Chapter 1.1 深入 Milvus 架构设计:数据写入和查询高层级流程(选学)
掌握 Milvus 仅了解基础使用是不够的,深入理解其云原生分布式架构设计原理至关重要。这将助你优化性能、高效排查问题,并在生产环境中做出明智的配置决策。
这部分内容包括:
- Milvus 核心架构概览
- Milvus 核心组件详解
- Milvus 数据写入高层级流程
- Milvus 查询高层级流程
- Milvus 数据处理流程
- 关键架构优势与机制总结
- 回顾与总结
- 补充 解惑
- 关键问题/挑战
1.1.1 Milvus 核心架构概览
Milvus 采用存储计算分离的分布式架构,核心组件如下:
- 接入层(Access Layer):处理客户端请求(SDK, REST API)。
- 协调服务(Coordinator Services):集群的“大脑”,管理元数据和任务调度。
- 工作节点(Worker Nodes):执行具体任务的“肌肉”(查询、写入、索引)。
- 存储层(Storage):持久化数据和元数据的“基石”。
| 组件 | 存储内容 | 后端技术 |
|---|---|---|
| Log Broker | 数据变更日志(Insert/Delete/Update) | Pulsar/Kafka/RocksDB |
| Object Storage | 向量原始数据、索引文件、Segment 文件 | MinIO/S3/Azure Blob/GCS/本地文件 |
| Metadata Storage | 集合Schema、Segment状态、节点信息、TSO | ETCD/MySQL/TiDB |
| Query Node | 热数据缓存、内存索引、执行引擎 | 本地SSD/Memory/GPU |
| Data Node | 写入缓冲区(WAL) | 本地磁盘 |
核心设计理念
存储计算分离:计算节点无状态,状态(元数据、数据、索引)存于外部服务(Query Node以及Data Node从外部的Object Storage和MetaData Storage中获取segment、index file和segment状态、TSO)。实现弹性扩缩容、高可用(查询节点与数据节点分别归在各个部分的协调器下,当一个节点故障时可快速替换其他节点)、成本优化(计算按需,存储经济)。
读写分离:Query Node (读)、Data Node (写)、Index Node (索引构建) 职责清晰,互不干扰。
日志即数据:数据写入首先进入 Log Broker,作为数据的“唯一真实来源”。Data Node 消费日志写存储,Query Node 消费日志保持数据最新视图,确保数据一致性和流批一体。
流批一体:Log Broker 处理实时流,Object Storage 存储批数据,Query Node 通过订阅日志实现流批统一视图。
微服务化:组件独立部署、通信(gRPC),易于维护、升级、扩展。
向量优化:架构围绕高效处理大规模高维向量 ANN 搜索设计。
增量模型:该模型是milvus中非常重要的一部分,你可以理解为Milvus采用"基础数据+增量变更"的存储模式,类似于数据库的WAL(Write-Ahead Log)机制。
核心思想:
- 基础快照:Object Storage中存储的Segment文件是某个时间点的完整数据快照
- 增量日志:Log Broker中记录所有后续的Insert/Delete操作
- 实时合并:Query Node在查询时动态合并基础数据+增量变更,呈现最新视图
# 时间轴
t0: 插入向量 [A]
t1: 插入向量 [B]
t2: 发起查询Q1
t3: 删除向量 [A]
t4: 发起查询Q2
# 快照隔离效果
Q1(在t2执行) 看到数据: [A, B] // 包含t2前的所有写入
Q2(在t4执行) 看到数据: [B] // 包含t4前的所有写入1.1.2 核心组件详解
一致性模型&&TSO
首先,在你看下面的流程性的内容之前,需要重点的来理解一下Milvus的TSO到底是什么,在整个底层中扮演了什么角色,起到了什么作用。
如果你学习过分布式系统,那么你应该知道水印watermark这个概念,想象一下你有一个不断流动的水流(数据流),水印就是标记,到目前为止这些水已经到达水库的那个位置
在milvus中,水印就是TSO(时间戳),它表示在这个时间点之前的所有数据,已经完成持久化存储(已经被存入到Object Storage),这个时间戳TSO由根协调器Root Coordinator分配,由Data Coordinator维护(当根协调器分配TSO给数据协调器后,数据协调器分发给下面的数据节点Data Node,当data node完成数据的Flush后更新TSO)。我们用一段伪代码来理解TSO的分配以及使用流程:
def handle_data_update(request):
# 1. 客户端发起请求
client_request = {"operation": "insert", "data": [...]} # 客户端请求数据
# 2. Proxy转发给Root Coord
root_coord = RootCoordinator() # 根协调器实例
tso = root_coord.alloc_timestamp() # 分配全局唯一时间戳
# 3. 写入Log Broker
log_broker.publish(
channel="collection-01", # 集合对应的消息通道
message={"data": request["data"], "ts": tso} # 消息内容包含数据和时间戳
)
# 4. Data Coord 的职责开始
data_coord = DataCoordinator() # 数据协调器实例
# 5. Data Coord 分配Segment给Data Node
if not has_assigned_segment("collection-01"): # 检查是否已分配Segment
# 选择Data Node (负载均衡)
data_node = select_data_node_by_load() # 根据负载选择数据节点
# 分配Segment ID并记录元数据
segment_id = generate_segment_id() # 生成唯一Segment ID
metadata_store.save(
collection="collection-01", # 集合名称
segment_id=segment_id, # Segment标识
assigned_node=data_node.id # 分配的节点ID
)
# 通知Data Node开始消费日志
data_node.watch_channel(
channel="collection-01", # 要监听的通道
segment_id=segment_id # 负责的Segment ID
)
# 6. Data Node 持续消费日志
data_node.consume_logs(
channel="collection-01", # 消费的消息通道
segment_id=segment_id, # 处理的Segment
callback=process_data # 数据处理回调函数
)
def process_data(data, segment_id):
# 7. Data Node处理数据
buffer = get_buffer(segment_id) # 获取Segment对应的缓冲区
buffer.append(data) # 将数据添加到缓冲区
# 达到阈值时触发Flush
if buffer.size() > FLUSH_THRESHOLD: # 检查缓冲区大小是否达到阈值
flush_to_storage(segment_id, buffer) # 将数据刷写到对象存储
update_watermark(segment_id, data["ts"]) # 更新水印时间戳补充一点说明,你可以在代码中看到有一个地方写了负载均衡,这个负载均衡是由谁来完成的呢,是Data Coordinator还是k8s呢? 其实,此处的Data Node的负载均衡是由上层的Data Coordinator完成的,具体实现算法等到之后另外的章节再详细介绍,Data Coord负责向Data Node发放Segment,处于应用层,k8s负责milvus的整体,也就是基础设施层,当Data Node Pod的CPU使用率持续>70%,k8s会自动扩容,比如从3 Pod -> 5 Pod,新的Pod启动后会自动向Data Coordinator注册,所以总结来说,k8s控制的是上层数据流量的均衡(因为它只知道CPU/内存使用情况,不知道Segment大小),Data Coord负责Milvus中数据节点的负载均衡(因为Segment是有状态的,需要持久化到Metadata Storage中,k8s做不到这一点),最重要的一点,为什么不能用k8s做数据协调器向下面的Data Node的负载均衡,当我们的一个request进来后,你不可能等待好几秒甚至数分钟才得到相应吧,受不了的,k8s的HPA要完成节点的segment的负载均衡,往往需要数分钟(假设可以管理segment),而协调器则可以在ms级别做出响应,决定Segmen应该发放到哪个Node。
回到代码中,问一个问题请你判断是否正确:Data Coordinator检测到来自根协调器发出的数据更新请求后,下发给某一个拿到segmentID的Data Node然后Data Node去消费日志。对吗?
答案自然是不对的,很容易理解成这种错误的意思,实际情况是根协调器只负责分配TSO,请求是客户端发起的。Data Coordinator不检测请求,只管理Segemnt的分配(分给哪个Data Node),然后通知Data Node去消费日志(更准确来说是节点订阅了协调器的topic),Data Node拿到从Data Coordinator分配的segment后才开始消费特定的channel。这个描述一定要准确,各个组件的功能和责任要分清楚!
