策略梯度方法
策略参数化
基于策略梯度的方法首先需要将策略参数化,即直接将策略
然后,目标函数就可表示为
通常为了方便,会将梯度上升法转化为梯度下降法,即通过最小化目标函数的负值来更新参数
也就是说,只要能定义出目标函数
怎么定义关于策略的目标函数
基于轨迹推导
轨迹概率密度
智能体与环境交互过程中,首先环境会返回一个初始状态
这样完整的有限步数的交互过程,称为一个 回合(
② 参考自CS234,该词出现频率不算高,了解即可
为了计算轨迹产生的概率,我们可以先具体展开轨迹产生的路径。如图 1 所示,首先环境会从初始状态分布中采样出一个初始状态
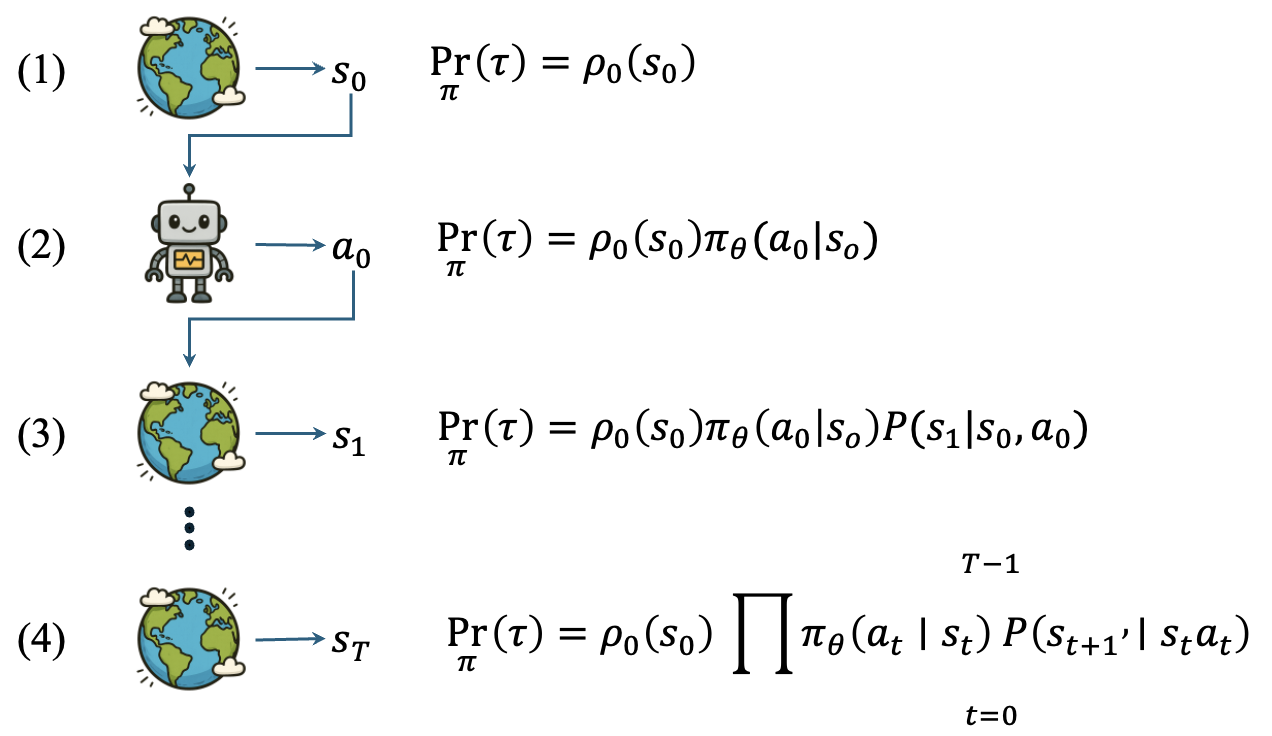
以此类推,可得完整轨迹的概率计算如式
可以看出,轨迹概率确实可以写成关于策略
给定策略
对数导数技巧
为了最大化目标函数
实际运用中为了方便,会将梯度上升法转化为梯度下降法,即通过最小化目标函数的负值来更新参数
但无论哪种方式,关键都是要计算梯度
其中
将式
根据式
由于环境的状态转移概率
将式
其中回报
将式
占用测度推导
回顾状态价值相关部分,设环境初始状态为
其中
根据贝尔曼期望方程(
这样一来,目标函数
乍看初始状态分布
因此,在计算梯度
平稳分布
在引入平稳分布概念之前,先来看一个例子。如图 2 所示,假设有一个简单的马尔可夫过程(
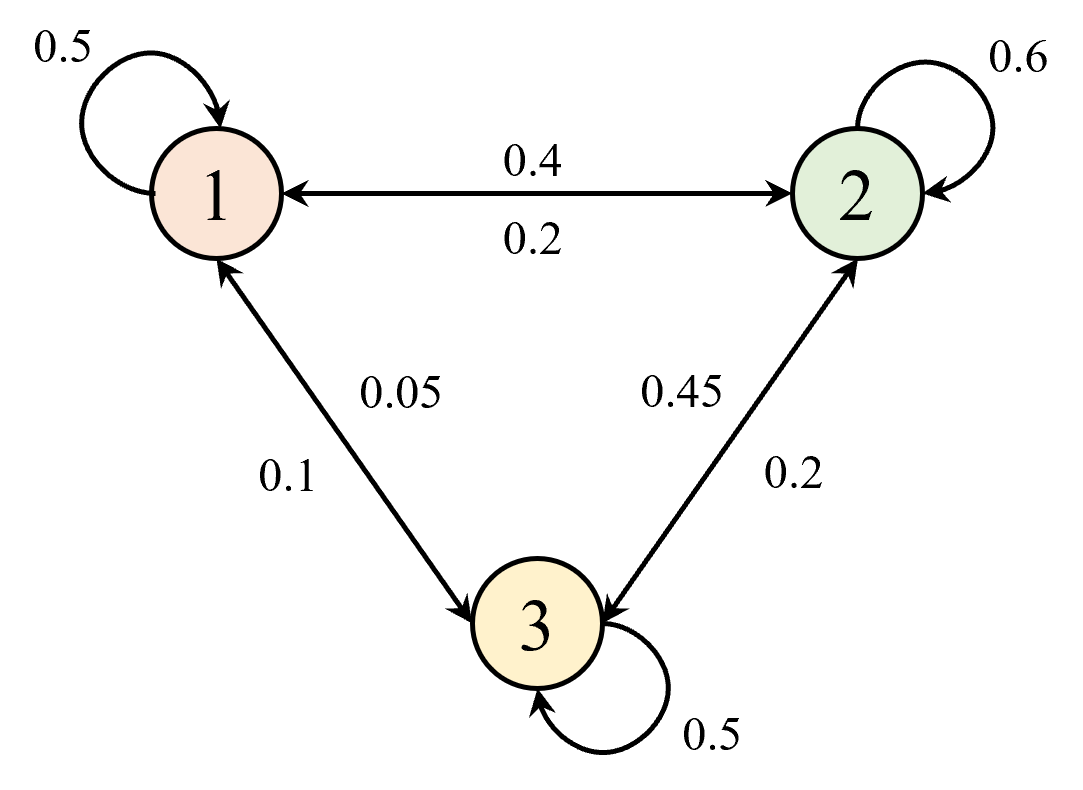
从图中可以该马尔可夫过程的状态转移矩阵
设初始状态分布为
同理,经过两次状态转移或者说两次状态迭代后,新的状态分布
那么经过多次状态转移或者说多次状态迭代后,状态分布会发生什么变化呢?我们可以通过编程来模拟一下,如代码 1 所示。
import numpy as np
pi_0 = np.array([[0.15,0.62,0.23]])
P = np.array([[0.5,0.4,0.1],[0.2,0.6,0.2],[0.05,0.45,0.5]])
for i in range(1,10+1):
pi_0 = pi_0.dot(P)
print(f"第{i}次迭代后状态分布为:{np.around(pi_0,3)}")
运行结果如代码 2 所示。
第1次迭代后状态分布为:[[0.21 0.536 0.254]]
第2次迭代后状态分布为:[[0.225 0.52 0.255]]
第3次迭代后状态分布为:[[0.229 0.517 0.254]]
第4次迭代后状态分布为:[[0.231 0.516 0.253]]
第5次迭代后状态分布为:[[0.231 0.516 0.253]]
第6次迭代后状态分布为:[[0.231 0.516 0.253]]
第7次迭代后状态分布为:[[0.232 0.516 0.253]]
第8次迭代后状态分布为:[[0.232 0.516 0.253]]
第9次迭代后状态分布为:[[0.232 0.516 0.253]]
第10次迭代后状态分布为:[[0.232 0.516 0.253]]
可以看出,经过多次迭代后,状态分布逐渐趋于稳定,并最终收敛到一个固定的分布,即
第1次迭代后状态分布为:[[0.462 0.413 0.125]]
第2次迭代后状态分布为:[[0.32 0.489 0.191]]
第3次迭代后状态分布为:[[0.267 0.507 0.225]]
第4次迭代后状态分布为:[[0.246 0.513 0.241]]
第5次迭代后状态分布为:[[0.238 0.515 0.248]]
第6次迭代后状态分布为:[[0.234 0.515 0.251]]
第7次迭代后状态分布为:[[0.233 0.516 0.252]]
第8次迭代后状态分布为:[[0.232 0.516 0.252]]
第9次迭代后状态分布为:[[0.232 0.516 0.252]]
第10次迭代后状态分布为:[[0.232 0.516 0.253]]
