随着大型语言模型(LLM)的广泛应用,企业面临一个现实问题:如何让模型准确回答基于内部文档、实时数据或专业知识的问题?毕竟,模型的训练数据有限且存在时效性,无法覆盖企业特有的业务知识和不断更新的信息。
一个直观的解决思路是:既然模型的上下文窗口正不断扩大,从8K、128K到如今突破百万token,那何不直接将相关文档塞进提示词,让模型基于这些材料生成答案?
然而,能够处理长上下文与能在企业级场景中稳定、高效、可控地交付正确答案是截然不同的两件事。盲目依赖长上下文会带来成本飙升、注意力分散、知识更新滞后等一系列严峻挑战。
正是为了解决这些痛点,一种名为检索增强生成(RAG)的技术应运而生。RAG让大模型在生成答案前先精准检索外部知识,相比简单粗暴地扩展上下文长度,它以更低成本、更高准确性和更强可控性,满足企业级应用对事实准确与知识鲜活的严苛要求,成为构建可信AI应用的关键基石。
在本篇教程中,我们将系统介绍什么是RAG,追溯其诞生的背景与核心原理,并深入探讨其从基础到进阶的演化路径,以及未来的发展方向。
本节课你将学到
- RAG的核心价值:深入理解它如何解决长上下文在成本、注意力、知识更新上的核心难题
- RAG的工作原理:通过具体案例看它如何完成从检索到生成的闭环
- RAG的技术演进脉络:从基础的Naive RAG到Advanced RAG再到模块化的Modular RAG
- RAG的模型选型建议:掌握Embedding、Rerank和LLM三大关键模型的评估与选择策略
- RAG的企业级实践:学习从数据预处理到系统上线评估的全链路构建指南
- RAG的效果评估与调优:了解核心评测指标、主流框架与持续优化的方法
- RAG的前沿趋势:探索其与智能体、多模态等技术融合的未来方向
本节课你将收获
完成本教程后,你将建立起对 RAG 技术入门级的系统性理解,不仅知其然,更知其所以然。你将获得一个清晰的蓝图,知道如何评估、选型设计一个符合企业级要求的高效、可靠且可控的 RAG 系统,为开发真正的企业级 RAG 应用打下坚实基础。
为什么需要 RAG
检索增强生成(Retrieval-Augmented Generation,RAG)是当前生成式 AI 中非常重要的一种技术方式。它的基本思路是:在让大模型生成回答之前,先从外部知识库中检索出与问题相关的信息,再把这些检索结果连同用户的问题一起交给模型,让模型在参考真实资料的基础上作答。这个外部知识库可以是企业内部的制度与流程文档、产品知识库,也可以是行业数据库、法规标准库等。
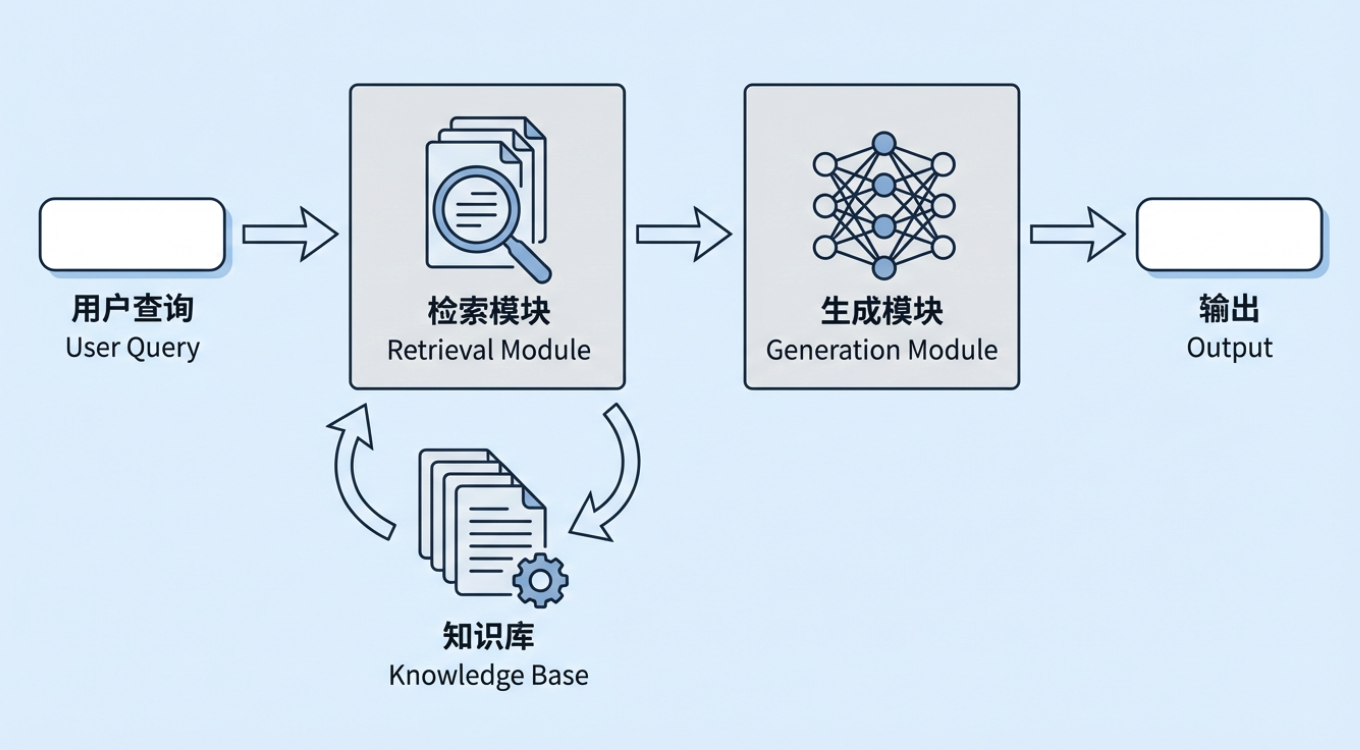
但此时我们会有一个疑问:既然大模型本身已经可以“直接回答问题”,为什么还需要额外增加“检索增强生成”这一层?尤其是现在大模型的上下文窗口越来越大,似乎只要把相关资料都提供给模型,让它先理解再回答,也能解决大部分需求。
真正的区别在于: “能给出一个回答” 和“在真实业务环境中,持续、稳定、可控地给出正确答案” ,是两件完全不同的事情。如果只是依赖模型参数中的“记忆”,或者仅仅把大量文档放进长上下文中,在企业实际应用中,依然会暴露出至少三类典型问题:
成本与效率的问题 : 即便大模型的上下文持续扩容,试图将所有文档 “一股脑通通塞进去” 的做法,在实际应用中依然不现实。核心矛盾集中在两点:
推理成本与上下文长度呈强正相关:上下文越长,推理成本几乎呈线性甚至超线性上升。以单次调用为例,8K Token 与 200K Token 对应的价格、响应延迟,完全处于不同量级,长上下文的成本门槛显著更高;
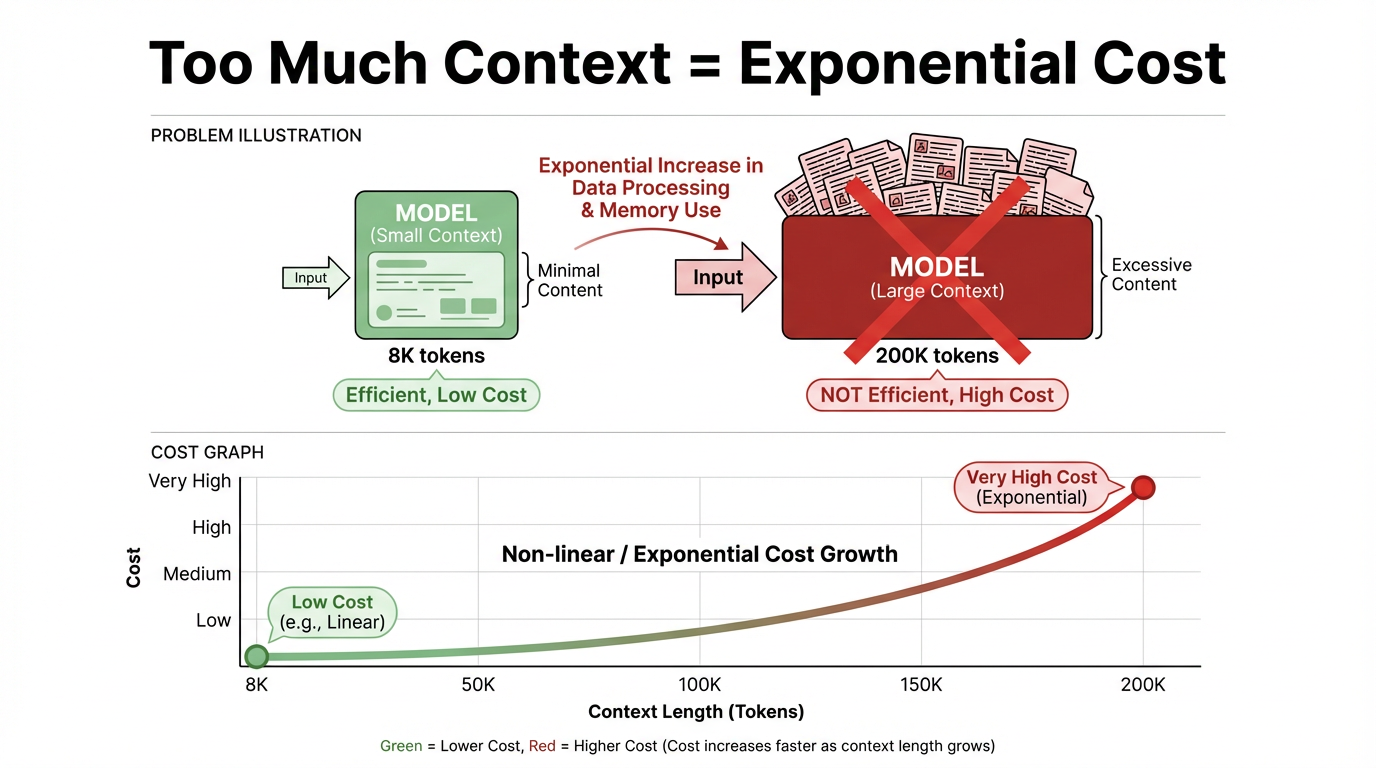
上下文(context)从意义上指模型在回答当前问题时所“参考”的背景信息与对话历史;从技术上则是指一次推理时输入给模型的 Token 序列(如 system/user 指令、历史消息、检索片段等)的总和。
“上下文窗口”是这批输入内容的 容量上限 :模型一次最多只能“看到”这么多 Token。在当前主流的大模型架构(例如 Transformer)中,这些 Token 会在模型的每一层里彼此做注意力计算、反复参与运算,因此一旦窗口变长、Token 变多,计算量和成本都会成倍甚至指数级增加。
计算资源存在大量浪费:绝大多数任务仅需极少量与当前问题高度相关的信息,将全量文档塞入上下文,会造成严重的计算资源闲置与浪费,进而降低系统吞吐量,拖慢响应速度,最终影响用户体验。
注意力与聚焦的问题 : 大模型虽能 “覆盖” 超长上下文,却无法对每一段信息都实现同等质量的利用。当上下文长度达到一定阈值时,模型会出现明显的 “注意力偏差”:
注意力衰减:模型对上下文前端、中端的信息关注度会逐渐减弱,更倾向于依赖刚读取的后端文本,导致早期关键信息被 “忽略”;
信息干扰:模型容易被上下文内无关、重复甚至冲突的信息 “带偏”,即便最终回答看似逻辑自洽,实际也可能与核心问题脱节,准确性难以保证。 可见,若缺乏检索环节进行信息过滤与相关性排序,上下文越长,反而越难确保回答聚焦于真正关键的证据,长上下文的优势会被信息干扰完全抵消。
知识更新与可控性的问题 : 若将所有知识完全依赖模型参数存储,或手动复制到提示词中调用,会存在两个难以规避的天然缺陷:
知识更新困难:一旦知识发生变更(如政策调整、产品迭代、价格更新等),要么需要重新训练或微调模型 —— 投入高、周期长;要么需要人工逐次维护提示词模板 —— 不仅成本高,还容易因人工操作失误导致信息偏差;
可追溯性差:模型回答时究竟依据了哪些具体信息,人们往往难以从 “黑盒化的参数” 或冗长的提示词中定位核心证据,这使得合规审计、风控解释等需要明确 “决策依据” 的工作,面临极大的操作困难。
在这些现实约束下,RAG 的优势就更加清晰。它的核心做法是:在模型生成答案之前,先通过检索精准定位相关、可靠的信息,让模型只基于必要的知识生成回答。知识可以独立存储在外部知识库中,便于更新与管理;同时,生成结果可以附带引用来源,提升回答的可解释性与可信度。即便未来模型的上下文窗口继续扩大,RAG 依旧能够以较低成本实现知识的高效管理与利用,从而支撑起一个过程可观测、行为可追踪的企业级知识应用体系。
从企业需求出发,相比只依赖模型自身参数的传统 LLM,RAG 主要解决了企业在落地应用中面临的以下现实问题:
- 时效性问题: 传统模型对 2024 年之后的新规、新产品、新流程往往不了解,而 RAG 可以直接读取最新的制度文件、业务数据库和知识库内容,无需频繁重新训练模型,就能让回答保持与最新业务同步。
- 专业性问题: 通用大模型在医疗、化工、金融等垂直领域,常常存在“懂得不够深、说得不够准”的情况。接入企业自有专业文档和行业标准之后,模型回答可以基于权威资料,显著更贴近真实业务实践。
- “幻觉”问题: 通过要求回答尽量基于检索到的文档片段,并能够给出对应的出处引用,可以在机制上减少无依据编造内容的概率,让“说得像真的”更接近“确实是真的”。
- 可解释与可审计问题: 纯参数模型给出结论时,往往难以回答“这是从哪条规定推导出来的”。RAG 让每条回答都可以回溯到具体的制度条款、业务文档或历史案例,既方便业务人员抽查和纠错,也为审计、风控、合规部门提供了必要的溯源依据。
- 算力成本与资源效率问题: 让大模型在参数中“背下”所有企业知识,往往意味着更大的模型、更高的推理成本。RAG 通过“按需检索”把大部分知识存放在外部向量库和文档库中,使企业可以在较小模型和有限算力条件下,依然获得覆盖面更广、细节更准确的回答能力
因此,对希望在真实业务场景中长期、稳定、可控地使用大模型的企业而言,RAG 不是一个可有可无的增强选项,而是构建高质量企业知识应用体系时几乎不可缺少的基础技术。
什么是 RAG
RAG(Retrieval-Augmented Generation,检索增强生成)的核心思路是让大模型在回答问题时,不仅依赖训练阶段学到的静态知识,更能够实时调用外部知识库中的最新、可靠信息。
在典型的 RAG 系统中,用户的问题不会被直接丢给大模型,而是先由检索模块从企业知识库中找到最相关的文档片段,再将这些内容与原始提问一起组合成完整的上下文,输入给大模型生成回答。这种"先检索、再生成"的方式,让模型能够基于真实参考资料进行推理,而不是仅凭参数中"记住"的知识进行推测。我们可以参考一个典型案例:
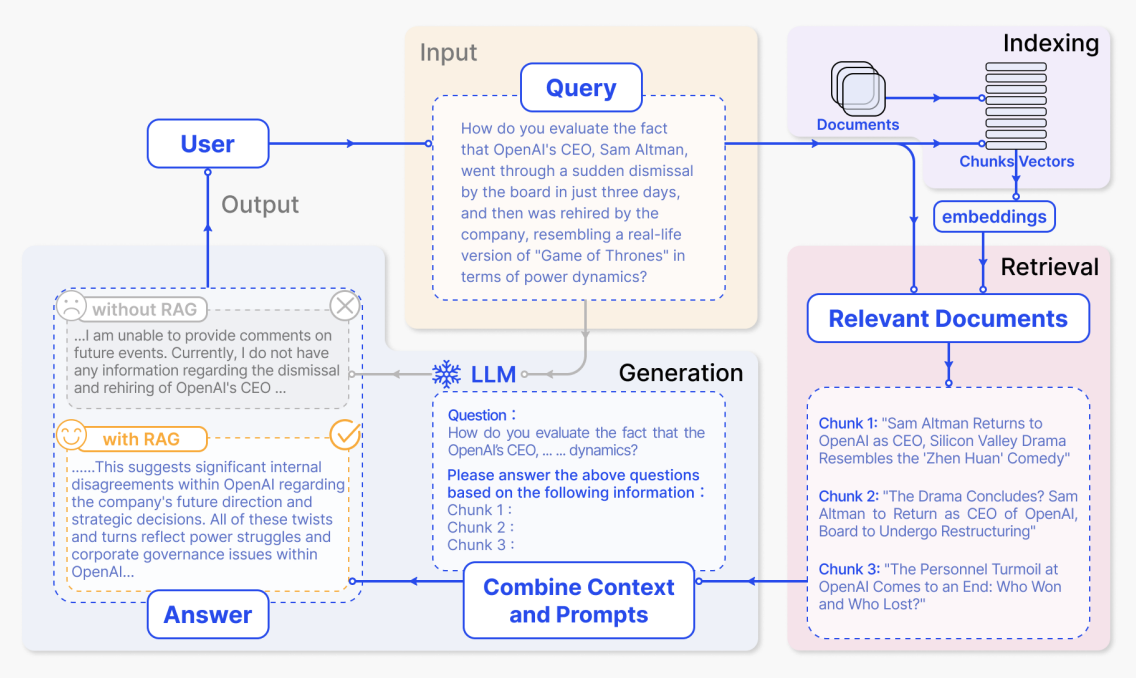
- 索引阶段
在索引阶段,系统会先处理企业内部文档、网页文章、报告等原始资料,将它们拆分成较小的语义片段(chunks),再用向量模型为每个片段生成向量表示并建立索引。这样,后续接收到用户问题时,就可以在向量空间中快速找到“语义最相近”的几段内容。
在图中,这一阶段对应右上角紫色区域 “Indexing”。从 “Documents” 出发,经由 “Chunks / Vectors” 到 “embeddings” 的那一部分,就是在说明文档被切块并转换为向量、写入索引的过程。具体过程如下:
- 文档被划分为若干个语义相对完整的 chunks,每个 chunk 可能对应一小段新闻、一段说明或一段分析。
- 每个 chunk 会通过 embedding 模型转换成高维向量,并存入向量索引中。
- 这个索引支持后续基于相似度的检索,为回答问题提前准备好“可被查阅的知识库”。
- 检索阶段 + 基于检索结果生成答案
当用户提出问题后,系统会先从索引中检索相关内容,再把问题和检索到的文本一并交给大模型生成答案。图中从上到下、从右到左的几个关键区域,正好对应这一整条流程。
(1)用户输入问题——图中黄色区域 Input – Query
“How do you evaluate the fact that OpenAI's CEO, Sam Altman, went through a sudden dismissal by the board in just three days, and then was rehired by the company, resembling a real-life version of 'Game of Thrones' in terms of power dynamics?”
