第四章 Transformer 音乐大模型介绍与调用
4.1 MusicGen 部署及使用
MusicGen是Meta(原Facebook)于2023年发布的开源AI音乐创作工具。该项目采用单阶段自回归Transformer架构,能够根据文本描述或音频提示生成音乐。
1. 准备工作
在开始体验MusicGen模型之前,我们需要做好以下准备工作: * 可用的浏览器 * 本教程基于魔搭社区,请在 https://www.modelscope.cn 注册账号,完成邮箱验证后即可登录 接下来跟着教程走,带你跑通这个模型!
2. 步骤
A. 启动环境
魔搭平台为每一位用户准备了永久免费的CPU环境和36小时GPU环境的使用权。 * 在魔搭首页,点击“我的Notebook” * 右侧会出现两个免费实例,分别是CPU环境和GPU环境,可以选择预装的镜像,如果没有特别的要求,默认即可。 * 点击启动,静候两分钟后点击“查看Notebook”进入虚拟环境(注:以上步骤可能需要验证,按指引操作即可,本次将以CPU环境为例)。
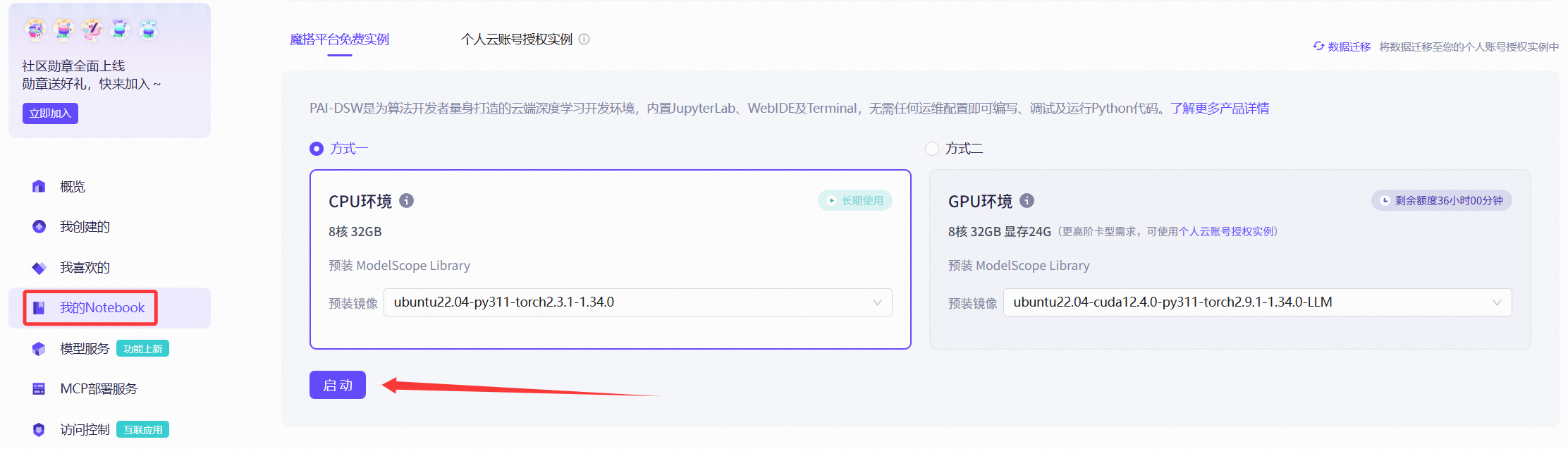
图4.2.1 启动环境
- 进入虚拟环境后,右侧是虚拟环境的文件列表,中间可以看到可使用的组件,本次需要用到的组件有Python 3与Terminal。
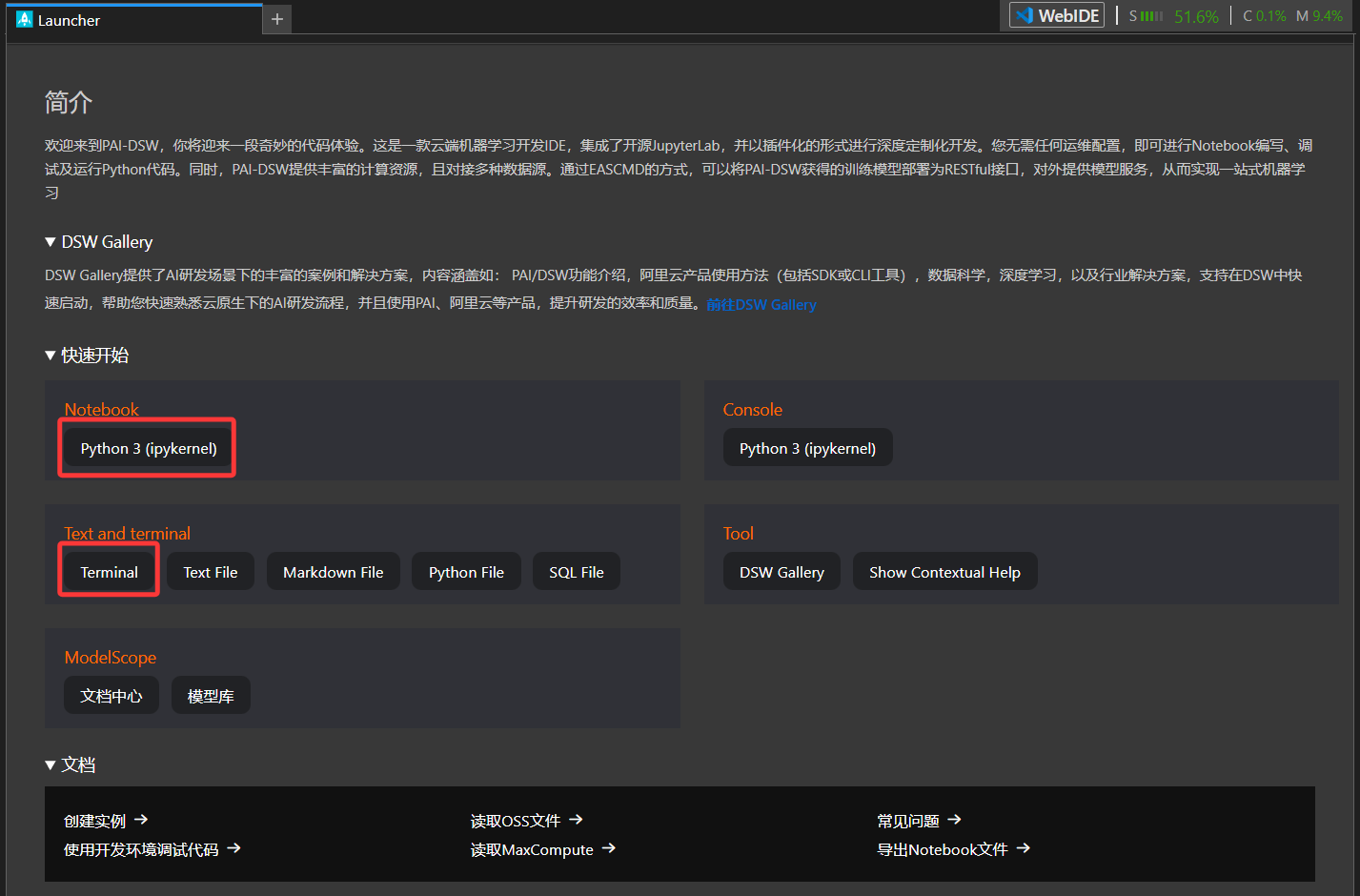
图4.2.2 启动环境
B. 选择模型
- 点击顶部菜单栏中的“模型库”。
- 在搜索界面键入“MusicGen”后点击搜索,这样就会弹出很多可用的模型库,本次选用的是“musicgen-large”的模型。
