第 6 章 时序差分学习#
时序差分(Temporal-Difference, TD)学习结合了蒙特卡洛(Monte Carlo, MC)方法和动态规划(Dynamic Programming, DP)的思想。像蒙特卡洛方法一样,时序差分方法可以直接从原始经验中学习,不需要环境模型;像动态规划方法一样,时序差分方法在更新估计时部分依赖于其他已经学习到的估计值,而不必等到最终结果(即它们使用自举更新(bootstrap))。
和往常一样,我们首先关注策略评估或预测问题,即在给定策略 \(\pi\) 的情况下估计其状态价值函数 \(v_\pi\) 的问题。对于控制问题(寻找最优策略),动态规划、时序差分和蒙特卡洛方法都使用某种形式的广义策略迭代(Generalized Policy Iteration, GPI)。这些方法之间的差异主要体现在它们解决预测问题的方式上。
6.1 时序差分预测#
为了引入时序差分方法,首先回顾 $\( \begin{align} v_{\pi}(s) &\dot= E[G_t | S_t = s] \\ &= E[R_{t+1} + \gamma G_{t+1}| S_t = s] \\ &= E[R_{t+1} + \gamma v_{\pi}(S_{t+1})| S_t = s] \end{align} \)$
蒙特卡洛方法(Monte Carlo methods) 使用公式(1)的估计作为目标:
\(V(S_t) \leftarrow V(S_t) + \alpha (G_t - V(S_t))\),其中 \(G_t\) 是每个回合中的一次实际回报。
动态规划方法(Dynamic Programming methods) 使用公式(3)的估计作为目标: \(V(s) = \sum_a \pi(a|s) \sum_{s', r} p(s',r|s,a) [r + \gamma V(s')]\)
时序差分方法(Temporal Difference methods) 也使用公式(3)的估计,但不需要环境模型,通过以下方式结合了上述两种方法:
\(V(S_t) \leftarrow V(S_t) + \alpha (R_{t+1} + \gamma V(S_{t+1}) - V(S_t))\),其中 \(R_{t+1} + \gamma V(S_{t+1})\) 是 \(R_{t+1} + \gamma v_\pi(S_{t+1})\) 的一次实际取值。