“你如何评价这样一件事:OpenAI 的 CEO Sam Altman 被董事会突然解职,仅仅三天后又被公司重新聘回,在权力博弈上几乎像现实版《权力的游戏》?”
这一大段文字就是图中 “Query” 方框里的内容,对应“用户发起的自然语言提问”。系统会将这段话向量化,并据此去右上角的索引里查找相关文档片段。
(2)检索到的相关文档——图中右下角粉色区域 Relevant Documents
检索完成后,系统会得到若干个与问题最相关的文档块,它们在图中以三个 Chunk 的形式展示:
“Sam Altman Returns to OpenAI as CEO, Silicon Valley Drama Resembles the 'Zhen Huan' Comedy” “Sam Altman 回归担任 OpenAI CEO,这场硅谷大戏宛如一出《甄嬛传》式的宫斗喜剧。”
“The Drama Concludes? Sam Altman to Return as CEO of OpenAI, Board to Undergo Restructuring” “大戏要落幕了吗?Sam Altman 将重返 OpenAI CEO 职位,董事会则将进行重组。”
“The Personnel Turmoil at OpenAI Comes to an End: Who Won and Who Lost?” “OpenAI 的人事动荡告一段落:谁赢了,谁输了?”
(3)组合 Prompt 并生成回答——图中蓝色区域 LLM / Combine Context and Prompts
系统随后会将“用户原始问题 + 检索到的 chunks”组合成一个完整的 Prompt,发给大模型。图中中下部、靠中央的虚线框,就是这个 Prompt 的示例内容:
“Question: How do you evaluate the fact that the OpenAI's CEO, … … dynamics?
Please answer the above questions based on the following information : Chunk 1 : Chunk 2 : Chunk 3 :”
“问题: 你如何评价 OpenAI 的 CEO …… 这件事中的权力博弈?
请基于下面提供的信息来回答上述问题: Chunk 1: Chunk 2: Chunk 3:”
(4)有无 RAG 的回答对比——图中左下角灰色 / 黄色区域 Output – Answer
最后,大模型基于这些信息生成答案,结果展示在图的左下角 “Answer” 区域。这里同时给出了“未使用 RAG”和“使用 RAG”两种情况下的输出示例。不用 RAG 时,模型缺乏外部资料,只能给出非常模糊的回应,对应灰色框里那段话:
“… I am unable to provide comments on future events. Currently, I do not have any information regarding the dismissal and rehiring of OpenAI's CEO …”
“……我无法就未来事件发表评论。目前我没有关于 OpenAI CEO 被解雇和重新聘用的任何信息……”
使用 RAG 时,模型可以利用刚才检索到的新闻和分析,给出更有信息量的回答,对应黄色框中那段文本:
“… This suggests significant internal disagreements within OpenAI regarding the company's future direction and strategic decisions. All of these twists and turns reflect power struggles and corporate governance issues within OpenAI …”
“……这表明 OpenAI 内部在公司未来方向和战略决策上存在重大分歧。这一连串的反复与曲折,反映出 OpenAI 内部的权力斗争以及公司治理方面的问题……”
以上展示了一个典型 RAG 系统的完整流程,让我们从整体上理解了系统包含哪些核心环节、信息如何在各阶段流转。但是,检索时如何进行向量匹配?提示词如何组织才能让模型更好地利用检索到的内容?这些决定 RAG 实际效果的技术细节,目前仍是"黑盒"。接下来,我们将深入 RAG 的内部机制,从向量化原理、相似度计算、到提示词工程等关键环节,逐步拆解 RAG 究竟是如何工作的。
RAG 如何工作
我们可以通过一个“苹果”的知识库问答案例,逐步拆解它的关键环节。
3.1 文档向量化阶段
假设我们有一个简化的知识库,包含以下三个文档片段:
- 文档片段A:苹果公司于1976年4月1日由史蒂夫·乔布斯、史蒂夫·沃兹尼亚克和罗纳德·韦恩创立,总部位于加利福尼亚州库比蒂诺。
- 文档片段B:苹果是一种水果,富含维生素C和膳食纤维,有助于消化和免疫系统健康。
- 文档片段C:苹果公司在2007年推出了第一款iPhone,彻底改变了智能手机行业。
当我们使用嵌入模型(如 OpenAI 的 text-embedding-ada-002 或开源的 BGE 模型)处理文档时,每个文档片段会被转换为高维向量(通常含 768、1024 或 1536 个维度)。
“向量”本质是由多个数值组成的数组,每个维度的数值都对应文本某一维度的语义特征,比如 “猫” 的向量中,可能有维度对应 “哺乳动物”“家养宠物”“有毛” 等属性,最终通过整体数值组合精准捕捉文本的语义含义,让计算机能 “读懂” 文本间的关联。
简化示例(实际向量维度高得多,这里仅示意):
- 文档A向量(关于苹果公司创立):
[0.85, -0.23, 0.41, -0.56, 0.12, 0.78, ...] - 文档B向量(关于水果苹果):
[-0.12, 0.95, -0.34, 0.67, -0.89, 0.05, ...] - 文档C向量(关于iPhone发布):
[0.79, -0.18, 0.52, -0.61, 0.23, 0.81, ...]
相关向量需存入向量数据库(如 Pinecone、Weaviate、FAISS)用于之后的检索召回工作。
数据库是按特定结构存储、管理数据的系统,核心功能是实现数据的有序存储与高效存取,常见于通讯录、电商商品库等场景。
而向量数据库是数据库的细分类型,区别于传统数据库存储文本、表格等数据的逻辑,它专门用于存储 “向量”(高维数值数组),并优化了向量相似性检索能力,以适配 AI 场景下的高维数据管理需求。
3.2 用户查询检索、回复阶段
在知识库完成向量化存储后,RAG系统便能够支持用户的实时查询操作。当用户提出问题时,系统会执行一套连贯的流程:先将问题转化为向量,再通过相似度计算从知识库中召回最相关的信息片段,最终将这些片段作为生成答案的依据。我们通过三个具体查询来完整呈现这一过程。
查询一:“苹果公司是什么时候创立的?”
在查询向量化阶段,此问题被嵌入模型转换为一个语义向量,例如 [0.82, -0.21, 0.38, -0.58, 0.15, 0.76, ...]。该向量在数值模式上,与之前存储的“文档A向量”(关于公司创立)[0.85, -0.23, 0.41, -0.56, 0.12, 0.78, ...]高度相似。
接下来系统将进行相似度检索 (Top-K, K=2)操作,计算该查询向量与知识库中所有文档向量的余弦相似度(一种衡量向量方向接近程度的指标)。结果如下:
- 与文档A(公司创立)相似度:0.97(高度相关)
- 与文档C(iPhone发布)相似度:0.88(相关,同属公司主题)
- 与文档B(水果营养)相似度:0.12(几乎不相关)
Top-K 是向量检索场景中常用的筛选策略,核心含义是 “从所有匹配结果中,按相似度从高到低排序后,选取排名前 K 个的结果”;而 K=2 则是对该策略的具体数值定义,即明确要求系统仅保留相似度排名前 2 的文档向量,过滤掉其余相似度更低的结果,以确保后续仅基于最相关的 2 个文档片段生成答案。
此时根据相似度值过滤后的返回结果我们叫做召回结果。系统根据相似度分数从高到低,返回Top-2的文档片段作为证据:
- 文档A (相似度0.97):“苹果公司于1976年4月1日由史蒂夫·乔布斯、史蒂夫·沃兹尼亚克和罗纳德·韦恩创立,总部位于加利福尼亚州库比蒂诺。”
- 文档C (相似度0.88):“苹果公司在2007年推出了第一款iPhone,彻底改变了智能手机行业。”
在根据检索结果对话的大模型回复阶段,系统会构建如下所示的完整对话输入,将召回的结果放入参考信息中,和系统提示一起发送给LLM:
【系统指令 (System Prompt)】
你是一个专业的问答助手。请严格根据用户提供的“参考信息”来回答问题。
如果参考信息中包含问题答案,请直接基于该信息进行回答。
如果参考信息中不包含问题答案,请明确告知用户“根据现有资料无法回答该问题”,切勿自行编造信息。
请在回答中注明依据的信息点。
【参考信息 (Retrieved Context)】
苹果公司于1976年4月1日由史蒂夫·乔布斯、史蒂夫·沃兹尼亚克和罗纳德·韦恩创立,总部位于加利福尼亚州库比蒂诺。
苹果公司在2007年推出了第一款iPhone,彻底改变了智能手机行业。
【用户问题 (User Query)】
苹果公司是什么时候创立的?LLM接收到上述结构化输入后,会遵循系统指令,将“参考信息”视为回答问题的唯一可信来源。其最终回复将类似:根据提供的参考信息,苹果公司于 1976年4月1日 创立。【依据:信息1】”
查询二:“吃苹果有什么好处?”
在查询向量化阶段,此问题被嵌入模型转换为一个语义向量,例如 [-0.08, 0.92, -0.31, 0.71, -0.85, 0.08, ...]。该向量在数值模式上,与之前存储的“文档B向量”(关于水果营养)[-0.12, 0.95, -0.34, 0.67, -0.89, 0.05, ...]高度相似。
接下来系统将进行相似度检索 (Top-K, K=2) 操作,计算该查询向量与知识库中所有文档向量的余弦相似度。结果如下:
- 与文档B(水果营养)相似度:0.95(高度相关)
- 与文档C(iPhone发布)相似度:0.18(几乎不相关)
- 与文档A(公司创立)相似度:0.15(几乎不相关)
系统根据相似度分数从高到低,返回 Top‑2 的文档片段作为证据:
- 文档B (相似度0.95):“苹果是一种水果,富含维生素C和膳食纤维,有助于消化和免疫系统健康。”
- 文档C (相似度0.18):“苹果公司在2007年推出了第一款iPhone,彻底改变了智能手机行业。”(相关性极弱,实际可能被阈值过滤)
在根据检索结果对话的大模型回复阶段,系统会构建如下所示的完整对话输入,将召回的结果放入参考信息中,和系统提示一起发送给LLM:
【系统指令 (System Prompt)】
你是一个专业的问答助手。请严格根据用户提供的“参考信息”来回答问题。
如果参考信息中包含问题答案,请直接基于该信息进行回答。
如果参考信息中不包含问题答案,请明确告知用户“根据现有资料无法回答该问题”,切勿自行编造信息。
请在回答中注明依据的信息点。
【参考信息 (Retrieved Context)】
苹果是一种水果,富含维生素C和膳食纤维,有助于消化和免疫系统健康。
苹果公司在2007年推出了第一款iPhone,彻底改变了智能手机行业。
【用户问题 (User Query)】
吃苹果有什么好处?LLM接收到上述结构化输入后,其最终回复将类似:
根据提供的参考信息,苹果富含维生素C和膳食纤维,食用苹果有助于消化以及免疫系统健康。【依据:信息1】
查询三:“今天天气怎么样”
在查询向量化阶段,此问题被嵌入模型转换为一个与气象、天气相关的语义向量,例如 [0.10, -0.05, 0.30, -0.12, 0.21, 0.08, ...]。该向量在数值模式上,与知识库中所有关于“苹果(公司/水果)”的文档向量在语义空间中距离较远,因此不会出现显著相似性。
接下来系统将进行相似度检索 (Top-K, K=2) 操作,计算余弦相似度。由于问题主题与知识库内容无关,整体相似度得分都很低。结果如下:
- 与文档B(水果营养)相似度:0.18(极低)
- 与文档C(iPhone发布)相似度:0.10(几乎不相关)
- 与文档A(公司创立)相似度:0.08(几乎不相关)
Top-K 仍会返回相似度排名前 K 个结果,但在该场景下,这些结果并不能提供有效证据。实际系统常会结合“最低相似度阈值”直接返回空召回,即没有任何召回的结果,参考信息为 0,以减少无关信息干扰。
- 文档B (相似度0.18):“苹果是一种水果,富含维生素C和膳食纤维,有助于消化和免疫系统健康。”
- 文档C (相似度0.10):“苹果公司在2007年推出了第一款iPhone,彻底改变了智能手机行业。”
在根据检索结果对话的大模型回复阶段,系统会构建如下完整输入:
【系统指令 (System Prompt)】
你是一个专业的问答助手。请严格根据用户提供的“参考信息”来回答问题。
如果参考信息中包含问题答案,请直接基于该信息进行回答。
如果参考信息中不包含问题答案,请明确告知用户“根据现有资料无法回答该问题”,切勿自行编造信息。
请在回答中注明依据的信息点。
【参考信息 (Retrieved Context)】
