第4章. 动态规划#
术语”动态规划”(Dynamic Programming, DP)指的是一类算法,这些算法可以在给定环境的完美模型(以马尔可夫决策过程(MDP)的形式)的情况下,用于计算最优策略,因此它不需要与环境进行交互。
动态规划算法在实际应用中存在局限性,因为它们假设存在完美模型,并且计算成本很高。然而,动态规划为理解本书其余部分介绍的方法提供了重要基础。事实上,所有这些方法都可以看作是试图实现与动态规划大致相同的效果,只是计算量更少,并且不假设存在环境的完美模型。
动态规划以及强化学习的关键思想是使用价值函数来组织和构建对良好策略的搜索。正如我们将看到的,动态规划算法是通过将贝尔曼方程(如下面这些方程)转化为赋值语句得到的,也就是说,转化为用于改进所需价值函数近似值的更新规则。
4.1 策略评估(Policy Evaluation,预测问题/Prediction Problem)#
策略评估:计算任意策略 \(\pi\) 的状态价值函数 \(v_\pi\)。(我们也将此称为预测问题(Prediction Problem)。)
动态规划假设环境的动态特性是完全已知的(环境的完美模型),在这种情况下,我们可以使用贝尔曼方程形成一个包含 \(|S|\) 个方程和 \(|S|\) 个未知数的联立线性方程组。 初始近似值 \(v_0\) 可以任意选择(除非存在终止状态,终止状态的值必须设为 0):
\[\begin{split} \begin{align*} v_{k + 1}(s) &= E_{\pi}[R_{t + 1} + \gamma v_{k}(S_{t + 1}) | S_t = s] \\ &= \sum_a \pi(a|s) \sum_{s', r}p(s', r|s, a) [r + \gamma v_{k}(s')] \text{ 对于所有 } s \in S \end{align*} \end{split}\]上述算法称为迭代策略评估(Iterative Policy Evaluation)。字母 \(k\) 表示迭代次数。
