Chapter1 基于Annoy向量召回的推荐系统实战
ipynb可执行代码请点击:基于Annoy向量召回的推荐系统实战.ipynb
本项目将使用 torch-rechub 框架训练一个 DSSM 双塔召回模型,并结合 Annoy 向量检索库实现推荐系统中的召回环节。通过本项目,你将理解向量数据库在推荐系统中的核心作用。
1. 推荐系统召回概述
推荐系统通常采用多阶段漏斗架构:
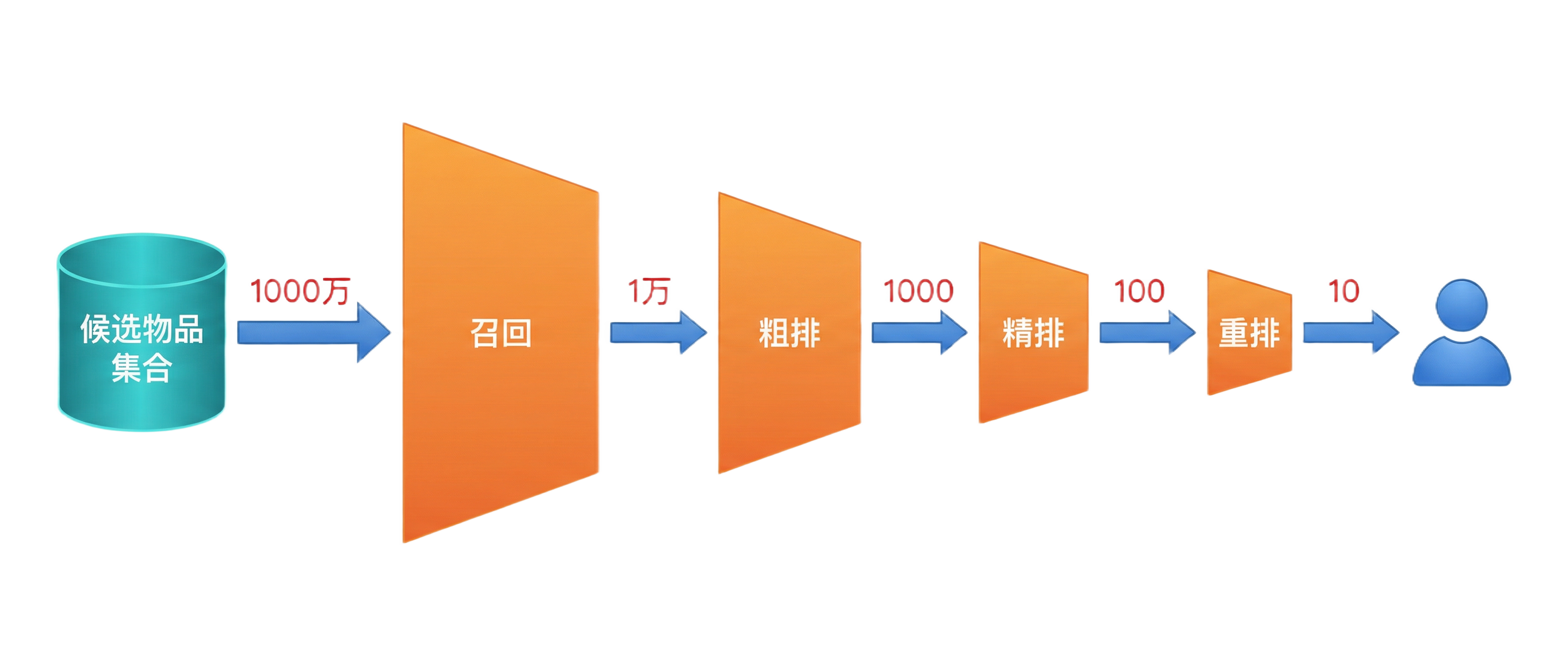
召回(Recall) 是推荐系统的第一个环节,目标是从海量物品中快速筛选出用户可能感兴趣的候选集。召回的核心要求是:速度快、覆盖广。
向量召回的核心思想:
- 将用户和物品分别编码为向量(Embedding)
- 在同一向量空间中,通过近似最近邻(ANN)搜索找到与用户最相似的物品
- 相比规则召回(协同过滤、热门推荐),向量召回能捕捉更深层的语义关系
2. 向量数据库在推荐召回中的角色
在推荐系统的向量召回中,向量数据库(或 ANN 检索库)扮演着关键角色:
- 离线阶段:训练双塔模型,生成所有物品的 Embedding,构建 ANN 索引
- 在线阶段:用户请求到来时,实时计算用户 Embedding,查询索引获取候选集
Annoy 是 Spotify 开源的轻量级 ANN 检索库,特别适合单机、中等规模的召回场景:
- 基于随机投影树(Random Projection Trees),查询速度快
- 支持内存映射(mmap),多进程可共享同一份索引文件
- API 简洁,易于集成
如果你还不熟悉 Annoy,建议先阅读本教程的 Annoy入门与环境搭建 和 Annoy核心API详解。
3. DSSM 双塔模型简介
DSSM(Deep Structured Semantic Model)是经典的双塔召回模型:
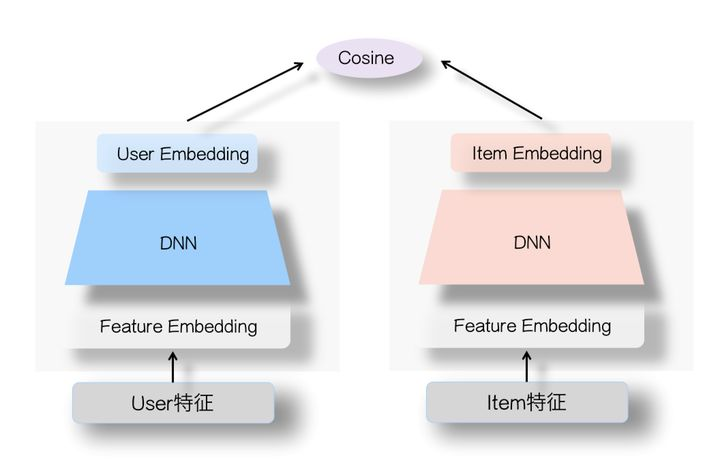
- 用户塔(User Tower):输入用户的稀疏特征(ID、性别、年龄等)和序列特征(观看历史),经过 Embedding + MLP 输出用户向量
- 物品塔(Item Tower):输入物品的稀疏特征(ID、类别),经过 Embedding + MLP 输出物品向量
- 训练时通过正负样本对比学习,使得用户与其喜欢的物品在向量空间中距离更近
- 推理时分别获取用户/物品向量,用 ANN 检索完成召回
4. 环境准备
pip install torch-rechub annoy torch pandas numpy scikit-learnWindows 用户注意:annoy 需要 C++ 编译环境,如果 pip 安装失败,可使用
conda install -c conda-forge python-annoy。
import torch
import pandas as pd
import numpy as np
import os
import collections
import time
from sklearn.preprocessing import LabelEncoder
pd.set_option('display.max_rows', 500)
pd.set_option('display.max_columns', 500)
pd.set_option('display.width', 1000)
torch.manual_seed(2022)5. 数据预处理
数据集:MovieLens-1M
MovieLens-1M 是电影推荐领域的经典数据集,包含约 100 万条用户对电影的评分记录。
| 字段 | 含义 | 示例 |
|---|---|---|
| user_id | 用户ID | 1 |
| movie_id | 电影ID | 1193 |
| rating | 评分 (1-5) | 5 |
| timestamp | 时间戳 | 978300760 |
| title | 电影名称 | One Flew Over the Cuckoo's Nest (1975) |
| genres | 电影类型 | Drama |
| gender | 用户性别 | F |
| age | 用户年龄段 | 1 |
| occupation | 用户职业 | 10 |
| zip | 用户邮编 | 48067 |
本教程使用采样后的
ml-1m_sample.csv(100条样本,包含 2 个用户、93 部电影)进行调试。跑通代码后,可下载全量数据集(约100万条)测试效果。
