- Memory 的工作原理
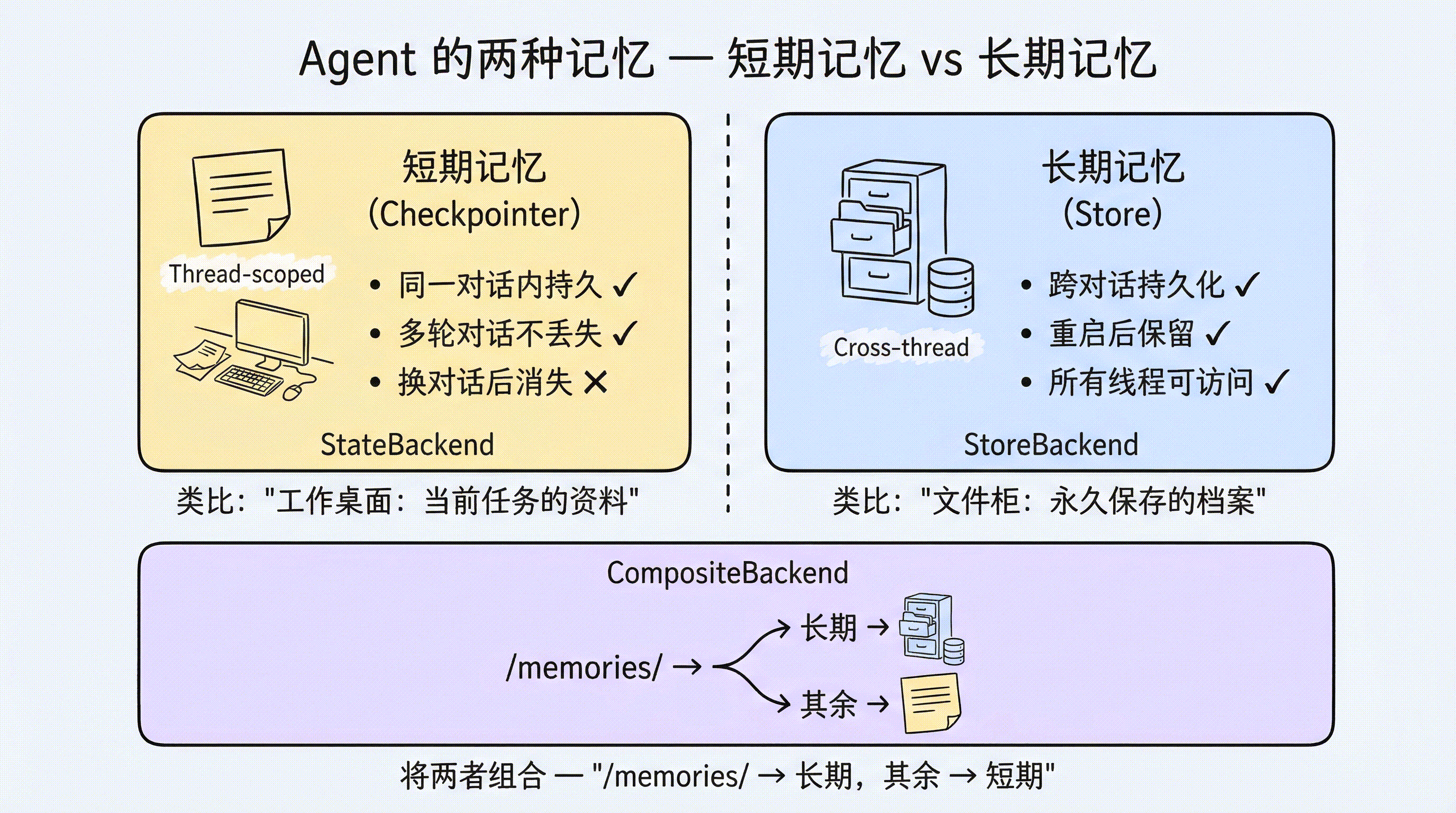
- Agent 的两种”记忆”
- 短期记忆:Thread-scoped
- 长期记忆:Cross-thread
- Checkpointer:短期记忆的基础
- 短期记忆的管理策略
- 进阶:自定义 AgentState
- CompositeBackend:长期记忆的核心方案
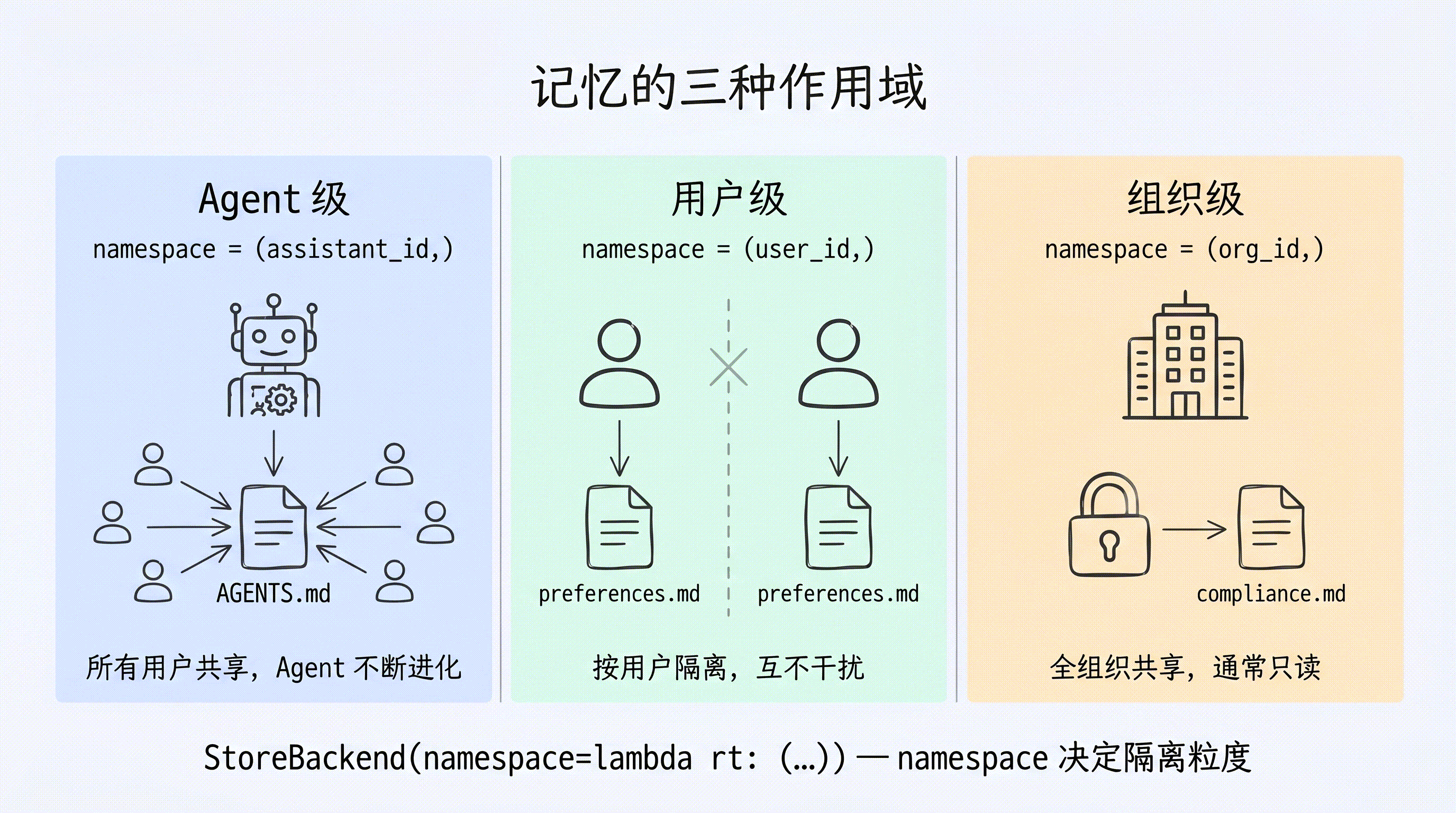
- 运行时身份与 namespace
- Agent 级记忆(Agent-scoped)
- 用户级记忆(User-scoped)
- 路径路由的工作方式
- 跨对话访问
- 四种实用场景
- 1. 用户偏好记忆
- 2. 自我改进的 Agent
- 3. 知识库累积
- 4. 研究项目持续推进
- 高级用法
- 记忆的六个维度
- 组织级记忆(Organization-level)
- 情景记忆(Episodic Memory)
- 后台记忆整合(Background Consolidation)
- 读写权限控制
- 并发写入
- 从开发到生产:Store 的升级路径
- 开发阶段:InMemoryStore
- 生产阶段:PostgresStore
- LangSmith 部署
- 文件存储格式与外部写入
- 最佳实践
- 1. 使用描述性路径
- 2. 用 memory= 声明而非 System Prompt
- 3. 按主题拆分文件
- 4. 多 Agent 部署隔离
- 5. 选择合适的 Store
- 6. 用 LangSmith 审计记忆写入
- 小结
长期记忆 — 让 Agent 拥有跨对话的记忆
在 GitHub 编辑此页前几章我们学习了 Deep Agents 的核心能力:虚拟文件系统、任务规划、子 Agent、Skills。但这些能力都有一个共同的局限——对话结束后,一切都丢失了。本章学习如何让 Agent 拥有跨对话、跨会话的持久化记忆。
Memory 的工作原理
Deep Agents 将记忆作为一等公民——Agent 以文件形式读写记忆,你用 Backend 控制这些文件存储在哪里。整个流程分三步:
- 指定记忆文件路径:通过
memory=参数传入文件路径列表,也可以通过skills=传入程序性记忆(Skills) - Agent 读取记忆:启动时加载到系统提示词,或对话过程中按需读取
- Agent 更新记忆(可选):学到新信息时,用内置的
edit_file工具更新记忆文件,变更持久化到下次对话
最常见的两种模式:Agent 级记忆(所有用户共享)和用户级记忆(按用户隔离)。
Agent 的两种”记忆”
人类有短期记忆和长期记忆——你记得今天的对话内容(短期),也记得你的名字和偏好(长期)。Agent 也一样,但需要不同的技术来实现。
短期记忆:Thread-scoped
在第 3 章我们学过,默认的 StateBackend 将文件存在 LangGraph 的 Agent State 中。这是一种短期记忆:
- 同一个对话线程(thread)内持久化
- 多轮对话不丢失(通过 Checkpointer 机制)
- 对话结束后消失——换一个 thread_id,之前的文件就没了
这就像你的工作桌面——当前任务的资料都摊在上面,但下班清理后就干净了。
长期记忆:Cross-thread
有些信息需要在不同对话间保留:
- 用户的偏好设置(“我喜欢简洁的代码风格”)
- 项目的背景知识(“我们用 React + TypeScript”)
- 累积的研究成果(多次对话中逐渐收集的资料)
- Agent 从反馈中学到的改进指令
这些信息不应该随着对话结束而消失。这就是长期记忆——它需要一种能跨线程持久化的存储方式。
Checkpointer:短期记忆的基础
在深入长期记忆之前,先理解 Checkpointer——它是 LangGraph 的短期记忆机制。
from langgraph.checkpoint.memory import MemorySaver
checkpointer = MemorySaver()
agent = create_deep_agent(
model=model,
checkpointer=checkpointer,
)
