ONNX Export & Quantization
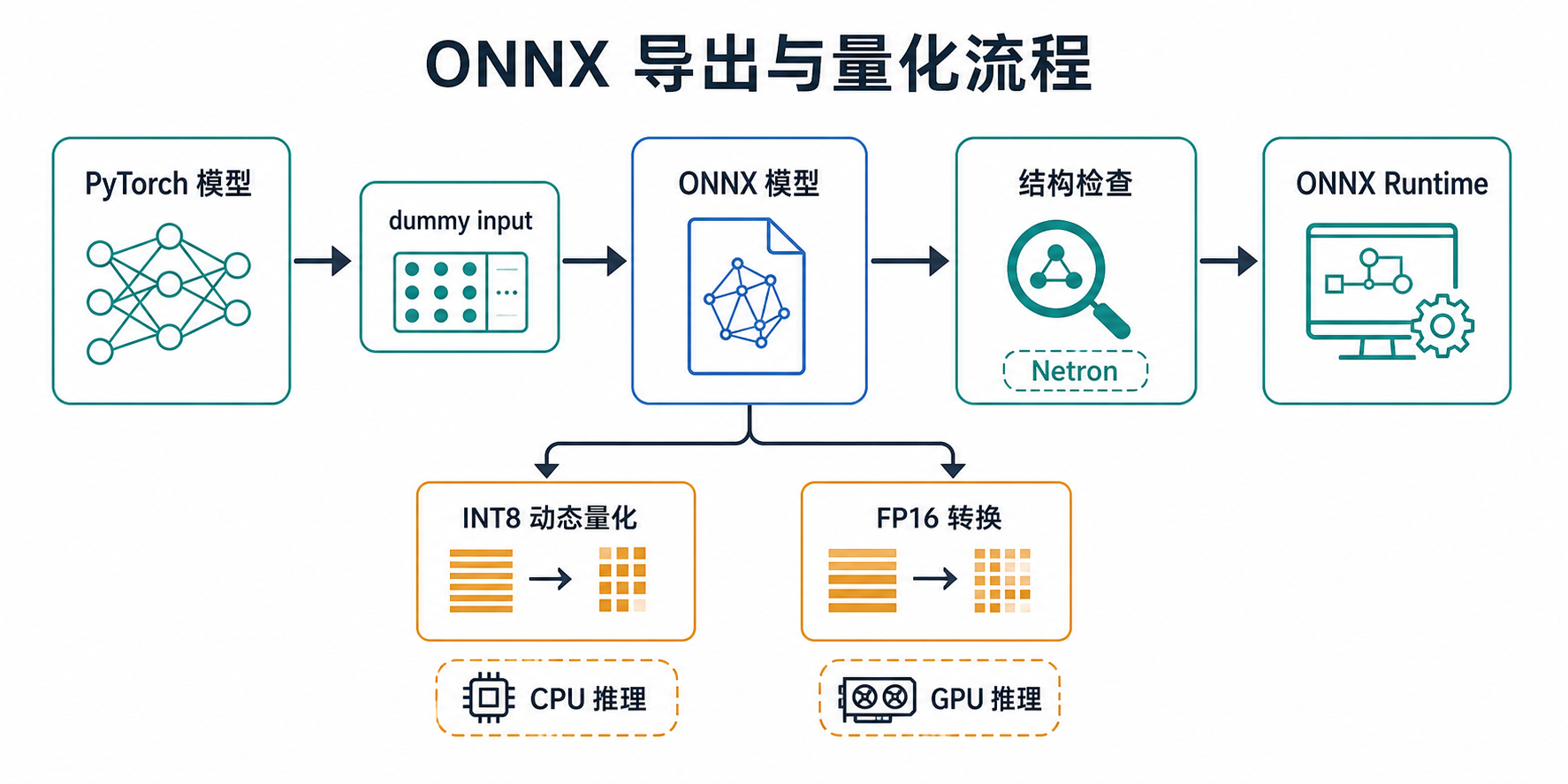
Torch-RecHub supports exporting trained models to ONNX format for cross-platform inference deployment.
Installation
ONNX dependencies are optional:
bash
pip install "torch-rechub[onnx]"Export ONNX
All trainers provide export_onnx() method with automatic dummy input generation and dynamic batch size support.
CTR Model Export
python
from torch_rechub.trainers import CTRTrainer
trainer.export_onnx("deepfm.onnx")Matching Model Export
For dual-tower models, export user and item towers separately:
python
from torch_rechub.trainers import MatchTrainer
trainer.export_onnx("user_tower.onnx", mode="user")
trainer.export_onnx("item_tower.onnx", mode="item")MTL Model Export
python
from torch_rechub.trainers import MTLTrainer
trainer.export_onnx("mmoe.onnx")View ONNX Model Structure
After exporting to ONNX, you can use Netron to view the model structure online:
- Open https://netron.app/
- Drag or upload your
.onnxfile - Visualize network structure, layer parameters, and tensor shapes
Tip: Netron supports multiple model formats (ONNX, TensorFlow, PyTorch, etc.) and is a convenient tool for debugging and verifying exported models.
ONNX Quantization
INT8 Dynamic Quantization (CPU)
python
from torch_rechub.utils import quantize_model
quantize_model(
input_path="model_fp32.onnx",
output_path="model_int8.onnx",
mode="int8",
)FP16 Conversion (GPU)
python
from torch_rechub.utils import quantize_model
quantize_model(
input_path="model_fp32.onnx",
output_path="model_fp16.onnx",
mode="fp16",
keep_io_types=True,
)