马尔可夫决策过程
本章开始介绍马尔可夫决策过程的基本概念,包括马尔可夫性质、回报、状态转移矩阵等内容。马尔可夫决策过程是强化学习的核心问题模型,即想用强化学习来解决问题,首先需要将问题建模为马尔可夫决策过程,并明确状态空间、动作空间、状态转移概率和奖励函数等要素。此外,还介绍了策略、状态价值和动作价值等重要概念,这些概念在后续的强化学习算法中会频繁用到,务必牢记。
马尔可夫决策过程
在强化学习中,马尔可夫决策过程(
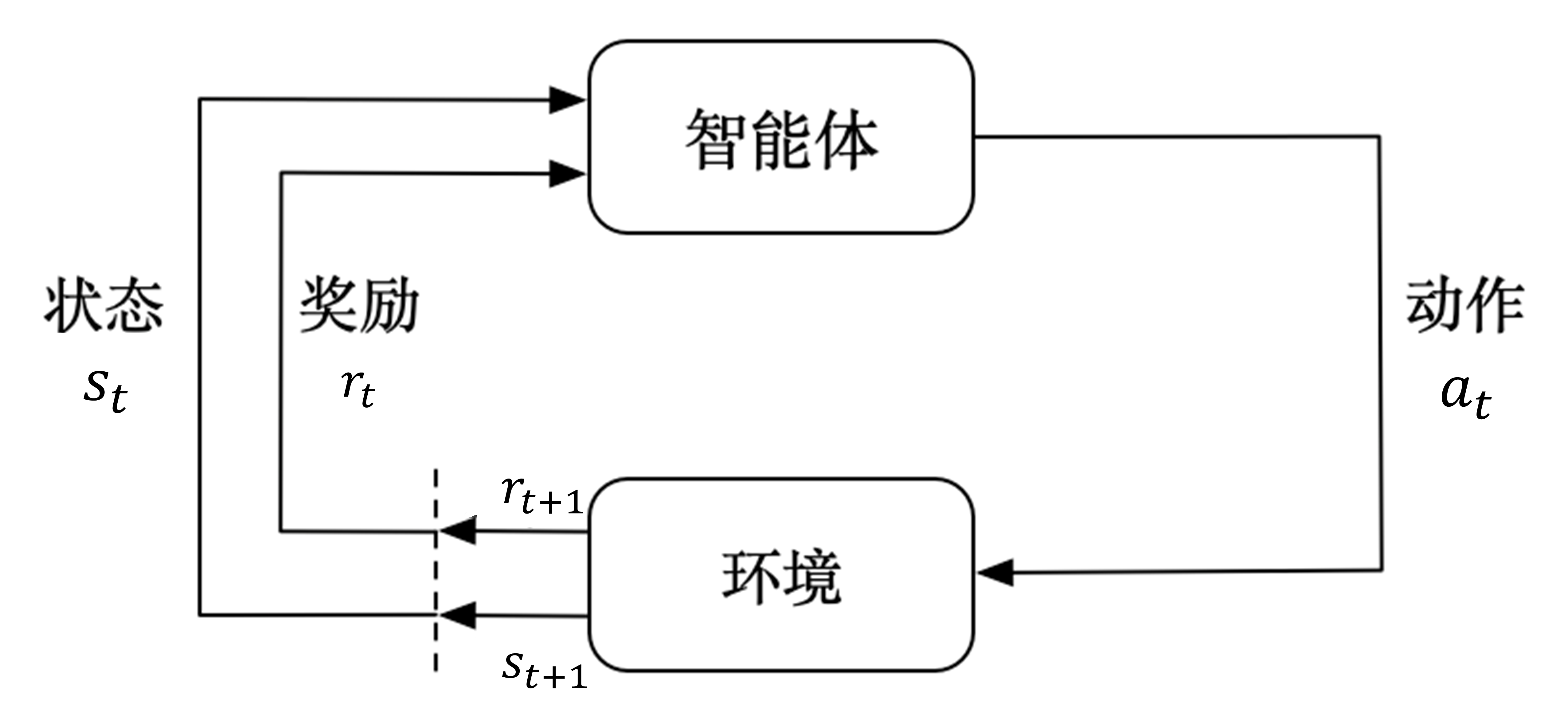
这个过程不断重复,形成一条轨迹,如式
完成一条完整的轨迹,即从初始状态到终止状态(例如玩游戏玩到最终的胜负结算阶段),也称为一个回合(
如果要用强化学习来解决问题,首先需要将问题建模为马尔可夫决策过程,即明确状态空间、动作空间、状态转移概率和奖励函数等要素。通常我们用一个五元组来定义马尔可夫决策过程,如式
其中
马尔可夫性质
马尔可夫决策过程的核心假设是马尔可夫性质(Markov Property),即系统未来状态的概率分布只依赖于当前的状态和动作,而与过去的状态和动作无关,如式
然而,在真实世界中严格满足马尔可夫性质的情况并不多见,但大多情况下,我们依然可以通过适当的状态表示来近似满足马尔可夫性质。
例如在自动驾驶中,将当前车辆的位置、速度和周围环境信息作为状态表示,这些信息足以预测下一时刻的状态,而不需要考虑更早之前的历史数据,从而近似满足马尔可夫性质,这样的过程也叫做部分可观测马尔可夫决策过程(Partially Observable Markov Decision Process, POMDP)。
状态转移矩阵
通常,马尔可夫决策过程通常指有限马尔可夫决策过程(
既然状态数有限,就可以用一种状态流向图的形式表示智能体与环境交互过程中的走向。如图 2 所示,图中每个曲线箭头表示指向自己,对于状态
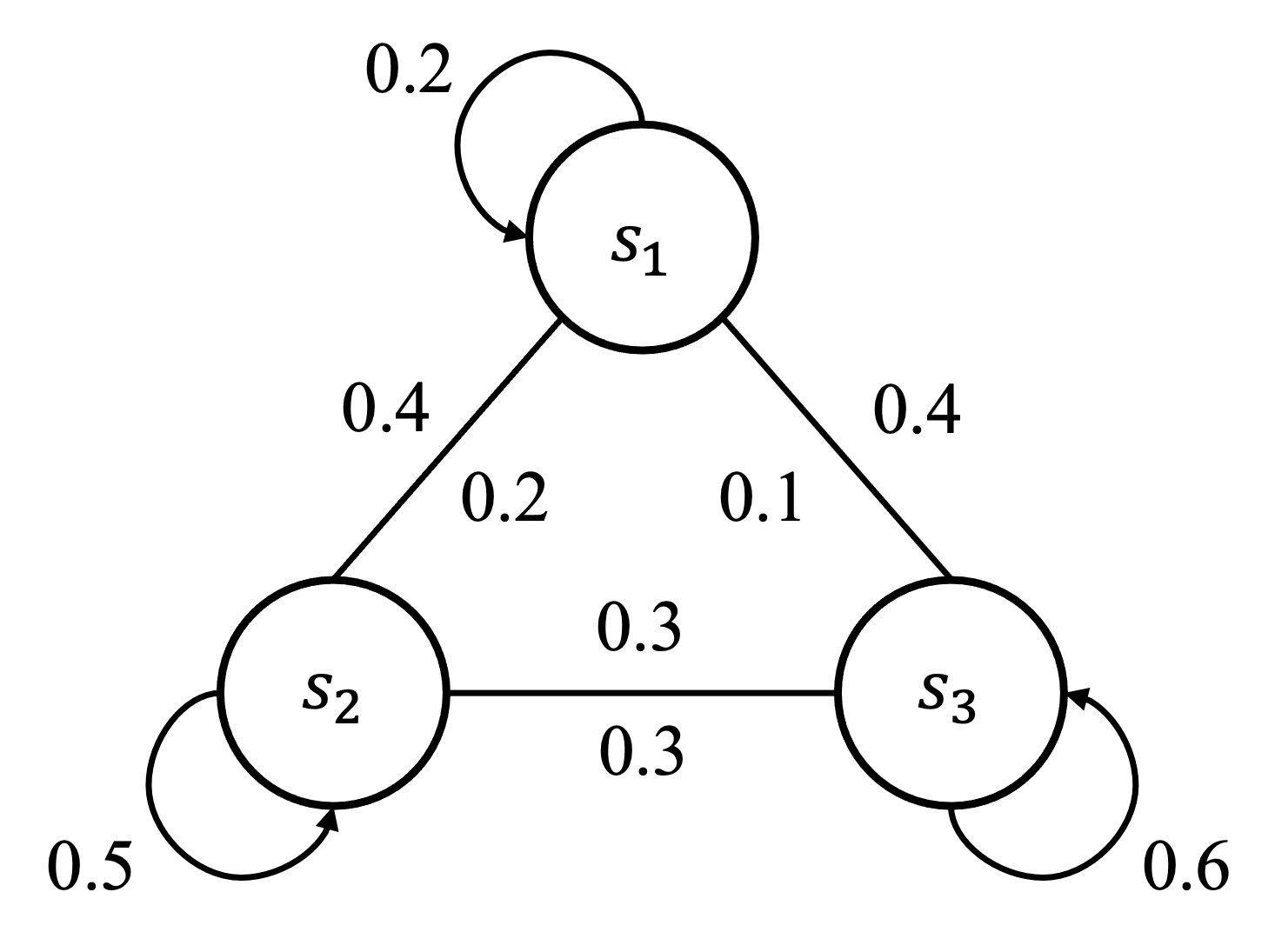