加载数据后,我们可以先观察数据的基本分布情况:
特征工程
在 DSSM 模型中,我们使用两类特征:
- 稀疏特征(SparseFeature):离散值(如用户ID、性别),经过 LabelEncoding 后输入 Embedding 层
- 序列特征(SequenceFeature):用户的历史行为序列(如观看历史),对序列中每个元素取 Embedding 后做平均池化
# 加载数据
file_path = 'ml-1m_sample.csv'
data = pd.read_csv(file_path)
# 提取电影的第一个类型作为类别特征
data["cate_id"] = data["genres"].apply(lambda x: x.split("|")[0])
# 定义特征列
user_col, item_col = "user_id", "movie_id"
sparse_features = ['user_id', 'movie_id', 'gender', 'age', 'occupation', 'zip', "cate_id"]
# LabelEncoding:将离散特征转换为连续整数
feature_max_idx = {}
for feature in sparse_features:
lbe = LabelEncoder()
data[feature] = lbe.fit_transform(data[feature]) + 1
feature_max_idx[feature] = data[feature].max() + 1
if feature == user_col:
user_map = {encode_id + 1: raw_id for encode_id, raw_id in enumerate(lbe.classes_)}
if feature == item_col:
item_map = {encode_id + 1: raw_id for encode_id, raw_id in enumerate(lbe.classes_)}
# 保存 ID 映射
save_dir = './saved/'
if not os.path.exists(save_dir):
os.makedirs(save_dir)
np.save(save_dir + "raw_id_maps.npy", (user_map, item_map))生成序列特征
from torch_rechub.utils.match import generate_seq_feature_match, gen_model_input
# 定义用户塔和物品塔的特征列
user_cols = ["user_id", "gender", "age", "occupation", "zip"]
item_cols = ['movie_id', "cate_id"]
user_profile = data[user_cols].drop_duplicates('user_id')
item_profile = data[item_cols].drop_duplicates('movie_id')
# 生成序列特征和训练/测试集
df_train, df_test = generate_seq_feature_match(
data, user_col, item_col,
time_col="timestamp",
item_attribute_cols=[],
sample_method=1,
mode=0, # point-wise
neg_ratio=3,
min_item=0
)
x_train = gen_model_input(df_train, user_profile, user_col, item_profile, item_col, seq_max_len=50)
y_train = x_train["label"]
x_test = gen_model_input(df_test, user_profile, user_col, item_profile, item_col, seq_max_len=50)定义特征类型
from torch_rechub.basic.features import SparseFeature, SequenceFeature
# 用户塔特征
user_features = [
