评测指标面试题
metric主要用来评测机器学习模型的好坏程度,不同的任务应该选择不同的评价指标,分类,回归和排序问题应该选择不同的评价函数. 不同的问题应该不同对待,即使都是分类问题也不应该唯评价函数论,不同问题不同分析.
回归(Regression)
平均绝对误差(MAE)
平均绝对误差MAE(Mean Absolute Error)又被称为 L1范数损失。
MAE虽能较好衡量回归模型的好坏,但是绝对值的存在导致函数不光滑,在某些点上不能求导,可以考虑将绝对值改为残差的平方,这就是均方误差。
均方误差(MSE)
均方误差MSE(Mean Squared Error)又被称为 L2范数损失 。
由于MSE与我们的目标变量的量纲不一致,为了保证量纲一致性,我们需要对MSE进行开方 。
均方根误差(RMSE)
R2_score
因此:
分类(Classification)
准确率和错误率
Acc与Error平等对待每个类别,即每一个样本判对 (0) 和判错 (1) 的代价都是一样的。使用Acc与Error作为衡量指标时,需要考虑样本不均衡问题以及实际业务中好样本与坏样本的重要程度。
混淆矩阵
对于二分类问题,可将样例根据其真是类别与学习器预测类别的组合划分为:
真正例(true positive, TP):预测为 1,预测正确,即实际 1
假正例(false positive, FP):预测为 1,预测错误,即实际 0
真反例(ture negative, TN):预测为 0,预测正确,即实际 0
假反例(false negative, FN):预测为 0,预测错误,即实际 1则有:TP+FP+TN+FN=样例总数. 分类结果的混淆矩阵(confusion matrix)如下:

精确率(查准率) Precision
Precision 是分类器预测的正样本中预测正确的比例,取值范围为[0,1],取值越大,模型预测能力越好。
召回率(查全率)Recall
Recall 是分类器所预测正确的正样本占所有正样本的比例,取值范围为[0,1],取值越大,模型预测能力越好。
F1 Score
Precision和Recall 是互相影响的,理想情况下肯定是做到两者都高,但是一般情况下Precision高、Recall 就低, Recall 高、Precision就低。为了均衡两个指标,我们可以采用Precision和Recall的加权调和平均(weighted harmonic mean)来衡量,即F1 Score
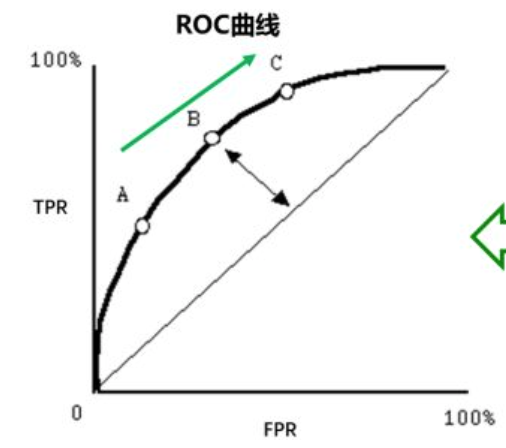
ROC
ROC全称是"受试者工作特征"(Receiver Operating Characteristic)曲线. ROC曲线为 FPR 与 TPR 之间的关系曲线,这个组合以 FPR 对 TPR,即是以代价 (costs) 对收益 (benefits),显然收益越高,代价越低,模型的性能就越好。 其中ROC曲线的横轴是"假正例率"(False Positive Rate, FPR), 纵轴是"真正例率"(True Positive Rate, TPR), 注意这里不是上文提高的P和R.
- y 轴为真阳性率(TPR):在所有的正样本中,分类器预测正确的比例(等于Recall)
- x 轴为假阳性率(FPR):在所有的负样本中,分类器预测错误的比例
现实使用中,一般使用有限个测试样例绘制ROC曲线,此时需要有有限个(真正例率,假正例率)坐标对. 绘图过程如下:
- 给定
个正例和 个反例,根据学习器预测结果对样例进行排序,然后将分类阈值设为最大,此时真正例率和假正例率都为0,坐标在(0,0)处,标记一个点. - 将分类阈值依次设为每个样本的预测值,即依次将每个样本划分为正例.
- 假设前一个坐标点是(x,y),若当前为真正例,则对应坐标为
, 若是假正例,则对应坐标为 - 线段连接相邻的点.
ROC曲线如下图(其中对角线对应于"随机猜测"模型):
AUC
对于二分类问题,预测模型会对每一个样本预测一个得分s或者一个概率p。 然后,可以选取一个阈值t,让得分s>t的样本预测为正,而得分s<t的样本预测为负。 这样一来,根据预测的结果和实际的标签可以把样本分为4类,则有混淆矩阵:
| 实际为正 | 实际为负 | |
|---|---|---|
| 预测为正 | TP | FP |
| 预测为负 | FN | TN |
随着阈值t选取的不同,这四类样本的比例各不相同。定义真正例率TPR和假正例率FPR为:
随着阈值t的变化,TPR和FPR在坐标图上形成一条曲线,这条曲线就是ROC曲线。 显然,如果模型是随机的,模型得分对正负样本没有区分性,那么得分大于t的样本中,正负样本比例和总体的正负样本比例应该基本一致。
实际的模型的ROC曲线则是一条上凸的曲线,介于随机和理想的ROC曲线之间。而ROC曲线下的面积,即为AUC!
