Chapter 4 Milvus的AI应用开发:基于BM25的混合搜索向量数据库开发实战
本章节将带大家一步一步的完成政务问答领域的向量+BM25混合搜索的demo,数据集已经处理好并且向量化完成。
Milvus版本:2.5.4 python版本:3.12.0
4.1 学习目标
- 理解单向量检索和BM25全文检索的优缺点
- 理解混合检索的实际意义与优势
- 跑通所有代码
4.2 总体流程
- 创建环境
- 创建虚拟环境,下载相关依赖,确认milvus版本,启动milvus,构建Schema与Collection
- 导入数据
- 下载数据集,运行代码导入数据
- 执行检索
- 执行单向量检索,BM25全文检索,混合检索
- 观察执行结果
- 总结
4.3 创建环境
- 首先创建虚拟环境,下载依赖
python -m venv venv
. venv/bin/activate
# 如果要退出虚拟环境
# deactivate
pip install -r requirement.txtrequirement.txt内容如下:
numpy==1.24.3
pandas==2.0.3
torch==2.0.1
pymilvus==2.5.4
modelscope==1.9.5
transformers==4.30.2
sentencepiece==0.1.99
openpyxl==3.1.2
setuptools==68.0.0
wheel==0.40.0- 本次使用的Milvus版本为2.5.x,首先启动Milvus(docker部署)以及Attu(用于查看数据)。等待全部准备完成后,运行以下代码,构建Schema与Collection
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Milvus集合Schema设计和创建脚本
支持向量相似度检索和BM25全文检索的混合搜索
"""
import json
from typing import Optional
from pymilvus import (
MilvusClient,
DataType,
Function,
FunctionType,
connections,
utility
)
class MilvusSchemaDesigner:
def __init__(self, uri: str = "http://127.0.0.1:19530", token: str = "root:Milvus"):
"""
初始化Milvus连接
Args:
uri: Milvus服务器URI
token: 认证token
"""
self.uri = uri
self.token = token
self.client = None
self.collection_name = "hybrid_search_collection"
def connect(self):
"""连接到Milvus服务器"""
try:
print(f"正在连接Milvus服务器: {self.uri}")
self.client = MilvusClient(
uri=self.uri,
token=self.token
)
print("✓ Milvus连接成功")
return True
except Exception as e:
print(f"✗ Milvus连接失败: {e}")
print("请确保:")
print("1. Milvus服务器正在运行")
print("2. URI和token配置正确")
print("3. 网络连接正常")
return False
def check_collection_exists(self) -> bool:
"""检查集合是否存在"""
try:
if utility.has_collection(self.collection_name):
print(f"集合 '{self.collection_name}' 已存在")
return True
else:
print(f"集合 '{self.collection_name}' 不存在,将创建新集合")
return False
except Exception as e:
print(f"检查集合时出错: {e}")
return False
def drop_existing_collection(self):
"""删除已存在的集合"""
try:
if self.check_collection_exists():
print(f"正在删除已存在的集合: {self.collection_name}")
self.client.drop_collection(collection_name=self.collection_name)
print(f"✓ 集合 '{self.collection_name}' 已删除")
except Exception as e:
print(f"删除集合时出错: {e}")
def create_hybrid_search_schema(self, vector_dimension: int = 768):
"""
创建支持混合搜索的Schema
Args:
vector_dimension: 向量维度
"""
print(f"向量维度: {vector_dimension}")
# 创建Schema
schema = self.client.create_schema(
auto_id=False, # 我们自己管理ID
enable_dynamic_field=True # 允许动态字段
)
# 2.1 添加基础字段
schema.add_field(field_name="id", datatype=DataType.VARCHAR, max_length=100, is_primary=True)
schema.add_field(field_name="embedding", datatype=DataType.FLOAT_VECTOR, dim=1024)
schema.add_field(
field_name="title",
datatype=DataType.VARCHAR,
max_length=512,
enable_analyzer=True,
analyzer_params={"tokenizer": "jieba"}
)
schema.add_field(
field_name="content",
datatype=DataType.VARCHAR,
max_length=65535,
enable_analyzer=True,
analyzer_params={"tokenizer": "jieba"}
)
# 2.3 添加稀疏向量字段 (用于存储 BM25 结果)
schema.add_field(field_name="title_sparse", datatype=DataType.SPARSE_FLOAT_VECTOR)
schema.add_field(field_name="content_sparse", datatype=DataType.SPARSE_FLOAT_VECTOR)
# 3. 定义 BM25 函数 (Function)
# 作用:告诉 Milvus 自动把 title/content 的文本转成稀疏向量
title_bm25_func = Function(
name="title_bm25_func",
input_field_names=["title"],
output_field_names=["title_sparse"],
function_type=FunctionType.BM25
)
content_bm25_func = Function(
name="content_bm25_func",
input_field_names=["content"],
output_field_names=["content_sparse"],
function_type=FunctionType.BM25
)
# 添加BM25函数到Schema
schema.add_function(title_bm25_func)
schema.add_function(content_bm25_func)
return schema
def create_collection_with_indexes(self, schema, vector_dimension: int = 768):
"""
创建集合并配置索引
Args:
schema: 集合Schema
vector_dimension: 向量维度
"""
print(f"\n创建集合并配置索引...")
# 创建集合
collection = self.client.create_collection(
collection_name=self.collection_name,
schema=schema
)
print(f"✓ 集合 '{self.collection_name}' 创建成功")
# 准备索引参数
index_params = self.client.prepare_index_params()
# 添加向量索引(使用IVF_FLAT)
index_params.add_index(
field_name="embedding",
index_type="FLAT",
metric_type="IP", # Inner Product (用于余弦相似度)
params={}
)
# TODO:这里有params参数,调研不同参数值下的效果
# params={
# "inverted_index_algo": "DAAT_MAXSCORE",
# "bm25_k1": 1.2,
# "bm25_b": 0.75
# }
# 为 content_sparse 创建倒排索引
index_params.add_index(
field_name="title_sparse",
index_type="SPARSE_INVERTED_INDEX",
metric_type="BM25",
index_name="title_sparse_index"
)
index_params.add_index(
field_name="content_sparse",
index_type="SPARSE_INVERTED_INDEX",
metric_type="BM25",
index_name="content_sparse_index"
)
# 创建索引
self.client.create_index(
collection_name=self.collection_name,
index_params=index_params
)
return collection
def load_collection(self):
"""加载集合到内存"""
try:
print(f"\n加载集合到内存...")
self.client.load_collection(collection_name=self.collection_name)
print(f"✓ 集合 '{self.collection_name}' 已加载到内存")
except Exception as e:
print(f"✗ 加载集合失败: {e}")
def create_collection(self, vector_dimension: int = 768, drop_existing: bool = False):
"""
完整的集合创建流程
Args:
vector_dimension: 向量维度
drop_existing: 是否删除已存在的集合
"""
print("=" * 60)
print("Milvus混合搜索集合创建向导")
print("=" * 60)
# 连接Milvus
if not self.connect():
return False
# 检查并处理已存在的集合
if self.check_collection_exists():
if drop_existing:
self.drop_existing_collection()
else:
print("集合已存在,使用drop_existing=True来删除并重建")
return False
# 创建Schema
schema = self.create_hybrid_search_schema(vector_dimension)
# 创建集合并配置索引
collection = self.create_collection_with_indexes(schema, vector_dimension)
# 加载集合
self.load_collection()
return True
def main():
# 从配置文件读取向量维度
vector_dimension = 1024
# 创建Schema设计器
schema_designer = MilvusSchemaDesigner()
try:
# 创建集合
success = schema_designer.create_collection(
vector_dimension=vector_dimension,
drop_existing=True # 删除已存在的集合
)
if success:
print("\n🎉 Milvus集合设置完成!")
else:
print("\n❌ Milvus集合设置失败!")
except Exception as e:
print(f"\n集合创建过程中出错: {e}")
import traceback
traceback.print_exc()
if __name__ == "__main__":
import os
main()4.4 导入数据
首先下载数据集:https://haluki.oss-cn-hangzhou.aliyuncs.com/code.zip
解压文件后可以看到三个json文件:
- vector_texts.json 用于向量化的原始文本json
{ "id": "doc_1_6b57413d", "vector_text": "你的浏览器不支持video新华网上海8月\n\n你的浏览器不支持video新华网上海8月27日电(有之炘佘灵)24日,......" }, - vectors.json 向量化后的文本,根据id与原始的文本对应json
{ "id" : "doc_10000_8efdf098", "embedding" : [ 0.0038397987, 0.015784778, 0.01619642, -0.076500155, -0.033315383, -0.045836534, -0.012616322, ...... ], "vector_norm" : 0.9999999875290796 }, - quest.json 同于搜索的问题集合json
{ "title": "根据国务院常务会议新闻稿内容生成的100条相关问题", "sections": [ { "section_title": "关于全国统一大市场建设", "questions_count": 35, "questions": [ "建设全国统一大市场的核心目标是什么?", "市场分割和地方保护有哪些典型表现形式?" ... ] } ], }
数据导入代码用于将预处理好的政务问答数据批量插入到Milvus集合中。以下是数据导入的Python实现:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
数据批量导入到Milvus的脚本
将处理后的文本数据和向量数据导入Milvus集合
"""
import json
import os
import time
from typing import List, Dict, Any, Tuple
from pymilvus import MilvusClient
class DataImporter:
def __init__(self, uri: str = "http://localhost:19530", token: str = "root:Milvus"):
"""
初始化数据导入器
Args:
uri: Milvus服务器URI
token: 认证token
"""
self.uri = uri
self.token = token
self.client = None
self.collection_name = "hybrid_search_collection"
def connect(self) -> bool:
"""连接到Milvus服务器"""
try:
print(f"正在连接Milvus服务器: {self.uri}")
self.client = MilvusClient(
uri=self.uri,
token=self.token
)
print("✓ Milvus连接成功")
return True
except Exception as e:
print(f"✗ Milvus连接失败: {e}")
return False
def check_collection_exists(self) -> bool:
"""检查集合是否存在"""
try:
if self.client.has_collection(collection_name=self.collection_name):
print(f"✓ 找到集合: {self.collection_name}")
return True
else:
print(f"✗ 集合不存在: {self.collection_name}")
print("请先运行 milvus_setup.py 创建集合")
return False
except Exception as e:
print(f"检查集合时出错: {e}")
return False
def load_data_files(self, processed_data_path: str, vectors_path: str) -> Tuple[List[Dict], List[Dict]]:
"""
加载数据文件
Args:
processed_data_path: 处理后的文本数据文件路径
vectors_path: 向量数据文件路径
Returns:
(文本数据, 向量数据)
"""
print(f"\n加载数据文件...")
