第2章. 多臂老虎机问题(Multi-armed Bandit)#
在本章中,我们将在一个简化的环境中研究强化学习的评价性(evaluative)问题,该环境不涉及在多种情况下学习如何动作,即只有一个单一的状态。
2.1 k臂老虎机问题#
设定:在单一状态下,你有 \(k\) 种不同的选项或动作可供选择。每次采取一个动作,都会从一个固定的概率分布中随机获得一个数值奖励。目标是在一段时间内最大化预期总奖励。
时间步(Time steps):时间步描述了采取动作的次数。
动作价值(Action value):采取该动作所获得的平均奖励
\[ q_{*}(a) \dot= E[R_{t}|A_{t}=a] \]我们假设你并不确定地知道每个动作的价值(否则问题就已经解决了)。在时间步 \(t\),你可能对动作 \(a\) 的价值有一个估计值 \(Q_t(a)\),理想情况下,\(Q_t(a)\) 应该接近 \(q_{*}(a)\)。
对于觉得这个设定比较抽象的初学者,可以观看这个可选课程视频,讲师在视频中用医生选择药物的小例子引出了这个问题。
探索与利用的权衡(Exploration vs. Exploitation):在任何强化学习问题中,我们总是需要在两个选项之间进行权衡:探索或利用。在这个设定下的解释如下:
利用(Exploitation):利用你当前对动作价值的了解,即总是选择估计价值最大的那个动作。这个动作也被称为贪心动作(greedy action)。
探索(Exploration):选择一个非贪心动作。这有时候是有益的,因为它能让你改进对非贪心动作价值的估计。
利用是在当前步骤中最大化预期奖励的正确做法,但从长远来看,探索可能会带来更大的总奖励。这种权衡在强化学习问题中几乎无处不在。我们将在2.5节中看到一些鼓励探索的技巧。
2.2 动作价值方法#
定义:用于估计动作价值并使用这些估计值来做出动作选择决策的方法被称为动作价值方法(Action-value methods)。
\(Q_{t}(a)\) 的估计:
一种自然的估计 \(Q_{t}(a)\) 的方法是使用所谓的**样本平均法(sample-average method)**对实际收到的奖励进行平均
\[\begin{split} \begin{align*} Q_{t}(a) \ &\dot= \ \frac{\text{在$t$之前采取动作$a$所获得的奖励总和}}{\text{在$t$之前采取动作$a$的次数}} \\ &= \frac{\sum_{i=1}^{t-1}R_{i} \cdot \mathbb{1}_{A_{i}=a}}{\sum_{i=1}^{t-1} \mathbb{1}_{A_{i}=a}} \end{align*} \end{split}\]动作选择方法:基于估计值选择动作有两种自然的方法,一种是最大化利用,另一种在此基础上考虑了探索:
贪心动作选择(Greedy action selection):总是利用当前的知识来最大化即时奖励
\[ A_t \dot= \underset{a}{\arg\max} Q_{t}(a) \]\(\epsilon\)-贪心动作选择(\(\epsilon\)-greedy action selection):大多数时候表现得很贪心,但每次都有一个小概率 \(\epsilon\)(\(0<\epsilon<1\) 且接近 0),我们会以相等的概率在所有动作(包括贪心动作)中随机选择。
2.3 十臂测试平台#
设置:为了证明贪心和 \(\epsilon\)-贪心动作选择的有效性,我们进行了以下实验:
我们设置 \(k = 10\),即创建一个十臂老虎机问题。
设计每个动作的奖励分布遵循标准正态分布(\(\mu = 0\) 且 \(\sigma = 1\))
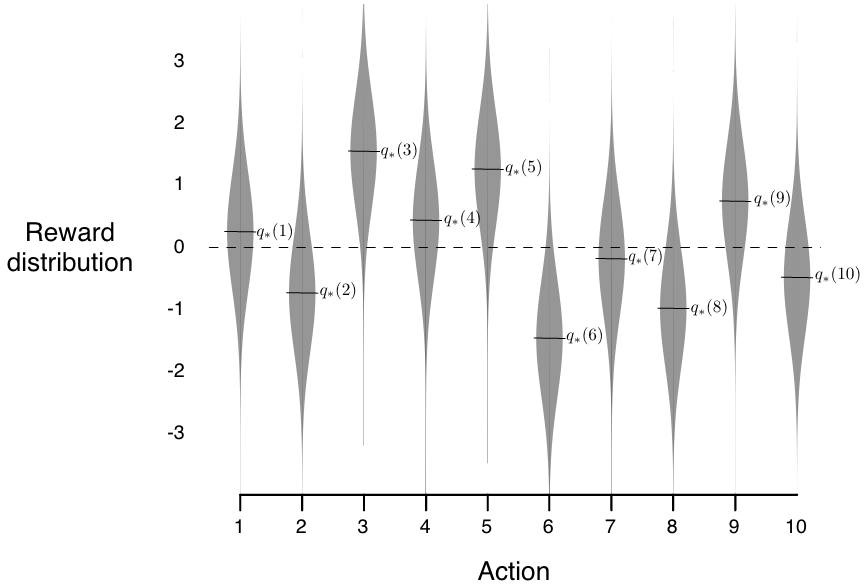
性能:每种动作选择方法的性能是通过对 2000 次独立的运行(runs)结果进行平均来衡量的,每次运行包含 1000 个时间步(回想一下,时间步描述了采取动作的次数)。
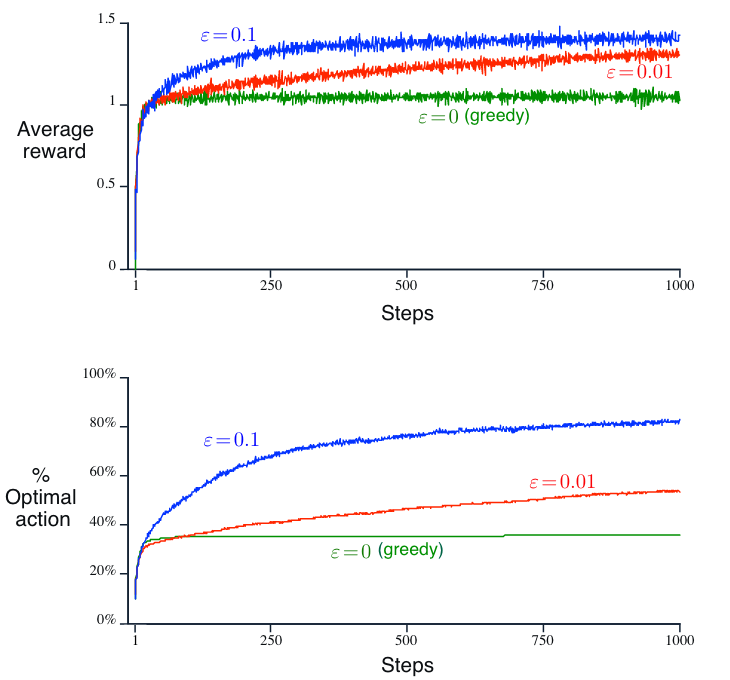
更大的 \(\epsilon\) 值表示更多的探索,并且所有选择方法都使用样本平均值作为它们的动作价值估计。从上图可以得出以下结论:
从长远来看,贪心方法的表现明显更差,因为它常常会陷入执行次优动作的困境。
\(\epsilon = 0.01\) 的方法(探索较少)改进得更慢,但最终会比 \(\epsilon = 0.1\) 的方法(探索较多)表现更好。这强调了探索和利用之间的权衡,即探索(\(\epsilon = 0.01\))可以提高性能,但过度探索(\(\epsilon = 0.1\))会使结果变差。
Note
关于探索优势的说明:取决于具体任务。
奖励方差(Reward Variance):如果奖励方差较大(奖励更具噪声),则需要更多的探索来找到最优动作,在这种情况下,\(\epsilon\)-贪心方法应该更好。相反,如果奖励方差为零,贪心方法显然会表现得最好。
平稳性(Stationarity):假设奖励的分布随时间变化(就像在下一章将介绍的马尔可夫决策过程中的不同状态一样)。在这种情况下,即使在确定性情况下也需要进行探索,以确保某个非贪心动作没有变得比贪心动作更好。
2.4 动作价值的增量估计(Incremental Implementation)#
我们现在重新审视2.2节中提到的样本平均法,并研究如何以一种计算高效的方式计算这些平均值。具体来说,我们分别在平稳和非平稳场景下研究这个问题。
2.4.1 平稳问题#
推导:设 \(R_i\) 表示在第 \(i\) 次选择动作 \(a\) 时获得的奖励,\(Q_n\) 表示在\(n - 1\) 次选择动作 \(a\) 后对该动作价值的估计。对于第 \(n\) 次动作选择:
\[\begin{split} \begin{align*} Q_{n+1} &= \frac{R_1 + R_2 + ... + R_n}{n} \\ &= \frac{1}{n}\sum_{i=1}^{n}R_i \\ &= \frac{1}{n}(R_{n} + (n - 1)\frac{1}{n - 1}\sum_{i=1}^{n - 1}R_i) \\ &= \frac{1}{n}(R_{n} + (n - 1)Q_n) \\ &= Q_n + \frac{1}{n}(R_{n} - Q_n) \quad \text{(一种增量估计)} \end{align*} \end{split}\]上述增量估计遵循一般形式:
\[ 新估计值 \leftarrow 旧估计值 + 步长(StepSize) * [目标值 - 旧估计值] \]其中步长等于 \(\frac{1}{n}\),它会随着时间步的变化而变化。在本书中,步长用 \(\alpha\) 表示,更一般地用 \(\alpha_t(a)\) 表示。
这个增量估计方程是强化学习中许多基本更新规则的一个非常有代表性的形式,将在第6章中进行深入介绍。
有了这个增量实现,我们现在可以为解决平稳老虎机问题编写如下伪代码。
算法:一个简单的老虎机算法

2.4.2 非平稳问题#
