第 11 章 现代策略梯度方法(Modern Policy Gradient Methods)#
本章介绍的算法并未包含在 Sutton 的原著中,但每一个算法在强化学习发展历程中都具有里程碑意义,并持续推动该领域的深入研究。我用”现代”一词来区分本章算法与第10章的内容,而你在学习过程中会发现,这些策略近似方法实际上有很多相似之处。
对于可追溯至原始论文的算法,本章保留了原论文的符号表示。尽管不同小节可能采用不同的符号规范,但这些符号均基于本教程已介绍的基本概念,因此读者理解起来不会有明显困难。请注意,学习本章内容需要具备神经网络的基础知识。
11.1 优势函数的概念#
11.1.1 定义#
优势函数(Advantage Function)是一个比较动作Q值与状态价值函数的概念,用于衡量在特定状态下某个动作 \(a_t\) 相对于智能体平均行为的优劣。其定义如下:
直观理解:优势函数衡量动作 \(a_t\) 相对于状态 \(s_t\) 下期望回报 \(E_\pi[G_t \vert s_t]\) 的好坏程度。
当 \(A(s_t, a_t) > 0\) 时,动作 \(a_t\) 被认为优于状态 \(s_t\) 下的平均动作;
当 \(A(s_t, a_t) < 0\) 时,动作 \(a_t\) 不如状态 \(s_t\) 下的平均动作;
当 \(A(s_t, a_t) = 0\) 时,该动作与期望值持平,既不更好也不更差。
Note
优势函数 \(A(s_t, a_t)\) 常简写为 \(A_t\),但请注意区分动作 \(A_t\) 和优势 \(A(s_t, a_t)\)。在后续章节中,当需要明确区分这两者时,我们将使用 \(A(s_t, a_t)\) 表示优势。
11.1.2 存在意义#
如第10章中REINFORCE算法所示,策略梯度方法的梯度估计通常噪声较大,这是因为该估计依赖于观测到的回报(Return),而回报本身具有随机性且可能差异显著。
优势函数通过在梯度估计中简单替换回报项,有效降低了梯度估计的方差,从而实现更稳定的参数更新:
Note
对于带基线的 REINFORCE 方法,当使用近似状态价值函数 \(\hat{v}(S_t, \boldsymbol{w})\) 作为基线时,量 \(G_t - b(S_t)\) 可被视为优势 \(A_t\) 的一种估计形式,因为根据定义,\(G_t\) 是 \(q(s_t, a_t)\) 的估计值。
在实际中,人们常将带基线的 REINFORCE 方法视为 演员-评论员 方法。但本教程遵循 Sutton 书中的原则,仅将那些利用 critic 模型进行自举的方法视为 AC 方法。
11.1.3 优势函数的估计方法#
定义估计法:\(A(s_t, a_t)\) 可直接通过动作价值减去状态价值来估计:
\[\begin{split} \begin{align*} \hat{A}(s_t, a_t) \ &\dot= \ q(s_t, a_t) - v(s_t) \\ &= G_t - v(s_t) \end{align*} \end{split}\]需注意,这种估计方法在实际应用中较少使用,因为它需要学习两个评论员(critic)模型,通常会被第二种方法替代。
TD误差估计法:时间差分(TD)误差是一种实用的优势近似估计方法。回顾第3章第3.3节,
\[ q(s,a) \dot= \sum_{s', r}p(s', r|s, a) [r + \gamma v_{\pi}(s')] \]这表明,当从状态-动作对 (s,a) 出发并实际到达状态 \(s'\) 时,\(r + \gamma v_{\pi}(s')\) 可视为一个单次实现(realization)。
因此,我们可用 \(r_{t+1} + \gamma v(s_{t+1})\) 代替 \(q(s_t,a_t)\),并将优势估计为:
