YoutubeDNN Tutorial
1. Model Overview and Use Cases
YoutubeDNN is the deep retrieval model proposed by Google at RecSys 2016 and is one of the core components of the YouTube recommendation system. Unlike DSSM, YoutubeDNN uses list-wise training with sampled softmax style objectives. In the original paper, the item side is usually represented by an embedding table rather than a deep DNN tower.
Paper: Deep Neural Networks for YouTube Recommendations
Model Architecture
- User Tower: maps user profile + behavior sequence to a user embedding
- Item Tower: directly uses item embedding
- Training: list-wise training with softmax over positive + negative items
- Negative Sampling: other items in the same batch or sampled negatives are used as negatives
Suitable Scenarios
- Large-scale candidate retrieval
- Content / video recommendation systems
- Scenarios with rich user behavior sequences
- Retrieval tasks that benefit from list-wise optimization
2. Data Preparation and Preprocessing
This example uses the MovieLens-1M dataset and builds list-wise training data with mode=2.
import os
import pandas as pd
import torch
from sklearn.preprocessing import LabelEncoder
from torch_rechub.basic.features import SparseFeature, SequenceFeature
from torch_rechub.utils.data import MatchDataGenerator, df_to_dict
from torch_rechub.utils.match import gen_model_input, generate_seq_feature_match
data = pd.read_csv("examples/matching/data/ml-1m/ml-1m_sample.csv")
for col in ["user_id", "movie_id", "gender", "age", "occupation", "zip"]:
data[col] = LabelEncoder().fit_transform(data[col])
# mode=2: list-wise negative sampling, negatives are stored in "neg_items"
train, test = generate_seq_feature_match(
data,
user_col="user_id",
item_col="movie_id",
time_col="timestamp",
item_attribute_cols=[],
sample_method=0,
mode=2,
)
# List-wise training: the label is always 0 because the first position is the positive item.
train_user_input, train_item_input, y_train = gen_model_input(train, mode=2, seq_max_len=50)
test_user_input, test_item_input, y_test = gen_model_input(test, mode=2, seq_max_len=50)Define Features
# User features = user profile + history sequence
user_features = [
SparseFeature("user_id", vocab_size=data["user_id"].max() + 1, embed_dim=16),
SparseFeature("gender", vocab_size=data["gender"].max() + 1, embed_dim=8),
SequenceFeature("hist_movie_id", vocab_size=data["movie_id"].max() + 1, embed_dim=16, pooling="mean"),
]
# Item features (only movie_id embedding)
item_features = [
SparseFeature("movie_id", vocab_size=data["movie_id"].max() + 1, embed_dim=16),
]
# Negative item features
neg_item_feature = [
SequenceFeature("neg_items", vocab_size=data["movie_id"].max() + 1, embed_dim=16, pooling="concat", shared_with="movie_id")
]# Create DataLoader
dg = MatchDataGenerator(x=train_user_input, y=y_train)
train_dl, test_dl, item_dl = dg.generate_dataloader(
x_test=test_user_input,
y_test=y_test,
item_dataset=df_to_dict(data[["movie_id"]].drop_duplicates("movie_id")),
batch_size=256,
num_workers=0,
)3. Model Configuration and Parameter Notes
3.1 Create the Model
from torch_rechub.models.matching import YoutubeDNN
model = YoutubeDNN(
user_features=user_features,
item_features=item_features,
neg_item_feature=neg_item_feature,
user_params={"dims": [128, 64, 16]},
temperature=0.02,
)3.2 Parameter Details
neg_item_featureis required for list-wise training- The negative item sequence should use
pooling="concat"so the sampled negatives are preserved explicitly temperaturecontrols the softness of the sampled softmax logits
4. Training Process and Code Example
from torch_rechub.trainers import MatchTrainer
os.makedirs("./saved/youtube_dnn", exist_ok=True)
trainer = MatchTrainer(
model,
mode=2,
optimizer_params={"lr": 1e-4, "weight_decay": 1e-6},
n_epoch=5,
device="cpu",
model_path="./saved/youtube_dnn",
)
trainer.fit(train_dl)DSSM vs YoutubeDNN Training Mode
DSSMcommonly usesmode=0YoutubeDNNcommonly usesmode=2with list-wise negatives
5. Evaluation and Result Analysis
# Generate embeddings
user_embedding = trainer.inference_embedding(model=trainer.model, mode="user", data_loader=test_dl)
item_embedding = trainer.inference_embedding(model=trainer.model, mode="item", data_loader=item_dl)YoutubeDNN often performs better than DSSM when list-wise objectives and richer negative sampling matter.