时序差分更新的目标是 \(R_{t+1} + \gamma V(S_{t+1})\),这种时序差分方法称为 TD(0) 或一步TD(one-step TD),它是 TD(\(\lambda\)) 或 n步TD 的特例(本教程未涉及)。
时序差分结合了蒙特卡洛的采样和动态规划的自举更新(bootstrapping):
时序差分和蒙特卡洛都涉及对后继状态(或状态–动作对)进行采样,即它们都使用 \(\textit{采样更新(sample update)}\),而不像动态规划那样使用 \(\textit{期望更新(expected update)}\)。
蒙特卡洛方法必须等到整个回合结束后才能确定 \(V(S_t)\) 的更新量(因为只有那时 \(G_t\) 才可知),而时序差分和动态规划方法只需等到下一个时间步,即它们使用自举更新(bootstrap)。
术语\(\delta_t = R_{t+1} + \gamma V(S_{t+1}) - V(S_t)\)称为\(\textit{TD误差(TD error)}\)。\(\delta_t\)是\(V(S_t)\)的误差,在时间\(t+1\)即可获得。
用于估计\(v_\pi\)的表格型TD(0)算法(Tabular TD(0)):
算法:

Note
注意时序差分与蒙特卡洛算法的区别,现在不再需要生成整个回合。相反,一旦采取了动作并观察到新状态,就会立即更新 $V(s)$,也就是说,时序差分方法是以"逐步(step-wise)"的方式工作的。
驾车回家示例 (点击观看讲座视频)
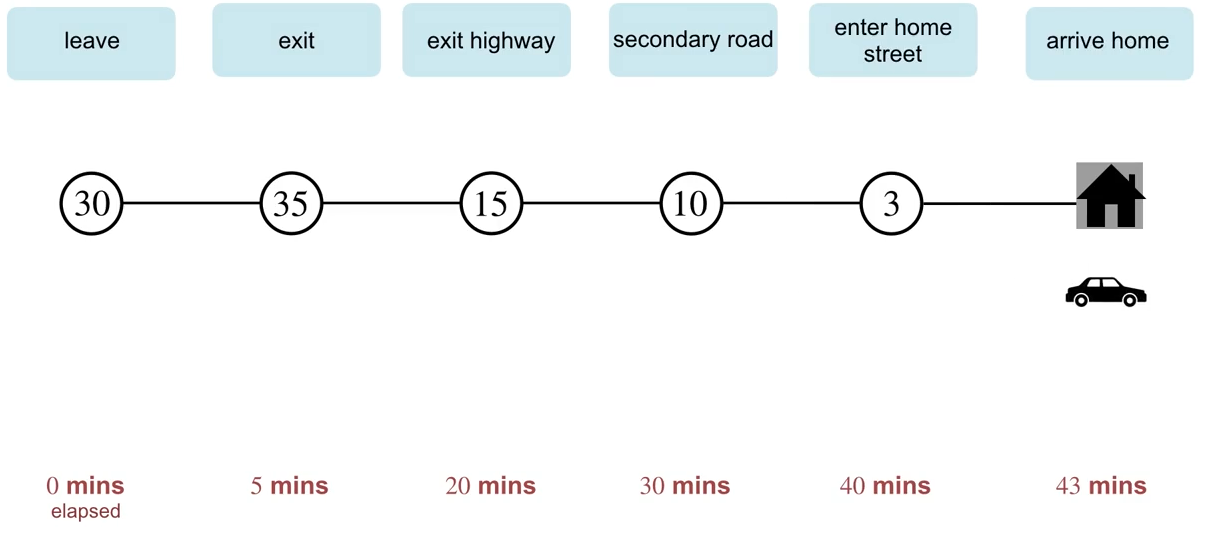
时序差分预测的优势:
相较于动态规划:时序差分方法不需要环境的模型;相较于蒙特卡洛方法:时序差分方法可以天然地以在线、完全增量的方式实现,即不需要等到回合结束。
对于任意固定策略 \(\pi\),TD(0) 已被证明会收敛到 \(v_\pi\)。详细内容请参考教材第6.2章,本教程中略去证明。
在实际中,时序差分方法在随机任务中通常比常数步长的蒙特卡洛方法收敛得更快。一个示例性视频如下所示:
6.2 时序差分控制#
6.2.1 Sarsa: 同策略时序差分控制#
Sarsa的背景:
由于时序差分方法适用于没有环境模型的任务,因此自然会估计 \(Q_\pi(s,a)\) 而不是 \(V_\pi(s)\)。类似于第6.1节,Sarsa的更新规则如下:
\[Q(S_t, A_t) \leftarrow Q(S_t, A_t) + \alpha [R_{t+1} + \gamma Q(S_{t+1}, A_{t+1}) - Q(S_t, A_t)]\]其中若 \(S_t\) 是终止状态,则 \(Q(S_t, A_t)=0\)。
Sarsa命名的由来:上述更新规则使用了状态–动作对转移中的五元组事件(\(S_t,A_t,R_{t+1},S_{t+1},A_{t+1}\))的每一项。这五元组构成了名称Sarsa(State,Action,Reward,State,Action)的由来。
与其他任意同策略方法类似,我们持续对行为策略\(\pi\)估计\(q_\pi\),同时将\(\pi\)逐步调整为对\(q_\pi\)趋于贪婪(即广义策略迭代(GPI)的模式)。
Sarsa(同策略时序差分控制)用于估计 \(Q \approx q_\star\)

Note
不需要在一开始初始化策略 \(\pi\),当所有 \(Q(s,a)\) 都已知时,可以直接根据给定策略选取动作,其中 \(s \in S, a \in A(s)\)。
在选取下一个动作时,要确保使用一个软策略(soft-policy)以保证探索。
注意,在转移到状态 \(S'\) 后,仍需执行另一个动作 \(A'\),才能更新 \(Q(S,A)\)。
只要所有状态–动作对被访问无限次,且策略最终收敛于贪婪策略,Sarsa以概率1收敛至最优策略和动作价值函数(例如,通过设置 \(\epsilon = 1/t\) 的 \(\epsilon\)-贪婪策略来实现)。
示例:有风网格世界中的Sarsa
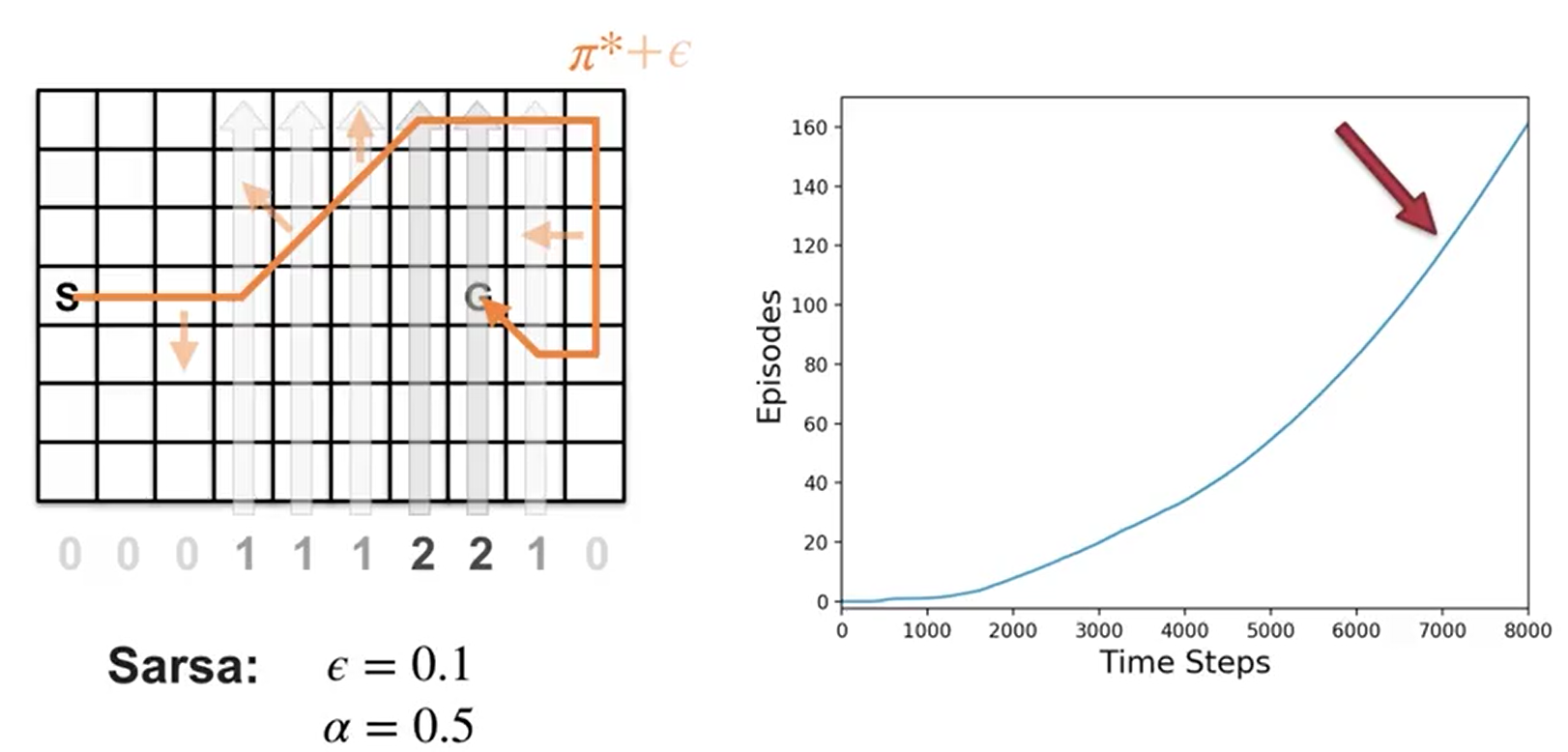
注意,前几个回合可能需要几千步才能完成。随着曲线逐渐变陡,说明每个回合完成得越来越快。
注意回合完成速率停止上升。这意味着智能体的策略在最优策略附近徘徊,但由于探索的存在,不会完全达到最优。