也就是说,无论初始状态分布如何变化,经过多次迭代后,状态分布最终都会收敛到同一个固定的分布
简单来说,它描述了系统在长期运行后,处于各状态的概率分布。需要注意的是,平稳分布的存在是有前提条件的,必须是遍历(
平稳分布的存在性推导
本节内容主要从数学上来推导说明为什么平稳分布是存在的,换句话说为什么马尔可夫过程在长期运行后会收敛到一个固定的分布,即“不动点”, 如式
用矩阵的语言来表示,就是转移算子
两边转置,并结合矩阵转置的性质
由于状态转移矩阵本身就是一个特殊的矩阵,即随机矩阵(
有时也写作式
用矩阵语言来表示,就是每一列的元素和为1,且每个元素都非负,如式
回顾线性代数相关知识,对于方阵
回到式
目标函数梯度
回顾式
写成期望的形式,如式
同样地,只要能求出目标函数的梯度,就能利用梯度上升法来更新参数
其中近似符号
目标函数梯度的推导
先看价值函数部分,如式
这样就得到了一个迭代公式,如式
其中
其中:
- 当
时, - 当
时, - 以此类推,可得
为了简化,设
接下来,回到目标函数梯度
至此,目标函数梯度
两种推导方式的等价性
对比基于轨迹概率密度推导出的目标函数和基于状态值函数推导出的目标函数, 会发现两者形式上是类似的,区别在于一个是从时间步
首先,回顾状态值函数的策略梯度表达式,如式
接下来,展开期望的定义,如式
再将状态值函数
将式
接下来,将状态分布
将式
策略梯度通用表达式
在 GAE 论文 ③ 中,提出了一种更为通用的策略梯度表达式,如式
其中
:表示整条轨迹的累计奖励 :表示动作 之后的累计奖励 : 表示折扣回报,也是后面要讲的 算法形式 :引入基线函数 来减少方差 :动作价值函数 :优势函数,表示动作相对于平均水平的好坏 :时序差分误差( )
公式
策略函数建模
前面讲到,在策略梯度方法中,策略函数
离散动作空间
对于离散动作空间,例如动作集合
然而,神经网络一般不能直接输出满足概率分布要求的向量,因此需要对神经网络的输出进行转换,转换的方式必须是可微分的,以便能够计算梯度并进行优化。为此,可以采用软最大化(
其中 logits 。
对应的梯度计算如式
再代入到前面推导出的目标函数梯度(例如式
注意到,由于使用了指数函数,如果某个动作的得分
为了解决这个问题,通常会在计算
为帮助理解,我们使用Numpy模块实现一个
import numpy as np
# softmax 函数
def softmax(z):
z = np.array(z)
e = np.exp(z - np.max(z))
return e / e.sum()
# softmax 函数 梯度
def softmax_grad(y):
# 输入 y 是 softmax 输出向量
return np.diag(y) - np.outer(y, y)
# logits -> 概率
logits = [2.0, 1.0, 0.1]
probs = softmax(logits)
# 从 Categorical 分布中采样动作
action = np.random.choice(len(probs), p=probs)
# 对数概率
log_prob = np.log(probs[action])
print(f"动作索引: {action}")
print(f"动作概率: {probs[action]:.3f}")
print(f"log π(a|s): {log_prob:.3f}")
运行结果如代码 5 所示。
动作索引: 0
动作概率: 0.659
log π(a|s): -0.417
接下来,我们使用PyTorch模块实现一个基于
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
# 定义策略网络
class PolicyNetwork(nn.Module):
def __init__(self, state_dim, action_dim):
super(PolicyNetwork, self).__init__()
