Dueling DQN 算法实战
class DuelingQNetwork(nn.Module):
def __init__(self, state_dim, action_dim,hidden_dim=128):
super(DuelingQNetwork, self).__init__()
# 隐藏层
self.hidden_layer = nn.Sequential(
nn.Linear(state_dim, hidden_dim),
nn.ReLU()
)
# 优势层
self.advantage_layer = nn.Sequential(
nn.Linear(hidden_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, action_dim)
)
# 价值层
self.value_layer = nn.Sequential(
nn.Linear(hidden_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, 1)
)
def forward(self, state):
x = self.hidden_layer(state)
advantage = self.advantage_layer(x)
value = self.value_layer(x)
return value + advantage - advantage.mean() # Q(s,a) = V(s) + A(s,a) - mean(A(s,a))
最后我们展示一下它在
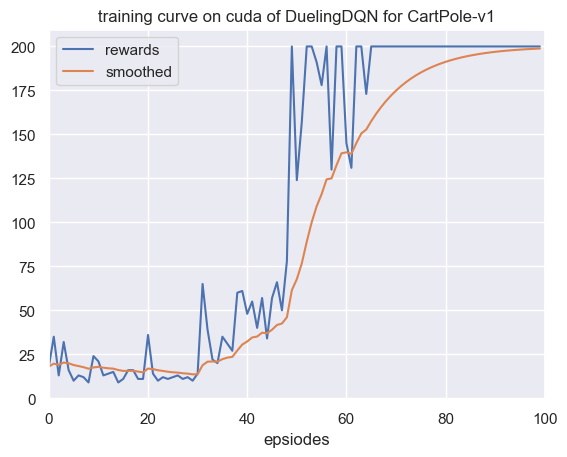
图 1
由于环境比较简单,暂时还看不出来