6.2.2 Q-learning(Q学习):异策略时序差分控制#
Q-learning的背景:
Q-learning 的更新规则为:
\[Q(S_t, A_t) \leftarrow Q(S_t, A_t) + \alpha [R_{t+1} + \gamma \max_a Q(S_{t+1}, a) - Q(S_t, A_t)]\]这种直接逼近 \(q_\star\) 的方式大大简化了算法的分析,并促成了早期的收敛性证明。正确收敛所需的唯一条件是所有状态–动作对持续被更新(即保持探索)。
\(Q\)-learning(异策略时序差分控制)用于估计 \(\pi \approx \pi_\star\)

Note
- **与Sarsa不同的是,在目标状态 $S'$,Q-learning 直接选择使 $Q(S', a)$ 最大化的贪婪动作**,而不是根据从 $Q$ 导出的策略选择(虽然由 $Q$ 导出的策略也可以是贪婪策略,如果是这样,Sarsa和Q-learning的更新规则是相同的)。 - **Q-learning 为什么是异策略(off-policy)的?** 将当前 $Q$ 导出的策略视为 $\textit{行为策略}$,例如 $\epsilon$-贪婪策略,但Q-learning的 $\textit{目标策略}$ 实际上是根据更新规则中的最大值项选择的贪婪策略(动作根据 $\epsilon$-贪婪选择,更新则依据贪婪策略)。想了解Q-learning为何是离策略的读者可参考此[讲座视频](https://www.coursera.org/learn/sample-based-learning-methods/lecture/1OikH/how-is-q-learning-off-policy)示例:有风网格世界中的 Q-learning
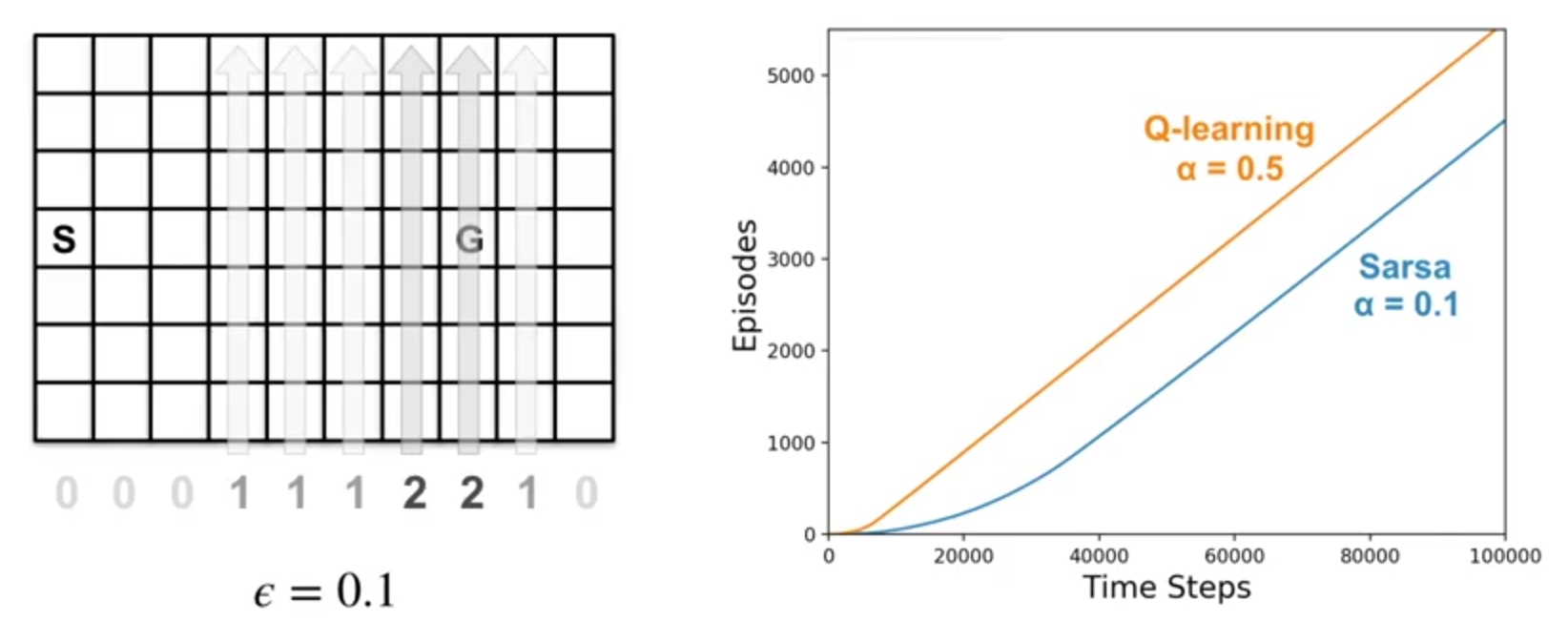
刚开始时,两种算法的学习速度相近。到后期,Q-learning 似乎学得了更优的最终策略。
当我们减小步长参数 \(\alpha\),Sarsa 学习到的最终策略与 Q-learning 相同,但收敛更慢。此实验凸显了强化学习中参数选择的重要性。\(\alpha\)、\(\epsilon\)、初始值和实验长度都可能影响最终结果。
