PPO 算法实战
算法流程
如图

图
算法更新
无论是连续动作空间还是离散动作空间,
def update(self):
# 采样样本
old_states, old_actions, old_log_probs, old_rewards, old_dones = self.memory.sample()
# 转换成tensor
old_states = torch.tensor(np.array(old_states), device=self.device, dtype=torch.float32)
old_actions = torch.tensor(np.array(old_actions), device=self.device, dtype=torch.float32)
old_log_probs = torch.tensor(old_log_probs, device=self.device, dtype=torch.float32)
# 计算回报
returns = []
discounted_sum = 0
for reward, done in zip(reversed(old_rewards), reversed(old_dones)):
if done:
discounted_sum = 0
discounted_sum = reward + (self.gamma * discounted_sum)
returns.insert(0, discounted_sum)
# 归一化
returns = torch.tensor(returns, device=self.device, dtype=torch.float32)
returns = (returns - returns.mean()) / (returns.std() + 1e-5) # 1e-5 to avoid division by zero
for _ in range(self.k_epochs): # 小批量随机下降
# 计算优势
values = self.critic(old_states)
advantage = returns - values.detach()
probs = self.actor(old_states)
dist = Categorical(probs)
new_probs = dist.log_prob(old_actions)
# 计算重要性权重
ratio = torch.exp(new_probs - old_log_probs) #
surr1 = ratio * advantage
surr2 = torch.clamp(ratio, 1 - self.eps_clip, 1 + self.eps_clip) * advantage
# 注意dist.entropy().mean()的目的是最大化策略熵
actor_loss = -torch.min(surr1, surr2).mean() + self.entropy_coef * dist.entropy().mean()
critic_loss = (returns - values).pow(2).mean()
# 反向传播
self.actor_optimizer.zero_grad()
self.critic_optimizer.zero_grad()
actor_loss.backward()
critic_loss.backward()
self.actor_optimizer.step()
self.critic_optimizer.step()
注意在更新时由于每次采样的轨迹往往包含的样本数较多,我们通过利用小批量随机下降将样本随机切分成若干个部分,然后一个批量一个批量地更新网络参数。最后我们展示算法在
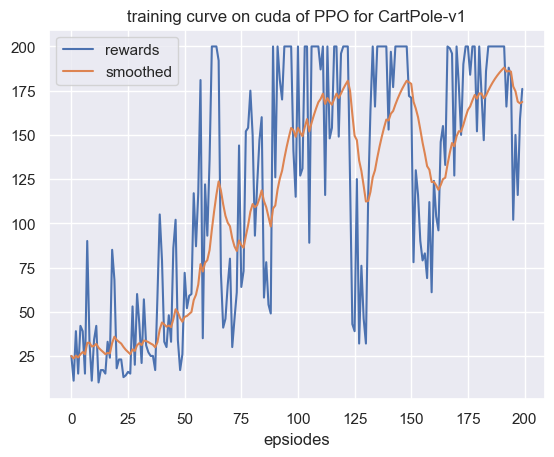
图
可以看到,与