第9章. 基于函数近似的同策略控制#
在本章中,我们将重点转向控制问题(control problem,即策略优化问题)。我们的目标是估计动作价值函数 \(\hat{q}(s, a, \boldsymbol{w}) \dot= \boldsymbol{w}^{T} \boldsymbol{x}(s, a)\),并且仍然专注于同策略 (on-policy) 的情形。
本章的核心内容是半梯度Sarsa算法(semi-gradient Sarsa)。该算法是上一章介绍的半梯度TD(0)算法在动作价值估计和同策略控制问题上的自然延伸。在回合制任务(episodic tasks)中,这种延伸相对直接明了。然而,在持续性任务(continuing tasks)中,我们需要重新审视折扣因子(discounting)在定义最优策略时所扮演的角色,并可能采取不同的思路。我们将探讨如何放弃折扣机制,转而采用一种新的控制问题表述方式——“平均奖励”框架(average-reward framework),并引入与之对应的新型**”差分”价值函数**(differential value functions)。
9.1 回合制半梯度控制#
如何计算动作价值函数(action-value function,线性情况)
与上一章的线性情况类似,近似的动作价值函数通过以下方式计算:
\[ \hat{q}(s, a, \boldsymbol{w}_t) \dot= \boldsymbol{w}^{T} \boldsymbol{x}(s, a) \]对于依赖动作的函数近似,特征向量 \(\boldsymbol{x}(s, a)\) 是通过将每个动作的特征堆叠起来构建的。例如,代表系统状态的4个特征和3个可能的动作会产生一个包含12个元素的特征向量。
为了对动作进行泛化(就像上一章中对状态进行泛化一样),我们可以将状态和动作都输入到神经网络中,该网络将以状态-动作对作为输入,并产生单个输出:该特定状态和动作的近似动作价值。
这个可选课程视频生动地说明了上述笔记,即关于如何完成计算,特别是如何构建特征向量。
梯度下降更新(gradient descent update):
动作价值预测的通用更新规则(general update rule for action-value prediction)
\[ \boldsymbol{w_{t+1}} \dot= \boldsymbol{w_t} + \alpha [U_t - \hat{q}(S_t, A_t, \boldsymbol{w_t})]\nabla\hat{q}(S_t, A_t, \boldsymbol{w_t}) \]回合制半梯度单步Sarsa的更新规则
更新规则
