Appearance
入门案例
1. 聊天机器人(ChatBot)
难度:入门 | 模式:链式 + 循环 | 关键词:对话历史、多轮对话
1.1 架构
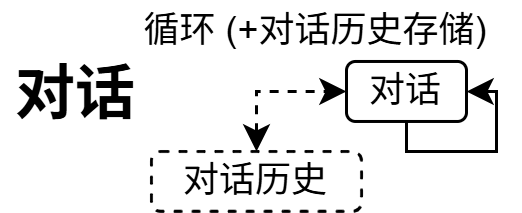
对话循环:循环 + 对话历史存储
1.2 核心思路
聊天机器人是最基础的 LLM 应用,它的 Flow 只有三个节点:
- GetInput:从用户获取输入,将其追加到
shared["history"] - CallLLM:拼接对话历史为 prompt,调用 LLM API
- SendReply:输出回复,
post()返回"continue"跳回 GetInput
1.3 关键代码
下面是完整的聊天机器人实现。注意 SendReply 的 post() 返回 "continue" 跳回 GetInput,形成对话循环:
python
from pocketflow import Node, Flow
class GetInput(Node):
def prep(self, shared):
return shared.get("history", [])
def exec(self, history):
user_input = input("You: ")
return user_input
def post(self, shared, prep_res, exec_res):
if exec_res.lower() == "quit":
return "end"
shared.setdefault("history", []).append(
{"role": "user", "content": exec_res}
)
return "default"
class CallLLM(Node):
def prep(self, shared):
return shared["history"]
def exec(self, history):
# 调用你的 LLM API
response = call_llm(history)
return response
def post(self, shared, prep_res, exec_res):
shared["history"].append(
{"role": "assistant", "content": exec_res}
)
shared["last_reply"] = exec_res
class SendReply(Node):
def prep(self, shared):
return shared["last_reply"]
def exec(self, reply):
print(f"AI: {reply}")
return reply
def post(self, shared, prep_res, exec_res):
return "continue"
# 构建 Flow
get_input = GetInput()
call_llm = CallLLM()
send_reply = SendReply()
get_input >> call_llm >> send_reply
send_reply - "continue" >> get_input
flow = Flow(start=get_input)
flow.run({})学习要点
- 循环模式:
send_reply - "continue" >> get_input实现多轮对话 - shared 通信:对话历史存在
shared["history"]中 - 退出条件:
get_input的post()返回"end"时无后继节点,Flow 结束
延伸思考:长期记忆
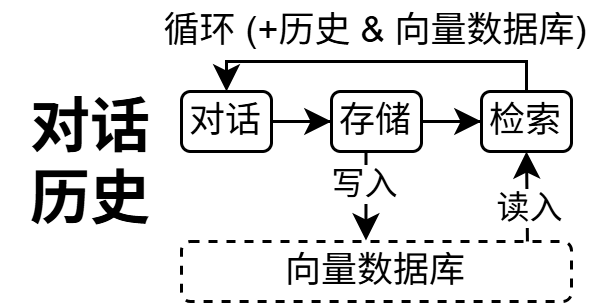
对话历史 + 向量数据库:实现长期记忆
上面的聊天机器人将对话历史保存在内存列表中,对话结束即丢失。如果你希望机器人具备长期记忆,可以将对话历史写入向量数据库,每次对话时先检索相关的历史片段作为上下文。这本质上是将 RAG 的检索能力融入对话循环 —— 你可以在学完 §3 RAG 后尝试实现。
2. 写作工作流(Writing Workflow)
难度:入门 | 模式:链式 | 关键词:多步骤生成、内容流水线
2.1 架构

写作工作流:按顺序执行各阶段
写作工作流的架构非常简洁 —— 三个节点依次处理,从大纲到草稿再到润色。
2.2 核心代码
每个节点对应写作流程的一个阶段,通过 shared 字典传递中间结果(大纲 → 草稿 → 成稿):
python
from pocketflow import Node, Flow
class OutlineNode(Node):
"""第一步:生成文章大纲"""
def prep(self, shared):
return shared["topic"] # 从 shared 读取主题
def exec(self, topic):
prompt = f"为主题'{topic}'列出文章大纲(3-5 个章节)"
return call_llm(prompt) # 调用 LLM 生成大纲
def post(self, shared, prep_res, exec_res):
shared["outline"] = exec_res # 写入 shared,供下一个节点读取
class WriteDraftNode(Node):
"""第二步:根据大纲撰写草稿"""
def prep(self, shared):
return shared["outline"] # 读取上一步的大纲
def exec(self, outline):
prompt = f"根据以下大纲撰写完整文章:\n{outline}"
return call_llm(prompt)
def post(self, shared, prep_res, exec_res):
shared["draft"] = exec_res # 写入草稿
class PolishNode(Node):
"""第三步:润色成稿"""
def prep(self, shared):
return shared["draft"] # 读取草稿
def exec(self, draft):
prompt = f"润色以下文章,使语言更流畅:\n{draft}"
return call_llm(prompt)
