第 10 章 策略梯度方法#
到目前为止,本书中几乎所有方法都是动作价值方法(action-value methods),即它们试图学习动作的价值,然后根据估计的动作价值选择动作。现在我们考虑的是直接学习参数化策略(parameterized policy)的方法,该策略可以在不参考价值函数(value function)的情况下选择动作。注意,价值函数仍可能用于\(\textit{学习}\)策略参数(记为\(\theta \in \mathbb{R}^{d'}\)),但在动作选择时并非必须。
本章考虑基于某个标量性能度量\(J(\theta)\)的梯度来学习策略参数(策略表示为\(\pi(a \mid s, \theta) = \Pr\{ A_t = a \mid S_t = s, \theta_t = \theta \}\))的方法,我们的目标是最大化该性能度量。因此,策略参数的更新遵循梯度上升(gradient ascent):
其中\(\nabla \widehat{J}(\theta_t)\)是一个随机估计,其期望近似于性能度量对参数\(\theta_t\)的梯度。所有遵循此通用模式的方法称为策略梯度方法(policy gradient methods)。
在策略梯度方法中,同时学习策略函数和价值函数近似的方法通常称为演员-评论家方法(actor-critic methods),其中\textit{“演员”}(actor)指学习到的策略,\textit{“评论家”}(critic)指学习到的价值函数。
10.1 策略逼近及其优势(Policy Approximation and Its Advantages)#
设置(setup):在策略梯度方法中,策略可以以任意方式参数化,只要\(\pi(a|s, \theta)\)关于参数可微。实际中,为保证探索(exploration),通常要求策略不会变得确定性(即对所有\(s, a, \theta\),\(\pi(a|s, \theta) \in (0, 1)\))。
离散且较小动作空间的逼近示例:
策略的参数化:在此设置下,我们首先为每个状态-动作对参数化数值\textit{动作偏好}(action preference)\(h(s, a, \theta) \in \mathbb{R}\)。在每个状态中,偏好最高的动作根据例如指数软最大(soft-max)分布获得最高选择概率:
\[ \pi(a|s,\theta) \dot= \frac{e^{h(s,a,\theta)}}{\sum_b e^{h(s,b,\theta)}} \]这种策略参数化方式称为基于动作偏好的软最大化(soft-max based on action preferences)。
状态-动作对的参数化:动作偏好\(h(s, a, \theta) \in \mathbb{R}\)本身可以任意参数化。例如:
使用深度人工神经网络(ANN),其中\(\theta\)是网络所有连接权重的向量(如AlphaGo系统,感兴趣的读者可参见第16.6节)
线性特征系统(linear feature system):
\[ h(s, a, \theta) = \theta^\top x(s, a) \]其中特征向量\(x(s, a) \in \mathbb{R}^{d'}\)可用第9章介绍的任一方法构造。
策略参数化的优势
允许确定性:不同于传统的\(\epsilon\)-贪婪方法(\(\epsilon\)-greedy method)限制探索,参数化策略可以从随机开始,自然收敛到贪婪策略。即若最优策略是确定性的,最优动作的偏好会被参数化推向无限大,超越所有次优动作(如果参数化允许)。这样避免了外部判断何时结束探索。