动态规划算法中的所有更新都称为期望更新(Expected Update),因为它们基于对所有可能的下一个状态的期望,而不是基于一个采样的下一个状态。
在一次迭代中对所有状态进行的更新称为对状态空间的一次扫描(Sweep)。
用于估计 \(V \approx v_\pi\) 的迭代策略评估算法
算法:

直观理解:\(\Delta\) 在每次迭代开始时会被设为 0,用于记录状态空间中所有状态值的最大变化。因此,当一次扫描中的最大变化小于阈值 \(\theta\) 时,算法停止。我们得到一个近似的最优价值函数 \(V \approx v_{\pi_\star}\)。
网格世界示例:如果你觉得策略评估过程中扫描的图示难以理解,可以观看这个课程视频。
描述:
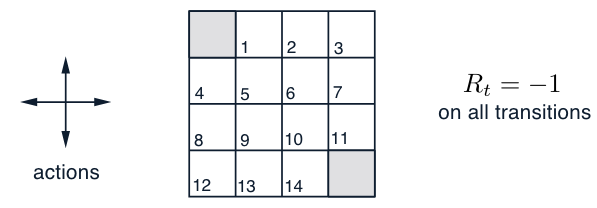
状态:非终止状态为 \(S = \{1, 2, ..., 14\}\)。
动作:每个状态有四种可能的动作,\(A = \{上, 下, 右, 左\}\),这些动作会确定性地导致相应的状态转移,除非动作会使智能体移出网格,在这种情况下,状态保持不变。
例如,\(p(6, -1|5, 右) = 1\),\(p(7, -1|7, 右) = 1\),并且对于所有 \(r \in R\),\(p(10, r|5, 右) = 0\)。
奖励:这是一个无折扣的回合制任务。在到达终止状态之前,所有转移的奖励都是 \(-1\)。因此,期望奖励函数为 \(r(s, a, s') = -1\),对于所有状态 \(s, s'\) 和动作 \(a\)。