def post(self, shared, prep_res, exec_res):
shared["final_article"] = exec_res # 最终成品
# 实例化节点并用 >> 连接成链
outline = OutlineNode()
write_draft = WriteDraftNode()
polish = PolishNode()
outline >> write_draft >> polish # 链式连接
flow = Flow(start=outline)
flow.run({"topic": "PocketFlow 入门指南"})学习要点
- 最简链式模式:三个节点顺序执行,每个节点做一件事
- 任务分解原则:复杂任务拆分为小步骤,每步用一个 Node 处理
- 不要过度拆分:太细的拆分会导致节点间上下文不连贯
3. RAG 检索增强生成
难度:入门 | 模式:链式 + BatchNode | 关键词:向量检索、知识库
3.1 架构
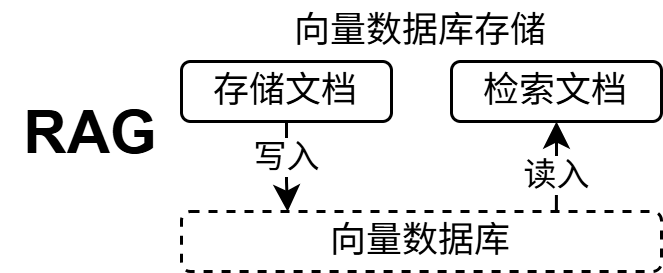
RAG 架构:离线存储文档 + 在线检索回答
3.2 核心思路
RAG 分两个阶段:
离线阶段(构建索引):
- Chunk:将文档切分成小片段
- Embed:使用 BatchNode 批量计算向量
- Index:存入向量数据库
在线阶段(回答问题):
- Retrieve:根据问题检索相关片段
- Generate:将检索到的 context 和 question 拼接,调用 LLM
3.3 关键代码
离线阶段将文档切分、向量化、建索引;在线阶段根据问题检索相关片段并生成答案。注意 EmbedBatch 使用 BatchNode 批量处理每个 chunk:
python
from pocketflow import Node, BatchNode, Flow
# ===== 离线阶段 =====
class ChunkNode(Node):
def prep(self, shared):
return shared["documents"]
def exec(self, docs):
chunks = []
for doc in docs:
chunks.extend(split_text(doc, chunk_size=500))
return chunks
def post(self, shared, prep_res, exec_res):
shared["chunks"] = exec_res
class EmbedBatch(BatchNode):
"""使用 BatchNode 批量处理每个 chunk"""
def prep(self, shared):
return shared["chunks"] # 返回列表
def exec(self, chunk):
# 每个 chunk 独立计算 embedding
return compute_embedding(chunk)
def post(self, shared, prep_res, exec_res):
shared["embeddings"] = exec_res # 所有结果的列表
class IndexNode(Node):
"""将 chunk 与 embedding 配对存入索引"""
def prep(self, shared):
return {
"chunks": shared["chunks"],
"embeddings": shared["embeddings"],
}
def exec(self, data):
# 构建索引(实际场景使用向量数据库)
index = list(zip(data["chunks"], data["embeddings"]))
return index
def post(self, shared, prep_res, exec_res):
shared["index"] = exec_res
# ===== 在线阶段 =====
class RetrieveNode(Node):
def prep(self, shared):
return shared["question"]
def exec(self, question):
q_embedding = compute_embedding(question)
top_k = vector_search(q_embedding, k=3)
return top_k
def post(self, shared, prep_res, exec_res):
shared["context"] = "\n".join(exec_res)
class GenerateNode(Node):
def prep(self, shared):
return {
"context": shared["context"],
"question": shared["question"]
}
def exec(self, data):
prompt = f"""基于以下信息回答问题:
{data['context']}
问题:{data['question']}"""
return call_llm(prompt)
def post(self, shared, prep_res, exec_res):
shared["answer"] = exec_res
print(f"Answer: {exec_res}")
# 构建离线 Flow
chunk = ChunkNode()
embed = EmbedBatch()
index = IndexNode()
chunk >> embed >> index
offline_flow = Flow(start=chunk)
# 构建在线 Flow
retrieve = RetrieveNode()
generate = GenerateNode()
retrieve >> generate
online_flow = Flow(start=retrieve)学习要点
- BatchNode:
EmbedBatch的prep()返回列表,exec()对每个 chunk 独立执行 - 两条 Flow:离线索引和在线查询是独立的 Flow,共享同一个向量数据库
- 三节点离线流水线:Chunk → Embed → Index 完整覆盖索引构建过程