Double DQN 算法实战
# 计算当前网络的Q值,即Q(s_t+1|a)
next_q_value_batch = self.policy_net(next_state_batch)
# 计算目标网络的Q值,即Q'(s_t+1|a)
next_target_value_batch = self.target_net(next_state_batch)
# 计算 Q'(s_t+1|a=argmax Q(s_t+1|a))
next_target_q_value_batch = next_target_value_batch.gather(1, torch.max(next_q_value_batch, 1)[1].unsqueeze(1))
最后与
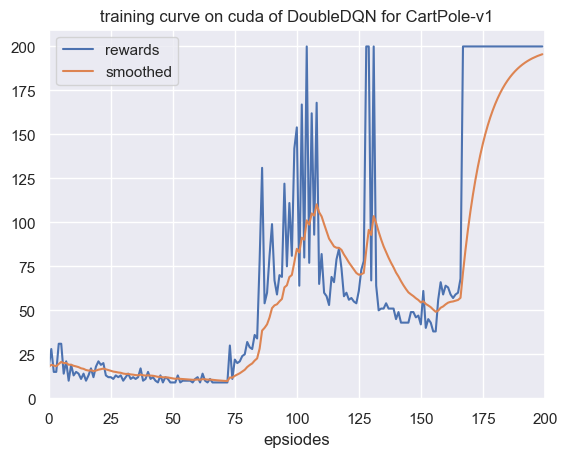
图 1
与