ANN搜索算法
聪明的你已经知道暴力搜索是如何工作的:当你要搜索一个向量时,它会计算这个查询向量与数据库中所有其他向量的相似度(如欧氏距离或余弦相似度),然后排序返回最相似的前K个结果.这种方法的优势在于结果的绝对准确性,因为它比较了所有可能性。但这也是其最大的劣势,因为计算成本与数据量成正比(O(N)复杂度) 。当数据量从几千增长到百万、千万甚至亿级时,一次查询的耗时可能从毫秒级增加到分钟、小时甚至无法接受,无法满足实时应用的需求。此外,在高维空间中,所有点对之间的距离会变得非常接近,这使得区分真正近邻的难度增加,暴力搜索的效率会进一步降低,这一现象被称为“维度灾难”。具体维度灾难是怎么影响向量搜索,可以详细查看【向量搜索算法基础】这一章节。
什么是ANN搜索? ANN(Approximate Nearest Neighbors)搜索是一种用于在高维空间中快速查找最近邻的算法。与暴力搜索不同,ANN搜索通过引入近似计算,在保持较高召回率的同时,显著减少了计算复杂度。ANN的核心价值在于解决了"维度灾难"问题——当数据维度和数量增加时,暴力搜索的计算复杂度呈指数级增长,而ANN通过巧妙的近似方法维持了可接受的搜索性能。
ANN算法之所以必要,正是为了打破暴力搜索在效率上的瓶颈。其核心思想是:牺牲微不足道的精度,换取数百倍甚至数千倍的速度提升。这并不是随意的妥协,而是通过智能的索引策略实现的。
1.索引类型
在向量搜索(Vector Search)中,索引(Index)是加速相似度检索的关键结构。 根据核心思想与数据组织方式,向量索引大体可以分为以下几大类👇
1.1空间划分类(Spatial Partitioning)
通过划分向量空间来减少搜索范围。 代表算法:
- IVF(Inverted File Index):使用 K-Means 将向量聚成多个簇(Cluster),搜索时只在最相近的几个簇内查找。
- K-D Tree / Ball Tree:以树结构递归划分空间,适合低维向量。
- Annoy(Approximate Nearest Neighbors Oh Yeah):基于多棵随机投影树(Random Projection Tree),在磁盘上高效存储,适合静态数据。
📌 特点:粗筛效果好,速度快,但在高维空间性能下降明显。
1.2图索引类(Graph-based Index)
通过构建 向量之间的邻接图(近邻关系) 来实现高效导航搜索。 代表算法:
- HNSW(Hierarchical Navigable Small World):分层小世界图结构,搜索从稀疏层向密集层逐步细化。
- NSG(Navigating Spreading-out Graph):通过优化边连接减少图复杂度,常用于工业大规模检索。
- NN-Descent:通过“近邻传播”逐步逼近KNN图,常用于HNSW或NSG的预构建阶段。
📌 特点:召回率高、延迟低,是目前性能最优的ANN索引类型之一。
1.3量化压缩类(Quantization-based Index)
通过压缩向量存储与近似距离计算来节省资源。 代表算法:
- PQ(Product Quantization):将高维向量分块并分别量化,使用短码近似表示原向量。
- OPQ(Optimized PQ):在PQ基础上增加旋转优化,使量化误差更小。
