第8章. 使用近似方法进行同策略预测#
在本章中,我们将重点关注如何根据同策略数据(on-policy data)来估计状态价值函数。近似价值函数不再以表格形式呈现,而是 采用参数化的函数形式(parametric function form),记为 \(\hat{v}(s, \boldsymbol{w}) \approx v_\pi(s)\),其中 \(\boldsymbol{w} \in \mathbb{R}^d\) 是权重向量(weight vector)。
例如,\(\hat{v}\) 可能是一个关于状态特征的线性函数,\(\boldsymbol{w}\) 就是特征权重向量。更一般地,\(\hat{v}\) 可能是由多层人工神经网络计算得到的函数,\(\boldsymbol{w}\) 则是所有层中的连接权重向量。
通常情况下,权重的数量(即 \(\boldsymbol{w}\) 的维度)远小于状态的数量(\(d << |S|\)),并且改变一个权重会影响多个状态的估计值。因此,当更新单个状态时,这种改变会从该状态泛化到其他许多状态,进而影响它们的价值。这种泛化特性使得学习过程可能更强大,但同时也更难管理和理解。
8.1 价值函数近似#
更新规则回顾:
动态规划: \(s \rightarrow E_\pi[R_{t+1} + \gamma \hat{v}(S_{t+1}, \boldsymbol{w}_t)|S_t = s]\)
蒙特卡罗方法: \(s \rightarrow G_t\)
时序差分方法: \(s \rightarrow R_{t+1} + \gamma \hat{v}(S_{t+1}, \boldsymbol{w}_t)\)
用于函数近似的监督学习
我们将每次更新解释为指定价值函数所需的输入 - 输出(\(s\rightarrow u\))行为的一个示例,其中 \(u\) 表示 更新目标(update target)。
在函数近似中,我们将每次更新的输入 - 输出行为 \(s\rightarrow u\) 作为一个训练示例,然后将训练后得到的近似函数解释为估计的价值函数。
预测目标(\(\overline{VE}\))
动机:由于我们假设状态数量远多于权重数量,因此提高一个状态的估计精度必然会降低其他状态的估计精度。所以,我们必须明确指出哪些状态对我们来说最为重要。
衡量指标:平均平方价值误差(mean squared value error,\(\overline{VE}\)),公式如下:
\[ \overline{VE}(\boldsymbol{w}) = \sum_{s \in S} \mu(s)[v_\pi(s) - \hat{v}(s,\boldsymbol{w})]^2 \]其中,状态分布 \(\mu(s) \ge 0\) 且 \(\sum_s \mu(s)=1\),称为 同策略分布(on-policy distribution),它表示我们对每个状态 \(s\) 的误差的关注程度。通常情况下,\(\mu(s)\) 被选择为在状态 \(s\) 上花费的时间比例。