下面我们进入整体流程的讲解。
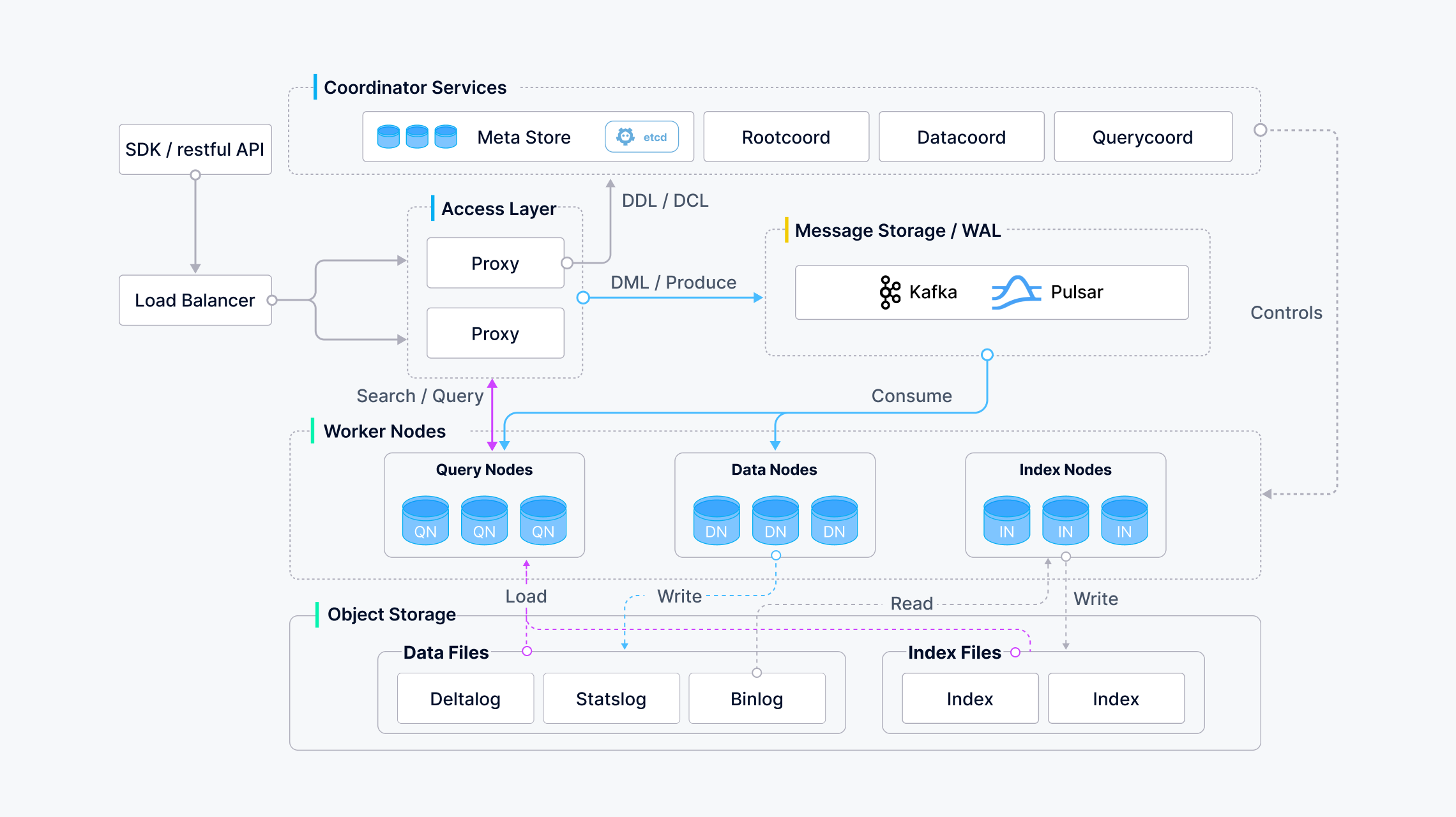
1. 接入层 (Access Layer)
- SDKs / RESTful Gateway:用户交互入口(如
pymilvus.insert()/.search())。 - 负载均衡器 (LB):分发请求到后端 Coordinator(通常由 K8s Service 或 Nginx 实现)。
2. 协调服务 (Coordinator Service)
由多个角色组成(可同进程或不同进程部署):
- Root Coordinator (Root Coord):
- 管理 DDL(创建/删除集合/分区/索引)。
- 分配全局唯一递增的时间戳 (TSO - Timestamp Oracle),保证操作顺序和快照隔离一致性。
- 收集展示集群指标。唯一有状态角色(状态存于 Metadata Storage)。
- Query Coordinator (Query Coord):
- 接收查询请求,解析查询计划。
- 将查询任务分发给 Query Node,合并结果。
- 管理 Query Node 负载均衡和故障转移。
- Data Coordinator (Data Coord):
- 管理数据生命周期(Segment)、刷新 (Flush)、压缩 (Compaction)。
- 分配数据写入任务给 Data Node。
- 协调 Data Node 与 Index Node。
- 管理 Data Node 负载均衡和故障转移。
- Index Coordinator (Index Coord):
- 接收索引创建请求。
- 分配索引构建任务给 Index Node,监控状态。
- 管理 Index Node 负载均衡和故障转移。
3. 工作节点 (Worker Nodes)
分为Query Node和Data Node,两者都是无状态,可水平扩展。
Query Node (查询):
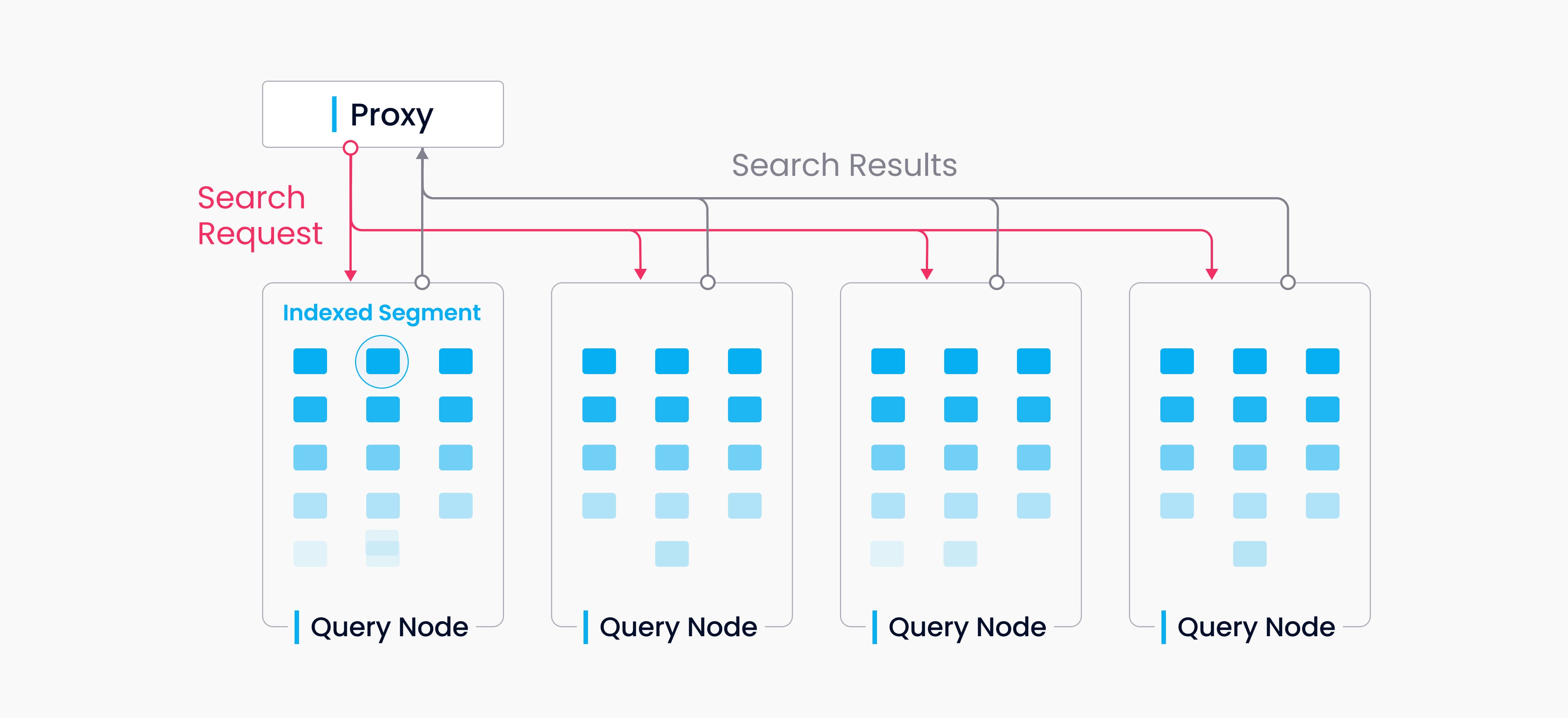
- 核心职责:执行向量/标量数据的搜索 (Search) 和查询 (Query)。
- 关键机制:
- 订阅日志:从 Log Broker 订阅负责 Segment 的增量数据,保持内存视图最新。
- 加载 Segment:按 Query Coord 调度,从 Object Storage 加载 Segment 数据(向量、标量、索引文件)到内存或本地 SSD 缓存(冷数据加载)。
- 执行引擎:包含核心算子:
- 向量距离计算算子 (多线程/GPU 优化):支持L2, IP, Cosine 等。
- ANN 搜索算子 (基于索引如 IVF_FLAT/HNSW):在内存索引上执行近似搜索。
- 标量过滤算子:执行属性过滤 (
price>100,color='red'),涉及布尔运算、比较等。 - 结果合并与排序算子:对局部结果进行合并、全局 TopK 排序(堆排序/归并排序)。
- 资源管理:控制内存、CPU 并发。
Data Node (写入):
- 核心职责:处理数据插入、删除、更新(通过 Delete+Compaction),持久化数据。
- 关键机制:
- 消费日志:从 Log Broker 消费 Insert/Delete 消息。
- 写 Buffer & Flush:内存缓冲数据,达到阈值(时间/大小)后以 Segment 文件形式 Flush 到 Object Storage。
query node 在之后的查询阶段是会先从缓存里面查询数据的,这保证了查询速度并且可以确保增量数据能及时被查询到。所以此处data node要先写缓存,等达到阈值后再进行flush操作,将数据刷入Object Storage中。
- Compaction 算子:后台合并小 Segment、清理删除数据,优化查询性能。
segment合并的必要性:占用存储空间、并且最重要的是影响query node的计算,可以想象一下,你打开attu查看数据,全是小分段,很影响召回率。
Index Node (索引构建):
- 核心职责:为 Data Node Flush 生成的 Segment 文件构建索引。
- 关键机制:
- 加载 Segment 数据:从 Object Storage 加载数据。
- 索引构建算子:调用底层库执行构建(如 IVF 聚类 / HNSW 图构建),完成后将索引文件存回 Object Storage。
4. 存储层 (Storage Layer)
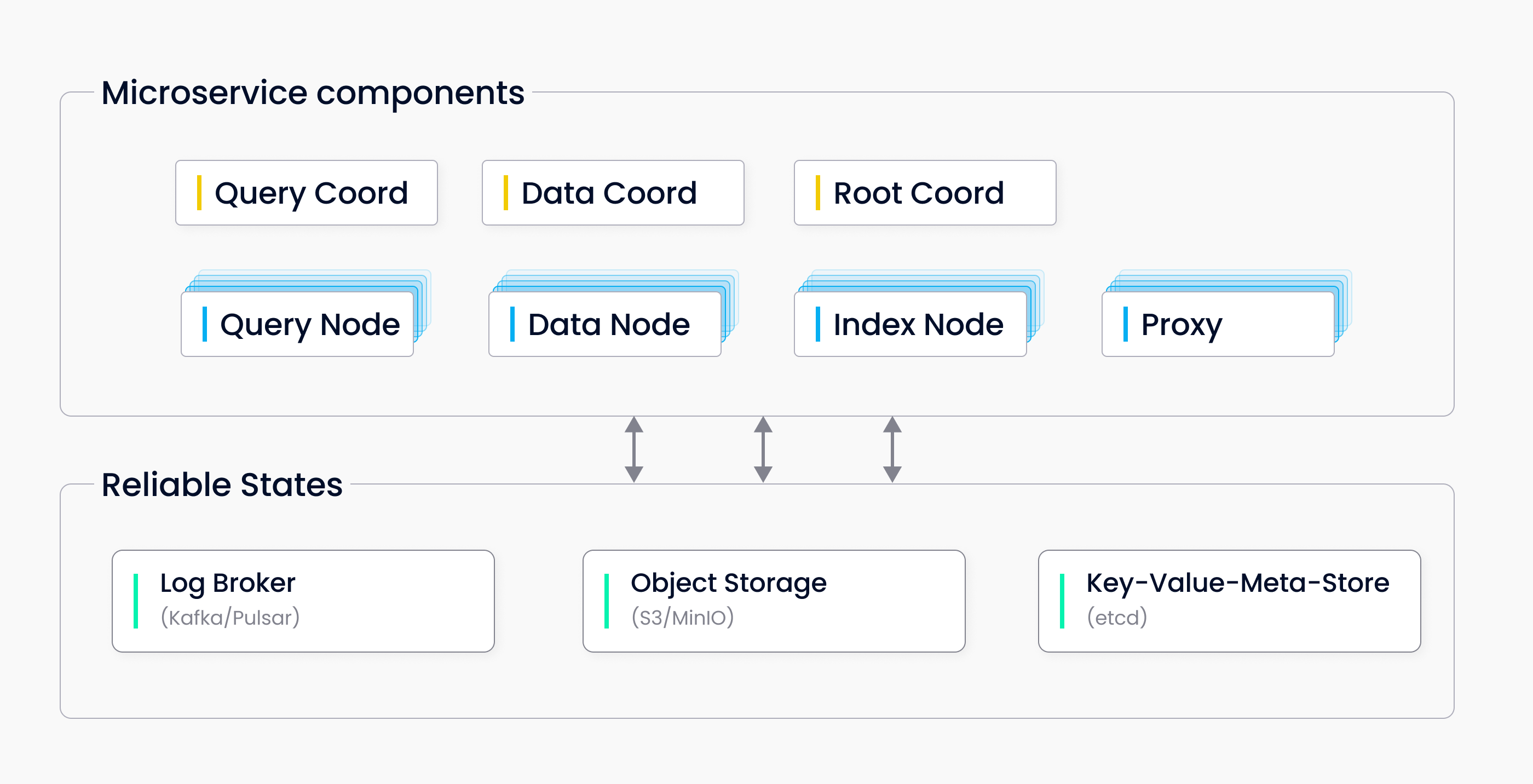
- 元数据存储 (Metadata Storage):存储所有系统元数据(Schema, 分区, Segment 元信息, TSO 状态等)。采用强一致、高可用 (etcd/MySQL/TiDB)。Root Coord 是其主要的使用者。
为什么根协调器是主要使用者呢?因为根协调器控制着查询协调器与数据协调器,根协调器从MetaData Storage中获取最新TSO,处理、分配给两个子协调器,这样保证了两个协调器间服务的一致性。
- 日志存储 (Log Broker):数据变更操作(Insert/Delete/DDL)的载体。高吞吐、低延迟、持久化、顺序保证 (Pulsar/Kafka)。Data Node 的写入来源,Query Node 的数据更新来源。
- 对象存储 (Object Storage):持久化 Segment 原始数据文件、索引文件、Compaction 中间文件。高可靠、高持久、高扩展、低成本 (MinIO/S3/Azure Blob/GCS)。访问延迟相对较高。
1.1.3 Milvus 数据写入高层级流程 (结合图片步骤)
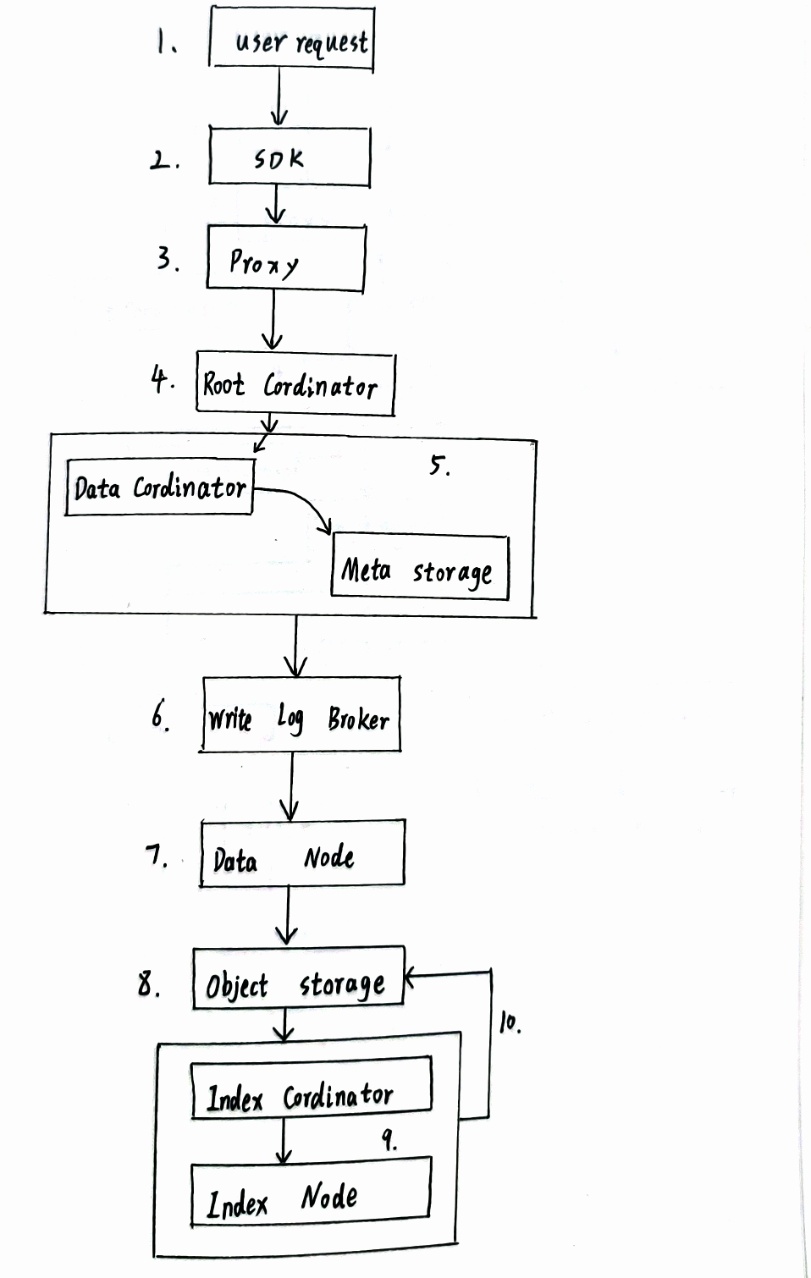
用户请求:客户端通过 SDK (如
pymilvus.insert()) 发起插入请求。接入代理:请求到达 Proxy 网关。
验证与转发:
- Proxy 验证请求合法性(集合存在、数据格式合规)。
- 负载均衡转发给 Root Coordinator。
分配顺序:
- Root Coord 为操作分配全局唯一时间戳 (TSO),确保分布式顺序一致性。
- 通知 Data Coord。
元数据管理与分配 (Data Coord):
- 查询 Metadata Storage (etcd) 获取目标集合存储策略。