允许随机性:策略参数化支持任意概率选择动作。在有显著函数逼近的问题中,确定性策略未必可行。随机策略(stochastic policy)常常表现更好,如下文走廊例子中,随机动作帮助智能体获得更高回报。
例子:动作反转的短走廊
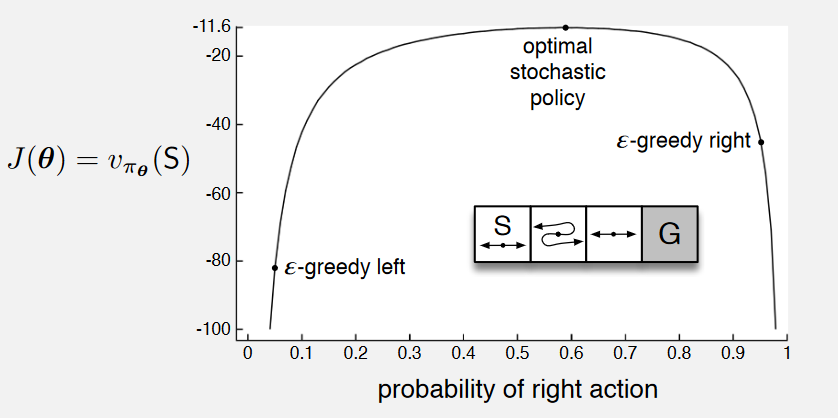
设置:
如图所示,有三个非终止状态,每步奖励为1。
在第一个状态,左动作不移动。
在第二个状态动作方向反转,右动作使智能体向左移动,左动作向右移动。
动作价值方法与策略逼近的比较:
使用\(\epsilon\)-贪婪动作选择的动作价值方法只能在两种策略间选择。例如,若\(\epsilon=0.1\),则左或右动作的概率为\(1-\frac{\epsilon}{2} = 0.95\),另一动作为0.05。这两种\(\epsilon\)-贪婪策略在起始状态\(S\)的值分别低于\(-44\)和\(-82\)。
策略逼近能显著更优,因为它学习选择右动作的具体概率(允许更多随机性)。如图所示,策略逼近选择右动作的最佳概率约为0.59,对应的值约为\(-11.6\)。
10.2 策略梯度定理(Policy Gradient Theorem)#
策略梯度目标:
当我们直接参数化策略时,可以将强化学习的终极目标直接作为学习目标,即学习一个在长期内获得尽可能多奖励的策略。回顾我们三种奖励形式:
回合设置(episodic setup):\(G_t = \sum_{t=0}^{T} R_t\)
带折扣回报的持续设置(continuing setup with discounted return):\(G_t = \sum_{t=0}^{\infty} \gamma^t R_t\)
带平均奖励形式的持续设置(continuing setup with average reward):\(G_t = \sum_{t=0}^{\infty} R_t - r(\pi)\)
本章聚焦于以平均奖励为目标的持续设置(仅针对持续任务)。策略\(\pi\)的平均奖励(average reward)定义为:
\[\begin{split} \begin{align*} r(\pi) &= \sum_{s}\mu(s) v(s) \\ &= \sum_{s}\mu(s) \sum_{a} \pi(a \vert s, \theta) q(s,a) \\ \end{align*} \end{split}\]因此,目标是找到最大化该平均奖励的策略,所以本章开头介绍的梯度上升更新可表示为:
\[\begin{split} \begin{align*} \theta_{t+1} &= \theta_t + \alpha \nabla \widehat{J}(\theta_t) \\ &= \theta_t + \alpha \nabla r(\pi) \\ &= \theta_t + \alpha \nabla \sum_{s}\mu(s) \sum_{a} \pi(a \vert s, \theta) q(s,a) \end{align*} \end{split}\]然而,不同于价值函数逼近(其中\(\mu(s)\)是固定的),这里\(\mu(s)\)依赖于策略,策略更新时\(\mu(s)\)的分布也会改变。我们需要一个不依赖\(\mu(s)\)的策略参数更新规则,此时策略梯度定理发挥作用。
策略梯度定理:
该定理给出了性能(平均奖励)对策略参数梯度的解析表达式,不涉及状态分布的导数,证明如下:
\[ \nabla J(\theta) \propto \sum_s \mu(s) \sum_a q_{\pi}(s, a) \nabla \pi(a | s, \theta) \]这里符号\(\propto\)表示”成比例”。在情节式情况下,比例常数为平均情节长度;在持续情况下为1。分布\(\mu\)为上一章介绍的策略\(\pi\)下的在策略分布。