\[ \boldsymbol{w_{t+1}} \dot= \boldsymbol{w_t} + \alpha [R_{t+1} + \gamma\hat{q}(S_{t+1}, A_{t+1}, \boldsymbol{w_t}) - \hat{q}(S_t, A_t, \boldsymbol{w_t})]\nabla\hat{q}(S_t, A_t, \boldsymbol{w_t}) \]注意,时间步 \(t+1\) 的更新目标是由时间步 \(t\) 的权重所对应的动作价值函数给出的。
算法:半梯度Sarsa(semi-gradient Sarsa)

半梯度期望Sarsa(semi-gradient expected Sarsa)的更新规则:
\[ \mathbf{w} \leftarrow \mathbf{w} + \alpha \left( R_{t+1} + \gamma \sum_{a'} \pi(a' \mid S_{t+1}) \hat{q}(S_{t+1}, a', \mathbf{w}) - \hat{q}(S_t, A_t, \mathbf{w}) \right) \nabla \hat{q}(S_t, A_t, \mathbf{w}) \]半梯度Q学习(semi-gradient Q-learning)的更新规则:
\[ \mathbf{w} \leftarrow \mathbf{w} + \alpha \left( R_{t+1} + \gamma \max_{a'} \hat{q}(S_{t+1}, a', \mathbf{w}) - \hat{q}(S_t, A_t, \mathbf{w}) \right) \nabla \hat{q}(S_t, A_t, \mathbf{w}) \]
同策略控制的梯度方法(gradient methods for on-policy control):登山车示例(课程视频)
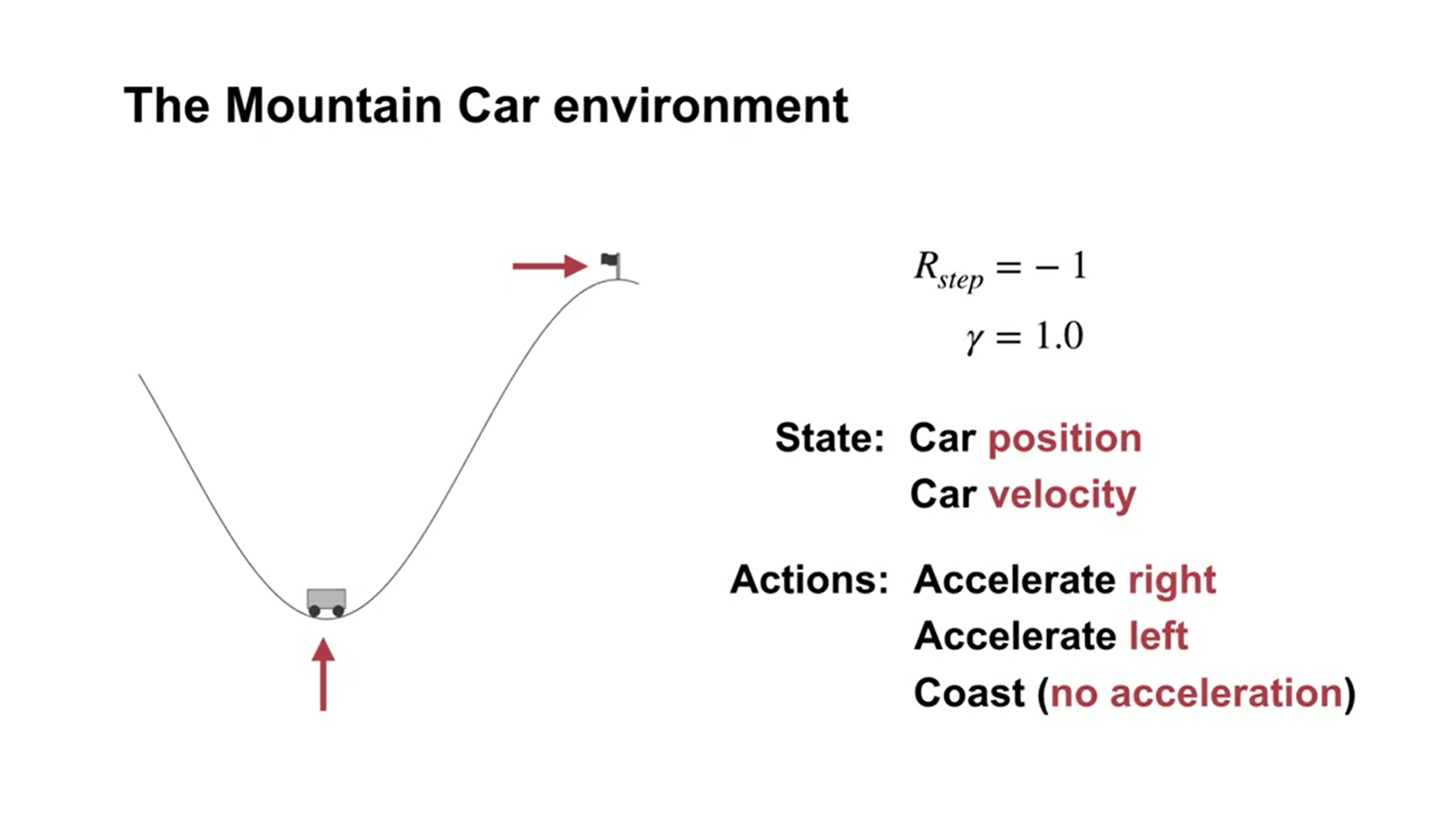
简介:驾驶一辆马力不足的汽车上陡峭的山路,此时重力比汽车发动机的牵引力要大——这是一个简单的连续控制任务示例,在某种意义上,情况必须先变得更糟(离目标更远),然后才能变得更好。该问题的设置如下:
汽车根据简化的物理规则移动。其位置 \(x_t\) 和速度 \(\dot{x}_t\) 按以下方式更新:
\[\begin{split} \begin{align*} & x_{t+1} \dot= \text{bound}[x_t + \dot{x}_t] \\ & \dot{x}_{t+1} \dot= \text{bound}[\dot{x}_t + 0.001 A_t - 0.0025 \cos(3x_t)], \end{align*} \end{split}\]其中 \(\text{bound}\) 操作强制 \(-1.2 \leq x_{t+1} \leq 0.5\) 且 \(-0.07 \leq \dot{x}_{t+1} \leq 0.07\)。