- 决定数据存储位置(创建新 Segment 或使用现有写入 Segment)。
- 记录 Segment ID、状态、分配信息到 Metadata Storage。
日志先行 (Log Broker):所有数据变更必须首先写入 Log Broker (如 Pulsar/Kafka),保证操作的持久性和严格顺序性。这是“日志即数据”理念的核心体现。
& 8. 数据节点消费与持久化 (Data Node):
- Data Node 订阅并消费 Log Broker 中的 Insert/Delete 消息。
- 数据先写入内存缓冲区 (此时即可被 Query Node 订阅消费用于实时查询)。
- 当缓冲区达到阈值(时间或大小)时,触发 Flush 操作:
- 将缓冲数据(向量、标量)作为 Segment 文件写入 Object Storage (MinIO/S3)。
- Flush 创建新的 Segment。
触发索引构建 (Index Coord):
- Data Coord 通知 Index Coord 有新 Segment 产生。
- Index Coord 调度 Index Node 为新 Segment 构建索引。
异步索引构建 (Index Node):
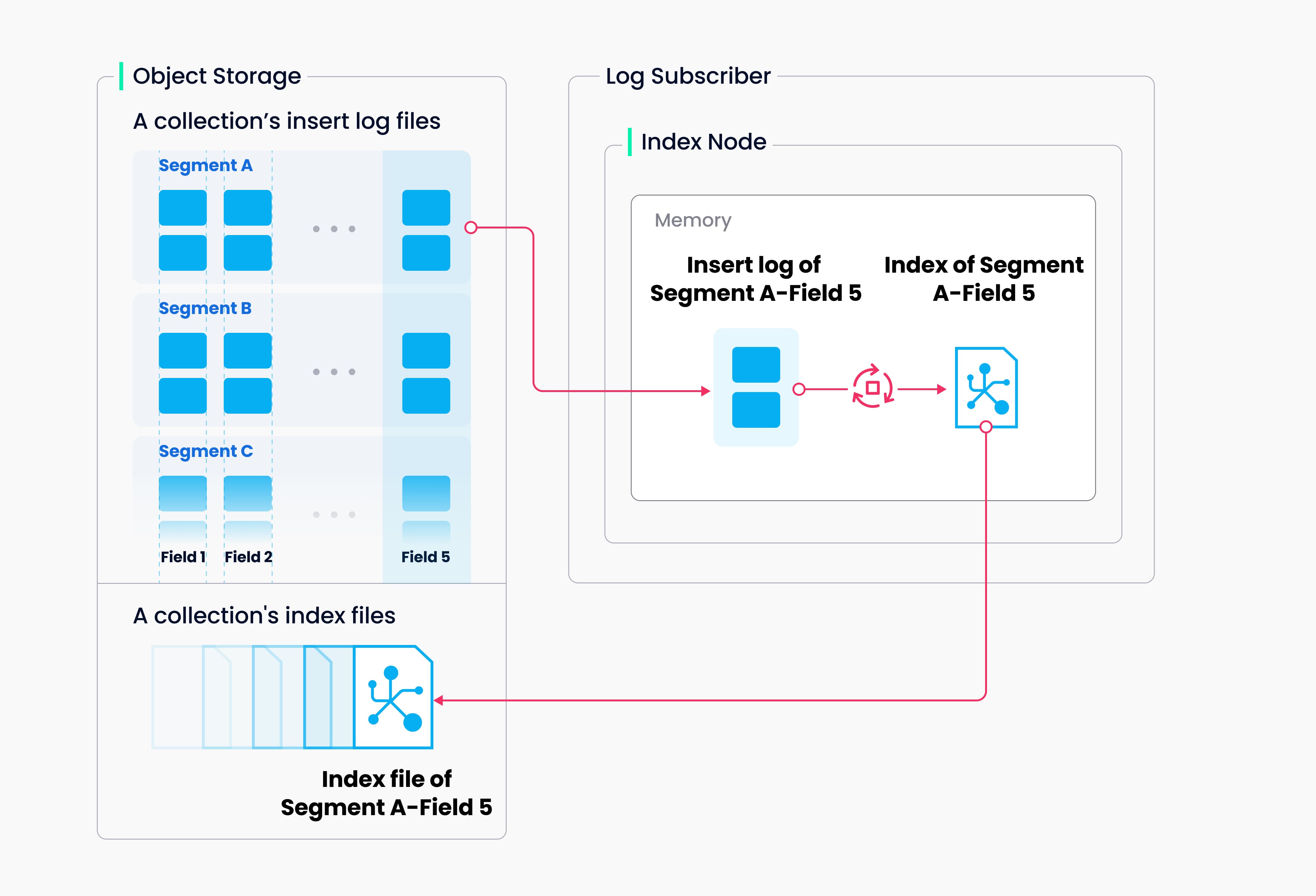
- Index Node 从 Object Storage 读取新 Segment 的原始数据。
- 执行索引构建算子(如 IVF 聚类、HNSW 图构建)。
- 将生成的索引文件写回 Object Storage。此过程是异步的,避免阻塞写入。
1.1.4 Milvus 查询高层级流程 (结合图片步骤)
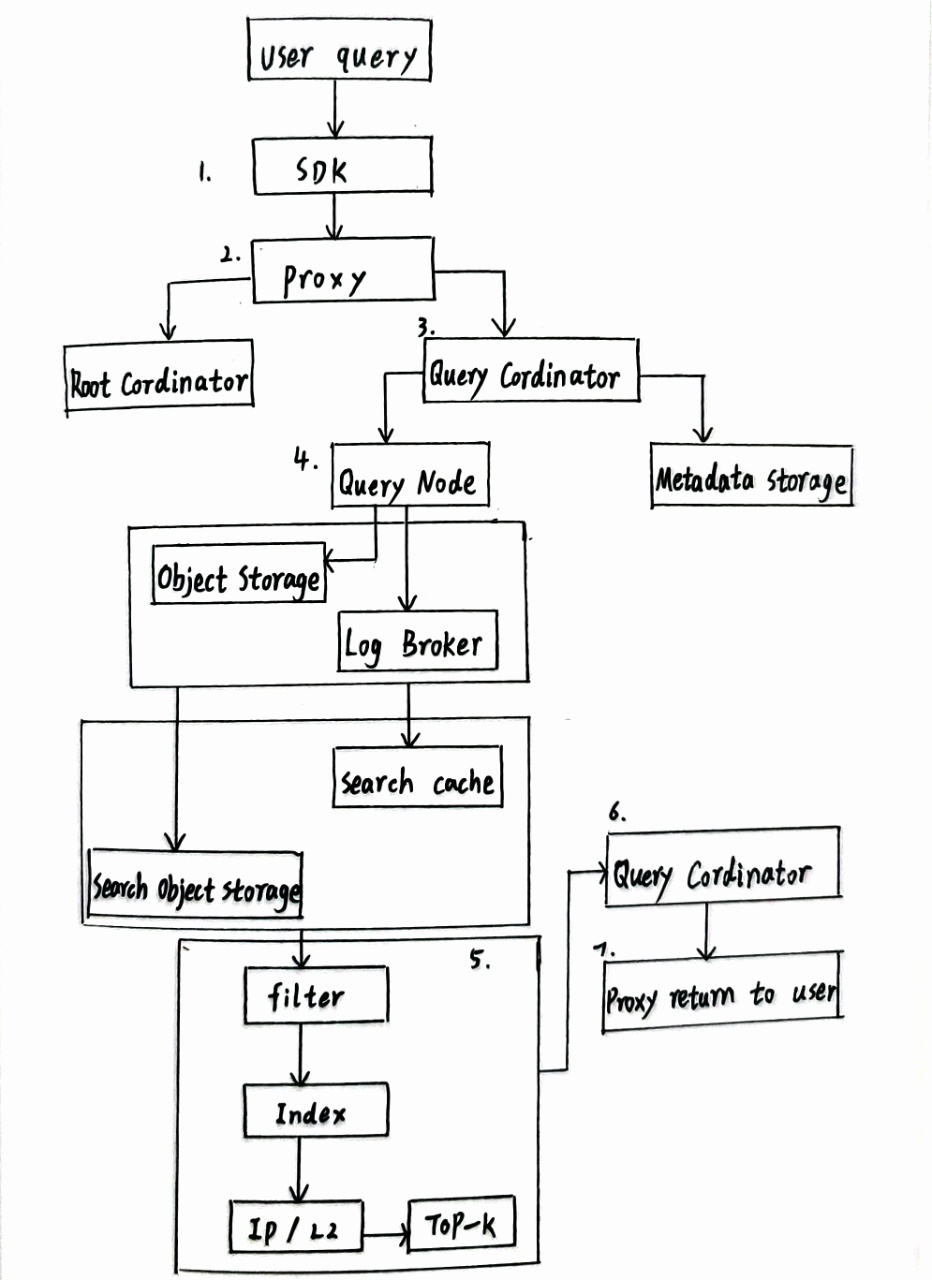
- 用户请求:客户端通过 SDK (如
pymilvus.search()) 发起搜索请求。 - 接入代理:请求到达 Proxy 网关。
- 协调与分发 (Query Coord):
- Proxy 转发请求给 Query Coord。
- Query Coord 从 Root Coord 获取时间戳 (TSO),保证读取一致性(快照隔离)。
- 解析查询请求和过滤条件。
- 根据 Metadata Storage 信息,确定哪些 Segment 包含目标数据。
- 将搜索子任务分发给持有这些 Segment 的 Query Node 实例(支持并行)。
- 查询节点执行准备 (Query Node):
- Query Node 接收任务。
- 检查缓存:所需 Segment 数据(向量、标量、索引)是否已在内存或本地 SSD 缓存中(热数据)。
- 冷数据加载:若不在缓存中,则从 Object Storage 拉取对应的 Segment 原始数据文件和索引文件到内存/缓存。
- 索引文件是什么? 是为加速搜索预先构建的数据结构文件(非原始数据)。例如:
- IVF 索引:存储聚类中心向量和各中心的向量 ID 列表。搜索时先找近邻中心,再在对应列表内精搜。
- HNSW 索引:存储向量间的多层图连接关系。搜索时在图上游走快速逼近目标。
- FLAT:无额外文件,直接暴力比较(最准但最慢)。