self.fc = nn.Linear(state_dim, action_dim)
def forward(self, x):
return F.softmax(self.fc(x), dim=-1)
# 创建策略网络实例
state_dim = 4 # 状态维度
action_dim = 3 # 动作维度
policy_net = PolicyNetwork(state_dim, action_dim)
optimizer = optim.Adam(policy_net.parameters(), lr=0.01)
# 示例状态输入
state = torch.FloatTensor([1.0, 0.5, -0.5, 2.0])
# 前向传播计算动作概率
action_probs = policy_net(state)
# 从动作概率中采样动作
action_dist = torch.distributions.Categorical(action_probs)
action = action_dist.sample()
log_prob = action_dist.log_prob(action)
# 假设一个示例回报
reward = torch.FloatTensor([1.0])
# 计算损失(负的策略梯度)
loss = -log_prob * reward
# 反向传播计算梯度
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f"动作索引: {action.item()}")
print(f"动作概率: {action_probs[action].item():.3f}")
print(f"log π(a|s): {log_prob.item():.3f}")
运行结果如代码 7 所示。
动作索引: 2
动作概率: 0.123
log π(a|s): -2.095
连续动作空间
连续动作空间的策略建模通常使用高斯分布(
标量高斯分布
在标量高斯分布中,需要将均值
对应的策略函数如式
对应的概率公式,如式
利用偏微分,分别求出对
对于
其中由于
向量高斯分布
对于多维连续动作空间,例如
相应地,策略函数如式
其中
再求梯度,如式
可以看出,式
为帮助理解,同样使用 Numpy 模块来实现高斯分布的采样和梯度求解,如代码 8 所示。
import numpy as np
def gaussian_policy_and_grads(mu, log_std):
"""
mu, log_std: np.ndarray, 形状 [B, d] 或 [d] 或标量。
返回:
a: 采样动作 a ~ N(mu, σ²)
logp: [B] 或标量,log π(a|s)
dmu: ∂logπ/∂μ
dlogstd: ∂logπ/∂logσ
"""
mu = np.asarray(mu)
log_std = np.asarray(log_std)
std = np.exp(log_std)
# 1️⃣ 采样动作 (重参数化技巧)
eps = np.random.randn(*mu.shape) # ε ~ N(0, I)
a = mu + std * eps # a = μ + σ·ε
# 2️⃣ 计算 log π(a|s)
quad = ((a - mu) / std) ** 2
logp_dims = -0.5 * (quad + 2 * log_std + np.log(2 * np.pi))
logp = np.sum(logp_dims, axis=-1) if logp_dims.ndim > 0 else logp_dims
# 3️⃣ 计算梯度
var = std ** 2
dmu = (a - mu) / var # ∂logπ/∂μ
dlogstd = ((a - mu) ** 2 / var) - 1.0 # ∂logπ/∂logσ