Note
最适合寻找更优策略的价值函数并不一定是最小化 \(\overline{VE}\) 的函数。不过,目前还不清楚价值预测更有用的替代目标是什么。就目前而言,我们将重点关注 \(\overline{VE}\)。
对于像神经网络这样的复杂函数逼近器,我们通常无法找到一个全局最优(global optimum)的 \(\boldsymbol{w}_\star\),使得对于所有的 \(\boldsymbol{w}\) 都有 \(\overline{VE}(\boldsymbol{w}_\star) \le \overline{VE}(\boldsymbol{w})\)。相反,我们只能找到一个局部最优解(local optimum),即在 \(\boldsymbol{w}_\star\) 的某个邻域内,对于所有的 \(\boldsymbol{w}\) 都有 \(\overline{VE}(\boldsymbol{w}_\star) \le \overline{VE}(\boldsymbol{w})\),但通常这已经足够了。
8.2 随机梯度和半梯度方法#
梯度下降方法的设置:
权重向量是一个列向量,包含固定数量的实值分量,记为 \(\boldsymbol{w} \dot= (w_1,w_2,...,w_d)^T\)。(注意,在本书中,除非明确以水平形式写出或进行转置,否则向量通常被视为列向量。)
近似价值函数 \(\hat{v}(s,\boldsymbol{w})\) 对于所有的 \(s \in S\) 都是关于 \(\boldsymbol{w}\) 的可微函数。
随机梯度方法(stochastic gradient descent,SGD)
设置:假设在每一步,我们观察到一个新的示例 \(S_t \rightarrow v_\pi(S_t)\),它由一个(可能是随机选择的)状态 \(S_t\) 及其在策略下的真实值组成。
SGD 方法:
更新规则:
\[\begin{split} \begin{align} \boldsymbol{w_{t+1}} &\dot= \boldsymbol{w_t} - \frac{1}{2} \alpha \nabla[v_\pi(S_t) - \hat{v}(S_t, \boldsymbol{w_t})]^2 \\ &= \boldsymbol{w_t} + \alpha [v_\pi(S_t) - \hat{v}(S_t, \boldsymbol{w_t})]\nabla\hat{v}(S_t, \boldsymbol{w_t}) \end{align} \end{split}\]
Note
在实际应用中,显然不可能直接得到 \(v_\pi(S_t)\)。实际上,只要目标是 \(v_\pi(S_t)\) 的无偏估计,即 \(E[Target | S_t=s] = v_\pi(S_t)\),那么在通常的随机近似条件下(随着 \(\alpha\) 逐渐减小),\(\boldsymbol{w_t}\) 保证收敛到一个局部最优解(关于收敛的主题不在 DistilRL 中讨论,请参考书籍的第 2.7 章获取详细信息)。
