Actor-Critic 算法
基于价值的算法如
纯策略梯度算法的缺点
纯策略梯度算法虽然通过直接对策略进行参数化,解决了基于价值算法难以适配连续动作空间和随机策略的问题,但也带来了新的挑战。回顾策略梯度算法通用的目标函数,如式
其中
然而,由于蒙特卡洛估计本身的高方差特性,导致策略梯度估计也会具有较高的方差,从而影响训练的稳定性和收敛速度。而且,每次更新策略参数时都需要采样完整的轨迹,这进一步降低了采样效率,尤其是在复杂环境中,可能需要大量的样本才能获得可靠的梯度估计。此外,奖励稀疏的环境中,蒙特卡洛估计可能会导致梯度估计不准确,从而影响策略的改进。
Actor-Critic 原理
为了兼顾策略梯度算法的灵活性和基于价值算法的高效性,
如图
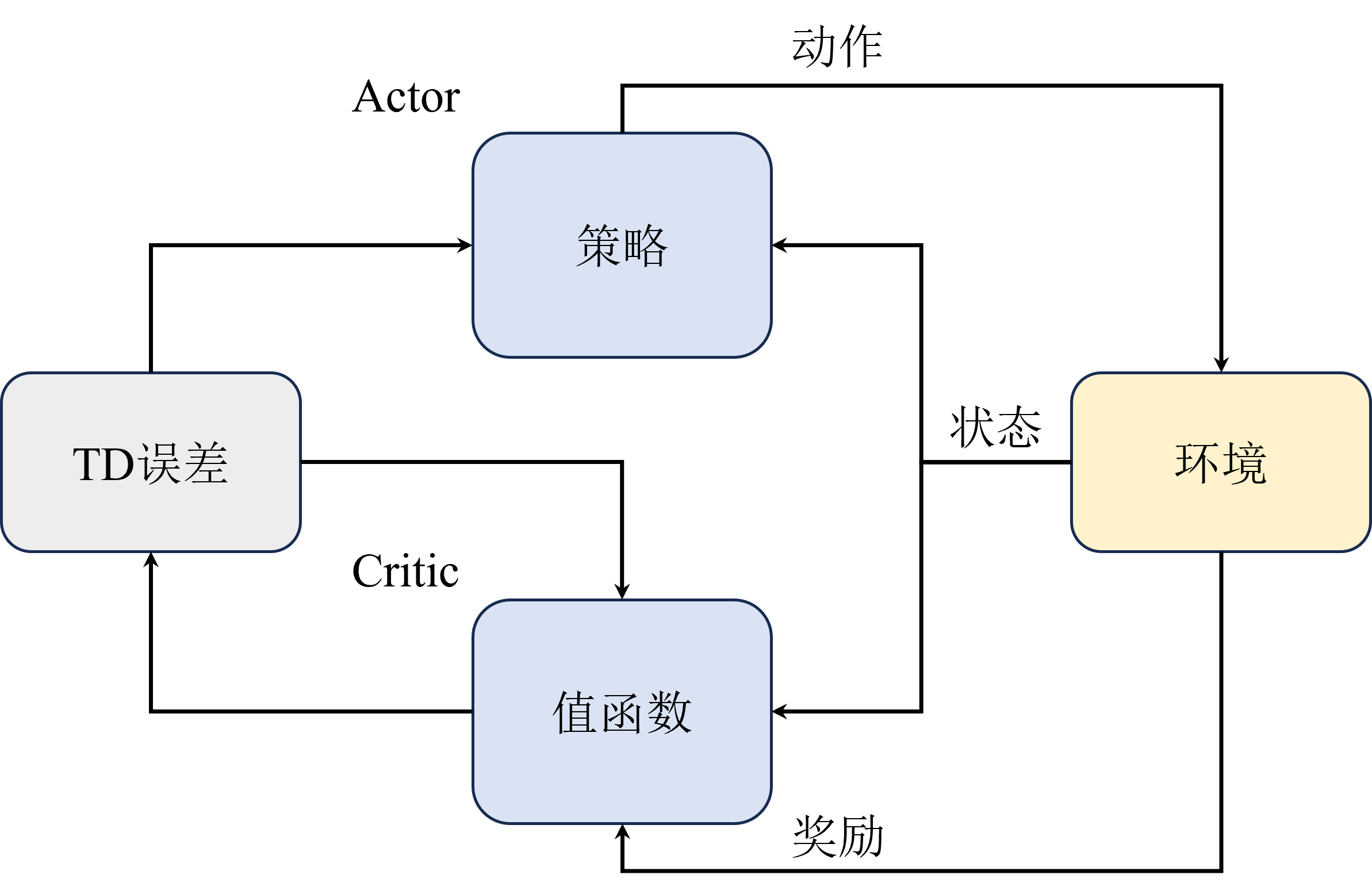
注意,
例如,对于值估计部分(
使用状态价值函数来表示
其中
对于值函数网络(
在式
注意,跟
使用状态-动作值函数来表示
同样地,
A2C 算法
与纯策略梯度算法中使用蒙特卡洛估计回报相比,使用状态价值
为了进一步提高梯度估计的稳定性和准确性,我们可以引入优势函数(
优势函数
其中
为什么引入优势函数能提高梯度估计的稳定性呢?这是因为优势函数通过减去一个基线(通常选择状态价值函数
举例来说,小明在上次数学考试中得了
类似地,引入优势函数后的
多进程
在讲 multiprocessing模块或者ray等分布式计算框架来实现多进程训练,如代码
import time
import ray
# 模拟耗时任务
def slow_square(x):
time.sleep(1)
return x * x
# Ray 版本
@ray.remote
def ray_square(x):
time.sleep(1)
return x * x
def run_single(nums):
"""单进程串行执行"""
results = []
for x in nums:
results.append(slow_square(x))
return results
def run_ray(nums):
"""Ray 并行执行"""
futures = [ray_square.remote(x) for x in nums]
results = ray.get(futures)
ray.shutdown()
return results
if __name__ == "__main__":
nums = list(range(1, 9))
print(f"任务数量: {len(nums)}")
# --- 单进程 ---
t0 = time.time()
res_single = run_single(nums)
t1 = time.time()
print(f"单进程耗时: {t1 - t0:.2f} 秒")
# --- Ray 并行 ---
ray.init(ignore_reinit_error=True, num_cpus=8)
t2 = time.time()
res_ray = run_ray(nums)
t3 = time.time()
print(f"Ray 并行耗时: {t3 - t2:.2f} 秒")
执行结果如代码
任务数量: 8
单进程耗时: 8.01 秒
Ray 并行耗时: 2.69 秒