这段可选课程视频(2:08 - 4:27)直观说明了项\(\sum_a q_{\pi}(s, a) \nabla \pi(a | s, \theta)\)的作用。详细推导请参见本书第13.2章,第325页。
10.3 REINFORCE(带基线):蒙特卡洛策略梯度(REINFORCE with Baseline: Monte Carlo Policy Gradient)#
10.3.1 REINFORCE#
REINFORCE更新规则推导:
随机梯度上升策略(stochastic gradient ascent policy)需要一种方式采样,使得样本梯度的期望与性能度量的真实梯度成比例,即需要某种采样方法,其期望等于或近似策略梯度定理给出的表达式。
自然地,我们可以将策略梯度定理重写为
\[\begin{split} \begin{align*} \nabla J(\theta) &\propto \sum_s \mu(s) \sum_a q_{\pi}(s, a) \nabla \pi(a | s, \theta) \\ &= \mathbb{E}_{\pi} \left[ \sum_a q_{\pi}(S_t, a) \nabla \pi(a | S_t, \theta) \right], \end{align*} \end{split}\]并可在此停下,将随机梯度上升算法实例化为
\[ \theta_{t+1} \doteq \theta_t + \alpha \sum_a \hat{q}(S_t, a, \mathbf{w}) \nabla \pi(a | S_t, \theta), \]其中\(\hat{q}\)是对\(q_\pi\)的某种学习近似。该算法称为全动作方法(all-actions method),因为其更新涉及所有动作。该算法有前景且值得深入研究,但我们目前关注的是经典的REINFORCE算法,它将上述变换继续如下:
\[\begin{split} \begin{align*} \nabla J(\theta) &= \mathbb{E}_{\pi} \left[ \sum_a \pi(a|S_t, \theta) q_{\pi}(S_t, a) \frac{\nabla \pi(a|S_t, \theta)}{\pi(a|S_t, \theta)} \right] \\ &= \mathbb{E}_{\pi} \left[ q_{\pi}(S_t, A_t) \frac{\nabla \pi(A_t|S_t, \theta)}{\pi(A_t|S_t, \theta)} \right] \quad \text{(将} a \text{替换为样本} A_t \sim \pi)\\ &= \mathbb{E}_{\pi} \left[ G_t \frac{\nabla \pi(A_t|S_t, \theta)}{\pi(A_t|S_t, \theta)} \right] \quad \text{(因为} \mathbb{E}_{\pi} [ G_t | S_t, A_t] = q_{\pi}(S_t, A_t) \text{)} \end{align*} \end{split}\]因此,REINFORCE的随机梯度上升更新可实例化为
\[ \theta_{t+1} \doteq \theta_t + \alpha \ G_t \frac{\nabla \pi(A_t|S_t, \theta)}{\pi(A_t|S_t, \theta)} \]REINFORCE的直观理解