# 同一个 thread_id 内,Agent 记得之前的对话
config = {"configurable": {"thread_id": "conversation-001"}}
agent.invoke({"messages": [{"role": "user", "content": "我叫张三"}]}, config=config)
agent.invoke({"messages": [{"role": "user", "content": "我叫什么名字?"}]}, config=config)
# Agent 能回答"你叫张三"
# 换一个 thread_id,Agent 不记得了
config2 = {"configurable": {"thread_id": "conversation-002"}}
agent.invoke({"messages": [{"role": "user", "content": "我叫什么名字?"}]}, config=config2)
# Agent 不知道你是谁Checkpointer 的工作原理:
- 每次 Agent 执行完一步,自动保存当前状态(消息历史、文件系统状态、任务清单等)
- 下次调用时,如果
thread_id相同,自动恢复上次的状态 - 开发用
MemorySaver(内存,重启丢失),生产用PostgresSaver(数据库,持久化)
关键限制:Checkpointer 只在同一个 thread_id 内有效。不同的对话(不同 thread_id)之间,状态完全隔离。
短期记忆的管理策略
随着对话越来越长,消息历史可能超出 LLM 的上下文窗口。LangChain 提供了三种应对策略:
| 策略 | 做法 | 适用场景 |
|---|---|---|
| Trim(裁剪) | 只保留最近 N 条消息,丢弃更早的 | 简单粗暴,适合不需要历史上下文的场景 |
| Delete(删除) | 用 RemoveMessage 精确删除特定消息 | 需要选择性清理(如删除敏感信息) |
| Summarize(总结) | 用 LLM 将旧消息压缩为摘要 | 需要保留历史语义,是最推荐的方式 |
在 Deep Agents 中,Summarize 策略已经自动内置(第 3 章和第 4 章讲过的 SummarizationMiddleware)。当上下文达到模型窗口的 85% 时,自动触发总结。
如果你需要自定义裁剪逻辑,可以用 LangChain 的 @before_model 中间件:
from langchain.messages import RemoveMessage
from langgraph.graph.message import REMOVE_ALL_MESSAGES
from langchain.agents import AgentState
from langchain.agents.middleware import before_model
from langgraph.runtime import Runtime
@before_model
def trim_messages(state: AgentState, runtime: Runtime) -> dict | None:
"""只保留最近几条消息,防止上下文溢出。"""
messages = state["messages"]
if len(messages) <= 3:
return None # 不需要裁剪
first_msg = messages[0] # 保留第一条(通常是系统消息)
recent = messages[-3:] # 保留最近 3 条
return {
"messages": [
RemoveMessage(id=REMOVE_ALL_MESSAGES),
first_msg,
*recent,
]
}
# 在 create_agent 或 create_deep_agent 中通过 middleware 参数添加
agent = create_deep_agent(
model=model,
middleware=[trim_messages],
)
@before_model是 LangChain 的中间件装饰器——它在每次模型调用之前执行,可以修改传给模型的消息。对应地还有@after_model(模型调用之后执行)。这和第 4 章讲的中间件机制是同一套体系。