\[ \hat{A}(s_t, a_t) \ = \ r_{t+1} + \gamma v(s_{t+1}) - v(s_{t}) \]广义优势估计(Generalized Advantage Estimation,GAE):
如前所述,优势可通过 \(G_t - v(s_t)\) 来估计,因为时间步 \(t\) 的回报是对应动作价值的一个估计。现在我们从另一角度考虑回报的估计方式。在 \(n\) 步TD方法中(本教程未详细介绍),回报定义为:
\[\begin{split} \begin{align*} G_{t:t+n} \ &\dot= \ R_{t+1} + \gamma R_{t+2} + \cdots + \gamma^{n-1} R_{t+n} + \gamma^n V(S_{t+n}) \\ &= \sum_{k=0}^{n-1} \gamma^k R_{t+k+1} + \gamma^n v(s_{t+n}) \end{align*} \end{split}\]这种 \(n\) 步回报 \(G_{t:t+n}\) 相比蒙特卡洛回报具有更低的方差,但代价是引入了一定偏差。为进一步推广这一思想,我们可使用衰减参数 \(\lambda\) 对 \(n\) 步回报进行指数加权平均,得到 \(\lambda\)-回报:
\[\begin{split} \begin{align*} G^{\lambda}_t \ &\dot= \ (1 - \lambda) \sum_{n=1}^{\infty} \lambda^{n-1} G_{t:t+n} \\ &= (1 - \lambda) \sum_{n=1}^{T-t-1} \lambda^{n-1} G_{t:t+n} + \lambda^{T-t-1} G_t \end{align*} \end{split}\]上式第二个等式基于时间步 \(T\) 之后所有奖励为0的假设推导而来,此时对于所有 \(n \geq T-t\),有 \(G_{t:t+n} = G_{t:T}\)。与 \(n\) 步回报在离散设置中调节偏差-方差权衡不同,\(\lambda\)-回报提供了一种连续的调节机制,使权衡更加平滑。实证研究表明,\(\lambda\)-回报的性能优于简单的 \(n\) 步回报。
广义优势估计(GAE)通过用 \(\lambda\)-回报替代蒙特卡洛回报来计算:
\[\begin{split} \begin{align*} \hat{A}^{GAE}(s_t, a_t) \ &\dot= \ G^{\lambda}_t - v(s_t) \tag{1} \\ &= \sum_{l=0}^{\infty} (\gamma \lambda)^l \delta_{t+l} \tag{2} \\ &= \delta_{t} + (\gamma \lambda)\delta_{t+1} + (\gamma \lambda)^2\delta_{t+2} + \ ... \tag{3} \\ &= \delta_{t} + (\gamma \lambda)\hat{A}^{GAE}(s_{t+1}, a_{t+1}) \tag{4} \end{align*} \end{split}\]关于GAE如何具体由公式\((2)\)表示,感兴趣的读者可参考原始论文。公式\((3)\)是GAE的展开形式,它给出了TD误差的加权和,其中未来的TD误差通过\(\lambda\)参数进行折扣和平滑。在实际应用中,GAE通常使用公式\((4)\)以反向递归方式在每个时间步计算。
Note
关于 \(n\) 步回报 \(G_{t:t+n}\) 的直觉理解:当 \(n=1\) 时,回报为 \(R_{t+1} + \gamma v(s_{t+1})\),这正是 TD 方法的更新目标(高偏差,低方差);当 \(n\) 趋于无穷时,则回到原始蒙特卡洛回报(无偏,高方差)。因此,\(n\) 是价值估计器中偏差与方差之间的权衡参数。
