Training & Evaluation
Torch-RecHub provides trainers for ranking, matching, multi-task, and generative models. All trainers expose a unified interface for training, evaluation, prediction, ONNX export, and optional experiment tracking/visualization.
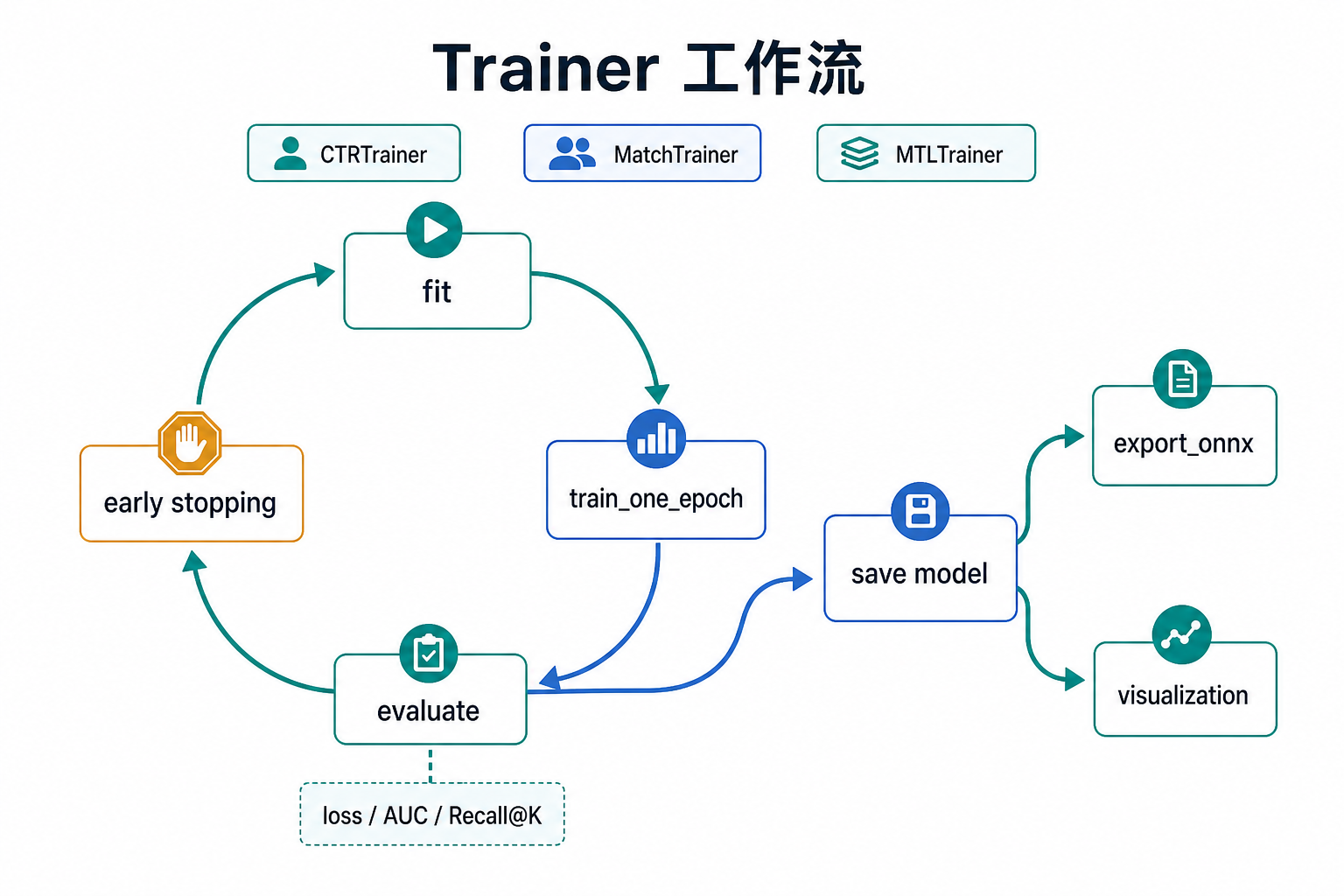
Experiment Tracking & Visualization
- Supports WandB / SwanLab / TensorBoardX as
model_logger; you can pass a single instance or a list. - Auto-logs train/validation metrics and hyperparameters:
train/loss,learning_rate,val/auc(CTR/Match),val/task_i_score(MTL),val/accuracy(Seq). - Set
model_logger=None(default) for zero overhead when tracking is not needed.
python
from torch_rechub.basic.tracking import WandbLogger, TensorBoardXLogger
from torch_rechub.trainers import CTRTrainer
wb = WandbLogger(project="rechub-demo", name="deepfm")
tb = TensorBoardXLogger(log_dir="./runs/deepfm")
trainer = CTRTrainer(model, model_logger=[wb, tb])
trainer.fit(train_dataloader, val_dataloader)Trainers
CTRTrainer
Used for ranking (CTR prediction) models such as DeepFM, Wide&Deep, DCN.