悬崖漫步示例 —— Sarsa 与 Q-learning 的另一对比
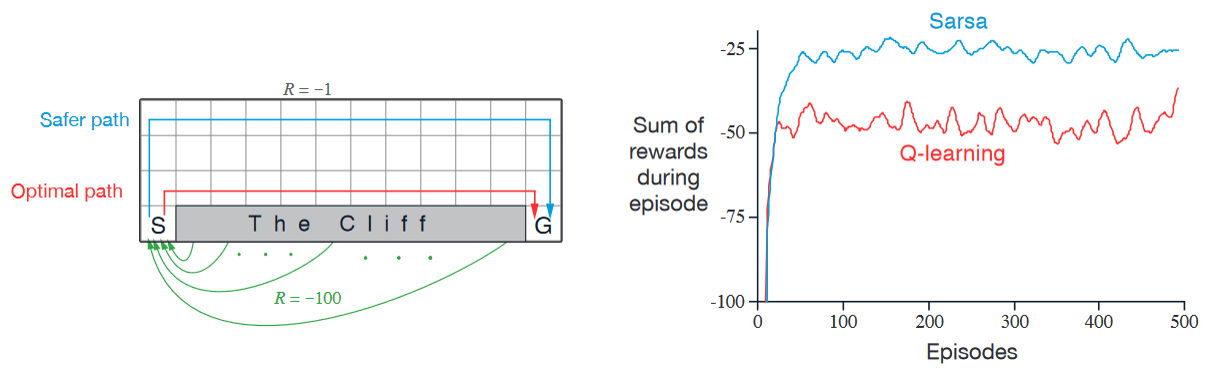
描述:
状态与目标:智能体从左下角状态 \(S\) 出发,试图到达右下角的目标点 \(G\)。
动作:上、下、左、右。
奖励:除进入标记为”悬崖”区域的转移奖励为 \(-100\) 外,所有转移奖励均为 \(-1\)。
性能比较:
Q-learning(红色):学习得到的策略是沿悬崖边缘向右移动的最优策略,但因 \(\epsilon\)-贪婪动作选择,有时会掉下悬崖。
Sarsa(蓝色):学习较长但更安全的路径,绕过网格上方。
虽然 Q-learning 实际学习到了最优策略的价值,但其在线表现却不如学习绕行策略的Sarsa。当然,如果逐渐减小 \(\epsilon\),则两者最终都会渐进收敛至最优策略。
6.2.3 期望 Sarsa (Expected Sarsa)#
期望 Sarsa的背景:
更新规则:
\[\begin{split} \begin{align*} Q(S_t, A_t) \leftarrow Q(S_t, A_t) + \alpha [R_{t+1} + \gamma E_\pi[Q(S_{t+1}, A_{t+1})|S_{t+1})] - Q(S_t, A_t)] \\ \leftarrow Q(S_t, A_t) + \alpha [R_{t+1} + \gamma \sum_{a}\pi(a|S_{t+1}) Q(S_{t+1}, a) - Q(S_t, A_t)] \end{align*} \end{split}\]给定下一个状态 \(S_{t+1}\),该更新确定性地沿着Sarsa的期望方向移动,因此称为期望 Sarsa(Expected Sarsa)。
期望Sarsa在计算上比Sarsa更复杂,但它消除了由于随机选择动作 \(A_{t+1}\) 而产生的方差。在相同经验量的情况下,期望Sarsa的表现通常略优于Sarsa。
期望Sarsa用于估计 \(\pi \approx \pi_\star\)
算法参数: 步长 \(\alpha \in (0,1], \epsilon > 0\)
初始化 \(Q(s,a)\), 对于所有 \(s \in S^+, a \in A(s)\)