推导:如果问题是非平稳的(nonstationary),即奖励分布随时间变化,那么给近期奖励赋予比久远奖励更多的权重会更有意义。为了实现这个目标,我们可以使用一个恒定的步长参数 \(\alpha\)
\[\begin{split} \begin{align*} Q_{n+1} &= Q_n + \alpha \left[ R_n - Q_n \right] \\ &= \alpha R_n + (1 - \alpha) Q_n \\ &= \alpha R_n + (1 - \alpha) \left[ \alpha R_{n-1} + (1 - \alpha) Q_{n-1} \right] \\ &= \alpha R_n + (1 - \alpha) \alpha R_{n-1} + (1 - \alpha)^2 Q_{n-1} \\ &= \alpha R_n + (1 - \alpha) \alpha R_{n-1} + (1 - \alpha)^2 \alpha R_{n-2} + \\ &\quad \ldots + (1 - \alpha)^{n-1} \alpha R_1 + (1 - \alpha)^n Q_1 \\ &=(1 - \alpha)^n Q_1 + \sum_{i=1}^n \alpha (1 - \alpha)^{n-i} R_i \end{align*} \end{split}\]解释:
最终形式的直觉解释
最终结果仍然是一个加权平均,因为 \((1 - \alpha)^n + \sum_{i=1}^n \alpha (1 - \alpha)^{n - i} = 1\)
随着中间奖励数量的增加,即随着 \(i\) 变得更久远,赋予 \(R_i\) 的权重呈指数下降。
\(\alpha\) 的直觉解释
如果 \(\alpha = 1\),\(Q_{n + 1} = R_n\);如果 \(\alpha = 0\),\(Q_{n + 1} = Q_{n}\)。\(\alpha\) 控制着赋予近期奖励的权重。
选择 \(\alpha_n(a) = \frac{1}{n}\) 会得到样本平均法。
可选内容:关于不同 \(\alpha_n(a)\) 选择下估计收敛性的研究,请参考原书第2.5章。一般来说,由于现实中的非平稳性,实际上更希望 \(\alpha_n(a)\) 使估计永远不会收敛。
2.5 更多探索技巧#
除了 \(\epsilon\)-贪心算法(或作为其扩展)之外,还有两种简单的鼓励探索的技巧。请注意,由于后续各小节将解释的原因,它们仅适用于平稳问题。
2.5.1 乐观初始值法(Optimistic Initial Values)#
定义:该方法通过将初始动作值设置为一个较大的正数来鼓励探索(仅在开始阶段)。
性能表现:例如,在2.3节介绍的十臂老虎机测试平台中,我们现在将所有动作 \(a\) 的 \(Q_1(a)\) 都设置为 \(+5\)(这是非常乐观的估计,因为动作值是由标准正态分布给出的)。使用与之前相同的设置再次进行实验,即对 2000 次运行结果进行平均,每次运行包含 1000 个时间步。
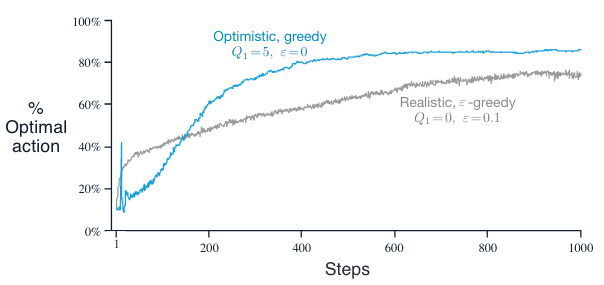
起初,乐观初始值法的表现较差,因为它进行了更多的探索,但最终它的表现会更好,因为随着时间的推移,其探索程度会降低。
在开始阶段,由于频繁探索,乐观初始值法的最优动作选择比例会急剧上升。
特性:
它不太适合非平稳问题,因为其探索驱动力本质上是暂时的,即仅在运行开始阶段有效。