进阶:自定义 AgentState
LangChain 允许你扩展默认的 AgentState,添加自定义字段:
from langchain.agents import create_agent, AgentState
class CustomAgentState(AgentState):
user_id: str # 用户 ID
preferences: dict # 用户偏好
agent = create_agent(
model=model,
tools=[get_user_info],
state_schema=CustomAgentState,
checkpointer=checkpointer,
)
# 自定义状态可以在 invoke 时传入
result = agent.invoke(
{
"messages": [{"role": "user", "content": "你好"}],
"user_id": "user_123",
"preferences": {"theme": "dark"},
},
{"configurable": {"thread_id": "1"}},
)工具可以通过 ToolRuntime 读写这些自定义状态字段。ToolRuntime 是一个隐藏参数——模型看不到它,但工具可以用它访问 Agent 的完整状态:
from langchain.tools import tool, ToolRuntime
@tool
def get_user_info(runtime: ToolRuntime) -> str:
"""查询当前用户信息。"""
user_id = runtime.state["user_id"] # 从 Agent State 中读取
# 根据 user_id 查询用户信息
if user_id == "user_123":
return "用户:张三,VIP 会员,偏好简洁风格"
return "未知用户"
@tool
def update_preferences(new_theme: str, runtime: ToolRuntime):
"""更新用户偏好设置。"""
from langgraph.types import Command
from langchain.messages import ToolMessage
current_prefs = runtime.state.get("preferences", {})
current_prefs["theme"] = new_theme
# 通过 Command 写回 Agent State
return Command(update={
"preferences": current_prefs,
"messages": [
ToolMessage("偏好已更新", tool_call_id=runtime.tool_call_id)
]
})关键点:runtime.state 是读状态,Command(update={...}) 是写状态。这样工具不仅能返回结果给模型,还能直接修改 Agent 的短期记忆。
CompositeBackend:长期记忆的核心方案
第 3 章我们已经介绍过 CompositeBackend 的概念——不同路径路由到不同后端。现在我们用它来实现长期记忆。
运行时身份与 namespace
StoreBackend 通过 namespace 区分不同用户、Agent 或组织的数据。部署到 LangSmith / LangGraph Server 时,rt.server_info 可以提供 assistant_id 和登录用户信息;但在本地 agent.invoke() 或自托管环境中,server_info 可能为空。因此,示例代码最好先封装一层兜底逻辑:
from dataclasses import dataclass
@dataclass(frozen=True)
class MemoryContext:
user_id: str = "local-user"
org_id: str = "default-org"
def assistant_namespace(rt):
if rt.server_info:
return (rt.server_info.assistant_id,)
return ("local-agent",)
def user_namespace(rt):
if rt.server_info and rt.server_info.user:
return (rt.server_info.user.identity,)
user_id = getattr(rt.context, "user_id", "local-user")
return (user_id,)
def org_namespace(rt):
org_id = getattr(rt.context, "org_id", "default-org")
return (org_id,)本地调试时,可以通过 context_schema=MemoryContext 声明上下文,并在调用时传入:
agent.invoke(
{"messages": [{"role": "user", "content": "记住我喜欢简洁风格"}]},
context=MemoryContext(user_id="user-123", org_id="org-acme"),
config={"configurable": {"thread_id": "1"}},
)Agent 级记忆(Agent-scoped)
Agent 级记忆在所有用户间共享。Agent 通过每次对话积累知识、完善自身。关键在于 namespace 设为 (assistant_id,)——同一个 Agent 的所有对话读写同一份记忆:
from deepagents import create_deep_agent
from deepagents.backends import CompositeBackend, StateBackend, StoreBackend
agent = create_deep_agent(
model="google_genai:gemini-3.5-flash",
context_schema=MemoryContext,
memory=["/memories/AGENTS.md"], # 启动时自动加载的记忆文件
skills=["/skills/"], # 程序性记忆(Skills)
backend=CompositeBackend(
default=StateBackend(),
routes={
"/memories/": StoreBackend(
namespace=assistant_namespace,
),
"/skills/": StoreBackend(
namespace=assistant_namespace,
),
},
),
)
memory=参数接受一个路径列表,Agent 启动时会自动将这些文件内容加载到系统提示词中。这是 Deep Agents 0.5.0+ 的新特性——比手动在 system_prompt 里引导 Agent 读文件更优雅。
用户级记忆(User-scoped)
每个用户拥有独立的记忆文件。namespace 使用 (user_id,) 确保 A 用户的偏好不会泄露给 B 用户:
agent = create_deep_agent(
model="google_genai:gemini-3.5-flash",
context_schema=MemoryContext,
memory=["/memories/preferences.md"],
skills=["/skills/"],
backend=CompositeBackend(
default=StateBackend(),
routes={
"/memories/": StoreBackend(
namespace=user_namespace,
),
"/skills/": StoreBackend(
namespace=user_namespace,
),
},
),
)
路径路由的工作方式
配置好 CompositeBackend 后,Agent 的文件操作会根据路径自动路由:
# 临时文件 → StateBackend(对话结束后丢失)
write_file("/workspace/draft.txt", "草稿内容...")
write_file("/notes.txt", "临时笔记...")