遍历每个回合:
初始化 \(S\)
遍历每一步:
使用 \(Q\) 导出的策略(如 \(\epsilon\)-贪婪策略)从 \(S\) 选择 \(A\)
执行动作 \(A\), 观察到 \(R, S'\)
\(Q(S, A) \leftarrow Q(S, A) + \alpha [R + \gamma \sum_{a}\pi(a|S') Q(S', a) - Q(S, A)]\)
\(S \leftarrow S'\)
直到 \(S\) 终止
Note
该算法与 Q-learning 类似,但它不是取下一状态动作对的最大值,而是计算期望值,考虑当前策略下各动作的可能性。
期望 Sarsa 的有趣之处在于,它既可以是同策略,也可以是异策略。上述算法为同策略的情形,但一般情况下,期望 Sarsa 可以使用与目标策略 \(\pi\) 不同的策略来生成行为,此时它就成为异策略算法。
例如,若 \(\pi\) 是贪婪策略,而行为策略更具探索性,则期望 Sarsa 恰好等同于 Q-learning。
从这个意义上讲,期望 Sarsa 包含并推广了 Q-learning,同时在性能上优于 Sarsa。除了计算开销略有增加外,期望 Sarsa 很可能完全优于其他两种更为知名的时序差分控制算法。
悬崖漫步示例中的比较:
下图展示了三种时序差分控制方法在悬崖漫步任务中,随步长参数 \(\alpha\) 变化的中期和渐近性能表现。
三种算法均使用 \(\epsilon\)-贪婪策略,\(\epsilon=0.1\)。
渐近性能为100,000回合的平均结果,再对10次运行取平均。
中期性能为前100回合的平均结果,再对50,000次运行取平均。
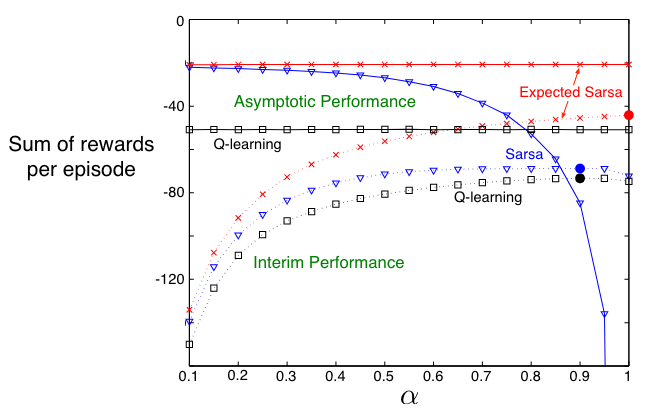
期望 Sarsa 保留了 Sarsa 相比于 Q-learning 在该问题上的显著优势。在悬崖漫步中,状态转移是确定性的,所有随机性仅来自策略。在这种情况下,期望 Sarsa 可以安全地设置 \(\alpha = 1\) 而不影响渐近性能;而 Sarsa 只能在较小的 \(\alpha\) 值下长期表现良好,但其短期性能较差。
6.3 总结#