SparseFeature(feature_name, vocab_size=feature_max_idx[feature_name], embed_dim=16)
for feature_name in user_cols
]
user_features += [
SequenceFeature("hist_movie_id",
vocab_size=feature_max_idx["movie_id"],
embed_dim=16,
pooling="mean",
shared_with="movie_id")
]
# 物品塔特征
item_features = [
SparseFeature(feature_name, vocab_size=feature_max_idx[feature_name], embed_dim=16)
for feature_name in item_cols
]6. DSSM 模型训练
from torch_rechub.models.matching import DSSM
from torch_rechub.trainers import MatchTrainer
from torch_rechub.utils.data import df_to_dict, MatchDataGenerator
all_item = df_to_dict(item_profile)
test_user = x_test
dg = MatchDataGenerator(x=x_train, y=y_train)
train_dl, test_dl, item_dl = dg.generate_dataloader(test_user, all_item, batch_size=256)
# 定义 DSSM 双塔模型
model = DSSM(
user_features,
item_features,
temperature=0.02,
user_params={"dims": [256, 128, 64], "activation": 'prelu'},
item_params={"dims": [256, 128, 64], "activation": 'prelu'}
)
# 定义训练器
trainer = MatchTrainer(
model,
mode=0,
in_batch_neg=True,
in_batch_neg_ratio=3,
optimizer_params={"lr": 1e-4, "weight_decay": 1e-6},
n_epoch=5,
device='cpu',
model_path=save_dir
)
trainer.fit(train_dl)7. 基于 Annoy 的向量召回
训练完成后,使用模型分别推理出用户 Embedding 和物品 Embedding,然后用 Annoy 构建物品向量索引,实现高效的近似最近邻召回。
<<<<<<< HEAD
# 推理 Embedding
user_embedding = trainer.inference_embedding(model=model, mode="user", data_loader=test_dl, model_path=save_dir)
item_embedding = trainer.inference_embedding(model=model, mode="item", data_loader=item_dl, model_path=save_dir)
# 使用 Annoy 构建索引并召回
from torch_rechub.utils.match import Annoy
=======
class FaissVectorStore:
def __init__(self, dimension: int):
"""初始化 Faiss 向量数据库"""
self.dimension = dimension
self.texts = []
self.embeddings = []
self.metadata = []
self.index = faiss.IndexFlatIP(dimension) # 使用内积 (Inner Product) 进行余弦相似度搜索
def add_vectors(self, embeddings: List[List[float]], texts: List[str], metadata: Optional[List[Dict[str, Any]]] = None):
"""向数据库添加向量及其对应的文本内容,可选添加元数据"""