# 加载处理后的文本数据
try:
with open(processed_data_path, 'r', encoding='utf-8') as f:
processed_data = json.load(f)
print(f"✓ 已加载文本数据: {len(processed_data)} 条记录")
except Exception as e:
raise Exception(f"加载文本数据失败: {e}")
# 加载向量数据
try:
with open(vectors_path, 'r', encoding='utf-8') as f:
vectors_data = json.load(f)
print(f"✓ 已加载向量数据: {len(vectors_data)} 条记录")
except Exception as e:
raise Exception(f"加载向量数据失败: {e}")
# 验证数据一致性
if len(processed_data) != len(vectors_data):
raise Exception(
f"数据不一致: 文本数据 {len(processed_data)} 条, "
f"向量数据 {len(vectors_data)} 条"
)
return processed_data, vectors_data
def merge_data(self, processed_data: List[Dict], vectors_data: List[Dict]) -> List[Dict]:
"""
合并文本数据和向量数据
Args:
processed_data: 处理后的文本数据
vectors_data: 向量数据
Returns:
合并后的数据
"""
print(f"\n合并数据...")
# 创建ID到向量的映射
vector_map = {}
for item in vectors_data:
if 'id' in item and 'embedding' in item:
vector_map[item['id']] = item['embedding']
merged_data = []
missing_vectors = []
for text_item in processed_data:
doc_id = text_item['id']
if doc_id in vector_map:
merged_item = {
'id': doc_id,
'title': text_item.get('title', ''),
'content': text_item.get('content', ''),
'embedding': vector_map[doc_id]
}
merged_data.append(merged_item)
else:
missing_vectors.append(doc_id)
if missing_vectors:
print(f"⚠ 警告: {len(missing_vectors)} 条记录缺少向量数据")
print(f"示例缺失ID: {missing_vectors[:3]}")
print(f"✓ 成功合并 {len(merged_data)} 条记录")
return merged_data
def validate_data(self, data: List[Dict]) -> bool:
"""
验证数据格式
Args:
data: 待验证的数据
Returns:
验证结果
"""
print(f"\n验证数据格式...")
if not data:
print("✗ 数据为空")
return False
required_fields = ['id', 'title', 'content', 'embedding']
errors = []
for i, item in enumerate(data[:5]): # 只检查前5条
for field in required_fields:
if field not in item:
errors.append(f"记录 {i+1}: 缺少字段 '{field}'")
# 检查向量格式
if 'embedding' in item:
embedding = item['embedding']
if not isinstance(embedding, list) or len(embedding) == 0:
errors.append(f"记录 {i+1}: 向量格式错误")
if errors:
print("✗ 数据验证失败:")
for error in errors:
print(f" - {error}")
return False
else:
print(f"✓ 数据验证通过 ({len(data)} 条记录)")
return True
def batch_import(self, data: List[Dict], batch_size: int = 100) -> bool:
"""
批量导入数据
Args:
data: 待导入的数据
batch_size: 批处理大小
Returns:
导入结果
"""
print(f"\n开始批量导入数据...")
print(f"总记录数: {len(data)}")
print(f"批处理大小: {batch_size}")
print(f"总批次数: {(len(data) + batch_size - 1) // batch_size}")
successful_imports = 0
failed_batches = []
start_time = time.time()
for i in range(0, len(data), batch_size):
batch_data = data[i:i + batch_size]
batch_num = i // batch_size + 1
total_batches = (len(data) + batch_size - 1) // batch_size
print(f"\n处理批次 {batch_num}/{total_batches} ({len(batch_data)} 条记录)")
try:
# 准备批处理数据 - 使用字典列表格式
batch_insert_data = []
for item in batch_data:
batch_insert_data.append({
'id': item['id'],
'title': item['title'],
'content': item['content'],
'embedding': item['embedding']
})
# 插入数据 - 使用推荐的格式
insert_result = self.client.insert(
collection_name=self.collection_name,
data=batch_insert_data
)
successful_imports += len(batch_data)
print(f"✓ 批次 {batch_num} 导入成功")
# 显示进度
progress = (i + len(batch_data)) / len(data) * 100
print(f"进度: {progress:.1f}% ({i + len(batch_data)}/{len(data)})")
except Exception as e:
print(f"✗ 批次 {batch_num} 导入失败: {e}")
failed_batches.append((batch_num, str(e)))
# 记录失败的数据
print(f"失败批次数据示例:")
for j, item in enumerate(batch_data[:2]):
print(f" {j+1}. ID: {item.get('id', 'N/A')}, 标题: {item.get('title', 'N/A')[:30]}...")
total_time = time.time() - start_time
# 导入结果统计
print(f"\n" + "=" * 60)
print("批量导入完成!")
print(f"总耗时: {total_time:.2f}秒")
print(f"成功导入: {successful_imports} 条记录")
print(f"失败批次: {len(failed_batches)} 个")
print(f"平均速度: {successful_imports/total_time:.1f} 记录/秒")
if failed_batches:
print(f"\n失败批次详情:")
for batch_num, error in failed_batches:
print(f" 批次 {batch_num}: {error}")
# 刷新数据到磁盘
try:
print(f"\n刷新数据到磁盘...")
self.client.flush(collection_name=self.collection_name)
print("✓ 数据刷新完成")
except Exception as e:
print(f"⚠ 数据刷新失败: {e}")
return len(failed_batches) == 0
def get_collection_stats(self):
"""获取集合统计信息"""
try:
print(f"\n集合统计信息:")
print("-" * 40)
stats = self.client.get_collection_stats(collection_name=self.collection_name)
print(f"总记录数: {stats.get('row_count', 'N/A')}")
# 显示字段统计
if 'entities' in stats:
for field_name, field_stats in stats['entities'].items():
print(f"{field_name}: {field_stats}")
except Exception as e:
print(f"获取统计信息失败: {e}")
def import_data(self, processed_data_path: str, vectors_path: str, batch_size: int = 100):
"""
完整的数据导入流程
Args:
processed_data_path: 处理后的文本数据文件路径
vectors_path: 向量数据文件路径
batch_size: 批处理大小
"""
print("=" * 60)
print("Milvus数据导入向导")
print("=" * 60)
# 连接Milvus
if not self.connect():
return False
# 检查集合是否存在
if not self.check_collection_exists():
return False
# 检查输入文件
if not os.path.exists(processed_data_path):
print(f"✗ 文本数据文件不存在: {processed_data_path}")
return False
if not os.path.exists(vectors_path):
print(f"✗ 向量数据文件不存在: {vectors_path}")
return False
try:
# 加载数据文件
processed_data, vectors_data = self.load_data_files(processed_data_path, vectors_path)
# 合并数据
merged_data = self.merge_data(processed_data, vectors_data)
# 验证数据
if not self.validate_data(merged_data):
return False
# 批量导入
success = self.batch_import(merged_data, batch_size)
# 获取统计信息
self.get_collection_stats()
return success
except Exception as e:
print(f"\n数据导入过程中出错: {e}")
import traceback
traceback.print_exc()
return False
def main():
# 配置文件路径
processed_data_path = "processed_data.json" # 来自数据预处理步骤
vectors_path = "vectors.json" # 来自向量生成步骤
# 创建数据导入器
importer = DataImporter()
