第六章 LangGraph基础:有状态工作流与核心概念
前言
各位同学,上一章我们掌握了LangChain的基础工作流构建,当面对更复杂的任务——比如需要循环迭代、动态分支、状态回溯的场景时,LangChain的链式流就显得有些局限了。 这一章我们聚焦LangGraph,它作为LangChain生态中负责复杂工作流编排的核心框架,1.0版本后更是强化了生产级特性,能帮我们实现有状态、可追溯、高灵活度的工作流。
接下来我们从理念到实操,逐步吃透LangGraph。
LangGraph 是 LangChain 团队在 2024 年推出的核心框架,到了 2025 年,它已经成为构建 Production-Ready(生产级)Agent 的行业标准。
先提前准备依赖(终端执行安装):
pip install langgraphlanggraph 推荐安装版本 ≥1.0.0
6.1 LangGraph图结构驱动的工作流
在正式上手前,我们先搞懂LangGraph的设计初衷。大家可以把工作流想象成一张“任务地图”,传统链式流是“单一路线”,而LangGraph的图结构是“多节点、多路径”的地图,能应对更复杂的路况。
6.1.1 为什么需要图结构工作流?
在AI应用开发中,我们常面临超越线性流程的复杂任务。比如一个智能客服系统,需要先识别用户意图,再根据意图分发到技术支持、订单咨询等不同节点,若回答不达标还需回退重生成——这种包含分支、循环的场景,传统线性链式工作流(如LangChain早期Chain)难以高效支撑。
线性流程的核心痛点是“刚性”:一旦定义好步骤顺序,难以动态调整,且无法很好地管理跨步骤的数据共享和状态回溯。而图结构工作流通过“节点”封装功能、“边”定义路径、“状态”共享数据,能精准解决这些问题,让复杂流程的每一步都可控制、可追溯。
LangGraph通过对智能体工作流进行图结构建模,它具有以下几个核心价值:
- 显式控制: 通过流程图明确指定执行路径,避免智能体在复杂任务中"乱跑"
- 可预测性: 结果更稳定,行为更可预测
- 精细调控: 明确规定下一步走哪个节点、何时调用工具、何时循环或终止
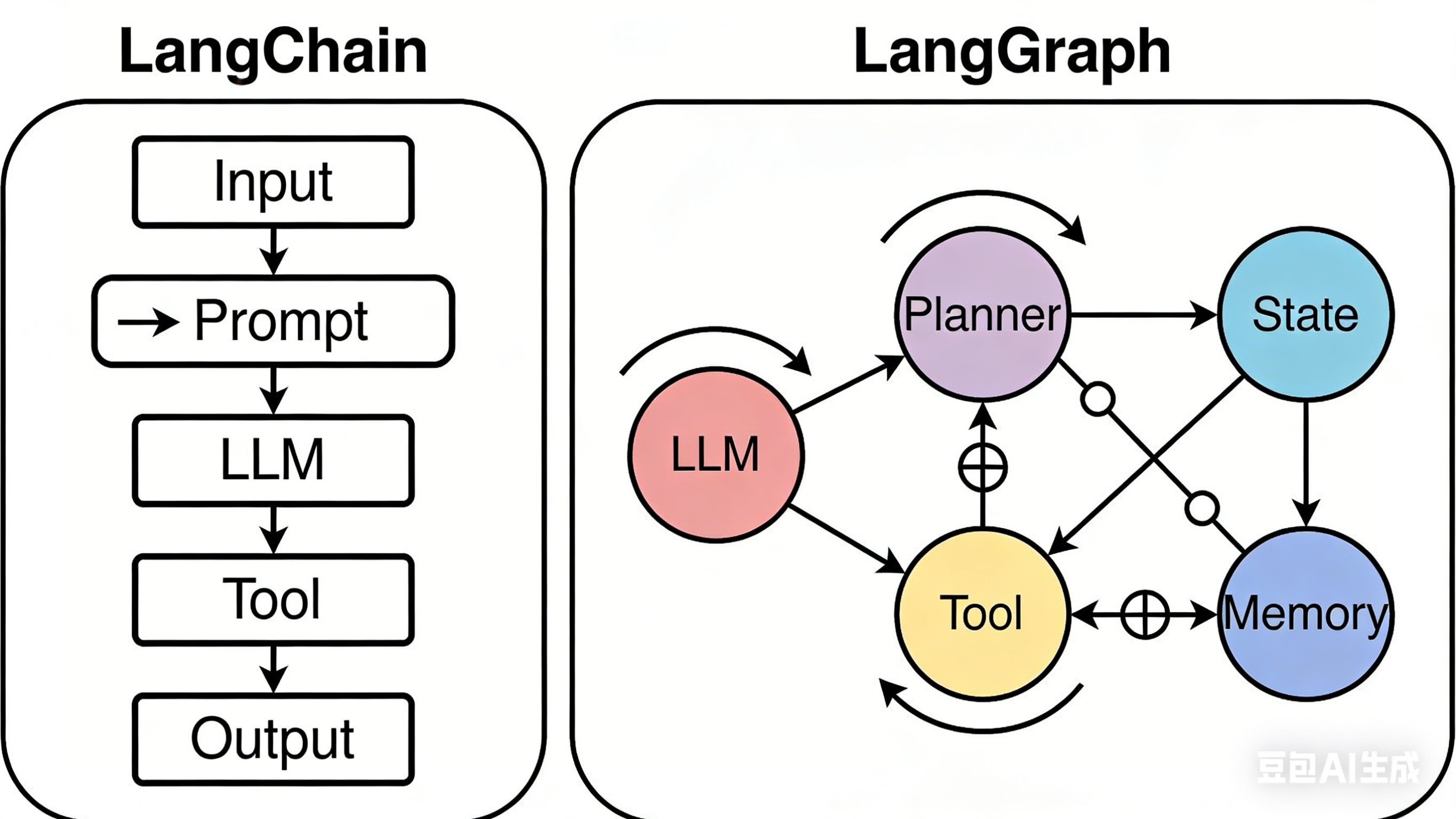
6.1.2 与LangChain工作流的差异与互补性
很多同学会问:有了LangChain,为什么还要用LangGraph?其实两者不是替代关系,而是互补关系,LangChain的Agent能力甚至是基于LangGraph运行时构建的。
对比维度:流程灵活性、状态管理、循环与分支支持
| 核心维度 | LangChain | LangGraph |
|---|---|---|
| 流程灵活性 | 采用链式流设计,适用于线性、固定步骤的任务;抽象层级高,降低上手门槛,能快速搭建简单流程。 | 基于图结构流构建,原生支持分支、循环、并行等复杂流程逻辑,灵活性极强;需手动定义节点及节点间的边,对流程设计能力要求更高。 |
| 状态管理 | 状态分散存储于各个Chain组件中,上下文传递需手动编码实现,无统一管理入口,扩展性较弱。 | 具备统一状态对象,支持字段级状态合并策略(如追加、覆盖等),状态管理更规范;内置状态持久化能力,无需额外开发适配,降低运维成本。 |
| 循环与分支支持 | 仅能通过条件判断代码实现简单分支逻辑,循环功能需手动控制执行次数,难以适配复杂动态流程。 | 通过条件边、循环边原生支持复杂分支与循环逻辑,可配置终止条件避免无限循环,适配多场景交互、动态决策等复杂业务需求。 |
总结:
- LangChain更适合快速搭建线性、固定流程的轻量化应用,上手成本低,能满足简单任务的开发需求;
- LangGraph则聚焦复杂流程场景,尤其适用于智能体工作流、合规审核多步骤校验等场景。
实际开发中,我们可以这样选择:快速搭建原型、任务流程固定(如“文本生成→格式转换”),选LangChain链式流,效率更高;任务流程复杂(有分支、循环、并行)、需要状态追溯、追求生产级稳定性(如多Agent协作、长时任务),选LangGraph图结构流。
6.2 LangGraph核心概念:图状态、点、边
LangGraph的核心是“图(Graph)”,而构成图的三大组件是:状态(State)、节点(Nodes)、边(Edges)。这三者就像乐高积木,既能搭简单的线性流程,也能拼出复杂的分支、循环工作流。
提示:先理解“组件作用”,再结合代码实操,能快速突破抽象壁垒。
6.2.1 状态(State):工作流的“共享黑板”
状态是LangGraph工作流的“数据中枢”,所有节点的输入、输出都围绕它展开。
通俗类比:把工作流想象成班级大扫除,状态就是一块共享黑板——扫地的同学(节点1)把“地面已清洁”写在黑板上,擦玻璃的同学(节点2)从黑板看到进度后,完成工作再补充“玻璃已擦完”,所有节点只和黑板交互,不用互相喊话。
这种设计让每个步骤的结果都可追溯,也支持中途暂停、恢复(比如大扫除中途放学,第二天看黑板就知道从哪继续)。
核心本质:共享数据载体+状态快照
- 共享数据载体:所有节点都能读取、修改状态中的数据(比如字段、列表、字典),确保数据一致性。
- 状态快照:配合工具,每一步状态变化都会被记录,支持回溯和断点续跑(比如长任务中途服务器重启,恢复后从上次状态继续,不用重做)。
定义规范:TypedDict类型定义与字段设计原则
LangGraph 1.0+推荐使用Python的TypedDict+ Annotated定义状态结构,明确字段类型和含义,提升代码可读性和类型校验能力。
字段设计需遵循三个原则:
- 最小必要原则:只定义工作流必需的字段,避免冗余数据占用内存;
- 可更新原则:将需要跨节点传递、修改的数据设为状态字段,固定不变的配置无需放入;
- 清晰命名原则:字段名需直观反映数据含义,如“user_query”“generated_text”“quality_score”。
基础定义示例(TypedDict方式):
from typing import TypedDict, NotRequired
class TaskState(TypedDict):
user_query: str #用户原始查询
tool_result: NotRequired[str] #工具调用结果
final_answer: NotRequired[str] #最终回答
progress: NotRequired[int] #任务进度百分比
#NotRequired 表示是非必须要求也可以用 Pydantic 的方式
from pydantic import BaseModel, Field
from typing import Optional
class TaskState(BaseModel):
user_query: str = Field(description="用户原始查询")
tool_result: Optional[str] = Field(default=None, description="工具调用结果")
final_answer: Optional[str] = Field(default=None, description="最终回答")
progress: Optional[int] = Field(default=None, description="任务进度百分比")两种写法各有优劣,目前2种写法官方都是支持的,因为Pydantic 写法学习起来有难度,本文以下教学均使用TypedDict的写法,但实际的企业生产建议是使用Pydantic 写法,更工程化一些。
6.2.1.2 状态传递机制
LangGraph的状态传递采用“不可变更新”原则:节点接收当前状态的副本,执行逻辑后返回更新后的部分状态(无需返回完整状态),框架会自动合并为新的全局状态,再传递给下一个节点。
这种机制的优势是避免节点间相互干扰,每个节点只需关注自己需要处理的字段。
例如
def parse_query(state: TaskState):
print("\n====== 节点1 parse_query 输入状态 ======")
print(state)
query = state.user_query
update = {
"tool_result": f"已解析问题: {query}",
"progress": 30
}
return update是不是还是感觉内容很抽象,看不懂,多说无益,我们通过一个代码案例来学习:
现在我们假设一个简单的智能体工作流场景:用户输入问题,系统先解析问题,再调用外部工具获取信息,最后生成最终回答。
整个过程需要通过 LangGraph 的边来定义执行顺序,从而形成一个可自动运行的任务流水线。
# NotRequired 来自 Python 的 typing 模块扩展,它是 PEP 655 引入的特性
# NotRequired 从 Python 3.11 开始内置支持
from typing import TypedDict, NotRequired
#如果你使用的是 Python ≤3.10,需要安装 typing_extensions:
# pip install typing_extensions
#from typing import TypedDict
#from typing_extensions import NotRequired
class TaskState(TypedDict):
user_query: str #用户原始查询
tool_result: NotRequired[str] #工具调用结果
final_answer: NotRequired[str] #最终回答
progress: NotRequired[int] #任务进度百分比
# ======节点函数=========
def parse_query(state: TaskState):
print("\n====== 节点1 parse_query 输入状态 ======")
print(state)
query = state["user_query"]
update = {
"tool_result": f"已解析问题: {query}",
"progress": 30
}