苹果是一种水果,富含维生素C和膳食纤维,有助于消化和免疫系统健康。
苹果公司在2007年推出了第一款iPhone,彻底改变了智能手机行业。
【用户问题 (User Query)】
今天天气怎么样?LLM接收到上述结构化输入后,会先判断参考信息是否包含“天气/气象/实时数据”等直接信息;在确认参考信息与问题无关后,会遵循系统指令执行“无法回答”。其最终回复将类似:
根据现有资料无法回答“今天天气怎么样”,因为参考信息仅包含与苹果(水果营养、苹果公司产品)相关内容,不包含天气信息或实时气象数据。【依据:参考信息中无天气相关信息】
通过以上三个实例可以看出,在检索增强生成的大模型对话阶段中,系统指令设定了LLM的角色和回答规则,检索证据提供了具体、可信的作答素材,用户问题则明确了任务目标。这种结构化的输入方式,正是RAG技术能够有效引导并约束原本可能产生“幻觉”的大模型,使其输出稳定、可靠答案的关键所在。它确保了大模型的能力被精准地应用于理解与组织已有信息,而非无根据地创造信息。
RAG 技术演进史
RAG 技术并非诞生于大模型时代,在更早期的研究中就已有雏形。从发展脉络来看,RAG 的出现源于对传统 LLM 局限性的认识。早期的大语言模型主要依赖预训练数据,这些数据往往在模型训练完成后就固定下来,无法获取后续更新的信息。例如,GPT-3 等模型的知识截止点通常在训练数据收集的日期之后,无法获取新知识。此外,重新训练或微调 LLM 以适应特定领域需要大量资源和专业知识,成本高昂且难以快速迭代。
RAG 技术的起源可以追溯到 2017 年的 DrQA 框架,该框架首次尝试将检索机制与语言模型相结合。随后,2020 年引入的 Dense Passage Retrieval (DPR) 标志着 RAG 技术的重大突破,它利用预训练的神经网络模型进行语义检索,而非传统的 TF-IDF 或 BM25 等基于词频的方法。2021 年,RAG 被正式提出并系统化,成为解决 LLM 知识截止和幻觉问题的标准方法。
整体来看,RAG 的演进大致可以分为三个阶段:
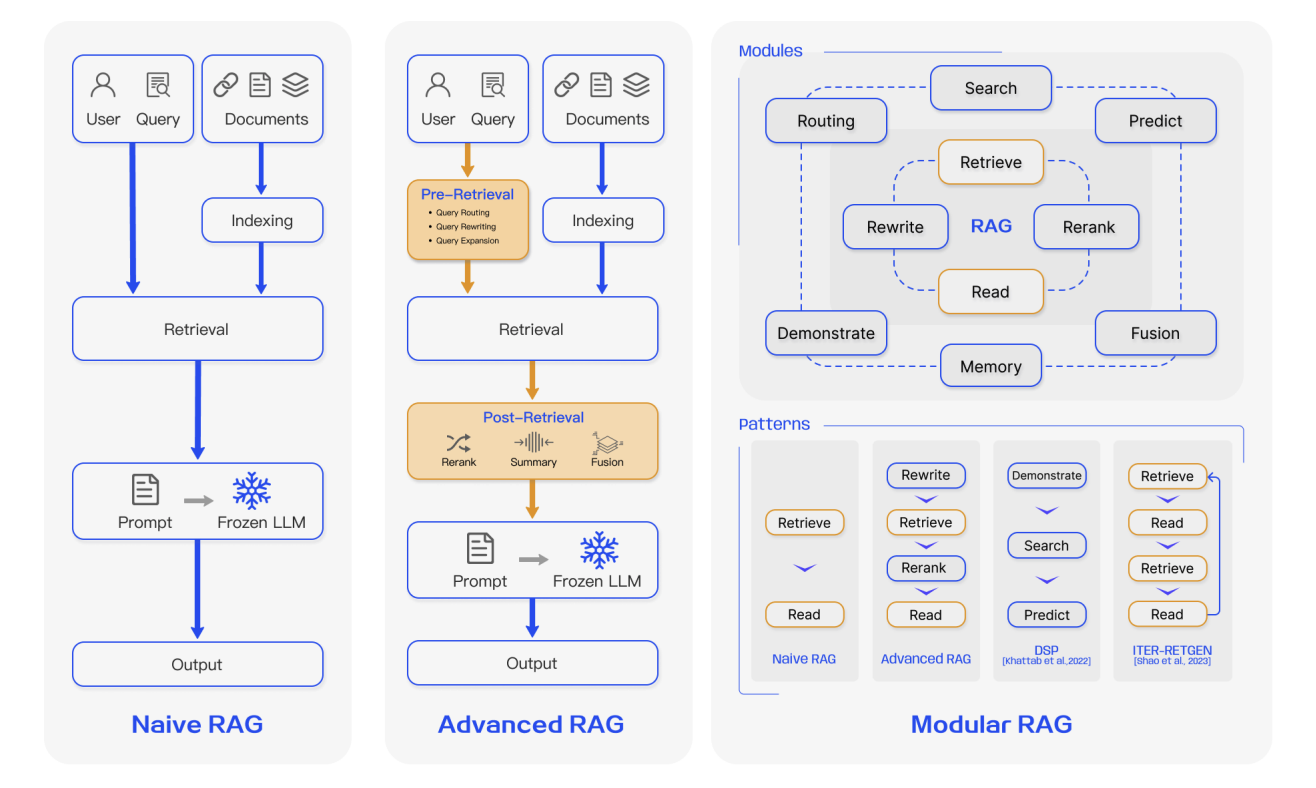
4.1 第一代 RAG:Naive RAG(基础检索增强)
Naive RAG可以理解为基础的 RAG 形态,它在工程上非常直接,典型流程可以概括为“三步走”:第一步是文档预处理与索引,将原始文档经过清洗之后,按固定长度切分成若干文本块(chunks),再用嵌入模型将每个文本块编码为向量,写入向量数据库;第二步是基于相似度的检索,将用户的自然语言问题编码成向量,在向量库中执行 Top‑K 相似度搜索,取回相似度最高的若干文本块;第三步则是简单拼接后的增强生成,把这些检索出来的文本块和原始问题直接拼在一起,构成一个长提示词交给 LLM,由模型在这个上下文基础上生成回答。
这一阶段的价值在于,以极低门槛验证了“先查再答”的思路确实有效:相比完全依赖模型内部记忆,已经能明显缓解知识截止和部分幻觉问题,在早期的原型系统和示例工程中发挥了重要作用。这使得 RAG 从一开始就具备了很强的实用性,成为大量 Demo、原型系统和入门教程的首选方案。
然而,这一代 RAG 的局限同样非常明显。首先,文本分块策略通常比较粗糙,大多采用固定长度切分,容易把一个完整的语义段落从中间“截断”,也可能把多个主题混杂在同一个块里,既影响检索准确性,也会给 LLM 的理解带来额外负担。其次,检索信号非常单一,往往只依赖向量相似度进行排序,没有利用关键词、时间戳、来源可信度、访问权限等更丰富的结构化线索。再次,检索结果几乎不经过筛选和治理,噪音、重复甚至彼此矛盾的片段都会原样塞进上下文,使得本来就紧张的上下文窗口被大量“低价值信息”占据。
可以说,第一代 RAG 解决了“要不要检索”的问题,但在“如何更好地检索”和“检回来的东西如何更合理地用起来”这两个问题上,还停留在相当原始的阶段。
4.2 第二代 RAG:Advanced RAG(检索与上下文的精细化优化)
随着 RAG 应用从 Demo 走向真实业务场景,系统对稳定性、可控性以及结果质量的要求迅速提高。此时出现的第二代 RAG,通常可以笼统地称作 Advanced RAG,它仍然遵循先检索、再生成的方法,但在检索前和检索后两个环节引入了系统化的精细化优化策略。换句话说,不再满足于“能不能检到东西”,而是要“把该存的东西存好,把该问的问题问清,把检回来的上下文治理好”。
在检索前,重点是把“存什么”和“怎么问”处理好:
- 在索引端,从固定长度切分演进到语义感知分块与分层索引,例如按章节、小节、段落或句子边界进行切分,辅以滑动窗口和多粒度索引结构。
- 为每个文档块附加丰富的元数据,例如来源、时间、作者、主题、文档类型等,为后续的过滤和排序提供更多维度。
- 在查询端,对用户原始问题进行重写、扩展和拆分,例如通过 Query Rewrite、多路查询(Multi-Query)、子问题分解(Sub-Query)、Step-back Prompting 等方式,将含糊或口语化的问题转换为更利于检索理解的表达。
- Query Rewrite(查询重写)
核心是将用户模糊、口语化或不规范的原始查询,转化为检索系统更易理解的标准化表述,补充关键信息、修正歧义。
- 用户原始问题为 “咋查明天北京的天气啊”,会去除 “咋”“啊” 等口语化词汇,补充 “实时”“全天” 等关键限定,重写为 “查询北京市明日全天实时天气”;
- 用户原始问题为 “推荐好看的电影”,若结合用户历史行为发现其常看悬疑片,会补充 “2024 年高分”“悬疑题材” 等信息,重写为 “推荐 2024 年高分悬疑题材电影”。
- Multi-Query(多路查询)
基于原始问题生成多个 “语义相关但角度不同” 的查询语句,避免单一查询遗漏潜在结果,覆盖用户未明确的潜在需求。
- 用户原始问题为 “如何给刚满月的宝宝拍嗝”,会生成聚焦 “姿势” 的查询:“新生儿拍嗝的正确姿势”;
- 生成聚焦 “防吐奶” 的查询:“满月宝宝拍嗝避免吐奶的方法”;
- 生成聚焦 “月龄适配” 的查询:“婴儿拍嗝的步骤(0-1 个月)”;
- 生成聚焦 “新手场景” 的查询:“新手爸妈给满月宝宝拍嗝技巧”。
- Sub-Query(子问题分解)
针对包含多个诉求的复合问题,拆分为独立、简单的子查询,让检索系统针对单一诉求精准匹配数据,避免信息混杂缺失。
- 用户原始复合问题为 “北京到上海的高铁,明天有哪些班次?票价多少?需要坐多久?”,会拆解出聚焦 “班次” 的子查询:“北京市至上海市 明日高铁班次表”;
- 拆解出聚焦 “票价” 的子查询:“北京到上海高铁 二等座 / 一等座票价”;
- 拆解出聚焦 “时长” 的子查询:“北京到上海高铁 行驶时长(最快 / 平均)”。
- Step-back Prompting(回溯提示)
先生成 “比原始问题更宏观的上位问题”,再基于上位逻辑回推检索方向,解决原始问题因聚焦细节导致的理解偏差。
- 用户原始问题为 “为什么 2024 年某国产新能源汽车品牌的销量突然下降?”,第一步生成宏观上位问题:“影响新能源汽车品牌短期销量波动的核心因素有哪些?”(如产品迭代、竞品动作、政策变化、市场需求等);
- 第二步基于上位问题逻辑,生成具体检索方向:“2024 年某国产新能源品牌 产品更新情况”“2024 年新能源汽车市场 竞品定价策略”“2024 年新能源汽车补贴政策调整”。
在检索后,重点是把“取回来的内容”治理好:
- 使用专门的 Rerank 模型或 LLM 对候选文档进行重新排序,确保最关键、最贴近问题的内容优先进入上下文。
Rerank 模型是信息检索流程中的关键组件,主要用于对 “召回阶段” 初步筛选出的候选结果进行二次排序 —— 它会借助更复杂的语义理解能力(常基于 Transformer 等深度学习架构),分析用户需求与候选结果的深层关联,修正初步排序中可能存在的语义偏差,最终让更贴合用户需求的结果排在更靠前的位置,提升用户获取有效信息的效率。
- 对检索结果进行筛选、去重与压缩,去掉明显无关或高度重复的片段,缓解长上下文中部信息被忽略的问题。
- 在必要时,结合轻量的模型微调,使 LLM 更倾向于依据检索证据作答,并在回答中附带引用或出处信息。
总体来看,第二代检索增强生成技术其关注点不再局限于 “是否需要检索”“能否检索到信息” 这两个基础问题,而是进一步聚焦于三个更大的挑战:“能否精准定位到真正关键的段落内容”“传递给大模型的上下文是否简洁有序、具备清晰结构且易于高效利用”“当面临信息噪音、内容冲突或多资料源查找需求时,系统整体性能是否依然稳健可靠”。
从大量实验验证与工程落地实践来看,Advanced RAG 在问答准确率、幻觉抑制能力、系统鲁棒性及结果可解释性等关键指标上,均显著优于 Naive RAG。也正因此,Advanced RAG 已逐步取代传统方案,成为当前工业界构建 RAG 系统的主流技术范式。
4.3 第三代 RAG:Modular RAG
在企业级的复杂应用场景中,需求往往跨越多个领域。在这种情况下,RAG系统若仅采用检索、重排、生成这样的单一线性处理方式,常常难以应对:
- 同一系统既要支持简单 FAQ,又要生成长篇报告、进行代码检索或调用数据库。
- 需要同时接入向量库、全文检索、关系数据库、知识图谱以及外部搜索引擎等多种数据源。
- 需要在多轮交互中保持对用户偏好、历史决策的记忆,并对输出结果实施合规审核和溯源。
在这样的背景下,RAG 的系统形态开始向模块化演进。Modular RAG 不再被看作一条固定的流水线,而是由一组可插拔、可替换、可组合的功能模块组成,通过编排逻辑按需组合执行。典型模块包括:
- 查询理解与路由模块 用于意图识别、问题重写、子任务拆解和路径选择,决定一条请求是主要依赖内部知识,还是外部检索,抑或需要调用特定工具或数据库。 例如,用户问「这条错误日志代表什么问题?」系统会将其路由到代码与日志知识库;而问「最近该行业的监管新规有哪些变化?」则更适合走互联网搜索或合规法规库。
- 多源检索与融合模块 同时连接向量数据库、全文检索系统、结构化数据库与知识图谱,对不同数据源进行查询,并将结果进行统一的融合与排序。 例如,在做「客户年度分析报告」时,一部分信息来自 CRM 数据库(如客户成交额),一部分来自文档库(如项目复盘),还可能需要从知识图谱中补充行业关系,最终由该模块将多源结果合并成一份有序的证据集。
- 记忆与个性化模块 维护长期用户画像、短期会话记忆和领域知识缓存,使系统能够在长期交互中不断积累和利用历史信息。 比如,系统记住某位用户偏好「先给结论再给细节」,以及他所在的业务线与常用术语,下次回答时会自动采用对应风格,并优先使用与该业务线相关的案例和数据。
- 任务适配与治理模块 面向不同任务加载对应的适配器,对输出格式、语气、风格进行约束,并结合事实核查、风险过滤和引用对齐等机制,对生成结果进行治理。 例如,同样是基于同一批检索结果,为产品经理生成的是结构化 PRD 模板,为法务人员则是正式合规审查意见;在此过程中,该模块会对关键事实进行二次核查,并强制要求给出引用来源。
总的来说,传统 RAG 往往是一轮检索配合一轮生成就结束,而 Modular RAG 则打破了这种单一流程。当系统在生成过程中发现信息不足时,可以主动触发新的检索轮次,甚至多次往返检索与生成,以完成更复杂的任务。
进一步地,模型还可以学习自我决策:对于把握较大的问题直接基于内部知识或短上下文作答;遇到不确定的情况时才发起检索或调用外部工具,从而在保证质量的前提下提高效率、节约资源。对于那些表达不清、信息缺失严重的查询,系统甚至可以先由大模型生成一个假设性的答案或中间文档,再以此作为“线索”去检索真实文档,不断逼近可靠信息源。
在这一阶段,RAG 已经不再只是给大模型补几段参考资料的简单组件,而逐步演变为企业级智能应用的中枢式知识编排层,负责在多数据源、多工具、多任务之间进行协调与调度。
从 Demo 到企业级的 RAG 系统
从企业工程实践的角度来看,RAG 系统的构建不能仅局限于检索增强生成技术本身,前面提到的内容更多是一个 Demo 级别的介绍。由于实际业务场景中的数据往往存在质量参差不齐、格式混乱等问题,因此需要在数据预处理、清洗及导入环节投入更多精力,同时在各个关键节点做好模型选型。
一个完整的企业级 RAG 系统通常可以划分为三个核心模块:版面分析与知识采集、知识库构建、以及基于 RAG 的知识问答服务。在整个技术链路中,涉及多个关键模型的选型决策,包括 Embedding 模型、Rerank 模型和 LLM 模型。只有在每个环节都做出合理的技术选型,才能确保系统达成最佳效果。
- 版面分析与本地知识文件读取
这一模块负责将各种格式的本地知识资产转换为可用于检索的文本。输入可能包括 PDF、TXT、HTML、Word、Excel、PPT 等文档,也包括 PNG、JPG 等图片类扫描文件,甚至是语音录音。
系统需要针对不同格式做解析,对文本文档做版面分析与结构抽取,区分标题、正文、表格、页眉页脚等元素,恢复合理的阅读顺序。对图片类文件进行 OCR 识别,对语音进行语音转写(ASR),最终统一转换为较为干净的知识文本,并尽量保留一些基础元信息,如文档名、章节、页码、时间等,为后续切分和索引打下基础。
- 知识库构建(切分、Embedding、索引)
在拿到清洗后的知识文本后,需要先进行合理的文本切分(Chunking),把长文档拆成若干语义相对完整、长度适中的文本块,通常按段落、标题结构或滑动窗口切分,同时保留每个块对应的文档来源和元数据。