# 导入数据
importer.import_data(
processed_data_path=processed_data_path,
vectors_path=vectors_path,
batch_size=50 # 调整批处理大小
)
if __name__ == "__main__":
main()代码说明:
- 数据加载:从JSON文件读取预处理好的政务问答数据,包含ID、标题、内容和向量字段
- 数据准备:验证数据完整性,确保每条记录都有对应的向量,并限制文本字段长度
- 批量插入:使用分批插入策略(默认每批100条),避免单次插入数据量过大导致内存溢出
- 数据刷新:调用
flush()操作确保数据持久化到磁盘 - 统计信息:显示导入的文档总数和性能指标
注意事项:
- 向量维度必须与Schema定义一致(768或1024维)
- 超长文本会被截断以符合Schema定义的max_length
- BM25函数会在数据插入时自动生成稀疏向量,无需手动计算
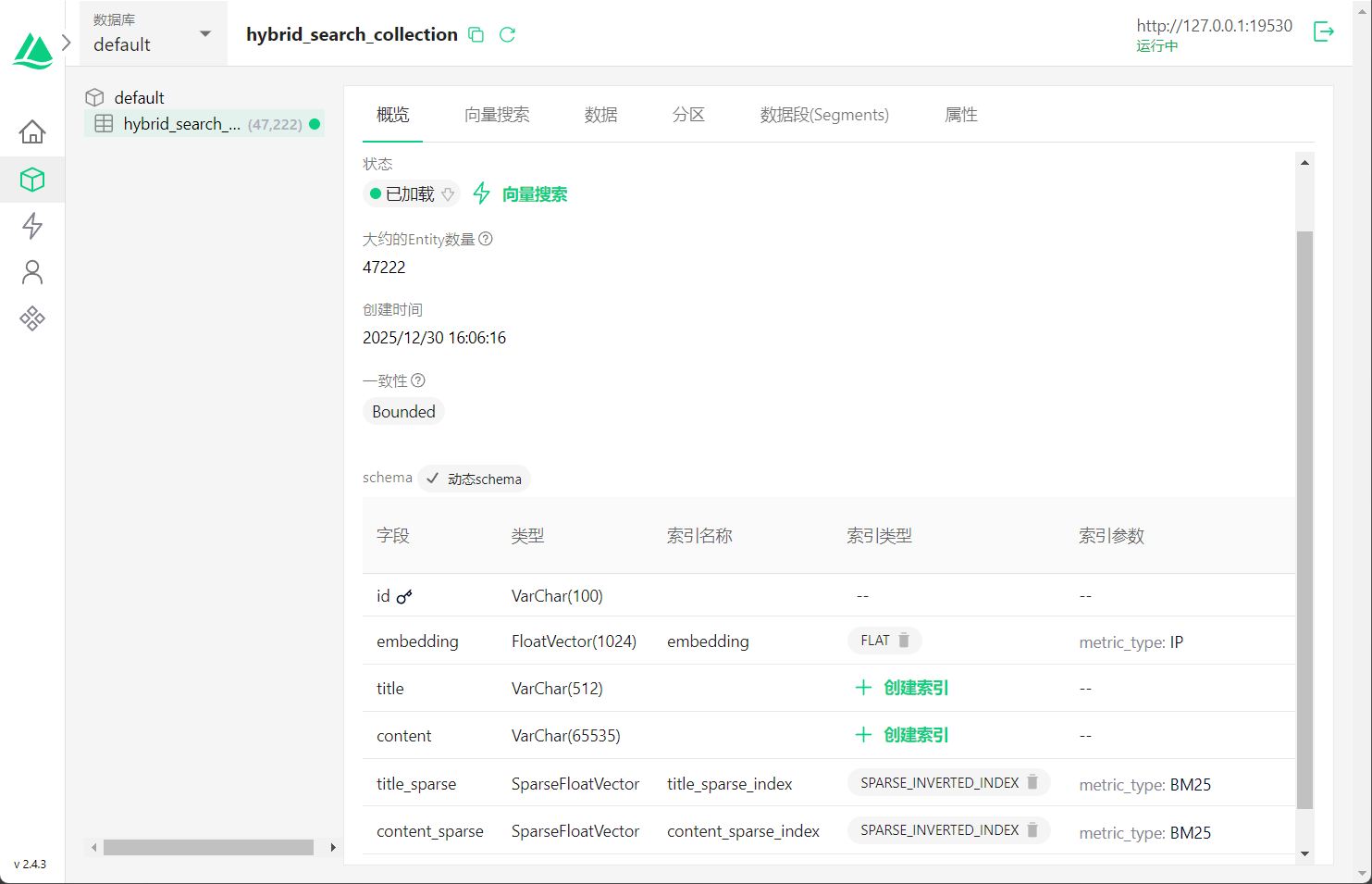
数据导入之后,进入Attu的概览界面,观察Schema格式和数据量
数据导入注意事项:
由于字段长度的限制,部分超长文本(超过8000字)可能被截断,导致实际导入的数据量与原始JSON文件的数据量略有差异。这是正常的,因为:
title字段最大长度为512字符content字段最大长度为65535字符
Attu界面观察:
数据导入完成后,可以通过Attu界面观察Schema格式和数据量:
从界面中可以清楚看到Schema的结构:
- embedding:采用FLAT索引的稠密向量字段,用于语义检索
- title/content:原始文本数据字段
- title_sparse/content_sparse:BM25生成的稀疏向量字段,用于全文检索
由于我们在Schema中预定义了BM25 Function,当查询时输入的文本会自动转换为稀疏向量进行BM25检索,无需手动计算。
查看数据的方法:
点击Attu的"数据"页面,可能会遇到以下情况:
直接查看数据报错:由于BM25稀疏向量字段的存在,Attu默认禁止直接显示包含稀疏向量的数据

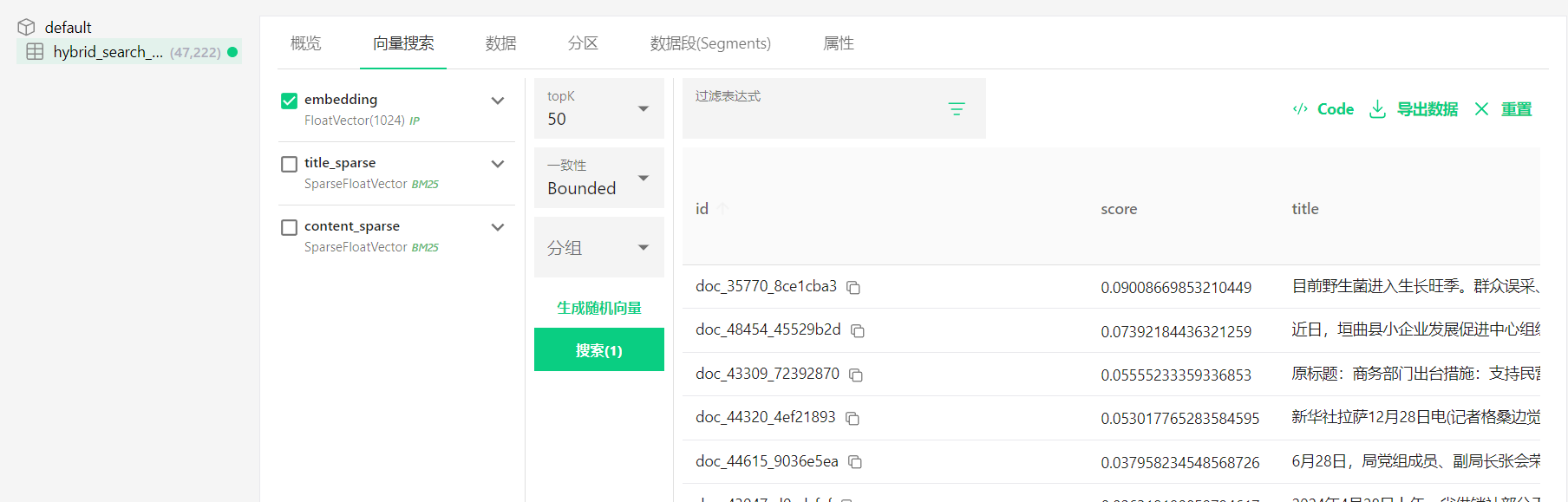
通过向量搜索查看数据:
- 进入"向量搜索"页面
- 勾选
embedding字段 - 点击"生成随机向量"
- 执行搜索即可看到数据内容
注意事项:
- 如果同时勾选
title_sparse和content_sparse字段并执行搜索,可能会出现错误 - 这是Attu对稀疏向量支持的已知限制
- 建议通过我们的检索代码来验证BM25搜索功能
- 如果同时勾选
4.5 执行检索
当我们确定数据已经存储好,并且Schema字段无误后,可以执行检索代码。这段代码将分别进行单向量检索、BM25检索、混合检索,并输出检索结果、性能对比等分析数据。
4.5.1 向量生成方法
在执行检索之前,需要实现generate_embedding方法,用于将查询文本转换为向量。以下是几种常见的实现方式:
方式1:使用ModelScope模型(本地推理)
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
def generate_embedding(self, texts: List[str]) -> List[List[float]]:
"""
使用ModelScope模型生成文本向量
Args:
texts: 待向量化的文本列表
Returns:
向量列表,每个向量是1024维的float数组
"""
# 初始化pipeline(只需执行一次)
if not hasattr(self, 'embedding_pipeline'):
self.embedding_pipeline = pipeline(
task=Tasks.SENTENCE_EMBEDDING,
model='damo/nlp_corom_sentence-embedding_chinese-base'
)
# 批量生成向量
embeddings = self.embedding_pipeline(inputs=texts)
# 提取向量数据
result = []
for item in embeddings['text_embedding']:
result.append(item['embedding'].tolist())
return result方式2:使用API服务
import requests
def generate_embedding(self, texts: List[str]) -> List[List[float]]:
"""
调用向量化API服务生成文本向量
Args:
texts: 待向量化的文本列表
Returns:
向量列表,每个向量是1024维的float数组
"""
# API配置
api_url = "https://your-embedding-api.com/embeddings"
api_key = "your-api-key"
# 构建请求
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
data = {
"texts": texts,
"model": "embedding-model-name"
}
# 发送请求
response = requests.post(api_url, headers=headers, json=data)
response.raise_for_status()
# 解析结果
result = response.json()['embeddings']
return result方式3:使用Transformers库
from transformers import AutoTokenizer, AutoModel
import torch
def generate_embedding(self, texts: List[str]) -> List[List[float]]:
"""
使用Transformers模型生成文本向量
Args:
texts: 待向量化的文本列表
Returns:
向量列表
"""
# 初始化模型(只需执行一次)
if not hasattr(self, 'tokenizer'):
model_name = "shibing624/text2vec-base-chinese"
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
self.model = AutoModel.from_pretrained(model_name)
self.model.eval()
# Tokenize输入文本
encoded_input = self.tokenizer(
texts,
padding=True,
truncation=True,
max_length=512,
return_tensors='pt'
)
# 生成向量
with torch.no_grad():
model_output = self.model(**encoded_input)
# 使用[CLS] token的向量作为句子向量
embeddings = model_output.last_hidden_state[:, 0, :]
return embeddings.tolist()注意事项:
- 向量维度必须与Schema中定义的一致(768维或1024维)
- 建议在类初始化时加载模型,避免每次查询都重新加载
- 批量处理可以提高效率
- 生产环境建议使用API服务,避免本地GPU资源占用
下面是完整的检索代码实现:
import os
import json
import time
from datetime import datetime
from typing import List, Dict, Any
import requests
import psutil
from pymilvus import (
MilvusClient,
AnnSearchRequest,
WeightedRanker
)
class SearchDemo:
def __init__(self):
self.client = self.connect_to_milvus()
self.collection_name = "hybrid_search_collection"
def connect_to_milvus(self) -> MilvusClient:
return MilvusClient(uri="http://127.0.0.1:19530")
def generate_embedding(self, texts: List[str]) -> List[List[float]]:
pass
def vector_search(self, query_text: str, top_k: int) -> List[Dict[str, Any]]:
query_vectors = self.generate_embedding([query_text])
res = self.client.search(
collection_name=self.collection_name,
data=query_vectors,
anns_field="embedding",
search_params={"metric_type": "IP", "params": {"nprobe": 16}},
limit=top_k,
output_fields=["id", "title", "content"]
)
results = []
for hits in res:
for hit in hits:
results.append({
"id": hit["id"],
"title": hit["entity"].get("title"),
"content": hit["entity"].get("content"),
"score": hit["score"],
"search_type": "vector"
})
return results
def bm25_search(self, query_text: str, top_k: int) -> List[Dict[str, Any]]:
res = self.client.search(
collection_name=self.collection_name,
data=[query_text],
anns_field="content_sparse",
search_params={"metric_type": "BM25", "params": {}},
limit=top_k,
output_fields=["id", "title", "content"]
)
results = []
for hits in res:
for hit in hits:
results.append({
"id": hit["id"],
"title": hit["entity"].get("title"),
"content": hit["entity"].get("content"),
"score": hit["score"],
"search_type": "bm25"
})
return results
def hybrid_search(self, query_text: str, vector_weight: float, bm25_weight: float, top_k: int) -> List[Dict[str, Any]]:
query_vectors = self.generate_embedding([query_text])
dense_req = AnnSearchRequest(
data=query_vectors,
anns_field="embedding",
param={"metric_type": "IP", "params": {"nprobe": 16}},
limit=top_k
)
bm25_req = AnnSearchRequest(
data=[query_text],
anns_field="content_sparse",
param={"metric_type": "BM25", "params": {}},
limit=top_k
)
ranker = WeightedRanker(vector_weight, bm25_weight)
res = self.client.hybrid_search(
collection_name=self.collection_name,
reqs=[dense_req, bm25_req],
ranker=ranker,
limit=top_k,
