ONNX 导出与量化
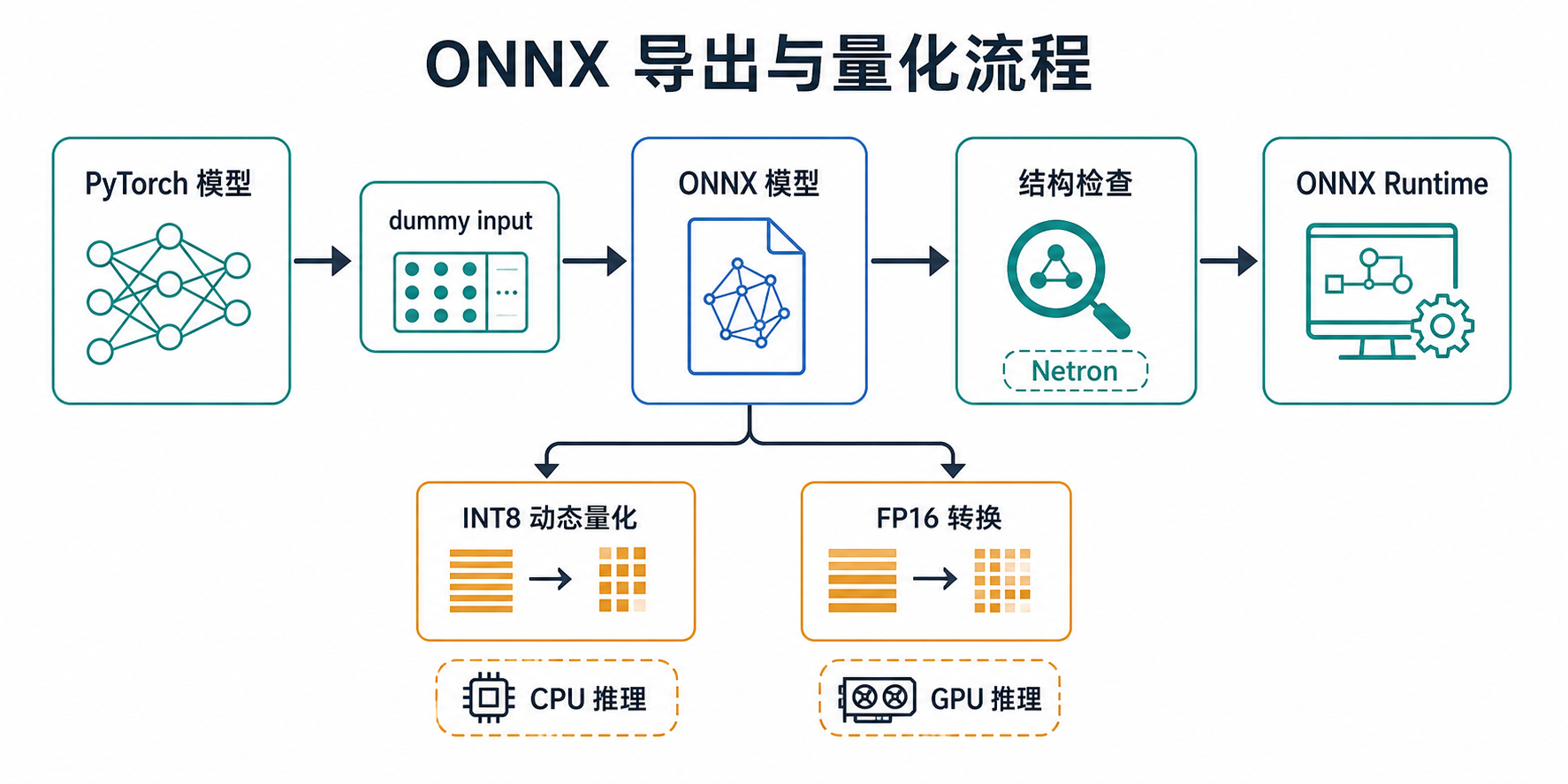
Torch-RecHub 已支持将训练好的模型导出为 ONNX,用于跨平台推理部署。面向工业推理场景(低延迟、低内存), ONNX 导出 与 量化(INT8/FP16) 的完整用法与建议实践。
安装依赖
ONNX 相关依赖是可选的,按需安装:
bash
pip install "torch-rechub[onnx]"说明:
torch-rechub[onnx]会安装onnx、onnxruntime,以及用于 FP16 转换的onnxconverter-common。- 如需 GPU 推理,请自行安装对应 CUDA 版本的
onnxruntime-gpu(与本机 CUDA/驱动匹配)。
导出 ONNX(训练器 export_onnx)
Torch-RecHub 各训练器均提供 export_onnx() 方法(CTR/Matching/MTL/Seq),导出过程会自动构造 dummy input,并可支持 动态 batch size。
CTR(排序/精排)导出
python
from torch_rechub.trainers import CTRTrainer
# ... trainer.fit(train_dl, val_dl)
trainer.export_onnx("deepfm.onnx")Matching(召回)导出:全模型 / 双塔分导
双塔模型通常建议分开导出用户塔与物品塔,线上分别做 embedding 计算:
python
from torch_rechub.trainers import MatchTrainer
# 导出用户塔(用于 user embedding)
trainer.export_onnx("user_tower.onnx", mode="user")
# 导出物品塔(用于 item embedding)
trainer.export_onnx("item_tower.onnx", mode="item")多任务(MTL)导出
python
from torch_rechub.trainers import MTLTrainer
trainer.export_onnx("mmoe.onnx")导出参数与高级控制(onnx_export_kwargs)
如需调整 torch.onnx.export() 的高级参数(例如某些算子导出策略、常量折叠、导出器选择等),可以通过 onnx_export_kwargs 透传:
python
trainer.export_onnx(
"model.onnx",
dynamic_batch=True, # 动态 batch size(推荐)
onnx_export_kwargs={
"do_constant_folding": True,
# "operator_export_type": torch.onnx.OperatorExportTypes.ONNX_ATEN_FALLBACK,
# "dynamo": False, # 需要动态轴时通常建议关闭(见下文说明)
},
)导出器选择建议:
- 需要动态 batch(或动态序列长度):优先使用 legacy 导出(
dynamo=False),更稳定地支持dynamic_axes。 - 输入 shape 固定:可尝试
dynamo=True获取更好的导出覆盖率(不同 torch 版本表现不同)。 - 老版本 PyTorch:可能不支持
dynamo参数;Torch-RecHub 会自动兼容(不传该参数)。
查看 ONNX 模型结构
导出 ONNX 后,可以使用 Netron 在线查看模型结构:
- 打开 https://netron.app/
- 拖拽或上传导出的
.onnx文件 - 即可可视化查看模型的网络结构、各层参数和张量形状
提示:Netron 支持多种模型格式(ONNX、TensorFlow、PyTorch 等),是调试和验证导出模型的便捷工具。
ONNX 量化(Quantization)
在工业推理中,FP32 往往不是最优解。常用两类压缩方式:
- INT8 动态量化(Dynamic Quantization):主要对 Linear/MatMul 等权重做 INT8,通常对 CPU 推理加速明显,且精度损失可控。
- FP16 转换:对支持 Tensor Core 的 GPU 推理更友好,能降低显存占用并提升吞吐。
Torch-RecHub 在 torch_rechub.utils 提供统一 API:
python
from torch_rechub.utils import quantize_model1) INT8 动态量化(推荐 CPU)
python
from torch_rechub.utils import quantize_model
quantize_model(
input_path="model_fp32.onnx",
output_path="model_int8.onnx",
mode="int8",
)可选参数(按需):
per_channel=True:对权重启用 per-channel 量化reduce_range=True:缩小量化范围(部分 CPU 可能更稳)weight_type="qint8"|"quint8":权重量化类型
注意:不同
onnxruntime版本对quantize_dynamic()的参数支持略有差异;Torch-RecHub 会自动过滤掉当前版本不支持的参数,保证兼容性。
2) FP16 转换(推荐 GPU)
python
from torch_rechub.utils import quantize_model
quantize_model(
input_path="model_fp32.onnx",
output_path="model_fp16.onnx",
mode="fp16",
keep_io_types=True, # 通常建议保留 I/O 为 FP32,兼容性更好
)脚本示例与基准测试(Benchmark)
仓库内提供脚本,便于快速验证:
量化脚本
bash
python examples/serving/quantize_onnx.py --input model_fp32.onnx --output model_int8.onnx --mode int8
python examples/serving/quantize_onnx.py --input model_fp32.onnx --output model_fp16.onnx --mode fp16性能对比脚本
对比 FP32 / INT8 / FP16 的 模型大小 与 推理耗时:
bash
python examples/serving/benchmark_onnx_quantization.py --fp32 model_fp32.onnx --int8 model_int8.onnx
python examples/serving/benchmark_onnx_quantization.py --fp32 model_fp32.onnx --fp16 model_fp16.onnx --provider CUDAExecutionProvider脚本会根据 ONNX 输入签名自动构造 dummy inputs(适合做快速的端到端性能 sanity check)。