Chapter1 RAG with FAISS
什么是 RAG?
检索增强生成(Retrieval-Augmented Generation,RAG)= 检索 +增强+ 生成 整个过程就像“开卷考试”:
- 提问: 你向RAG系统提一个问题。
- 检索 (Retrieval): RAG系统不会直接把问题给大模型,而是先拿着你的问题,去你的私有数据库里搜索最相关的信息。
- 增强 (Augmented): 系统把你的原始问题和它从数据库里检索到的相关资料,一起“打包”成一个新的 Prompt。
- 生成 (Generation): 把这个包含了背景资料的新 Prompt 发给大模型,让它基于这些资料来回答你的问题。 用来解决大模型两大核心痛点:知识更新不及时和容易胡说八道(幻觉)。
RAG的基本组成
讲RAG的基本组成就不得不拿出这张经典的图
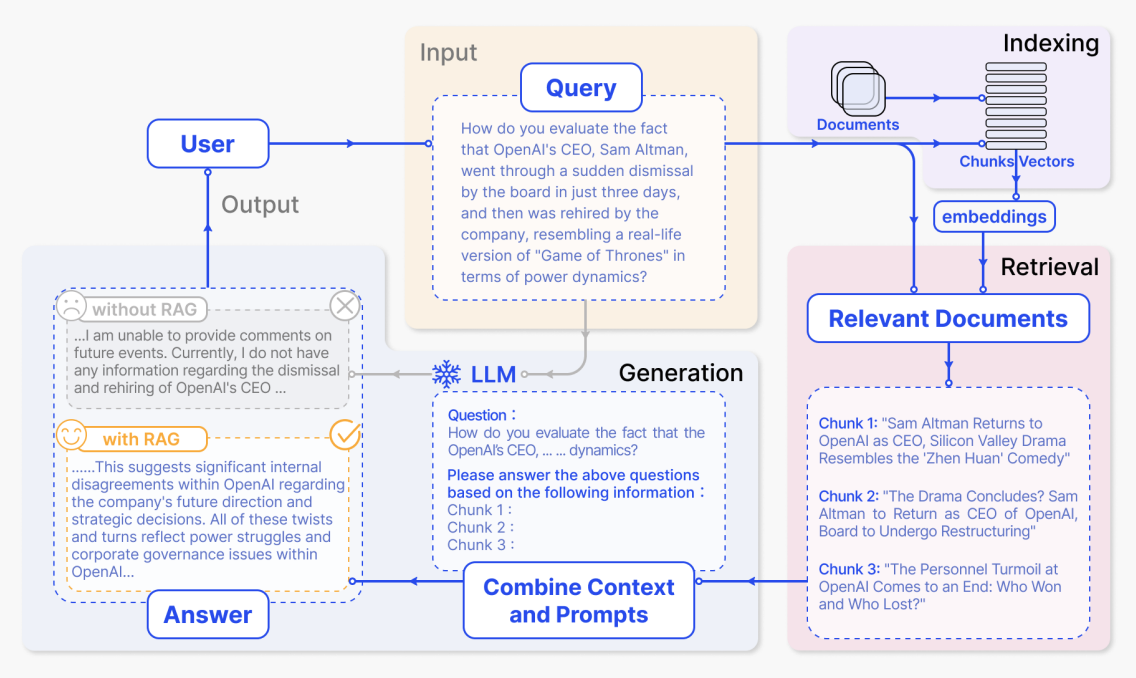
整个RAG流程分为四大模块:
- Input(输入) —— 用户提出问题
- Indexing(索引构建) —— 对文档进行预处理和向量化
- Retrieval(检索) —— 根据问题从知识库中找到相关文档片段
- Generation(生成) —— 将检索到的信息与问题结合,让 LLM 生成高质量答案
- Output(回答) —— LLM进行输出,回答用户的问题
参考目录结构
project1/
├── rag/ # 核心源代码
│ ├── Embeddings.py # 向量化实现
│ ├── faiss_db.py # 向量数据库操作
│ ├── utils.py # 文档切分与流程工具
│ ├── llm.py # 大模型客户端适配
│ └── prompt.py # 提示词模板
├── docs/ # 知识库 (.md 文件)
├── db/ # 自动生成的索引文件
├── main.py # 交互式入口
├── config.yaml # 全局配置文件
└── README.md # 项目文档环境搭建
基础环境:Python 3.10+
环境依赖:
pip install -r requirements.txt- 下载Embedding 模型:
#模型下载
from modelscope import snapshot_download
model_dir = snapshot_download('Qwen3-Embedding-0___6B')- config.yaml 配置
| 配置项 | 说明 | 示例值 |
|---|---|---|
llm.model | 使用的大模型名称 | deepseek-chat |
llm.api_key | 您的 API Key | sk-xxxx... |
embedding.model | 本地 Embedding 模型路径 | ./Qwen3-Embedding-0.6B |
embedding.device | 运行设备 | cpu 或 cuda |
rag.top_k | 检索返回的参考文档数量 | 5 |
storage.persist_dir | 向量数据库保存路径 | db/faiss_db |
data.path | 知识库文档存放路径 | docs |
七步构建RAG
第一步:准备数据
首先我们准备知识库”来源,我们这边使用开源项目 HowToCook(https://github.com/Anduin2017/HowToCook)的食谱来作为我们知识库的数据,该数据中主要以Markdown 文件为主,统一将数据存储到data文件下。
第二步:数据清洗和分块
由于我们使用开源数据集,格式清晰,不需要进行清洗。然后进行分块,对不同格式的文档使用不同方法进行分块,针对 Markdown 切分方法是按 Markdown 标题(# 到 ######)将文档拆分为标题与内容交替的片段;遍历这些片段时,将最近的标题作为当前内容块的前缀;随后在保留该前缀的前提下,按指定的 chunk_size(默认 500)和 chunk_overlap(默认 50)对内容进行滑动窗口式切分,确保每个文本块既包含上下文相关的标题信息,又满足长度限制。
def read_documents(directory: str) -> List[str]:
"""读取目录下所有 .md 文件的内容"""
documents = []
for file_path in glob(os.path.join(directory, "**", "*.md"), recursive=True):
with open(file_path, "r", encoding="utf-8") as f:
documents.append(f.read())
return documents
def split_markdown(text: str, chunk_size: int = 500, chunk_overlap: int = 50) -> List[str]:
"""Markdown 切分:按标题分段,段内保留标题并按长度切分"""
# 使用正则按标题行拆分文档
parts = re.split(r'(^#{1,6}\s+.*)', text, flags=re.MULTILINE)
chunks, header = [], ""
for part in parts:
part = part.strip()
if not part: continue
if part.startswith('#'):
header = part
else:
prefix = f"{header}\n" if header else ""