本章介绍的方法是如今最为广泛使用的强化学习方法。这很可能归功于它们的极简特性:它们可在线应用,计算量极小,直接基于与环境交互产生的经验;且几乎可以用单个方程完全表达,便于通过小型程序实现。
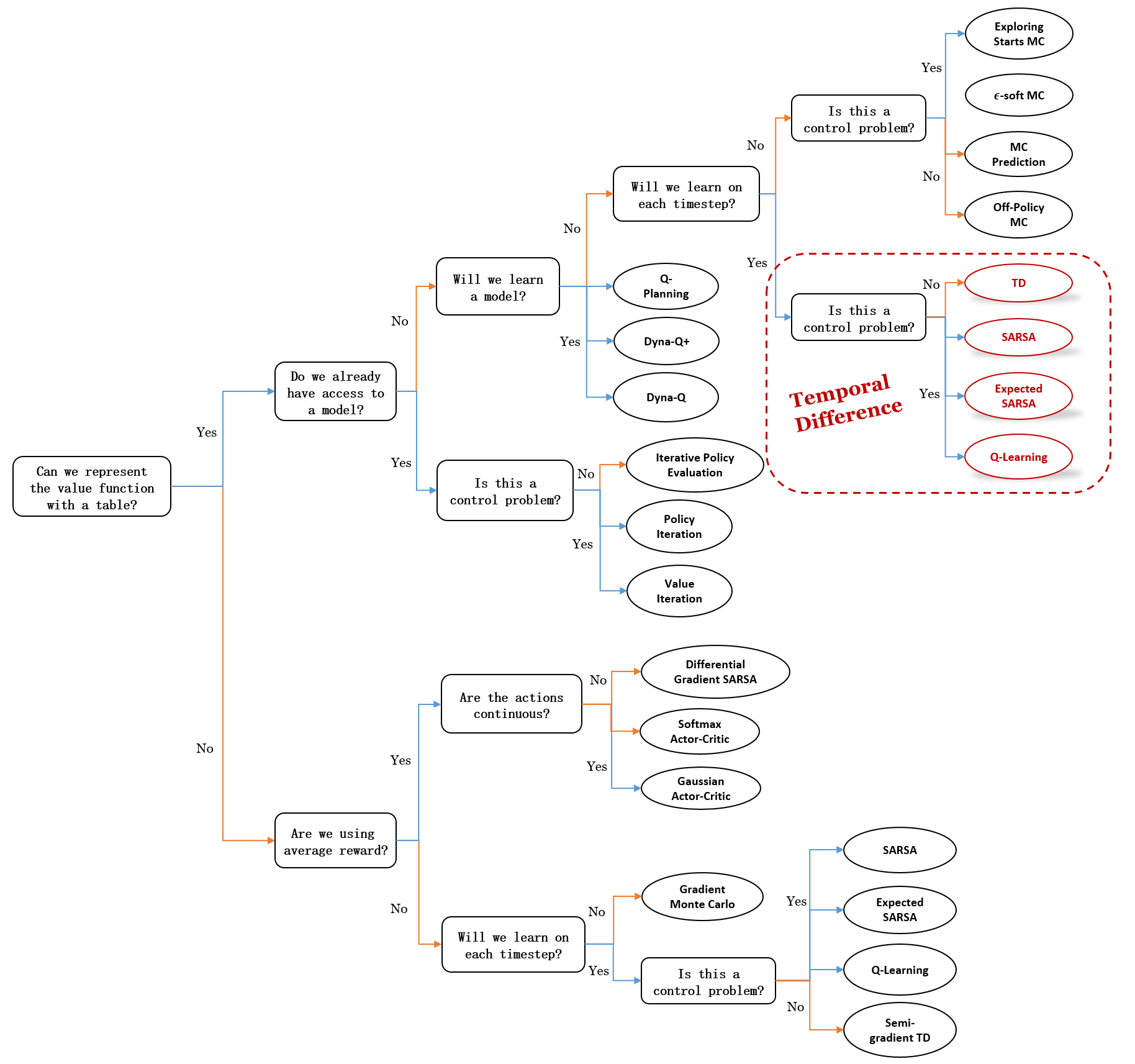
本章介绍的时序差分方法特例应称为\(\textit{单步、表格型、无模型}\)时序差分方法。下一章我们将扩展至包含环境模型的形式,但目前,简要总结如下:
思维导图:我们现在的位置
关键要点
时序差分预测(TD(0))
每步更新价值估计:
\[V(S_t) \leftarrow V(S_t) + \alpha (R_{t+1} + \gamma V(S_{t+1}) - V(S_t))\]时序差分误差(\(\delta_t\))衡量预测值与更新值之间的差异。
优点:无需环境模型,增量更新,收敛速度快于蒙特卡洛方法。
时序差分控制方法
Sarsa(同策略):基于当前策略更新。更安全,但可能找不到最优路径。
\[Q(S_t, A_t) \leftarrow Q(S_t, A_t) + \alpha [R_{t+1} + \gamma Q(S_{t+1}, A_{t+1}) - Q(S_t, A_t)]\]Q-learning(异策略):利用最大未来奖励更新。学习最优策略,但探索时风险较大。
\[Q(S_t, A_t) \leftarrow Q(S_t, A_t) + \alpha [R_{t+1} + \gamma \max_a Q(S_{t+1}, a) - Q(S_t, A_t)]\]期望 Sarsa:使用期望未来奖励,降低方差,提升稳定性。
\[Q(S_t, A_t) \leftarrow Q(S_t, A_t) + \alpha [R_{t+1} + \gamma \sum_a \pi(a|S_{t+1}) Q(S_{t+1}, a) - Q(S_t, A_t)]\]比较
Sarsa 学习到的策略较为保守,适合存在风险的环境。
Q-learning 能够找到最优策略,但由于探索带来的风险,其在线表现可能较差。
期望 Sarsa 兼顾了两者的优点,性能稳定且额外计算开销较小。
收敛性:只要探索充分且学习率设置合理,所有方法都能收敛至最优策略。
额外讲座视频(可选):Rich Sutton:时序差分学习的重要性