python
from torch_rechub.trainers import CTRTrainer
from torch_rechub.models.ranking import DeepFM
model = DeepFM(deep_features=deep_features, fm_features=fm_features, mlp_params={"dims": [256, 128], "dropout": 0.2})
trainer = CTRTrainer(
model=model,
optimizer_params={"lr": 0.001, "weight_decay": 0.0001},
n_epoch=50,
earlystop_patience=10,
device="cuda:0",
model_path="saved/deepfm"
)
trainer.fit(train_dataloader, val_dataloader)
auc = trainer.evaluate(trainer.model, test_dataloader)
trainer.export_onnx("deepfm.onnx")
trainer.visualization(save_path="deepfm_architecture.pdf")Parameters
model: Ranking model instance.optimizer_fn: Optimizer function, defaulttorch.optim.Adam.optimizer_params: Optimizer parameters.regularization_params: Regularization parameters.scheduler_fn: Learning rate scheduler.scheduler_params: Scheduler parameters.n_epoch: Number of training epochs.earlystop_patience: Patience for early stopping.device: Training device.gpus: List of GPU ids.loss_mode: Boolean.Truewhen the model returns only predictions;Falsewhen the model returns predictions plus auxiliary loss.model_path: Path to save the model.
MatchTrainer
Used for matching/retrieval models such as DSSM, YoutubeDNN, MIND.
python
from torch_rechub.trainers import MatchTrainer
from torch_rechub.models.matching import DSSM
model = DSSM(
user_features=user_features,
item_features=item_features,
temperature=0.02,
user_params={"dims": [256, 128, 64]},
item_params={"dims": [256, 128, 64]}
)
trainer = MatchTrainer(
model=model,
mode=0, # 0: point-wise, 1: pair-wise, 2: list-wise
optimizer_params={"lr": 0.001},
n_epoch=50,
device="cuda:0",
model_path="saved/dssm"
)
trainer.fit(train_dataloader)
trainer.export_onnx("user_tower.onnx", mode="user")
trainer.export_onnx("item_tower.onnx", mode="item")Parameters
model: Matching model instance.mode: Training mode, one of 0 (point-wise), 1 (pair-wise), 2 (list-wise).optimizer_fn: Optimizer function, defaulttorch.optim.Adam.optimizer_params: Optimizer parameters.regularization_params: Regularization parameters.scheduler_fn: Learning rate scheduler.scheduler_params: Scheduler parameters.n_epoch: Number of training epochs.earlystop_patience: Patience for early stopping.device: Training device.gpus: List of GPU ids.model_path: Path to save the model.
MTLTrainer
Used for multi-task models such as MMoE, PLE, ESMM, SharedBottom.
python
from torch_rechub.trainers import MTLTrainer
from torch_rechub.models.multi_task import MMOE
model = MMOE(
features=features,
task_types=["classification", "classification"],
n_expert=8,
expert_params={"dims": [32,16]},
tower_params_list=[{"dims": [32, 16]}, {"dims": [32, 16]}]
)
trainer = MTLTrainer(
model=model,
task_types=["classification", "classification"],
optimizer_params={"lr": 0.001},
adaptive_params={"method": "uwl"},
n_epoch=50,
earlystop_taskid=0,
device="cuda:0",
model_path="saved/mmoe"
)
trainer.fit(train_dataloader, val_dataloader)
trainer.export_onnx("mmoe.onnx")Parameters
model: Multi-task model instance.task_types: List of task types (classification,regression).optimizer_fn: Optimizer function, defaulttorch.optim.Adam.optimizer_params: Optimizer parameters.regularization_params: Regularization parameters.scheduler_fn: Learning rate scheduler.scheduler_params: Scheduler parameters.adaptive_params: Adaptive loss weighting parameters.n_epoch: Number of training epochs.earlystop_taskid: Task id used for early stopping.earlystop_patience: Patience for early stopping.device: Training device.gpus: List of GPU ids.model_path: Path to save the model.
Callbacks
EarlyStopper
Used for early stopping when validation performance no longer improves.
python
from torch_rechub.basic.callback import EarlyStopper
early_stopper = EarlyStopper(patience=10)
if early_stopper.stop_training(auc, model.state_dict()):
print(f'validation: best auc: {early_stopper.best_auc}')
model.load_state_dict(early_stopper.best_weights)
breakParameters
patience: Number of consecutive epochs without improvement before stopping.delta: Minimum improvement threshold to be considered progress.
Loss Functions
RegularizationLoss
Supports L1 and L2 regularization.
python
from torch_rechub.basic.loss_func import RegularizationLoss
reg_loss_fn = RegularizationLoss(
embedding_l1=0.0,
embedding_l2=0.0001,
dense_l1=0.0,
dense_l2=0.0001
)BPRLoss
Pairwise loss for matching models.
python
from torch_rechub.basic.loss_func import BPRLoss
bpr_loss = BPRLoss()
loss = bpr_loss(pos_score, neg_score)