- SQ(Scalar Quantization):每个维度独立量化,简单但压缩率有限。
📌 特点:极大降低内存占用,适合海量数据和资源受限场景。
1.4哈希类(Hash-based Index)
通过哈希函数将相似向量映射到相同桶(Bucket),实现近似相似度检索。 代表算法:
- LSH(Locality Sensitive Hashing):通过特定哈希函数(如随机投影)保持相似性。
- SimHash / MinHash:用于文本或稀疏特征的快速相似度匹配。
📌 特点:计算简单、可并行,但召回率较低,常用于粗筛阶段。
1.5混合索引(Hybrid Index)
结合多种技术取长补短,以兼顾速度、精度与资源。 常见组合:
- IVF+PQ(FAISS 默认方案):先聚类再量化,平衡性能与存储。
- HNSW+PQ:在图索引基础上进行量化,适合大规模高维检索。
- DiskANN / SPANN:结合图索引与磁盘访问优化,用于超大规模数据。
📌 特点:工业级应用首选方案,广泛用于 Milvus、FAISS、Weaviate、Elasticsearch dense vector 等系统。
1.6基于磁盘或分布式的扩展索引
针对 超大规模数据(数十亿向量) 场景:
- DiskANN(Microsoft):图索引 + 顺序磁盘访问优化,可在TB级数据上实现亚秒级响应。
- SPANN(Microsoft):分布式向量搜索架构,结合多层索引与分区调度。
- ScaNN(Google):融合空间划分与量化,优化了ANN在TPU/GPU环境下的性能。
📌 特点:面向分布式、超大规模、云原生向量检索。
2.向量索引类型对比表
| 索引类型 | 代表算法 | 核心思想 | 优势 | 局限 |
|---|---|---|---|---|
| 空间划分类 | IVF, KD-Tree, Annoy | 空间划分 + 局部搜索 | 简单高效 | 高维退化 |
| 图索引类 | HNSW, NSG | 构建近邻图进行导航搜索 | 高召回率,低延迟 | 构建成本高,更新慢 |
| 量化压缩类 | PQ, OPQ, SQ | 向量压缩 + 近似距离计算 | 内存占用低,速度快 | 精度下降 |
| 哈希类 | LSH, SimHash | 哈希映射保持相似性 | 查询速度极快,可并行 | 召回率较低 |
| 混合索引 | IVF+PQ, HNSW+PQ | 融合多种索引优势 | 平衡速度、精度与存储 | 实现复杂,参数多 |
接下来,本节针对不同索引中的代表性算法进行详细介绍。
2.1 基于聚类的索引 (IVF)
IVF(Inverted File Index,倒排文件索引)是一种基于聚类思想的近似最近邻搜索方法。
它通过将整个向量空间划分为若干个簇(Cluster),并将每个向量分配到对应的簇中,从而在搜索时只需在与查询向量最相近的簇中进行查找,大幅减少搜索范围。
可以把 IVF 想象成在一个巨大的图书馆中找书的过程。
如果所有书籍都杂乱无章地堆在一起,你只能一本一本地翻查,这就相当于暴力搜索(Brute Force Search),效率极低。
而一个高效的图书馆,会先将书籍按照主题(如文学、历史、科学)分类摆放。这样,当你要找一本“物理学”相关的书时,只需去“科学”书架中查找即可——这正是 IVF 的工作原理。
