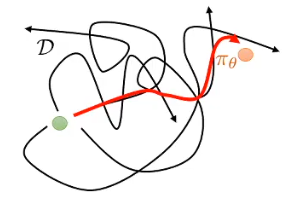
我们希望离线强化学习可以从混乱中获得秩序,超越数据集中的最佳策略,“
缝合”各种次优策略产出新的更优策略
可缝线处全是盲区:数据集没出现过的状态-动作对,价值估计全靠猜。 在线 RL 能当场试一把,错了立刻改;离线 RL 却可能把“没见过的左转”当成高价值捷径,一头撞墙才后知后觉(如图4)。

于是,离线强化学习的命门浮出水面:如何安全评估数据集之外的动作(out of distribution),而不被外推幻觉引入歧途。所有离线 RL 算法,归根结底都是在”无法在线验证策略性能“的前提下,用不同手段保证”策略评估+改进“仍可靠。