Data Pipeline
Torch-RecHub offers datasets, generators, and utilities for recommendation data.
Datasets
TorchDataset
Training/validation dataset with features and labels.
from torch_rechub.utils.data import TorchDataset
dataset = TorchDataset(x, y)PredictDataset
Prediction-only dataset (features only).
from torch_rechub.utils.data import PredictDataset
dataset = PredictDataset(x)Data Generators
DataGenerator
Build dataloaders for ranking / multi-task models.
from torch_rechub.utils.data import DataGenerator
dg = DataGenerator(x, y)
train_dl, val_dl, test_dl = dg.generate_dataloader(
split_ratio=[0.7, 0.1],
batch_size=256,
num_workers=8,
)MatchDataGenerator
Build dataloaders for matching/retrieval models.
from torch_rechub.utils.data import MatchDataGenerator
dg = MatchDataGenerator(x, y)
train_dl, test_dl, item_dl = dg.generate_dataloader(
x_test_user=x_test_user,
x_all_item=x_all_item,
batch_size=256,
num_workers=8,
)Utilities
get_auto_embedding_dim
Compute embedding dim from vocab size: int(floor(6 * num_classes**0.25)).
from torch_rechub.utils.data import get_auto_embedding_dim
embed_dim = get_auto_embedding_dim(vocab_size=1000)get_loss_func
Return default loss by task type: BCELoss for classification, MSELoss for regression.
from torch_rechub.utils.data import get_loss_func
loss_fn = get_loss_func(task_type="classification")Parquet Streaming Dataset
In industrial scenarios, feature engineering is typically done by PySpark on big data clusters, with data volumes reaching GB to TB scale. Using spark_df.toPandas() directly causes Driver OOM.
Torch-RecHub provides ParquetIterableDataset for streaming Parquet files generated by Spark without loading all data into memory.
Installation
Parquet data loading requires pyarrow:
pip install pyarrowParquetIterableDataset
Inherits from torch.utils.data.IterableDataset with multi-worker support.
from torch.utils.data import DataLoader
from torch_rechub.data import ParquetIterableDataset
dataset = ParquetIterableDataset(
["/data/train1.parquet", "/data/train2.parquet"],
columns=["user_id", "item_id", "label"], # Optional
batch_size=1024,
)
loader = DataLoader(dataset, batch_size=None, num_workers=4)
for batch in loader:
user_id = batch["user_id"] # torch.Tensor
item_id = batch["item_id"] # torch.Tensor
label = batch["label"] # torch.TensorParameters:
file_paths: List of Parquet file pathscolumns: Column names to read;Nonereads all columnsbatch_size: Rows per batch (default: 1024)
Features:
- Streaming: Uses PyArrow Scanner for constant memory usage
- Multi-worker: Automatically partitions files across workers
- Type conversion: Converts PyArrow arrays to PyTorch Tensors
- Nested arrays: Supports Spark
Arraycolumns as 2D Tensors
Working with Spark
# ========== Spark Side ==========
# df.write.parquet("/data/train.parquet")
# ========== PyTorch Side ==========
import glob
from torch_rechub.data import ParquetIterableDataset
file_paths = glob.glob("/data/train.parquet/*.parquet")
dataset = ParquetIterableDataset(file_paths, batch_size=2048)
loader = DataLoader(dataset, batch_size=None, num_workers=8)Supported Types
| Parquet/Arrow Type | Result |
|---|---|
| int8/16/32/64 | torch.float32 |
| float32/64 | torch.float32 |
| boolean | torch.float32 |
| list/array | torch.Tensor (2D) |
Note: Nested arrays require equal row lengths; otherwise raises
ValueError.