output_fields=["id", "title", "content"]
)
results = []
for hits in res:
for hit in hits:
results.append({
"id": hit["id"],
"title": hit["entity"].get("title"),
"content": hit["entity"].get("content"),
"score": hit["score"],
"search_type": "hybrid"
})
return results
def close(self):
self.client.close()
class ResourceUsage:
def __init__(self, memory_used, memory_total, disk_free, disk_total):
self.memory_used = memory_used
self.memory_total = memory_total
self.disk_free = disk_free
self.disk_total = disk_total
def get_current_resource_usage() -> ResourceUsage:
"""获取当前系统资源"""
mem = psutil.virtual_memory()
process = psutil.Process(os.getpid())
used_memory = process.memory_info().rss / (1024 * 1024)
total_memory = mem.total / (1024 * 1024)
disk_path = 'C:' if os.name == 'nt' else '/'
try:
disk = psutil.disk_usage(disk_path)
free_disk = disk.free / (1024 * 1024 * 1024)
total_disk = disk.total / (1024 * 1024 * 1024)
except:
free_disk = 0
total_disk = 0
return ResourceUsage(used_memory, total_memory, free_disk, total_disk)
def escape_markdown(text: str) -> str:
if not text:
return ""
chars = ['|', '*', '_', '#', '`', '[', ']', '(', ')', '<', '>']
for char in chars:
text = text.replace(char, f"\\{char}")
return text
def generate_markdown_report(all_results: List[Dict], initial_res: ResourceUsage, final_res: ResourceUsage):
lines = []
lines.append("# 搜索性能对比报告\n")
lines.append(f"生成时间: {datetime.now()}\n")
lines.append(f"总查询数: {len(all_results)}\n")
lines.append("## 一、系统资源使用情况 (客户端)\n")
lines.append("### 1.1 内存使用情况\n")
mem_delta = final_res.memory_used - initial_res.memory_used
lines.append("| 指标 | 初始状态 (MB) | 最终状态 (MB) | 变化量 (MB) |")
lines.append("|------|-------------|-------------|-----------|")
lines.append(f"| 已用内存 | {initial_res.memory_used:.2f} | {final_res.memory_used:.2f} | {mem_delta:+.2f} |")
lines.append(f"| 总内存 | {initial_res.memory_total:.0f} | {final_res.memory_total:.0f} | - |\n")
lines.append("### 1.2 磁盘使用情况\n")
disk_delta = final_res.disk_free - initial_res.disk_free
lines.append("| 指标 | 初始状态 (GB) | 最终状态 (GB) | 变化量 (GB) |")
lines.append("|------|-------------|-------------|-----------|")
lines.append(f"| 可用空间 | {initial_res.disk_free:.2f} | {final_res.disk_free:.2f} | {disk_delta:+.2f} |")
lines.append(f"| 总容量 | {initial_res.disk_total:.2f} | {final_res.disk_total:.2f} | - |\n")
lines.append("### 1.3 理论资源占用对比 (服务端)\n")
lines.append("| 检索方式 | 特点 | 内存占用 | 磁盘占用 |")
lines.append("|---------|------|---------|---------|")
lines.append("| **向量搜索** | 需加载向量索引 | 中等 | 高(向量数据) |")
lines.append("| **BM25搜索** | 倒排索引 | 较低 | 较低(稀疏向量) |")
lines.append("| **混合搜索** | 结合两者 | 较高 | 高(双索引) |\n")
lines.append("## 二、总体性能统计\n")
total_vector_time = sum(r['vector_time'] for r in all_results)
total_bm25_time = sum(r['bm25_time'] for r in all_results)
total_hybrid_time = sum(r['hybrid_time'] for r in all_results)
total_overall_time = sum(r['total_time'] for r in all_results)
count = len(all_results)
avg_vec = total_vector_time / count if count else 0
avg_bm25 = total_bm25_time / count if count else 0
avg_hybrid = total_hybrid_time / count if count else 0
avg_total = total_overall_time / count if count else 0
lines.append("### 2.1 性能汇总\n")
lines.append("| 搜索方式 | 总耗时(ms) | 平均耗时(ms) | 相对速度 |")
lines.append("|---------|-----------|-------------|----------|")
lines.append(f"| 向量搜索 | {total_vector_time:.0f} | {avg_vec:.2f} | 基准 |")
bm25_speedup = avg_vec / avg_bm25 if avg_bm25 > 0 else 0
lines.append(f"| BM25搜索 | {total_bm25_time:.0f} | {avg_bm25:.2f} | {bm25_speedup:.2f}x |")
hybrid_speedup = avg_vec / avg_hybrid if avg_hybrid > 0 else 0
lines.append(f"| 混合搜索 | {total_hybrid_time:.0f} | {avg_hybrid:.2f} | {hybrid_speedup:.2f}x |")
lines.append(f"| 总计 | {total_overall_time:.0f} | {avg_total:.2f} | - |\n")
lines.append("## 三、搜索结果对比\n")
for r in all_results:
lines.append(f"### {r['query_index']}. 查询: {escape_markdown(r['query_text'])}\n")
lines.append(f"- 向量结果数: **{r['vector_count']}** | BM25结果数: **{r['bm25_count']}** | 混合结果数: **{r['hybrid_count']}**\n")
lines.append("| 排名 | 向量分数 | BM25分数 | 混合分数 | 向量内容 |")
lines.append("|------|---------|---------|---------|---------|")
max_rows = min(5, max(len(r['vector_res']), len(r['bm25_res']), len(r['hybrid_res'])))
for i in range(max_rows):
v_item = r['vector_res'][i] if i < len(r['vector_res']) else {}
b_item = r['bm25_res'][i] if i < len(r['bm25_res']) else {}
h_item = r['hybrid_res'][i] if i < len(r['hybrid_res']) else {}
v_s = f"{v_item.get('score', 0):.4f}" if v_item else "-"
b_s = f"{b_item.get('score', 0):.4f}" if b_item else "-"
h_s = f"{h_item.get('score', 0):.4f}" if h_item else "-"
content = str(v_item.get('content', '-'))
v_c = escape_markdown(content[:20] + "...") if len(content) > 20 else escape_markdown(content)
lines.append(f"| {i+1} | {v_s} | {b_s} | {h_s} | {v_c} |")
lines.append("\n")
lines.append("## 四、总结\n")
lines.append("### 4.1 资源占用说明\n")
lines.append("- 上述资源变化仅反映客户端脚本的开销,不代表 Milvus 数据库的实际负载。")
lines.append("- **真实情况**: 开启全文检索会增加约 5-15% 的磁盘占用(稀疏向量索引),对内存影响较小。\n")
lines.append("### 4.2 策略建议\n")
lines.append("- **资源充足**: 推荐混合检索。")
lines.append("- **资源受限**: 关键词查询用 BM25,语义查询用向量。")
with open("search_comparison_report.md", "w", encoding="utf-8") as f:
f.writelines([line + "\n" if not line.endswith("\n") else line for line in lines])
def main():
demo = SearchDemo()
all_query_results = []
initial_resource = get_current_resource_usage()
print("开始执行搜索测试...")
try:
json_path = os.path.join("src", "quest.json")
if not os.path.exists(json_path):
json_path = "quest.json"
if not os.path.exists(json_path):
print("Quest file not found, using dummy data.")