尽管如此,这些简单的方法(包括样本平均法),或者其中之一,或者它们的某种简单组合,在实践中通常就足够了。
2.5.2 上置信界动作选择法(Upper-Confidence-Bound Action Selection)#
定义:该方法通过考虑动作的不确定性来进行探索,公式如下:
\[ A_t \dot= \underset{a}{\arg\max} [Q_{t}(a) + c\sqrt{\frac{\ln(t)}{N_t(A)}}] \]\(t\) 表示当前时间步
\(N_t(A)\) 表示截至时间步 \(t\) 动作 \(A\) 被选择的次数
\(c > 0\) 控制探索的程度
原理直觉:
命名约定:平方根项是对动作 \(a\) 值的不确定性(uncertainty)或方差的一种度量。因此,被最大化的量是动作 \(a\) 可能真实值的一种上界(upper bound),\(c\) 决定了置信水平。
工作机制:
每次选择动作 \(a\) 时,其不确定性预计会降低:\(N_t(a)\) 增加,由于它出现在分母中,不确定性项会减小。
另一方面,每次选择除 \(a\) 之外的动作时,动作 \(a\) 的不确定性估计会增加,导致其动作值估计变大,在后续选择中该动作会被更多地探索。
所有动作最终都会被选择,但估计值较低或已经被频繁选择的动作,随着时间的推移,其被选择的频率会降低。简而言之,不确定性越大,探索越多,而探索又会反过来降低不确定性。
性能表现:
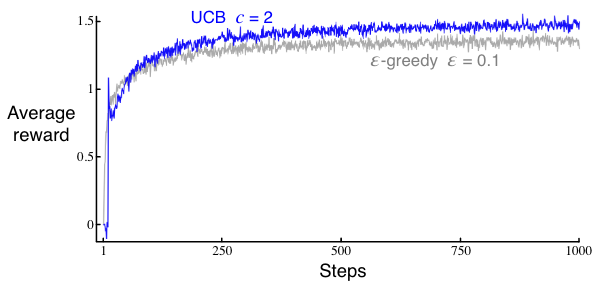
除了在前 \(k\) 步随机选择尚未尝试过的动作之外,上置信界法通常比 \(\epsilon\)-贪心动作选择法表现更好。
与乐观初始值法类似,上置信界法在实验开始阶段也会导致平均奖励突然增加。这是因为上置信界法用乐观的上置信界初始化每个动作(当 \(N_t(a)\) 较小时,\(c\sqrt{\frac{\ln(t)}{N_t(A)}}\) 相当大),使得所有动作在开始时都具有较高的值,从而被探索。
特性:由于以下原因,与 \(\epsilon\)-贪心算法相比,上置信界法更难从多臂老虎机问题扩展到本书其余部分所考虑的更一般的强化学习场景:
处理非平稳问题的难度:对于上置信界法,\(N_t(a)\) 会随时间累积。这意味着较旧的观测值在估计奖励 \(Q_t(a)\) 中占主导地位。如果奖励分布随时间发生变化,上置信界法不能快速适应,即它会继续利用过时的”最优”动作,而不是重新进行探索。
处理大状态空间的难度:当动作数量较多或由于环境变化需要频繁重新评估动作时,上置信界法的计算成本可能会很高。
2.6 总结#
本章介绍了多臂老虎机问题(Multi-armed Bandit),这是一个简化的强化学习问题,在该问题中,智能体需要在 \(k\) 个动作中进行选择,每个动作都有一个未知的奖励分布。目标是在平衡利用和探索的同时,随着时间的推移最大化总奖励。
关键要点
探索与利用的权衡
贪心算法最大化即时奖励,但可能会陷入局部最优。
\(\epsilon\)-贪心算法以概率 \(\epsilon\)(在所有动作中平均分配)随机探索,以寻找更好的动作。
更好的探索方法
乐观初始值法(Optimistic Initial Values):从较高的初始值开始,鼓励早期探索。
上置信界法(Upper-Confidence-Bound, UCB):更频繁地探索不确定性较高的动作。
高效学习
样本平均更新适用于稳定的奖励情况。
恒定步长(\(\alpha\))更新能适应变化的奖励情况。
额外课程视频(可选):乔纳森·兰福德:现实世界强化学习中的上下文老虎机