根据定义,蒙特卡罗目标 \(G_t\) 是 \(v_\pi(S_t)\) 的无偏估计器。
用于估计 \(\hat{v} \approx v_\pi\) 的梯度蒙特卡罗算法

半梯度方法(semi-gradient methods):
设置:训练示例 \(S_t \rightarrow U_t\),其中 \(U_t \in \mathbb{R}\) 不是真实值 \(v_\pi(S_t)\) 而是使用 \(\hat{v}\) 的自举目标(bootstrapped target)
半梯度方法:
更新规则:
\[\begin{split} \begin{align} \boldsymbol{w_{t+1}} &\dot= \boldsymbol{w_t} - \frac{1}{2} \alpha \nabla[U_t - \hat{v}(S_t, \boldsymbol{w_t})]^2 \\ &= \boldsymbol{w_t} + \alpha [U_t - \hat{v}(S_t, \boldsymbol{w_t})]\nabla\hat{v}(S_t, \boldsymbol{w_t}) \end{align} \end{split}\]
Note
如果使用 \(v(S_t)\) 的自举估计作为目标 \(U_t\),则不能保证像随机梯度方法那样收敛。自举方法使用 \(\hat{v}(S_{t+1}, \boldsymbol{w_t})\) 作为目标,这依赖于当前的 \(\boldsymbol{w_t}\)。然而,从等式 \((1)\) 到 \((2)\) 的推导需要关于 \(\boldsymbol{w_t}\) 的独立性。
换句话说,自举方法考虑改变权重向量 \(\boldsymbol{w_t}\) 对估计的影响,但忽略其对目标的影响。它们只包含梯度的一部分,因此,我们称它们为 \(\textit{半梯度方法}\)。
尽管半梯度(自举)方法不如梯度方法那样稳健地收敛,但它们确实在重要情况下(如线性情况)可靠地收敛,并且由于自举相对于蒙特卡罗方法的优势,在实践中通常更受欢迎。
用于估计 \(\hat{v} \approx v_\pi\) 的半梯度 TD(0) 算法

示例:状态聚合#
状态聚合(state aggregation):一种通过将状态分组来实现函数近似泛化的方法,同一组内的状态共享一个估计值。
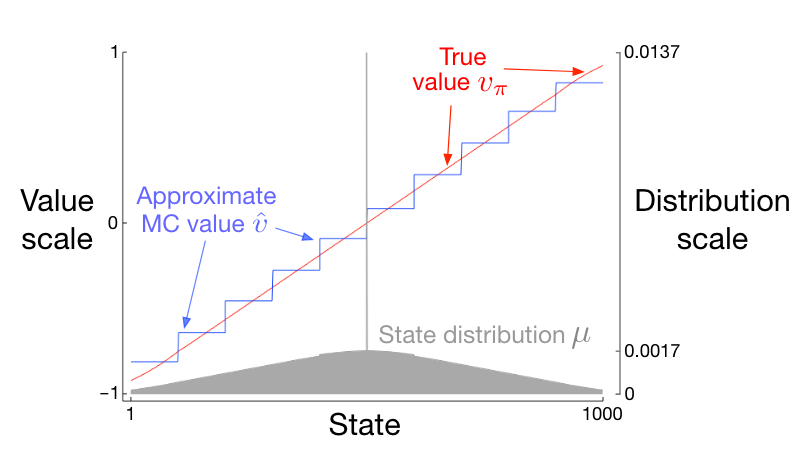
将状态聚合用于梯度蒙特卡罗方法(课程视频):
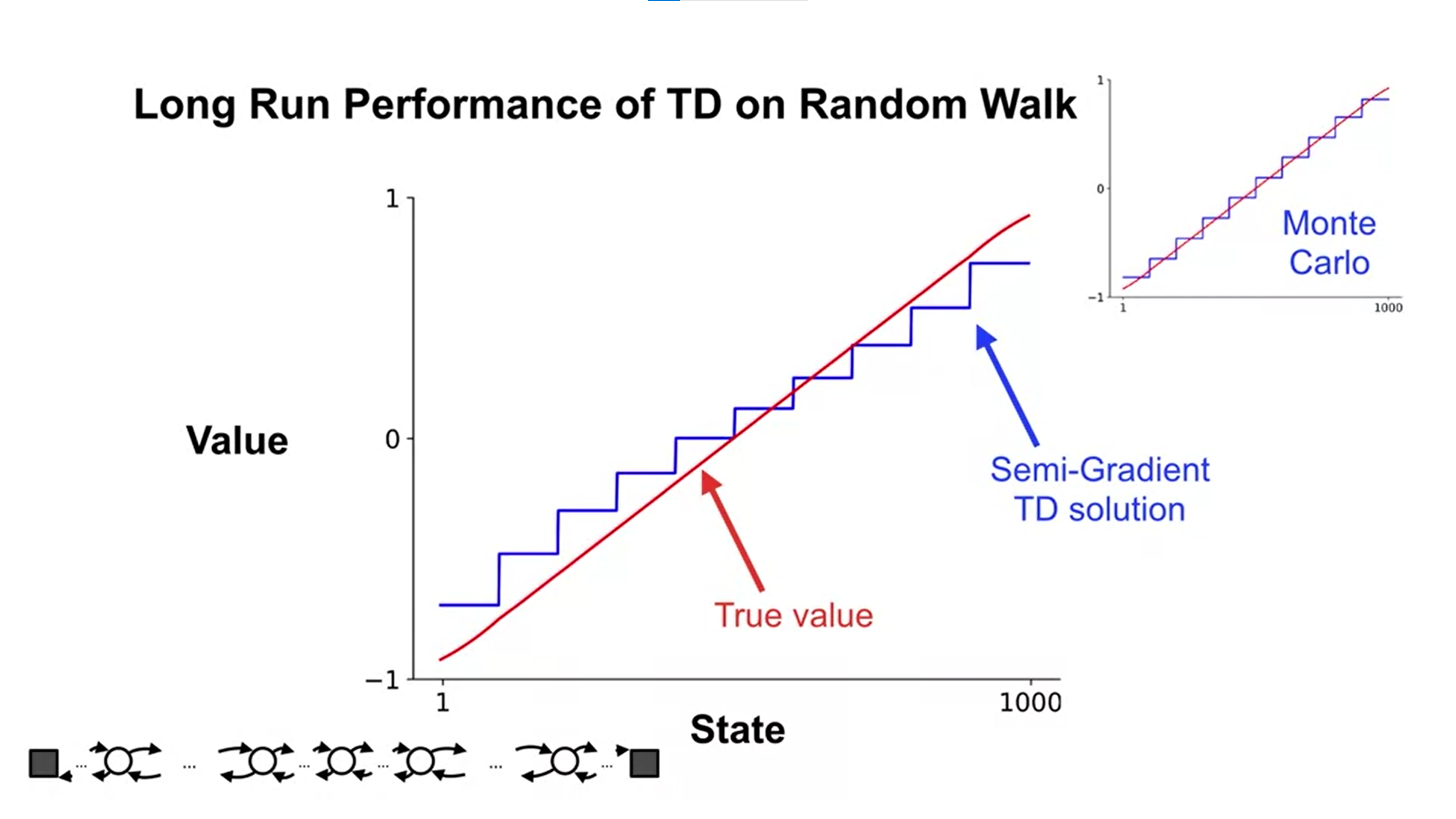
将状态聚合用于半梯度 TD 方法(课程视频):
额外课程视频(可选):Doina Precup:利用强化学习为人工智能智能体构建知识
8.3 线性模型#