embeddings_array = np.array(embeddings, dtype=np.float32)
# 归一化以支持余弦相似度
norms = np.linalg.norm(embeddings_array, axis=1, keepdims=True)
embeddings_array = embeddings_array / (norms + 1e-8) # 添加极小值防止除以零
self.index.add(embeddings_array)
self.texts.extend(texts)
self.embeddings.extend(embeddings)
# 添加元数据(如果未提供,则默认为空字典)
if metadata:
self.metadata.extend(metadata)
else:
self.metadata.extend([{} for _ in texts])
>>>>>>> 2d971f1 (fix code)
annoy = Annoy(n_trees=10)
annoy.fit(item_embedding)
topk = 10
user_map, item_map = np.load(save_dir + "raw_id_maps.npy", allow_pickle=True)
match_res = collections.defaultdict(dict)
for user_id, user_emb in zip(test_user[user_col], user_embedding):
items_idx, items_scores = annoy.query(v=user_emb, n=topk)
match_res[user_map[user_id]] = np.vectorize(item_map.get)(all_item[item_col][items_idx])下图左侧展示了用户和物品在 Embedding 空间中的 PCA 投影分布,右侧展示了召回结果中各物品与用户的余弦相似度:
8. 召回效果评估
| 指标 | 含义 |
|---|---|
| Recall@K | 在 Top-K 召回结果中,命中的正样本占所有正样本的比例 |
| Precision@K | 在 Top-K 召回结果中,命中的正样本占 K 的比例 |
| Hit@K | 至少命中一个正样本的用户比例 |
| NDCG@K | 归一化折损累积增益,考虑了命中位置的排序质量 |
| MRR@K | 平均倒数排名,关注第一个命中结果的位置 |
注意:使用 sample 数据集(仅 2 个用户、93 部电影)时,所有指标均为 0.0 是正常现象——样本量太小,模型无法充分学习用户偏好。使用全量数据集(100万条)训练后效果会显著提升。
from torch_rechub.basic.metric import topk_metrics
data_test = pd.DataFrame({user_col: test_user[user_col], item_col: test_user[item_col]})
data_test[user_col] = data_test[user_col].map(user_map)
data_test[item_col] = data_test[item_col].map(item_map)
user_pos_item = data_test.groupby(user_col).agg(list).reset_index()
ground_truth = dict(zip(user_pos_item[user_col], user_pos_item[item_col]))
out = topk_metrics(y_true=ground_truth, y_pred=match_res, topKs=[topk])9. 深入理解:Annoy 在推荐召回中的作用
torch_rechub.utils.match.Annoy 封装的核心逻辑等价于以下原生 annoy 代码:
from annoy import AnnoyIndex
dim = item_embedding.shape[1] # 64
index = AnnoyIndex(dim, 'angular') # angular 距离 ≈ cosine 距离
# 将所有物品向量加入索引
for i, emb in enumerate(item_embedding):