print("------ 节点1 更新字段 ------")
print(update)
return update
def call_tool(state: TaskState):
print("\n====== 节点2 call_tool 输入状态 ======")
print(state)
result = f"工具搜索结果:关于『{state['user_query']}』的相关知识"
update = {
"tool_result": result,
"progress": 70
}
print("------ 节点2 更新字段 ------")
print(update)
return update
def generate_answer(state: TaskState):
print("\n====== 节点3 generate_answer 输入状态 ======")
print(state)
answer = f"最终回答:基于工具结果 -> {state['tool_result']}"
update = {
"final_answer": answer,
"progress": 100
}
print("------ 节点3 更新字段 ------")
print(update)
return update
#========构建 LangGraph 工作流======
from langgraph.graph import StateGraph
# 1. 创建图(绑定状态类型)
builder = StateGraph(TaskState)
# 2. 添加节点
builder.add_node("parse_query", parse_query)
builder.add_node("call_tool", call_tool)
builder.add_node("generate_answer", generate_answer)
# 3. 定义执行顺序(边)
builder.set_entry_point("parse_query")
builder.add_edge("parse_query", "call_tool")
builder.add_edge("call_tool", "generate_answer")
# 4. 编译图
graph = builder.compile()
# ====== 运行工作流 ======
init_state = TaskState(user_query="什么是 LangGraph?")
final_state = graph.invoke(init_state)
print("\n最终状态:")
print(final_state)运行结果
====== 节点1 parse_query 输入状态 ======
user_query='什么是 LangGraph?' tool_result='' final_answer='' progress=0
------ 节点1 更新字段 ------
{'tool_result': '已解析问题: 什么是 LangGraph?', 'progress': 30}
====== 节点2 call_tool 输入状态 ======
user_query='什么是 LangGraph?' tool_result='已解析问题: 什么是 LangGraph?' final_answer='' progress=30
------ 节点2 更新字段 ------
{'tool_result': '工具搜索结果:关于『什么是 LangGraph?』的相关知识', 'progress': 70}
====== 节点3 generate_answer 输入状态 ======
user_query='什么是 LangGraph?' tool_result='工具搜索结果:关于『什么是 LangGraph?』的相关知识' final_answer='' progress=70
------ 节点3 更新字段 ------
{'final_answer': '最终回答:基于工具结果 -> 工具搜索结果:关于『什么是 LangGraph?』的相关知识', 'progress': 100}
最终状态:
{'user_query': '什么是 LangGraph?', 'tool_result': '工具搜索结果:关于『什么是 LangGraph?』的相关知识', 'final_answer': '最终回答:基于工具结果 -> 工具搜索结果:关于『什么是 LangGraph?』的相关知识', 'progress': 100}从上面的图就能清晰的看到状态在不同节点之间进行流转。
6.2.1.3 状态传递机制:节点间的数据共享与更新逻辑
状态传递的逻辑很简单:工作流启动时初始化状态,每个节点执行时接收当前状态,处理后返回需要更新的字段,LangGraph会根据合并策略更新全局状态,再传递给下一个节点。
这里要注意:节点返回的字典只需包含要更新的字段,无需返回完整状态。比如节点只更新progress字段,就返回{"progress": 1},LangGraph会自动合并到全局状态中。
思考: 为什么节点返回的字典只需包含要更新的字段,无需返回完整状态?
6.2.2 节点(Nodes):工作流的“功能小工人”
节点是工作流的“执行单元”,相当于图中的“站点”,每个节点封装一段具体逻辑(比如调用LLM、查数据库、处理数据),本质是“输入状态→处理→返回更新状态”的纯函数。
通俗类比:每个节点都是一个“专业小工人”,只做一件事——从共享黑板(状态)拿材料,做完后把结果写回黑板,不依赖外部无关信息。
6.2.2.1 核心作用:接收状态、执行逻辑、输出新状态
节点的核心作用有三个:一是接收全局状态,提取所需字段作为输入;二是执行具体逻辑,比如调用LLM、工具、数据处理;三是将执行结果封装成状态更新字典,返回给LangGraph。
需要注意:节点必须是无副作用的纯函数,逻辑只依赖输入的状态,不依赖外部变量,这样才能保证状态的可追溯性和可复现性。
6.2.2.2 节点类型:LLM调用节点、工具调用节点、数据处理节点
根据功能不同,节点主要分为三类:
LLM调用节点:负责调用大模型生成内容,比如根据用户查询生成回答,核心是将状态中的字段(如user_query)传入模型,将生成结果存入状态。
工具调用节点:负责调用外部工具,比如Elasticsearch检索、天气API查询,核心是提取状态中的参数,调用工具后将结果更新到状态。
数据处理节点:负责数据转换、校验、格式处理,比如将生成的回答格式化、校验结果是否合格,核心是对状态中的数据进行加工,返回处理后的值。
下面结合自定义TaskState演示:
from typing import TypedDict, NotRequired
class TaskState(TypedDict):
user_query: str #用户原始查询
intent: NotRequired[str] #用户意图
llm_answer: NotRequired[str] #LLM 生成的回答
tool_result: NotRequired[str] #工具调用结果
final_answer: NotRequired[str] #最终回答
progress: NotRequired[int] #任务进度百分比
#=======LLM 调用节点(模拟)=========
#LLM 节点只负责“生成文本”,不负责工具、不负责格式化。
def llm_node(state: TaskState):
print("\n🧠 [LLM Node] 输入状态:", state)
# 模拟大模型生成
llm_output = f"LangGraph 是一种用于构建可控AI工作流的框架,问题是:{state['user_query']}"
return {
"llm_answer": llm_output,
"progress": 30
}
# ====== 工具调用节点(模拟检索) ======
#工具节点只做 I/O,不生成语言,不控制流程。
def tool_node(state: TaskState):
print("\n🔧 [Tool Node] 输入状态:", state)
# 模拟搜索工具
tool_output = f"检索结果:LangGraph 支持 DAG、状态机、Agent workflow"
return {
"tool_result": tool_output,
"progress": 70
}
# ====== 节点3:数据处理节点 ======
#数据节点负责加工 state,而不是生成或检索。
def data_process_node(state: TaskState):
print("\n🧹 [Data Node] 输入状态:", state)
final = f"""
【LLM回答】{state["llm_answer"]}
【工具补充】{state["tool_result"]}
"""
return {
"final_answer": final.strip(),
"progress": 100
}
from langgraph.graph import StateGraph
# 1. 创建图
builder = StateGraph(TaskState)
# 2. 添加节点
builder.add_node("llm_node", llm_node)
builder.add_node("tool_node", tool_node)
builder.add_node("data_process_node", data_process_node)
# 3. 定义流程
builder.set_entry_point("llm_node")
builder.add_edge("llm_node", "tool_node")
builder.add_edge("tool_node", "data_process_node")
# 4. 编译
graph = builder.compile()
# 初始化状态
init_state = TaskState(user_query="什么是 LangGraph?")