随后,使用选定的 Embedding 模型,如 text-embedding-3-small、Sentence Transformers、BGE 等,对每个文本块计算向量表示,并基于这些向量构建向量索引,如使用 Faiss、Milvus、向量搜索服务等,就得到一个可按语义相似度进行快速查询的知识库。至此,我们完成了知识转换为可检索向量的核心步骤。
- 基于 RAG 的知识问答(召回、排序、拼接、生成)
在在线问答阶段,用户首先发出查询请求,系统会对查询进行 Embedding,得到查询向量,并在向量索引中检索出一批最相似的文本块(Top N),这是粗排阶段。在此基础上,可以选用 Rerank 模型,如 BGE Reranker 或 LLM 充当 Reranker,对查询与文档对进行精排打分,从中选出 Top K 个真正最相关的文档作为知识上下文。
接着,结合精心设计的系统提示词如"请严格基于以下资料回答"等等,将用户查询和检索出的文档片段进行拼接,把这个合并后的提示发给 LLM,由它在检索得到的证据基础上生成最终答案,并在需要时附上引用或出处。
5.1 模型选型
接下来我们关注各环节的模型选型,一个完整的 RAG 系统通常涉及三类核心模型:即 Embedding 模型、Rerank 模型和大语言模型。这三类模型各司其职,共同构成了从知识检索到答案生成的完整流程。其中,Embedding 模型负责将文本转化为可检索的语义向量,Rerank 模型对初步检索结果进行精细筛选与重排序,大语言模型则基于筛选后的知识上下文生成最终答案。
5.1.1 Embedding model
在 RAG 系统中,Embedding 模型的作用是将文本,如用户查询和知识库内容,转换为高维向量。语义相近的文本,其向量在空间中的位置也更接近,这使得系统能够通过向量相似度快速定位相关知识。因此,选择合适的 Embedding 模型是构建高性能 RAG 系统的关键一步,直接决定了召回阶段的质量。
为了选出好的模型,我们在这里介绍一个系统化的评价基准:MTEB(大规模文本嵌入评测基准)
MTEB为各类Embedding模型提供了一个统一、客观的评估框架。它通过8大类任务、56个数据集,全面评测模型在检索、聚类、分类、重排序、文本匹配、语义相似度等多种场景下的表现。模型在MTEB上的整体得分,能够反映其向量表示能力的通用性和稳健性,可作为选型的重要数据参考。最新排名和详细结果可通过 HuggingFace MTEB Leaderboard 查看。
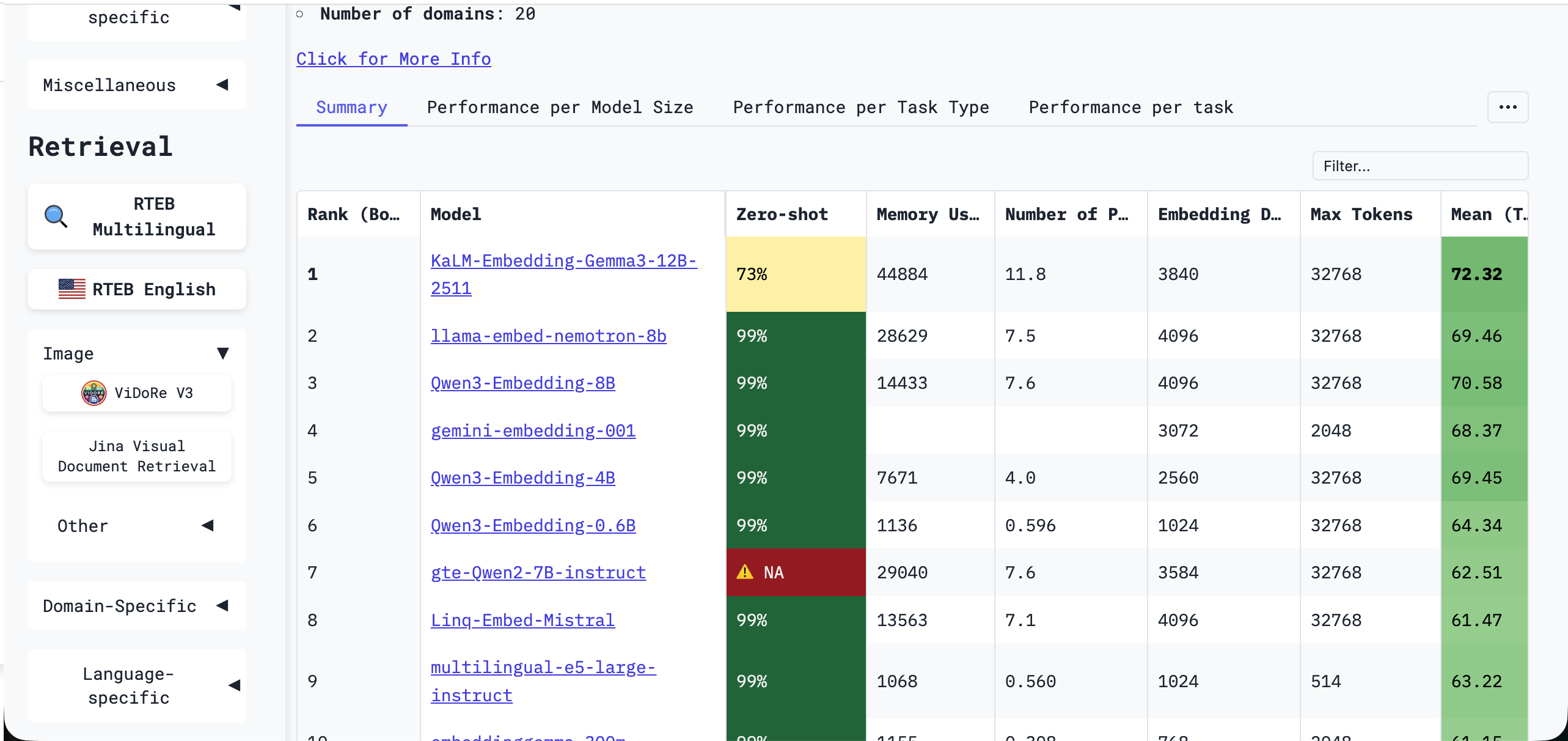
尽管榜单上存在大量模型,你可以根据实际需求进行选择,并不需要掌握所有的模型(一般来说,选择大模型厂商自带的 Embedding 模型,或者使用云服务平台部署对外使用的模型就大概率不会错,因为这个是大多人检验后的标准),你还可以在侧边栏中选择具体的类别或者语言进行筛选:
此外,在筛选 Embedding 模型时,需重点关注直接影响 RAG 性能的两个核心参数:维度和上下文长度。其中,维度是指模型输出向量的维度数(如 128 维、768 维),它本质上反映了描述语义信息时所使用的“特征数量”。维度越高,向量能刻画的语义细节越丰富、区分度越强,例如一个 768 维的向量可以从品种、口感、产地等数百个角度精细表征“苹果”,从而更适用于医疗、法律等需要精准检索的专业场景;维度越低,则计算与存储成本越小、检索速度越快,适合千万级文档等高并发、强实时性要求的通用场景。
另一个参数Context Length(上下文长度) ,指 Embedding 模型单次可处理的最大文本长度(以 token 为单位,1 英文 token 约 0.75 个单词、1 中文 token 约 1 个汉字),超出部分会被截断:它直接决定模型能否完整理解文本,若长度不足导致信息丢失,会大幅降低检索准确性。因此处理用户短句、问答对这类短文本时,选 512-1024token 的模型即可;处理论文、报告等长文本时,需选 2048token 及以上的模型以避免关键信息丢失。
以下是几种常见Embedding模型的横向对比,你需要在实际调用过程中综合成本、性能进行选择最佳模型,没有最好的模型,只有对比多个模型的效果选出最合适的模型。
| 模型名称 | 模型规模 | 核心优势 | 适用场景 |
|---|---|---|---|
| OpenAI text-embedding-3-large | 闭源API | MTEB测试集上长期领先,成熟稳定 | 追求极致性能且预算充足的云端API场景,适合对延迟不敏感的应用 |
| jina-embeddings-v2 | 支持长文本(最高8K上下文) | 异步编码设计,处理长文档检索时强有力 | 需要长上下文理解的文档分析、法律合规、学术文献检索 |
| multilingual-e5-large | Large规模 | 经典的多语言备选方案 | 跨语言RAG、国际化产品、多语种客服系统 |
| Qwen/Qwen2-Embedding-8B | 8B参数,支持最高4096维自定义 | 曾MTEB多语言榜第一,长文本、多语言与代码能力强 | 高精度中英文RAG、长文档分析、代码检索 |
| Qwen/Qwen2-Embedding-4B | 4B参数 | 性能与效率平衡 | 大规模生产级RAG系统,性价比高 |
| Qwen/Qwen2-Embedding-0.6B | 0.6B | 适用于边缘端 | 资源不够的场景,需要速度优先的场景 |
| BAAI/bge-m3 | 支持混合检索(密集+稀疏+多向量) | 在MIRACL等跨语言基准领先 | 需要混合检索策略的复杂多语言场景 |
| BAAI/bge-large-zh-v1.5 | Large规模 | 中文RAG的稳定基线,社区验证充分 | 纯中文且文档较短、追求稳定性的项目 |
| 智谱AI Embedding-3 | 闭源云端API | 支持自定义维度(256-2048维) | 注重中文且偏好云端API服务的应用 |
5.1.2 Rerank model
在 RAG 系统中,Rerank 模型的作用是对初步检索结果进行精细化重排序。它接收用户查询和候选文档作为输入,为每对(查询-文档)计算精确的相关性分数,分数越高表示文档与查询的匹配度越好。因此,在 Embedding 召回的基础上引入 Rerank 模型,是提升 RAG 系统检索精度的关键一步。
在选择 Embedding 模型时,我们可以用 MTEB 这样的 benchmark。而对于 Rerank 模型我们可以参考 Agentset 的 Reranker Leaderboard,该网站针对 RAG 场景下的重排能力做了系统测试。
| Model Name↑ | ELO | nDCG@10 | Latency (ms) | Price / 1M | License |
|---|---|---|---|---|---|
| BAAI/BGE Reranker v2 M3 | 1314 | 0.201 | 2383 | $0.02 | Apache 2.0 |
| Cohere Rerank 3.5 | 1452 | 0.2 | 392 | $0.05 | Proprietary |
| Cohere Rerank 4 Fast | 1506 | 0.216 | 447 | $0.05 | Proprietary |
| Cohere Rerank 4 Pro | 1627 | 0.219 | 614 | $0.05 | Proprietary |
| Contextual AI Rerank v2 Instruct | 1461 | 0.23 | 3333 | $0.05 | cc-by-nc-4.0 |
| Jina Reranker v2 Base Multilingual | 1306 | 0.193 | 746 | $0.05 | cc-by-nc-4.0 |
| Voyage AI Rerank 2.5 | 1547 | 0.235 | 613 | $0.05 | Proprietary |
| Voyage AI Rerank 2.5 Lite | 1528 | 0.226 | 616 | $0.02 | Proprietary |
| Zerank 1 | 1574 | 0.192 | 266 | $0.03 | cc-by-nc-4.0 |
| Zerank 1 Small | 1541 | 0.202 | 248 | $0.03 | Apache 2.0 |
| Zerank 2 | 1644 | 0.195 | 265 | $0.03 | cc-by-nc-4.0 |
在评估 Rerank 模型性能时,Agentset 基准测试采用以下流程:首先依据向量数据库 FAISS 从大规模文档库中检索出与查询最相关的前 50 个候选结果,随后由待评估的 Rerank 模型对这 50 个文档进行重新排序。评估过程同时关注排序质量和推理延迟两个关键维度。实际应用场景中,仅追求高精度而忽视响应速度将损害用户体验,而仅追求速度却牺牲排序质量则会导致结果实用性下降。
为进一步对比模型能力,Agentset 基准测试额外引入 ELO 评分机制:针对每次查询,会以 GPT-5 作为客观 “裁判”,对两个不同 Rerank 模型输出的排序结果展开成对比较,核心判定标准是哪个模型能将真正相关的文档排列得更合理、更靠前。经过海量查询的持续对比,获胜频率更高的模型将获得更高的 ELO 分数,从而直观体现模型综合性能差异。
在此基础上,基准测试还设计了两组互补性指标,用于对模型进行多维度综合评估:
- nDCG@5/10:聚焦排序精准度,重点衡量相关文档是否被合理置于结果前列,直接反映 “排得准” 的能力;
- Recall@5/10:侧重结果覆盖面,核心评估系统能否识别出所有与查询相关的文档,对应 “找得全” 的能力。
这两组指标相辅相成,共同构建起对 Rerank 模型的完整评估体系,确保评估结果更具全面性与参考价值。
但在实际使用中,我们不一定需要仅是参考 LeaderBoard 进行模型选型,除去刷榜的因素,主要还是因为工业上的好用和分数高不一定是一回事,我们可以根据各个云服务厂商推荐的 Rerank 模型进行选择(比如大模型厂商的默认 Rerank API,或可以尝试 Qwen 对应的 Rerank 模型,在当前 2025 年的情况下作为多参数支持的 Rerank 模型效果尚可。)
5.1.3 LLM
经过Embedding模型的语义检索和Rerank模型的精准筛选后,相关文档片段会与用户的原始问题一同被整合进prompt,最终由LLM完成阅读理解、信息整合与自然语言生成,向用户输出连贯、准确且符合上下文的答案。
在实现层面,RAG 中的 LLM 使用方式主要分为两类:
- 私有化部署的大模型。适用于注重数据隐私、成本可控或需要深度定制的场景。当前主流开源LLM如Qwen系列、Llama系列、GLM系列等在RAG任务中表现优异。以Qwen2.5为例,7B或14B参数版本在保持较小资源占用的同时,展现出良好的指令遵循能力和中文理解能力,特别适合企业级RAG应用的本地化部署。KIMI、Minimax、DeepSeek等模型也在不同语言和领域展现出各自优势,可根据具体业务需求灵活选型。
- 作为云端API服务的大模型。适合追求快速上线、弹性扩展和持续模型迭代的场景。主流提供商如OpenAI(GPT-4系列)、Anthropic(Claude系列)、Google(Gemini系列)以及国内的阿里(通义千问)、智谱AI(GLM系列)等都提供稳定的API服务。这些模型普遍具备强大的语言理解和生成能力,能够高质量完成RAG场景下的答案合成任务。 在选择云端模型时,需要关注几个关键点:回答质量是否准确流畅、价格是否合理、响应速度是否够快、上下文窗口是否足够大(能放下检索到的多个文档)。实际使用时,可以先拿几个候选模型做对比测试,看看哪个回答得更准确完整。如果对成本敏感,可以用"大小模型搭配"的方式:简单问题用便宜的小模型,复杂问题才调用贵的大模型,这样既省钱又保证效果。另外,大模型更新很快,建议定期测试新模型,及时替换表现更好的版本。
对于大语言模型在对话和问答场景下的综合能力评估,LMSYS Chatbot Arena (LMArena) 提供了业界认可的黄金评测基准。该平台采用创新的"盲测对战"机制——人类评估者在不知晓模型身份的情况下,对两个匿名模型针对同一提示的回复进行质量比较,通过大量这样的两两对比为各模型排名。
以下是竞技场排名的示例(截止至 2025 年 12 月 15 日)
| Rank | Model | Score | Votes | Organization | License |
|---|---|---|---|---|---|
| 1 | gemini-3-pro | 1492 | 15,871 | Proprietary | |
| 2 | grok-4.1-thinking | 1478 | 16,660 | xAI | Proprietary |
| 3 | claude-opus-4-5-20251101-thinking-32k | 1470 | 9,879 | Anthropic | Proprietary |
| 4 | claude-opus-4-5-20251101 | 1467 | 10,659 | Anthropic | Proprietary |