策略:等概率随机策略(equiprobable random policy,所有动作的概率均为 0.25)。
策略评估:
第一次扫描:
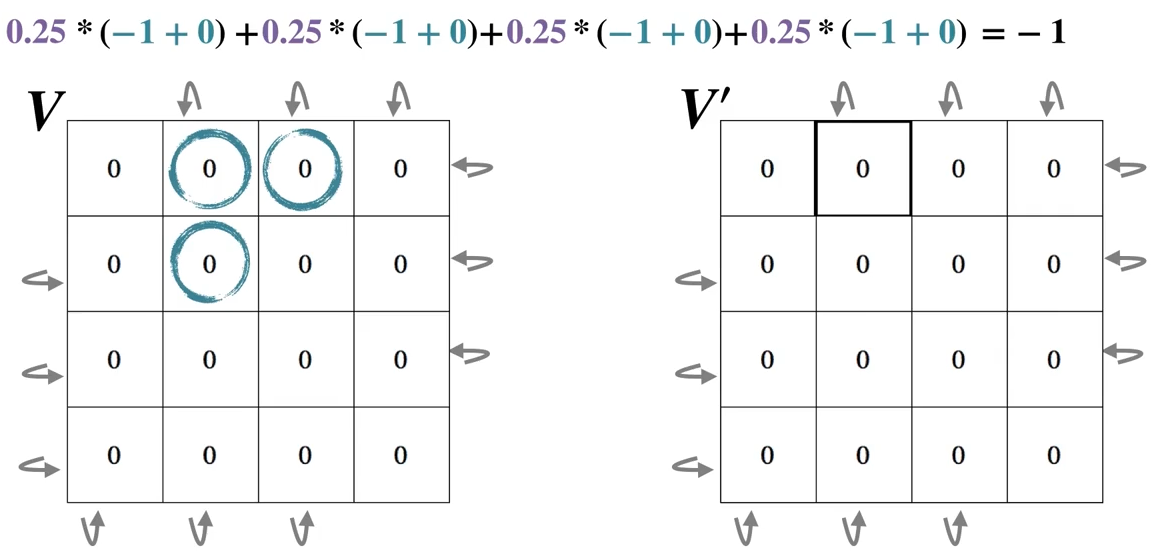
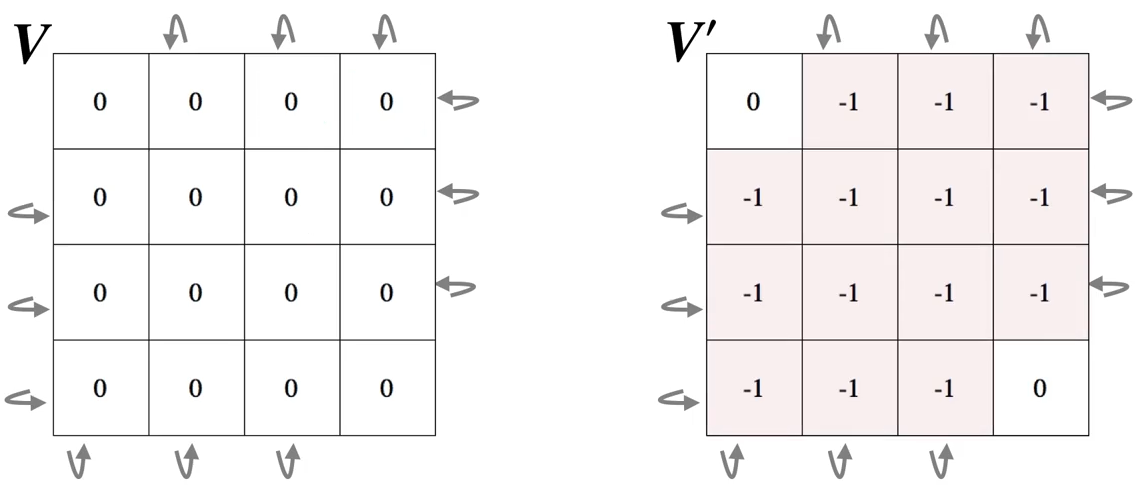
第二次扫描:
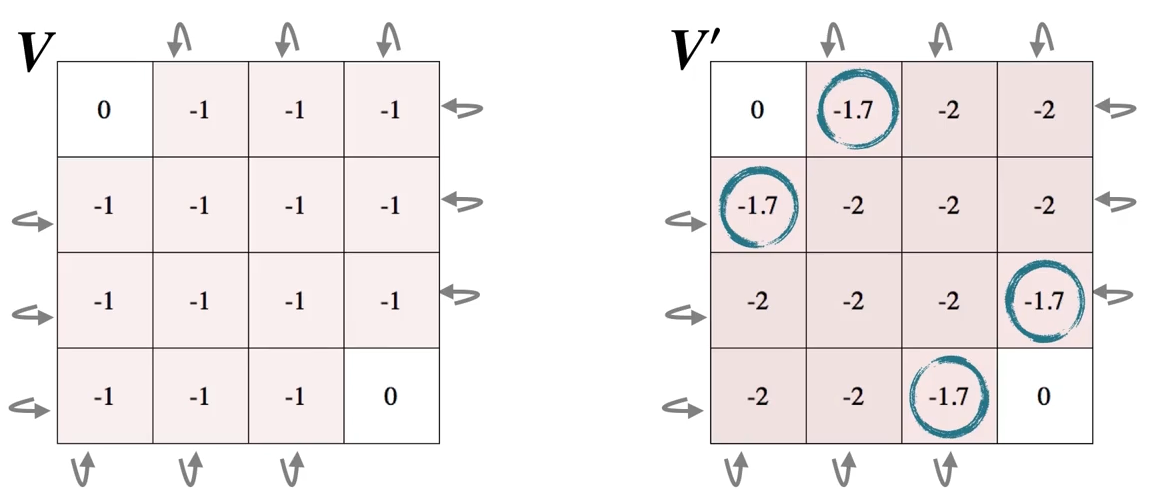
第三次扫描:
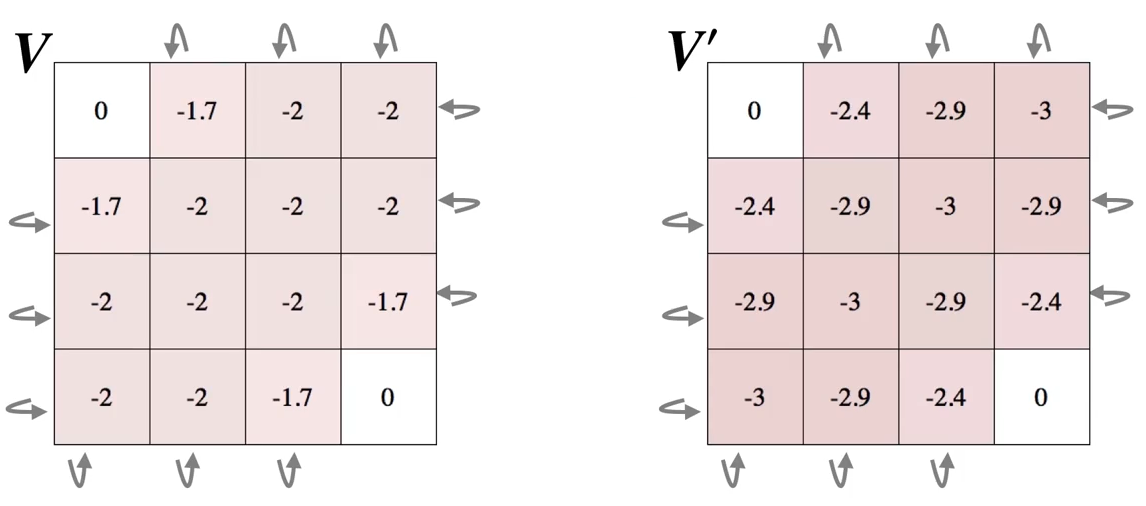
…
最后一次扫描:\(\Delta = 0\) 且最终小于 \(\theta\),\(V\) 和 \(V'\) 均为 \(V_\pi\)
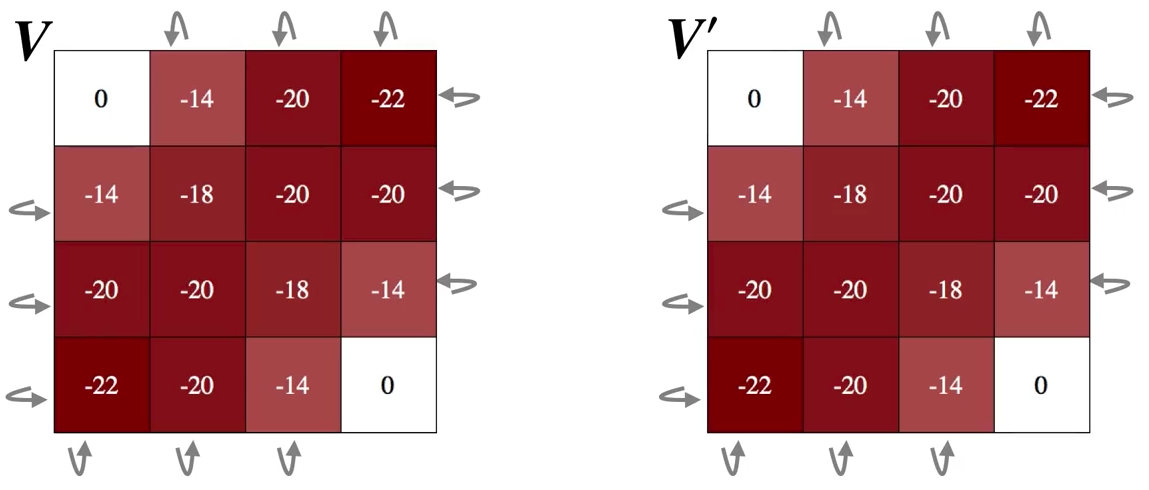
4.2 策略改进(Policy Improvement)#
策略改进定理(Policy Improvement Theorem):如果对于所有 \(s \in S\),都有 \(q_\pi(s, \pi'(s)) \ge v_\pi(s)\) 成立,那么策略 \(\pi'\) 一定与 \(\pi\) 一样好,或者比 \(\pi\) 更好。换句话说,对于所有 \(s \in S\),\(v_{\pi'}(s) \ge v_\pi(s)\) 也成立。
不等式 \(q_\pi(s, \pi'(s)) \ge v_\pi(s)\) 的直观理解是(回想下面从 \(v(s)\) 开始的备份图),存在一个(或多个)明确的动作,对于状态 \(s\) 来说,这些动作能带来比简单计算期望更多的回报(因为 \(v(s) = \sum_a \pi(a|s)q(s, a)\))。
策略改进:通过相对于原始策略的价值函数使其变得贪婪,从而创建一个比原始策略更优的新策略的过程。