推导过程:注意推导中,我们用采样动作\(A_t \sim \pi\)替代了期望项\(\sum_a \pi(a|S_t, \theta) q_{\pi}(S_t, a)\)。此策略类似于从蒙特卡洛方法转向TD方法,带来偏差但降低了方差。
最终更新形式:REINFORCE的增量与回报\(G_t\)和一个向量(称为资格向量(eligibility vector))的乘积成正比——该向量是实际采取动作概率的梯度除以该动作概率。初听起来可能难以理解,下面解释其含义:
增量中的回报\(G_t\)促使参数朝着有利于高回报动作的方向移动。(这就是REINFORCE名称的由来,算法强化好动作,抑制坏动作。)
向量\(\frac{\nabla \pi(A_t|S_t, \theta)}{\pi(A_t|S_t, \theta)}\)是一种典型的相对变化率(relative change rate),指示在参数空间中使得未来在状态\(S_t\)重复动作\(A_t\)概率最大化的方向。
此外,更新与动作概率成反比,使得较少选择的动作获得优势,鼓励探索。
为何称为蒙特卡洛:REINFORCE使用从时间\(t\)起的完整回报\(G_t\),涵盖直至情节结束的所有未来奖励,因此它是蒙特卡洛算法,并且仅对情节式任务定义良好。
REINFORCE算法:蒙特卡洛策略梯度控制(情节式)求解\(\pi_{\star}\)

REINFORCE在短走廊例子中的表现
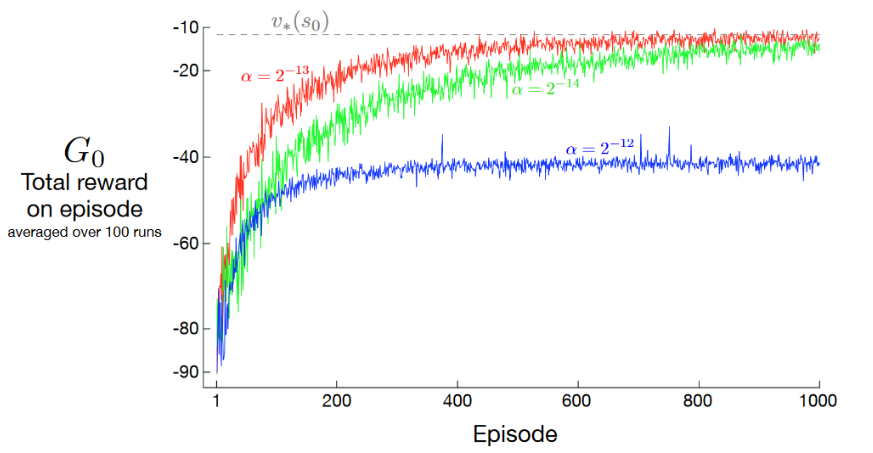
结果(results):如图所示,在合适步长下,每情节总奖励趋近于起始状态的最优值(\(v_\star(s_0)\))
REINFORCE的性质:对足够小的\(\alpha\),期望性能改进有保障,并在标准随机逼近条件下随\(\alpha\)递减收敛至局部最优。但作为蒙特卡洛方法,REINFORCE可能具有高方差,导致学习较慢。
10.3.2 带基线的 REINFORCE(REINFORCE with Baseline)#
带基线的 REINFORCE 推导
我们现在将策略梯度定理推广为比较动作值\(q_{\pi}(s, a)\)与任意基线\(baseline \quad b(s)\):
\[ \nabla J(\theta) \propto \sum_{s} \mu(s) \sum_{a} \left( q_{\pi}(s, a) - b(s) \right) \nabla \pi(a \mid s, \theta). \]该基线可以是任意函数,甚至随机变量,只要它不随动作\(a\)变化,该等式仍成立,因为被减去的项为零:
\[\begin{split} \begin{align*} \sum_{a} b(s) \nabla \pi(a \mid s, \theta) &= b(s) \nabla \sum_{a} \pi(a \mid s, \theta) \\ &= b(s) \nabla 1 \\ &= 0. \end{align*} \end{split}\]因此,我们得到包含通用基线的新更新规则,它是 REINFORCE 的严格推广(因为基线可以恒为零):
\[ \theta_{t+1} \doteq \theta_t + \alpha (G_t - b(S_t)) \frac{\nabla \pi(A_t|S_t, \theta)}{\pi(A_t|S_t, \theta)} \]添加基线的理由
降低方差:基线通常不改变更新的期望值,但对方差影响显著。加入基线可大幅降低方差,从而加速学习。
基线的设定:
对于MDP,基线应随状态变化。在某些状态下所有动作价值都高,此时需要较高基线以区分较高价值动作与较低价值动作;而在另一些状态下所有动作价值较低,低基线更合适。
