第1章. 强化学习简介#
通过与环境的交互来学习是获取知识的基础,从婴儿期到成年期都是如此。无论是儿童时期的玩耍还是学习复杂技能如驾驶,我们都在通过行动及其后果不断吸收关于因果关系的信息。这个想法支撑着大多数学习和智能理论。
本书采用计算方法来研究这种交互学习,重点不是直接研究人类或动物的学习过程,而是分析理想化的学习场景。我们将探索机器如何高效地解决具有科学价值的学习问题。我们探讨的方法称为强化学习,与其他机器学习方法相比,它更专注于通过交互进行目标导向的学习。
本章将通过定义、实例和强化学习中的关键要素来介绍这一领域。本章主要是描述性内容,所以您不会看到太多图表或公式。我们假设决心踏上这段学习之旅的读者,或多或少已经了解强化学习的能力,因此让我们略过介绍性内容,直接进入强化学习的世界!
1.1 强化学习(RL)#
定义:强化学习是学习”该采取什么行动”——如何将情境映射到动作——以最大化数值化的奖励信号。学习者不会被告知要采取哪些具体动作,而是必须通过尝试来发现哪些动作能带来最多的奖励。
强化学习同时是一个问题、一类能有效解决该问题的方法,以及研究这个问题及其解决方法的学术领域。它具有两个基本特征:
试错搜索:学习者通过不断尝试和从失败中学习。
延迟奖励:动作不仅会影响即时奖励,还可能影响后续状态,进而影响所有后续获得的奖励。
形式化:强化学习问题可以用动力系统理论(dynamical systems theory)的思想进行形式化,具体来说,它可被视为不完全已知的\(\textit{马尔可夫决策过程 (Markov decision processes)}\)的最优控制问题(将在第3章中详细介绍)。
简单来说,智能体能够在一定程度上感知其\(\textit{环境 (Environment)}\)的\(\textit{状态 (State)}\),并采取会影响状态的\(\textit{动作 (Action)}\)。同时,智能体有一个或多个与环境状态相关的\(\textit{目标 (Goal)}\)需要实现,这一目标通过它在每次交互中从环境接收的\(\textit{奖励 (Reward)}\)来体现。任何适合解决此类问题——引导智能体实现目标——的方法,我们都可视为强化学习方法。
独特性:
探索与利用的权衡:与其他类型的学习不同,在强化学习中,智能体必须利用已有的经验来获取奖励,同时也必须进行探索,以便在未来做出更优的动作选择。这一点将在第2章第2.1节中进一步解释。
目标导向学习:强化学习明确考虑了目标导向智能体与不确定环境交互的完整问题。它从一个完整的、交互式的、追求目标的智能体出发,该智能体纯粹基于接收到的奖励信号进行学习。这种学习范式看似简单,但在设计奖励信号方面需要投入大量精力,并且容易受到奖励黑客攻击 (reward hacking)的影响。
Note
我们所说的完整的、交互式的、追求目标的智能体,并不总是指完整的有机体或机器人这样的实体。这些当然是典型例子,但完整的、交互式的、追求目标的智能体也可以是更大行为系统中的一个组件。
一个简单的例子是:一个监控机器人电池电量并向机器人控制架构发送命令的智能体。这个智能体的环境包括机器人的其他部分以及机器人所处的外部环境。
强化学习问题示例
示例1:小羚羊在出生几分钟后就努力站起来。半小时后,它就能以每小时20英里的速度奔跑。