关于 \(\lambda\) 回报的直觉理解:类似于 \(n\) 步回报,\(\lambda=0\) 时退化为单步回报(1 步 TD 目标),而 \(\lambda=1\) 时恢复为蒙特卡洛回报。
关于 GAE 的直觉理解:同样,当 \(\lambda=0\) 时,GAE 退化为 1 步 TD;而 \(\lambda=1\) 时,GAE 回到蒙特卡洛估计。
11.2 异步优势演员-评论员(Asynchronous Advantage Actor-Critic,A3C)#
11.2.1 背景#
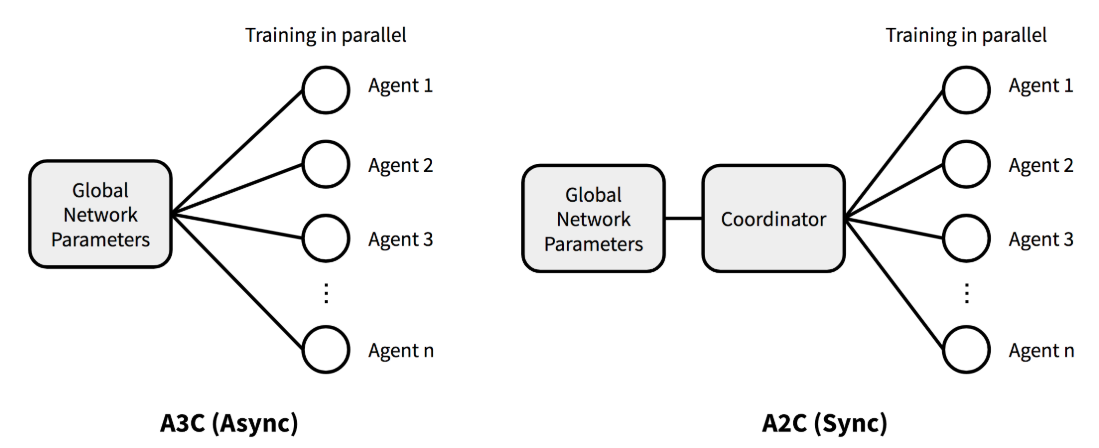
异步优势演员-评论家(Asynchronous Advantage Actor-Critic,A3C)是一种演员-评论家(Actor-Critic)算法,它通过多个工作线程(并行执行体)异步地探索环境并更新共享模型(在一台机器上使用多个 CPU 线程)。A3C 的作者将异步方法应用于四种已有的强化学习算法:一步 Q-learning、一步 Sarsa、n 步 Q-learning 和演员-评论员(Actor-Critic)。在这四种算法中,异步优势演员-评论员在当时的 Atari 游戏中实现了最先进的性能表现。
11.2.2 优势函数与梯度估计#
优势函数估计:A3C 中的优势函数按定义估计,但不使用蒙特卡洛回报,而是采用 \(n\) 步回报来计算 \(A(s_t, a_t; \theta, \theta_v)\)(符号记法不同于 11.1 节):
\[ A(s_t, a_t; \theta, \theta_v) = \sum_{i=0}^{k-1} \gamma^i r_{t+i} + \gamma^k V(s_{t+k}; \theta_v) - V(s_t; \theta_v) \]其中,\(\theta, \theta_v\) 分别表示演员和评论员模型的参数。步数 \(k\) 因状态而异,并受到上限 \(t_{max}\) 的约束。
优化目标:在估计出优势函数后,A3C 中策略模型的梯度按常规估计为:
\[\begin{split} \begin{align*} \hat{g} &= \nabla_{\theta'} \log \pi(a_t | s_t; \theta')A(s_t, a_t; \theta, \theta_v) \\ &=\nabla_{\theta'} \log \pi(a_t | s_t; \theta') (R_t - V(s_t; \theta_v)) \end{align*} \end{split}\]其中 \(R_t\) 是 \(n\) 步回报。
11.2.3 A3C 算法#
A3C 的伪代码:

演员 与 Critic 参数共享
在上述伪代码中,为了通用性展示了策略参数 \(\theta\) 与价值函数参数 \(\theta_v\) 是分开的,但在实际中我们通常会共享部分参数。
在 A3C 的论文中,作者指出他们通常使用一个卷积神经网络,该网络有一个 softmax 输出用于策略 \(\pi(a_t|s_t; \theta)\),一个线性输出用于价值函数 \(V(s_t; \theta_v)\),而所有非输出层是共享的。
熵奖励
在目标函数中加入策略 \(\pi\) 的熵项可以提升探索能力,防止过早收敛到次优的确定性策略。
加入熵奖励 / 正则化后,对策略参数的完整目标函数的梯度形式为:
\[ \nabla_{\theta'} \log \pi(a_t | s_t; \theta') (R_t - V(s_t; \theta_v)) + \beta \nabla_{\theta'} H(\pi(s_t; \theta')) \]其中 \(H\) 表示熵,超参数 \(\beta\) 控制熵正则项的强度。
11.2.4 A3C 的特性#
优点
多线程计算:A3C首次将强化学习算法的计算从多台独立机器和多个GPU,转移到单台机器的多个CPU线程上,并在性能上超越了其前身算法。