all_questions = ["test query 1", "test query 2"]
else:
with open(json_path, "r", encoding="utf-8") as f:
data = json.load(f)
all_questions = []
for section in data.get("sections", []):
for question in section.get("questions", []):
all_questions.append(question)
for idx, query_text in enumerate(all_questions, 1):
print(f"Processing query {idx}: {query_text}")
start_time = time.time() * 1000
# 向量搜索
v_start = time.time() * 1000
vec_res = demo.vector_search(query_text, 10)
v_time = (time.time() * 1000) - v_start
# BM25搜索
b_start = time.time() * 1000
bm25_res = demo.bm25_search(query_text, 10)
b_time = (time.time() * 1000) - b_start
# 混合搜索
h_start = time.time() * 1000
hybrid_res = demo.hybrid_search(query_text, 0.5, 0.5, 10)
h_time = (time.time() * 1000) - h_start
total_time = (time.time() * 1000) - start_time
all_query_results.append({
"query_text": query_text,
"query_index": idx,
"vector_time": v_time,
"bm25_time": b_time,
"hybrid_time": h_time,
"total_time": total_time,
"vector_count": len(vec_res),
"bm25_count": len(bm25_res),
"hybrid_count": len(hybrid_res),
"vector_res": vec_res,
"bm25_res": bm25_res,
"hybrid_res": hybrid_res
})
# 记录结束资源
final_resource = get_current_resource_usage()
generate_markdown_report(all_query_results, initial_resource, final_resource)
print("报告已生成: search_comparison_report.md")
except Exception as e:
print(f"Error during search: {e}")
import traceback
traceback.print_exc()
finally:
demo.close()
if __name__ == "__main__":
main()4.5.2 检索代码说明
上述Python检索代码实现了三种检索方式的性能对比测试,主要功能包括:
核心功能模块:
向量搜索(vector_search)
- 将查询文本转换为向量
- 使用内积(IP)度量计算相似度
- 返回最相似的top_k条记录
BM25全文搜索(bm25_search)
- 直接使用原始文本进行检索
- Milvus自动将文本转换为BM25稀疏向量
- 基于关键词匹配计算相关性分数
混合搜索(hybrid_search)
- 同时执行向量搜索和BM25搜索
- 使用加权策略融合两种结果(可配置权重)
- 综合语义相似度和关键词匹配度
性能监控:
- 记录每种搜索方式的响应时间
- 监控内存和磁盘资源使用情况
- 生成详细的性能对比报告
报告生成:
- 自动生成Markdown格式的对比报告
- 包含性能统计、结果对比、资源占用分析
- 输出文件:
search_comparison_report.md
4.5.3 Java版本实现
对于Java开发者,我们也提供了完整的Java实现版本。同样需要实现generateEmbedding方法来生成查询向量。
package com.czkj;
import com.google.gson.*;
import com.ilotterytech.dknow.llm.api.client.LLMClient;
import com.ilotterytech.dknow.llm.api.vo.EmbeddingStringResult;
import io.milvus.v2.client.ConnectConfig;
import io.milvus.v2.client.MilvusClientV2;
import io.milvus.v2.common.IndexParam;
import io.milvus.v2.service.vector.request.SearchReq;
import io.milvus.v2.service.vector.request.data.EmbeddedText;
import io.milvus.v2.service.vector.request.data.FloatVec;
import io.milvus.v2.service.vector.request.ranker.BaseRanker;
import io.milvus.v2.service.vector.request.ranker.WeightedRanker;
import io.milvus.v2.service.vector.response.SearchResp;
import io.milvus.v2.service.vector.request.AnnSearchReq;
import io.milvus.v2.service.vector.request.HybridSearchReq;
import java.io.IOException;
import java.util.*;
public class searchDemo {
/**
* 查询结果数据结构
*/
static class QueryResult {
String queryText;
int queryIndex;
long vectorTime;
long bm25Time;
long hybridTime;
long totalTime;
int vectorResultCount;
int bm25ResultCount;
int hybridResultCount;
List<Map<String, Object>> vectorResults;
List<Map<String, Object>> bm25Results;
List<Map<String, Object>> hybridResults;
}
/**
* 资源使用统计
*/
static class ResourceUsage {
long memoryUsed; // MB
long memoryTotal; // MB
long diskFree; // GB
long diskTotal; // GB
public ResourceUsage(long memoryUsed, long memoryTotal, long diskFree, long diskTotal) {
this.memoryUsed = memoryUsed;
this.memoryTotal = memoryTotal;
this.diskFree = diskFree;
this.diskTotal = diskTotal;
}
}
/**
* 获取当前资源使用情况
*/
private static ResourceUsage getCurrentResourceUsage() {
Runtime runtime = Runtime.getRuntime();
// JVM内存使用情况 (MB)
long usedMemory = (runtime.totalMemory() - runtime.freeMemory()) / (1024 * 1024);
long totalMemory = runtime.totalMemory() / (1024 * 1024);
// 磁盘使用情况 (GB)
java.io.File root = new java.io.File("C:"); // Windows系统盘
if (!root.exists()) {
root = new java.io.File("/"); // Linux/Mac根目录
}
long freeDisk = root.getUsableSpace() / (1024 * 1024 * 1024);
long totalDisk = root.getTotalSpace() / (1024 * 1024 * 1024);
return new ResourceUsage(usedMemory, totalMemory, freeDisk, totalDisk);
}
private static MilvusClientV2 connect2milvus(){
ConnectConfig config = ConnectConfig.builder()
.uri("http://127.0.0.1:19530")
.build();
MilvusClientV2 client = new MilvusClientV2(config);
return client;
}
private static List<List<Float>> generateEmbedding(List<String> text) {
}
public static void main(String[] args) {
// 初始化搜索演示类
searchDemo demo = new searchDemo();
// 连接到Milvus
MilvusClientV2 client = demo.connect2milvus();
// 存储所有查询结果
List<QueryResult> allQueryResults = new ArrayList<>();
// 记录初始资源使用情况
ResourceUsage initialResource = getCurrentResourceUsage();
System.out.println("开始执行搜索测试...");
try {
// 读取查询文本
String jsonString = null;
try {
jsonString = new String(java.nio.file.Files.readAllBytes(java.nio.file.Paths.get("src/quest.json")));
} catch (IOException e) {
throw new RuntimeException(e);
}
JsonObject root = JsonParser.parseString(jsonString).getAsJsonObject();
JsonArray sections = root.getAsJsonArray("sections");
List<String> allQuestions = new ArrayList<>();
for (JsonElement sectionElements : sections){
JsonObject section = sectionElements.getAsJsonObject();
JsonArray questions = section.getAsJsonArray("questions");
for(JsonElement questionElement : questions){
allQuestions.add(questionElement.getAsString());
}
}
// 执行所有查询
int queryIndex = 0;
for (String queryText : allQuestions) {
queryIndex++;
// 记录开始时间
long startTime = System.currentTimeMillis();
// 首先进行向量搜索
long vectorStartTime = System.currentTimeMillis();
List<Map<String, Object>> vectorResults = demo.vectorSearch(client, queryText, 10);
long vectorTime = System.currentTimeMillis() - vectorStartTime;
// 然后进行BM25搜索
long bm25StartTime = System.currentTimeMillis();
List<Map<String, Object>> bm25Results = demo.bm25Search(client, queryText, 10);
long bm25Time = System.currentTimeMillis() - bm25StartTime;
// 执行混合搜索
long hybridStartTime = System.currentTimeMillis();
List<Map<String, Object>> hybridResults = demo.hybridSearch(client, queryText, 0.5f, 0.5f, 10);
long hybridTime = System.currentTimeMillis() - hybridStartTime;
long totalTime = System.currentTimeMillis() - startTime;
// 保存查询结果
QueryResult queryResult = new QueryResult();
queryResult.queryText = queryText;
queryResult.queryIndex = queryIndex;
queryResult.vectorTime = vectorTime;
queryResult.bm25Time = bm25Time;
queryResult.hybridTime = hybridTime;
queryResult.totalTime = totalTime;
queryResult.vectorResultCount = vectorResults.size();
queryResult.bm25ResultCount = bm25Results.size();
queryResult.hybridResultCount = hybridResults.size();
queryResult.vectorResults = vectorResults;
queryResult.bm25Results = bm25Results;
queryResult.hybridResults = hybridResults;
allQueryResults.add(queryResult);
}
// 记录结束资源使用情况
ResourceUsage finalResource = getCurrentResourceUsage();
// 生成Markdown报告并写入文件
generateMarkdownReport(allQueryResults, initialResource, finalResource);
System.out.println("报告已生成: search_comparison_report.md");
} catch (Exception e) {
System.err.println("Error during search: " + e.getMessage());
e.printStackTrace();
} finally {
client.close();
}
}
/**
* 生成Markdown报告
*/
private static void generateMarkdownReport(List<QueryResult> allQueryResults,
ResourceUsage initialResource,