- 为什么单独存储? 分离存储节省内存、利用预计算优化、支持多种索引。
- 索引文件是什么? 是为加速搜索预先构建的数据结构文件(非原始数据)。例如:
- 本地搜索执行 (Query Node - 核心算子):
- 标量过滤算子:首先应用属性过滤条件 (如
price>100) 进行剪枝,得到候选向量 ID 集。 - ANN 搜索算子:在加载的索引文件结构上执行近似最近邻搜索(利用索引加速)。
- 向量距离计算算子:对 ANN 返回的候选向量,精确计算与查询向量的距离 (L2/IP/Cosine)。高度优化点 (多线程/GPU)。
- 局部 TopK 算子:基于精确距离,计算并保留当前 Query Node 负责的 Segment 数据中的局部 TopK 结果 (ID + 距离)。
- 标量过滤算子:首先应用属性过滤条件 (如
- 结果合并与返回 (Query Coord):
- Query Coord 收集所有 Query Node 返回的局部 TopK 结果。
- 全局 TopK 合并算子:使用最小堆等算法合并所有局部结果,得到最终的全局 TopK。
- 数据组装:若查询需要返回实体数据(非仅 ID 和距离),则从 Object Storage 或 Query Node 缓存中获取对应 ID 的完整字段。
- 结果返回:最终结果通过 Proxy 返回给客户端 SDK。
1.1.5 Milvus 数据处理流程
下面将复用Milvus官方的图片,我找不到比这个做的更清晰的图片了。
Milvus就像一个高度智能的物流分拣中心,它的核心任务有三个:高效接收包裹(数据插入)、为包裹建立智能目录(索引构建)、以及根据需求快速找出包裹(数据查询)。
数据插入
关于这个部分,原文是这样写的:您可以为 Milvus 中的每个 Collections 指定若干分片,每个分片对应一个虚拟通道(vchannel)。如下图所示,Milvus 会为日志代理中的每个 vchannel 分配一个物理通道(pchannel)。任何传入的插入/删除请求都会根据主键的哈希值路由到分片。
由于 Milvus 没有复杂的事务,因此 DML(Data Manipulation Language(数据操作符)) 请求的验证工作被前移到代理。代理会向 TSO(Timestamp Oracle)请求每个插入/删除请求的时间戳,TSO 是与根协调器共用的计时模块。由于旧的时间戳会被新的时间戳覆盖,因此时间戳可用于确定正在处理的数据请求的顺序。代理从数据协调器分批检索信息,包括实体的分段和主键,以提高总体吞吐量,避免中央节点负担过重。
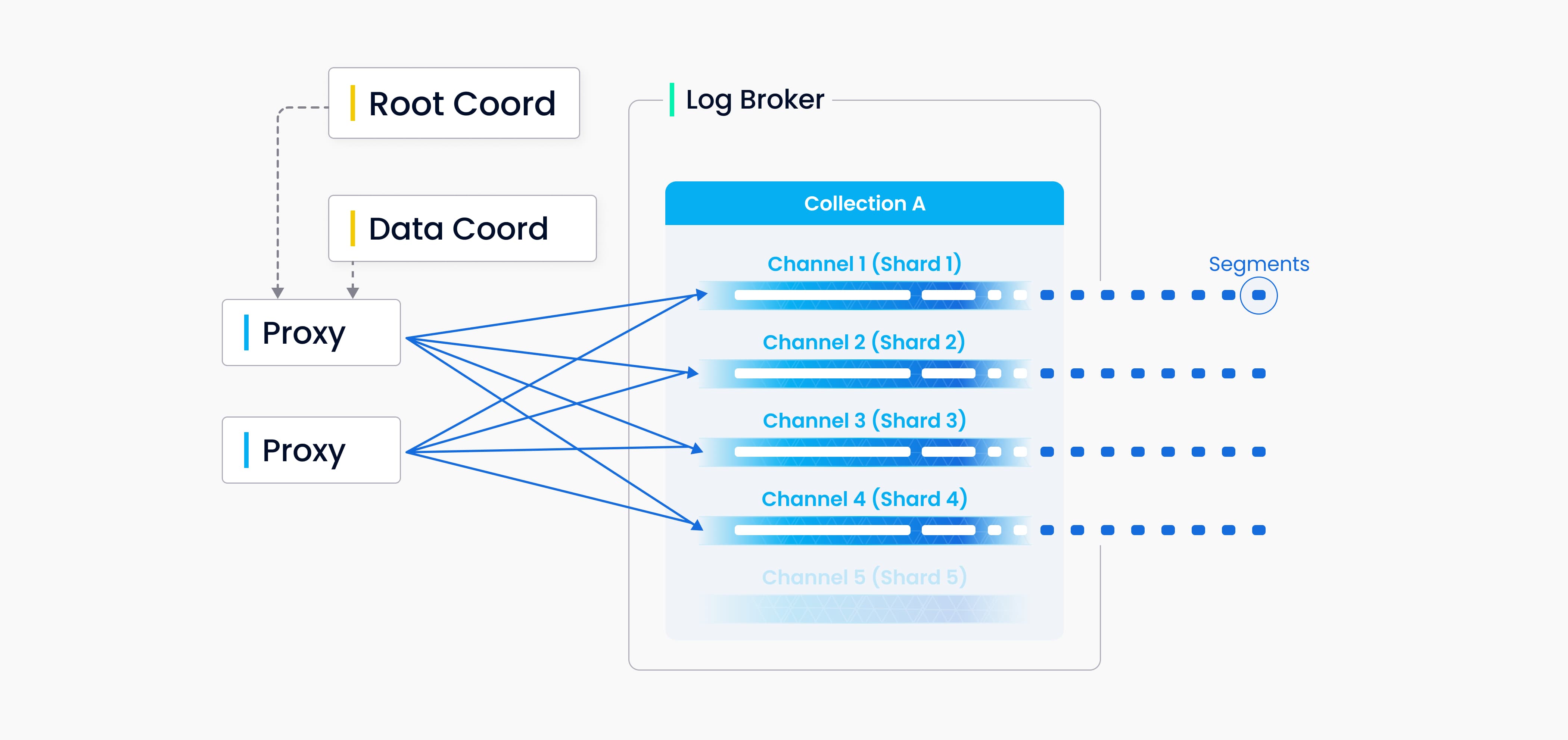
这张图里面包含很多名词,我们在这里再次回顾一下:
| 图中组件 | 核心职责 |
|---|---|
| Proxy (代理) | 接收应用程序发给milvus的请求,然后获取TSO时间戳,分发给数据 |
| Root Coord (根协调器) | 管理所有的元数据,发放TSO |
| Log Broker (日志代理) | 数据即日志,日志即数据,顺序的记录着所有数据 |
| Data Coord (数据协调器) | 管理图中的Collection A ,负责Collection中的Segment的创建和管理 |