训练速度:训练时间的减少大致与并行actor-learner(演员-学习者)的数量成线性关系。
稳定训练过程:可以在每个actor-learner中显式使用不同的探索策略以最大化多样性。多个actor-learner并行在线更新参数时整体更不易时间相关,从而有助于训练过程的稳定。
缺点:
可能收敛于局部最优:A3C中每个agent(智能体)独立与全局参数通信,可能导致线程内agent使用的是不同版本的策略,从而使得聚合更新并非最优。
调试复杂:A3C的异步特性增加了调试和分析的难度。由于多个worker(工作线程)独立更新全局网络,训练过程中错误或不一致的来源难以追踪。
11.3 优势演员-评论员(Advantage Actor-Critic,A2C)#
11.3.1 背景#
优势演员-评论员(Advantage Actor-Critic,A2C)是异步优势演员-评论员(A3C)的简化版本,目前并没有正式的发表文献系统介绍该方法。此处我们简要概述A2C的核心思想,并引导感兴趣的读者参考本教程的相关章节了解更详细的技术内容。
在A3C中,每个worker(工作线程)拥有自己的环境副本并独立更新共享的全局参数,这种机制引入了异步性。然而OpenAI的研究人员发现,并没有证据表明异步机制带来性能提升。相反,如果在每个演员完成其经验片段后再统一更新,并在多个演员之间进行平均,可以简化调试过程并更有效地利用GPU。
去除异步机制后,所得方法自然被称为优势演员-评论员(A2C)。接下来我们深入探讨其核心思想。
11.3.2 A2C 的核心思想#
梯度更新
除了去除异步性外,A2C中的梯度更新形式与A3C完全相同。为解决A3C中梯度更新不一致的问题,A2C中一个协调器等待所有并行演员完成工作后再统一更新全局参数。这样下一轮所有演员从同一策略开始执行。同步的梯度更新使训练更加一致,并可能加速收敛。
算法
实际上,当使用并行 演员 时,第 10 章 第 10.5.1 节 中介绍的一步演员–评论员算法就是 A2C 的一个典型例子,其优势函数通过一步 TD 误差估计。
为了以类似于 11.2节更实用的方式介绍 A2C 算法,我们采用 这篇发表在 Nature 上的论文 中给出的伪代码如下:

注意上述所示的 \(E\) 个 episode(回合)在实际实现中会被多个演员并行运行。
11.3.3 A2C 的特性#
优点
在单 GPU 机器上,A2C 比 A3C 性价比更高;当策略模型较大时,A2C 的速度也优于纯 CPU 实现的 A3C。
该方法的一大优势是能更高效地利用 GPU,尤其适合大批量数据的并行加速处理。
缺点
由于依赖梯度下降(Gradient Descent),A2C 在训练过程中可能出现不稳定和收敛问题,容易导致参数更新过快或不可预测,从而引发震荡、发散或性能下降。梯度裁剪(gradient clipping)和信赖域技术(trust region)等方法有助于实现更平滑、可靠的训练过程。
Note
一些研究者认为 A2C 是 Proximal Policy Optimization(PPO)的一个特例,我们将在下一节介绍 PPO。
11.4 近端策略优化(Proximal Policy Optimization,PPO)#
11.4.1 背景#
在所有现代强化学习算法中,近端策略优化(Proximal Policy Optimization,PPO)是最具影响力的框架之一。PPO基于信任区域策略优化(Trust Region Policy Optimization,TRPO)改进而来,相比TRPO,PPO实现更加简单,且在经验上表现不逊色甚至优于TRPO。本节仅通过简要介绍TRPO的核心思想来铺垫PPO的背景。
在引入优势函数的前提下,所有策略梯度方法的梯度估计器(即最大化目标)可统一表示为:
TRPO 采用如下的最大化目标:
其中 \(\theta_{old}\) 表示更新前的策略参数。