ResourceUsage finalResource) {
StringBuilder md = new StringBuilder();
// 报告标题
md.append("# 搜索性能对比报告\n\n");
md.append("生成时间: ").append(new Date()).append("\n\n");
md.append("总查询数: ").append(allQueryResults.size()).append("\n\n");
// 资源使用情况统计
md.append("## 一、系统资源使用情况\n\n");
md.append("### 1.1 内存使用情况\n\n");
long memoryDelta = finalResource.memoryUsed - initialResource.memoryUsed;
md.append("| 指标 | 初始状态 (MB) | 最终状态 (MB) | 变化量 (MB) |\n");
md.append("|------|-------------|-------------|-----------|\n");
md.append(String.format("| 已用内存 | %d | %d | %+d |\n",
initialResource.memoryUsed, finalResource.memoryUsed, memoryDelta));
md.append(String.format("| 总内存 | %d | %d | - |\n",
initialResource.memoryTotal, finalResource.memoryTotal));
md.append(String.format("| 使用率 | %.1f%% | %.1f%% | %+.1f%% |\n\n",
(double) initialResource.memoryUsed / initialResource.memoryTotal * 100,
(double) finalResource.memoryUsed / finalResource.memoryTotal * 100,
(double) memoryDelta / initialResource.memoryTotal * 100));
// 内存分析
md.append("**内存使用分析:**\n\n");
if (memoryDelta > 0) {
md.append(String.format("- 执行所有查询后,内存使用增加了 **%d MB**\n", memoryDelta));
md.append(String.format("- 平均每个查询占用内存: **%.2f MB**\n\n",
(double) memoryDelta / allQueryResults.size()));
} else {
md.append("- 内存使用基本稳定,可能存在垃圾回收\n\n");
}
md.append("### 1.2 磁盘使用情况\n\n");
long diskDelta = finalResource.diskFree - initialResource.diskFree;
md.append("| 指标 | 初始状态 (GB) | 最终状态 (GB) | 变化量 (GB) |\n");
md.append("|------|-------------|-------------|-----------|\n");
md.append(String.format("| 可用空间 | %d | %d | %+d |\n",
initialResource.diskFree, finalResource.diskFree, diskDelta));
md.append(String.format("| 总容量 | %d | %d | - |\n",
initialResource.diskTotal, finalResource.diskTotal));
md.append(String.format("| 使用率 | %.1f%% | %.1f%% | %+.1f%% |\n\n",
(double) (initialResource.diskTotal - initialResource.diskFree) / initialResource.diskTotal * 100,
(double) (finalResource.diskTotal - finalResource.diskFree) / finalResource.diskTotal * 100,
(double) (-diskDelta) / initialResource.diskTotal * 100));
// 磁盘分析
md.append("**磁盘使用分析:**\n\n");
if (diskDelta < 0) {
md.append(String.format("- 执行过程中磁盘可用空间减少了 **%d GB**\n", -diskDelta));
md.append("- 可能原因:日志文件、临时文件或缓存数据\n\n");
} else {
md.append("- 磁盘使用基本稳定\n\n");
}
md.append("### 1.3 不同检索方式的资源占用对比\n\n");
md.append("| 检索方式 | 特点 | 内存占用 | 磁盘占用 | 备注 |\n");
md.append("|---------|------|---------|---------|------|\n");
md.append("| **向量搜索** | 需要加载向量索引 | 中等 | 高(向量数据+索引) | 适合语义检索 |\n");
md.append("| **BM25搜索** | 倒排索引 | 较低 | 较低(稀疏向量) | 适合关键词检索 |\n");
md.append("| **混合搜索** | 结合两者 | 较高 | 高(双索引) | 性能最优但资源消耗大 |\n\n");
md.append("**说明:**\n");
md.append("- **内存占用**: 向量索引需要在内存中保持以快速响应,BM25倒排索引内存占用较小\n");
md.append("- **磁盘占用**: 向量数据和索引文件通常占用量较大,稀疏向量(BM25)占用较小\n");
md.append("- **混合搜索**: 同时维护两套索引,资源占用是两者的总和\n\n");
// 生成总体性能统计
md.append("## 二、总体性能统计\n\n");
// 计算统计数据
long totalVectorTime = 0;
long totalBm25Time = 0;
long totalHybridTime = 0;
long totalOverallTime = 0;
for (QueryResult result : allQueryResults) {
totalVectorTime += result.vectorTime;
totalBm25Time += result.bm25Time;
totalHybridTime += result.hybridTime;
totalOverallTime += result.totalTime;
}
double avgVectorTime = (double) totalVectorTime / allQueryResults.size();
double avgBm25Time = (double) totalBm25Time / allQueryResults.size();
double avgHybridTime = (double) totalHybridTime / allQueryResults.size();
double avgOverallTime = (double) totalOverallTime / allQueryResults.size();
md.append("### 1.1 性能汇总\n\n");
md.append("| 搜索方式 | 总耗时(ms) | 平均耗时(ms) | 相对速度 |\n");
md.append("|---------|-----------|-------------|----------|\n");
md.append(String.format("| 向量搜索 | %d | %.2f | 基准 |\n", totalVectorTime, avgVectorTime));
md.append(String.format("| BM25搜索 | %d | %.2f | %.2fx |\n",
totalBm25Time, avgBm25Time, avgVectorTime / avgBm25Time));
md.append(String.format("| 混合搜索 | %d | %.2f | %.2fx |\n",
totalHybridTime, avgHybridTime, avgVectorTime / avgHybridTime));
md.append(String.format("| 总计 | %d | %.2f | - |\n\n", totalOverallTime, avgOverallTime));
// 性能分析
md.append("### 1.2 性能分析\n\n");
if (avgBm25Time < avgVectorTime) {
md.append(String.format("- **BM25搜索**比向量搜索快 **%.2f倍**\n", avgVectorTime / avgBm25Time));
} else {
md.append(String.format("- **向量搜索**比BM25搜索快 **%.2f倍**\n", avgBm25Time / avgVectorTime));
}
md.append(String.format("- 混合搜索总耗时 = 向量搜索 + BM25搜索 (%.2f + %.2f = %.2f ms)\n\n",
avgVectorTime, avgBm25Time, avgHybridTime));
// 每个查询的详细性能对比
md.append("### 1.3 各查询性能详情\n\n");
md.append("| 查询# | 向量搜索(ms) | BM25搜索(ms) | 混合搜索(ms) | 总耗时(ms) |\n");
md.append("|-------|-------------|-------------|-------------|----------|\n");
for (QueryResult result : allQueryResults) {
md.append(String.format("| #%d | %d | %d | %d | %d |\n",
result.queryIndex, result.vectorTime, result.bm25Time,
result.hybridTime, result.totalTime));
}
md.append("\n");
// 生成结果对比表格
md.append("## 三、搜索结果对比\n\n");
for (QueryResult qr : allQueryResults) {
md.append("### ").append(qr.queryIndex).append(". 查询: ").append(escapeMarkdown(qr.queryText)).append("\n\n");
md.append("#### 结果统计\n\n");
md.append(String.format("- 向量搜索结果数: **%d**\n", qr.vectorResultCount));
md.append(String.format("- BM25搜索结果数: **%d**\n", qr.bm25ResultCount));
md.append(String.format("- 混合搜索结果数: **%d**\n\n", qr.hybridResultCount));
// Top 5 对比表格
md.append("#### Top 5 结果对比\n\n");
md.append("| 排名 | 向量搜索分数 | BM25搜索分数 | 混合搜索分数 | 向量搜索内容 | BM25搜索内容 | 混合搜索内容 |\n");
md.append("|------|-------------|-------------|-------------|-------------|-------------|-------------|\n");
int maxRows = Math.min(5, Math.max(qr.vectorResults.size(),
Math.max(qr.bm25Results.size(), qr.hybridResults.size())));
for (int i = 0; i < maxRows; i++) {
String vectorScore = "-";
String vectorContent = "-";
String bm25Score = "-";
String bm25Content = "-";
String hybridScore = "-";
String hybridContent = "-";
if (i < qr.vectorResults.size()) {
Map<String, Object> result = qr.vectorResults.get(i);
Number scoreNum = (Number) result.get("score");
vectorScore = String.format("%.4f", scoreNum.doubleValue());
String content = result.get("content").toString();
vectorContent = content.length() > 20 ? escapeMarkdown(content.substring(0, 20) + "...") : escapeMarkdown(content);
}
if (i < qr.bm25Results.size()) {
Map<String, Object> result = qr.bm25Results.get(i);
Number scoreNum = (Number) result.get("score");
bm25Score = String.format("%.4f", scoreNum.doubleValue());
String content = result.get("content").toString();
bm25Content = content.length() > 20 ? escapeMarkdown(content.substring(0, 20) + "...") : escapeMarkdown(content);
}
if (i < qr.hybridResults.size()) {
Map<String, Object> result = qr.hybridResults.get(i);
Number scoreNum = (Number) result.get("score");
hybridScore = String.format("%.4f", scoreNum.doubleValue());
String content = result.get("content").toString();
hybridContent = content.length() > 20 ? escapeMarkdown(content.substring(0, 20) + "...") : escapeMarkdown(content);
}
md.append(String.format("| %d | %s | %s | %s | %s | %s | %s |\n",
i + 1, vectorScore, bm25Score, hybridScore,
vectorContent, bm25Content, hybridContent));
}
md.append("\n");
// Top 3 详细对比
md.append("#### Top 3 详细对比\n\n");
int topK = Math.min(3, Math.min(qr.vectorResults.size(),
Math.min(qr.bm25Results.size(), qr.hybridResults.size())));