| Channel 1-5 (通道) | Collection根据请求的Hash值划分Shard,每个Shard拥有一个独立的物理流水线(Channel),可以并行处理数据,互不阻塞 |
| Segments (分段) | Channel上的数据被打包处理为Segments,记录TSO后存入对象存储区域,等待创建索引 |
记住这些名词后,我们再来看这个图中的流程并且解释原文:
- 当我们发送一批数据(插入请求)时,系统不会堆在一起处理,代理Proxy会先去为这批数据领取一个全局唯一时间戳TSO,决定数据的先后顺序
- 然后系统会为你数据的主键计算hash值,然后就像根据邮编分拣一样,将你的数据分配到对应的虚拟通道(vchannel)。每个集合可以设置多个 vchannel 来并行处理数据
- 数据会被写入一个可靠的日志序列Log Broker,随后,数据节点会将日志转化为更容易处理的格式
- 最终 这些数据会被存储到对象存储,长期保存,并等待构建索引
DML(数据操作符)操作和 DDL(数据定义语言)操作都会写入日志序列,但 DDL 操作由于出现频率较低,因此只分配一个通道。
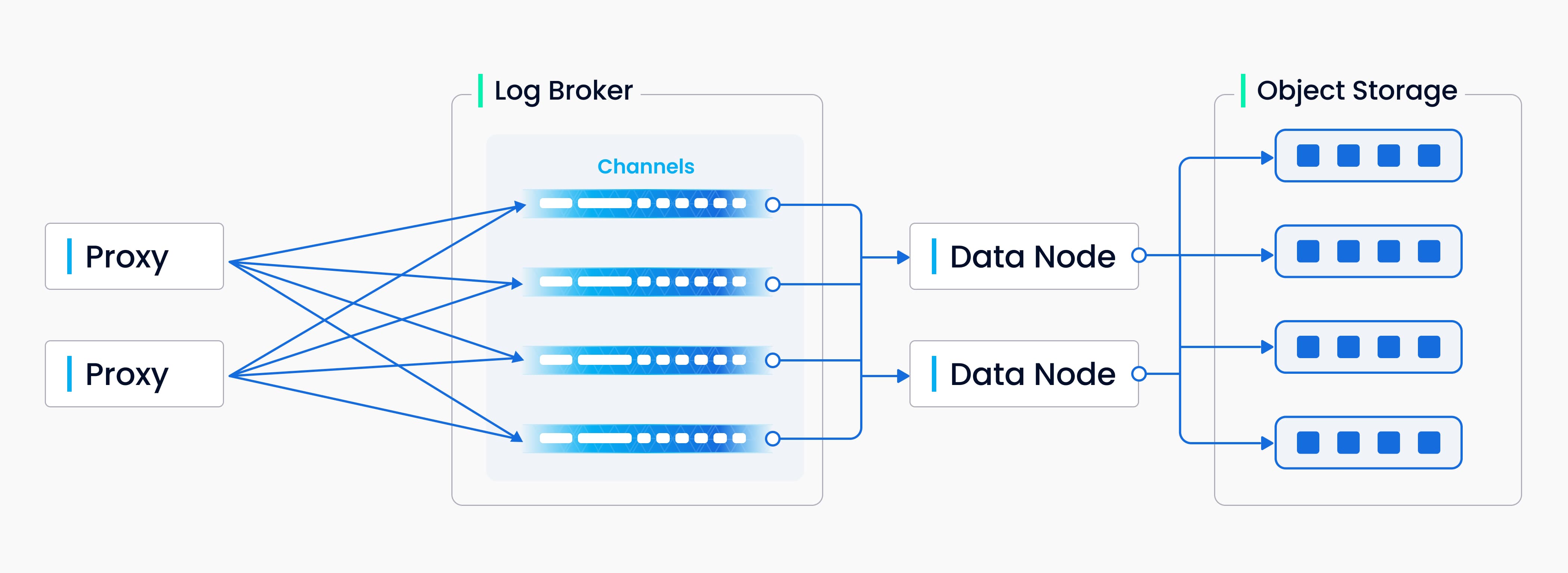
上图封装了写入日志序列过程中涉及的四个组件:代理、日志代理、数据节点和对象存储。该流程涉及四项任务:验证 DML 请求、发布-订阅日志序列、从流日志转换为日志快照,以及持久化日志快照。这四项任务相互解耦,以确保每项任务都由相应的节点类型来处理。同一类型的节点是平等的,可以灵活、独立地扩展,以适应各种数据负载,尤其是海量、高波动的流数据
索引构建
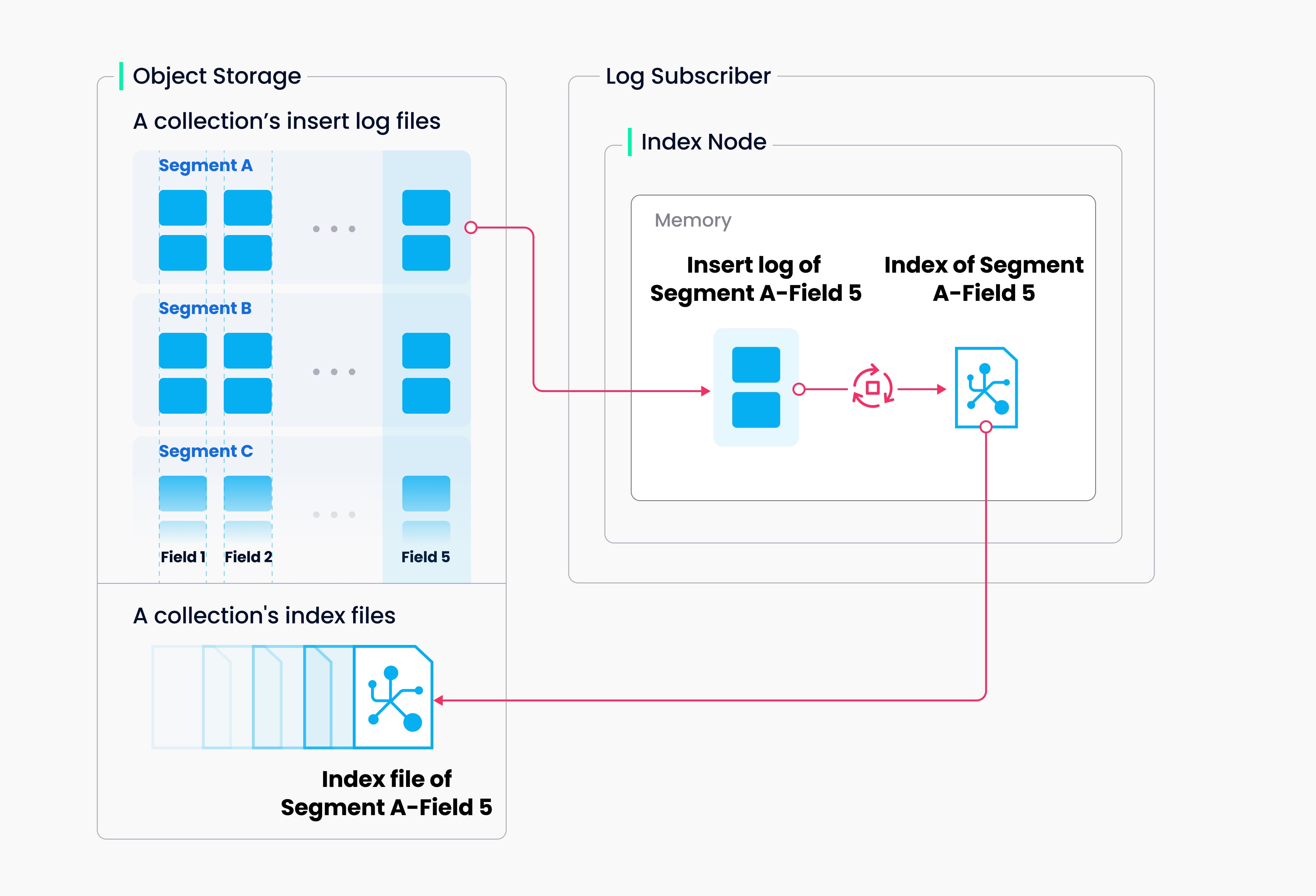
我们依然先看原文:Milvus 支持为每个向量场、标量场和主场建立索引。索引构建的输入和输出都与对象存储有关:索引节点将需要索引的日志快照从段(位于对象存储中)加载到内存,反序列化相应的数据和元数据以建立索引,索引建立完成后序列化索引,并将其写回对象存储。
索引构建主要涉及向量和矩阵操作,因此是计算和内存密集型操作。向量由于其高维特性,无法用传统的树形索引高效地建立索引,但可以用这方面比较成熟的技术建立索引,如基于集群或图形的索引。无论其类型如何,建立索引都涉及大规模向量的大量迭代计算,如 Kmeans 或图遍历。
与标量数据索引不同,建立向量索引必须充分利用 SIMD(单指令、多数据)加速。Milvus 天生支持 SIMD 指令集,例如 SSE、AVX2 和 AVX512。考虑到向量索引构建的 "打嗝 "和资源密集性质,弹性对 Milvus 的经济性而言变得至关重要。Milvus 未来的版本将进一步探索异构计算和无服务器计算,以降低相关成本。
总结一下:上一步数据被存储到对象存储,等待构建索引,索引节点从对象存储里面拉取需要处理的数据段(TSO会被发给IndexCoor的!),然后索引处理节点会把数据加载到内存并反序列化,并进行复杂的计算(比如IVF索引需要根据nprobe聚类),这里会充分运用到CPU的SIMD指令进行并行加速,也就是一条指令同时处理多个数据,之后构建好的索引被序列化后,再次写回对象存储,保存索引文件到??哪里呢?