Note
TRPO 背后的理论建议使用惩罚项代替约束条件,即解决一个无约束的最优化问题,在参数 \(\theta\) 上最大化:
TRPO 实际使用了硬约束而不是惩罚项,这是因为很难选取一个在不同问题间(甚至在同一个问题中)都表现良好的惩罚系数 \(\beta\)。
11.4.2 近端策略优化的目标函数#
我们已经看到,TRPO最大化如下形式的”代理”目标函数:
其中\(r_t(\theta)\)表示概率比率\(\frac{\pi_\theta(a_t | s_t)}{\pi_{\theta_{\text{old}}}(a_t | s_t)}\)(\(r(\theta_{\text{old}}) = 1\))。\(CPI\)指的是保守策略迭代(conservative policy iteration)。PPO不再使用KL散度,而是通过引入\(\textit{截断代理目标}\)来限制策略变动幅度,使\(r_t(\theta)\)不会偏离1过多。具体来说,PPO 的优化目标由三个部分组成:
截断代理目标(Clipped Surrogate Objective):通过将 \(r_t(θ)\) 限制在给定的范围内,惩罚那些使 \(r_t(θ)\) 偏离 1 的策略变化:
\[ L^{CLIP}(\theta) \ \dot= \ \hat{\mathbb{E}}_t \left[ \min \left( r_t(\theta) \hat{A}_t, \, \text{clip}(r_t(\theta), 1 - \epsilon, 1 + \epsilon) \hat{A}_t \right) \right], \]其中 epsilon 是用于控制截断范围的超参数。
价值函数损失(Value Function Loss):记作 \(L_t^{VF}(\theta)\),它是一个平方误差损失,形式如下:
\[ L_t^{VF}(\theta) \dot= (V_\theta(s_t) - V_t^{targ})^2 \]熵奖励(Entropy Bonus):PPO 在目标中加入熵奖励 \(S[\pi_\theta](s_t)\),表示为:
\[ S[\pi_\theta](s_t) = − \sum_a \pi(a_t \vert s_t) \log \pi(a_t \vert s_t) \]由于 PPO 使用梯度上升(Gradient Ascent),加入熵项鼓励智能体在最优动作上保持一定的不确定性(更高的熵意味着更高的不确定性),从而在训练中探索更广泛的动作空间。
如果策略过于确定(即总是选择相同的动作),熵值将降低,智能体将被激励去探索更多样的动作,这在训练早期尤为重要。
最终 PPO 目标函数:假设我们使用的神经网络结构在策略与价值函数之间共享参数,那么损失函数需将策略代理目标与价值函数误差项结合起来。再加入熵奖励以确保足够的探索,最终的 PPO 目标定义如下:
\[ L_t^{CLIP+VF+S}(\theta) = \hat{\mathbb{E}}_t \left[ L_t^{CLIP}(\theta) - c_1 L_t^{VF}(\theta) + c_2 S[\pi_\theta](s_t) \right], \]其中 \(c_1\), \(c_2\) 为正的系数。注意 \(L_t^{VF}(\theta)\) 是一个负项,因此在最大化整体目标时,相当于最小化平方误差损失。
11.4.3 PPO 算法#
伪代码

每次迭代中,\(N\)个(并行)演员各自收集\(T\)步的数据。然后我们基于这些\(N \times T\)的数据构造代理损失,并用小批量随机梯度下降(SGD)优化\(K\)轮。
算法细节
优势函数估计:如你在伪代码中可能已注意到,PPO 使用截断版本的广义优势估计。
一种由 A3C 论文 推广的策略梯度实现方式是让策略运行 \(T\) 步(\(T\) 通常远小于一个完整回合的长度)。这种方法需要不会超出第 \(T\) 步的优势估计器:
\[ \hat{A}_t = -V(s_t) + r_t + \gamma r_{t+1} + \cdots + \gamma^{T - t + 1} r_{T - 1} + \gamma^{T - t} V(s_T). \]对该方法的推广是,PPO 使用截断版本的广义优势估计,当 \(\lambda = 1\) 时退化为上述形式:
\[\begin{split} \begin{align*} \hat{A}_t &= \delta_t + (\gamma \lambda) \delta_{t+1} + \cdots + (\gamma \lambda)^{T - t + 1} \delta_{T - 1} \\ &= \delta_t + \gamma\lambda\hat{A}_{t+1}, \end{align*} \end{split}\]实际中的梯度上升
实际中,演员和评论家模型的更新是分开的。策略模型的梯度(上升)估计器如下:
\[ \hat{g}_{actor} = \frac{1}{NT}\sum_{n=0}^{N} \sum_{t=0}^{T} [\min ( r_t(\theta) \hat{A}_t, \ \text{clip}(r_t(\theta), 1 - \epsilon, 1 + \epsilon) \hat{A}_t) + S[\pi_\theta](s_0)] \]而价值函数的梯度(下降)估计器为:
\[ \hat{g}_{critic} = \frac{1}{NT}\sum_{n=0}^{N} \sum_{t=0}^{T}L_t^{VF}(\theta), \]适用于任意形式的价值函数损失。
11.4.4 PPO 的性质#
优点:
学习稳定:PPO 使用截断目标函数限制每次更新时策略的变化幅度,防止过大、不稳定的更新导致训练不稳定。
实现简单:与 TRPO 等更复杂的方法相比,PPO 实现相对简单,同时在多种任务中仍能达到具有竞争力的性能。
缺点:
对超参数敏感:PPO 对超参数(如截断参数和学习率)非常敏感,需要仔细调参以达到最优性能,这通常需要实验和对具体问题设置的理解。
计算开销大:PPO 的计算开销较高,特别是在分布式设置或大规模环境中,因为它在每次更新前依赖于收集数据批次,并且需要同时更新演员和评论家模型。
11.5 群体相对策略优化(Group-based Relative Policy Optimization,GRPO)#
11.5.1 背景#
与前面介绍的所有算法不同,群体相对策略优化(GRPO)是专为一种特定的强化学习任务提出的——大型语言模型(LLMs)的后训练。目前它在其他类型任务中的效果研究较少,因此我们主要在 LLM 训练背景下介绍 GRPO。
在 GRPO 提出之前,用于 LLM 训练的默认算法是 PPO,并配有一个特定的改动——在奖励中加入来自参考模型的 KL 惩罚项,以防止策略在更新过程中偏离参考模型太远。奖励计算方式如下:
其中 \(r_\phi\) 是奖励模型,参考模型 \(\pi_{ref}\) 是策略的一个冻结副本(不可训练)。
在 LLM 训练中,评论家模型通常与策略模型规模相当(共享部分参数)。为降低计算负担,GRPO 不再需要额外的价值函数逼近,而是使用多个采样输出的平均奖励作为基线(在优势估计中说明)。具体流程如下图所示。
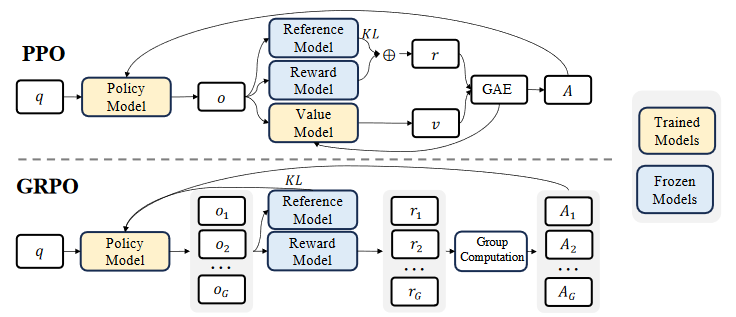
简而言之,GRPO 不需要评论员模型,采用群体平均奖励作为基线,优势值也通过该群体方法进行估计(后文介绍)。
Note
在 LLM 训练中的记号说明:
\(q\):输入给 LLM 的问题。
\(o_i\):时间步 \(t\) 的观测(状态)\(i\),通常为 \(q\) 与到 \(t\) 为止所有已生成内容的拼接。
\(r_i\):奖励模型 \(\phi\) 基于 \(o_i\) 给出的奖励。