线性方法:线性方法将价值函数 \(\hat{v}(s, \boldsymbol{w})\) 近似为一个线性函数,即 \(\boldsymbol{w}\) 与特征向量 \(\boldsymbol{x}(s)\) 的内积,公式如下:
\[ \hat{v}(s, \boldsymbol{w}) \dot= \boldsymbol{w}^{T} \boldsymbol{x}(s) \dot= \sum_{i=1}^d w_i x_i(s) \]在这种情况下,近似价值函数被称为 权重线性(weighted linear),或简称为 线性。
特征向量 \(\boldsymbol{x}(s) \dot= (x_1(s), x_2(s), ... x_d(s))^{T}\) 与权重向量 \(\boldsymbol{w}\) 具有相同的维度 \(d\)。每个特征 \(x_i: S \rightarrow \mathbb{R}\) 是一个所谓的 基函数(basis function),它为状态 \(s\) 分配一个值(\(x_i(s)\))。
线性价值函数的(半)梯度方法
更新规则:
\[\begin{split} \begin{align*} \boldsymbol{w_{t+1}} &\dot= \boldsymbol{w_t} + \alpha [U_t - \hat{v}(S_t, \boldsymbol{w_t})]\nabla\hat{v}(S_t, \boldsymbol{w_t}) \\ &= \boldsymbol{w_t} + \alpha [U_t - \hat{v}(S_t, \boldsymbol{w_t})]\boldsymbol{x}(S_t) \\ \end{align*} \end{split}\]收敛性:
蒙特卡罗方法:如果 \(\alpha\) 随时间按照通常的条件减小,那么上一节中介绍的梯度蒙特卡罗算法在线性函数近似下收敛到 \(\overline{VE}\) 的全局最优解。
TD(0) 方法:权重向量最终收敛到局部最优解附近的一个点。
更新规则:
\[\begin{split} \begin{align*} \boldsymbol{w_{t+1}} &\dot= \boldsymbol{w_t} + \alpha [R_{t+1} + \gamma \hat{v}(S_{t+1}, \boldsymbol{w_t}) - \hat{v}(S_t, \boldsymbol{w_t})]\boldsymbol{x_t} \\ &= \boldsymbol{w_t} + \alpha [R_{t+1} + \gamma \boldsymbol{w_t}^{T}\boldsymbol{x_{t+1}} - \boldsymbol{w_t}^{T}\boldsymbol{x_{t}}]\boldsymbol{x_t} \\ &= \boldsymbol{w_t} + \alpha [R_{t+1}\boldsymbol{x_{t}} - \boldsymbol{x_{t}}(\boldsymbol{x_{t}} - \gamma \boldsymbol{x_{t+1}})^{T}\boldsymbol{w_{t}}]\\ \end{align*} \end{split}\]注意:为了简化表示,\(\boldsymbol{x_t}\) 用来表示 \(\boldsymbol{x}(S_t)\)。