# 执行
final_state = graph.invoke(init_state)
print("\n====== 最终状态 ======")
print(final_state)运行结果
🧠 [LLM Node] 输入状态: user_query='什么是 LangGraph?' llm_answer='' tool_result='' final_answer='' progress=0
🔧 [Tool Node] 输入状态: user_query='什么是 LangGraph?' llm_answer='LangGraph 是一种用于构建可控AI工作流的框架,问题是:什么是 LangGraph?' tool_result='' final_answer='' progress=30
🧹 [Data Node] 输入状态: user_query='什么是 LangGraph?' llm_answer='LangGraph 是一种用于构建可控AI工作流的框架,问题是:什么是 LangGraph?' tool_result='检索结果:LangGraph 支持 DAG、状态机、Agent workflow' final_answer='' progress=70
====== 最终状态 ======
{'user_query': '什么是 LangGraph?', 'llm_answer': 'LangGraph 是一种用于构建可控AI工作流的框架,问题是:什么是 LangGraph?', 'tool_result': '检索结果:LangGraph 支持 DAG、状态机 、Agent workflow', 'final_answer': '【LLM回答】LangGraph 是一种用于构建可控AI工作流的框架,问题是:什么是 LangGraph?\n【工具补充】检索结果:LangGraph 支持 DAG、状态机、Agent workflow', 'progress': 100}结论: 在 LangGraph 中,节点(Node)是 AI 工作流的最小执行单元,负责完成具体计算任务,如调用大模型、调用外部工具或进行数据处理。每个节点遵循“读取状态 → 执行逻辑 → 返回状态更新”的工作模式,本质上是一个以状态为输入、以状态补丁为输出的纯函数。
6.2.2.3 节点实现规范:函数定义格式与状态交互方式
LangGraph 1.0+对节点函数有明确的规范要求,确保框架能正确解析和执行:
- 输入参数:必须包含状态参数(通常命名为state),类型需与定义的状态结构一致(如ConversationState);可选包含config参数,用于接收工作流配置。
- 输出格式:支持三种形式——返回状态片段(字典或TypedDict实例)、返回None(无状态更新)、返回多个状态片段(通过元组)。
- 交互原则:节点只能通过状态与其他节点交互,禁止直接调用其他节点函数,确保流程的可追溯性。
错误示例(直接调用其他节点):
# 不推荐:节点间直接调用,破坏流程完整性
def bad_node(state: ConversationState):
answer = generate_answer(state) # 直接调用其他节点
return {"generated_answer": answer}6.2.3 边(Edges):工作流的“路径导航员”
边是连接节点的“路径”,定义了节点间的跳转规则,决定了工作流的执行顺序。LangGraph 1.0+支持两种核心边类型:固定边和条件边。
6.2.3.1 核心作用:定义节点间的跳转规则
边的核心作用就是“导航”,告诉工作流“当前节点执行完后,下一步该去哪个节点”。没有边的连接,节点就是孤立的,无法形成完整工作流。简单来说,边就是工作流的“执行路线图”。
6.2.3.2 核心边类型与实践
固定边是最简单的边类型,指定“从A节点到B节点”的固定跳转,无论状态如何变化,执行完A后必然执行B,适合线性流程。
条件边是动态边,根据当前状态判断跳转方向,支持多分支跳转,适合需要动态决策的场景。比如根据用户需求意图,判断是走“总结”分支还是“改写”分支。
此外,LangGraph还支持循环边,本质是条件边的一种特殊形式,通过判断状态是否满足终止条件,决定是回溯到前序节点继续执行,还是进入下一个节点。
固定边(Fixed Edges):节点执行完成后,固定跳转到下一个节点,适用于线性流程。通过add_edge()方法配置,参数为“起始节点名”和“目标节点名”。
from typing import TypedDict, NotRequired
# ====== 全局共享状态(黑板) ======
class TaskState(TypedDict):
user_query: str #用户原始查询
intent: NotRequired[str] #用户意图
llm_answer: NotRequired[str] #LLM 生成的回答
tool_result: NotRequired[str] #工具调用结果
final_answer: NotRequired[str] #最终回答
progress: NotRequired[int] #任务进度百分比
#========固定边(线性流程)实践代码======
def parse_intent(state: TaskState):
print("\n🔹 parse_intent")
# 简单模拟意图识别
intent = "summarize" if "总结" in state['user_query'] else "rewrite"
return {"intent": intent, "progress": 30}
def summarize_node(state: TaskState):
print("\n🔹 summarize_node")
return {"llm_answer": f"总结结果: {state['user_query']}", "progress": 60}
def rewrite_node(state: TaskState):
print("\n🔹 rewrite_node")
return {"llm_answer": f"改写结果: {state['user_query']}", "progress": 60}
def final_node(state: TaskState):
print("\n🔹 final_node")
return {"progress": 100}
from langgraph.graph import StateGraph
builder = StateGraph(TaskState)
builder.add_node("parse_intent", parse_intent)
builder.add_node("summarize_node", summarize_node)
builder.add_node("rewrite_node", rewrite_node)
builder.add_node("final_node", final_node)
# 固定边(线性)
builder.set_entry_point("parse_intent")
builder.add_edge("parse_intent", "summarize_node") # 固定走总结
builder.add_edge("summarize_node", "final_node")
graph = builder.compile()
state = TaskState(user_query="请帮我总结这段话")
print(graph.invoke(state))运行结果
🔹 parse_intent
🔹 summarize_node
🔹 final_node
{'user_query': '请帮我总结这段话', 'intent': 'summarize', 'result': '总结结果: 请帮我总结这段话', 'progress': 100}也可以看一下图的执行状态(在ipynb代码里执行)
from IPython.display import Image, display
display(Image(graph.get_graph().draw_mermaid_png()))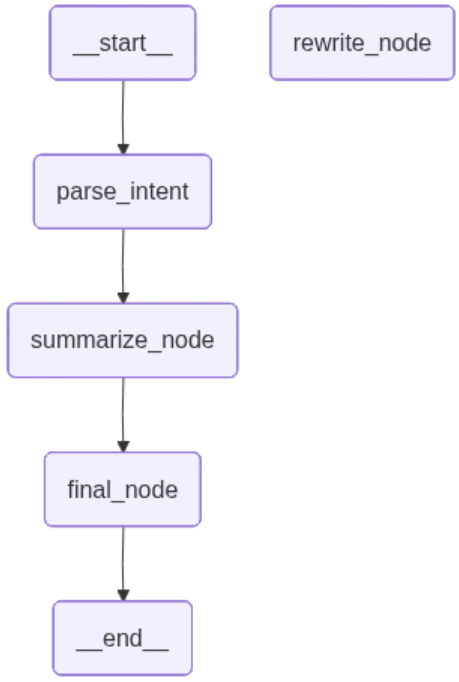
从图中能清楚看到节点的运行状态,可以从图中看到我们将rewrite_node 增加到了节点 但是没有用边连接起来,于是rewrite_node变成了孤立的节点~
学习实践: 将rewrite_node 使用边连接起来,比较最后生成的图