\(A_i\):在时间步 \(t\) 计算得到的优势。
11.5.2 优化目标#
总体目标
\[\begin{split} \begin{align*} \mathcal{J}_{GRPO}(\theta) &= \mathbb{E}_{q \sim P(Q), \{o_i\}_{i=1}^G \sim \pi_{\theta_{old}}(O|q)} \left[\frac{1}{G} \sum_{i=1}^G \frac{1}{|o_i|} \sum_{t=1}^{|o_i|} \min \left( \frac{\pi_{\theta}(o_{i,t}|q, o_i,<t)}{\pi_{\theta_{old}}(o_{i,t}|q, o_i,<t)} \hat{A}_{i,t}, \, \text{clip} \left( \frac{\pi_{\theta}(o_{i,t}|q, o_i,<t)}{\pi_{\theta_{old}}(o_{i,t}|q, o_i,<t)}, 1 - \epsilon, 1 + \epsilon \right) \hat{A}_{i,t} \right) - \beta D_{KL}[\pi_{\theta_{old}} || \pi_{ref}] \right] \\ &\text{with} \ \mathbb{D}_{KL} (\pi_{\theta} || \pi_{\text{ref}}) = \frac{\pi_{\text{ref}}(o_i|q)}{\pi_{\theta}(o_i|q)} - \log \frac{\pi_{\text{ref}}(o_i|q)}{\pi_{\theta}(o_i|q)} - 1 \end{align*} \end{split}\]与 PPO 相同,群体相对策略优化(GRPO)也采用截断目标函数,但不同的是,其目标函数中不包含熵奖励项。
还需注意,GRPO 并非在奖励中加入 KL 惩罚,而是通过直接在最大化目标中加入训练策略与参考策略之间的 KL 散度来实现正则化,从而避免了复杂化 \(A_{i,t}\) 的计算。
Note
注意到 GRPO 使用一种不同于本节开头所述 KL 估计的无偏估计方法来估计 KL 散度。
优势估计
由于 GRPO 不需要价值函数,它通过仅基于每个组内输出的相对奖励来计算优势 \(A_{i,t}\),方式如下:
\[ A_{i,t} = \frac{r_i - \text{mean}(\{r_1, r_2, \dots, r_G\})}{\text{std}(\{r_1, r_2, \dots, r_G\})} \]
11.5.3 GRPO 算法#
伪代码

上述群体相对策略优化(GRPO)算法 [参考 GRPO] 采用迭代方式,除常规计算所有必要组件外,还有两个主要点需注意:
奖励模型再训练:在迭代式 GRPO 中,作者基于策略模型的采样结果生成新的奖励模型训练集,并使用包含 10% 历史数据的重放机制持续训练旧的奖励模型。然后,将参考模型设置为策略模型,并用新奖励模型持续训练策略模型。
11.5.4 GRPO 的性质#
优点
降低计算负担:群体相对策略优化(GRPO)不再需要评论家模型,通过基于群体的采样减少内存占用和计算成本。
高效优势估计:通过比较同一输入的多个输出,GRPO 实现稳定且高效的优势估计。
保守的策略更新:GRPO 目标函数中的 KL 惩罚项确保策略更新更稳定、更保守。
缺点
奖励设计复杂:GRPO 需要精心设计奖励函数以准确反映输出质量,这具有挑战性。
依赖于群体大小:群体大小影响优势估计的准确性,群体过小信息不足,而群体过大会增加计算开销。
11.6 总结#
本章介绍了多种强化学习算法,重点阐述了它们的核心概念、优点与缺点。首先讨论了**优势(Advantage)**的概念,用于衡量在某一状态下某个动作相对于平均行为的好坏程度,有助于减少梯度估计的方差,从而使策略梯度方法的更新更稳定。优势可以通过 TD 误差、蒙特卡罗回报或广义优势估计(GAE)来估算,其中 GAE 在偏差与方差之间提供平滑权衡。