for (int i = 0; i < topK; i++) {
md.append("**第 ").append(i + 1).append(" 名**\n\n");
if (i < qr.vectorResults.size()) {
Map<String, Object> result = qr.vectorResults.get(i);
Number scoreNum = (Number) result.get("score");
md.append("##### 向量搜索\n\n");
md.append(String.format("- **分数**: %.6f\n", scoreNum.doubleValue()));
md.append(String.format("- **标题**: %s\n", escapeMarkdown(result.get("title").toString())));
md.append(String.format("- **内容**: %s\n\n", escapeMarkdown(result.get("content").toString())));
}
if (i < qr.bm25Results.size()) {
Map<String, Object> result = qr.bm25Results.get(i);
Number scoreNum = (Number) result.get("score");
md.append("##### BM25搜索\n\n");
md.append(String.format("- **分数**: %.6f\n", scoreNum.doubleValue()));
md.append(String.format("- **标题**: %s\n", escapeMarkdown(result.get("title").toString())));
md.append(String.format("- **内容**: %s\n\n", escapeMarkdown(result.get("content").toString())));
}
if (i < qr.hybridResults.size()) {
Map<String, Object> result = qr.hybridResults.get(i);
Number scoreNum = (Number) result.get("score");
md.append("##### 混合搜索\n\n");
md.append(String.format("- **分数**: %.6f\n", scoreNum.doubleValue()));
md.append(String.format("- **标题**: %s\n", escapeMarkdown(result.get("title").toString())));
md.append(String.format("- **内容**: %s\n\n", escapeMarkdown(result.get("content").toString())));
}
md.append("---\n\n");
}
}
// 生成总结
md.append("## 四、总结\n\n");
md.append("### 4.1 性能总结\n\n");
md.append(String.format("- 向量搜索平均响应时间: **%.2f ms**\n", avgVectorTime));
md.append(String.format("- BM25搜索平均响应时间: **%.2f ms**\n", avgBm25Time));
md.append(String.format("- 混合搜索平均响应时间: **%.2f ms**\n\n", avgHybridTime));
md.append("### 4.2 资源使用总结\n\n");
md.append(String.format("- 内存使用增加: **%d MB** (平均 %.2f MB/查询)\n",
memoryDelta, (double) memoryDelta / allQueryResults.size()));
md.append(String.format("- 初始内存使用率: **%.1f%%**\n",
(double) initialResource.memoryUsed / initialResource.memoryTotal * 100));
md.append(String.format("- 最终内存使用率: **%.1f%%**\n\n",
(double) finalResource.memoryUsed / finalResource.memoryTotal * 100));
md.append("### 4.3 检索特点分析\n\n");
md.append("**向量搜索**\n");
md.append("- 优点: 能够理解语义,找到语义相关但关键词不匹配的内容\n");
md.append("- 缺点: 可能忽略精确的关键词匹配\n");
md.append("- 适用场景: 语义相似度搜索、概念检索\n\n");
md.append("**BM25搜索**\n");
md.append("- 优点: 精确匹配关键词,适合查找特定术语\n");
md.append("- 缺点: 无法理解语义,可能错过相关但用词不同的内容\n");
md.append("- 适用场景: 关键词搜索、术语查找\n\n");
md.append("**混合搜索**\n");
md.append("- 优点: 结合语义理解和关键词匹配,提供更全面的结果\n");
md.append("- 缺点: 响应时间较长(需要执行两次搜索)\n");
md.append("- 适用场景: 需要综合考虑语义和关键词的复杂查询\n\n");
md.append("### 4.4 有全文检索 vs 无全文检索对比\n\n");
md.append("**资源占用对比**\n\n");
md.append("| 对比项 | 仅向量检索 | 向量+全文检索 | 差异分析 |\n");
md.append("|--------|-----------|--------------|----------|\n");
md.append("| **内存占用** | 中等(向量索引) | 中等+低(向量+倒排索引) | 增加约10-20% |\n");
md.append("| **磁盘占用** | 高(向量数据+索引) | 高+较低(向量+稀疏向量) | 增加约5-15% |\n");
md.append("| **索引大小** | 大(稠密向量) | 大+小(稠密+稀疏向量) | 稀疏向量约1-5% |\n");
md.append("| **查询速度** | 快 | 更快(BM25)/ 混合稍慢 | BM25最快,混合叠加耗时 |\n");
md.append("| **检索精度** | 语义相关 | 关键词精确+语义 | 混合检索召回率最高 |\n\n");
md.append("**关键差异说明**\n\n");
md.append("1. **存储成本**\n");
md.append(" - **无全文检索**: 仅存储稠密向量(通常每个文档768-1536维float32)\n");
md.append(" - **有全文检索**: 额外存储稀疏向量(BM25倒排索引),通常只占稠密向量的1-5%\n");
md.append(" - **结论**: 全文检索的额外存储成本很低,但显著提升关键词检索能力\n\n");
md.append("2. **内存占用**\n");
md.append(" - **无全文检索**: 向量索引需要常驻内存以保证查询速度\n");
md.append(" - **有全文检索**: BM25倒排索引内存占用极小(通常是向量索引的1/10到1/100)\n");
md.append(" - **结论**: 增加全文检索对内存压力影响有限\n\n");
md.append("3. **查询性能**\n");
md.append(" - **无全文检索**: 单一向量检索,响应时间稳定\n");
md.append(" - **有全文检索**: \n");
md.append(" - 纯BM25查询: 速度快3-10倍\n");
md.append(" - 混合查询: 耗时约为两者之和,但结果质量最优\n");
md.append(" - **结论**: 可根据需求灵活选择检索方式\n\n");
md.append("4. **检索质量**\n");
md.append(" - **无全文检索**: 善于语义理解,弱于精确匹配\n");
md.append(" - **有全文检索**: 既能语义理解又能关键词匹配,混合检索效果最优\n");
md.append(" - **结论**: 全文检索显著提升整体检索质量和召回率\n\n");
md.append("**推荐策略**\n\n");
md.append("- **资源充足场景**: 优先使用混合检索,获得最佳检索效果\n");
md.append("- **资源受限场景**: 根据查询类型动态选择\n");
md.append(" - 关键词查询 → BM25检索\n");
md.append(" - 语义查询 → 向量检索\n");
md.append(" - 综合查询 → 混合检索\n");
md.append("- **成本敏感场景**: 额外存储和内存成本很低,建议默认开启全文检索\n\n");
// 写入文件
try {
java.nio.file.Files.write(
java.nio.file.Paths.get("search_comparison_report.md"),
md.toString().getBytes(java.nio.charset.StandardCharsets.UTF_8)
);
} catch (IOException e) {
System.err.println("写入报告文件失败: " + e.getMessage());
e.printStackTrace();
}
}
/**
* 转义Markdown特殊字符
*/
private static String escapeMarkdown(String text) {
return text.replace("|", "\\|")
.replace("*", "\\*")
.replace("_", "\\_")
.replace("#", "\\#")
.replace("`", "\\`")
.replace("[", "\\[")
.replace("]", "\\]")
.replace("(", "\\(")
.replace(")", "\\)")
.replace("<", "\\<")
.replace(">", "\\>");
}
/**
* 向量搜索
*/
private List<Map<String, Object>> vectorSearch(MilvusClientV2 client, String queryText, int topK) throws Exception {
// 生成查询向量
List<List<Float>> queryVectors = generateEmbedding(Collections.singletonList(queryText));
// 设置搜索参数
Map<String, Object> searchParams = new HashMap<>();
searchParams.put("metric_type", "IP");
searchParams.put("params", "{\"nprobe\": 16}");
FloatVec queryVector = new FloatVec(queryVectors.get(0));
// 执行向量搜索
SearchReq searchReq = SearchReq.builder()
.collectionName("hybrid_search_collection")
.data(Collections.singletonList(queryVector))
.annsField("embedding")
.topK(topK)
.searchParams(searchParams)
.outputFields(Arrays.asList("id", "title", "content"))
.build();
SearchResp searchResp = client.search(searchReq);
// 格式化结果
List<Map<String, Object>> results = new ArrayList<>();
List<List<SearchResp.SearchResult>> searchResults = searchResp.getSearchResults();
for (List<SearchResp.SearchResult> resultList : searchResults) {
for (SearchResp.SearchResult result : resultList) {
Map<String, Object> resultItem = new HashMap<>();
resultItem.put("id", result.getId());
resultItem.put("title", result.getEntity().get("title"));
resultItem.put("content", result.getEntity().get("content"));
resultItem.put("score", result.getScore());
resultItem.put("search_type", "vector");
results.add(resultItem);
}
}
return results;
}
// public static void main(String[] args) throws Exception {
// MilvusClientV2 milvusClientV2 = connect2milvus();
// List<Map<String, Object>> mapList = bm25Search(milvusClientV2, "建设全国统一大市场的核心目标是什么", 5);
// System.out.println(mapList);
// QueryReq queryReq = QueryReq.builder()
// .collectionName("hybrid_search_collection")
// .filter("id != ''") // 随便查一条
// .outputFields(Arrays.asList("id", "content"))
// .limit(1)
// .build();
//
// QueryResp queryResp = milvusClientV2.query(queryReq);
// System.out.println(queryResp.getQueryResults());
// }
/**
* BM25全文搜索
*/
private static List<Map<String, Object>> bm25Search(MilvusClientV2 client, String queryText, int topK) throws Exception {
// 设置BM25搜索参数
Map<String, Object> searchParams = new HashMap<>();
searchParams.put("metric_type", "BM25");
searchParams.put("params", "{}");
// 执行BM25搜索
SearchReq searchReq = SearchReq.builder()
.collectionName("hybrid_search_collection")
.data(Collections.singletonList(new io.milvus.v2.service.vector.request.data.EmbeddedText(queryText)))
.annsField("content_sparse")
.topK(topK)
.searchParams(searchParams)
.outputFields(Arrays.asList("id", "title", "content"))