条件边:根据当前状态动态决定跳转路径,适用于分支流程。通过add_conditional_edges()方法配置,需指定“起始节点名”“条件判断函数”和“路径映射表”
def route_by_intent(state: TaskState):
if state.get("intent") == "summarize":
return "summarize_node"
else:
return "rewrite_node"
builder = StateGraph(TaskState)
builder.add_node("parse_intent", parse_intent)
builder.add_node("summarize_node", summarize_node)
builder.add_node("rewrite_node", rewrite_node)
builder.add_node("final_node", final_node)
builder.set_entry_point("parse_intent")
# 条件边
builder.add_conditional_edges(
"parse_intent",
route_by_intent,
{
"summarize_node": "summarize_node",
"rewrite_node": "rewrite_node",
}
)
builder.add_edge("summarize_node", "final_node")
builder.add_edge("rewrite_node", "final_node")
graph = builder.compile()
print("\n====== 测试总结 ======")
print(graph.invoke(TaskState(user_query="请总结这段话")))
print("\n====== 测试改写 ======")
print(graph.invoke(TaskState(user_query="请改写这段话")))运行结果
====== 测试总结 ======
🔹 parse_intent
🔹 summarize_node
🔹 final_node
{'user_query': '请总结这段话', 'intent': 'summarize', 'result': '总结结果: 请总结这段话', 'progress': 100}
====== 测试改写 ======
🔹 parse_intent
🔹 rewrite_node
🔹 final_node
{'user_query': '请改写这段话', 'intent': 'rewrite', 'result': '改写结果: 请改写这段话', 'progress': 100}也可以看一下图的执行状态(在ipynb代码里执行)
from IPython.display import Image, display
display(Image(graph.get_graph().draw_mermaid_png()))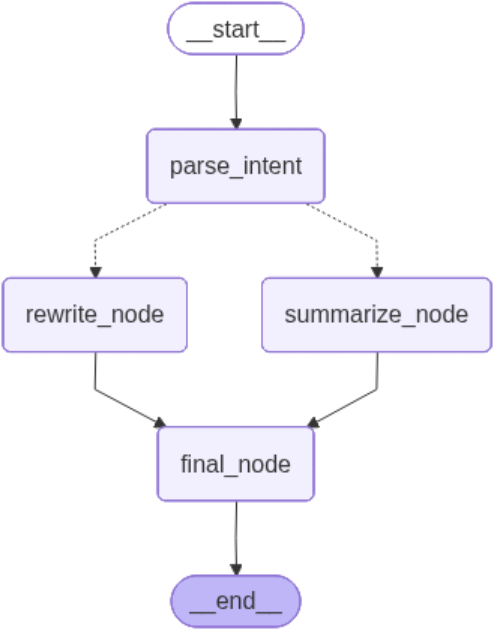
循环边
#=======循环节点======
def loop_node(state: TaskState):
progress = state.get("progress", 0)
print("\n🔄 loop_node, progress =", progress)
return {"progress": progress + 30}
#=======循环条件函数======
def loop_router(state: TaskState):
if state["progress"] >= 100:
return "final_node"
return "loop_node"
#=======构建图=========
builder = StateGraph(TaskState)
builder.add_node("loop_node", loop_node)
builder.add_node("final_node", final_node)
builder.set_entry_point("loop_node")
builder.add_conditional_edges(
"loop_node",
loop_router,
{
"loop_node": "loop_node", # 回环
"final_node": "final_node" # 终止
}
)
graph = builder.compile()
print(graph.invoke(TaskState(user_query="test")))运行结果
🔄 loop_node, progress = 0
🔄 loop_node, progress = 30
🔄 loop_node, progress = 60
🔄 loop_node, progress = 90
🔹 final_node
{'user_query': 'test', 'intent': '', 'result': '', 'progress': 100}也可以看一下图的执行状态(在ipynb代码里执行)
from IPython.display import Image, display
display(Image(graph.get_graph().draw_mermaid_png()))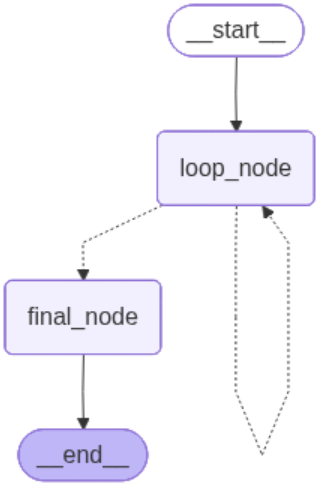
循环边本质是“返回前序节点”的条件边,用于需要重复执行的场景(比如校验结果不合格,重新调用工具)
6.2.4总结
- 状态(State):存数据、做共享,是工作流的“中枢”,用Pydantic定义更清晰。
- 节点(Nodes):做执行、处理逻辑,是“功能单元”,必须是纯函数。
- 边(Edges):定路线、控顺序,分固定边(线性)和条件边(分支/循环)。
三者组合的核心逻辑:状态贯穿全程,节点处理逻辑,边控制流向,这也是LangGraph能实现复杂工作流的根本。
6.3 LangGraph运行机制:基于超步骤的消息传递
了解了三大组件后,我们再来看LangGraph的运行机制。LangGraph采用“超步骤(super-step)”机制管理执行流程,确保节点执行的有序性和状态的一致性。
LangGraph 工作流是如何“跑起来”的?
LangGraph 的工作流执行过程,可以理解为:👉 状态驱动的任务调度引擎。
它不是简单地按顺序调用函数,而是像一个智能调度器,根据状态和边规则动态决定“谁该执行”。
6.3.1 超步骤(Super-step)与节点活跃状态
超步骤是LangGraph执行工作流的基本单位,可理解为“一轮并行任务执行周期”。每个超步骤内,框架会完成三件事:
- 激活节点:所有收到消息(状态更新)的节点会从“休眠状态”变为“活跃状态”;
- 执行节点:所有活跃节点并行执行逻辑,生成新的状态片段;
- 传递消息:将新的状态片段作为消息,传递给下一个节点,同时节点回归休眠状态。
这种机制让LangGraph天然支持并行执行——同一超步骤内的活跃节点可同时运行,提升流程效率;同时通过消息传递实现节点间的协同,确保状态一致性。
⚙️ 节点活跃状态:谁在这一轮被调度?
在某个超步骤中:
- 可能只激活一个节点
- 也可能同时激活多个节点
👉 这些被激活的节点叫 活跃节点(Active Nodes), 类比👉像多名工人同时在流水线上工作。
6.3.2 LangGraph 工作流执行全过程
一个完整的LangGraph工作流执行流程可分为六个阶段:
1.启动:调用graph.invoke()方法传入初始状态,框架将初始状态作为消息,发送给入口节点,入口节点被激活,进入第一个超步骤。
用户输入:{"user_query": "什么是 LangGraph?"}
系统创建 初始状态黑板,并激活起始节点。2.节点激活:入口节点接收消息后变为活跃状态,其他节点保持休眠。
LangGraph 查看 Graph:
parse → tool → generate
决定当前应执行的节点集合,例如:
当前激活节点 = [parse]3.逻辑执行:活跃节点执行自身逻辑,读取初始状态,生成更新后的状态片段。
每个活跃节点:
读取状态
执行逻辑
返回状态更新
例如:{"tool_result": "..."}4.状态传递:框架合并状态片段为新的全局状态,根据边的规则,将新状态作为消息传递给下一个(或多个)节点,激活对应节点。
LangGraph 自动执行:
state = merge(old_state, node_return)
更新后的状态会传递给下一级节点。5.停止判断:是否继续执行?