注意,图 2 中并没有包含动作和奖励等元素,因此严格来说它表示的是马尔可夫链(
我们用一个概率来表示状态之间的切换,如式
即当前状态是
拓展到所有状态,可以把这些概率绘制成一个状态转移表,如表 1 所示。
在数学上也可以用矩阵来表示,如式
这个矩阵就叫做状态转移矩阵(State Transition Matrix),拓展到所有状态可表示为式
其中
目标与回报
在强化学习中,智能体的目标是通过与环境的交互,学习一个最优策略,使得在每个状态下选择的动作能够最大化累积的奖励。这个累积的奖励通常被称为回报(Return),如式
表示从时间步
折扣因子一方面在数学上确保回报
当
此外,当前时步的回报
策略与价值
策略
策略 (
表示在状态
状态价值
状态价值函数(
举例来说,假设智能体处于一个
如果初始状态
动作价值
动作价值函数(
状态价值与动作价值的关系
状态价值函数和动作价值函数之间存在密切的关系,如式
换句话说,状态价值是对所有可能的动作价值的加权平均,而动作价值则是对特定动作的评价。
状态价值反映了策略本身的好坏,它不关心智能体在状态
有模型与无模型
在谈到有模型(
有模型的方法利用环境模型来进行规划和决策,通常包括动态规划(
无模型的方法则不依赖于环境模型,包括
预测与控制
预测(
控制(
复杂问题中通常需要同时解决预测和控制问题,即在学习最优策略的过程中,同时评估当前策略的好坏,从而不断改进策略,最终收敛到最优策略。
思考
强化学习所解决的问题一定要严格满足马尔可夫性质吗?请举例说明。
不一定。例如在围棋游戏场景中,不仅需要考虑当前棋子的位置,还需要考虑棋子的历史位置,因此不满足马尔可夫性质。但依然可以使用强化学习的方法进行求解,例如在
马尔可夫决策过程主要包含哪些要素?
马尔可夫决策
马尔可夫决策过程引入折扣因子
折扣因子
马尔可夫决策过程与金融科学中的马尔可夫链有什么区别与联系?