贪婪化(Greedification):用 \(\pi'\) 表示贪婪化后的策略:
\[\begin{split} \begin{align*} \pi'(s) &= \arg\max_a q_\pi(s, a) \\ &= \arg\max_a E_{\pi}[R_{t + 1} + \gamma v_\pi(S_{t + 1}) | S_t = s] \\ &= \arg\max_a \sum_{s', r} p(s', r|s, a)[r + \gamma v_\pi(s')] \end{align*} \end{split}\]策略改进将导致一个严格更优的策略,除非原始策略已经是最优策略:
假设新策略与旧策略一样好,但不比旧策略更好(最终策略不能再改进),即 \(v_{\pi'} = v_\pi\),那么:
\[\begin{split} \begin{align*} v_{\pi'} &= \max_a \sum_{s', r} p(s', r|s, a)[r + \gamma v_\pi(s')] \\ &= \max_a \sum_{s', r} p(s', r|s, a)[r + \gamma v_{\pi'}(s')] \end{align*} \end{split}\]上述最后一个方程正是贝尔曼最优方程,这意味着当策略不能再改进时,\(v_{\pi'}\) 就是 \(v_\star\),因此,\(\pi\) 和 \(\pi'\) 都是最优策略 \(\pi_\star\)。
如果一个策略相对于其自身的价值函数已经是贪婪策略,那么这个策略就是最优策略。
4.1 节 中的网格世界示例(续,课程视频可选)
在得到初始随机策略 \(\pi\) 的价值函数 \(v_\pi\) 后,我们进行贪婪化以得到新策略 \(\pi'\)(用白色箭头表示),根据策略改进的性质,\(\pi'\) 严格优于 \(\pi\)。