return a, logp, dmu, dlogstd
# ==== 示例 ====
# 批量 = 3, 动作维度 = 2
mu = np.array([[0.3, -0.1],
[0.8, 0.1],
[0.1, -0.1]])
log_std = np.array([[-0.7, -0.7],
[-0.7, -0.7],
[-0.7, -0.7]]) # log σ ≈ -0.7 → σ ≈ 0.496
a, logp, dmu, dlogstd = gaussian_policy_and_grads(mu, log_std)
print("采样动作 a:\n", np.round(a, 3))
print("log π(a|s):\n", np.round(logp, 4))
print("∂logπ/∂μ:\n", np.round(dmu, 3))
print("∂logπ/∂logσ:\n", np.round(dlogstd, 3))
运行结果如代码 9 所示。
采样动作 a:
[[ 0.231 -0.317]
[ 0.991 0.122]
[ 0.067 0.118]]
log π(a|s):
[-1.1136 -1.0822 -1.1314]
∂logπ/∂μ:
[[ 0.278 1.111]
[-0.786 -0.183]
[ 0.134 -0.914]]
∂logπ/∂logσ:
[[-0.923 -0.198]
[-0.382 -0.932]
[-0.928 -0.507]]
接下来,我们使用 PyTorch 模块来实现一个基于高斯分布的策略网络,并计算对应的梯度,如代码 10 所示。
import torch
import torch.nn as nn
import torch.nn.functional as F
class GaussianPolicy(nn.Module):
def __init__(self, state_dim, action_dim):
super().__init__()
self.fc1 = nn.Linear(state_dim, 128)
self.fc_mu = nn.Linear(128, action_dim)
self.fc_logstd = nn.Linear(128, action_dim)
def forward(self, state):
x = F.relu(self.fc1(state))
mu = self.fc_mu(x)
log_std = self.fc_logstd(x).clamp(-20, 2) # 避免数值不稳定
std = log_std.exp()
return mu, std
def get_action(self, state):
mu, std = self.forward(state)
dist = torch.distributions.Normal(mu, std)
action = dist.sample() # 采样动作
log_prob = dist.log_prob(action).sum(dim=-1)
return action, log_prob
REINFORCE 算法
使用蒙特卡洛方法来估计梯度,即通过多次采样轨迹
在实际应用中,

小结
本文首先介绍策略参数化的基本概念,即通过参数化策略函数
然后通过基于轨迹密度概率和占用测度两种方式推导出策略梯度的目标函数及梯度表达式,分别为式
在占用测度推导中,读者须谨记平稳分布在强化学习问题中是一定存在的,即随着迭代次数增加,状态分布会收敛到一个固定的分布,这个分布与初始状态分布无关。
接着,介绍了如何对策略函数进行建模,分别针对离散动作空间和连续动作空间,使用多项式分布和高斯分布进行建模,对于入门者来说,只需掌握相关的公式形式以及代码实现即可,不需要深入理解对应分布的梯度计算细节。
然后,介绍了
思考
为什么使用 Softmax 函数来建模离散动作空间的策略?