available = max(50, chunk_size - len(prefix))
# 按长度切分内容并加上标题前缀
for i in range(0, len(part), available - chunk_overlap):
chunks.append(prefix + part[i:i + available])
return chunks第三步:导入嵌入模型
在实验中使用Hugging Face 的 transformers 库直接加载Qwen3-Embedding-0.6B模型
from transformers import AutoTokenizer, AutoModel
import torch
from typing import List
from tqdm import tqdm
class QwenEmbedding:
def __init__(self, model_path: str, device: str):
"""初始化 Qwen 嵌入模型"""
self.device = device
self.tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
self.model = AutoModel.from_pretrained(
model_path,
trust_remote_code=True,
torch_dtype=torch.float32 if device == "cpu" else torch.bfloat16
).to(self.device)
self.model.eval()
def get_embeddings(self, texts: List[str], batch_size: int = 4) -> List[List[float]]:
"""获取文本列表的嵌入向量,增加批处理防止内存溢出"""
all_embeddings = []
# 增加进度条显示
for i in tqdm(range(0, len(texts), batch_size), desc="生成向量"):
batch_texts = texts[i : i + batch_size]
# 对当前批次进行分词
inputs = self.tokenizer(
batch_texts,
padding=True,
truncation=True,
max_length=512,
return_tensors="pt"
).to(self.device)
with torch.no_grad():
outputs = self.model(**inputs)
# 使用最后一层的平均值作为嵌入
batch_embeddings = outputs.last_hidden_state.mean(dim=1)
all_embeddings.extend(batch_embeddings.cpu().numpy().tolist())
# 及时释放显存/内存
if self.device == "cuda":
torch.cuda.empty_cache()
return all_embeddings
def get_embedding(self, text: str) -> List[float]:
"""获取单个文本的嵌入向量"""
return self.get_embeddings([text])[0]第四步:向量数据库
Faiss 是 Facebook AI 开源的高效相似性搜索库,具有高性能、低延迟、支持大规模向量检索的优点。Faiss 无需复杂依赖,可轻松嵌入本地应用,并支持将索引持久化到磁盘,非常适合中小规模 RAG 系统的快速部署与迭代。
class FaissVectorStore:
def __init__(self, dimension: int):
"""初始化 Faiss 向量数据库"""
self.dimension = dimension
self.texts = []
self.embeddings = []
self.metadata = []
self.index = self.faiss.IndexFlatIP(dimension) # 使用内积 (Inner Product) 进行余弦相似度搜索
def add_vectors(self, embeddings: List[List[float]], texts: List[str], metadata: Optional[List[Dict[str, Any]]] = None):
"""向数据库添加向量及其对应的文本内容,可选添加元数据"""
embeddings_array = np.array(embeddings, dtype=np.float32)
# 归一化以支持余弦相似度
norms = np.linalg.norm(embeddings_array, axis=1, keepdims=True)
embeddings_array = embeddings_array / (norms + 1e-8) # 添加极小值防止除以零
self.index.add(embeddings_array)
self.texts.extend(texts)
self.embeddings.extend(embeddings)
# 添加元数据(如果未提供,则默认为空字典)
if metadata:
self.metadata.extend(metadata)
else:
self.metadata.extend([{} for _ in texts])第五步:向量检索