示例2:移动机器人需要决定是进入新房间寻找更多可收集的垃圾,还是开始尝试返回电池充电站。它的决策基于当前电池电量以及过去找到充电站的速度和难易程度。
共同模式:
两个例子都涉及主动决策的智能体与其环境之间的交互,智能体需要在对环境存在不确定性的情况下实现目标。
动作的效果无法完全预测;因此智能体必须频繁监控环境并做出适当反应。
智能体能够利用经验,随着时间的推移改进其表现。
1.2 强化学习的要素#
策略(Policy) \(\pi\):定义学习智能体在特定时刻的行为方式。简单来说,策略是从感知到的环境状态到在该状态下应采取的动作的映射。
策略是强化学习智能体的核心,因为仅凭策略就足以确定其行为。一般而言,策略可以是随机的,为每个可能的动作分配概率。策略的概念将在第3章第3.3节中更正式地解释。
奖励信号 (Reward signal) \(R_t\):定义强化学习问题的目标。在每个时间步,环境会向强化学习智能体发送一个数字,称为奖励。智能体的唯一目标是最大化其长期获得的总奖励。
一般来说,奖励信号可以是环境状态和所采取动作的随机函数。这一概念将在第3章第3.2.1节中正式介绍。
价值函数:定义了长期来看什么是有利的。简单来说,某个状态的价值是智能体从该状态开始,预期在未来能够累积的奖励总和。奖励是即时的,而价值则更具前瞻性。一个状态可能总是产生较低的即时奖励,但如果它之后经常跟随能产生高奖励的状态,那么它仍可能具有很高的价值。
价值与奖励的关系:
用人类的感受类比,奖励有点像快乐(值高时)和痛苦(值低时),而价值则相当于我们对环境处于特定状态时的满足或不满程度的更精细、更具前瞻性的判断。
在某种意义上,奖励是首要的,而作为奖励预测的价值是次要的。没有奖励就不可能有价值;然而,在做出和评估决策时,我们最关注的是价值。事实上,我们所讨论的几乎所有强化学习算法中,最重要的组成部分就是有效估计价值的方法。
价值函数的类型:存在两种主要的价值函数:状态价值函数\(v(s)\)和动作价值函数\(q(s,a)\),我们将在后面的第3.3.1节中详细介绍它们。
环境模型(可选):我们所说的环境模型,指的是智能体可以用来预测环境如何对其动作做出反应的任何机制。给定一个状态和一个动作,模型可以预测出结果状态和下一个奖励。
模型主要用于\(\textit{规划}\),即通过在实际经历之前考虑可能的未来情况来决定行动方案的过程。在第7章中,我们将探讨\(\textit{基于模型}\)的强化学习系统,这些系统同时通过试错学习,并且会学习环境模型并利用该模型进行规划。
1.3 总结#
在本章中,我们介绍了强化学习(RL)这一试错学习过程,其中智能体与不确定环境交互,目标是最大化累积奖励。智能体在学习过程中需要平衡探索和利用,并且纯粹通过环境提供的奖励信号进行学习。
强化学习的关键要素包括:策略\(\pi\)(将状态映射到动作)、奖励信号\(R_t\)(定义学习目标)、价值函数(估计长期奖励)以及可选的环境模型。
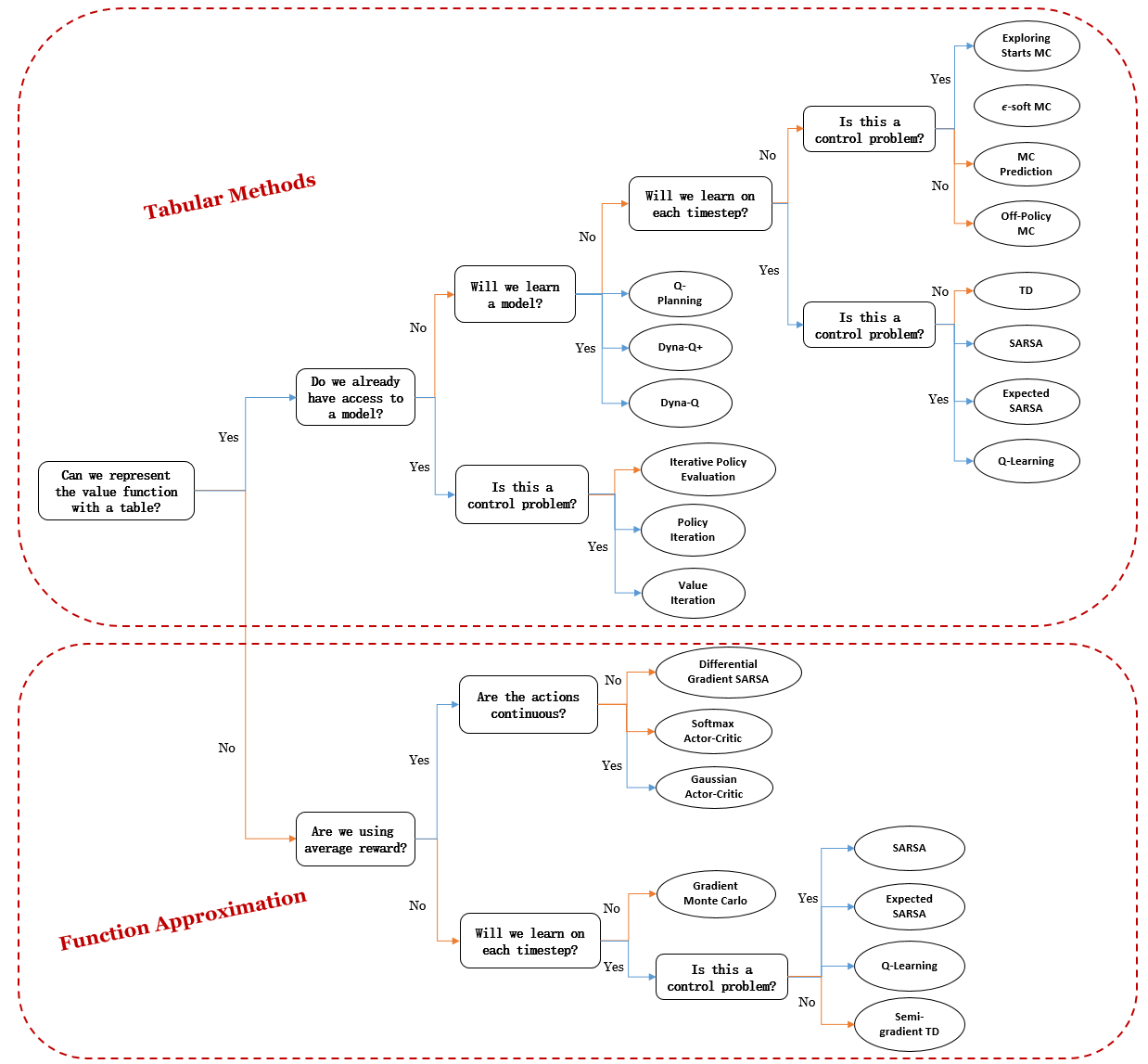
从本章开始,我们将在接下来的两章中介绍强化学习的基本概念,并在第4章至第10章展示不同的强化学习算法。下面是您将在这段学习之旅中接触到的所有算法的思维导图:
最后,为了”强化”您的学习,我特别添加了第11章,介绍深度学习时代(以及大型语言模型)中最具影响力的几个算法,这些内容在Sutton的原著中并未包含。所以,请保持兴奋,准备好开始这段学习之旅!