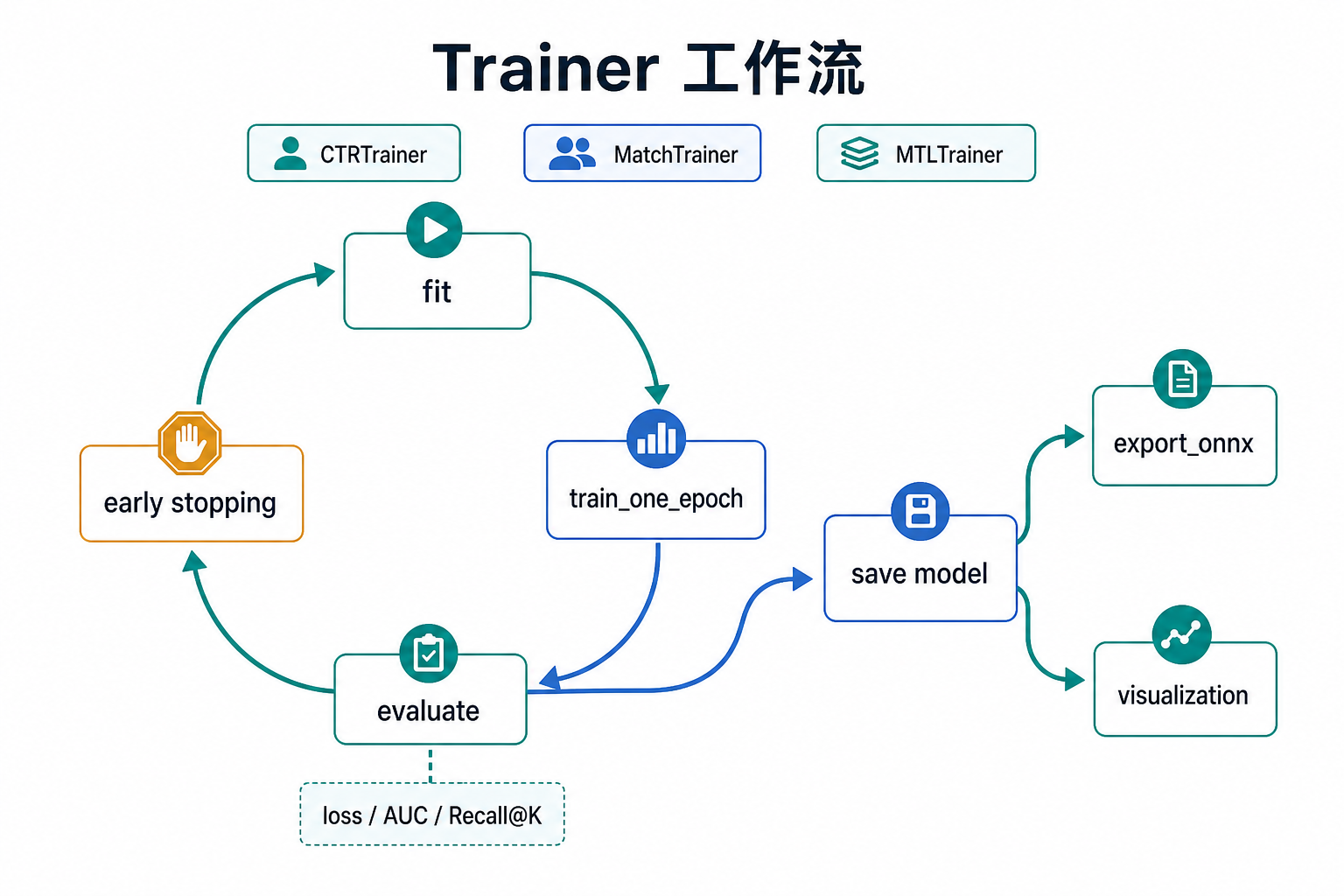
训练与评估
Torch-RecHub提供了多种训练器,用于训练不同类型的推荐模型,包括排序模型、召回模型和多任务模型。所有训练器均提供统一的接口,包括训练、评估、预测、ONNX导出,以及可选的实验跟踪与可视化能力。
实验跟踪与可视化
- 支持 WandB / SwanLab / TensorBoardX 作为
model_logger,可传入单个实例或列表。 - 自动记录训练/验证指标与超参数:
train/loss、learning_rate、val/auc(CTR/Match)、val/task_i_score(MTL)、val/accuracy(Seq)。 - 不需要记录时传
model_logger=None(默认)即可零开销。
python
from torch_rechub.basic.tracking import WandbLogger, TensorBoardXLogger
from torch_rechub.trainers import CTRTrainer
wb = WandbLogger(project="rechub-demo", name="deepfm")
tb = TensorBoardXLogger(log_dir="./runs/deepfm")
trainer = CTRTrainer(model, model_logger=[wb, tb])
trainer.fit(train_dataloader, val_dataloader)训练器
CTRTrainer
用于训练排序模型(CTR预测模型),如DeepFM、Wide&Deep、DCN等。
python
from torch_rechub.trainers import CTRTrainer
from torch_rechub.models.ranking import DeepFM
# 创建模型
model = DeepFM(deep_features=deep_features, fm_features=fm_features, mlp_params={"dims": [256, 128], "dropout": 0.2})
# 创建训练器
trainer = CTRTrainer(
model=model,
optimizer_params={"lr": 0.001, "weight_decay": 0.0001},
n_epoch=50,
earlystop_patience=10,
device="cuda:0",
model_path="saved/deepfm"
)
# 训练模型
trainer.fit(train_dataloader, val_dataloader)
# 评估模型
auc = trainer.evaluate(trainer.model, test_dataloader)
# 导出ONNX模型
trainer.export_onnx("deepfm.onnx")
# 可视化模型
trainer.visualization(save_path="deepfm_architecture.pdf")参数说明:
model:排序模型实例optimizer_fn:优化器函数,默认torch.optim.Adamoptimizer_params:优化器参数regularization_params:正则化参数scheduler_fn:学习率调度器函数scheduler_params:学习率调度器参数n_epoch:训练轮数earlystop_patience:早停耐心值device:训练设备gpus:多GPU列表loss_mode:损失模式,布尔值。True表示模型只返回预测值,False表示模型返回预测值和额外损失model_path:模型保存路径
MatchTrainer
用于训练召回模型,如DSSM、YoutubeDNN、MIND等。
python
from torch_rechub.trainers import MatchTrainer
from torch_rechub.models.matching import DSSM
# 创建模型
model = DSSM(user_features=user_features, item_features=item_features, temperature=0.02,
user_params={"dims": [256, 128, 64]}, item_params={"dims": [256, 128, 64]})
# 创建训练器
trainer = MatchTrainer(
model=model,
mode=0, # 0: point-wise, 1: pair-wise, 2: list-wise
optimizer_params={"lr": 0.001},
n_epoch=50,
device="cuda:0",
model_path="saved/dssm"
)
# 训练模型
trainer.fit(train_dataloader)
# 导出用户塔ONNX模型
trainer.export_onnx("user_tower.onnx", mode="user")
