数据流水线
Torch-RecHub提供了完整的数据处理流水线,包括数据集类、数据生成器和工具函数,用于处理推荐系统中的各种数据需求。
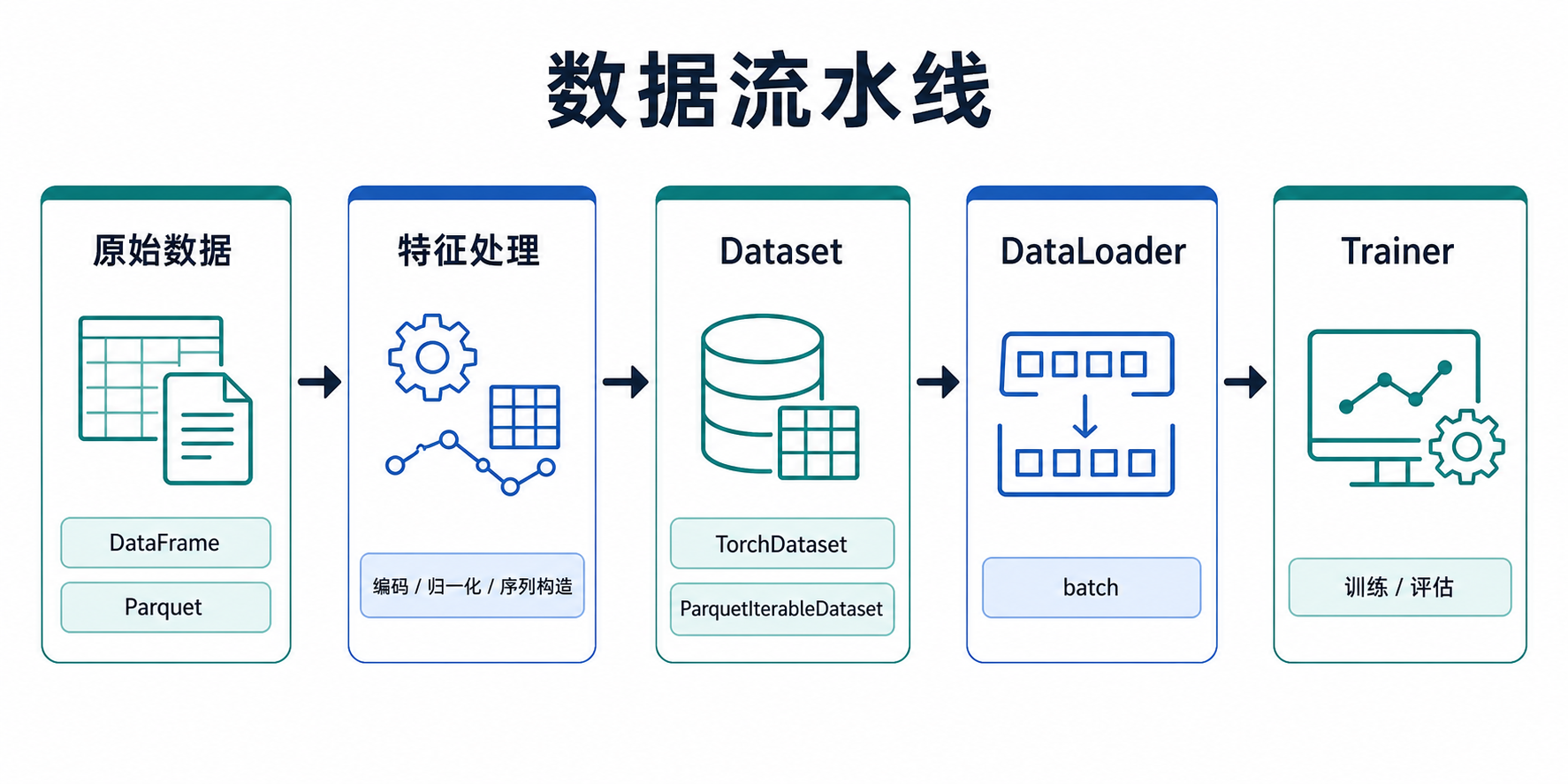
数据类
TorchDataset
用于训练和验证的数据集合,包含特征和标签。
python
from torch_rechub.utils.data import TorchDataset
# 创建数据集
dataset = TorchDataset(x, y)参数说明:
x:特征字典,键为特征名称,值为特征数据y:标签数据
PredictDataset
用于预测的数据集合,仅包含特征。
python
from torch_rechub.utils.data import PredictDataset
# 创建预测数据集
dataset = PredictDataset(x)参数说明:
x:特征字典,键为特征名称,值为特征数据
数据生成器
DataGenerator
用于生成排序模型和多任务模型的数据加载器。
python
from torch_rechub.utils.data import DataGenerator
# 创建数据生成器
dg = DataGenerator(x, y)
# 生成数据加载器
train_dl, val_dl, test_dl = dg.generate_dataloader(
split_ratio=[0.7, 0.1], # 训练集:验证集:测试集比例
batch_size=256, # 批次大小
num_workers=8 # 并行工作线程数
)参数说明:
x:特征数据y:标签数据
generate_dataloader方法参数:
split_ratio:数据分割比例,长度为2batch_size:批次大小num_workers:并行工作线程数
MatchDataGenerator
用于生成召回模型的数据加载器。
python
from torch_rechub.utils.data import MatchDataGenerator
# 创建召回数据生成器
dg = MatchDataGenerator(x, y)
# 生成数据加载器
train_dl, test_dl, item_dl = dg.generate_dataloader(
x_test_user=x_test_user, # 测试用户数据
x_all_item=x_all_item, # 所有物品数据
batch_size=256, # 批次大小
num_workers=8 # 并行工作线程数
)参数说明:
x:特征数据y:标签数据,可选
generate_dataloader方法参数:
x_test_user:测试用户数据x_all_item:所有物品数据batch_size:批次大小num_workers:并行工作线程数
工具函数
get_auto_embedding_dim
根据类别数量自动计算嵌入向量长度。
python
from torch_rechub.utils.data import get_auto_embedding_dim
# 自动计算嵌入向量长度
embed_dim = get_auto_embedding_dim(vocab_size=1000)参数说明:
num_classes:类别数量
返回值:
- 嵌入向量长度,计算公式:
int(np.floor(6 * np.pow(num_classes, 0.25)))
get_loss_func
根据任务类型获取对应的损失函数。
python
from torch_rechub.utils.data import get_loss_func
# 获取分类任务损失函数
loss_func = get_loss_func(task_type="classification")
# 获取回归任务损失函数
loss_func = get_loss_func(task_type="regression")参数说明:
task_type:任务类型,可选值:classification(分类)、regression(回归)
返回值:
- 对应的损失函数实例
Parquet 流式数据加载