系统判断:
是否还有后续节点
是否触发 END
是否满足循环终止条件6.终止:输出最终结果
当没有可执行节点时:
👉 返回最终状态
👉 输出 AI 结果好啦,你现在已经掌握了LangGraph的精髓~~~
6.3.3 并行与顺序执行
LangGraph的调度规则核心是“基于节点依赖关系”,分为顺序执行和并行执行两种场景,具体由边的配置和节点依赖决定:
1. 顺序执行:当节点A的后续节点只有节点B,且节点B依赖节点A的状态结果时,触发顺序执行——节点A执行完成并更新状态后,节点B才被激活,即“一超步骤一节点”。
适用场景:步骤间有强依赖(如摘要生成依赖去重后的文本,敏感词校验依赖摘要结果),前文案例均为顺序执行场景。
2. 并行执行:当节点A的后续节点有多个(如节点B和节点C),且节点B、C无相互依赖,仅依赖节点A的状态结果时,触发并行执行——节点A执行完成后,节点B、C被同时激活,纳入同一个超步骤并行执行。
适用场景:步骤间无依赖,比如现在有一个文体,同时生成文本的摘要和关键词(注意,摘要和关键词一般认为这2个是没有联系的)
from langgraph.graph import StateGraph, START, END
from typing import Optional
from typing import TypedDict, Optional, NotRequired
import time
import random
# ===== 1. 定义状态(共享黑板) =====
class TextProcessState(TypedDict):
raw_text: str
summary_text: NotRequired[str]
keyword_text: NotRequired[str]
has_sensitive: NotRequired[bool]
final_text: NotRequired[str]
# ===== 2. 去重节点(入口节点) =====
def deduplicate_node(state: TextProcessState):
print("\n【节点 deduplicate】执行中...")
text = state["raw_text"] # ✅ TypedDict 访问方式
time.sleep(1)
return {"raw_text": text}
# ===== 3. 摘要节点(并行节点1) =====
def summary_node(state: TextProcessState):
print("⚡ 并行节点 summary 执行中...")
time.sleep(random.uniform(1, 2))
summary = "摘要:" + state["raw_text"][:10]
return {"summary_text": summary}
# ===== 4. 关键词节点(并行节点2) =====
def keyword_node(state: TextProcessState):
print("⚡ 并行节点 keyword 执行中...")
time.sleep(random.uniform(1, 2))
keywords = "、".join(state["raw_text"].split(",")[:3])
return {"keyword_text": keywords}
# ===== 5. 并行汇合节点 =====
def sensitive_check_node(state: TextProcessState):
print("\n【节点 sensitive_check】汇总并行结果")
print(" summary_text =", state["summary_text"])
print(" keyword_text =", state["keyword_text"])
sensitive = "暴力" in state["raw_text"]
return {
"has_sensitive": sensitive,
"final_text": f"最终输出 | 摘要={state['summary_text']} | 关键词={state['keyword_text']}"
}
# ===== 6. 构建 LangGraph =====
builder = StateGraph(TextProcessState)
builder.add_node("deduplicate", deduplicate_node)
builder.add_node("summary", summary_node)
builder.add_node("keyword", keyword_node)
builder.add_node("sensitive_check", sensitive_check_node)
builder.add_edge(START, "deduplicate")
# 并行分叉
builder.add_edge("deduplicate", "summary")
builder.add_edge("deduplicate", "keyword")
# 并行汇合
builder.add_edge("summary", "sensitive_check")
builder.add_edge("keyword", "sensitive_check")
builder.add_edge("sensitive_check", END)
graph = builder.compile()
# ===== 7. 运行 =====
if __name__ == "__main__":
init_state = TextProcessState(
raw_text="LangGraph很强大,支持状态管理,支持动态分支,并行执行"
)
final_state = graph.invoke(init_state)
print("\n====== 最终状态 ======")
print(final_state)运行结果
【节点 deduplicate】执行中...
⚡ 并行节点 keyword 执行中...
⚡ 并行节点 summary 执行中...
【节点 sensitive_check】汇总并行结果
summary_text = 摘要:LangGraph很
keyword_text = LangGraph很强大、支持状态管理、支持动态分支
====== 最终状态 ======
{'raw_text': 'LangGraph很强大,支持状态管理,支持动态分支,并行执行', 'summary_text': '摘要:LangGraph很', 'keyword_text': 'LangGraph很强大、支持状态管理、支持动态分支', 'has_sensitive': False, 'final_text': '最终输出 | 摘要=摘要:LangGraph很 | 关键词=LangGraph很强大、支持状态管理、支持动态分支'}学习小结:顺序执行依赖“单后续节点+强状态依赖”,并行执行依赖“多后续节点+无相互依赖”;LangGraph会自动根据节点依赖和边配置选择调度方式,无需手动设置“并行/顺序”,一般而言只需关注业务逻辑的依赖关系即可。
6.4 综合实操
本节将通过三个递进式综合案例,从简单到复杂构建完整工作流,覆盖线性、分支、循环三种核心场景,帮助大家整合所学知识,实现“从理论到落地”的跨越。所有案例均采用LangGraph 1.0+接口,代码可直接运行(替换API密钥即可)
6.4.1 实操准备:LangGraph环境确认与核心API导入
首先确保环境配置正确,核心依赖安装完成,同时梳理常用核心API,方便后续案例调用:
1. 环境依赖安装:
pip install langgraph langchain langchain-openai python-dotenv推荐安装版本 ≥1.0.0
2. 核心API导入
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(
api_key=os.getenv("API_KEY"),
base_url="https://api.deepseek.com",
model="deepseek-chat",
temperature=0.3
)6.4.2 案例1:简单线性工作流——文本处理全流程串联
学习目标:整合“状态、节点、边”三大组件,构建“文本去重→摘要生成→敏感词校验→结果输出”的线性流程,掌握完整工作流的搭建、运行与结果校验方法,同时体验状态快照与可视化功能。
6.4.2.1 案例设计思路
流程逻辑:用户输入原始文本→先去重清理冗余内容→生成简洁摘要→校验摘要是否含敏感词→格式化输出结果。全程用固定边串联节点,依赖状态传递数据,最终通过可视化图结构和状态历史,验证流程正确性。
知识点: 状态字段的完整设计、节点函数复用与组合、固定边配置、图可视化、状态历史追溯。
完整代码实现
from typing import TypedDict
# 兼容低版本 Python 的 NotRequired 导入
try:
from typing import NotRequired
except ImportError:
from typing_extensions import NotRequired
from langgraph.graph import StateGraph, START, END
from langchain_core.prompts import PromptTemplate
from langgraph.checkpoint.memory import MemorySaver
# DeepSeek LLM(真实模型)
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
# 加载环境变量
load_dotenv()
# 提前校验 API Key,避免运行时报错模糊
api_key = os.getenv("API_KEY")
if not api_key:
raise ValueError("未在环境变量中检测到 API_KEY,请检查 .env 文件配置")
# 初始化真实 LLM
llm = ChatOpenAI(
api_key=api_key,
base_url="https://api.deepseek.com/",
model="deepseek-v4-flash",
temperature=0.6
)
# ==========================================================
# 1. 定义 State(工作流共享状态 = Agent 内存)
# ==========================================================
class TextProcessState(TypedDict):
"""
LangGraph 状态对象:
用于在节点之间传递数据(类似全局共享内存)
"""
raw_text: str # 输入:用户原始文本
deduplicated_text: NotRequired[str] # 过程:去重后的文本
summary_text: NotRequired[str] # 过程:LLM 生成摘要
has_sensitive: NotRequired[bool] # 过程:敏感词检测结果
final_output: NotRequired[str] # 输出:最终格式化结果
# ==========================================================
# 2. 定义节点函数(每个节点 = 一个处理模块)
# ==========================================================
def deduplicate_node(state: TextProcessState) -> TextProcessState:
"""文本去重节点:去除内容完全一致(忽略首尾空格)的重复行,丢弃纯空白行"""
raw_text = state["raw_text"]
lines = raw_text.split("\n")
unique_lines = []
seen = set()
for line in lines:
line_stripped = line.strip()
# 过滤纯空白行,且未出现过该文本
if line_stripped and line_stripped not in seen:
seen.add(line_stripped)
unique_lines.append(line)
result_text = "\n".join(unique_lines)
print("✅ 去重节点执行完成")
# 复制原有状态,仅更新输出字段
new_state = state.copy()
new_state["deduplicated_text"] = result_text
return new_state
def summary_node(state: TextProcessState) -> dict:
"""摘要生成节点(调用LLM)"""
deduplicated_text = state["deduplicated_text"]
prompt = PromptTemplate(
input_variables=["text"],
template="请为以下文本生成50字以内的简洁摘要,保留核心信息:\n{text}"
)
chain = prompt | llm
summary = chain.invoke({"text": deduplicated_text}).content
print("🤖 摘要节点执行完成")
return {"summary_text": summary}
def sensitive_check_node(state: TextProcessState) -> dict:
"""敏感词检测节点"""
summary = state["summary_text"]
sensitive_words = ["敏感词1", "敏感词2", "违法", "违规"]
has_sensitive = any(word in summary for word in sensitive_words)
print("🔍 敏感词检测完成:", has_sensitive)
return {"has_sensitive": has_sensitive}
def output_node(state: TextProcessState) -> dict:
"""输出节点(根据敏感词结果格式化)"""
summary = state["summary_text"]
has_sensitive = state["has_sensitive"]
if has_sensitive:
final_output = "⚠️ 检测到敏感内容,无法输出摘要"
else:
final_output = f"""✅ 文本处理完成
【摘要】
{summary}
【去重后原文】
{state['deduplicated_text']}
"""
print("📤 输出节点执行完成")
return {"final_output": final_output}
# ==========================================================
# 3. 构建线性工作流图(固定边)
# ==========================================================
def build_linear_graph():
"""构建线性 LangGraph 工作流,**实际启用状态历史**"""
graph_builder = StateGraph(TextProcessState)
# 注册节点
graph_builder.add_node("deduplicate", deduplicate_node)
graph_builder.add_node("summary", summary_node)
graph_builder.add_node("sensitive_check", sensitive_check_node)
graph_builder.add_node("output", output_node)
# 配置固定边(线性执行)
graph_builder.add_edge(START, "deduplicate")
graph_builder.add_edge("deduplicate", "summary")
graph_builder.add_edge("summary", "sensitive_check")
graph_builder.add_edge("sensitive_check", "output")
graph_builder.add_edge("output", END)
# 编译时传入MemorySaver,真正启用状态历史
# MemorySaver:内存级检查点,适合测试/开发,重启程序后状态丢失
return graph_builder.compile(checkpointer=MemorySaver())
# ==========================================================
# 4. 测试运行(get_state_history 可正常使用)
# ==========================================================
if __name__ == "__main__":
# 构建图
linear_graph = build_linear_graph()
# 初始状态(输入数据)
test_state: TextProcessState = {
"raw_text": "LangGraph是LangChain生态的工作流框架\nLangGraph支持状态管理\nLangGraph是LangChain生态的工作流框架\n支持动态分支和并行执行"
}
# thread_id:会话唯一标识,测试用随便命名,多会话用不同id即可
config = {"configurable": {"thread_id": "text_process_test_001"}}
# 执行工作流
final_state = linear_graph.invoke(test_state, config=config)
# 输出最终结果
print("\n" + "=" * 50)
print(final_state["final_output"])
# 查看状态历史
print("\n" + "=" * 50)
history = list(linear_graph.get_state_history(config))
print("状态快照数量:", len(history))
print("提示:get_state_history 默认按时间倒序返回,最新状态排在最前\n")
for i, snapshot in enumerate(history, 1):
print(f"第{i}步快照:")
print("状态数据:", snapshot.values)
print("下一节点:", snapshot.next)
print("-" * 30)运行结果
去重节点执行完成
🤖 摘要节点执行完成
🔍 敏感词检测完成: False
📤 输出节点执行完成
==================================================
✅ 文本处理完成
【摘要】
LangGraph是LangChain生态的工作流框架,支持状态管理、动态分支与并行执行。
【去重后原文】
LangGraph是LangChain生态的工作流框架
LangGraph支持状态管理
支持动态分支和并行执行
==================================================
状态快照数量(超步骤): 6
第1步:
state StateSnapshot(values={...也可以看一下图的执行状态
png_data = linear_graph.get_graph().draw_mermaid_png() # 获取PNG字节流
with open("linear_text_process_graph.png", "wb") as file: # wb=二进制写入
file.write(png_data)
print("📊 工作流可视化图已保存:linear_text_process_graph.png\n")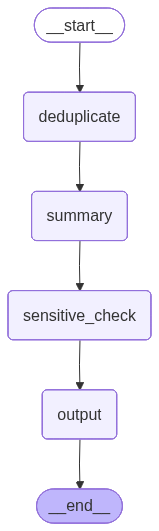
6.4.3 案例2:分支工作流——带结果校验的动态文本处理
本案例目标:在案例1基础上,新增“摘要质量校验”分支逻辑,实现“质量合格→输出结果”“质量不合格→回退重生成”的动态流转,掌握条件边配置、分支节点设计与状态依赖处理。
6.4.3.1 案例设计思路
流程逻辑:文本去重→生成摘要→敏感词校验(过滤风险)→摘要质量校验(判断是否符合长度、信息完整性)→质量合格则输出,不合格则回退到摘要生成节点重生成(限制重生成次数,避免无限循环)。
知识点: 条件边多分支配置、循环逻辑设计、状态字段扩展(记录重生成次数)、循环终止条件控制。
# ================== 依赖 ==================
from typing import TypedDict, NotRequired
from langgraph.graph import StateGraph, START, END
from langchain_core.prompts import PromptTemplate
from langgraph.checkpoint.memory import MemorySaver
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
# ================== LLM 初始化 ==================
load_dotenv()
llm = ChatOpenAI(
api_key=os.getenv("API_KEY"),
base_url="https://api.deepseek.com",
model="deepseek-chat",
temperature=0.3
)
# ==========================================================
# 6.4.3 分支工作流案例:带结果校验的动态文本处理
# ==========================================================
# ----------------------------------------------------------
# 1️⃣ 状态定义:扩展工作流状态(新增循环控制字段)
# ----------------------------------------------------------
class BranchTextProcessState(TypedDict):
"""分支工作流共享状态(类似共享黑板)"""
# 输入字段
raw_text: str
# 中间过程字段(可选)
deduplicated_text: NotRequired[str]
summary_text: NotRequired[str]
has_sensitive: NotRequired[bool]
# 循环控制字段
rewrite_count: NotRequired[int] # 重生成次数
quality_valid: NotRequired[bool] # 摘要质量是否合格
# 最终输出
final_output: NotRequired[str]
# ----------------------------------------------------------
# 2️⃣ 节点定义(工作流执行单元)
# ----------------------------------------------------------
# === 文本去重节点 ===
def deduplicate_node(state: BranchTextProcessState):
raw_text = state["raw_text"]
lines = raw_text.split("\n")
seen, unique_lines = set(), []
for line in lines:
line = line.strip()
if line and line not in seen:
seen.add(line)
unique_lines.append(line)
print("✅ [Node] 去重完成")
return {"deduplicated_text": "\n".join(unique_lines)}
# === 摘要生成节点 ===
def summary_node(state: BranchTextProcessState):
text = state.get("deduplicated_text", "")
if not text:
return {"summary_text": "无有效文本"}
prompt = PromptTemplate(
input_variables=["text"],
template="请为以下文本生成50字以内摘要,保留核心信息:\n{text}"
)
summary = (prompt | llm).invoke({"text": text}).content
print("🤖 [Node] 摘要生成:", summary)
return {"summary_text": summary}
# === 敏感词检测节点 ===
def sensitive_check_node(state: BranchTextProcessState):
summary = state.get("summary_text", "")
sensitive_words = ["违法", "违规"]
has_sensitive = any(w in summary for w in sensitive_words)
print(f"🔍 [Node] 敏感词检测: {has_sensitive}")
return {"has_sensitive": has_sensitive}
# === 摘要质量校验节点(教学重点) ===
def quality_check_node(state: BranchTextProcessState):
summary = state.get("summary_text", "")
# 长度校验
length_valid = 15 <= len(summary) <= 50
# 信息完整性校验
core_keywords = ["LangGraph", "工作流"]
info_valid = all(k in summary for k in core_keywords)
quality_valid = length_valid and info_valid
print(f"📏 [Node] 质量校验 | 长度OK={length_valid} | 关键词OK={info_valid} | 合格={quality_valid}")
return {"quality_valid": quality_valid}
# === 重生成次数更新节点 ===
def update_rewrite_count_node(state: BranchTextProcessState):
count = state.get("rewrite_count", 0) + 1