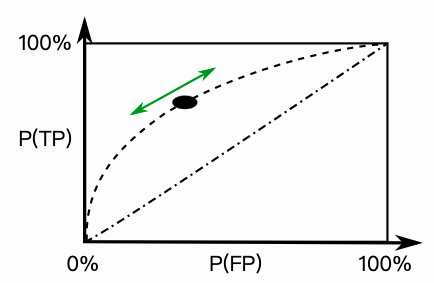
这里的x和y分别对应TPR和FPR,也是ROC曲线的横纵坐标。
参考:https://tracholar.github.io/machine-learning/2018/01/26/auc.html
KS Kolmogorov-Smirnov
KS值是在模型中用于区分预测正负样本分隔程度的评价指标,一般应用于金融风控领域。与ROC曲线相似,ROC是以FPR作为横坐标,TPR作为纵坐标,通过改变不同阈值,从而得到ROC曲线。ks曲线为TPR-FPR,ks曲线的最大值通常为ks值。可以理解TPR是收益,FPR是代价,ks值是收益最大。图中绿色线是TPR、蓝色线是FPR。
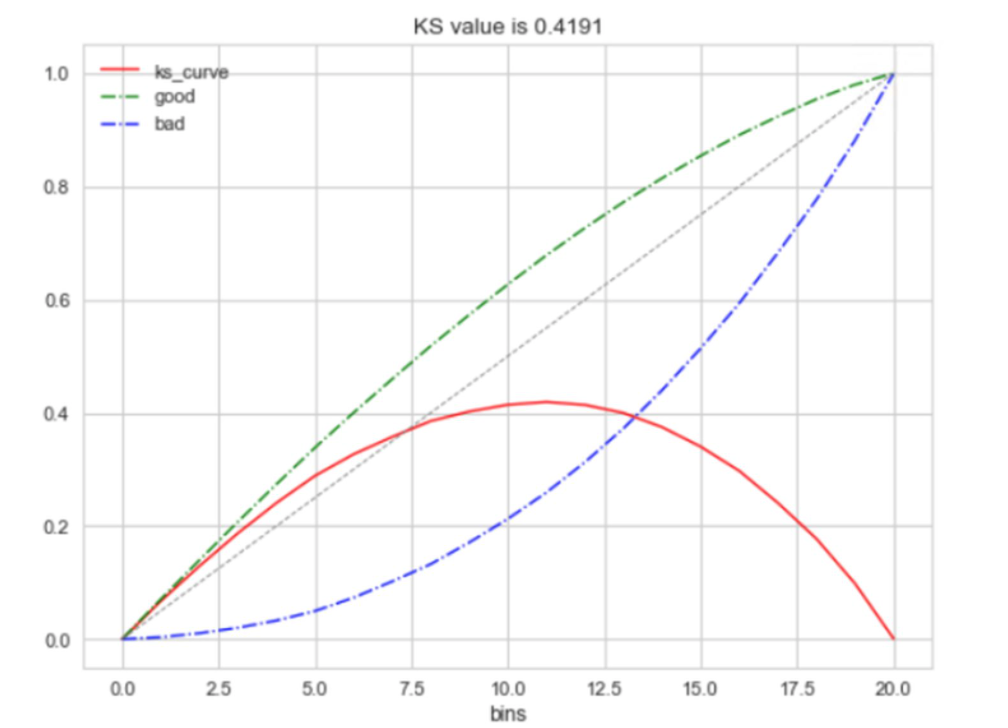
KS的计算步骤如下:
- 按照模型的结果对每个样本进行打分
- 所有样本按照评分排序,从小到大分为10组(或20组)
- 计算每个评分区间的好坏样本数。
- 计算每个评分区间的累计好样本数占总好账户数比率(good%)和累计坏样本数占总坏样本数比率(bad%)。
- 计算每个评分区间累计坏样本占比与累计好样本占比差的绝对值(累计bad%-累计good%),然后对这些绝对值取最大值即得此评分模型的K-S值。
CTR(Click-Through-Rate)
CTR即点击通过率,是互联网广告常用的术语,指网络广告(图片广告/文字广告/关键词广告/排名广告/视频广告等)的点击到达率,即该广告的实际点击次数(严格的来说,可以是到达目标页面的数量)除以广告的展现量(Show content).
CVR (Conversion Rate)
CVR即转化率。是一个衡量CPA广告效果的指标,简言之就是用户点击广告到成为一个有效激活或者注册甚至付费用户的转化率.