6. Tuning Suggestions
- Start by tuning the number of negatives and the user tower dimensions
- When training is unstable, increase
temperatureslightly or lower the learning rate
6.1 Vector Retrieval and Deployment
# Option 1: Annoy for fast local prototyping
# Option 2: Faiss for higher-performance retrieval
# Save the built index for online serving7. Model Visualization
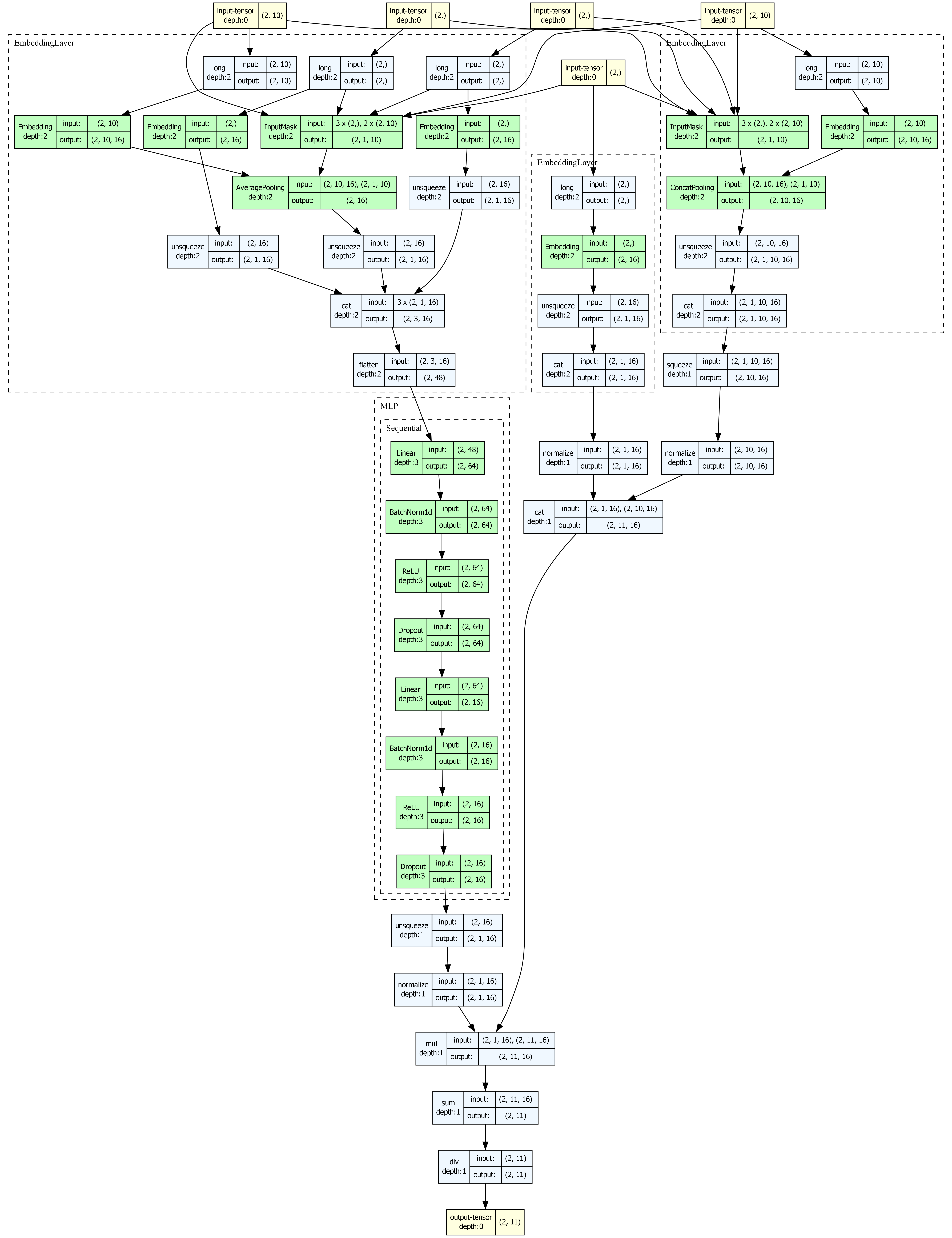
from torch_rechub.utils.visualize import visualize_model
# Automatically generate inputs and visualize
visualize_model(model, save_dir="./visualization", model_name="youtube_dnn")YoutubeDNN Architecture
YoutubeDNN is a good retrieval model to visualize because the training objective and the online serving pattern are both intuitive.
8. ONNX Export
# Export user tower / item tower separately for deployment
trainer.export_onnx("./saved/youtube_dnn/youtube_dnn.onnx", data_loader=test_dl, dynamic_batch=True)9. FAQ and Troubleshooting
Q1: What is the main difference between YoutubeDNN and DSSM?
YoutubeDNN is usually trained in list-wise mode, while DSSM is a more standard two-tower matching baseline.
Q2: Why is y_train all zeros?
In list-wise training, the positive item is placed at the first position, so the label is always index 0.
Q3: Why should neg_item_feature use pooling="concat"?
Because the model needs to keep the whole list of sampled negatives rather than a pooled summary.
Q4: How do I export ONNX for online serving?
The standard production pattern is to export the user side for online inference and the item side for offline batch embedding generation.
Full Example
The code blocks above form a complete runnable example. For a full MovieLens-based script, see examples/matching/run_ml_youtube_dnn.py.