此外,当 \(x_t\) 到达左边界时,\(\dot{x}_{t+1}\) 被重置为零。当它到达右边界时,即达到目标,该回合(episode)终止。
每回合(episode)从一个随机位置 \(x_t \in [-0.6, -0.4]\) 和零速度开始。
我们使用了8个瓦片(tilings),每个瓦片在每个维度上覆盖有界距离的 \(1/8\)。
\({\star}\) 函数近似下改进探索策略的方法
这一方面未包含在Sutton的书籍(2018版)中,但在此讲座视频中得到了很好的介绍。简而言之,改进探索策略的两种主要方法(不一定效果都很好)是:
乐观初始值(Optimistic Initial Values):在表格型设置中,将初始值设置得高于真实值可以鼓励探索。这在表格型设置中效果很好,但在函数近似(例如神经网络)中很复杂,因为输入和输出之间的关系是非线性的。虽然乐观初始化可以引导探索,但由于网络中的泛化或非局部更新,它可能会失去有效性。
\(\epsilon\)-贪心策略(Epsilon Greedy):这种方法使用随机性来探索动作,适用于任何函数近似并且易于实现。然而,它不像乐观初始化那样提供系统性的探索。
结论:将乐观值与函数近似相结合是复杂的,虽然\(\epsilon\)-贪心方法可以普遍使用,但其探索方向性较差。在函数近似中改进探索仍然是一个悬而未决的研究问题。
9.2 平均奖励:一种新的控制问题表述方式(Average-Reward Framework for Continuing Tasks)#
动机:此课程视频阐述了平均奖励设定的动机,为可选观看内容。
定义:与折扣设定类似,平均奖励设定适用于持续性问题,但是,它没有折扣。在平均奖励设定中,平均奖励定义如下,它反映了策略 \(\pi\) 的质量。
\[\begin{split} \begin{align} r(\pi) &\dot= \lim_{h \to \infty} \frac{1}{h} \sum_{t=1}^h \mathbb{E}[R_t \mid S_0, A_{0:t-1} \sim \pi] \\ &= \lim_{t \to \infty} \mathbb{E}[R_t \mid S_0, A_{0:t-1} \sim \pi], \\ &= \sum_{s} \mu_\pi(s) \sum_{a} \pi(a \mid s) \sum_{s',r} p(s', r \mid s, a) r, \end{align} \end{split}\]\(\mu_\pi(s)\dot= \lim_{t o \infty} \Pr\{S_t = s \mid A_{0:t-1} \sim \pi\}\) 是稳态分布(stationary distribution),假设对于任何策略 \(\pi\) 都存在,并且独立于初始状态 \(S_0\)(这个关于马尔可夫决策过程(MDP)的假设被称为\( extit{遍历性假设}\)(ergodicity assumption))。
我们认为所有达到 \(r(\pi)\) 最大值的策略都是最优策略。
平均奖励设定的必要性:折扣设定在函数近似方面存在问题,感兴趣的读者可以参考本书第10.4章。
派生定义:
回报(Returns):回报是根据奖励与平均奖励之间的差额来定义的:
\[ G_t \dot= R_{t+1} - r(\pi) + R_{t+2} - r(\pi) + R_{t+3} - r(\pi) + \cdots. \]贝尔曼方程(Bellman equation):
\[\begin{split} \begin{align} v_\pi(s) &= \sum_{a} \pi(a \mid s) \sum_{r, s'} p(s', r \mid s, a) \left[ r - r(\pi) + v_\pi(s') \right], \\ q_\pi(s, a) &= \sum_{r, s'} p(s', r \mid s, a) \left[ r - r(\pi) + \sum_{a'} \pi(a' \mid s') q_\pi(s', a') \right], \end{align} \end{split}\]贝尔曼最优方程(Bellman optimality equation):
\[\begin{split} \begin{align} v_*(s) &= \max_{a} \sum_{r, s'} p(s', r \mid s, a) \left[ r - \max_\pi r(\pi) + v_*(s') \right], \\ q_*(s, a) &= \sum_{r, s'} p(s', r \mid s, a) \left[ r - \max_\pi r(\pi) + \max_{a'} q_*(s', a') \right]. \end{align} \end{split}\]两种TD误差(differential TD error):