稳态(收敛)情况:
\[ E[\boldsymbol{w_{t+1}}|\boldsymbol{w_{t}}] = \boldsymbol{w_{t}} + \alpha(\boldsymbol{b - Aw_{t+1}}) \]其中 \(\boldsymbol{b} \dot= E[R_{t+1}\boldsymbol{x_{t}}] \in \mathbb{R}^d\),\(\boldsymbol{A} \dot= E[\boldsymbol{x_{t}}(\boldsymbol{x_{t}} - \gamma \boldsymbol{x_{t+1}})^{T}] \in \mathbb{R}^d \times \mathbb{R}^d\)。 并且在收敛时:
\[\begin{split} \begin{align*} & \Rightarrow \quad \mathbf{b} - \mathbf{A}\mathbf{w}_{\text{TD}} = \mathbf{0} \\ & \Rightarrow \quad \mathbf{b} = \mathbf{A}\mathbf{w}_{\text{TD}} \\ & \Rightarrow \quad \mathbf{w}_{\text{TD}} \dot= \mathbf{A}^{-1}\mathbf{b}. \end{align*} \end{split}\]
Note
\(\mathbf{w}_{\text{TD}} \dot= \mathbf{A}^{-1}\mathbf{b}\) 被称为 TD 不动点(TD fixed point)。线性半梯度 TD (0) 方法收敛到这个点。
已经证明(在连续情况下),在 TD 不动点处,\(\overline{VE}\) 处于最小可能误差的有界扩展范围内:
\[ \overline{VE}(\mathbf{w}_{\text{TD}}) \le \frac{1}{1-\gamma} \underset{\boldsymbol{w}}{min}\overline{VE}(\boldsymbol{w}) \]由于 \(\gamma\) 通常接近 1,这个扩展因子可能相当大,因此 TD 方法在渐近性能上可能会有显著损失。
8.4 线性方法的特征构建#
为任务选择合适的特征是将先验领域知识融入强化学习系统的重要方法。直观地说,特征应该对应于状态空间中适合进行泛化(generalization)的方面。
线性形式的一个局限性是它无法考虑特征之间的任何交互,例如特征 \(i\) 仅在特征 \(j\) 不存在时才是有益的。换句话说,我们需要能够考虑不同状态或状态维度组合的特征。