print(f"🔢 [Node] 重生成次数 -> {count}")
return {"rewrite_count": count}
# ----------------------------------------------------------
# 3️⃣ Router:条件分支决策(LangGraph 核心)
# ----------------------------------------------------------
def rewrite_router(state: BranchTextProcessState):
quality = state.get("quality_valid", False)
count = state.get("rewrite_count", 0)
print(f"🚦 [Router] quality={quality}, rewrite_count={count}")
# 质量合格 → 输出
if quality:
return "to_output"
# 不合格且次数 < 2 → 重生成
if count < 2:
return "to_rewrite"
# 次数耗尽 → 强制输出
return "to_force_output"
# ----------------------------------------------------------
# 4️⃣ 输出节点
# ----------------------------------------------------------
# 正常输出
def output_node(state: BranchTextProcessState):
summary = state.get("summary_text", "")
has_sensitive = state.get("has_sensitive", False)
if has_sensitive:
final_output = "⚠️ 检测到敏感内容,禁止输出摘要"
else:
final_output = f"""
✅ 文本处理完成
重生成次数: {state.get('rewrite_count', 0)}
【摘要】
{summary}
【去重原文】
{state.get('deduplicated_text')}
"""
print("📤 [Node] 正常输出")
return {"final_output": final_output}
# 强制输出
def force_output_node(state: BranchTextProcessState):
summary = state.get("summary_text", "")
final_output = f"""
⚠️ 摘要多次重生成仍不合格(教学示例)
重生成次数: {state.get('rewrite_count', 0)}
摘要长度: {len(summary)}
强制输出摘要:
{summary}
"""
print("📤 [Node] 强制输出")
return {"final_output": final_output}
# ----------------------------------------------------------
# 5️⃣ 构建 LangGraph 分支工作流
# ----------------------------------------------------------
def build_branch_graph():
graph = StateGraph(BranchTextProcessState)
# 注册节点
graph.add_node("deduplicate", deduplicate_node)
graph.add_node("summary", summary_node)
graph.add_node("sensitive_check", sensitive_check_node)
graph.add_node("quality_check", quality_check_node)
graph.add_node("update_rewrite_count", update_rewrite_count_node)
graph.add_node("output", output_node)
graph.add_node("force_output", force_output_node)
# 固定执行路径
graph.add_edge(START, "deduplicate")
graph.add_edge("deduplicate", "summary")
graph.add_edge("summary", "sensitive_check")
graph.add_edge("sensitive_check", "quality_check")
# 条件分支(教学核心)
graph.add_conditional_edges(
"quality_check",
rewrite_router,
{
"to_output": "output",
"to_rewrite": "update_rewrite_count",
"to_force_output": "force_output",
}
)
# 循环回退路径
graph.add_edge("update_rewrite_count", "summary")
# 结束节点
graph.add_edge("output", END)
graph.add_edge("force_output", END)
return graph.compile(checkpointer=MemorySaver())
# ----------------------------------------------------------
# 6️⃣ 运行测试(课堂演示用)
# ----------------------------------------------------------
if __name__ == "__main__":
branch_graph = build_branch_graph()
# 初始状态
test_state: BranchTextProcessState = {
"raw_text": "LangGraph是LangChain生态下的有状态工作流框架,支持图结构建模、状态追溯、动态分支和并行执行,适用于复杂AI任务编排",
"rewrite_count": 0,
}
config = {"configurable": {"thread_id": "branch_workflow_demo"}}
print("\n🚀 启动分支工作流示例\n" + "=" * 60)
final_state = branch_graph.invoke(test_state, config=config)
# 输出结果
print("\n🎯 最终结果:")
print(final_state["final_output"])
print("\n📊 执行统计:")
print("重生成次数:", final_state.get("rewrite_count"))
print("质量是否合格:", final_state.get("quality_valid"))
# 状态历史(教学亮点)
history = list(branch_graph.get_state_history(config))
print(f"\n📜 状态历史步数: {len(history)}")
# 可视化图
png_data = branch_graph.get_graph().draw_mermaid_png()
with open("branch_workflow_graph.png", "wb") as f:
f.write(png_data)
print("📊 工作流图已保存: branch_workflow_graph.png")运行结果
🚀 启动分支工作流示例
============================================================
✅ [Node] 去重完成
🤖 [Node] 摘要生成: LangGraph是LangChain生态的有状态工作流框架,支持图结构建模、状态追溯、动态分支和并行执行,适用于复杂AI任务编排。
🔍 [Node] 敏感词检测: False
📏 [Node] 质量校验 | 长度OK=False | 关键词OK=True | 合格=False
🚦 [Router] quality=False, rewrite_count=0
🔢 [Node] 重生成次数 -> 1
🤖 [Node] 摘要生成: LangGraph是LangChain生态的有状态工作流框架,支持图结构建模、状态追溯、动态分支和并行执行,适用于复杂AI任务编排。
🔍 [Node] 敏感词检测: False
📏 [Node] 质量校验 | 长度OK=False | 关键词OK=True | 合格=False
🚦 [Router] quality=False, rewrite_count=1
🔢 [Node] 重生成次数 -> 2
🤖 [Node] 摘要生成: LangGraph是LangChain生态的有状态工作流框架,支持图结构建模、状态追溯、动态分支和并行执行,适用于复杂AI任务编排。
🔍 [Node] 敏感词检测: False
📏 [Node] 质量校验 | 长度OK=False | 关键词OK=True | 合格=False
🚦 [Router] quality=False, rewrite_count=2
📤 [Node] 强制输出
🎯 最终结果:
⚠️ 摘要多次重生成仍不合格(教学示例)
重生成次数: 2
摘要长度: 66
强制输出摘要:
LangGraph是LangChain生态的有状态工作流框架,支持图结构建模、状态追溯、动态分支和并行执行,适用于复杂AI任务编排。
📊 执行统计:
重生成次数: 2
质量是否合格: False
📜 状态历史步数: 15
📊 工作流图已保存: branch_workflow_graph.png我们看一下工作图
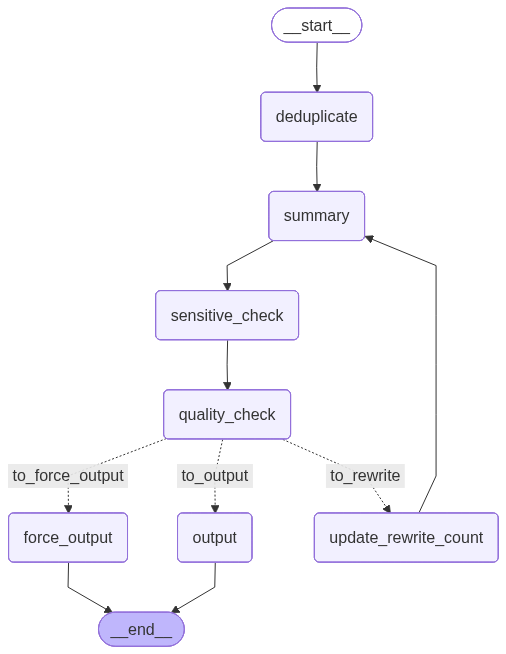
6.4.4 案例3:循环工作流——人机交互式文本优化
本案例目标:构建“用户输入→文本优化→结果反馈→用户确认→确认通过→结束/确认不通过→重新优化”的多轮交互循环流程,模拟智能编辑助手场景,掌握循环边、人机交互节点、持久化状态的使用。
6.4.4.1 案例设计思路
流程逻辑:用户输入待优化文本→AI优化文本→生成优化建议→展示结果给用户→用户输入“确认”则结束,输入“修改”则回退到优化节点重新生成,输入“退出”则终止流程。核心是实现“机器节点→人机交互节点→循环/终止”的闭环。
知识点:循环边配置、动态输入接收、流程中断控制。
import os
from typing import TypedDict, Optional
from dotenv import load_dotenv
from langgraph.graph import StateGraph, START, END
from langchain_core.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
from langgraph.checkpoint.memory import MemorySaver
# ------------------------------
# 1. 环境加载与模型初始化(保留你的DeepSeek配置,无任何修改)
# ------------------------------
load_dotenv() # 加载.env中的API_KEY
llm = ChatOpenAI(
api_key=os.getenv("API_KEY"),
base_url="https://api.deepseek.com",
model="deepseek-chat",
temperature=0.3
)
# ------------------------------
# 2. 定义交互式状态(强类型,持久化存储所有流程数据)
# ------------------------------
class InteractiveOptState(TypedDict):
user_input: str # 固定:用户原始输入(全程不变)
optimized_text: Optional[str] # 每轮覆盖:AI优化后文本(只保留最新一版)
optimize_suggest: Optional[str]# 每轮覆盖:优化建议/理由(只保留最新一版)
user_feedback: Optional[str] # 每轮覆盖:用户反馈(确认/修改/退出)
final_result: Optional[str] # 最终:流程结束时写入
# ------------------------------
# 3. 核心节点函数(无任何修改,保留你的原代码)
# ------------------------------
def optimize_node(state: InteractiveOptState) -> InteractiveOptState:
"""【机器节点】文本优化核心节点,使用管道符调用LLM"""
user_input = state["user_input"]
user_feedback = state["user_feedback"]
if not user_feedback:
prompt = PromptTemplate(
input_variables=["text"],
template="请优化以下文本,提升流畅度和专业度,严格保留核心信息:\n{text}\n优化完成后,单独一行以【优化理由:】开头给出1-2条简洁优化原因"
)
chain = prompt | llm