从结果可以看出,使用多进程并行计算显著减少了总的计算时间。
传统的强化学习算法通常是单进程串行训练,即一个智能体与环境交互并更新其策略和价值函数参数。然而,这种方式在某些情况下可能效率较低,尤其是在环境交互较慢或样本效率较低的情况下。而多进程训练可以让多个智能体同时与环境交互,同一时间内收集更多的样本数据,从而提高训练效率和样本利用率。
A3C 算法
基于多进程训练的思想,
如图
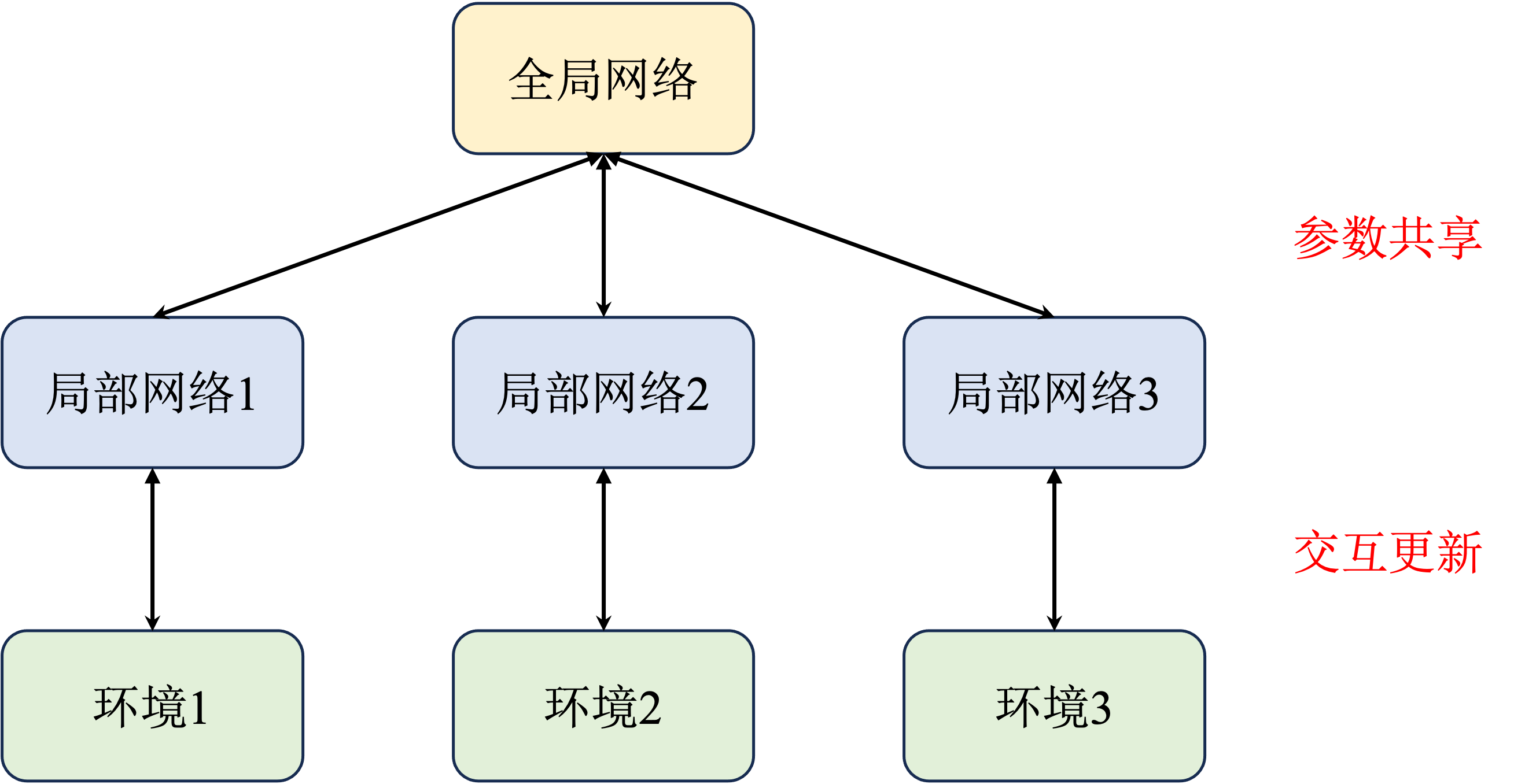
与传统的单进程训练相比,
- 增强探索能力:多个智能体在不同的环境实例中进行探索,能够覆盖更广泛的状态空间,减少陷入局部最优的风险。
- 稳定性提升:异步更新机制能够减少不同智能体之间的相互干扰,从而提高训练的稳定性。
此外,多进程训练的思路也可以应用到其他强化学习算法中,包括基于价值的方法例如
广义优势估计
前面讲到通过引入优化函数来评估策略相对于平均水平的优势,如式
然而,在实际中我们并不知道真实的
这种估计方式虽然方差较小,但是偏差较大。
也可以使用蒙特卡洛估计来估计优势函数,虽然这种方式是无偏估计,但是方差较大,如式
对应实现如代码
def monte_carlo_advantage_estimation(rewards, values, gamma):
"""计算蒙特卡洛优势估计
rewards: 奖励序列
values: 价值函数估计序列
gamma: 折扣因子
"""
T = len(rewards)
advantages = []
for t in range(T):
G = 0
for l in range(T - t):
G += (gamma ** l) * rewards[t + l]
advantages.append(G - values[t])
return advantages
# 示例数据
rewards = [1, 2, 3, 4, 5]
values = [0.5, 1.5, 2.5, 3.5, 4.5]
gamma = 0.9
advantages = monte_carlo_advantage_estimation(rewards, values, gamma)
print("蒙特卡洛优势估计:", advantages)
在这里我们还可以使用介于单步
对应实现如代码
def n_step_advantage_estimation(rewards, values, gamma, n):
"""计算 n 步优势估计
rewards: 奖励序列
values: 价值函数估计序列
gamma: 折扣因子
n: 步数
"""
T = len(rewards)
advantages = []
for t in range(T):
G = 0
for l in range(n):
if t + l < T: # 确保不越界
G += (gamma ** l) * rewards[t + l]
else:
break
if t + n < T:
G += (gamma ** n) * values[t + n]
advantages.append(G - values[t])
return advantages
# 示例数据
rewards = [1, 2, 3, 4, 5]
values = [0.5, 1.5, 2.5, 3.5, 4.5]
gamma = 0.9
n = 3