哦吼,新的问题来了,此时的索引文件保存到哪里?
Milvus 本身不直接暴露索引文件的物理路径给用户,但索引数据确实会持久化存储在磁盘上。具体位置取决于你部署 Milvus 的方式和配置。
如果我们使用的milvus官方提供的docker-compose.yaml文件,那对象存储一般都是MinlO做的,我们的原始数据和索引文件都在这里
注意:这些文件是经过编码的二进制对象(由 MinIO 管理),不能直接读取或复用,必须通过 Milvus API 访问。
如果你是集群K8s部署,那数据就存储在你配置的PV(持久化存储Persistent Volume)
这里我们举个例子:我们存储了10w条数据进入milvus,构建了IVF索引,此时,如果我们删除了部分数据,索引会怎么变化呢?
简单来说:在 Milvus 中,删除向量数据后,对应的 IVF 索引本身不会自动、立即地改变,但索引的“逻辑视图”会更新,并且索引会在后续的查询中生效。
让我们分解一下这个过程:
- 删除操作发生时:逻辑删除,物理索引不变
当你执行数据删除时(如通过 delete),Milvus 并不会去物理上改写或重建已有的 IVF 索引文件。索引文件在磁盘上保持原样。系统只是在元数据中标记了哪些数据行(通过主键)被删除了。你可以把这理解为在索引目录上贴了一个“此条数据已失效”的标签,但目录本页并没有被撕掉(是不是和ES一样)。
这样做:
- 节省资源:避免了每次删除都触发耗时的索引重建。
- 快速响应:删除操作本身非常快。
- 搜索/查询时:索引的“过滤”机制生效
当你执行搜索时,Milvus 会同时利用索引和删除标记。流程是这样的:
- 系统通过 IVF 索引快速定位到距离目标向量最近的 nprobe 个聚类中心(倒排列表)。
- 从这些聚类中心对应的向量列表中检索候选向量。
- 在返回最终结果之前,系统会自动过滤掉那些已被标记为删除的向量。
- 你将得到未被删除的向量结果。
所以,索引作为“加速器”的功能不变,但它检索出的结果会经过“垃圾过滤器”的清洗。
- 索引的物理更新:通过 Compaction 或重建
为了回收被删除数据占用的存储空间、并优化后续查询性能,Milvus 会在后台自动或手动触发 Compaction 操作。
- 自动压缩:系统根据配置(如 enable_auto_compaction)自动合并数据段,在合并过程中,被删除的数据会被物理清除,并基于合并后的新数据生成新的索引。
- 手动重建:你也可以在数据发生大规模删除后,手动调用 compact 或对集合进行 reindex 来重建索引。
这个时刻,索引才会在物理上被更新,以完全反映当前有效的数据集状态。
1.1.6 关键架构优势与机制总结
- 读写分离:Data Node 专注写入吞吐,Query Node 专注查询延迟,通过 Object Storage 解耦。
- 流批一体:Log Broker 处理实时流,Object Storage 存储批数据,Query Node 通过订阅日志实现流批统一视图。
- 索引异步构建:写入路径只处理原始数据持久化,索引构建由 Index Node 异步完成,避免阻塞写入。
- 段(Segment)管理:Data Node 的 Compaction 算子 自动合并小 Segment 为大 Segment,优化查询效率(减少打开文件数,提升索引效率)。
- 一致性模型:基于 Root Coord 分配的 TSO (Timestamp Oracle) 实现 快照隔离 (Snapshot Isolation)。查询看到的是其开始时刻确定的快照视图,写入按全局顺序提交。
- 性能关注点:遇到性能瓶颈时,需重点考察:
- Log Broker 吞吐:是否成为写入瓶颈?
- Object Storage 延迟:冷数据加载和索引构建是否过慢?
- Query Node 资源:内存是否足够缓存热数据和索引?CPU/GPU 是否达到瓶颈?索引加载状态是否健康?
- 网络带宽:Data/Index/Query Node 与 Object Storage 间数据传输是否受限?
1.1.7 回顾与总结
回过头来,回顾一下各个组件的作用
各个组件分为三个部分,协调器(Coordinator)、Node、Storage组件。
协调器组件中包含Root Coordinator,用于分配全局唯一的TSO,并管理集合、分区的元数据;Data Coordinator,管理Segment,创建和状态切换,然后触发flush刷入数据,并且通知索引协调器构建索引;Query Coordinator查询协调器,负责负载均衡查询节点,管理segment的分布,即分布到不同的node上,合并全局Topk结果,这个topk是从各个query node中获取的局部topk的总和;Index Coordinator索引协调器,被data coordinator协调器调用,segment被构建后,会进行索引的构建任务,并且索引协调器会监控索引的构建状态。
Node组件中包含Data Node,被根协调器调用,用于消费Log Broker数据,管理内存缓冲区(缓存,用户之后查询节点query node的查询),Flush segment到Object Storage对象存储中;Query Node查询节点,被查询协调器所调用,当然,这些节点不止有一个,包括数据的node也是,可以采用并行的策略一起处理,Query Node首先加载Segment和Index file并执行本地搜索,这个搜索就是先过滤,分片数据,然后使用索引加速搜索,最后进行精确的L2或者IP的距离计算,获取topK作为该node的局部topk返回给协调器。Index Node索引节点用于构建索引文件,上传索引到对象存储,被数据协调器所调用,segment变化时,通知Index Node构建索引。
Storage组件中包含Log Broker,用于持久化数据变更日志,数据协调器中,新的数据一定是先存日志!Object Storage组件用于存储Segment的原始文件数据和Index file,这个部分会被查询流程中Query Node查询节点调用,然后在数据的存储流程中被Data Node调用,触发Index Coordinator进行索引构建Index Node,然后segment会被存入到Object Storage中;Metadata Storage组件,存储集合Schema、Segment分配信息、索引元数据,该组件首先在proxy部分就会被调用一次,因为要根据schema验证用户请求是否合法,然后在查询流程中根据 Metadata Storage 信息,确定哪些 Segment 包含目标数据
以上部分即为各个组件的作用以及相互之间的调用关系总结。至于流程,看我画的图吧。
1.1.8 补充 解惑
你可以注意到一个问题,查询协调器和数据协调器是两个不同的组件,虽然都被根协调器所管理,但地下的各个查询、存储节点都是独立的,当数据节点还在运行,查询节点也同样的在运行,那么如何保证Query Node查询的数据是最新的呢?