向量检索采用了基于余弦相似度的内积索引策略。使用Qwen模型生成文本的嵌入向量,并通过归一化处理使其适用于余弦相似度计算。 检索时,查询向量同样被归一化,并在Faiss的IndexFlatIP(内积索引)中进行相似度搜索。索引通过内积来近似表示向量之间的余弦相似度,从而高效地检索出与查询向量最相似的top-k个文档片段。
def initialize_rag(directory: str, config: Dict[str, Any]) -> Dict[str, Any]:
"""初始化 RAG 系统:加载模型、读取文档并构建索引"""
# 1. 加载嵌入模型
embedding_model = QwenEmbedding(
model_path=config["embedding"]["model"],
device=config["embedding"]["device"]
)
# 2. 读取和切分文档
docs = read_documents(directory)
all_chunks = []
for doc in docs:
# 仅处理 Markdown 切分
all_chunks.extend(split_markdown(doc))
# 检查是否有文档
if not all_chunks:
print(f"警告: 在目录 {directory} 中未找到任何 Markdown 文档(.md)")
# 创建一个空的向量数据库
test_emb = embedding_model.get_embedding("test")
dim = len(test_emb)
print(f"嵌入模型维度: {dim}")
db = FaissVectorStore(dimension=dim)
persist_path = config["storage"].get("persist_dir", os.path.join(os.getcwd(), "db", "faiss_db"))
os.makedirs(os.path.dirname(persist_path), exist_ok=True)
print(f"创建空的索引文件: {persist_path}")
db.save(persist_path)
else:
# 3. 初始化向量数据库并添加文档
# 获取嵌入模型的实际维度
test_emb = embedding_model.get_embedding("test")
dim = len(test_emb)
print(f"嵌入模型维度: {dim}")
db = FaissVectorStore(dimension=dim)
persist_path = config["storage"].get("persist_dir", os.path.join(os.getcwd(), "db", "faiss_db"))
# 检查是否存在已有的索引文件
if os.path.exists(f"{persist_path}.index") and os.path.exists(f"{persist_path}.pkl"):
print(f"检测到现有索引文件,正在直接加载: {persist_path}")
db.load(persist_path)
else:
print(f"未找到索引,正在为 {len(all_chunks)} 个文本块生成向量向量(模型较大,请耐心等待)...")
embeddings = embedding_model.get_embeddings(all_chunks)
db.add_vectors(embeddings, all_chunks)
# 确保目录存在
os.makedirs(os.path.dirname(persist_path), exist_ok=True)
print(f"保存索引到: {persist_path}")
db.save(persist_path)第六步:配置LLM
配置LLM,我们使用 OpenAI SDK和deepseek的API
from openai import OpenAI
def load_model(config: dict):
"""加载DeepSeek"""
model_name = config["llm"]["model"]
api_key = config["llm"]["api_key"]
base_url = "https://api.deepseek.com"
client = OpenAI(api_key=api_key, base_url=base_url)
return client, model_name
def stream_chat(client_info, prompt: str) -> str:
"""流式输出"""
client, model_name = client_info
response = client.chat.completions.create(
model=model_name,
messages=[{"role": "user", "content": prompt}],
stream=True
)
response_text = ""
for chunk in response:
if chunk.choices[0].delta.content:
content = chunk.choices[0].delta.content
response_text += content
print(content, end="", flush=True)
print("\n", end="")
return response_text第七步:运行你的RAG
python main.py