IVF 采用的核心思想是 “分而治之(Divide and Conquer)”:
聚类阶段(索引构建):
使用聚类算法(如 K-Means)将所有向量划分成若干个簇,并记录每个簇的中心点(Centroid)。
每个向量只与其所属簇绑定,形成一种“倒排表”结构。搜索阶段(查询过程):
- 首先计算查询向量与所有簇中心的距离;
- 选出距离最近的几个簇(通常称为
nprobe); - 仅在这些簇内部进行精细的相似度计算。
这种策略大幅减少了需要比较的向量数量,使搜索效率相比暴力搜索实现指数级提升。
✅ IVF 的核心优势
- 高效率:只在部分簇内搜索,显著减少计算量;
- 易扩展:聚类结构清晰,适用于海量向量场景;
- 可组合性强:常与 PQ(Product Quantization)或 HNSW 等算法结合,进一步提升性能。
因此,IVF 是向量数据库(如 FAISS、Milvus)中最经典、最广泛使用的索引结构之一,为高维向量的高效检索奠定了基础。
2.2 基于图的索引 (HNSW)
HNSW(Hierarchical Navigable Small World,分层可导航小世界图)是一种基于图结构的近似最近邻搜索算法。
与 IVF 的“分而治之”思路不同,HNSW 采用的是“以图搜图”的策略——通过构建一个多层次的邻近关系图(近似小世界网络),让向量之间形成高效的导航路径,从而快速找到目标向量。
可以把 HNSW 想象成在一座多层迷宫城市中寻找目标位置的过程。
城市中的每一栋建筑代表一个向量,而道路代表这些向量之间的相似关系:
- 在最上层,只有少量的建筑和粗略的主干道,方便快速确定大致方向;
- 越往下层,建筑越来越多,道路也越来越密集,用于在局部区域中进行更精确的搜索。
当有一个查询向量进入系统时,算法会先从最高层开始,像在城市的高空俯瞰一样,快速确定一个靠近目标的大致位置;
然后逐层向下“着陆”,在更低层的图中进行局部搜索,直到找到最接近的向量。
这种“逐层缩小范围 + 层内局部精细搜索”的机制,使得 HNSW 能在极大程度上兼顾搜索的速度与精度。
相比 IVF 依赖聚类划分空间,HNSW 不需要显式的聚类步骤,而是通过构建稀疏的、层级化的图结构,使得每个节点既能快速跳转到远处的区域,又能在邻域内进行细粒度搜索。
这类似于人类在地图上先定位城市 → 再找街区 → 最后找到门牌号的过程。
✅ HNSW 的核心优势
- 高查准率:能在高维空间中保持较高的近似精度;
- 搜索高效:图结构天然支持“跳跃式”导航,能快速锁定目标区域;
- 动态可扩展:可以逐步插入新向量而无需完全重建索引。
因此,HNSW 已成为当今向量数据库(如 Milvus、FAISS、Weaviate 等)中性能最优、应用最广的索引结构之一。
2.3 量化技术 (PQ)
PQ(Product Quantization,乘积量化)是一种向量压缩与近似搜索技术,其核心目标是——在保证较高检索精度的同时,显著降低存储空间与计算成本。
它通常与 IVF 等索引结构结合使用(如 IVF-PQ),成为高效的近似最近邻搜索方案。
想象一下,你需要在上亿个高维向量中找到最相似的几个向量。
如果每个向量都要完整地存储和比对,那么不仅占用巨量内存,还会导致搜索时间暴涨。
PQ 的思路就像是“把复杂的向量拆开压缩成小片段,再在压缩后的空间中进行高效比较”。