\[\begin{split} \begin{align} \delta_t &\dot= R_{t+1} - \bar{R}_t + \hat{v}(S_{t+1}, \mathbf{w}_t) - \hat{v}(S_t, \mathbf{w}_t), \\ \delta_t &\dot= R_{t+1} - \bar{R}_t + \hat{q}(S_{t+1}, A_{t+1}, \mathbf{w}_t) - \hat{q}(S_t, A_t, \mathbf{w}_t). \end{align} \end{split}\]
派生算法示例:

与Sarsa不同,微分Sarsa的一个关键区别在于,它必须跟踪其策略下的平均奖励估计,并在其更新中从样本奖励中减去该估计,如下所示:
\[ > \bar{R} \leftarrow \bar{R} + \beta (R-\bar{R}) > \]
> 在实践中,项$(R-\bar{R})$ 被替换为 $\delta$ 以获得更好的性能(即更低的方差)。
拓展课程视频(可选):Satinder Singh 谈论内在奖励(intrinsic rewards)
9.3 总结#
在本章中,我们将表格型控制方法扩展到函数近似,研究了探索技术中的变化,并引入了用于持续性控制问题的平均奖励框架。详细内容包括:
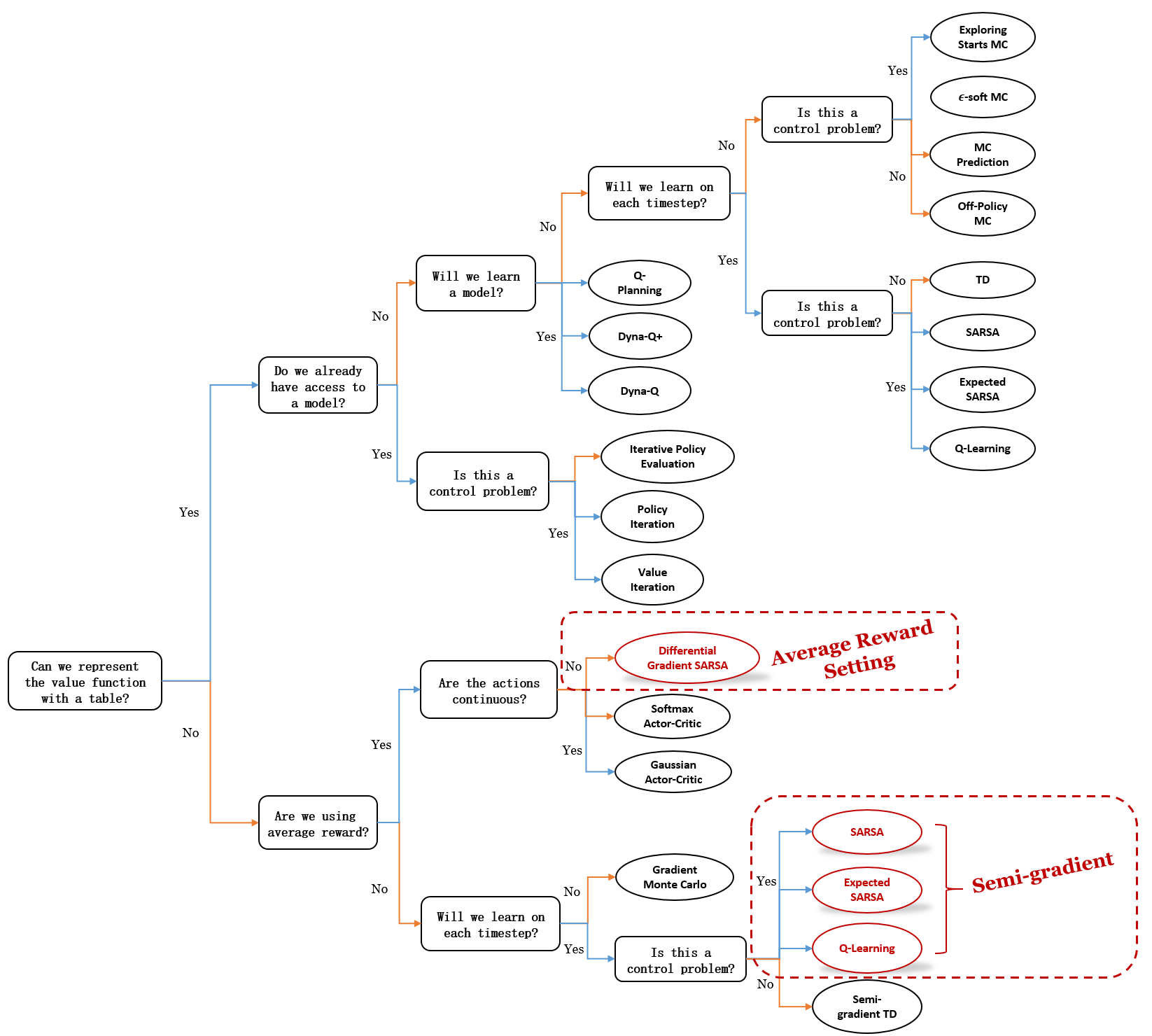
我们当前所处位置的思维导图
核心要点
动作价值估计(action-value estimation):对于离散动作空间,状态特征可以堆叠起来;而对于连续动作空间,动作可以与其他状态变量一起作为(神经网络的)输入。
算法概述:在算法图谱中引入了函数近似(function approximation)。我们专注于扩展表格型控制算法(SARSA、期望SARSA(expected SARSA)和Q学习),以适应函数近似。这些扩展涉及修改更新方程以使用基于梯度的权重更新。
回合制SARSA(episodic SARSA):我们演示了回合制SARSA如何解决登山车问题,表明较大的步长(0.5)可以加快学习速度。
探索策略:乐观初始化对于结构化特征很有用,但对于像神经网络这样的非线性函数近似器可能无法按预期工作,因为乐观情绪可能会迅速消退。无论使用何种函数近似器,\(\epsilon\)-贪心都是一种更可靠的探索方法。
平均奖励框架:我们引入了一种解决持续性控制问题的新方法,即最大化随时间推移的平均奖励,而不是关注折扣回报。我们定义了微分回报(differential return)和微分价值(differential value),这有助于智能体在此框架下评估动作。
微分半梯度SARSA(differential semi-gradient SARSA):这种新算法使用平均奖励框架,通过近似微分价值来学习策略,扩展了先前的算法。