DDPG 算法实战
同之前章节一样,本书在实战中将演示一些核心的代码,完整的代码请参考
算法流程
如图

图 1: DDPG 算法流程
定义模型
如代码
import torch
import torch.nn as nn
import torch.nn.functional as F
class Actor(nn.Module):
def __init__(self, state_dim, action_dim, hidden_dim = 256, init_w=3e-3):
super(Actor, self).__init__()
self.linear1 = nn.Linear(state_dim, hidden_dim)
self.linear2 = nn.Linear(hidden_dim, hidden_dim)
self.linear3 = nn.Linear(hidden_dim, action_dim)
self.linear3.weight.data.uniform_(-init_w, init_w)
self.linear3.bias.data.uniform_(-init_w, init_w)
def forward(self, x):
x = F.relu(self.linear1(x))
x = F.relu(self.linear2(x))
x = torch.tanh(self.linear3(x)) # 输入0到1之间的值
return x
class Critic(nn.Module):
def __init__(self, state_dim, action_dim, hidden_dim=256, init_w=3e-3):
super(Critic, self).__init__()
self.linear1 = nn.Linear(state_dim + action_dim, hidden_dim)
self.linear2 = nn.Linear(hidden_dim, hidden_dim)
self.linear3 = nn.Linear(hidden_dim, 1)
# 随机初始化为较小的值
self.linear3.weight.data.uniform_(-init_w, init_w)
self.linear3.bias.data.uniform_(-init_w, init_w)
def forward(self, state, action):
# 按维数1拼接
x = torch.cat([state, action], 1)
x = F.relu(self.linear1(x))
x = F.relu(self.linear2(x))
x = self.linear3(x)
return x
动作采样
由于
class Agent:
def __init__(self):
pass
def sample_action(self, state):
state = torch.FloatTensor(state).unsqueeze(0).to(self.device)
action = self.actor(state)
return action.detach().cpu().numpy()[0, 0]
策略更新
如代码
class Agent:
def __init__(self):
pass
def update(self):
# 从经验回放中中随机采样一个批量的样本
state, action, reward, next_state, done = self.memory.sample(self.batch_size)
actor_loss = self.critic(state, self.actor(state))
actor_loss = - actor_loss.mean()
next_action = self.target_actor(next_state)
target_value = self.target_critic(next_state, next_action.detach())
expected_value = reward + (1.0 - done) * self.gamma * target_value
expected_value = torch.clamp(expected_value, -np.inf, np.inf)
actual_value = self.critic(state, action)
critic_loss = nn.MSELoss()(actual_value, expected_value.detach())
self.actor_optimizer.zero_grad()
actor_loss.backward()
self.actor_optimizer.step()
self.critic_optimizer.zero_grad()
critic_loss.backward()
self.critic_optimizer.step()
# 各自目标网络的参数软更新
for target_param, param in zip(self.target_critic.parameters(), self.critic.parameters()):
target_param.data.copy_(
target_param.data * (1.0 - self.tau) +
param.data * self.tau
)
for target_param, param in zip(self.target_actor.parameters(), self.actor.parameters()):
target_param.data.copy_(
target_param.data * (1.0 - self.tau) +
param.data * self.tau
)
核心代码到这里全部实现了,我们展示一下训练效果,如图
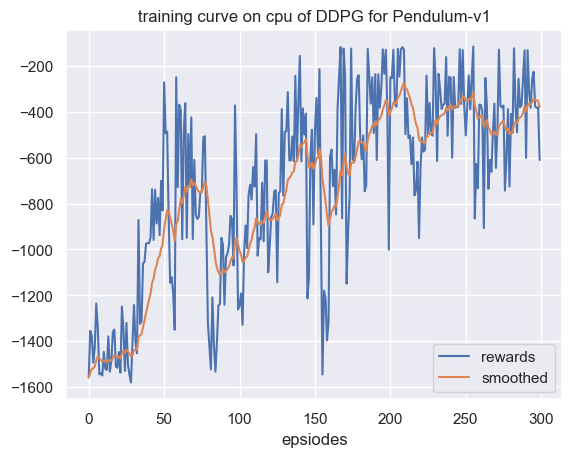
图 2: Pendulum 环境 DDPG 算法训练曲线
这里我们使用了一个具有连续动作空间的环境
图 3: Pendulum 环境演示