在最后一节中,我们将研究如何构建这样的 \(x(s)\) 来近似价值函数,并在泛化和区分能力之间取得平衡。
8.4.1 粗编码#
介绍:
场景:假设状态集的自然表示是一个连续的二维空间,一种可能的特征表示形式是状态空间中的 圆。
特征构建:如果状态位于一个圆内,则对应的特征值为 1,表示该特征存在;否则,特征值为 0,表示该特征不存在。(这种取值为 1 或 0 的特征称为 二进制特征)
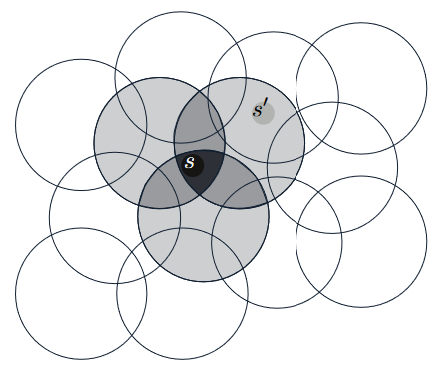
与每个圆(即特征)对应的是一个单一的权重(\(w\) 的一个分量),该权重会在学习过程中受到影响。对一个状态的权重进行更新会改变该状态所在的所有 感受野(receptive field,在这种情况下是圆)内的状态的价值估计。在上面的图像中,对状态 \(s\) 的更新也会改变状态 \(s\prime\) 的价值估计。
定义:以这种重叠的方式(尽管它们不一定是圆或二进制的)用特征表示状态被称为 粗编码(coarse coding)。
泛化和区分能力:
你可以选择观看这个 课程视频,因为下面的内容在视频中有很好的讲解,如果你更喜欢可视化和音频内容而不是文本的话。
演示:直观地说,如果圆很小,那么泛化的范围就会很短,如下面左图所示;而如果圆很大,泛化的范围就会很大,如中间图所示。特征的形状也会决定泛化的性质(右图)。
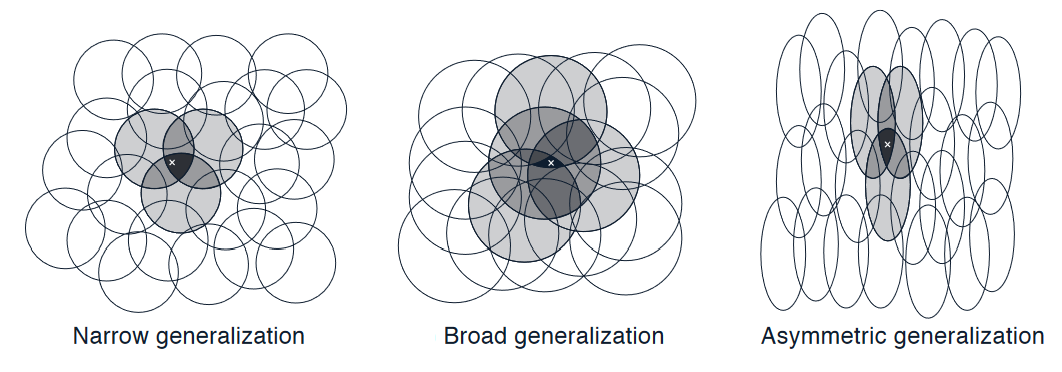
如上所示,具有大 感受野 的特征可以实现广泛的泛化,但似乎在区分能力上有所不足。但与直觉相反的是,事实并非如此。从一个点到另一个点的初始泛化确实由 感受野 的大小和形状控制,但最终的精细区分能力更多地由 特征的总数 控制,如下一个例子所示。
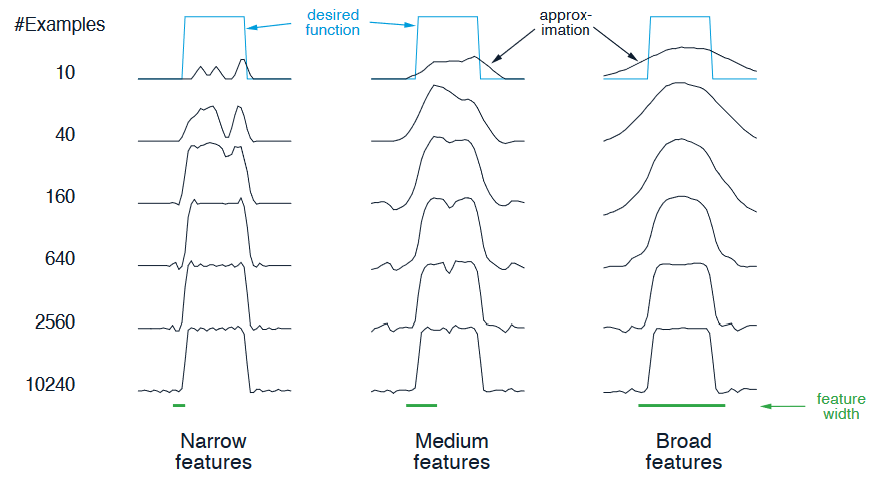
示例:粗编码的粗糙程度
设置:基于粗编码的线性函数近似和半梯度方法被用于学习一个一维方波函数,该函数的值被用作目标 \(U_t\)。
结果:如下所示,特征的宽度在学习初期有很大影响。然而,最终学习到的函数受特征宽度的影响很小。
8.4.2 瓦片编码#
介绍:
描述:瓦片编码(tile coding)是一种用于多维连续空间的 粗编码形式。在瓦片编码中,特征的 感受野 被分组为状态空间的划分。每个这样的划分称为一个 瓦片集(tiling),划分中的每个元素称为一个 瓦片(tile)。
演示:
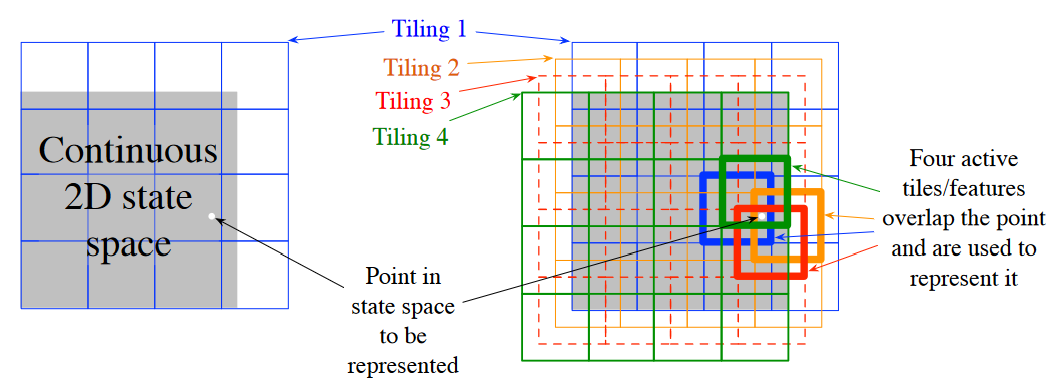
二维状态空间最简单的瓦片集是均匀网格,如上图左侧所示。注意,仅使用一个瓦片集时,这不是粗编码,而只是状态聚合(state aggregation)的一种情况。
为了通过瓦片编码实现真正的粗编码,需要使用多个瓦片集,每个瓦片集偏移一个瓦片宽度的分数(如上图右侧所示)。每个状态(由白色点表示)在四个瓦片集中的每个瓦片集中都恰好落在一个瓦片中。这四个瓦片对应于四个特征,当该状态出现时,这些特征会被激活。在这个例子中,有 \(4 \times 4 \times 4 = 64\) 个分量,除了对应于状态 \(s\) 所在瓦片的四个分量外,其余所有分量都为 0。
