DQN 算法实战
请读者再次注意,本书中所有的实战仅提供核心内容的代码以及说明,完整的代码请读者参考本书对应的
算法流程
如图 1 所示,

定义模型
首先是定义模型,就是定义两个神经网路,即当前网络和目标网络,由于这两个网络结构相同,这里我们只用一个
class MLP(nn.Module): # 所有网络必须继承 nn.Module 类,这是 PyTorch 的特性
def __init__(self, input_dim,output_dim,hidden_dim=128):
super(MLP, self).__init__()
# 定义网络的层,这里都是线性层
self.fc1 = nn.Linear(input_dim, hidden_dim) # 输入层
self.fc2 = nn.Linear(hidden_dim,hidden_dim) # 隐藏层
self.fc3 = nn.Linear(hidden_dim, output_dim) # 输出层
def forward(self, x):
# 各层对应的激活函数
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
return self.fc3(x) # 输出层不需要激活函数
这里我们定义了一个三层的全连接网络,输入维度就是状态数,输出维度就是动作数,中间的隐藏层采用最常用的
经验回放
经验回放的功能比较简单,主要实现缓存样本和取出样本等两个功能,如代码 2 所示。
class ReplayBuffer:
def __init__(self, capacity):
self.capacity = capacity # 经验回放的容量
self.buffer = [] # 用列表存放样本
self.position = 0 # 样本下标,便于覆盖旧样本
def push(self, state, action, reward, next_state, done):
''' 缓存样本
'''
if len(self.buffer) < self.capacity: # 如果样本数小于容量
self.buffer.append(None)
self.buffer[self.position] = (state, action, reward, next_state, done)
self.position = (self.position + 1) % self.capacity
def sample(self, batch_size):
''' 取出样本,即采样
'''
batch = random.sample(self.buffer, batch_size) # 随机采出小批量转移
state, action, reward, next_state, done = zip(*batch) # 解压成状态,动作等
return state, action, reward, next_state, done
def __len__(self):
''' 返回当前样本数
'''
return len(self.buffer)
当然,经验回放的实现方式其实有很多,这里只是一个参考。在
定义智能体
智能体即策略的载体,因此有的时候也会称为策略。智能体的主要功能就是根据当前状态输出动作和更新策略,分别跟伪代码中的交互采样和模型更新过程相对应。我们会把所有的模块比如网络模型等都封装到智能体中,这样更符合伪代码的逻辑。而在
如代码 3 所示,两个网络就是前面所定义的全连接网络,输入为状态维度,输出则是动作维度。这里我们还定义了一个优化器,用来更新网络参数。在
class Agent:
def __init__(self):
# 定义当前网络
self.policy_net = MLP(state_dim,action_dim).to(device)
# 定义目标网络
self.target_net = MLP(state_dim,action_dim).to(device)
# 将当前网络参数复制到目标网络中
self.target_net.load_state_dict(self.policy_net.state_dict())
# 定义优化器
self.optimizer = optim.Adam(self.policy_net.parameters(), lr=learning_rate)
# 经验回放
self.memory = ReplayBuffer(buffer_size)
self.sample_count = 0 # 记录采样步数
def sample_action(self,state):
''' 采样动作,主要用于训练
'''
self.sample_count += 1
# epsilon 随着采样步数衰减
self.epsilon = self.epsilon_end + (self.epsilon_start - self.epsilon_end) * math.exp(-1. * self.sample_count / self.epsilon_decay)
if random.random() > self.epsilon:
with torch.no_grad(): # 不使用梯度
state = torch.tensor(np.array(state), device=self.device, dtype=torch.float32).unsqueeze(dim=0)
q_values = self.policy_net(state)
action = q_values.max(1)[1].item() # choose action corresponding to the maximum q value
else:
action = random.randrange(self.action_dim)
def predict_action(self,state):
''' 预测动作,主要用于测试
'''
with torch.no_grad():
state = torch.tensor(np.array(state), device=self.device, dtype=torch.float32).unsqueeze(dim=0)
q_values = self.policy_net(state)
action = q_values.max(1)[1].item() # choose action corresponding to the maximum q value
return action
def update(self):
pass
<div align="center">
<img width="400" src={require("./figs/a2c_CartPole_training.png").default}/>
</div>
<div align="center">图 1: CartPole 环境 A2C 算法训练曲线</div>
首先由于我们是小批量随机梯度下降,所以当经验回放不满足批大小时选择不更新,这实际上是工程性问题。然后在更新时我们取出样本,并转换成
定义环境
由于我们在

① 官网环境介绍:https://gymnasium.farama.org/environments/classic_control/cart_pole/
环境的状态数是 CliffWalking-v0 环境(状态数是 Cart Pole 的状态包括推车的位置(范围是
环境的奖励设置是每个时步下能维持杆不到就给一个
设置参数
定义好智能体和环境之后就可以开始设置参数了,如代码 5 所示。
self.epsilon_start = 0.95 # epsilon 起始值
self.epsilon_end = 0.01 # epsilon 终止值
self.epsilon_decay = 500 # epsilon 衰减率
self.gamma = 0.95 # 折扣因子
self.lr = 0.0001 # 学习率
self.buffer_size = 100000 # 经验回放容量
self.batch_size = 64 # 批大小
self.target_update = 4 # 目标网络更新频率
与
最后展示一下我们的训练曲线和测试曲线,分别如图 3 和 4 所示。
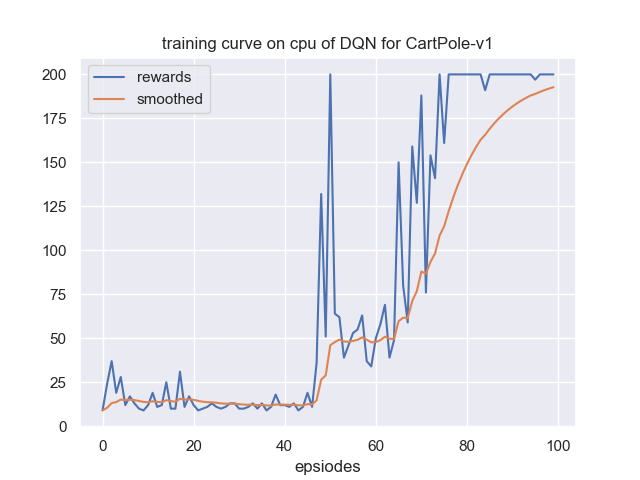
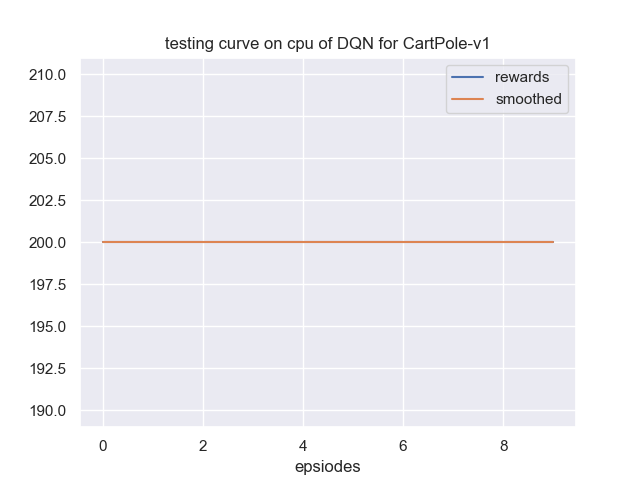
其中我们该环境每回合的最大步数是