主要考虑以下因素:
- 该函数是可微分的,这是计算梯度的必要条件
- 一方面可以确保概率为正数,即对于任意神经网络的输出
, ,另一方面可以将任意实数映射到 之间,并且所有动作的概率之和为 1,符合概率分布的要求 - 指数函数能够放大差距,如果某个动作的得分
较高,对应的 就会成倍增加,从而让策略更倾向于“高分动作”。这样一来,策略能够更有效地利用当前的知识,选择更优的动作,降低无意义的探索,让回报更加稳定。然而这一点并非总是好事,过度放大差距可能导致探索不足,容易收敛到局部最优。因此实际运用时需要辩证看待。
REINFORCE 算法是无偏的吗?为什么?
REINFORCE 算法是无偏的,因为它使用了蒙特卡洛方法来估计策略梯度,所得到的梯度估计是对真实梯度的无偏估计。然而,由于使用了采样方法,估计的方差可能较大,这可能会影响学习的稳定性和效率。核心思想是直接对策略进行参数化,并通过梯度上升法来优化策略参数,从而最大化预期回报。
如何改进 REINFORCE 算法以提高样本效率?
可以通过以下几种方法来改进 REINFORCE 算法以提高样本效率: 1) 使用基线函数来减少梯度估计的方差;2) 采用时间差分(TD)方法来替代蒙特卡洛估计,从而减少对完整轨迹的依赖;3) 使用经验回放(Experience Replay)技术来重用过去的经验数据;4) 结合价值函数近似方法,如 Actor-Critic 方法,以同时学习策略和价值函数。基本思想是通过参数化策略,并利用梯度上升法来优化策略参数,从而最大化预期回报。核心思想是通过参数化策略,并利用梯度上升法来优化策略参数,从而最大化预期回报。
基于价值和基于策略的算法各有什么优缺点?
前者的优点有:简单易用:通常只需要学习一个值函数,往往收敛性也会更好。保守更新:更新策略通常是隐式的,通过更新价值函数来间接地改变策略,这使得学习可能更加稳定。缺点有:受限于离散动作;可能存在多个等价最优策略:当存在多个等效的最优策略时,基于价值的方法可能会在它们之间不停地切换。后者的优点有:直接优化策略:由于这些算法直接操作在策略上,所以它们可能更容易找到更好的策略;适用于连续动作空间;更高效的探索:通过调整策略的随机性,基于策略的方法可能会有更高效的探索策略。缺点有:高方差:策略更新可能会带来高方差,这可能导致需要更多的样本来学习。可能会收敛到局部最优:基于策略的方法可能会收敛到策略的局部最优,而不是全局最优,且收敛较缓慢。在实践中,还存在结合了基于价值和基于策略方法的算法,即
确定性策略与随机性策略的区别?
对于同一个状态,确定性策略会给出一个明确的、固定的动作,随机性策略则会为每一个可能的动作(legal action)提供一个概率分布。前者在训练中往往需要额外的探索策略,后者则只需要调整动作概率。但前者相对更容易优化,因为不需要考虑所有可能的动作,但也容易受到噪声的影响。后者则相对更加鲁棒,适用面更广,因为很多的实际问题中,我们往往无法得到一个确定的最优策略,而只能得到一个概率分布,尤其是在博弈场景中。
马尔可夫平稳分布需要满足什么条件?
状态连通性:从任何一个状态可以在有限的步数内到达另一个状态;非周期性:由于马尔可夫链需要收敛,那么就一定不能是周期性的。