🧩 PQ 的核心思想
PQ 通过一种“分块 + 量化”的策略来表示高维向量:
分块(Subspace Division)
将原始的高维向量(如 128 维)划分为若干个低维子空间(如 8 个 16 维子空间)。量化(Quantization)
对每个子空间单独进行聚类(如使用 K-Means),生成多个子码本(Codebook),每个向量在对应子空间中会被表示为一个聚类中心的编号。
最终,一个向量就不再以浮点数存储,而是以一组“索引编号”表示——大大减少存储空间。搜索阶段(Approximate Distance Computation)
在搜索时,PQ 不再计算完整的欧氏距离,而是通过预先计算的“查表法(Lookup Table)”快速估算向量间的距离,实现常数时间级别的相似度计算。
✅ PQ 的核心优势
- 极高的压缩率:可将原始向量存储空间压缩至原来的 1/10 甚至更少;
- 计算高效:通过查表法快速估算距离,极大减少计算量;
- 可组合性强:常与 IVF(IVF-PQ)、HNSW(HNSW-PQ)等索引结构结合,兼顾速度与精度。
💡 类比理解
可以把 PQ 想象成“把一本厚重的百科全书拆分成若干个主题册,然后只保留每册的索引编号”。
虽然你丢失了一些细节信息(近似计算),但通过这些编号,你依然能快速定位最相关的章节(相似向量)。
因此,PQ 是现代向量数据库中兼顾存储效率与搜索速度的关键技术之一,广泛应用于大规模向量检索场景,如图像检索、文本相似度匹配和推荐系统等。
2.4 基于哈希的索引 (Hash-based Index)
基于哈希(Hashing)的索引是一类通过哈希函数将高维向量映射为紧凑的二进制码的近似最近邻搜索方法。
它的核心思想是:相似的向量在哈希空间中应被映射到相似或相同的哈希码上,从而实现“以码代距”的快速近似搜索。
想象一下,你要在上亿张图片中找到与目标图片相似的几张。
如果每张图片都需要计算完整的特征距离,代价极高。
而哈希技术就像为每张图片打上一个“特征指纹”,相似的图片指纹也会相似。
这样,系统只需比较指纹之间的差异(哈希码距离),就能快速筛出候选结果。
⚙️ 哈希索引的核心思想
哈希方法的基本流程可分为三步:
哈希函数构建(Hash Function Design)
通过特定的哈希函数(如随机投影、学习哈希)将高维向量映射到低维二进制空间。例如,一个 128 维向量可能被映射成一个 64 位的二进制码。哈希码生成(Hash Code Generation)
每个向量被编码成固定长度的哈希码(如101010...),这相当于为每个数据生成唯一的“二进制身份标识”。哈希桶查找(Bucket Search)
检索时,系统根据查询向量的哈希码,直接查找与之相同或相近的哈希桶(Bucket)中的向量,而不必遍历所有数据。
相似度可通过哈希码之间的 汉明距离(Hamming Distance) 进行快速比较。
✅ 哈希技术的主要优势
- 速度极快:二进制运算和汉明距离计算可在硬件级实现,速度远高于传统距离计算;
- 存储高效:每个向量只需几个字节的哈希码,大幅减少内存占用;
- 适用于超大规模数据:可轻松应对上亿级别的向量检索任务。
⚠️ 哈希索引的局限
- 精度较低:哈希映射存在信息损失,可能导致部分近邻被错过;
- 难以自适应:传统随机哈希(如 LSH)无法很好适应数据分布。