index.add_item(i, emb)
# 构建索引树
index.build(n_trees=10)
# 保存索引(支持内存映射,多进程共享)
index.save('movie_item.ann')
# 加载并查询
index2 = AnnoyIndex(dim, 'angular')
index2.load('movie_item.ann')
ids, distances = index2.get_nns_by_vector(user_emb, 10, include_distances=True)这正是我们在 Annoy核心API详解 中学到的核心 API。
10. 参数调优:n_trees 对召回效果的影响
Annoy 的 n_trees 参数控制索引中树的数量:
- 树越多 → 召回越精确,但构建时间和内存占用越大
- 树越少 → 速度越快,但可能遗漏一些近邻
for n_trees in [1, 5, 10, 50, 100]:
annoy_exp = Annoy(n_trees=n_trees)
annoy_exp.fit(item_embedding)
match_res_exp = collections.defaultdict(dict)
for user_id, user_emb in zip(test_user[user_col], user_embedding):
items_idx, items_scores = annoy_exp.query(v=user_emb, n=topk)
match_res_exp[user_map[user_id]] = np.vectorize(item_map.get)(all_item[item_col][items_idx])
out = topk_metrics(y_true=ground_truth, y_pred=match_res_exp, topKs=[topk])不同 n_trees 值下的构建耗时和查询耗时对比:
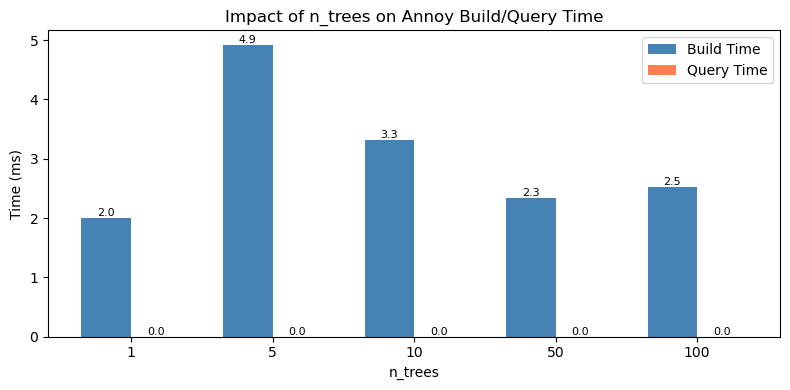
更多调优建议请参考 Annoy进阶技巧与最佳实践。
讨论:向量数据库如何赋能推荐系统
离线训练 + 在线召回的架构
- 离线阶段:训练 DSSM 模型,生成所有物品的 Embedding,构建 Annoy 索引
- 在线阶段:用户请求到来时,实时计算用户 Embedding,查询 Annoy 索引获取候选集
- Annoy 的内存映射特性使得多个服务进程可以共享同一份索引文件,非常适合 Web 服务部署
Annoy vs 其他向量检索方案
方案 适用场景 优势 局限 Annoy 单机、中等规模、只读 内存映射、多进程共享、API 简洁 不支持增量更新 FAISS 单机、大规模、需要 GPU 索引类型丰富、GPU 加速 部署复杂度较高 Milvus 分布式、超大规模 分布式扩展、实时增删改 需要部署服务 从召回到完整推荐系统
- 本项目实现的是推荐系统的"召回"环节
- 完整的推荐系统还需要:粗排(简单模型快速打分)→ 精排(复杂模型精细打分)→ 重排(业务规则调整)
- 向量数据库在召回层的价值:将 O(N) 的暴力搜索降低到 O(log N) 的近似搜索
动手练习
任务1:运行并理解代码
- 逐步执行上面的代码,观察每一步的输出
- 思考:用户 Embedding 和物品 Embedding 的维度为什么是 64?这个维度由什么决定?
任务2:使用全量数据集
- 下载 MovieLens-1M 全量数据集(约100万条记录)
- 替换
file_path为全量数据路径,重新训练模型 - 对比 sample 数据和全量数据的召回指标差异
任务3:调整 Annoy 参数
- 尝试不同的
n_trees值(1, 10, 50, 100),观察对召回精度和速度的影响 - 尝试不同的距离度量(
angular,euclidean,dot),对比效果 - 参考 Annoy进阶技巧与最佳实践 中的调优建议
任务4(进阶):保存和加载 Annoy 索引
- 将训练好的 Annoy 索引保存到文件
- 编写一个独立的"在线召回服务"脚本:加载索引文件,接收用户特征,返回推荐结果
- 思考:在生产环境中,如何实现索引的定期更新?
思考题:
- Annoy 不支持增量更新,在推荐系统中如何处理新物品的加入?
- 如果物品数量达到千万级,Annoy 还适用吗?应该选择什么方案?
- 双塔模型的 Embedding 维度对召回效果和检索速度有什么影响?