随后我们介绍了异步的**优势演员-评论家(A3C)**算法,它利用多个工作线程异步探索环境并更新共享模型。A3C 使用 n 步回报估计优势,并加入熵奖励以增强探索能力。虽然 A3C 利用多线程实现更快训练,但可能收敛于局部最优,且异步特性带来调试难度。
接着我们讨论了优势演员-评论家(A2C),它是 A3C 的同步变体,多个并行演员协同进行更新。这种方法在单 GPU 机器上更具性价比,并提高了 GPU 利用率,但由于依赖梯度下降,可能面临不稳定和收敛问题。
**近端策略优化(PPO)**在保持性能的同时简化了 TRPO,使用截断目标限制策略变化。PPO 结合了截断代理目标、价值函数损失和熵奖励,具有学习稳定、实现简单的优点,但需要仔细调参,且计算成本较高。
最后,**群体相对策略优化(GRPO)**主要用于大型语言模型(LLMs)的后训练,通过群体采样替代评论家模型,采用平均奖励作为基线,并加入 KL 惩罚以实现保守更新。GRPO 减轻了计算负担并高效估计优势,但高度依赖复杂的奖励设计和群体大小的合理设置。
资源#
参考文献#
[1] GAE paper: High-Dimensional Continuous Control Using Generalized Advantage Estimation
[2] A3C paper: Asynchronous Methods for Deep Reinforcement Learning
[3] Paper that proposed the Entropy Bonus: Function optimization using connectionist reinforcement learning algorithms
[4] A2C blog from OpenAI: https://openai.com/index/openai-baselines-acktr-a2c/
[5] PPO paper: Proximal Policy Optimization Algorithms
[6] GRPO paper: DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
[7] Lil’Llog which gives the graphical comparison between A3C and A2C: https://lilianweng.github.io/posts/2018-04-08-policy-gradient/#a2c
[8] Shulman’s blog that proposed the unbiased KL divergence estimator used in GRPO: http://joschu.net/blog/kl-approx.html
其他资源#
如果你对专门对 LLM 后训练开发的 RL 算法感兴趣,下面是一些建议参考的内容 (截止至该教程完成日,因此很遗憾以下参考不具有时效性):
RRHF: Rank Responses to Align Language Models with Human Feedback
RAFT: Reward rAnked FineTuning for Generative Foundation Model Alignment
Back to Basics: Revisiting REINFORCE Style Optimization for Learning from Human Feedback in LLMs
REINFORCE++: A Simple and Efficient Approach for Aligning Large Language Models