| 5 | grok-4.1 | 1465 | 16,501 | xAI | Proprietary |
| 6 | gpt-5.1-high | 1457 | 13,953 | OpenAI | Proprietary |
| 7 | gemini-2.5-pro | 1451 | 76,975 | Proprietary | |
| 8 | claude-sonnet-4-5-20250929-thinking-32k | 1450 | 28,019 | Anthropic | Proprietary |
| 9 | claude-opus-4-1-20250805-thinking-16k | 1448 | 43,836 | Anthropic | Proprietary |
| 10 | claude-sonnet-4-5-20250929 | 1445 | 23,185 | Anthropic | Proprietary |
LMArena的独特价值在于其评估方式更贴近真实用户体验,而非单纯依赖自动化指标。排行榜不仅展示整体排名,还细分为不同能力维度(如推理能力、创造能力、多语言支持等),帮助开发者根据实际应用场景选择最适合的模型。截至2025年,该平台已累计超过100万次人类评估,涵盖50+主流开源与闭源模型,成为LLM选型的重要参考。
访问LMArena官网可查看实时排行榜、详细能力分析和模型间的直接对比数据。但在实际选型中,建议将LMArena排名作为初步筛选依据,再结合企业特定数据进行A/B测试。特别是在专业领域(如医疗、法律、金融),通用榜单排名与实际表现可能存在较大差异,针对性测试尤为重要。
对于 LLM 选型的最佳实践是构建一个小型但代表性的测试集,包含20-30个典型业务问题,对候选模型进行端到端的RAG流程评估,而非仅评估LLM单点性能,比如使用推理模型还是非推理模型,使用什么参数的模型能平衡 RAG 效果和速度;这些都需要在实际的使用过程中测试得到最佳结论。
5.2 运行框架
在实际工程实践中,通常不需要从零开始构建整个 RAG 系统。目前业界已有多个成熟的开源框架可供选择,它们在架构设计、模块集成和开发效率等方面各有特色。企业可以根据自身的技术储备和业务场景,选择合适的框架快速搭建系统。常见的框架类型包括:
低代码 /可视化平台
- Dify:提供直观的可视化界面,支持快速搭建 RAG 应用,适合非技术团队或快速原型验证场景。内置多模型接入、工作流编排和 prompt 管理功能。
- Coze:字节跳动推出的 AI Bot 开发平台,提供零代码的可视化搭建能力。特色在于与豆包等字节系大模型深度集成,支持插件市场、定时任务和多渠道发布(飞书、微信等),适合快速构建面向 C 端用户的对话应用或企业内部智能助手。
- n8n:一个开源的、基于节点的工作流自动化平台。它通过可视化的方式连接各类应用、API和数据源。在RAG场景中,可以利用n8n编排复杂的业务逻辑,将数据预处理、向量数据库操作、大模型调用以及后续动作(如发送邮件、更新工单)串联成一个自动化流程。
- RAGFlow:专注于深度版面分析和知识抽取能力,对复杂文档(如多栏 PDF、表格密集型文档)的处理效果较好,适合文档结构复杂的企业知识库场景。
- FastGPT:中国国内开源方案,集成了知识库管理、对话流程编排和应用发布功能,中文文档完善,适合快速部署中文 RAG 应用。
代码框架/开发库
以下介绍的软件通常都有不同平台(前后端)语言的实现方式,你可以根据当前应用的语言选择下列对应软件的语言版本(例如 Python 或 Java 版)。
- LlamaIndex:专为 RAG 场景设计的 Python 框架,提供丰富的数据连接器(Connector)、索引结构和查询引擎,模块化程度高,适合需要深度定制检索策略或集成多种数据源的场景。
- LangChain:通用 LLM 应用开发框架,RAG 只是其中一个应用方向。优势在于生态丰富、组件齐全,支持复杂的 Agent 和工作流编排,但学习曲线相对陡峭,适合构建复杂的多模块 LLM 应用。
如果团队技术储备有限、追求快速上线,可优先考虑 Dify 、Coze 或 FastGPT 等低代码平台;如果需要深度定制检索框架、对接特殊数据源或优化性能细节,LlamaIndex 和 LangChain 提供了更大的灵活性。实际项目中,也可以采用"混合方案":用低代码平台快速验证可行性,再用代码框架实现生产级部署和性能优化。此外,这些框架大多支持主流 Embedding、Rerank 和 LLM 模型的快速接入,可以基于前文提到的模型选型标准灵活组合最后使用的模型型号。
5.3 效果评测
企业在 RAG 系统落地过程中,最大的挑战往往不是构建而是调优,对大型企业来说。生产级的大型 RAG 系统需要可监测可量化评估效果。RAG 涉及检索和生成两个非确定性环节,传统的软件测试方法不再适用,建立科学的评测体系(RAG Evaluation)至关重要,我们需要了解如何对 RAG 的效果进行系统化的评估。
5.3.1 入门示例:基于 LLM 的 RAG 效果评测
为帮助大家快速建立对 RAG 效果评测的直观理解,本节将以一个基于 LLM 的 RAG 效果自动化评测流程为例进行说明。该方案核心是 “LLM-as-a-judge”,即利用大模型本身作为裁判,来量化评估 RAG 系统的输出质量 https://huggingface.co/learn/cookbook/rag_evaluation。
具体而言,该流程通常包含三个关键步骤:
- 首先合成评测数据集,我们需要从知识库中采样文档,并指令 LLM 生成与之对应的、高质量的“问题-参考答案”对,再经过相关性、事实 groundedness 等过滤,形成基准测试集;
- 其次,运行 RAG 系统并收集答案,让待评估的系统处理测试集中的每个问题,得到其生成的答案;
- 最后,进行自动化判分,调用另一个作为“裁判”的 LLM,将系统生成的答案与参考答案进行对比,从准确性、完整性等维度给出量化评分。
可以用一个简单的例子展示其过程:
- 出题(合成评测集):我们有一份知识库,例如一段产品说明书:“本设备支持无线充电,电池容量为5000mAh。” 我们让一个大模型(如GPT-4)扮演“出题官”,根据这段文本自动生成一道测试题,例如:“这个设备的电池容量是多少?” 并记录标准答案:“5000mAh”。这就构成了一条评测数据。
- 答题(运行RAG系统):将这道题输入到待评测的 RAG 系统中。系统会从知识库检索相关信息,并生成一个答案。假设它回答:“该设备电池容量是5000mAh。”
- 批改(LLM-as-a-Judge):我们请另一个大模型(如Claude 3)扮演“批改老师”。将“问题”、“RAG生成的答案”和“标准答案”一起交给它,并指令:“请判断生成的答案是否正确,只需输出‘正确’或‘错误’。” “批改老师”经过对比,输出:“正确”。
通过自动化批量测试,我们能够得到RAG系统的准确率等具体指标。这就形成了一个“评测、优化、再评测”的实用循环:先看数据找出问题,再调整检索方法或优化模型,然后重新测试验证效果。系统就在这样一次次的迭代中,实现持续改进和性能提升。
你已经知道了评测在 RAG 中意味着什么,接下来我们将聚焦 RAG 评测的核心组成部分:常见的评测指标(如检索阶段的 Recall@K、生成阶段的 Faithfulness)、主流评测框架(如 RAGAS、ARES)与基准数据集(如 WikiEval、MedRAG)。鉴于这些内容覆盖面广、细节庞杂,此处暂先进行概览性介绍,帮助你建立整体认知框架。
若你需要深入掌握具体细节(如指标的数学计算逻辑、框架的实操部署步骤、不同基准数据集的适用场景等),建议参考以下两篇 RAG 评测领域的论文:
- https://arxiv.org/pdf/2504.14891(《Retrieval Augmented Generation Evaluation in the Era of Large Language Models: A Comprehensive Survey》):系统梳理了 LLM 时代 RAG 的内外部评测方法,涵盖组件级与系统级评估,还汇总了海量评测数据集与框架,并分析了当前研究趋势与挑战。
- https://arxiv.org/pdf/2405.07437(《Evaluation of Retrieval-Augmented Generation: A Survey》):提出了统一的 RAG 评测流程(Auepora),从 “评测目标、数据集、指标” 三维度拆解评测逻辑,同时对比了不同基准的优劣,为实践提供了清晰指引。
5.3.2 评测指标
RAG系统的评估本质上围绕两个核心问题:检索模块能否准确找到相关资料,生成模块能否基于这些资料给出高质量回答。因此,评测体系相应分为检索效果评估、生成质量评估两大模块,并辅以LLM裁判进行综合评分。下面我们逐一展开。
检索效果评估:召回准确性与排序质量
检索模块是RAG系统的第一道关口,其评估重点在于三个维度:找得准不准、找得全不全、排序好不好。
基础召回质量指标
首先是一组衡量召回基本质量的经典指标:Recall@K、Precision@K和F1。
- Recall@K 衡量在前K条检索结果中,相关文档被找回的比例。比如知识库中有5篇相关文档,前10条结果找回了3篇,则Recall@10为60%。这个指标告诉我们检索的"覆盖面"如何。
- Precision @K 衡量前K条结果中真正相关文档的占比。同样是前10条结果,如果其中有3篇相关、7篇不相关,则Precision@10为30%。这个指标反映检索的"准确度"。
- F1 则是Recall和Precision的调和平均,在两者间寻求平衡。
这组指标适合快速发现召回阶段的基础问题,比如向量化模型是否有效、检索策略是否合理、Query改写是否到位等。如果Recall很低,说明相关文档根本没被找到;如果Precision很低,说明检索噪声太大。
排序质量指标
找到相关文档只是第一步,更重要的是把最相关的文档排在前面。这就需要关注排序质量的指标:MRR、NDCG@K和MAP。
- MRR ( Mean Reciprocal Rank ) 计算第一个相关文档出现位置的倒数均值。如果第一个相关文档出现在第3位,该条查询的RR就是1/3。MRR适合那些只需要一个正确答案的场景,比如问答系统。
- NDCG@K(Normalized Discounted Cumulative Gain) 考虑了相关性分级和位置衰减两个因素。它不仅关注文档是否相关,还关注相关程度;同时,越相关的文档排在越前面,得分越高。这使得NDCG成为衡量排序质量最全面的指标之一。
- **MAP(Mean ** Average Precision ) 综合考虑所有相关文档的位置,对整体排序质量更为敏感。
在实际工程中,我们通常采用 Recall@K + MRR@K 的组合,既保证召回覆盖面又约束排序质量。举个例子,如果发现Recall@10达到80%但MRR@10只有0.3,说明相关文档虽然被找到了但都埋在后面,这时就需要优化重排序策略,比如引入交叉编码器或调整多路召回的权重分配。
必要时,还可以补充 Coverage 指标来监控知识库覆盖情况,发现系统性的召回盲区。比如某类专业术语相关的问题始终召回效果不佳,就要考虑是否需要针对性地优化该领域的文档切分或向量化方式。
生成质量评估:准确性与事实忠实度
检索为生成提供了"原材料",接下来要评估的是:基于这些材料,生成模块能否给出高质量的答案?生成质量评估的核心维度有两个:答案是否准确,是否忠于检索到的证据。
精确匹配与文本相似度
最直接的评估方式是 EM(Exact Match) ,要求生成答案与参考答案完全一致。这个指标适合答案唯一、形式固定的场景,比如"成立日期是什么时候?""总部在哪里?"这类事实性问答。但EM过于严格,同样正确的"2020年1月1日"和"2020-01-01"会被判为不匹配。
因此,更常用的是基于n-gram重叠的相似度指标: ROUGE 、 BLEU 、METEOR 。它们通过计算生成内容与参考答案的词汇重叠程度来打分。其中,ROUGE-L关注最长公共子序列,对答案的流畅性更敏感;BLEU源自机器翻译领域,注重精确匹配;METEOR则加入了同义词和词干的考量。这些指标的优势是计算简单、易于理解,但也有明显局限——它们只看表面词汇匹配,对语义理解不够深入。
为了弥补这一不足,我们可以引入 BertScore 或直接的 向量相似度 。它们利用预训练模型的向量表示来计算语义相似度,更能容忍表述差异。比如"这款产品很受欢迎"和"该设备广受好评"在词汇上几乎没有重叠,但向量相似度会很高。这对于需要改写、总结、解释的生成任务特别有效。
事实忠实度与幻觉检测
对于RAG系统而言,仅仅评估答案与参考标准的相似度还不够,更关键的问题是:生成的答案是否基于检索到的文档,有没有"无中生有"的幻觉?
这就需要专门的 Hallucination(幻觉率) 和 Faithfulness(忠实度) 指标。具体做法是让另一个LLM扮演"事实核查员",逐句检查生成答案,判断每句话是否能在检索文档中找到依据。比如,检索文档说"产品重量为500克",但生成答案写"该产品轻巧便携,仅重300克",这就是一个典型的幻觉。通过统计有依据的语句占比,我们可以量化系统的忠实度。