在工业界场景中,特征工程通常由 PySpark 在大数据集群上完成,数据量可达 GB 到 TB 级别。直接使用 spark_df.toPandas() 会导致 Driver OOM。
Torch-RecHub 提供 ParquetIterableDataset,支持从 Spark 生成的 Parquet 文件目录流式读取数据,无需将全部数据加载到内存。
安装依赖
Parquet 数据加载需要 pyarrow:
bash
pip install pyarrowParquetIterableDataset
继承自 torch.utils.data.IterableDataset,支持多进程数据加载。
python
from torch.utils.data import DataLoader
from torch_rechub.data import ParquetIterableDataset
# 创建流式数据集
dataset = ParquetIterableDataset(
["/data/train1.parquet", "/data/train2.parquet"],
columns=["user_id", "item_id", "label"], # 可选,指定读取的列
batch_size=1024, # 每批次读取的行数
)
# 创建 DataLoader(注意 batch_size=None)
loader = DataLoader(dataset, batch_size=None, num_workers=4)
# 迭代数据
for batch in loader:
user_id = batch["user_id"] # torch.Tensor
item_id = batch["item_id"] # torch.Tensor
label = batch["label"] # torch.Tensor参数说明:
file_paths:Parquet 文件路径列表columns:要读取的列名列表,None表示读取所有列batch_size:每批次读取的行数,默认 1024
特性:
- 流式读取:使用 PyArrow Scanner 逐批读取,内存占用恒定
- 多进程支持:自动将文件分配给不同 worker,避免重复读取
- 类型转换:自动将 PyArrow 数组转换为 PyTorch Tensor
- 嵌套数组支持:支持 Spark 的
Array类型列,自动转换为 2D Tensor
与 Spark 配合使用
python
# ========== Spark 端 ==========
# df.write.parquet("/data/train.parquet")
# ========== PyTorch 端 ==========
import glob
from torch_rechub.data import ParquetIterableDataset
file_paths = glob.glob("/data/train.parquet/*.parquet")
dataset = ParquetIterableDataset(file_paths, batch_size=2048)
loader = DataLoader(dataset, batch_size=None, num_workers=8)支持的数据类型
| Parquet/Arrow 类型 | 转换结果 |
|---|---|
| int8/16/32/64 | torch.float32 |
| float32/64 | torch.float32 |
| boolean | torch.float32 |
| list/array | torch.Tensor (2D) |
注意:嵌套数组(如 Spark 的
Array<Float>)要求每行长度相同,否则会抛出ValueError。
数据处理流程
- 特征定义:使用DenseFeature、SparseFeature、SequenceFeature定义特征
- 数据加载:加载原始数据
- 特征编码:对类别型特征进行LabelEncoder编码
- 序列处理:对序列特征进行填充、截断等处理
- 样本构造:构造训练样本,包括负采样等
- 数据生成:使用DataGenerator或MatchDataGenerator生成数据加载器
- 模型训练:将数据加载器传入模型进行训练