优点:
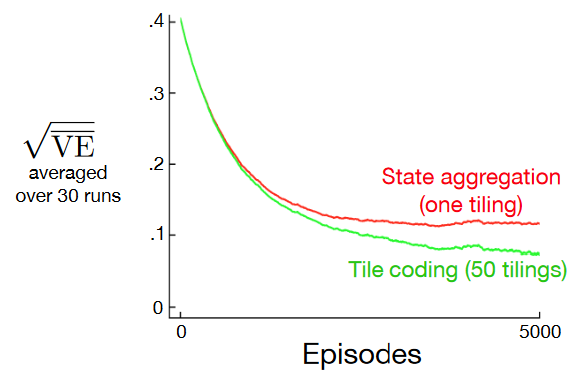
易于设置学习率:对于任何状态,同时激活的特征总数是相同的,因此存在的特征总数始终与瓦片集的数量相同。这使得步长参数(step-size parameter)\(\alpha\) 可以很容易、直观地设置,例如,选择 \(\alpha = \frac{1}{n}\)(其中 \(n\) 是瓦片集的数量)可以实现精确的单步学习。
计算优势:在计算 \(\sum_{i=1}^d w_i x_i(s)\) 时,只需计算 \(n \ll d\) 个激活特征的索引(\(n\) 等于瓦片集的数量),然后将权重向量中对应的 \(n\) 个分量相加即可。
工作原理:
建议观看下面的课程视频,因为它对瓦片编码如何与 TD 方法配合使用提供了更全面的解释。
8.5 总结#
在本章中,我们重点关注如何将强化学习(RL)从表格形式扩展到函数近似,这是处理现实世界中大型状态空间的关键一步。以下是简要总结:
我们目前的知识体系思维导图:
关键要点:
向函数近似的转变:
摆脱表格方法使 RL 能够应用于更复杂的问题,在这些问题中,枚举每个状态是不切实际的。
概念上的转变涉及参数化函数近似(parametric function approximation),即我们不再将状态值存储在表格中。
我们的目标是最小化 平均平方价值误差(mean squared value error),该误差衡量了真实状态值与我们的近似值之间的差异,并根据访问频率 \(u(s)\) 进行加权。
梯度方法:
梯度蒙特卡罗方法(gradient Monte Carlo):在每个回合结束时,使用采样回报进行更新。
半梯度 TD 方法(semi-gradient TD):使用下一个时间步的价值估计进行自举(bootstrapping),从而能够在回合中进行更新,加快学习速度。
我们还介绍了具有函数近似的 线性 TD 方法(linear TD),它被证明可以收敛到一个易于理解的解。
泛化和区分能力:
泛化(generalization):允许对一个状态的更新改善其他相似状态的价值估计,从而加速学习过程。
区分能力(discrimination):确保不同的状态被赋予不同的值,防止过度泛化。
特征构建和表示:
粗编码(coarse coding):将相邻状态分组为任意形状的特征,例如重叠的圆,当状态位于圆内时,圆对应的特征值为 1(激活),否则为 0(未激活)。
瓦片编码(tile coding):
一种特殊形式的粗编码,使用 重叠网格(瓦片集)(overlapping grids/tilings)。
每个瓦片集内的瓦片不重叠,每个网格有一个激活特征,但多个偏移的瓦片集允许更精细的状态区分。
瓦片集的设计需要在泛化、区分能力和效率之间取得平衡。
额外课程视频(可选):David Silver:深度学习 + 强化学习 = 人工智能?