通过这样做,我们现在已经成功地改进了我们的原始策略(进行了一次迭代)。
4.3 策略迭代(Policy Iteration,控制/Control)#
策略迭代:迭代地执行策略评估和策略改进以找到最优策略的过程。
由于有限马尔可夫决策过程(MDP)只有有限数量的策略,此过程必定会在有限的迭代次数内收敛到最优策略和最优价值函数。用 \(E\) 表示评估,\(I\) 表示改进,该过程如下:
\[ \pi_0 \xrightarrow{\text{E}} v_{\pi_0} \xrightarrow{\text{I}} \pi_1 \xrightarrow{\text{E}} v_{\pi_1} \xrightarrow{\text{I}} ... \xrightarrow{\text{I}} \pi_\star \xrightarrow{\text{E}} v_\star \]策略迭代算法:

新的网格世界示例:同样,如果你觉得这些内容过于抽象,可以观看这个课程视频,它会提供更详细、更清晰的讲解。
描述:
4.1节中的网格世界示例实际上仅需一次迭代就能达到最优策略。现在,我们让这个示例稍微复杂一些:移除一个终止网格,并添加奖励值显著更低(为 \(-10\))的蓝色状态。
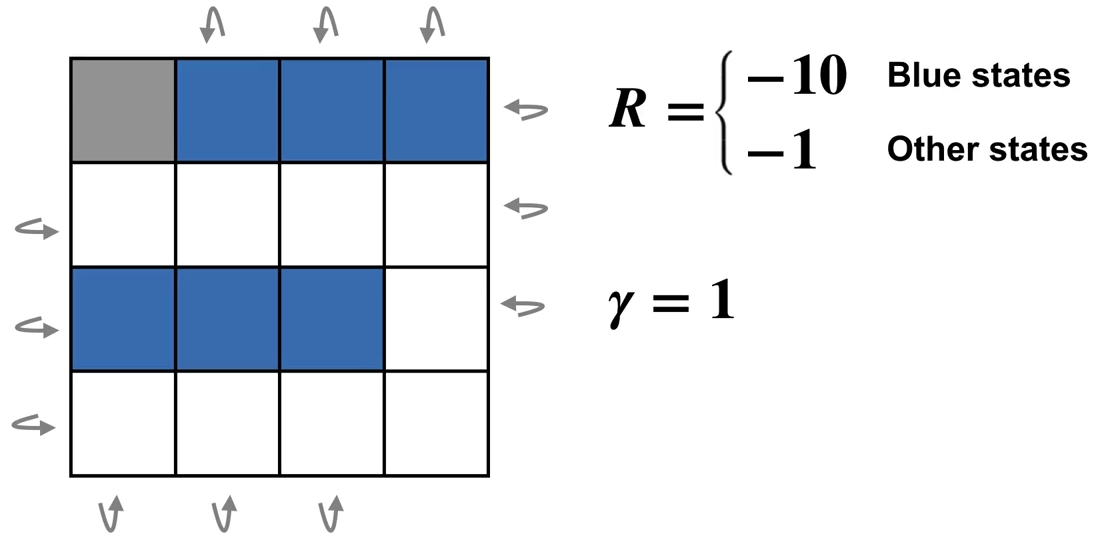
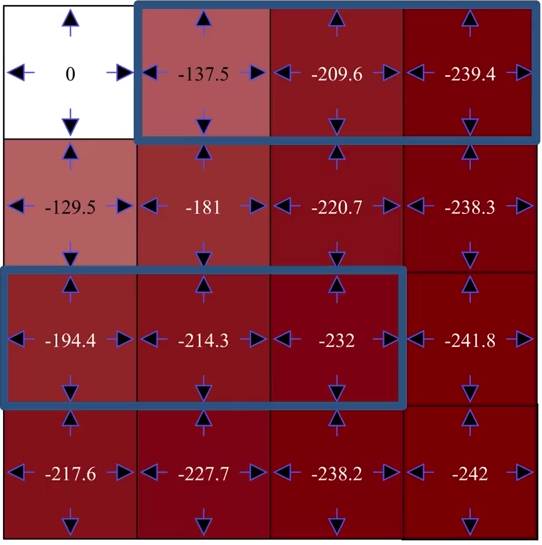
策略迭代:
第一次迭代:
评估
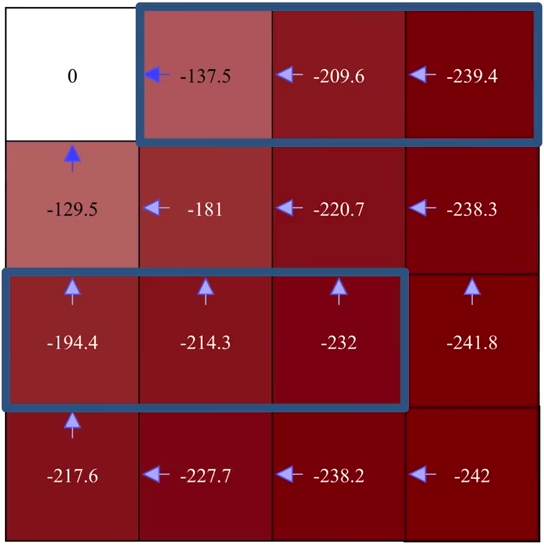
改进
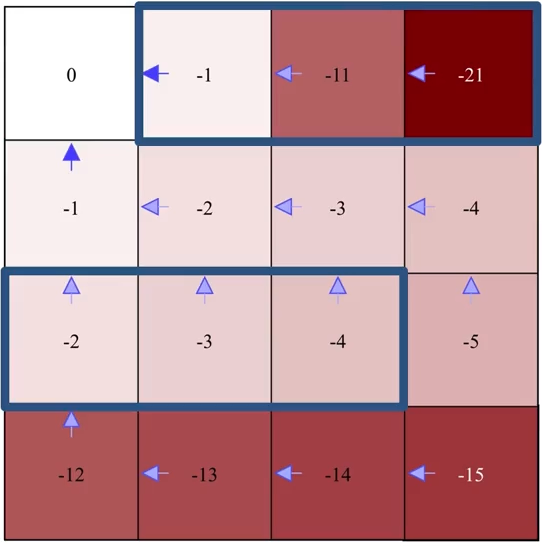
第二次迭代:
注意贪婪化具体是如何执行的(例如,最后一行的第二个左网格)。 请记住,\(\pi'(s) = \arg\max_a \sum_{s', r} p(s', r|s,a)[r + \gamma v_\pi(s')]\) 而不是 \(\pi'(s) = \arg\max_a v(s')\),所以不要仅仅因为某个状态 \(s'\) 的值 \(v(s')\) 更高,就简单地朝着该状态贪婪地选择一个动作。
评估
改进
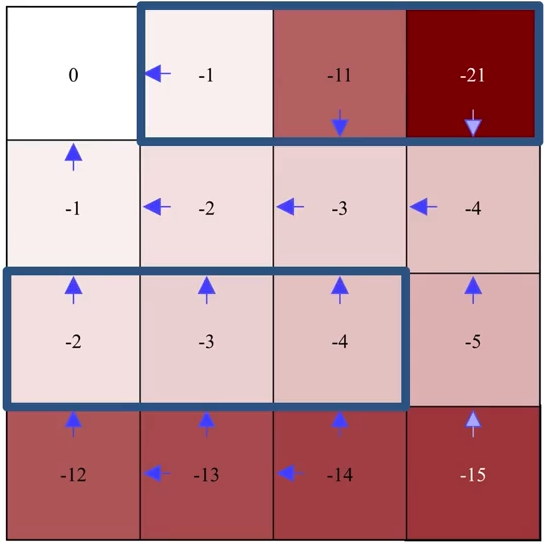
…
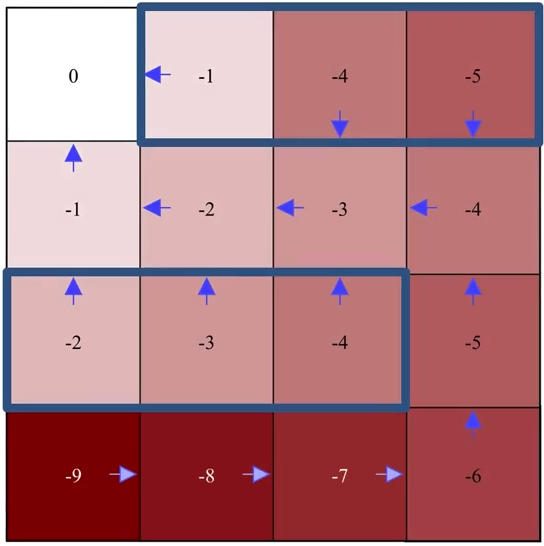
最后一次迭代:
注意在最后一次迭代中,经过策略改进后,策略保持不变,即(改进前的)原始策略已经是相对于其自身价值函数的贪婪策略,此时已找到最优策略。
评估
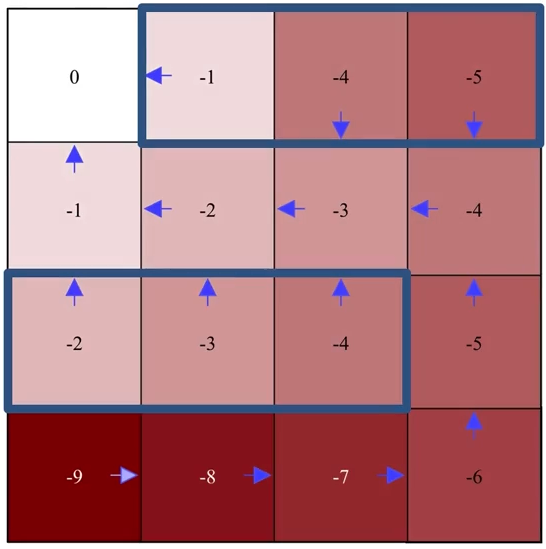
改进
4.4 值迭代(Value Iteration)#
值迭代:是策略迭代的一种特殊情况,其中策略评估仅进行一次扫描后就停止。
策略迭代的缺点:需要迭代计算,其每次迭代都涉及策略评估,而策略评估本身可能是一个漫长的迭代计算过程,需要对状态集进行多次扫描,并且只有在极限情况下才会收敛,这会花费大量时间。
值迭代在每次扫描中有效地融合了一次策略评估扫描和一次策略改进扫描。
更新规则:
\[\begin{split} \begin{align*} V_{k + 1}(s) &\dot= \max_a q_{k}(s, a) \\ &= \max_a \sum_{s', r} p(s', r|s,a) [r + \gamma V_{k}(s')] \text{对于所有} s \in S \end{align*} \end{split}\]请注意,上述方程只是将贝尔曼最优方程转化为了一个更新规则。