# 持久化文件 → StoreBackend(跨对话保留)
write_file("/memories/preferences.md", "用户偏好:简洁代码风格")
write_file("/memories/project/tech-stack.md", "React + TypeScript")对 Agent 来说,操作方式完全一样——都是调用同样的 write_file、read_file 工具。区别只在于路径前缀:以 /memories/ 开头的文件会被持久化。
跨对话访问
长期记忆的核心价值在于跨线程可访问:
from langchain_core.utils.uuid import uuid7
# 对话 1:保存用户偏好
config1 = {"configurable": {"thread_id": str(uuid7())}}
agent.invoke({
"messages": [{"role": "user", "content": "记住我的偏好:代码注释用中文,变量名用英文"}]
}, config=config1)
# Agent 将偏好写入 /memories/preferences.md
# 对话 2(全新的对话!):读取之前保存的偏好
config2 = {"configurable": {"thread_id": str(uuid7())}}
agent.invoke({
"messages": [{"role": "user", "content": "帮我写一个排序函数"}]
}, config=config2)
# Agent 读取 /memories/preferences.md,用中文注释、英文变量名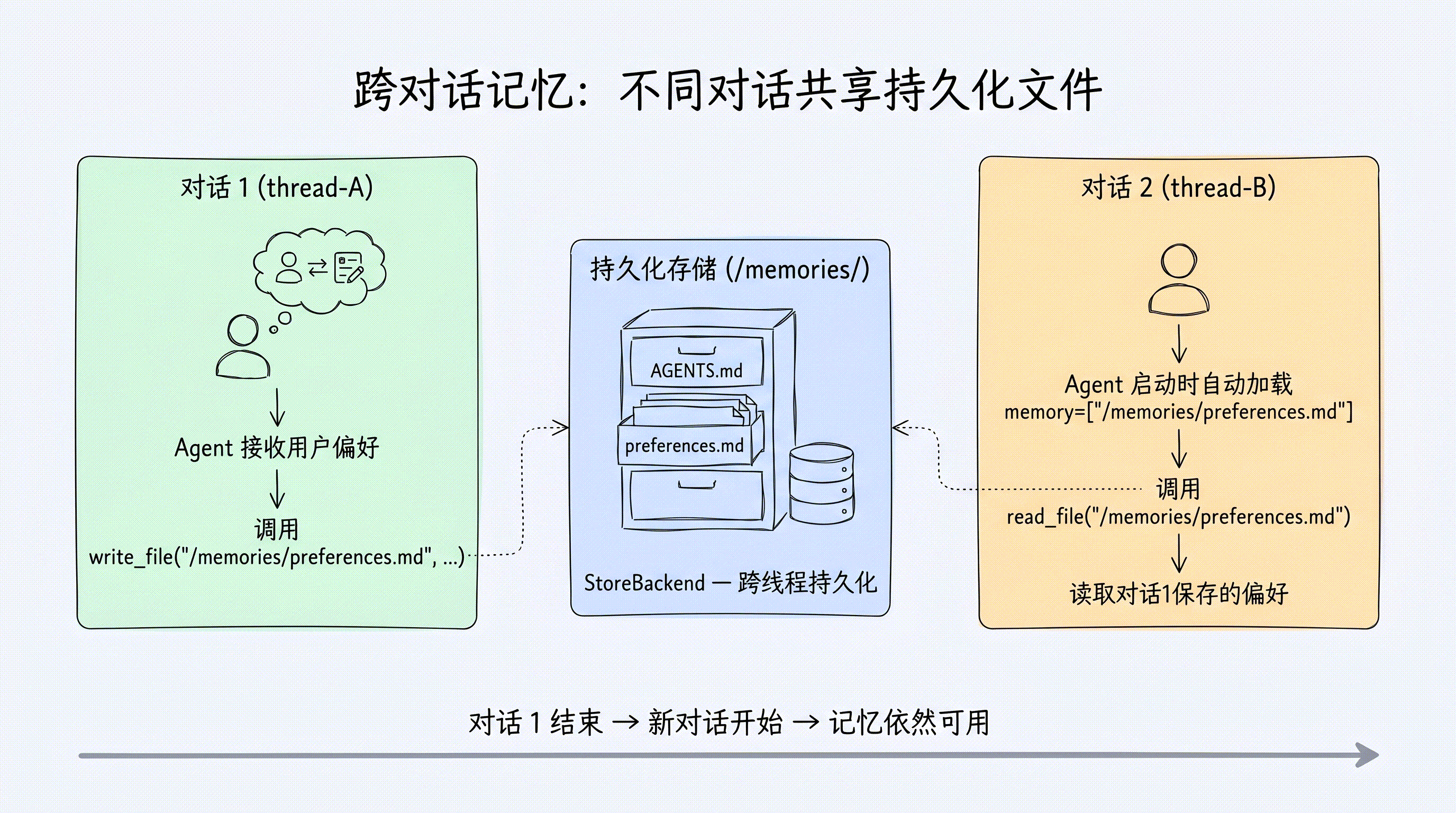
四种实用场景
1. 用户偏好记忆
最直接的用法——让 Agent 记住用户的个人偏好:
agent = create_deep_agent(
model="google_genai:gemini-3.5-flash",
context_schema=MemoryContext,
memory=["/memories/preferences.md"],
backend=CompositeBackend(
default=StateBackend(),
routes={
"/memories/": StoreBackend(
namespace=user_namespace,
),
},
),
)Agent 启动时自动加载 preferences.md,当用户告诉它新偏好时,用 edit_file 更新。
2. 自我改进的 Agent
Agent 可以根据用户反馈更新自己的指令:
agent = create_deep_agent(
model="google_genai:gemini-3.5-flash",
context_schema=MemoryContext,
memory=["/memories/AGENTS.md"],
backend=CompositeBackend(
default=StateBackend(),
routes={
"/memories/": StoreBackend(
namespace=assistant_namespace,
),
},
),
)随着时间推移,AGENTS.md 会不断积累从每次对话中学到的知识——Agent 发展出自己的专业能力、完善沟通风格,变得越来越”懂”这个领域。
3. 知识库累积
跨多次对话逐渐构建知识库:
# 对话 1:收集项目信息
# Agent 保存到 /memories/project/tech-stack.md
# 对话 2:补充更多信息
# Agent 读取已有内容,追加新的信息
# 对话 3:利用积累的知识
# Agent 基于完整的项目知识回答问题4. 研究项目持续推进
大型研究任务跨多次对话进行:
agent = create_deep_agent(
model="google_genai:gemini-3.5-flash",
context_schema=MemoryContext,
memory=[
"/memories/research/sources.md",
"/memories/research/notes.md",
"/memories/research/report.md",
],
backend=CompositeBackend(
default=StateBackend(),
routes={
"/memories/": StoreBackend(
namespace=user_namespace,
),
},
),
)Agent 启动时加载所有研究文件,每次对话结束后更新进度。多个 memory 路径让研究可以跨对话持续推进。
高级用法
记忆的六个维度
官方文档将记忆系统拆分为六个可独立配置的维度:
| 维度 | 核心问题 | 选项 |
|---|---|---|
| 持续时间 | 保留多久? | 短期(单次对话)/ 长期(跨对话) |
| 信息类型 | 记什么? | 情景记忆(过去经历)/ 程序性记忆(Skills)/ 语义记忆(事实) |
| 作用域 | 谁能看? | 用户级 / Agent 级 / 组织级 |
| 更新策略 | 何时写入? | 对话中(默认)/ 对话间(后台整合) |
| 检索方式 | 如何读取? | 启动加载(memory=)/ 按需读取(Skills) |
| 权限控制 | Agent 能写吗? | 读写(默认)/ 只读(共享策略) |
组织级记忆(Organization-level)
组织级记忆跨所有用户和 Agent 共享,通常设为只读以防止注入攻击:
agent = create_deep_agent(
model="google_genai:gemini-3.5-flash",
context_schema=MemoryContext,
memory=[
"/memories/preferences.md",
"/policies/compliance.md",
],
backend=CompositeBackend(