Typical Flow
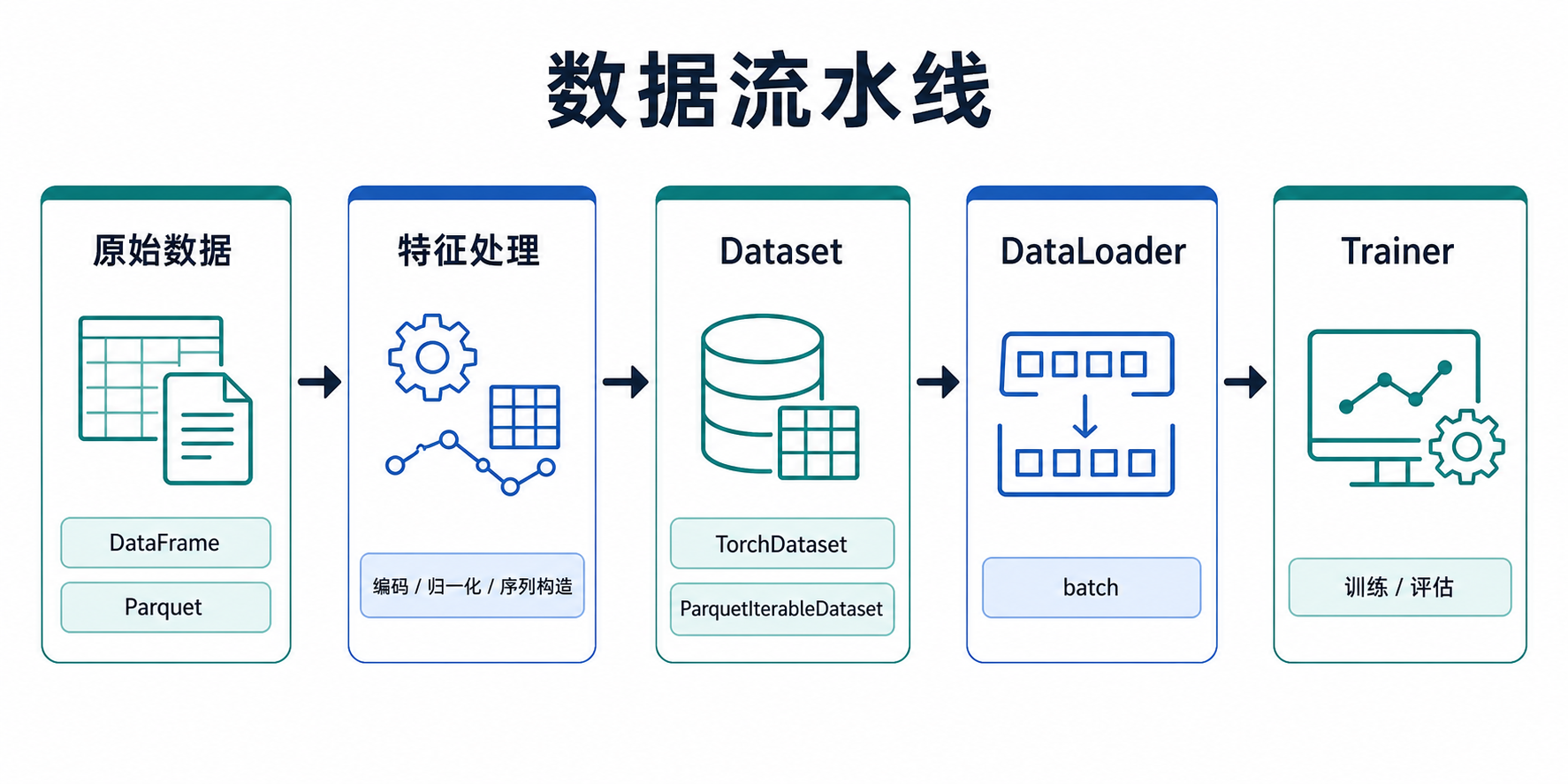
- Define features (Dense/Sparse/Sequence).
- Load raw data.
- Encode categorical features (e.g., LabelEncoder).
- Process sequences (pad/truncate).
- Construct samples (e.g., negative sampling).
- Use DataGenerator / MatchDataGenerator to build dataloaders.
- Train models with the trainers.