值迭代算法:

4.5 广义策略迭代(Generalized Policy Iteration,GPI)#
\(\star\) 两种动态规划类型:
同步动态规划(Synchronous DP):按特定顺序系统地更新所有状态(对于大状态空间而言,所需时间极长)。
异步动态规划(Asynchronous DP):无顺序地更新状态(可能更快,但当仅持续更新一小部分状态时也会出现问题)。
广义策略迭代(GPI):指的是让策略评估和策略改进过程相互作用的通用思想,而不考虑这两个过程的粒度和其他细节。
几乎所有强化学习方法都可以很好地用广义策略迭代来描述。也就是说,所有方法都有可识别的策略和价值函数,策略总是相对于价值函数进行改进,而价值函数总是朝着该策略的价值函数方向发展:
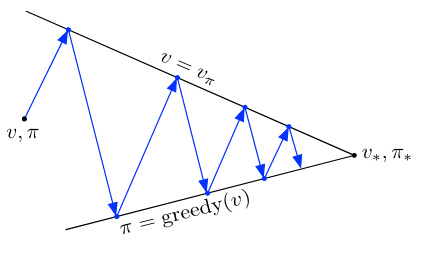
只有当找到一个相对于其自身评估函数是贪婪的策略时(即当 \(\pi\) 本身是 \(v_\pi\) 的贪婪策略时),这两个过程才会稳定下来。这意味着状态价值函数的贝尔曼最优方程成立,因此该策略和价值函数是最优的。
4.6 总结#
经典的动态规划方法通过对状态集进行扫描来操作,对每个状态执行一次期望更新(Expected Update)操作。状态的更新基于后继状态值的估计。也就是说,估计值是基于其他估计值进行更新的。我们将这种通用思想称为自举法(Bootstrapping)(这是许多强化学习算法中非常基础的概念,我们将在第6章中深入介绍),并且它需要环境的完美模型。
在下一章中,我们将探索蒙特卡洛方法——一种不需要模型且不使用自举法的强化学习方法。现在,快速总结如下:
当前内容思维导图:
关键要点:
动态规划概述:
使用环境的完美模型(马尔可夫决策过程/MDP)计算最优策略。