- 点击模型跳转到该模型的页面里,可以看到模型的简单介绍和使用方法,使用方法中附带了一些代码,可以直接点击代码块右上角的Notebook图标跳转至环境使用。
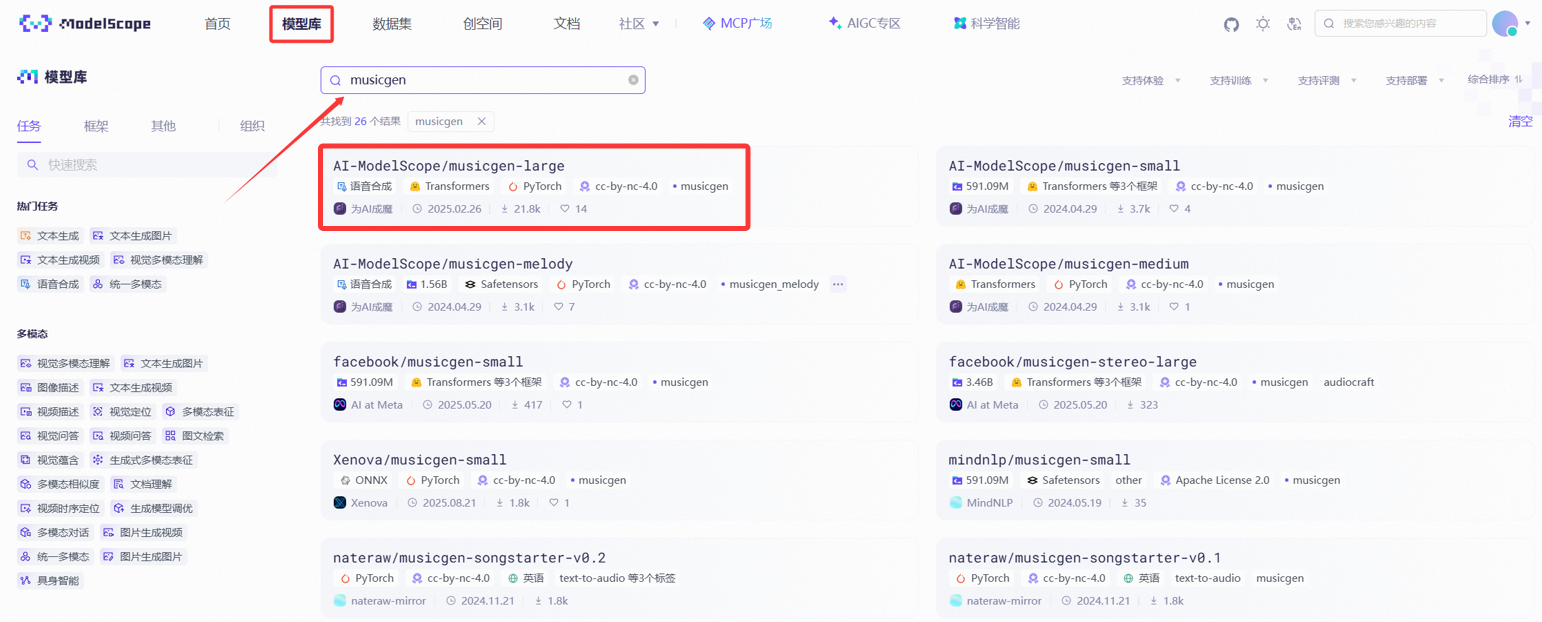
图4.2.3 选择模型
C. 使用模型
现在,让我们回到刚刚创建好的虚拟环境 * 首先点击Terminal,在Terminal中逐行运行下列代码。
pip install --upgrade pip
pip install --upgrade transformers scipy
- 接下来安装torch,首先给出的是CPU环境的安装命令,如果使用的是魔搭提供的GPU环境,则只需要在启用环境时选择torch>=2.6.0即可跳转到代码运行的步骤,甚至不需要切换核心。
pip install torch==2.6.0 torchvision==0.21.0 torchaudio==2.6.0 --index-url https://download.pytorch.org/whl/cpu
Looking in indexes: https://download.pytorch.org/whl/cpu
- 运行完毕后,关闭Terminal回到首页,点击Python 3,系统会自动为你创建一个ipynb文件。
- 点击右上角的“Python 3 (ipykernel)”切换核心至“Extension Examples”
- 运行下列代码,你可以修改prompt来生成你喜欢的音乐,修改tokens来控制生成音乐的长度,tokens的最大值为1500,这将会让你生成最长30s的音乐。
from modelscope import AutoProcessor, MusicgenForConditionalGeneration
processor = AutoProcessor.from_pretrained("facebook/musicgen-large")
model = MusicgenForConditionalGeneration.from_pretrained("facebook/musicgen-large")
prompt = "80s pop track with bassy drums and synth"
tokens = 256
inputs = processor(
text=prompt,
padding=True,
return_tensors="pt",
)
audio_values = model.generate(**inputs, max_new_tokens=tokens)
- 随后你将会看到右上角的CPU占用率变高,静候几分钟等他生成完毕。
- 运行结束后,按B或是上方的加号新建一个cell,运行以下代码,你就可以在这里听到刚刚生成的音乐了。
from IPython.display import Audio
sampling_rate = model.config.audio_encoder.sampling_rate
Audio(audio_values[0], rate=sampling_rate)
- 如果你想要保存,运行下列代码,它会在右侧的文件夹里生成一个name.wav文件,你可以右键点击它,随后点击下载来下载到你的电脑里
from scipy.io import wavfile
name = "musicgen_out"
wavfile.write("musicgen_out.wav", rate=sampling_rate, data=audio_values.numpy())