这个指标对监控事实性错误至关重要,特别是在医疗、法律、金融等对准确性要求极高的领域。实践中,许多企业会设置幻觉率阈值作为上线标准,比如要求准确度必须达到95%以上。
LLM裁判:多维度综合评分
前面介绍的指标各有侧重,但都存在一定局限性:自动化指标往往只看表面特征,难以把握语义深层含义和整体质量。这时,LLM-as-a-Judge 机制就显得尤为重要。
具体做法是:将问题、检索文档、系统回答、参考答案一并输入一个独立的大模型(通常选择能力较强的模型如GPT-4或Claude),让它按多个维度进行综合评分:
- 问题相关性 :答案是否真正回应了用户问题,有没有答非所问?
- 信息完整性 :该涵盖的要点是否都说到了,有没有遗漏关键信息?
- 事实忠实性 :答案是否出现了检索文档中不存在的内容,有没有幻觉?
- 整体正确性 :与参考答案相比,生成答案的质量如何?
LLM裁判的优势在于能进行更接近人类的整体性判断——它可以理解上下文、把握语义、识别逻辑,甚至能发现一些自动化指标捕捉不到的细微问题,比如语气不当、逻辑矛盾、表述含糊等。当然,裁判本身也需要精心设计prompt,并用人工标注样本进行校准,确保评分标准的一致性和可靠性。
构建实用的评测组合
面对如此多的评测指标,企业在落地时往往会感到困惑:该选哪些指标?如何组合使用?
一个务实的建议是 从精简组合开始,逐步完善 :
- 检索评估 :采用 Recall@K + MRR@K 的核心组合,快速把握召回覆盖和排序质量
- 生成评估 :根据任务特点,从 EM、ROUGE-L、BertScore 中选择一到两个作为基线
- 综合评估 :引入 LLM裁判,重点关注相关性、完整性、忠实性三个维度
在此基础上,采用"评测→发现问题→调整策略→再评测"的循环迭代。比如,发现召回率不错但MRR很低,就重点优化重排序;发现幻觉率偏高,就加强对检索文档的忠实度约束;发现某些类型的问题回答质量不好,就针对性地补充细分指标。
这种渐进式构建方式既能让团队快速起步,建立对系统效果的基本认知,又能随着理解的深入逐步完善评估体系,最终形成一套适合自己业务场景的评测方案。
5.3.3 评测框架
随着RAG技术的快速发展,学术界和工业界涌现出了大量优秀的评测框架,它们不仅封装了常用的评测指标,还提供了标准化的数据集、基准测试和端到端的评估流程。本节将系统梳理当前主流的RAG评测框架,帮助你快速选择适合自己场景的评测工具。
评测框架的分类体系
根据评测目标和使用场景,我们可以将RAG评测框架分为三大类:研究型框架、基准测试框架和工具型框架。
研究型框架主要服务于学术研究和前沿探索,特点是评测维度细致、方法创新性强。代表性的如FiD-Light和Diversity Reranker,它们专注于检索阶段的细粒度评估,前者关注召回的延迟性(Latency),后者强调结果的多样性(Diversity)。这类框架通常会深入到RAG系统的某个特定环节,提供精细化的诊断能力。
基准测试**框架**则提供了标准化的测试集和评测流程,用于横向比较不同RAG系统的性能。这类框架数量最多、影响最广。例如:
- RAGAS (2023.09)是最早的综合性RAG评测框架之一,采用LLM-as-a-Judge模式,同时评估检索和生成两个环节
- ARES (2023.11)引入了分类器辅助的评测方法,结合LLM判断和传统分类器来评估Context相关性和Answer相关性
- RGB (2023.12)专注于生成阶段的评估,提出了信息整合(Info Integration)、噪声鲁棒性(NoiseRobust)、负样本拒绝(NegRejection)、反事实鲁棒性(Counterfact)等细分维度
- MultiHop-RAG (2024.01)针对多跳推理场景,重点评估检索的相关性(Retrieval C)和回答的正确性(Response C),使用MAP、MRR、Hit@K等指标
- CRUD-RAG (2024.02)模拟真实的知识管理场景,评估系统在Create、Read、Update、Delete四种操作下的表现,引入了RAGQuerEval评分体系
进入2024年后,评测框架呈现出明显的专业化和细分化趋势。医疗领域有MedRAG,法律领域有LegalBench-RAG,金融领域有相关的domain-specific框架。这些领域框架不仅提供了专业数据集,还针对行业特点设计了定制化的评测指标,比如医疗场景特别关注准确性(Accuracy),法律场景强调文档级精确度(Doc-level Precision)和引用相关性(Citation Relevance)。
工具型框架则侧重于工程实践,提供了易用的评测工具和集成方案。TruEra RAG Triad、LangChain Benchmarks、RECALL等都属于这一类。它们通常与主流的RAG开发框架深度集成,支持快速接入现有系统,有些还提供了可视化的评测报告和监控面板。
上述我们介绍了多种不同的 RAG 评测框架,但在具体实战中该如何选择?不妨先选取 GitHub 星标数量较多的几款进行初步测试;而当企业面临丰富的框架选择、需要落地决策时,可从以下几方面着手。
- 快速上手需求:若需快速搭建基线评测,可选择 RAGAS、RAGEval 等综合性框架,它们能提供开箱即用的完整流程,若需深入诊断某一环节问题,则需选用针对性框架 :例如检索效果不佳时可用 MultiHop-RAG,幻觉问题突出时则可采用 CoURAGE 或 RAG Unfairness。
- 结合行业进行选择:若应用于医疗、法律、金融等专业领域,应优先选择适配该领域的框架,这类框架往往内置专业术语处理、合规性检查等关键能力,通用框架虽功能全面,但在专业场景中易出现 “水土不服” 的情况。
- 根据集成成本选择:像 LangChain Benchmarks、TruEra RAG Triad 等框架已与主流开发框架深度集成,能快速接入现有系统,而部分学术框架虽技术方法先进,却需额外投入工程适配工作;最后需关注持续维护情况,应优先选择社区活跃、文档完善且持续更新的框架,避开已停止维护的项目,具体可参考 GitHub 星标数量、更新频率、Issue 响应速度等指标。
除此之外,在社区中还公认推荐了一批工具,部分框架已在上述内容中提到:Ragas 提供了丰富指标且不绑定特定框架;Continuous Eval 以轻量和低成本为特点,支持构建具备数学保证的评估流水线;TruLens‑Eval 与 LangChain、Llama‑Index 等主流框架集成良好,并提供可视化分析;而 Llama‑Index 自身生态中也集成了评估与合成数据生成功能,便于对其构建的应用进行闭环测试。还有 Phoenix、DeepEval、LangSmith 和 OpenAI Evals 等工具也在持续迭代中,你可综合自身需求和对应工具的口碑进一步选用。
5.3.4 评测基准
评测基准的重要性在实践中常常被低估。许多团队在搭建RAG系统时,往往仅依靠少量人工编写的测试问题便匆忙开始评估,导致上线后的实际效果与测试阶段的表现差距显著。这一问题的根源在于,缺乏具有代表性和系统性的评测数据,难以真实反映复杂多变的业务场景。
一个能够有效支撑系统迭代的评测基准,通常具备三个核心特征。首先是代表性,测试数据需要全面覆盖真实业务中的各种场景,包括高频常见问题、复杂边界情况以及异常输入等;其次是标准化,问题和答案的格式、难度系数、评分标准需要统一规范,确保评测结果具有可比性和可重复性;最后是可演化性,基准应能随着系统能力提升和业务需求变化而持续更新,避免因固化的“应试”数据导致评测失真。
对于大多数企业而言,由于业务场景存在独特性,最终往往需要构建自己的评测数据集。
- 构建过程可以从业务日志中提取真实用户问题入手,并依据类型、频率和难度进行分层采样,以保证数据的代表性。对于简单问题可由领域专家直接标注,复杂问题则可先用高质量LLM生成候选答案,再由专家审核修改,这种"机器生成+人工校准"的方式能显著降低标注成本。
- 除答案本身,标注相关文档、答案类型、难度等级等元信息,为后续细分析提供支持。建立标注规范,进行多人交叉验证,计算标注一致性(如Kappa系数),确保数据质量。
- 定期从线上反馈中补充新的测试用例,尤其是系统回答不好的问题,让评测数据与系统能力同步演进。这种持续迭代的机制能让评测基准始终保持对业务场景的敏感度和有效性。
当然,如果团队资源有限或希望快速建立基线,参考业界成熟的公开评测基准也是一个可行的起点。截至2025年,已有诸多涵盖通用领域和垂直行业的基准可供选择(见图表)。
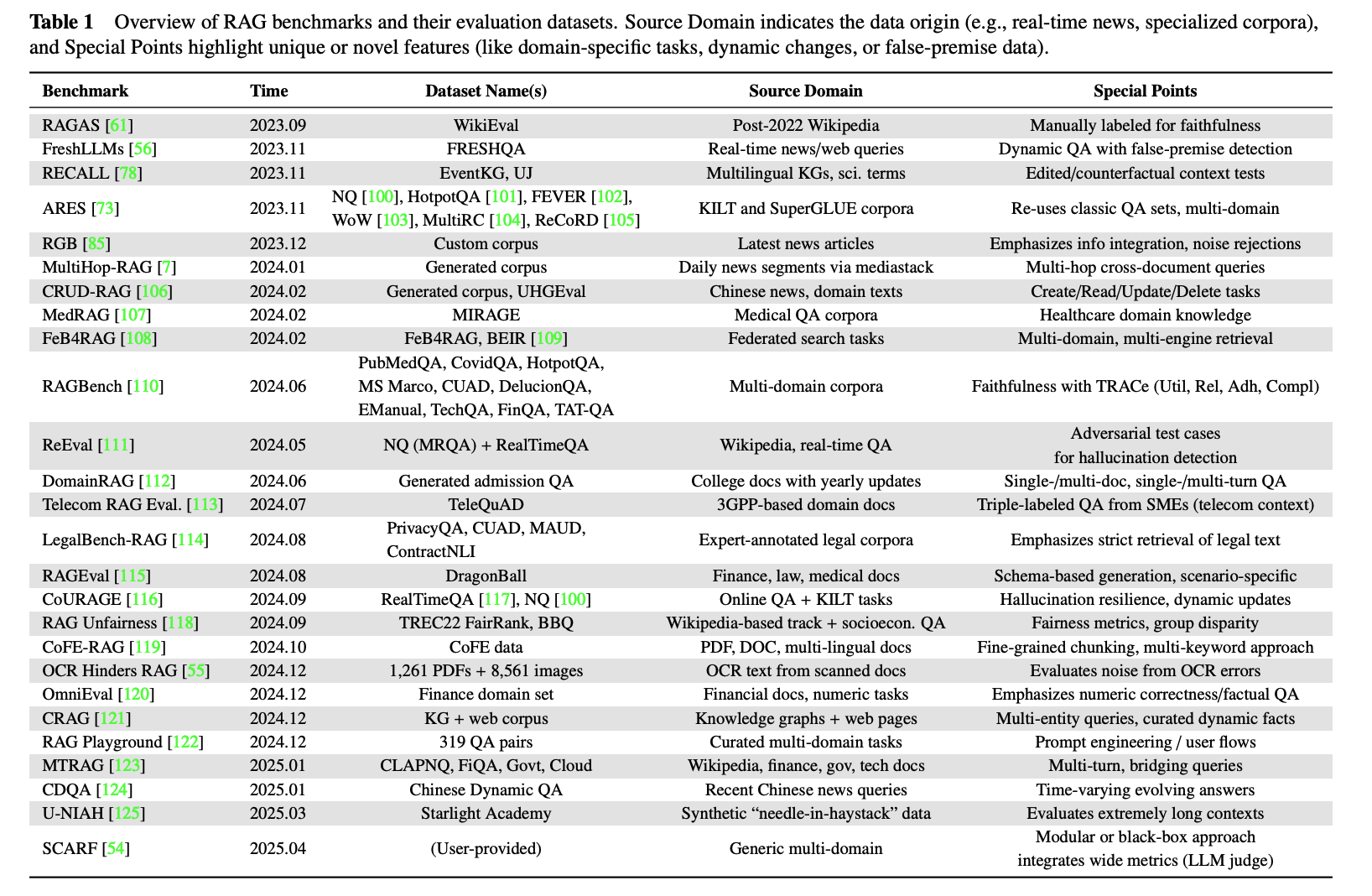
在选择时,应首先明确评测目的:是建立能力基线,还是为上线做最终验证?其次,需评估基准数据是否覆盖了所关心的场景、问题类型和难度。对于新闻、金融等时效性强的场景,必须考察基准是否包含实时数据测试;而对于历史知识处理,静态基准可能已足够。最后,还需权衡标注成本,是直接采用已完整标注的基准,还是使用原始数据自行标注。
将自建数据与公开基准结合使用,既能确保评测贴近业务实际,又能借助公共标准进行横向比对,是构建稳健评测体系的务实路径。
深度研究:从比赛与开源教程中学习(Optional)
前面介绍的RAG系统原理和基础实现,虽然能帮助你快速搭建起一个可用的原型,但距离真正解决生产环境中的复杂问题还有不小的距离。如果你想深入理解更落地、更有实战价值的RAG技术,参考各大比赛的获奖方案和优质开源教程是最高效的学习路径,这些方案往往集中了优秀团队在真实场景下反复尝试后的最佳实践。
但需要强调的是,本节列举的案例并非全部,而是挑选了几个有代表性的方案。当你在实践中遇到特定问题时,建议采用这样的学习策略:先根据问题类型(如"PDF解析"、"多模态检索"、"低延迟优化"等关键词)查找相关竞赛,再深入研究获奖队伍的技术报告或开源代码,往往能找到直接可用的解决思路。
6.1 语义缓存:优化高频查询场景
Hugging Face提供了一个基于Chroma向量数据库的语义缓存实现方案,该教程的地址为:
https://huggingface.co/learn/cookbook/semantic_cache_chroma_vector_database
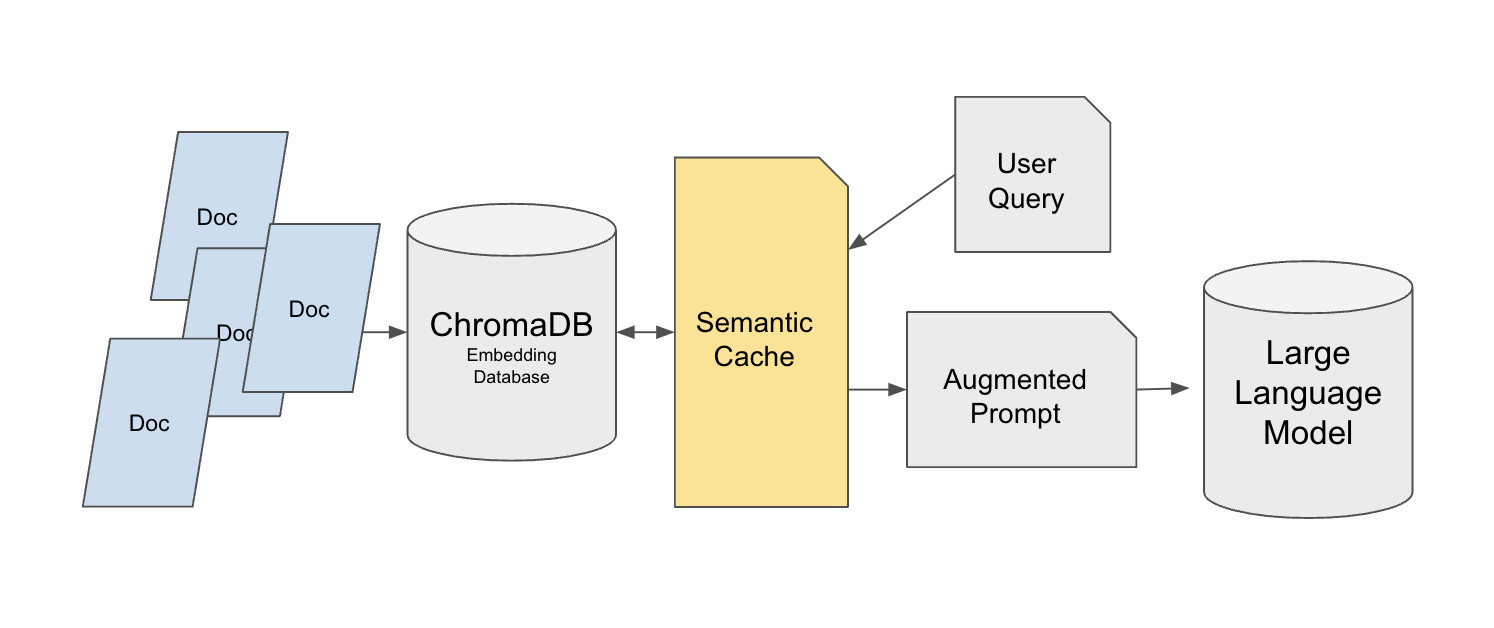
背景:大多数教程搭建的RAG系统只适合单用户测试,当系统部署到生产环境后,面对几十到几千次的重复查询(比如客服场景中用户反复询问"如何退款"),每次都要执行向量数据库检索和LLM调用,响应时间会明显增加,成本也会快速上升。通过引入语义缓存层,可以在保证答案质量的前提下,大幅减少对原始数据源的访问压力。
该方案采用了双层检索架构。基础层使用Chroma向量数据库存储原始知识库(以MedQuad医疗问答数据集为例),为每条数据添加唯一ID方便精确引用。缓存层则基于FAISS构建,选择FlatL2索引来处理小数据集和高维向量。语义缓存被放在用户查询与Chroma之间,而不是缓存LLM的最终回答——这个设计很重要,因为直接缓存回答会导致用户的个性化要求(如"用简单语言解释")失效。
缓存系统使用SentenceTransformer的all-mpnet-base-v2模型生成查询向量,通过欧氏距离(设定阈值为0.35)来判断查询是否相似。当缓存满了(max_response参数控制容量)时,采用先进先出策略删除最早的条目。为了支持跨会话使用,缓存数据会保存到JSON文件中。
在小规模测试中,首次查询"How do vaccines work?"从Chroma获取结果耗时0.057秒,而相似查询"Briefly explain me what is a Sydenham chorea."从缓存获取仅需0.016秒,检索时间减半。在大规模生产环境中,这个方案可以实现90%-95%的性能优化,有效降低了向量数据库的访问压力和API调用成本。
6.2 非结构化数据处理:统一多格式文档解析
Hugging Face的另一个教程展示了如何使用Unstructured库构建完整的非结构化数据处理流程,教程地址为:
https://huggingface.co/learn/cookbook/rag_with_unstructured_data

背景:企业场景中的知识往往分散在PDF、PowerPoint、EPUB、HTML等多种格式中,传统的数据预处理方法要么只能处理单一格式(比如只支持PDF),要么在格式转换过程中丢失关键信息(特别是表格、标题层级等结构化内容),导致RAG系统无法准确理解和检索这些信息。
该方案首先下载多格式测试文档作为示例,包括加拿大环境部农药手册PDF(包含大量表格数据)、佛罗里达大学柑橘IPM PowerPoint(包含图表和多层级标题)等真实文档。然后使用Unstructured库的Local Runner完成解析。配置分为三个部分:ProcessorConfig指定输出目录和并行进程数(2个进程),PartitionConfig可选择API分区模式(需要Unstructured密钥,OCR效果更好,特别适合扫描版PDF),SimpleLocalConfig定义文档输入路径。解析后的文档会转换为JSON格式,包含正文、标题、表格等元素类型。
系统使用chunk_by_title方法进行分块,设置最大字符数为512,并将200字符以下的连续片段合并以保持语义完整性。在转换为LangChain Document格式时,会过滤掉复杂的元数据字段以适配Chroma向量数据库。向量化阶段采用BAAI/bge-base-en-v1.5嵌入模型,结合4bit量化的Llama-3-8B-Instruct模型和LangChain的RetrievalQA链构建完整的RAG系统。