default=StateBackend(),
routes={
"/memories/": StoreBackend(
namespace=user_namespace,
),
"/policies/": StoreBackend(
namespace=org_namespace,
),
},
),
)从应用代码中填充组织级记忆:
from langgraph_sdk import get_client
from deepagents.backends.utils import create_file_data
client = get_client(url="<DEPLOYMENT_URL>")
await client.store.put_item(
(org_id,),
"/compliance.md",
create_file_data("""## 合规政策
- 不得披露内部定价
- 金融建议必须附加免责声明
"""),
)使用 Permissions 确保组织级记忆只读。
情景记忆(Episodic Memory)
情景记忆存储过去的完整经历——发生了什么、按什么顺序、结果如何。与语义记忆(事实和偏好)不同,情景记忆保留对话全貌,让 Agent 能回忆”如何解决问题”而不仅是”学到了什么”。
Deep Agents 的 Checkpointer 天然支持情景记忆——每次对话都被完整持久化。要让过去的对话变得可搜索,可以包装一个搜索工具:
from langgraph_sdk import get_client
from langchain.tools import tool, ToolRuntime
client = get_client(url="<DEPLOYMENT_URL>")
def current_user_id(runtime: ToolRuntime) -> str:
if runtime.server_info and runtime.server_info.user:
return runtime.server_info.user.identity
user_id = getattr(runtime.context, "user_id", None)
if user_id:
return user_id
raise ValueError("需要在 server_info 或 runtime.context 中提供 user_id")
@tool
async def search_past_conversations(query: str, runtime: ToolRuntime) -> str:
"""搜索过去的对话以获取相关上下文。"""
user_id = current_user_id(runtime)
threads = await client.threads.search(
metadata={"user_id": user_id},
limit=5,
)
results = []
for thread in threads:
history = await client.threads.get_history(thread_id=thread["thread_id"])
results.append(history)
return str(results)这对执行复杂多步任务的 Agent 尤为有用——比如代码 Agent 可以回溯上次调试过程,直接跳到可能的根因。
后台记忆整合(Background Consolidation)
默认情况下 Agent 在对话中实时写入记忆(热路径)。另一种模式是在对话间后台处理——部署一个独立的”整合 Agent”来审查最近对话、提取关键事实、合并到记忆存储中:
| 方式 | 优点 | 缺点 |
|---|---|---|
| 热路径(对话中写入) | 即时可用,对用户透明 | 增加延迟,Agent 需同时处理多任务 |
| 后台整合(对话间写入) | 无用户感知延迟,可跨多次对话综合 | 下次对话才可用,需额外 Agent |
整合 Agent 示例:
from datetime import datetime, timedelta, timezone
from deepagents import create_deep_agent
from langchain.tools import tool, ToolRuntime
from langgraph_sdk import get_client
sdk_client = get_client(url="<DEPLOYMENT_URL>")
def current_user_id(runtime: ToolRuntime) -> str:
if runtime.server_info and runtime.server_info.user:
return runtime.server_info.user.identity
user_id = getattr(runtime.context, "user_id", None)
if user_id:
return user_id
raise ValueError("需要在 server_info 或 runtime.context 中提供 user_id")
@tool
async def search_recent_conversations(query: str, runtime: ToolRuntime) -> str:
"""搜索过去 6 小时内该用户的对话。"""
user_id = current_user_id(runtime)
since = datetime.now(timezone.utc) - timedelta(hours=6)
threads = await sdk_client.threads.search(
metadata={"user_id": user_id},
updated_after=since.isoformat(),
limit=20,
)
conversations = []
for thread in threads:
history = await sdk_client.threads.get_history(thread_id=thread["thread_id"])
conversations.append(history["values"]["messages"])
return str(conversations)
consolidation_agent = create_deep_agent(
model="google_genai:gemini-3.5-flash",
system_prompt="审查最近对话并更新用户记忆文件。合并新事实、移除过期信息、保持简洁。",
tools=[search_recent_conversations],
)用 Cron Job 定时触发:
from langgraph_sdk import get_client
client = get_client(url="<DEPLOYMENT_URL>")
cron_job = await client.crons.create(
assistant_id="consolidation_agent",
schedule="0 */6 * * *", # 每 6 小时
input={"messages": [{"role": "user", "content": "整合最近的记忆。"}]},
)注意:Cron 间隔必须与整合 Agent 的回溯窗口匹配。上例每 6 小时运行,Agent 也回溯 6 小时——两者必须同步。
读写权限控制
| 权限 | 适用场景 | 实现方式 |
|---|---|---|
| 读写(默认) | 用户偏好、自我改进、Skills 学习 | Agent 通过 edit_file 更新 |
| 只读 | 组织策略、合规规则、共享知识库 | 应用代码写入 + Permissions 禁止 Agent 写入 |
安全注意事项:
- 如果一个用户能写入另一个用户读取的记忆,恶意用户可以注入指令
- 默认使用用户级 namespace
(user_id,),除非有明确理由需要共享 - 共享策略用只读模式(通过应用代码填充,不让 Agent 写入)
- 敏感路径写入前添加 Human-in-the-Loop 审批
并发写入
多个线程可以并行写入记忆,但对同一文件的并发写入可能产生 last-write-wins 冲突。对用户级记忆这种情况很少(用户通常一次只有一个活跃对话)。对 Agent 级或组织级记忆,考虑用后台整合来序列化写入,或将记忆按主题拆分成独立文件以减少冲突。
更稳妥的做法是把“写入热路径”和“整理冷路径”分开:
- 按主题拆文件:把
/memories/preferences.md、/memories/project/tech-stack.md、/memories/research/sources.md拆开,减少多个线程同时改同一文件的概率 - 追加式记录,再后台合并:对话中先写入
/memories/events/2026-xx-xx-thread-id.md这类追加日志,后台整合 Agent 定期去重、合并到稳定记忆文件 - 共享记忆只让后台任务写入:Agent 级、组织级记忆尽量只读;普通对话只提交候选更新,由后台整合任务串行审核后写入
- 敏感记忆加审批:涉及组织策略、安全规则、长期偏好覆盖时,用 Permissions 或 Human-in-the-Loop 阻止未经确认的直接覆盖
从开发到生产:Store 的升级路径
开发阶段:InMemoryStore
from langgraph.store.memory import InMemoryStore
store = InMemoryStore() # 数据在内存中,重启丢失适合本地开发和测试。优点是零配置,缺点是重启后数据丢失。
生产阶段:PostgresStore
先安装 Postgres Store 依赖:
pip install langgraph-checkpoint-postgresfrom langgraph.store.postgres import PostgresStore
import os
with PostgresStore.from_conn_string(os.environ["DATABASE_URL"]) as store:
# 第一次连接该数据库时调用,用于创建 Store 所需表结构
store.setup()
agent = create_deep_agent(
model="google_genai:gemini-3.5-flash",
context_schema=MemoryContext,
memory=["/memories/AGENTS.md"],
store=store,
backend=CompositeBackend(
default=StateBackend(),
routes={
"/memories/": StoreBackend(
namespace=assistant_namespace,
),
},
),
)PostgresStore 提供真正的持久化——数据写入 PostgreSQL 数据库,即使应用重启也不会丢失。上面的 with 写法适合脚本和示例;如果是 Web 服务或常驻进程,通常在应用启动生命周期中初始化 Store,并在服务关闭时统一释放连接。
LangSmith 部署
如果通过 LangSmith 部署,不需要手动配置 Store——平台会自动为你的 Agent 配置持久化存储:
# LangSmith 部署时,省略 store 参数
agent = create_deep_agent(
model="google_genai:gemini-3.5-flash",
context_schema=MemoryContext,
memory=["/memories/AGENTS.md"],
backend=CompositeBackend(
default=StateBackend(),
routes={
"/memories/": StoreBackend(
namespace=assistant_namespace,
),
},
),
# store 由平台自动提供
)文件存储格式与外部写入