advantages = n_step_advantage_estimation(rewards, values, gamma, n)
print("n 步优势估计:", advantages)
然而
为了解决这个问题,我们可以引入一个新的参数
其中
并且广义优势还有一个递推形式,如式
注意为了方便,这里将
当
当
通过调整
import torch
def compute_gae(rewards, values, dones, gamma=0.99, lam=0.95):
"""
计算 Generalized Advantage Estimation (GAE)
参数:
rewards (Tensor): shape = [T],每一步的即时奖励
values (Tensor): shape = [T+1],值函数 V(s_t),最后一个是 V(s_{T+1})
dones (Tensor): shape = [T],是否为终止状态(True/False)
gamma (float): 折扣因子
lam (float): GAE 衰减系数 λ
返回:
advantages (Tensor): shape = [T],GAE 优势值
returns (Tensor): shape = [T],对应的回报值 (adv + value)
"""
T = len(rewards)
advantages = torch.zeros(T, dtype=torch.float32)
last_adv = 0.0
for t in reversed(range(T)):
# 如果到达终止状态,下一步优势为0
if dones[t]:
next_non_terminal = 0.0
next_value = 0.0
else:
next_non_terminal = 1.0
next_value = values[t + 1]
# TD 误差 δ_t
delta = rewards[t] + gamma * next_value * next_non_terminal - values[t]
# GAE 递推公式
advantages[t] = delta + gamma * lam * next_non_terminal * last_adv
last_adv = advantages[t]
returns = advantages + values[:-1]
return advantages, returns
# 示例数据
rewards = torch.tensor([1.0, 2.0, 3.0, 4.0, 5.0])
values = torch.tensor([0.5, 1.5, 2.5, 3.5, 4.5, 0.0]) # 注意 values 长度为 T+1
dones = torch.tensor([0, 0, 0, 0, 1], dtype=torch.bool)
advantages, returns = compute_gae(rewards, values, dones)
print("GAE 优势估计:", advantages)
print("对应回报值:", returns)
思考
相比于
改进点主要有:优势估计:可以更好地区分好的动作和坏的动作,同时减小优化中的方差,从而提高了梯度的精确性,使得策略更新更有效率;使用