系统能够准确处理多格式文档。测试"Are aphids a pest?"等问题时,可以从解析后的文档中提取蚜虫危害、吸引蚂蚁等关键信息,生成符合需求的回答。这个方案成功实现了从非结构化数据到RAG可用数据的完整转化,特别适合需要处理多种文档格式的企业知识库场景。
6.3 企业级文档问答:高精准可追溯的RAG实现
Enterprise RAG Challenge的冠军方案展示了如何在严格的时间和精度要求下构建生产级RAG系统,相关技术文章地址为:
https://abdullin.com/ilya/how-to-build-best-rag/
https://hustyichi.github.io/2025/07/03/rag-complete/
背景:参赛者需要在2.5小时内完成100份真实企业年度报告PDF的解析,这些报告每份最多1000页,包含复杂的财务表格、多栏布局、图表等内容。解析完成后,系统需要回答100个精确的业务问题,这些问题要求明确的答案类型(比如Yes/No判断、公司名称、具体数值指标、高管职位名称等),并且必须给出答案来源的页码引用,以便业务人员验证。整个过程模拟的是投资分析师或财务审计人员的实际工作场景。
冠军团队选择IBM开源的Docling作为PDF解析工具,因为它在处理复杂表格(比如跨页表格、嵌套表格)和多列文本方面表现最好。团队对Docling代码进行了改进,使其生成包含元数据的JSON和Markdown+HTML格式,特别修复了表格结构的解析问题(比如单元格合并、表头识别等)。为了加速处理,团队租用RTX 4090 GPU,在40分钟内完成了100份报告的解析。
文本分块采用300 token长度,重叠50 token,使用递归分割策略保持语义完整。为了避免跨公司信息混淆(比如查询A公司CEO时检索到B公司的信息),为每个公司单独构建FAISS向量库,采用IndexFlatIP索引(不压缩以保证精度)。检索阶段采用三步走策略:首先通过向量检索找到Top30文本块,然后提取这些块所在的父页面并去重(因为多个块可能来自同一页),最后使用GPT-4o-mini对页面进行重新排序。向量检索分数与LLM重排序分数按0.3:0.7的权重混合。
生成阶段根据答案类型(数字/布尔/字符串等)使用不同的prompt模板。对于数字类问题(比如"2023年营收是多少"),设计了5步分析流程来确保指标匹配的准确性:识别问题中的指标类型、在文档中定位相关表格、提取数值、验证单位一致性、交叉验证。系统输出采用结构化格式,包含分析过程、相关页码等字段,确保答案可追溯。对于涉及多公司比较的问题(比如"哪家公司营收最高"),会拆分为单公司子查询后再合并结果。
该方案在竞赛中获得双奖项及排行榜第一。值得注意的是,即使使用小模型(如Llama 8B)也能超过80%的参与者,使用Llama 3.3 70B时仅比GPT-4o-mini稍差一点,成功实现了准确性、效率与成本的平衡。
6.4 AIOps场景:图文混合数据的智能处理
AIOps RAG竞赛的EasyRAG项目专注于运维场景下的问答任务,技术文章地址为:
http://blog.csdn.net/hustyichi/article/details/143323746
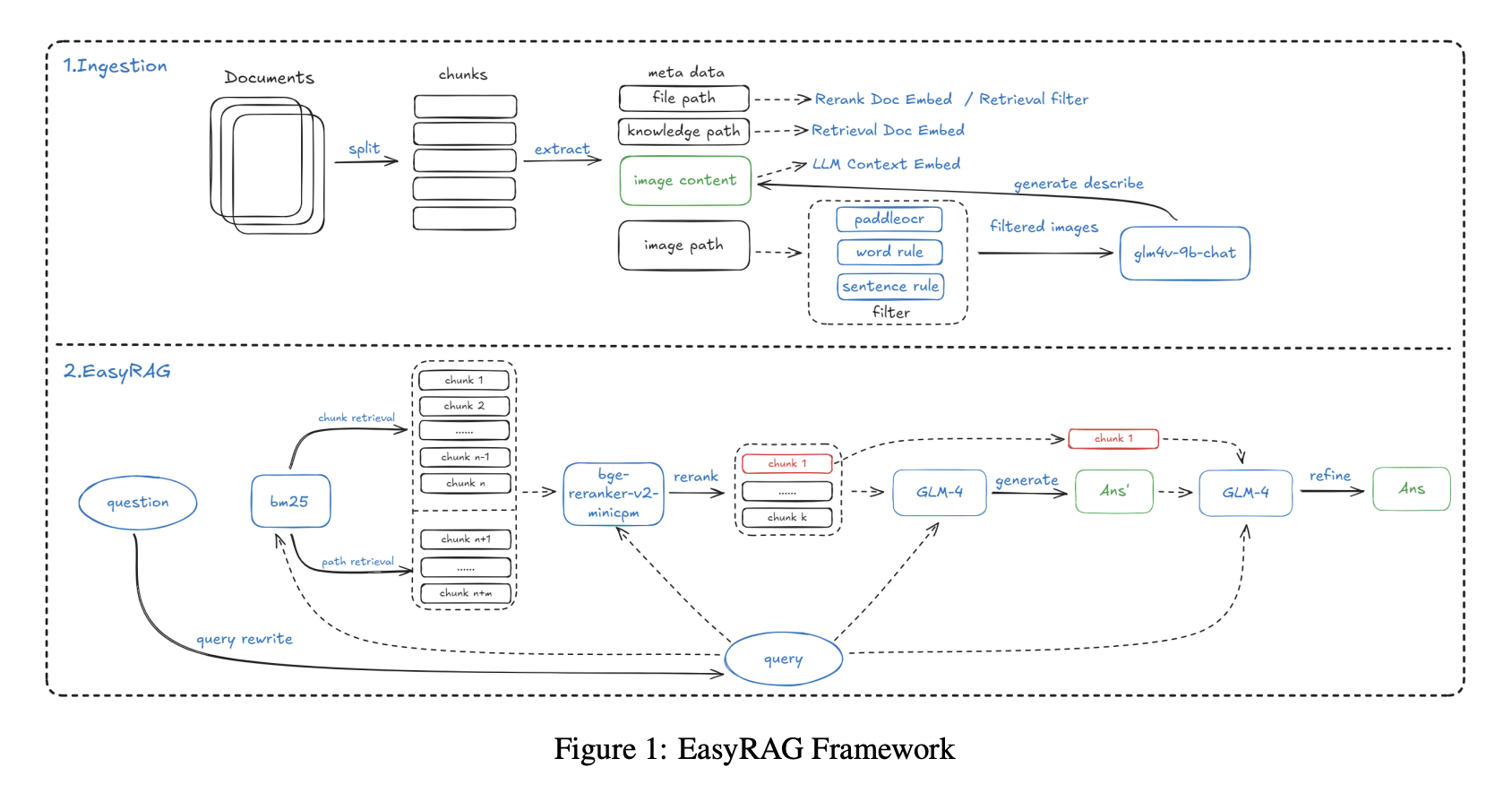
背景:运维工程师日常工作中需要查阅大量技术文档,这些文档不仅包含文字说明,还包含监控图表、系统架构图、性能曲线等图片信息。比如当系统出现性能问题时,工程师需要快速查询"CPU使用率超过80%时应该如何处理",答案可能分散在文字说明和监控图表中。传统RAG系统只能处理文字,无法理解图表中的趋势和数值,导致答案不完整。该项目最终获得初赛第一、复赛第二的成绩。
索引阶段使用改进过的SentenceSplitter(修复了原版块大小计算问题),按1024 token分块,重叠200 token。关键创新在于为每个文本块添加知识库路径、文件路径等元信息,这个改进使召回率提升了2%。对于图片数据,先使用PaddleOCR提取图片中的文字(比如图表的标题、坐标轴标签),再调用GLM-4V-9B多模态模型生成图片的自然语言描述(比如"该折线图显示CPU使用率在下午3点达到峰值90%"),将文字和描述一起入库,实现了图文信息的统一检索。
检索阶段采用"双路BM25+向量检索"策略进行广泛召回。BM25包含文档块检索(召回192条)和路径检索(通过文件路径过滤无关文档,比如只检索运维手册而不检索开发文档),使用哈工大停用词表进行去噪。向量检索使用gte-Qwen2-7B-instruct模型,召回288条候选结果。重排序阶段使用bge-reranker-v2-minicpm-layerwise模型,经过测试发现28层配置效果最好。
答案生成采用两步策略——先基于Top6文档生成初步结果(覆盖多个相关知识点),再结合Top1最相关文档进行二次优化(突出最核心的答案)。这个设计确保了答案既有足够的信息覆盖面,又能突出最核心的内容。
为了应对长文本场景(比如一份完整的运维手册可能有几百页),系统实现了基于BM25的上下文压缩方法。该方法将文档拆分为句子级别,计算每个句子与查询的相似度,然后按比例拼接高相关句子。实验表明,在50%压缩率下,该方法耗时仅7.7秒,准确率达86.48%,优于LLMLingua等现有压缩工具。
相比基础方案,加入元信息和答案二次优化后,系统准确性分别都提升了2%。BM25压缩方法在保证效率的同时保持了较高的准确性,很好地适配了AIOps场景下图文数据处理和实时响应的需求。
6.5 多源数据融合:结构化与非结构化知识的协同
KDD Cup 2024 Meta RAG挑战赛的冠军方案展示了如何整合非结构化Web数据和结构化知识图谱,技术文章地址为:
https://blog.csdn.net/m0_59164520/article/details/143694213
https://arxiv.org/pdf/2410.00005
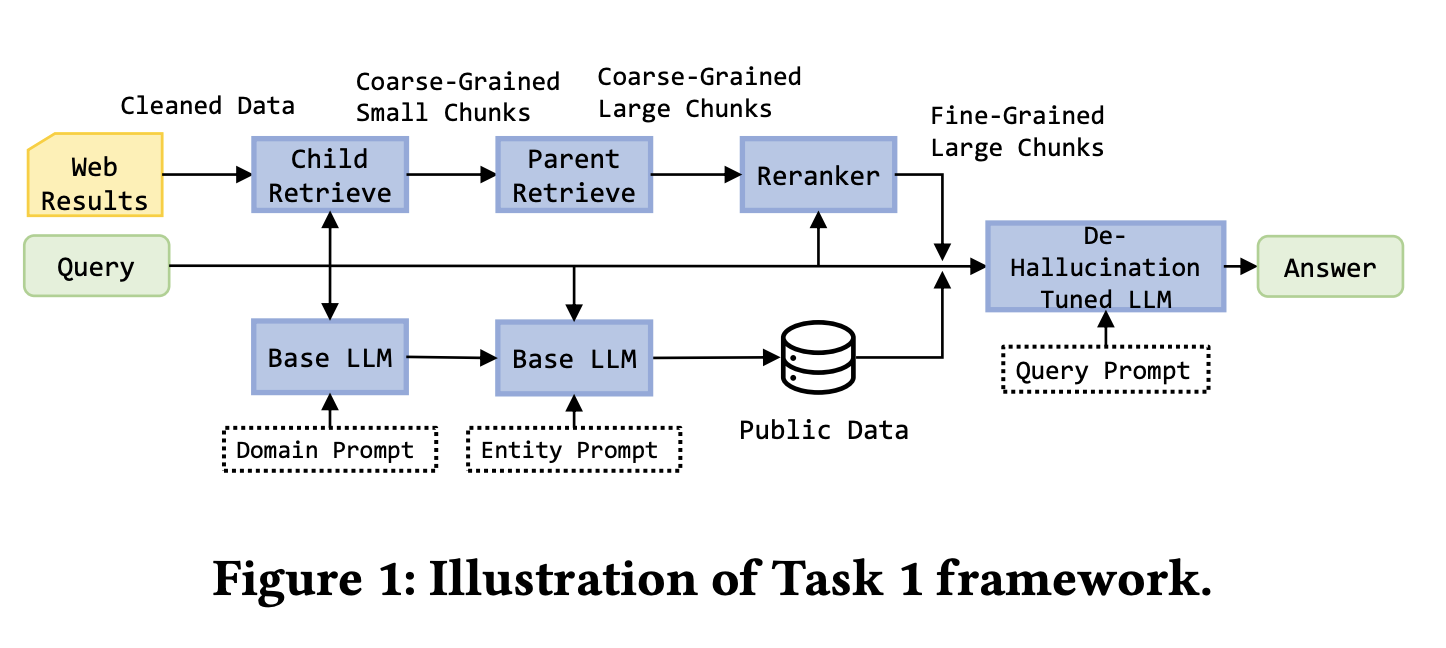
背景:任务1要求基于5个网页做检索摘要,比如用户搜索"星际穿越导演是谁",系统需要从给定的网页中提取答案。任务2在任务1基础上增加了Mock API(模拟访问结构化知识图谱),系统可以调用API查询电影数据库、人物关系等结构化信息。任务3进一步扩大难度,基于50个网页与Mock API处理复杂查询,比如"哪些由诺兰导演的电影票房超过5亿美元",这需要同时查询知识图谱(导演作品关系)和网页(票房数据)。每个查询需在30秒内完成,核心目标是提升多源数据整合的准确性并减少幻觉。
北大db3团队针对任务1设计了精细化的Web数据处理流程。使用BeautifulSoup提取网页文本,ParentDocumentRetriever管理父子块关系(子块200 token用于检索、父块500-2000 token用于生成),确保检索准确性和生成完整性。嵌入模型选用bge-base-en-v1.5,向量库使用Chroma,重排序采用bge-reranker-v2-m3。团队还补充了电影、金融等领域的公开数据(比如IMDB电影数据、上市公司财报),转换为规范格式后入库。模型层面使用LoRA微调Llama-3-8B-instruct,训练数据包括无效问题标注(比如"今天天气怎么样"这类超出知识库范围的问题)、正确答案等。
任务2-3的关键创新在于优先使用知识图谱。团队设计了规范化的API调用机制,包括get_person(查询人物信息)、get_movie(查询电影信息)等接口,支持条件过滤(比如cmp操作符筛选票房>5亿的电影)和排序(按票房降序)。API调用生成采用GPT-4初步标注后人工优化的方式进行微调。系统执行时先调用知识图谱API,只有在知识图谱结果无效(比如查询的电影不在数据库中)时才回退到Web检索,这个设计大幅提升了查询效率和答案准确性。
通过知识图谱优先策略和结构化输出格式,系统明显减少了LLM的幻觉现象。当知识图谱能提供确定性答案时(比如"诺兰出生年份"),直接输出不经过生成步骤;当需要从Web检索时(比如"诺兰最新访谈内容"),通过严格的文档引用和分步推理确保答案可验证。
该方案在三个任务中均获第一,得分分别达到28.4%、42.7%和47.8%,成功平衡了多源数据整合的准确性与实时性。这个案例的核心启示在于,对于包含结构化和非结构化数据的企业场景,应该根据数据特点设计不同的检索策略,优先使用确定性强的结构化数据,用非结构化数据作为补充。
深入分析这几个实践案例,我们可以总结出构建高质量RAG系统的几个共同原则:在架构设计上,应该根据业务场景选择合适的缓存、检索和生成策略;在数据处理上,需要针对不同格式和模态设计专门的解析和索引方案;在检索优化上,混合检索加重排序已成为标准配置;在答案生成上,分类型的prompt和结构化输出能明显提升准确性和可追溯性。
这些来自真实竞赛和开源项目的经验,为搭建更好的企业级RAG系统提供了宝贵的参考,你可以根据实际问题搜索对应的比赛,找到成熟现有方案进行尝试。
广度探索:RAG 的未来演化(Optional)
在深入掌握了RAG的实战技巧与优化方法后,你已经能够在具体场景中有效提升系统性能。然而,要全面把握RAG技术,仅靠对局部的深入钻研还不够,我们还需拓展视野,从更广阔的维度理解其演进方向与扩展空间。
当前,RAG技术正在迅速突破传统基于文档分块的检索生成范式,朝着更多样化的方向发展。本节将重点探讨以下几个演进路径:从简单的分块检索转向对图数据结构的检索;融合图像、音频等多模态信息以增强RAG的检索能力;利用向量化技术优化长文档的分块处理策略;以及RAG如何逐步演化为智能体(Agent)系统。
7.1 Graph RAG:用关系网络重塑深度检索
相关研究:https://arxiv.org/pdf/2410.05779, https://arxiv.org/pdf/2502.11371, https://arxiv.org/pdf/2404.16130
传统RAG依靠寻找和问题相似的文本段落来工作,这就像在一堆材料里挑出看起来最相关的几段话。对于直接查找某个具体信息,这种方法很有效。但如果一个问题需要联系多份文档、结合不同线索才能回答,它的表现就会打折扣。
比如,医生可能想问:“根据这些病例和最新的治疗指南,如何评估某种药物对老年患者的好处和风险?”又或者,项目团队可能关心:“综合过去两年的需求文档、评审记录和线上问题报告,我们这个系统架构最常出问题的环节是什么?”这类问题的关键,不是找到某一句原话,而是要从各种分散的材料中,找出其中提到的人、事、物以及它们之间的联系,理清头绪,形成一幅完整的全景图。
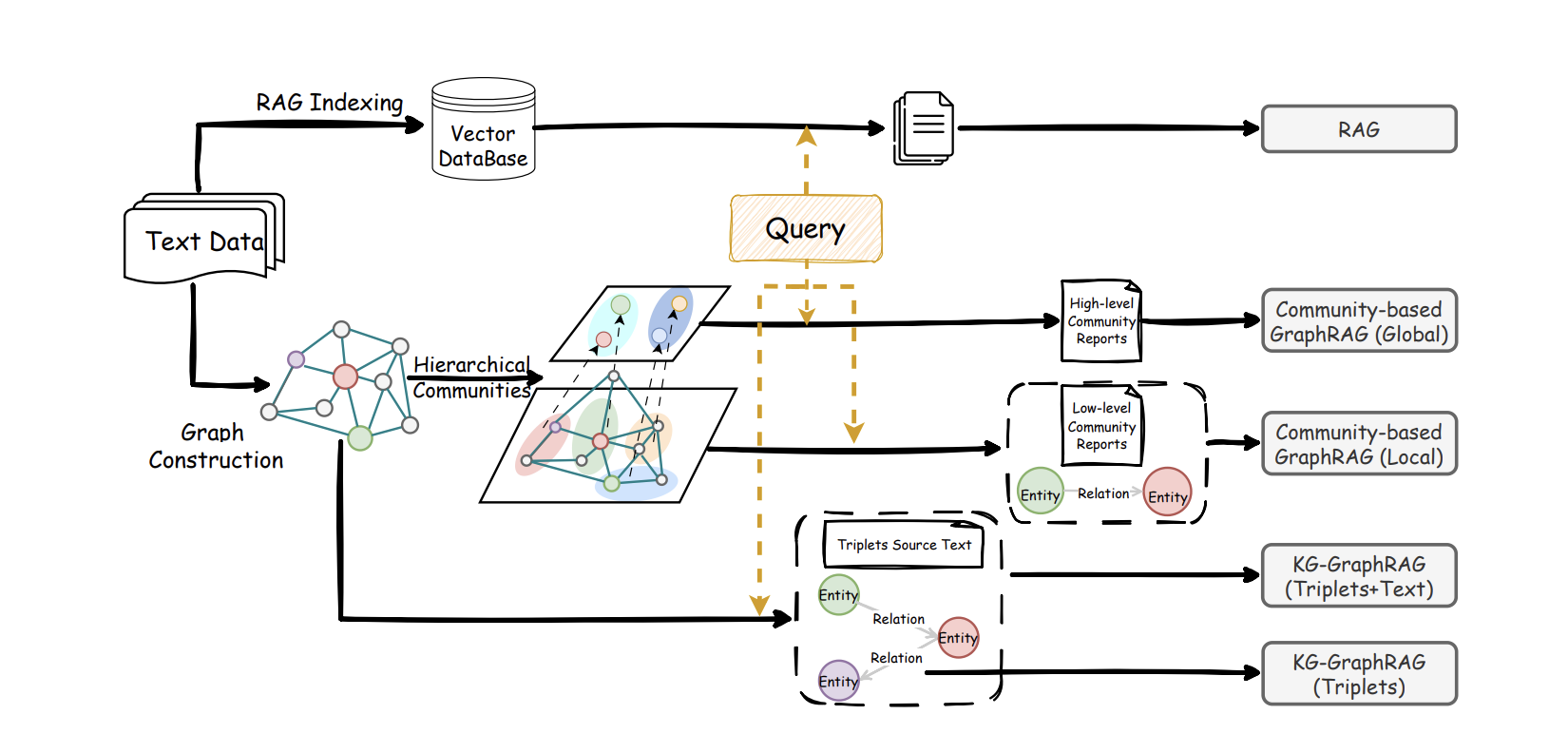
Graph RAG的做法,就是先主动画出这幅全景图。系统会利用大模型从文本中识别出关键元素(比如人物、机构、功能模块、事件、数据等)以及它们之间的关系(比如谁导致了什么、什么依赖于什么、如何变化、有何矛盾等),从而构建一个随着资料增加而不断丰富的知识网络。接着,通过自动分组,把联系紧密的元素和关系归类到不同的主题下,并为每个主题提前生成一段概括性描述。这样,当用户提问时,系统不再仅仅是寻找字面上最相似的段落,而是会先在知识网络里找到与问题最相关的元素和局部结构,再顺着连接线扩展到相关的主题组,最后将这些分析路径、节点说明和对应的原始文本片段,一起交给大模型进行推理并组织答案。
在这样的框架下,Graph RAG和传统RAG形成了很好的分工与配合:传统RAG仍然擅长回答直接的、一步就能找到答案的细节问题;而Graph RAG则更像人在做研究或写报告时的思路——先梳理出整体结构和主题(构建网络与分组),再填充具体依据(引用原文),最后给出有逻辑、有条件限制的结论。已有的系统对比也显示,在需要联系多个信息点进行推理的任务中,Graph RAG通常能涵盖更关键的内容,提供更全面的视角;而根据问题的具体特点,灵活结合使用两种方法,整体效果往往比只使用其中一种更好。
7.2 Multimodal RAG:多模态 RAG
相关研究:https://arxiv.org/pdf/2502.08826
现实世界的数据从来不是单一文本。工程师排查服务器故障时,需要同时看温度监控曲线、设备面板截图和系统日志;医生做诊断时,需要把 CT / MRI 影像、检查报告和电子病历放在一起看。传统的文本 RAG 最多只能检索到“温度异常”“怀疑肺结节”这样的文字描述,却难以把这些描述与具体的曲线走势、影像病灶形态对应起来,更做不到用“图/音/视频”去反向检索相关文档和知识。
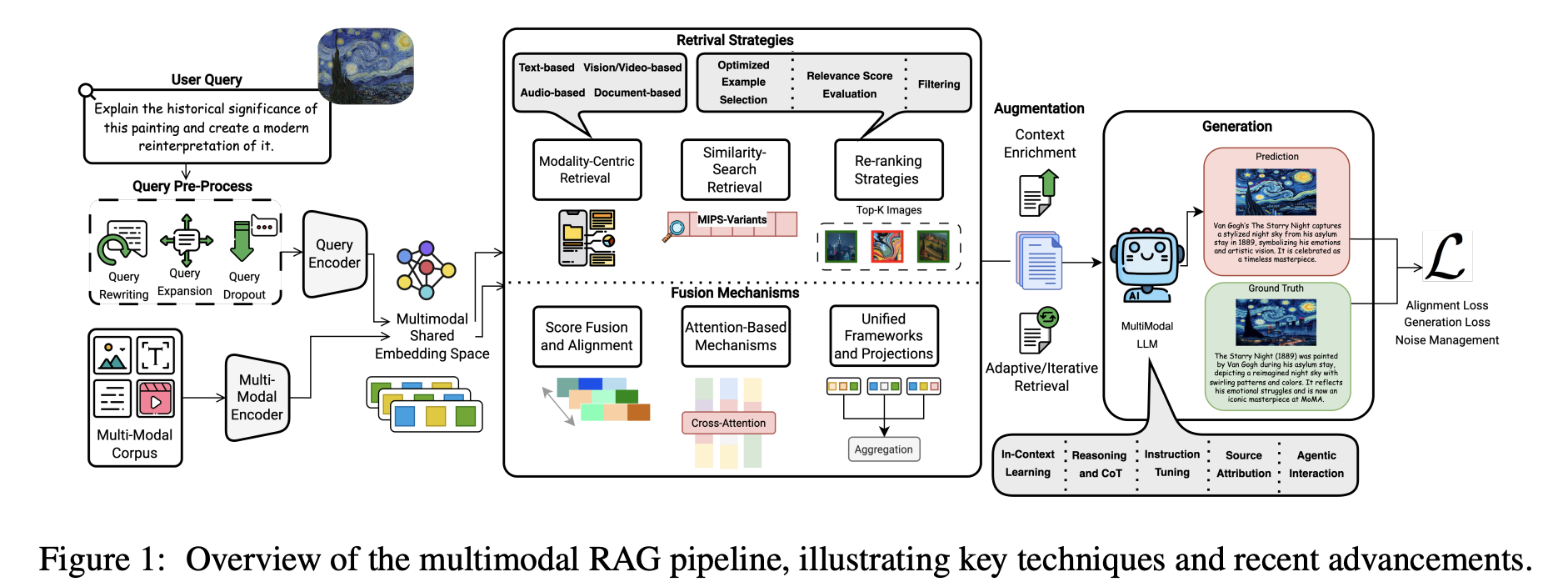
Multimodal RAG(多模态 RAG)解决的是这种“模态之间互相看不见”的问题。它的核心在于跨模态语义对齐:为图像、视频、音频、文本等分别配置合适的编码器(如 ViT/CLIP 编图像和视频帧,Whisper 编音频,BGE-M3 等编码文本),配合 OCR、ASR、版面分析等工具,把视觉和音频里的关键信息抽取出来,再通过模型把不同模态的表示映射到一个共享的语义空间中,构建统一的多模态索引。