这就要得益于Log Broker的日志订阅机制+TSO+增量数据管理,
在此之前,所有的插入和删除操作都是先写入Log Broker中,每条操作分配一个全局递增的TSO。
- 日志订阅机制:当每个Query Node启动时,会向Data Coordinator数据协调器注册并订阅所负责的segment的Delta Channel日志通道(比如delta-collection-01),这个channel是Log Broker(比如Kafka)中存储增量变更的特殊Topic。
func stratQueryNode(){
channels := DataCoord.GetDmlChannels(colletcionId) // 从数据协调器获取DML通道列表
for _,ch := range channels{ // 遍历每个通道
//Query Node会持续的从Log Broker拉取日志(gRPC)。并且写入内存缓冲区(还没有被Flush到Object Storage)
go SubscirbeToDeltaChannel(ch) // 启动协程订阅增量数据通道
}
}在这个订阅下,消费的内容格式将为:
{
op_type: Insert, // 操作类型:插入
data:[vector1,id:100], // 插入的数据:向量和ID
tso:4500 // 全局时间戳
}
{
op_type: Delete, // 操作类型:删除
ids: [200,201], // 要删除的ID列表
tso: 4502 // 全局时间戳
}TSO全局一致性:当用户通过SDK发起请求后,进入Proxy网关代理,Proxy从Root Cooordinator中获取一个全局TSO,假如这次请求是用户查询请求,那可以设置ts_query = 5000,这个5000就作为整个流程下的时钟。
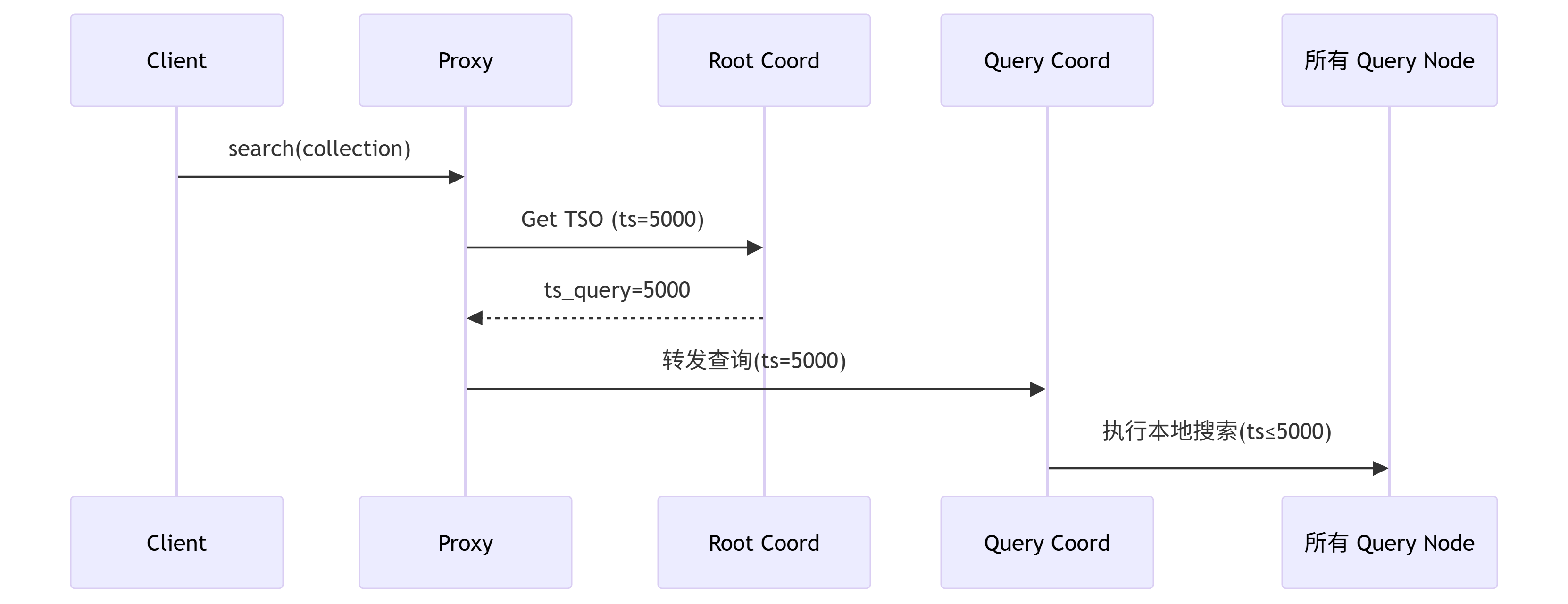
增量数据管理:首先你需要知道这些增量数据从哪里来,一是从Object Storage中存储的Segment文件(就是数据协调器创建的),二是由Query Node内存中增量生成的。我们消费这些数据是根据分配的TSO来消费的,对于来源一的数据,他的数据的范围即数据中tso <= Flush时间点,即这个数据的创建时间要比他入库Object Storage中的时间要小。对于来源二的数据,他的数据范围是 Flush时间点 < tso <= 当前tso
def execute_local_search(segment, ts_query):
# 1. 加载持久化数据(历史快照)
base_data = load_segment_from_storage(segment) # 从对象存储加载基础数据,ts ≤ flush_ts
# 2. 应用增量变更
delta_ops = delta_buffer.get_ops_range(flush_ts+1, ts_query) # 获取指定时间范围内的增量操作
for op in delta_ops: # 遍历每个增量操作
if op.is_insert: # 如果是插入操作
base_data.insert(op.data) # 将数据插入到基础数据集
elif op.is_delete: # 如果是删除操作
base_data.delete(op.ids) # 从基础数据集中删除指定ID的数据
# 3. 在合并后数据上执行搜索
return search_on_dataset(base_data) # 在合并后的完整数据集上执行搜索1.1.9 关键问题/挑战
看到这里,细心的小伙伴可以注意到,我们的数据都是存储到日志里面的,那我们查询的时候,万一查到过期的增量数据了怎么办,毕竟这些数据都在Log Broker里面,我们又没有执行删除。对于这个问题,Milvus的Delta Channel有一种叫做Checkpoit机制,该机制下,Data Coordinator会标记每一个Segment的seal time停止写入时间,当我们有一个Query Node订阅了该topic的时候,Query Node只需要消费
tso > checkpoint_ts的日志即可,避免了全量重放。上文go代码里面注释里面写道:我们Query Node会持续的从Log Broker拉取日志,并且写入内存缓冲区,注意此处还没有Flush到Object Storage中。那此时我们就有了一个问题:Flush到Object Storage的时候如何保证数据一致性呢? 对于这个问题,Milvus采用两段式切换策略,在该策略下,Data Node完成Flush后先通知Data Coordinator数据协调器,由数据协调器更新元数据
// etcd 元数据变更
{
"segment_id": 1001,
"state": "Flushed",
"flush_ts": 4500 // 新时间戳分水岭
}下面的Query Coordinator收到数据变更的通知后:要求Query Node停止使用旧的增量,比如这里的flush_ts=4500,那表示ts<=4500的数据以及被持久化存储到Object Storage中了,然后就可以加载新的Segment文件了。
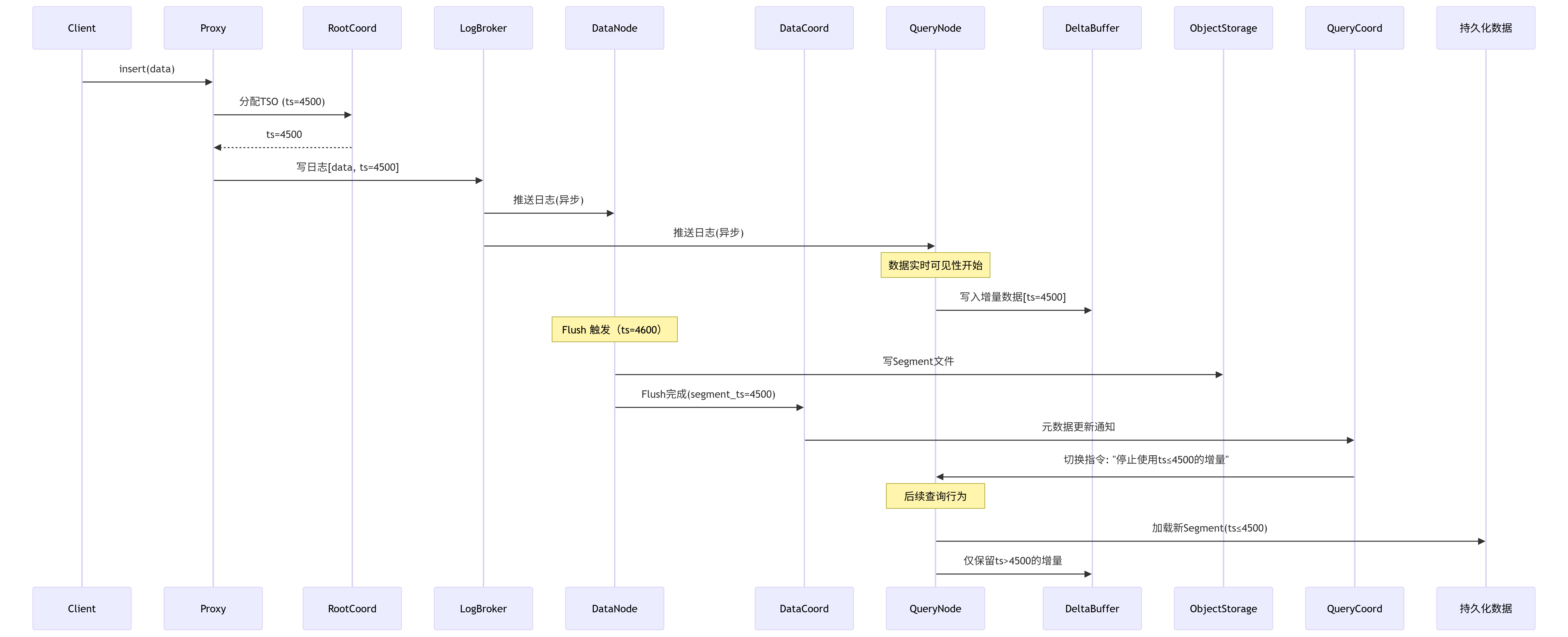
上图中,根协调器异步的将请求发送到查询协调器和数据协调器,或者说,这种发布-订阅的模式,使得查询节点和数据节点无需直接通信即可获取相同的数据变更,并且根据tso判断待处理的segment,这就保证了数据的实时性获取。但数据协调器和查询协调器又不是完全的互不关联的,两者通过etcd共享segment的状态(回过头想一想,哪一步用到了segment状态?)确保存储层和查询层对数据可见性达成共识。
最后,附带上基于Java实现的类Milvus架构的分布式向量数据库系统,包含TSO分发、Kafka日志消费、负载均衡等核心功能。