result = chain.invoke({"text": user_input}).content
else:
prompt = PromptTemplate(
input_variables=["text", "feedback"],
template="根据用户反馈针对性优化文本,严格保留核心信息:\n原文本:{text}\n用户反馈:{feedback}\n优化完成后,单独一行以【优化理由:】开头给出1-2条简洁优化原因"
)
chain = prompt | llm
result = chain.invoke({"text": user_input, "feedback": user_feedback}).content
split_flag = "【优化理由:】"
if split_flag in result:
optimized_text, optimize_suggest = result.split(split_flag, 1)
else:
optimized_text = result
optimize_suggest = "AI未生成明确优化理由,建议重新优化"
return {
"optimized_text": optimized_text.strip(),
"optimize_suggest": optimize_suggest.strip()
}
def feedback_node(state: InteractiveOptState) -> InteractiveOptState:
"""【人机交互节点】展示优化结果,接收用户操作和具体修改意见"""
print("\n" + "-"*60)
print("📝 AI优化后文本:")
print(state["optimized_text"])
print("\n💡 优化建议/理由:")
print(state["optimize_suggest"])
print("\n" + "-"*60)
while True:
action = input("请选择操作(确认/修改/退出):").strip()
if action == "确认" or action == "退出":
return {"user_feedback": action}
if action == "修改":
detail = input("请输入具体修改意见:").strip()
if detail:
return {"user_feedback": detail}
print("❌ 修改意见不能为空,请重新输入\n")
else:
print("❌ 请输入「确认」「修改」或「退出」\n")
def feedback_router(state: InteractiveOptState) -> str:
"""【条件路由】确认→结束,退出→终止,其他内容都是修改意见→回到优化节点"""
feedback = state["user_feedback"]
if feedback == "确认":
return "final"
if feedback == "退出":
return "exit"
return "optimize"
def final_node(state: InteractiveOptState) -> InteractiveOptState:
"""【机器节点】流程正常结束,生成格式化结果"""
final_result = (
"✅ 【多轮文本优化流程完成】\n"
f"📌 最终优化文本:\n{state['optimized_text']}\n"
f"💡 优化核心总结:\n{state['optimize_suggest']}"
)
return {"final_result": final_result}
def exit_node(state: InteractiveOptState) -> InteractiveOptState:
"""【机器节点】用户主动退出,生成终止提示"""
return {"final_result": "🔚 【文本优化流程终止】\n你主动退出,本次无最终优化结果"}
# ------------------------------
# 4. 搭建循环交互图(无任何修改,保留你的原代码)
# ------------------------------
def build_interactive_graph():
"""构建LangGraph循环状态图,彻底适配最新API终极规范"""
graph_builder = StateGraph(InteractiveOptState)
# 添加节点(无修改)
graph_builder.add_node("optimize", optimize_node)
graph_builder.add_node("feedback", feedback_node)
graph_builder.add_node("final", final_node)
graph_builder.add_node("exit", exit_node)
# 配置普通边(无修改)
graph_builder.add_edge(START, "optimize")
graph_builder.add_edge("optimize", "feedback")
# 适配最新API:source + path
graph_builder.add_conditional_edges(
source="feedback", # 分支起始节点
path=feedback_router # 路由函数(直接返回目标节点名)
)
# 配置结束边(无修改)
graph_builder.add_edge("final", END)
graph_builder.add_edge("exit", END)
# 编译图:开启状态持久化(多轮交互必需)
return graph_builder.compile(checkpointer=MemorySaver())
# ------------------------------
# 5. 运行交互测试(★仅修改初始输入部分★,改为用户手动输入+非空校验)
# ------------------------------
if __name__ == "__main__":
# 构建循环图(彻底解决所有API报错)
interactive_graph = build_interactive_graph()
print("🔧 多轮交互式文本优化工具已启动(适配LangGraph最新API)...\n")
# ★核心修改:用户手动输入待优化句子 + 非空校验★
print("="*40 + " 输入待优化句子 " + "="*40)
while True:
user_input_text = input("请输入需要AI优化的句子:").strip()
if user_input_text: # 非空校验,避免用户输入空内容
break
print("❌ 输入不能为空,请重新输入需要优化的句子!\n")
# 初始状态:使用用户输入的句子,其余字段保持默认
initial_state: InteractiveOptState = {
"user_input": user_input_text, # 替换为用户输入的内容
"optimized_text": None,
"optimize_suggest": None,
"user_feedback": None,
"final_result": None
}
# 启动多轮交互流程(保留你的config配置)
print(f"\n🚀 已接收你的句子,开始第一轮AI优化...")
config = {"configurable": {"thread_id": "text_process_test_001"}}
final_state = interactive_graph.invoke(initial_state, config=config)
# 展示最终结果
print("\n" + "="*60)
print(final_state["final_result"])
print("="*60)
# 展示交互轮次(状态持久化验证)
history = list(interactive_graph.get_state_history(config))
interact_rounds = len(history) // 2 # 每轮=优化节点+反馈节点
print("状态快照数量(超步骤):", len(history))
# 保存可视化流程图(保留你的原代码)
png_data = interactive_graph.get_graph().draw_mermaid_png() # 获取PNG字节流
with open("interactive_optimize_graph.png", "wb") as file: # wb=二进制写入
file.write(png_data)
print("📊 工作流可视化图已保存:interactive_optimize_graph.png\n")运行结果
请输入需要AI优化的句子:LangGraph这工具不错,能做工作流,比以前的Chain好用
------------------------------------------------------------
📝 AI优化后文本:
LangGraph是一款优秀的工作流构建工具,相较于传统的Chain方案,其在功能与实用性上表现更为出色。
💡 优化建议/理由:
1. 将口语化、模糊的表达转化为具体、专业的表述,如将”不错”明确为”优秀”,”好用”具体化为”在功能与实用性上表现更为出色”。
2. 优化了句子结构与逻辑关系,使对比更清晰、论述更流畅,提升了整体表达的严谨性。
------------------------------------------------------------
请选择操作(确认/修改/退出):修改
请输入具体修改意见:语气太正式了,保持口语化风格,但让逻辑更清晰
------------------------------------------------------------
📝 AI优化后文本:
LangGraph这个工具挺好用的,专门做工作流编排,比之前的Chain灵活不少,分支和循环都能搞定。
💡 优化建议/理由:
1. 保留了口语化风格(”挺好用””不少””搞定”),同时补充了具体优势点(”分支和循环”),让表达更有信息量。
2. 用”灵活”替代模糊的”好用”,更准确地传达对比差异。
------------------------------------------------------------
请选择操作(确认/修改/退出):确认
✅ 【多轮文本优化流程完成】
📌 最终优化文本:
LangGraph这个工具挺好用的,专门做工作流编排,比之前的Chain灵活不少,分支和循环都能搞定。
💡 优化核心总结:
1. 保留了口语化风格(”挺好用””不少””搞定”),同时补充了具体优势点(”分支和循环”),让表达更有信息量。
2. 用”灵活”替代模糊的”好用”,更准确地传达对比差异。
============================================================核心小结:
1. 人机交互节点设计:feedback_node通过input()函数接收用户手动输入,实现“机器流程→人工干预→机器流程”的闭环,这类节点在智能助手、审批系统等场景中高频使用,核心是“状态接收用户输入,驱动后续流程”。
2. 动态优化适配:optimize_node根据“user_feedback”是否存在,切换不同提示词,实现“针对性优化”——体现了状态的“记忆能力”,让多轮交互更智能,而非机械重复。
3. 流程中断控制:通过“退出”分支直接终止流程,无需等待循环条件满足,给用户主动控制权,实际开发中可扩展为“超时退出”“异常退出”等多场景中断逻辑。
6.4.5 综合实操小结
本节三个案例从“线性→分支→循环”逐步递进,覆盖了LangGraph工作流的核心应用场景,核心要点可归纳为三点:
第一,状态是核心枢纽:所有流程流转、节点协作都依赖状态,字段设计需“覆盖全链路需求”,同时通过状态历史实现追溯,这是LangGraph与其他工作流框架的核心差异。
第二,边是流程灵魂:固定边保障基础线性流转,条件边实现动态分支,循环边支撑多轮交互,三类边的灵活组合可适配绝大多数复杂场景,配置时需重点关注“分支判断逻辑”和“循环终止条件”。
第三,节点是功能载体:节点可封装任意逻辑(LLM调用、工具调用、人机交互),适配状态接口即可复用,开发时需遵循“单一职责”,避免节点逻辑过于复杂,便于调试和维护。
6.5 本章总结与实践建议
6.5.1 核心知识梳理
本章围绕LangGraph三大核心组件(状态、节点、边)展开,从基础概念到融合实操,构建了“组件→机制→应用”的知识体系:
- 组件核心:状态是数据枢纽,节点是功能载体,边是路径灵魂,三者的灵活组合是构建复杂工作流的基础。
- 运行机制:以超步骤为单位的消息传递的,支持顺序与并行执行,理解该机制可精准调试流程执行顺序与节点依赖。
- 融合应用:LangGraph可无缝集成RAG、智能体、外部工具,实现“检索→生成→优化”“工具调用→分支决策”等生产级流程,解决传统线性流程的刚性问题。
6.5.2 实践落地建议
- 从小场景入手:首次落地可从线性流程(如文本处理)开始,熟练后逐步添加分支、循环逻辑,再融合RAG、智能体等复杂场景。
- 重视状态设计:字段需覆盖“输入→过程→输出”全链路,避免冗余字段,同时预留调试字段(如重试次数、质量分数),便于问题排查。
- 节点拆分原则:遵循“单一职责”,将复杂逻辑拆分为多个轻量节点,便于单独调试、复用和扩展,避免单个节点逻辑过于臃肿。
- 强化容错设计:生产级流程需添加异常捕获、重试机制、循环终止条件,避免工具调用失败、逻辑错误导致流程卡死。
6.5.3 实践练习
完成本章中的langgraph学习案例,从实践中感悟langgraph的特性,完成综合实操的3个案例,针对案例3进行优化,进一步提升智能体的效果。