.build();
SearchResp searchResp = client.search(searchReq);
// 格式化结果
List<Map<String, Object>> results = new ArrayList<>();
List<List<SearchResp.SearchResult>> searchResults = searchResp.getSearchResults();
for (List<SearchResp.SearchResult> resultList : searchResults) {
for(SearchResp.SearchResult result : resultList) {
Map<String, Object> resultItem = new HashMap<>();
resultItem.put("id", result.getId());
resultItem.put("title", result.getEntity().get("title"));
resultItem.put("content", result.getEntity().get("content"));
resultItem.put("score", result.getScore());
resultItem.put("search_type", "bm25");
results.add(resultItem);
}
}
return results;
}
/**
* 混合搜索(向量+BM25)
*/
/**
* 混合搜索(向量+BM25)
* 修正后:使用 MilvusClientV2 对应的 Request 类
*/
private List<Map<String, Object>> hybridSearch(MilvusClientV2 client, String queryText,
float vectorWeight, float bm25Weight, int topK) throws Exception {
// 1. 生成查询向量 (Dense Vector)
List<List<Float>> queryVectors = generateEmbedding(Collections.singletonList(queryText));
FloatVec vectorData = new FloatVec(queryVectors.get(0));
// 2. 构建向量搜索子请求 (AnnSearchReq)
Map<String, Object> vecParams = new HashMap<>();
vecParams.put("nprobe", 16);
AnnSearchReq vectorReq = AnnSearchReq.builder()
.vectorFieldName("embedding")
.vectors(Collections.singletonList(vectorData))
.metricType(IndexParam.MetricType.IP)
.params(new Gson().toJson(vecParams)) // V2 通常接受 JSON 字符串作为参数
.topK(topK)
.build();
// 3. 构建 BM25 搜索子请求 (AnnSearchReq)
// 使用 EmbeddedText 包装文本,Milvus 会自动处理为稀疏向量(前提是 Schema 配置正确)
EmbeddedText bm25Data = new EmbeddedText(queryText);
AnnSearchReq bm25Req = AnnSearchReq.builder()
.vectorFieldName("content_sparse") // 修正字段名,与 bm25Search 方法保持一致
.vectors(Collections.singletonList(bm25Data))
.metricType(IndexParam.MetricType.BM25)
.params("{}")
.topK(topK)
.build();
// 4. 配置重排序器 (WeightedRanker)
// 根据传入的权重参数配置
BaseRanker ranker = new WeightedRanker(Arrays.asList(vectorWeight, bm25Weight));
// 5. 构建混合搜索请求 (HybridSearchReq)
HybridSearchReq hybridReq = HybridSearchReq.builder()
.collectionName("hybrid_search_collection")
.searchRequests(Arrays.asList(vectorReq, bm25Req))
.ranker(ranker)
.topK(topK)
.outFields(Arrays.asList("id", "title", "content"))
.build();
// 6. 执行混合搜索
SearchResp searchResp = client.hybridSearch(hybridReq);
// 7. 解析结果
List<Map<String, Object>> results = new ArrayList<>();
List<List<SearchResp.SearchResult>> searchResults = searchResp.getSearchResults();
if (searchResults != null && !searchResults.isEmpty()) {
// 获取第一条查询(我们只查了一个 queryText)的结果列表
for (SearchResp.SearchResult result : searchResults.get(0)) {
Map<String, Object> resultItem = new HashMap<>();
resultItem.put("id", result.getId());
resultItem.put("score", result.getScore());
// V2 SDK 返回的 Entity 是 Map<String, Object>
if (result.getEntity().containsKey("title")) {
resultItem.put("title", result.getEntity().get("title"));
}
if (result.getEntity().containsKey("content")) {
resultItem.put("content", result.getEntity().get("content"));
}
resultItem.put("search_type", "hybrid");
results.add(resultItem);
}
}
return results;
}
}Java代码核心说明:
向量搜索(vectorSearch)
- 使用
FloatVec包装查询向量 - 通过
SearchReq.builder()构建搜索请求 - 返回包含ID、标题、内容和分数的结果列表
- 使用
BM25搜索(bm25Search)
- 使用
EmbeddedText包装原始查询文本 - Milvus自动应用BM25函数生成稀疏向量
- 执行关键词匹配并返回相关性分数
- 使用
混合搜索(hybridSearch)
- 构建两个
AnnSearchReq:一个用于向量搜索,一个用于BM25 - 使用
WeightedRanker加权融合两种结果 - 通过
HybridSearchReq执行混合查询
- 构建两个
与Python版本的差异:
- Java版本使用Milvus V2 SDK,API设计更符合Java习惯
- 使用Builder模式构建请求对象
- 需要手动处理JSON序列化(使用Gson库)
- 资源管理通过try-finally确保客户端关闭
4.5.4 generateEmbedding方法实现
Java版本同样需要实现向量化方法。以下是几种实现方式:
方式1:调用本地LLM客户端(自己部署)
private static List<List<Float>> generateEmbedding(List<String> texts) {
// 初始化LLM客户端
LLMClient llmClient = LLMClient.getInstance();
// 配置API密钥和URL
System.setProperty("llm.client.key", "your-api-key");
System.setProperty("llm.client.secret", "your-secret");
System.setProperty("llm.client.url", "https://api.example.com");
// 调用批量向量化接口
EmbeddingStringResult result = llmClient.createEmbedding(
"/llm-api/embedding/create_batch",
texts
);
// 返回向量列表
return result.getData();
}方式2:调用REST API
private static List<List<Float>> generateEmbedding(List<String> texts) {
try {
// 构建请求体
JsonObject requestBody = new JsonObject();
JsonArray textsArray = new JsonArray();
texts.forEach(textsArray::add);
requestBody.add("texts", textsArray);
requestBody.addProperty("model", "embedding-model");
// 发送HTTP请求
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create("https://api.example.com/embeddings"))
.header("Content-Type", "application/json")
.header("Authorization", "Bearer your-api-key")
.POST(HttpRequest.BodyPublishers.ofString(requestBody.toString()))
.build();
HttpClient client = HttpClient.newHttpClient();
HttpResponse<String> response = client.send(
request,
HttpResponse.BodyHandlers.ofString()
);
// 解析响应
JsonObject responseBody = JsonParser.parseString(response.body()).getAsJsonObject();
JsonArray embeddings = responseBody.getAsJsonArray("embeddings");
// 转换为List<List<Float>>
List<List<Float>> result = new ArrayList<>();
for (JsonElement elem : embeddings) {
JsonArray vector = elem.getAsJsonArray();
List<Float> vec = new ArrayList<>();
for (JsonElement val : vector) {
vec.add(val.getAsFloat());
}
result.add(vec);
}
return result;
} catch (Exception e) {
throw new RuntimeException("Failed to generate embeddings", e);
}
}4.6 观察结果
执行检索代码后,会生成一个名为search_comparison_report.md的Markdown格式报告文件。该文件包含详细的性能对比和结果分析。
4.6.1 报告结构
生成的报告包含以下四个主要部分:
一、系统资源使用情况
- 内存使用情况:显示客户端脚本的内存占用变化(初始/最终/变化量)
- 磁盘使用情况:记录磁盘可用空间的变化
- 理论资源占用对比:对比三种检索方式在服务端的资源占用特点
二、总体性能统计
- 性能汇总:展示所有查询的总耗时、平均耗时和相对速度
- 性能分析:对比不同检索方式的性能差异
- 各查询性能详情:列出每个查询的具体耗时数据
三、搜索结果对比
- 每个查询的详细对比:包含Top 5结果的三种检索分数对比
- Top 3详细对比:展示前3名结果的完整信息(标题、内容、分数)
四、总结
- 性能总结:平均响应时间统计
- 资源使用总结:内存和磁盘使用情况
- 检索特点分析:三种检索方式的优缺点对比
- 有无全文检索对比:详细的资源占用和性能对比
4.6.2 关键指标解读
1. 搜索分数(score)
- 向量搜索分数:内积(IP)值,范围通常在-1到1之间,越大越相似
- BM25分数:基于词频和文档频率的相关性分数,通常为正数
- 混合搜索分数:加权融合后的综合分数,同时反映语义和关键词相关性
2. 性能指标
- 相对速度:以向量搜索为基准,其他方式的加速比
- 平均耗时:单次查询的平均响应时间
- 资源占用:内存和磁盘的使用情况
3. 结果质量评估 通过对比三种检索方式返回的结果,可以观察到:
- 向量搜索:倾向于返回语义相关的文档,即使关键词不完全匹配
- BM25搜索:优先返回包含查询关键词的文档
- 混合搜索:结合两者优势,通常能获得更好的召回率
4.6.3 结果分析建议
权重调优:根据业务特点调整混合搜索的权重参数
- 关键词重要的场景:提高BM25权重(如0.3向量 + 0.7 BM25)
- 语义理解重要的场景:提高向量权重(如0.7向量 + 0.3 BM25)
性能优化:
- 如果BM25速度明显快于向量搜索,可以考虑先用BM25缩小范围,再做向量检索
- 根据资源情况选择合适的索引类型和参数
结果质量:
- 观察不同查询类型下三种检索方式的表现差异
- 分析检索失败或结果不理想的查询,优化查询文本或数据预处理
总结
通过本章节的实战演练,我们完成了从零开始构建一个基于Milvus的向量+BM25混合搜索系统的全过程。
常见问题解决
| 问题 | 可能原因 | 解决方案 |
|---|---|---|
| 查询结果为空 | 向量维度不匹配 | 检查embedding模型的输出维度 |
| BM25无结果 | 文本未正确分词 | 检查analyzer配置,确保使用jieba分词 |
| 混合搜索报错 | 权重参数错误 | 确保两个权重之和不为0,通常设为0.5和0.5 |
| Attu无法查看数据 | 稀疏向量显示限制 | 使用代码查询而非Attu界面 |
| 内存占用过高 | 数据集过大 | 考虑使用IVF索引而非FLAT索引 |
进阶学习方向
1. 高级索引优化
- 调研IVF_FLAT的nprobe参数对性能的影响
- 学习HNSW索引的构建参数(M、efConstruction)
- 理解不同索引类型的适用场景和性能特点
2. BM25参数调优
- 调整BM25的k1和b参数以改善检索效果
- 尝试不同的分词器(standard、jieba、自定义词典)
- 理解BM25算法原理和参数影响
3. 混合检索策略
- 学习更复杂的融合策略(RRF、Reciprocal Rank Fusion)
- 实现动态权重调整机制
- 探索重排序(rerank)技术提升最终结果质量
4. 生产环境部署
- Milvus集群部署和负载均衡
- 监控告警系统搭建
- 数据备份和灾备方案
5. 性能调优
- 查询优化技巧(分区键、过滤表达式)
- 缓存策略应用
- 并发查询处理
结语
本章节通过政务问答领域的实战案例,帮助大家掌握了Milvus向量数据库的核心功能和混合检索技术。从理论到实践,我们系统地学习了如何构建一个高质量的检索系统。
混合检索技术结合了向量搜索的语义理解能力和BM25的关键词精确匹配能力,能够显著提升检索系统的召回率和用户体验。在实际应用中,需要根据具体业务场景和数据特点,选择合适的检索策略和参数配置。
希望本章节的内容能够帮助大家在实际项目中更好地应用Milvus,构建高效、智能的检索系统!