通过 StoreBackend 存储的文件使用以下 JSON 格式。deepagents>=0.5 默认使用 v2 格式,content 是完整字符串,并通过 encoding 标明文本或二进制编码:
{
"content": "第一行\n第二行\n第三行",
"encoding": "utf-8",
"created_at": "2024-01-15T10:30:00Z", # 创建时间
"modified_at": "2024-01-15T11:45:00Z" # 最后修改时间
}旧版本中 content 可能是 list[str],但该格式只是向后兼容。不要手写底层 JSON,Agent 外部(后端服务、初始化脚本)预填记忆时应使用 create_file_data 辅助函数:
from deepagents.backends.utils import create_file_data
from langgraph.store.memory import InMemoryStore
store = InMemoryStore()
# 预填 Agent 记忆
store.put(
("my-agent",), # namespace
"/memories/AGENTS.md", # 文件路径
create_file_data("""## Response style
- Keep responses concise
- Use code examples where possible
"""),
)
# 预填一个 Skill
store.put(
("my-agent",),
"/skills/langgraph-docs/SKILL.md",
create_file_data("""---
name: langgraph-docs
description: Fetch relevant LangGraph documentation to provide accurate guidance.
---
# langgraph-docs
Use the fetch_url tool to read https://docs.langchain.com/llms.txt, then fetch relevant pages.
"""),
)使用 LangSmith 部署时,也可以通过 SDK 远程写入:
await client.store.put_item(namespace, key, value)
最佳实践
1. 使用描述性路径
给持久化文件起有意义的路径名,方便组织和检索:
/memories/AGENTS.md # Agent 自身知识(Agent-scoped)
/memories/preferences.md # 用户偏好(User-scoped)
/memories/project/tech-stack.md # 项目技术栈
/memories/research/topic-a/notes.md # 研究笔记
/policies/compliance.md # 组织合规策略(只读)2. 用 memory= 声明而非 System Prompt
优先使用 memory= 参数声明记忆文件,而不是在 system_prompt 中引导 Agent 手动读取。前者让框架自动管理加载时机:
# ✅ 推荐
agent = create_deep_agent(
memory=["/memories/AGENTS.md", "/memories/preferences.md"],
...
)
# ❌ 不推荐(旧模式)
agent = create_deep_agent(
system_prompt="启动时先读取 /memories/preferences.md...",
...
)3. 按主题拆分文件
将记忆按主题拆分成独立文件,而不是一个大文件。这减少并发写入冲突,也让 Agent 能按需加载特定主题。
4. 多 Agent 部署隔离
在同一部署中运行多个 Agent 时,在 namespace 中加入 assistant_id 确保记忆互不干扰:
StoreBackend(
namespace=lambda rt: (
assistant_namespace(rt)[0],
user_namespace(rt)[0],
),
)5. 选择合适的 Store
| 场景 | 推荐 Store | 理由 |
|---|---|---|
| 本地开发 | InMemoryStore | 零配置,快速迭代 |
| 生产环境 | PostgresStore | 真正持久化,可伸缩 |
| LangSmith 部署 | 平台自动配置 | 无需手动管理 |
6. 用 LangSmith 审计记忆写入
每次文件写入都作为 tool call 出现在 LangSmith trace 中。对敏感记忆路径,开启 tracing 审计 Agent 写了什么。
审计回答“发生了什么”,权限回答“是否允许发生”。对于组织策略和共享知识库,应同时拒绝 Agent 写入;完整的只读记忆规则与 CompositeBackend 限制见第 11 章:文件系统权限。
小结
本章我们学习了 Deep Agents 的长期记忆能力:
- Memory 一等公民:通过
memory=参数声明记忆路径,Agent 启动时自动加载到系统提示词 - 三种作用域:Agent 级(共享知识)、用户级(个人偏好)、组织级(合规策略)
- CompositeBackend 路由:
/memories/路径路由到 StoreBackend,namespace lambda 控制隔离粒度 - 高级特性:情景记忆(搜索过去对话)、后台整合(Cron + 整合 Agent)、读写权限控制
- 升级路径:InMemoryStore(开发)→ PostgresStore(生产)→ LangSmith 平台自动配置
- 外部预填:
store.put()+create_file_data()从应用代码初始化记忆和 Skills
下一章,我们将学习 Human-in-the-Loop——如何为敏感操作添加人工审批,构建安全的人机协作流程。