马尔可夫链是一个随机过程,其下一个状态只依赖于当前状态而不受历史状态的影响,即满足马尔可夫性质。马尔可夫链由状态空间、初始状态分布和状态转移概率矩阵组成。马尔可夫决策过程是一种基于马尔可夫链的决策模型,它包含了状态、行动、转移概率、奖励、值函数和策略等要素。马尔可夫决策过程中的状态和状态转移概率满足马尔可夫性质,但区别在于它还包括了行动、奖励、值函数和策略等要素,用于描述在给定状态下代理如何选择行动以获得最大的长期奖励。
有模型与免模型算法的区别?举一些相关的算法?
有模型算法在学习过程中使用环境模型,即环境的转移函数和奖励函数,来推断出最优策略。这种算法会先学习环境模型,然后使用模型来生成策略。因此,有模型算法需要对环境进行建模,需要先了解环境的转移函数和奖励函数,例如动态规划等算法。免模型算法不需要环境模型,而是直接通过试错来学习最优策略。这种算法会通过与环境的交互来学习策略,不需要先了解环境的转移函数和奖励函数。免模型算法可以直接从经验中学习,因此更加灵活,例如
举例说明预测与控制的区别与联系。
区别:预测任务主要是关注如何预测当前状态或动作的价值或概率分布等信息,而不涉及选择动作的问题;控制任务则是在预测的基础上,通过选择合适的动作来最大化累计奖励,即学习一个最优的策略。联系:预测任务是控制任务的基础,因为在控制任务中需要对当前状态或动作进行预测才能选择最优的动作;控制任务中的策略通常是根据预测任务中获得的状态或动作价值函数来得到的,因此预测任务对于学习最优策略是至关重要的。以赌博机问题为例,预测任务是估计每个赌博机的期望奖励(即价值函数),控制任务是选择最优的赌博机来最大化累计奖励。在预测任务中,我们可以使用多种算法来估计每个赌博机的期望奖励,如蒙特卡罗方法、时间差分方法等。在控制任务中,我们可以使用贪心策略或ε-贪心策略来选择赌博机,这些策略通常是根据预测任务中得到的每个赌博机的价值函数来确定的。因此,预测任务对于控制任务的实现至关重要。