因此,基线的自然选择是状态值的估计:\(\hat{v}(S_t, \boldsymbol{w})\)。由于 REINFORCE 是蒙特卡洛方法,使用蒙特卡洛方法学习状态值权重\(\boldsymbol{w}\)也是自然的。为此,以下给出带基线的 REINFORCE 算法。
带基线的 REINFORCE 算法:蒙特卡洛策略梯度控制(情节式)求解\(\pi_\theta \approx \pi_{\star}\)

带基线的 REINFORCE 在短走廊例子中的表现
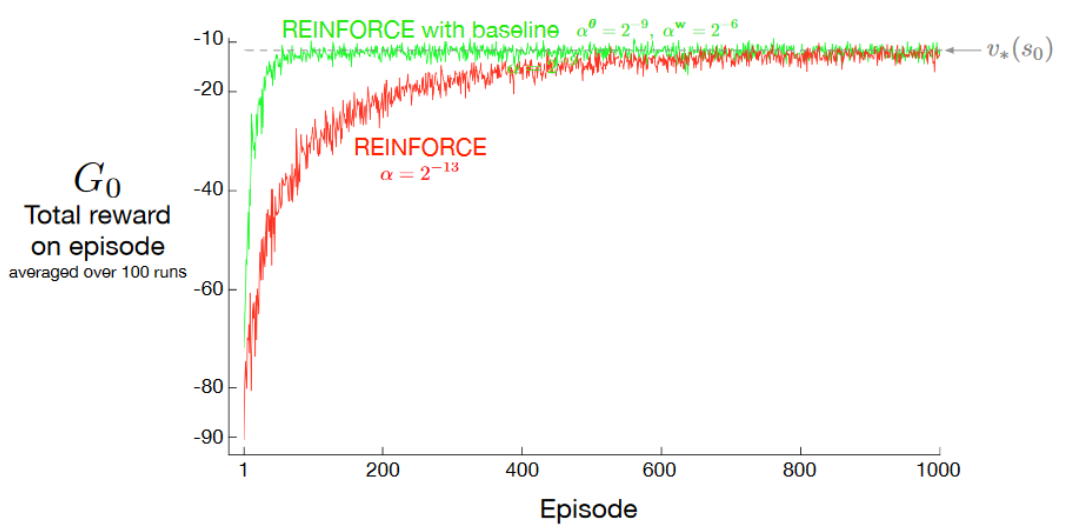
在 REINFORCE 中加入基线能显著加快学习速度。此处所用的步长为普通 REINFORCE 表现最佳时的步长。
10.4 演员-评论家方法(Actor–Critic Methods)#
本章开头,我们简要定义了演员-评论家方法,即同时学习策略函数和值函数近似的策略梯度方法。此处需特别指出,虽然带基线的REINFORCE方法也学习两者,但它不被视为演员-评论家方法。原因在于其状态值函数仅用作基线,而非评论家。换言之,值函数并未用于自举(bootstrap,利用后续状态的估计值更新当前状态的估计),而只是作为当前状态估计的基线。
由于带基线的REINFORCE本质是蒙特卡洛方法,因此无偏且渐近收敛于局部极小值。正如我们从TD学习中了解到的,只有通过自举才会引入偏差,并使得渐近性能依赖函数逼近的质量,从而降低方差并加速学习。为了在策略梯度方法中获得这些优势,我们采用带自举的演员-评论家方法。
在演员-评论家方法中,状态值函数负责”评判”(criticize)策略的动作选择,因此称其为评论家(critic),而策略本身称为演员(actor),相关算法细节将在本节后续部分介绍。
10.4.1 适用于情节任务的演员-评论家方法(Actor-Critic for Episodic Tasks)#
推导
一步演员-评论家方法用一步回报替代REINFORCE的完整回报(并使用学习得到的状态值函数作为基线),具体如下:
\[\begin{split} \begin{align*} \theta_{t+1} &\doteq \theta_t + \alpha \ G_t \frac{\nabla \pi(A_t|S_t, \theta)}{\pi(A_t|S_t, \theta)} \quad \quad \quad \quad \quad \quad \quad \text{(REINFORCE)} \\ &\doteq \theta_t + \alpha \ (G_t - b(S_t)) \frac{\nabla \pi(A_t|S_t, \theta)}{\pi(A_t|S_t, \theta)} \quad \quad \quad \text{(REINFORCE with Baseline)} \\ &\doteq \theta_t + \alpha \left( G_{t:t+1} - \hat{v}(S_t, \mathbf{w}) \right) \frac{\nabla \pi(A_t | S_t, \theta_t)}{\pi(A_t | S_t, \theta_t)} \quad \quad \quad \quad \quad \quad \quad \quad \text{(Actor-Critic)} \\ &= \theta_t + \alpha \left( R_{t+1} + \gamma \hat{v}(S_{t+1}, \mathbf{w}) - \hat{v}(S_t, \mathbf{w}) \right) \frac{\nabla \pi(A_t | S_t, \theta_t)}{\pi(A_t | S_t, \theta_t)} \quad \quad \text{(Actor-Critic)} \\ &= \theta_t + \alpha \delta_t \frac{\nabla \pi(A_t | S_t, \theta_t)}{\pi(A_t | S_t, \theta_t)} \quad \quad \quad \quad \quad \quad \quad \quad \quad \quad \quad \quad \quad \quad \quad \text{(Actor-Critic)}. \end{align*} \end{split}\]与此配套的自然状态值函数学习方法是半梯度TD(0),具体算法如下。注意,这现在是一个完全在线的增量算法,状态、动作和奖励按发生顺序处理,且处理后不再回顾。
算法:一步演员-评论家(情节式),估计\(\pi_\theta \approx \pi_{\star}\)

10.4.2 适用于连续任务的演员-评论家方法(Actor-Critic for Continuing Tasks)#
设置:
对于连续任务,我们将性能指标\(J(\theta)\)定义为每时间步的平均奖励率\(r(\pi)\)。\(r(\pi)\)的定义见第9章9.2节
注意,针对情节任务给出的策略梯度定理对连续任务同样成立,证明见书中第13章6节第334页。因此,我们现可针对平均奖励设置调整演员-评论家算法,示例如下。
演员-评论家算法(连续任务),估计\(\pi_\theta \approx \pi_{\star}\)

关于演员-评论家算法(连续任务)的更多内容:
演员-评论家方法示例:摆锤摆起(连续任务)
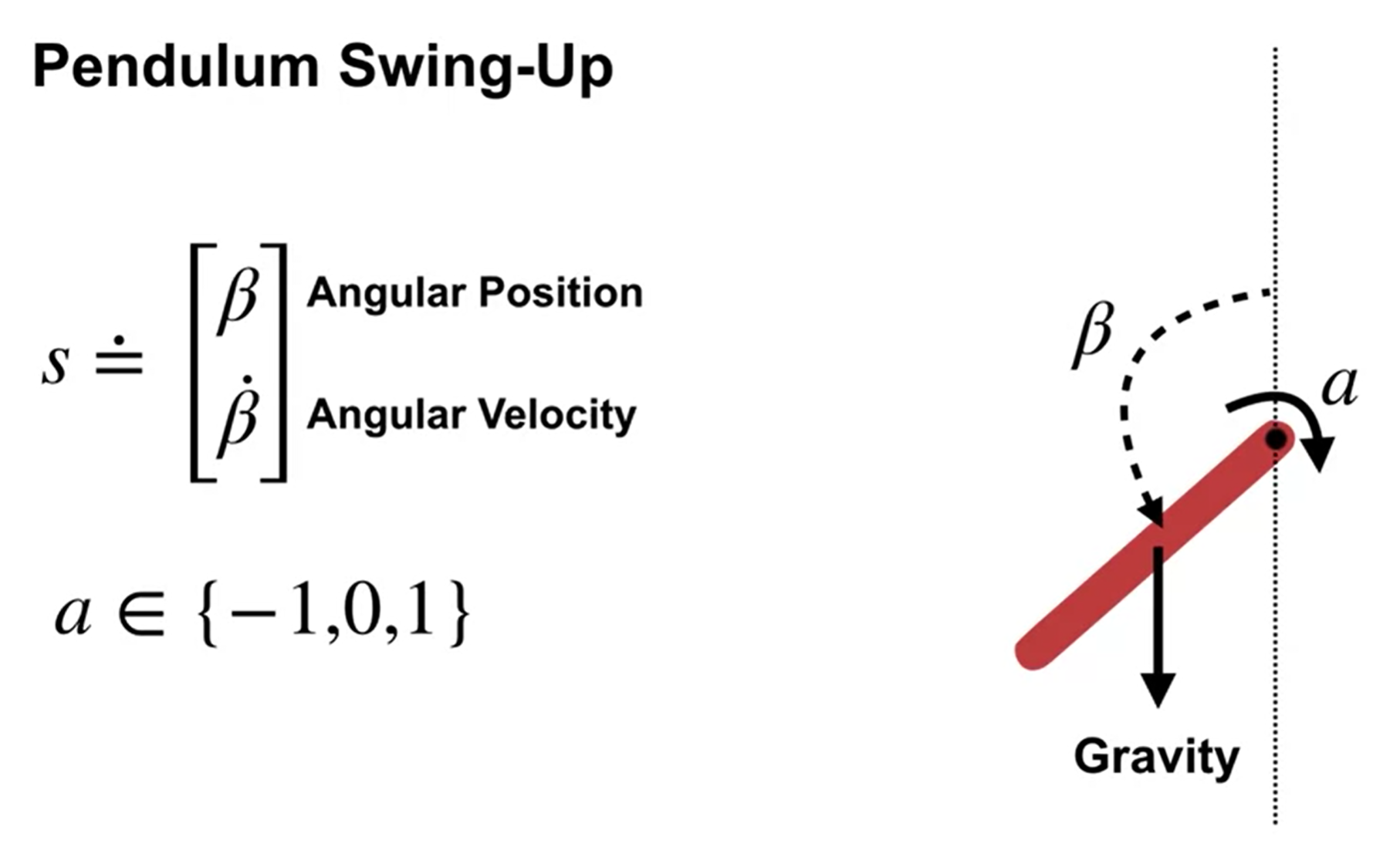
设置:智能体需通过对枢轴点施加力矩使摆锤保持竖直平衡,摆锤初始静止(垂直向下),速度为零,可在重力和施加动作作用下自由运动。
状态(state):角位置 \(\beta\) 和角速度 \(\dot{\beta}\),且\(-2\pi < \dot{\beta} < 2\pi\)(过高角速度会损坏系统)。
动作(action):施加三种力矩之一:1) 顺时针力矩,2) 逆时针力矩,3) 无力矩。
奖励(reward):\(r = -|\beta|\),即保持竖直(\(\beta=0\))获得最高奖励0。
参数化与特征构造(:
状态值函数:\(\hat{v}(s, \mathbf{w}) \dot= \mathbf{w}^{\intercal} x(s)\)
软最大策略:\(\pi(a|s,\theta) \dot= \frac{e^{h(s,a,\theta)}}{\sum_b e^{h(s,b,\theta)}}\) with \(h(s, a, \theta) = \theta^\top x_h(s, a)\)
特征构造:因状态为二维,可用32个8×8大小的平铺编码(tile coding)构造特征。
学习(learning):一般要求 \(\alpha^\theta < \alpha^\mathbf{w}\),即评论家的学习率(learning rate)应大于演员的学习率,使评论家能更快更新,从而准确评价较慢变化的策略。
性能(performance):训练重复100次,使用指数加权奖励曲线评估性能。如下图所示,学习到的策略较为稳定且可靠。
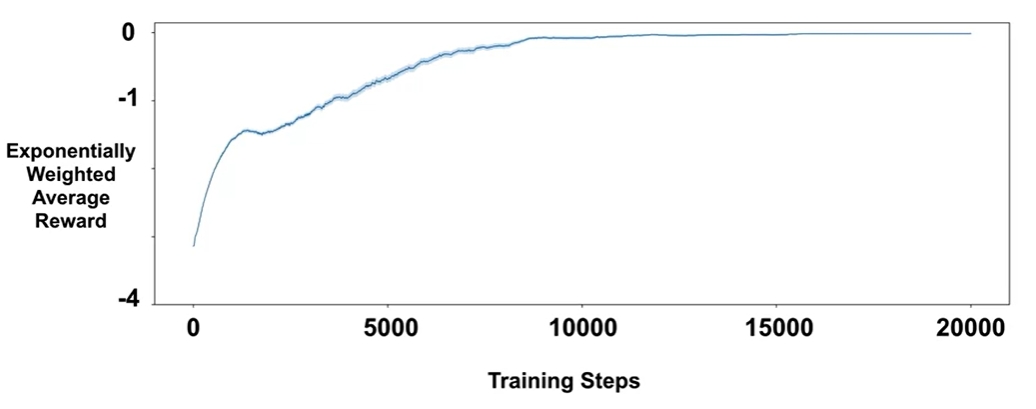
可选:指数加权移动平均(exponential weighted moving average, EWMA)用于强化学习中平滑奖励,减少噪声,更好地观察学习趋势,计算公式为:
\[ R_t^{EW} = \lambda R_{t-1}^{EW} + (1 - \lambda) R_t \]其中:
\(R_t^{EW}\) 是时间步 \(t\) 的指数加权奖励。
\(R_t\) 是时间 \(t\) 实际获得的奖励。
\(\lambda\) 是平滑因子(通常介于0和1之间)。
\(R_0^{EW}\) 初始化为第一个奖励。
10.5 连续动作的策略参数化(Policy Parameterization for Continuous Actions)#
连续动作的高斯策略设定(Gaussian policy setup for continuous actions):
现在我们关注连续动作空间(continuous action space),其动作数量无限。对于此类问题,不是对每个动作计算学习到的概率,而是学习概率分布的统计量,并通过从该分布采样来选择动作。
假设分布为正态分布(normal distribution),为了构建策略参数化(policy parameterization),策略可以定义为对实值标量动作的正态概率密度函数(normal probability density function),其均值和标准差由依赖状态的参数化函数近似给出,如下所示:
\[ \pi(a | s, \theta) \doteq \frac{1}{\sigma(s, \theta) \sqrt{2\pi}} \exp \left( -\frac{(a - \mu(s, \theta))^2}{2\sigma(s, \theta)^2} \right), \]其中 \(\mu : \mathcal{S} \times \mathbb{R}^{d'} \to \mathbb{R}\) 和 \(\sigma : \mathcal{S} \times \mathbb{R}^{d'} \to \mathbb{R}^+\) 是两个参数化的函数近似器。因此,策略有两个部分的参数需要学习,记为 \(\theta = [\theta_\mu, \theta_\sigma]^\top\)。
均值(mean)可以近似为线性函数(linear function)。标准差(standard deviation)必须始终为正,通常更适合近似为线性函数的指数形式(exponential form)。因此
\[ \mu(s, \theta) \doteq \theta_{\mu}^{\top} \mathbf{x}_{\mu}(s) \quad \text{and} \quad \sigma(s, \theta) \doteq \exp \left( \theta_{\sigma}^{\top} \mathbf{x}_{\sigma}(s) \right), \]有了这些定义,本章其余部分描述的所有算法都可以用于学习选择实值动作。
高斯策略在摆动摆任务中的应用:
状态和奖励:保持不变
动作:不再是三个离散动作,智能体现在选择范围为[-3, 3]的连续角加速度。
参数化:我们采用高斯策略,从依赖状态的高斯分布中采样动作。\(\mu(s)\) 和 \(\sigma(s)\) 分别如上文所述建模为线性函数和指数函数。
动作选择:1) 根据当前状态 \(s\) 计算 \(\mu(s)\) 和 \(\sigma(s)\)。2) 从该高斯策略的分布中采样动作。
选择过程中,\(\sigma(s)\) 控制探索:较大的 \(\sigma\) 表示较高的方差,导致较强的探索;相反,较小的 \(\sigma\) 导致较低的探索。通常初始化时将 \(\sigma(s)\) 设为较大值,随着学习进行,期望方差缩小,策略在每个状态下集中于最佳动作。