# 导出物品塔ONNX模型
trainer.export_onnx("item_tower.onnx", mode="item")参数说明:
model:召回模型实例mode:训练模式,可选值:0(point-wise)、1(pair-wise)、2(list-wise)optimizer_fn:优化器函数,默认torch.optim.Adamoptimizer_params:优化器参数regularization_params:正则化参数scheduler_fn:学习率调度器函数scheduler_params:学习率调度器参数n_epoch:训练轮数earlystop_patience:早停耐心值device:训练设备gpus:多GPU列表model_path:模型保存路径
MTLTrainer
用于训练多任务模型,如MMoE、PLE、ESMM、SharedBottom等。
python
from torch_rechub.trainers import MTLTrainer
from torch_rechub.models.multi_task import MMOE
# 创建模型
model = MMOE(features=features, task_types=["classification", "classification"], n_expert=8,
expert_params={"dims": [32,16]}, tower_params_list=[{"dims": [32, 16]}, {"dims": [32, 16]}])
# 创建训练器
trainer = MTLTrainer(
model=model,
task_types=["classification", "classification"],
optimizer_params={"lr": 0.001},
adaptive_params={"method": "uwl"}, # 自适应损失权重方法
n_epoch=50,
earlystop_taskid=0, # 早停依赖的任务ID
device="cuda:0",
model_path="saved/mmoe"
)
# 训练模型
trainer.fit(train_dataloader, val_dataloader)
# 导出ONNX模型
trainer.export_onnx("mmoe.onnx")参数说明:
model:多任务模型实例task_types:任务类型列表,可选值:classification、regressionoptimizer_fn:优化器函数,默认torch.optim.Adamoptimizer_params:优化器参数regularization_params:正则化参数scheduler_fn:学习率调度器函数scheduler_params:学习率调度器参数adaptive_params:自适应损失权重参数n_epoch:训练轮数earlystop_taskid:早停依赖的任务IDearlystop_patience:早停耐心值device:训练设备gpus:多GPU列表model_path:模型保存路径
回调函数
EarlyStopper
用于早停,当验证集性能不再提升时停止训练。
python
from torch_rechub.basic.callback import EarlyStopper
# 创建早停器
early_stopper = EarlyStopper(patience=10)
# 在训练过程中使用
if early_stopper.stop_training(auc, model.state_dict()):
print(f'validation: best auc: {early_stopper.best_auc}')
model.load_state_dict(early_stopper.best_weights)
break参数说明:
patience:早停耐心值,即连续多少轮验证集性能没有提升就停止训练delta:性能提升阈值,即性能提升超过该值才被认为是有效提升
损失函数
RegularizationLoss
用于正则化,支持L1和L2正则化。
python
from torch_rechub.basic.loss_func import RegularizationLoss
# 创建正则化损失函数
reg_loss_fn = RegularizationLoss(
embedding_l1=0.0, # Embedding层L1正则化系数
embedding_l2=0.0001, # Embedding层L2正则化系数
dense_l1=0.0, # 密集层L1正则化系数
dense_l2=0.0001 # 密集层L2正则化系数
)BPRLoss
用于召回模型的 pairwise 损失。
python
from torch_rechub.basic.loss_func import BPRLoss
# 创建BPR损失函数
bpr_loss = BPRLoss()
# 计算损失
loss = bpr_loss(pos_score, neg_score)