无需与环境交互;计算成本高,但为强化学习奠定了重要理论基础。
核心思想是使用价值函数和贝尔曼方程作为更新规则来持续优化策略。
策略评估(预测):
为给定策略 \(\pi\) 迭代估计其状态价值函数 \(v_\pi\):
\[ v_{k + 1}(s) = \sum_a \pi(a|s) \sum_{s', r} p(s', r | s, a) [r + \gamma v_k(s')] \]当 \(v(s)\) 的变化小于阈值 \(\theta\) 时停止迭代。
策略改进:
基于当前价值函数 \(v_\pi\) 创建一个贪婪策略 \(\pi'\):
\[ \pi'(s) = \arg\max_a \sum_{s', r} p(s', r | s, a) [r + \gamma v_\pi(s')] \]如果无法进一步改进,则当前策略 \(\pi\) 已达到最优。
策略迭代:
通过在策略评估和策略改进之间交替进行,直至收敛:
\[ \pi_0 \rightarrow v_{\pi_0} \rightarrow \pi_1 \rightarrow v_{\pi_1} \rightarrow \ldots \rightarrow \pi_* \rightarrow v_* \]值迭代:
一种简化的策略迭代方法,每次迭代仅进行一次扫描:
\[ V_{k + 1}(s) = \max_a \sum_{s', r} p(s', r | s, a) [r + \gamma V_k(s')] \]最终收敛到最优价值函数 \(V_*\) 和最优贪婪策略 \(\pi_*\)。
广义策略迭代(GPI):
策略评估和策略改进过程的持续交互与相互作用。
当策略相对于其自身价值函数达到贪婪状态时,整个过程趋于稳定。
额外课程视频(可选):沃伦·鲍威尔:用于车队管理的近似动态规划(Long)