在检索和生成阶段,不管用户是问“找一张显示 2023 年 Q3 销售峰值的图表”,还是上传一张产品草图或一段操作视频发起查询,系统都会先在这个统一空间里找到一批最相近的多模态内容,然后根据文本相似度、图像相似度等信号,筛掉明显无关的结果,保留几条最有用的证据。最后,把这些经过筛选的图、文、表格等,一并交给多模态大模型,由它综合不同模态的信息给出答案,并尽量标明信息来源,或在截图、文档中高亮相关位置。这样一来,相比只看文本的 RAG,系统既能利用更多模态的线索,又更容易减少幻觉,让答案更完整也更容易核实。
7.3 Late Chunking:为长文档保留完整上下文
相关介绍:https://jina.ai/news/late-chunking-in-long-context-embedding-models/
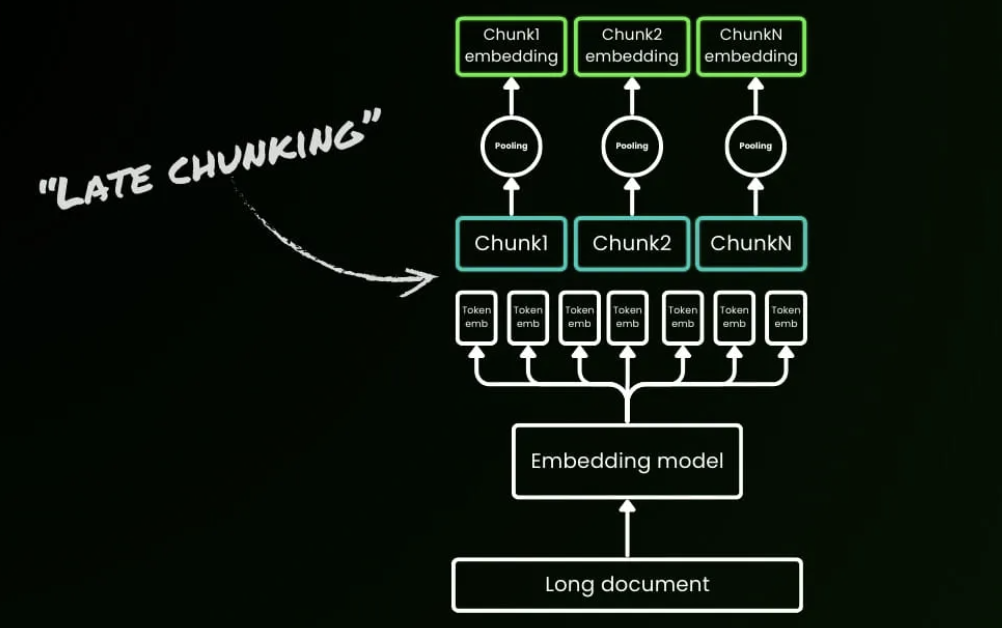
想象你正在阅读一篇关于柏林的维基百科文章,传统RAG系统会先将其切成独立段落再生成向量。当第一句提到"柏林是德国首都"后,后续段落中的"该城市"、"它的人口"等指代词就失去了与"柏林"的关联。此时若查询"柏林的人口是多少",系统会因为"柏林"和"人口数据"从未在同一文本块出现而检索失败。这个问题在长文档场景更为严重:一份200页的保险合同中,"免赔额"的定义在第5页,具体适用条件在第30页,传统的固定长度切分(如每512 tokens一块)会将这些相关信息分散到40多个独立文本块中,实验数据显示这种割裂会导致语义相似度从0.85暴跌至0.71。
Late Chunking颠覆了"先切后编"的传统流程,改为"先编后切":利用支持8192 tokens(约10页文本)的长上下文嵌入模型(如Jina Embeddings v2),首先将整个文档输入Transformer层,生成每个token的向量表示——此时每个token的嵌入已经"看到"了全文信息,捕获了跨段落的指代关系和概念关联。随后,再对这些已经全局感知的token向量进行分块平均池化(mean pooling),生成最终的块嵌入。这样生成的文本块不再是独立同分布的孤岛,而是"条件依赖"的上下文链:当处理"该城市有385万居民"这句话时,向量中已经包含了前文"柏林"的语义信息,使相似度从0.71提升至0.83。关键区别在于边界标记的使用时机:传统方法在预处理阶段就用句号、段落符切分文本,而Late Chunking仅在获得全局token嵌入后,才应用边界线索进行智能分块。
在BEIR基准测试的5个数据集上,Late Chunking全面超越传统切分方法。最显著的案例是NFCorpus数据集(平均文档长度1590字符),检索准确率从23.46%飙升至29.98%,相对提升27.8%;而在短文本场景(如Quora的62字符问题)两者表现相同,验证了一个关键规律:文档长度与Late Chunking的优势呈正相关。从技术对比表可见核心差异:传统切分在预处理阶段直接应用边界标记,产生独立同分布的块嵌入,上下文信息丢失;Late Chunking在获得token嵌入后才应用边界标记,产生条件依赖的块嵌入,由长上下文模型完整保留上下文信息。
该方法现已集成到Jina Embeddings v3 API中,虽然需要先编码整个长文档,推理时间增加10-20%,但在医疗病历(跨章节的诊断依据)、法律文档(定义与条款的交叉引用)、技术手册(概念解释分散在多个章节)等场景中,检索准确率的大幅提升远超过这点性能开销。Late Chunking不仅证明了8K+长上下文模型的实用价值——不是"过度设计",而是实现高质量块嵌入的必要条件,更为RAG系统提供了一条摆脱滑动窗口、多次扫描等"hit-or-miss"启发式技巧、具有理论保证的优化路径,代表了从"先切后编"到"先编后切"的范式转变。
7.4 从 RAG 到 Agent 时代的 RAG
相关讨论:https://ragflow.io/blog/rag-at-the-crossroads-mid-2025-reflections-on-ai-evolution, https://arxiv.org/pdf/2501.09136, https://www.letta.com/blog/rag-vs-agent-memory, https://www.linkedin.com/posts/richmondalake_100daysofagentmemory-rag-memorizz-activity-7348281860843577346-LM7Y/, https://www.llamaindex.ai/blog/rag-is-dead-long-live-agentic-retrieval
RAG技术已从最初的检索增强生成工具,发展为构建智能体认知架构的关键部分。 传统RAG系统基于提问、检索、回答的简单模式,本质是被动接受查询,不具备主动行动的能力。为了突破这种被动性并处理更复杂的认知任务,RAG与智能体能力进行了深度融合,由此诞生了Agentic RAG这一新范式。 在此范式中,RAG的角色发生了根本转变:它不再仅仅是外部知识的被动提供者,而是在智能体的主动规划、目标指引和反思能力驱动下,成为支撑智能行为的核心处理单元。这种融合使系统整体具备了目标导向、迭代优化和自主决策的能力,显著提升了人机交互的深度与质量。具体而言,Agentic RAG能够理解复杂任务,自主拆解问题,规划检索策略,并在获取初步信息后评估结果质量,决定是否深入探索,从而胜任传统RAG难以应对的多步骤复杂任务。
Agentic RAG实现上述复杂任务处理的关键,在于其建立了一个多层次的主动循环工作机制。 面对复杂查询,智能体首先分析问题本质,将其拆解为子问题,并为每个子问题设计精准的检索策略。获得初步结果后,智能体进行评估与反思,判断信息的完整性和相关性,识别知识缺口,并动态生成更精确的新查询。这种迭代过程常包含多跳检索,即基于前一轮结果发现新的检索方向,形成类似人类研究者的知识探索链条。然而,要支撑这种持续的、迭代的智能行为,尤其是实现长期交互中的个性化和知识积累,仅依赖单次会话的短期上下文(短期记忆)是远远不够的。这引出了对长期、结构化记忆能力的需求。
正是为了满足这一需求,RAG被赋予了作为智能体长期记忆系统的角色,构建了一个完整的外部记忆架构。 该系统与负责维护当前会话上下文的短期记忆形成互补。该长期记忆系统的核心运作依赖于三项关键机制: 第一,结构化索引能力:使智能体能够为海量非结构化数据建立多维索引体系(如按时间、主题或实体关系),支持多角度高效检索,模拟人脑通过不同线索回忆信息的方式。 第二,智能遗忘机制:通过价值评估算法,系统对使用频率低、相关性弱或过时的信息进行权重衰减或选择性剔除,维持记忆系统的精炼高效,防止信息过载。 第三,知识巩固过程:系统将零散对话和交互经验提炼为结构化知识,利用实体识别、关系抽取和语义聚类等技术,将碎片信息整合连接成知识图谱,完成从短期经验到长期知识的转化与沉淀。
这种由RAG构建的外部记忆系统,不仅极大地扩展了智能体的认知边界,更重要的是赋予了其持续学习和知识进化的能力。 它使得智能体能够在长期互动中积累经验,形成个性化的处理模式和领域专业知识体系,从而为执行更复杂、更持久的任务提供了坚实的基础。
总结
检索增强生成不仅是一种弥补大模型幻觉与知识滞后性的技术方案,更是将通用AI能力转化为企业深度业务价值的关键桥梁。从基础的Naive RAG演进至模块化、智能体协同的Advanced RAG,这一过程反映出RAG在各个环节均需持续深化——无论是更精细的数据处理、更科学的模型选型(Embedding、Rerank、LLM),还是更体系化的效果评测,都是构建可控、可信、高效的企业级知识系统的必经之路。同时,从各类竞赛与实践案例中汲取经验技巧,也能进一步加深对技术细节的理解。
随着图结构检索(Graph RAG)、多模态理解与Late Chunking等前沿方向的融合发展,RAG正不断突破传统检索生成的边界,逐步具备更深层的语义关联与可持续的记忆能力。希望通过这篇综述类文章的学习,能够帮助你掌握从原理到实践、从评估到演进的全链路方法论,从而在快速迭代的技术浪潮中,打造出真正落地、能够应对复杂业务挑战的高质量智能应用。
Reference
[1] Ask in Any Modality: A Comprehensive Survey on Multimodal Retrieval-Augmented Generation.
https://arxiv.org/pdf/2502.08826
[2] Retrieving Multimodal Information for Augmented Generation: A Survey.
https://arxiv.org/pdf/2303.10868
[3] A Survey on RAG Meeting LLMs: Towards Retrieval-Augmented Large Language Models.
https://arxiv.org/pdf/2405.06211
[4] Retrieval-Augmented Generation for Large Language Models: A Survey.
https://arxiv.org/pdf/2312.10997
[5] LightRAG: Simple and Fast Retrieval-Augmented Generation.
https://arxiv.org/pdf/2410.05779
[6] Agentic Retrieval-Augmented Generation: A Survey on Agentic RAG.
https://arxiv.org/pdf/2501.09136
[7] ERAGent: Enhancing Retrieval-Augmented Language Models with Improved Accuracy, Efficiency, and Personalization.
https://arxiv.org/pdf/2405.06683
[8] Graph Retrieval-Augmented Generation: A Survey.
https://www.arxiv.org/pdf/2408.08921
[9] Evaluation of Retrieval-Augmented Generation: A Survey.
https://arxiv.org/pdf/2405.07437
[10] Retrieval Augmented Generation Evaluation in the Era of Large Language Models: A Comprehensive Survey.
https://arxiv.org/pdf/2504.14891
[11] From Local to Global: A Graph RAG Approach to Query-Focused Summarization.
https://arxiv.org/pdf/2404.16130
[12] RAG vs. GraphRAG: A Systematic Evaluation and Key Insights.
https://arxiv.org/pdf/2502.11371
[13] Introduction to RAG | LlamaIndex Python Documentation.
https://developers.llamaindex.ai/python/framework/understanding/rag/
[14] All-in-RAG | 大模型应用开发实战:RAG 技术全栈指南.
https://datawhalechina.github.io/all-in-rag/#/en/
[15] Ilya Rice: How I Won the Enterprise RAG Challenge.
https://abdullin.com/ilya/how-to-build-best-rag/
[16] RAG Research Table – Awesome Generative AI Guide (GitHub).
[17] RAG is dead, long live agentic retrieval.
https://www.llamaindex.ai/blog/rag-is-dead-long-live-agentic-retrieval
[18] LLM/RAG Zoomcamp 課外補充 5:RAG Evolution 常見評估方法和市場偏好.
https://vip.studycamp.tw/t/llmrag-zoomcamp-課外補充-5:rag-evolution-常見評估方法和市場偏好/8185
[19] How to Evaluate Retrieval Augmented Generation (RAG) Applications.
https://zilliz.com.cn/blog/how-to-evaluate-rag-zilliz
[20] RAG is not Agent Memory.
https://www.letta.com/blog/rag-vs-agent-memory
[21] Richmond Alake. LinkedIn post on #100DaysOfAgentMemory, RAG and MemoRizz.