Production Deployment Overview
Torch-RecHub provides a complete production deployment solution, supporting deployment of trained models to production environments.
Deployment Process Overview
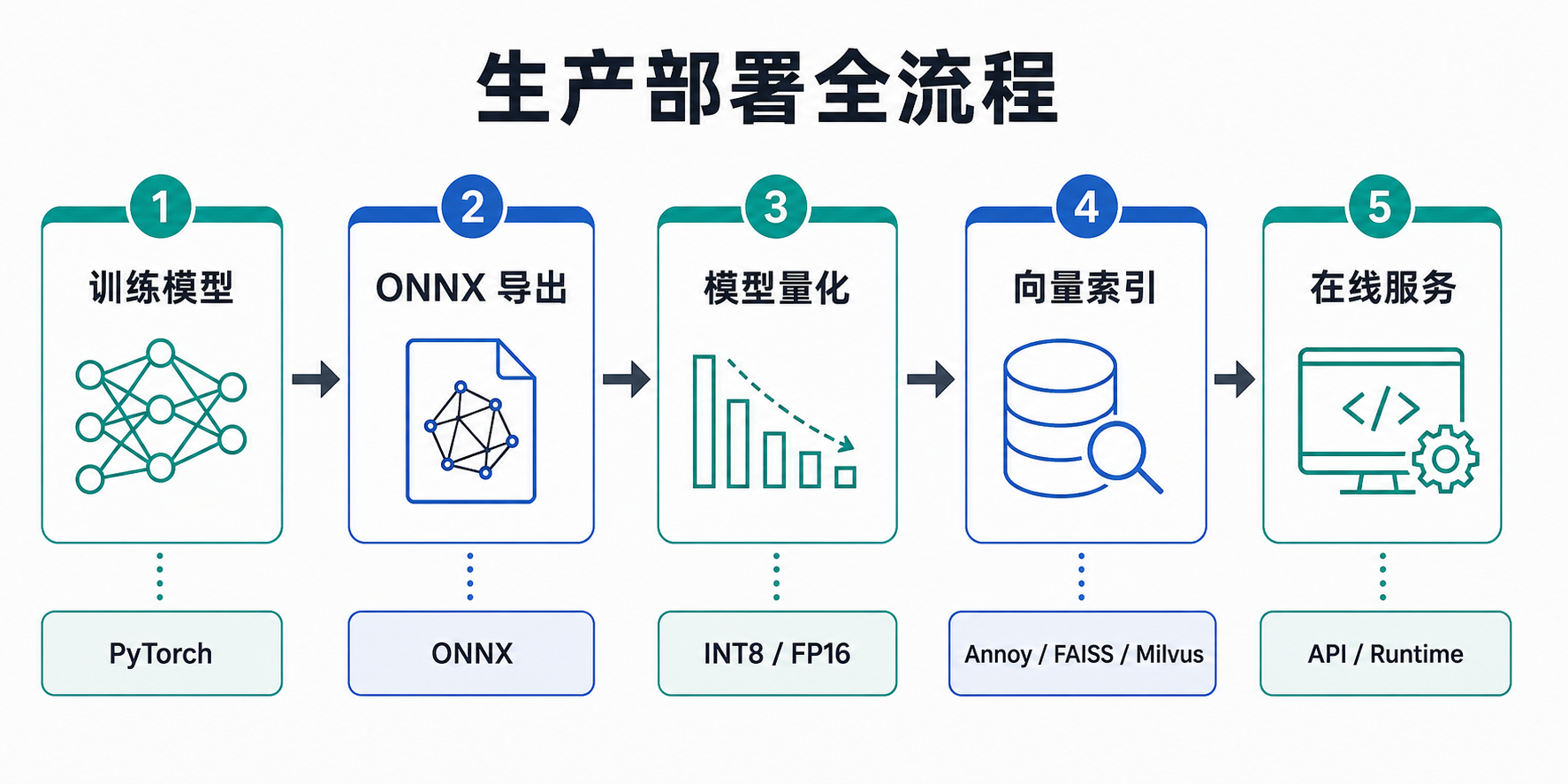
Core Features
| Feature | Description | Documentation |
|---|---|---|
| ONNX Export | Export PyTorch models to ONNX format | ONNX Export & Quantization |
| Model Quantization | INT8/FP16 quantization to reduce inference latency | ONNX Export & Quantization |
| Vector Retrieval | Annoy/FAISS/Milvus vector indexing | Vector Retrieval |
| Online Service | Deployment examples and best practices | Online Service Demo |
Quick Start
1. ONNX Export
python
from torch_rechub.trainers import CTRTrainer
# Export after training
trainer.export_onnx("model.onnx")
# Export two-tower models separately
trainer.export_onnx("user_tower.onnx", mode="user")
trainer.export_onnx("item_tower.onnx", mode="item")2. Model Quantization
python
from torch_rechub.utils import quantize_model
# INT8 quantization (recommended for CPU)
quantize_model("model_fp32.onnx", "model_int8.onnx", mode="int8")
# FP16 quantization (recommended for GPU)
quantize_model("model_fp32.onnx", "model_fp16.onnx", mode="fp16")3. Vector Retrieval
python
from torch_rechub.serving import builder_factory
# Create FAISS index
builder = builder_factory("faiss", index_type="HNSW", metric="IP")
with builder.from_embeddings(item_embeddings) as indexer:
ids, distances = indexer.query(user_embeddings, top_k=10)
indexer.save("item.index")Deployment Architecture Recommendations
Ranking Model Deployment
User Request → Feature Service → ONNX Runtime → Ranking ResultsMatching Model Deployment
User Request → User Tower Inference → Vector Retrieval → Retrieval Results
↓
Item Tower Offline Computation → Vector IndexNext Steps
- Learn about ONNX Export & Quantization in detail
- Learn about Vector Retrieval configuration
- Check Online Service Demo for complete deployment workflow