为什么选择连续动作策略:
更灵活的动作选择:智能体可以进行细微调整,而不是从固定动作集中选择。
动作的泛化能力:若某动作表现良好,邻近动作也会获得较高概率,减少大量探索需求。
处理大规模或无限动作空间:即使真实动作空间是离散且庞大,将其视为连续有助于避免逐一探索所有动作的高昂成本。
10.6 总结#
本章介绍策略梯度方法,这是一类直接参数化并优化策略的强化学习技术,相较于传统的动作值方法(通过估计动作值并由此推导策略)。简要总结如下:
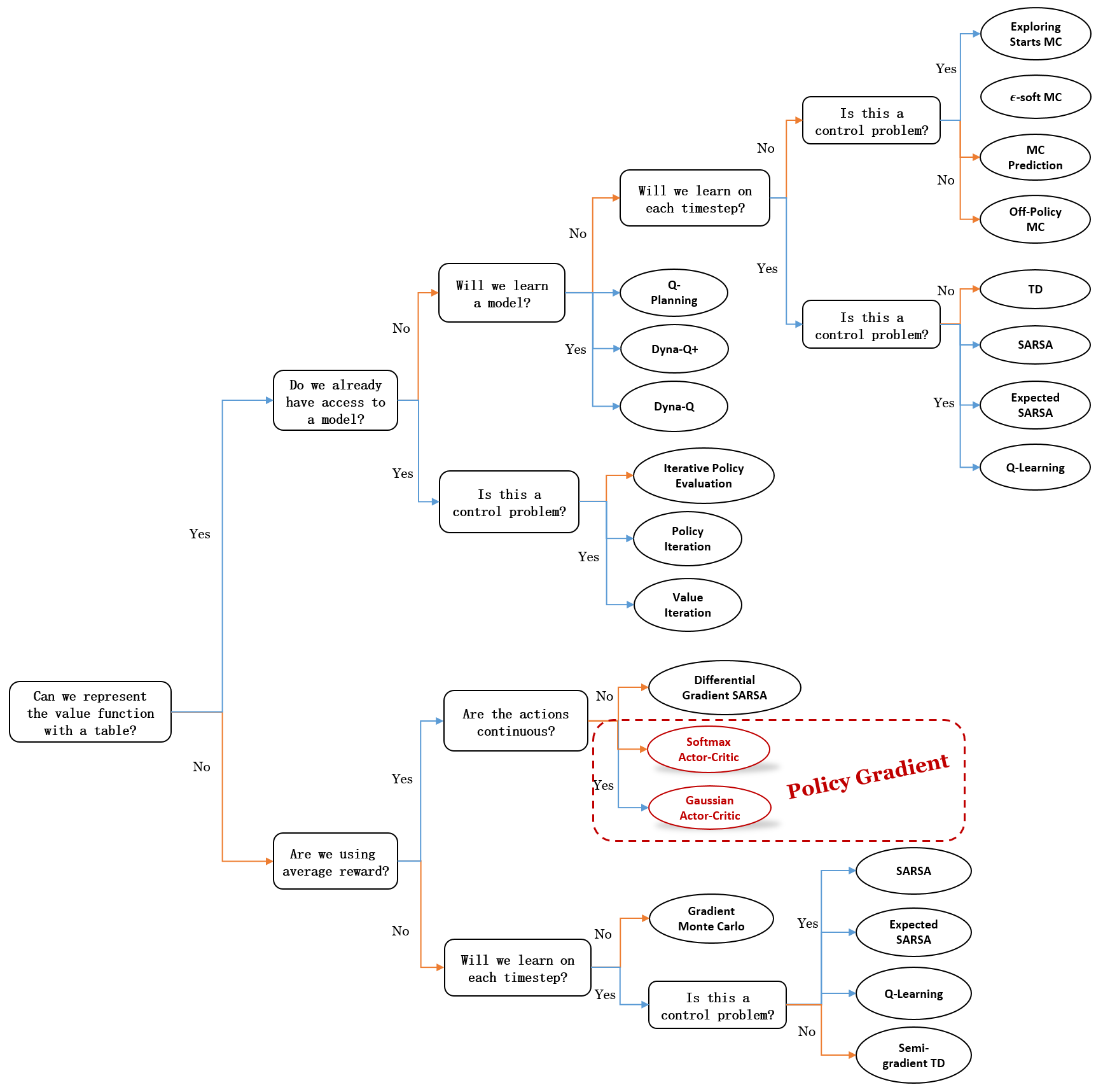
思维导图:我们现在的位置
关键要点
策略梯度方法简介
直接策略优化:与动作值方法不同,策略梯度方法直接参数化并优化策略 \(\pi(a|s, \theta)\)。
梯度上升:通过对性能指标 \(J(\theta)\) 的梯度进行上升来更新策略。
策略参数化的优势
灵活性:策略可以是随机的或确定性的,能够自然收敛到最优行为。
改进探索:随机策略相比 \(\epsilon\)-贪婪方法能够实现更好的探索。
策略梯度定理
目标:最大化持续任务中的平均奖励 \(r(\pi)\)。
梯度表达式:
\[ \nabla J(\theta) \propto \sum_s \mu(s) \sum_a q_{\pi}(s, a) \nabla \pi(a | s, \theta) \]避免对状态分布 \(\mu(s)\) 求导。
REINFORCE算法
蒙特卡洛策略梯度:使用整回合的回报来更新策略。
更新规则:
\[ \theta_{t+1} = \theta_t + \alpha G_t \frac{\nabla \pi(A_t|S_t, \theta)}{\pi(A_t|S_t, \theta)} \]局限性:某些情况下方差较大,学习较慢。
带基线的REINFORCE
方差降低:引入基线 \(b(s)\),通常为状态值估计 \(\hat{v}(s)\),以降低方差。
带基线的更新规则:
\[ \theta_{t+1} = \theta_t + \alpha (G_t - b(S_t)) \frac{\nabla \pi(A_t|S_t, \theta)}{\pi(A_t|S_t, \theta)} \]性能表现:相比原始REINFORCE,学习更快且更稳定。
演员-评论家方法
结合策略与价值学习:演员负责更新策略,评论家利用自举的价值估计对动作进行评估。
更新规则:
策略(演员):
\[ \theta \leftarrow \theta + \alpha^\theta \delta \nabla \ln \pi(A_t|S_t, \theta) \]价值函数(评论家):
\[ \mathbf{w} \leftarrow \mathbf{w} + \alpha^w \delta \nabla \hat{v}(S_t, \mathbf{w}) \]时序差分误差(TD误差):
\[ \delta = R_{t+1} + \gamma \hat{v}(S_{t+1}) - \hat{v}(S_t) \]
优势:方差更低,收敛更快,支持完全在线学习。
连续动作空间与高斯策略
高斯策略参数化:对于连续动作,策略建模为具有可学习均值 \(\mu(s)\) 和标准差 \(\sigma(s)\) 的高斯分布。
更新灵活性:
\[ \pi(a | s, \theta) = \frac{1}{\sigma(s, \theta) \sqrt{2\pi}} \exp \left( -\frac{(a - \mu(s, \theta))^2}{2\sigma(s, \theta)^2} \right) \]优点:实现细粒度控制、高效探索,并支持大规模或无限动作空间的泛化。