因此,在现代向量数据库中,哈希方法往往与其他技术(如 IVF、PQ、HNSW)组合使用,用于粗筛阶段或快速预检索。
💡 类比理解
可以把哈希索引想象成为每个向量生成一张“指纹卡”。
当你需要找相似的对象时,不必看完整的照片(向量特征),
而是只需比对“指纹”是否相似(哈希码距离)。
虽然这种方法略有误差,但在大规模检索场景下,能以极低的成本实现惊人的搜索速度。
因此,基于哈希的索引是向量检索体系中最轻量、最快速的一类方案,
特别适合在早期阶段进行候选集快速过滤,再结合其他高精度索引进行精细搜索。
2.5 混合索引 (Hybrid Index)
混合索引(Hybrid Index)是一种 融合多种索引技术优势 的近似最近邻搜索方法。
它的设计目标是—— 在速度、精度、存储开销三者之间取得最优平衡 。
在实际的大规模向量检索系统中,单一索引往往难以同时满足所有需求,因此混合索引成为工业级系统的主流方案之一。
想象一下,你要在一座 超大型图书馆 中快速找到某个主题的书:
- 你可以先根据 主题分类(IVF) 确定大致区域;
- 再用 哈希指纹(Hashing) 快速筛掉无关的书;
- 最后通过 精确匹配或量化比较(PQ/HNSW) 确定最相似的几本。
这套多层过滤与精细查找结合的机制,就是混合索引的核心思想。
⚙️ 混合索引的常见组合形式
IVF + PQ(最经典组合)
- 先用 IVF 将向量空间划分为多个簇;
- 再在每个簇内部使用 PQ 对向量进行压缩存储与快速距离估计。
✅ 兼顾了搜索速度与内存效率,广泛应用于 FAISS、Milvus 等系统。
HNSW + PQ
- HNSW 提供高精度的图结构导航;
- PQ 用于减少存储占用与计算量。
✅ 适合高精度要求但资源受限的场景。
IVF + HNSW
- IVF 用于粗粒度聚类分区;
- HNSW 用于分区内的精细图搜索。
✅ 同时提升搜索速度与局部召回率。
Hash + IVF 或 Hash + HNSW
- 先用哈希快速过滤候选;
- 再使用更精细的索引算法进行高精度检索。
✅ 适合亿级以上规模的向量预筛阶段。
✅ 混合索引的核心优势
- 性能均衡:融合不同算法优点,在速度、精度、资源占用之间取得最佳折中;
- 灵活可配置:可根据场景灵活组合组件(如粗检 + 精检);
- 可扩展性强:支持增量更新与多层次结构优化;
- 工程实用性高:已成为向量数据库的主流选择(如 Milvus 的 IVF_PQ、HNSW_PQ、Hybrid Index 等实现)。
💡 类比理解
可以把混合索引理解为一套多阶段检索系统:
像机场安检一样,
- 第一关快速筛查(哈希/聚类),
- 第二关重点检测(量化/图搜索),
- 最后一关人工复核(精确比对)。
这种多层次策略既能保持高效率,又能确保搜索结果的高质量。
因此,混合索引(Hybrid Index)代表了当前向量检索领域的工程最佳实践,
是连接理论算法与实际应用性能的关键桥梁。
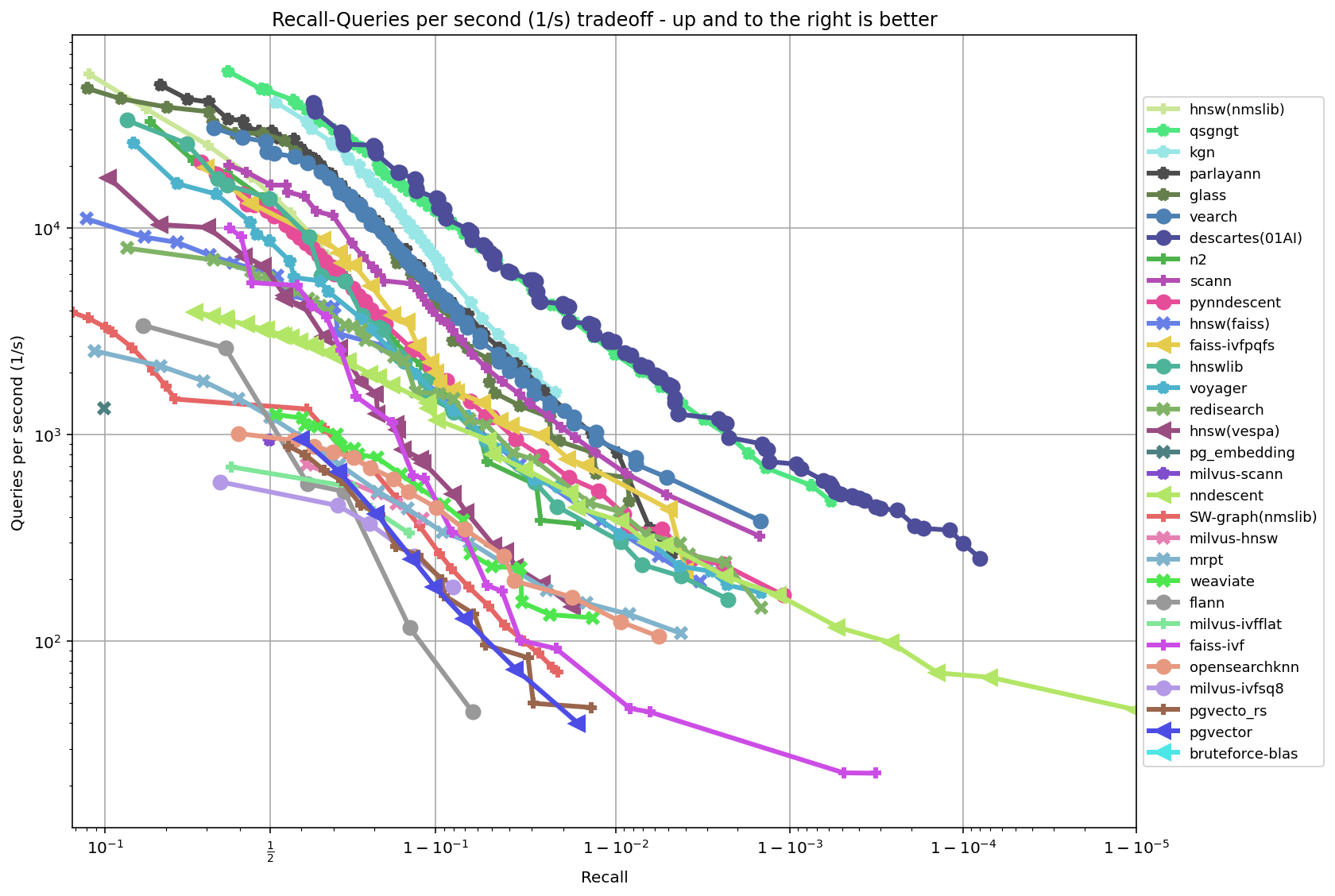 在单CPU上的ANN基准测试对比图
在单CPU上的ANN基准测试对比图
TIP
本节ANN算法相关代码ipynb:https://github.com/datawhalechina/easy-vectordb/tree/main/src/ANN_alorithms