
第1章:预备定理
编辑:赵志民, 李一飞
本章将对书中出现或用到的重要定理进行回顾,并简要解释其证明和应用场景。对于可能不熟悉相关基础知识的读者,建议参考附录中的基础知识部分。通过这些定理的阐述,希望帮助读者更好地理解数学推导的核心原理,并为后续章节的学习打下坚实基础。大数定律(Law of Large Numbers)和集中不等式(Concentration Inequality)密切相关,二者共同揭示了随机变量偏离其期望值的行为。大数定律说明,当样本量足够大时,样本均值会以概率收敛于总体的期望值,反映了长期平均结果的稳定性。而集中不等式(定理 1.8 至 1.18)则更进一步,为随机变量在有限样本量下偏离其期望值的可能性提供了精确的上界。这些不等式描述了随机变量偏离期望值的程度有多大,通过对概率的约束,确保这种偏离发生的概率较小,从而为各种随机现象提供了更细致的控制。集中不等式在大数定律的基础上提供了有力的工具,用于分析有限样本中的波动。
1.1 Jensen 不等式
对于任意凸函数
成立。
证明
设
对上式取期望,得到:
因此,原不等式得证。
如果
这一结论可以通过将上述证明中的
1.2 Hölder 不等式
对于任意
成立。
证明
设
代入 Young 不等式:
对该不等式两边同时取期望:
因此,Hölder 不等式得证。
1.3 Cauchy-Schwarz 不等式
当
1.4 Lyapunov 不等式
对于任意
证明
由 Hölder 不等式: 对任意
记
因此,原不等式得证。
1.5 Minkowski 不等式
对于任意
证明
由三角不等式和 Hölder 不等式,可得:
化简后即得证。
1.6 Bhatia-Davis 不等式
对
证明
因为
因此,
考虑 AM-GM 不等式:
将
1.7 Union Bound(Boole's)不等式
对于任意事件
证明
根据概率的加法公式:
由于
1.8 Markov 不等式
若
证明
由定义可得:
因此,原不等式得证。
1.9 Chebyshev 不等式
对于任意
证明
利用 Markov 不等式,得到:
因此,Chebyshev 不等式得证。
1.10 Cantelli 不等式
对于任意
证明
设
通过对
原不等式得证。
值得注意的是,Cantelli 不等式是 Chebyshev 不等式的加强版,也称为单边 Chebyshev 不等式。通过类似的构造方法,可以推导出比 Cantelli 不等式更严格的上界。
1.11 Chernoff 界(Chernoff-Cramér 界)
对于任意
对于任意
证明
应用 Markov 不等式,有:
同理,
因此,Chernoff 界得证。
基于上述 Chernoff 界的技术,我们可以进一步定义次高斯性:
定义 1 (随机变量的次高斯性):若一个期望为零的随机变量
则称
实际上,Hoeffding 引理中的随机变量
次高斯分布有一个直接的性质:假设两个独立的随机变量
显然,并非所有常见的随机变量都是次高斯的,例如指数分布。为此可以扩大定义:
定义 2 (随机变量的次指数性):若非负的随机变量
则称
同样地,次指数性也有一系列等价定义。一种不直观但更常用的定义如下:存在
常见的次指数分布包括:指数分布,Gamma 分布,以及任何有界随机变量。
类似地,次指数分布对于加法也是封闭的:如果
1.12 Chernoff 不等式(乘积形式)
对于
证明
应用 Markov 不等式,有:
由于
其中,第二步使用了
又由于
当我们将
1.13 最优 Chernoff 界
如果
或
其中,
证明
根据 Chernoff 不等式,有:
因此,最优 Chernoff 界得证。
1.14 Hoeffding 不等式
设有
证明
首先,我们引入一个引理 (Hoeffding 定理):
对于
由于
对上式取期望,得到:
记
定义函数
显然有
根据泰勒展开式,可以得到:
由 Markov 不等式可知,对于任意
利用随机变量的独立性及 Hoeffding 引理,有:
考虑二次函数
因此可以得到:
注意,这里并未要求随机变量同分布,因此Hoeffding 不等式常用来解释集成学习的基本原理。
1.15 McDiarmid 不等式
对于
证明
构造一个鞅差序列:
容易验证:
由于
原不等式得证。
1.16 Bennett 不等式
对于
证明
首先,Bennett 不等式是 Hoeffding 不等式的一个加强版,对于独立随机变量的条件可以放宽为弱独立条件,结论仍然成立。
这些 Bernstein 类的集中不等式更多地反映了在非渐近观点下的大数定律表现,即它们刻画了样本均值如何集中在总体均值附近。
如果将样本均值看作是样本(数据点的函数),即令
为了在某些泛函上也具有类似 Bernstein 类的集中不等式形式,显然
定义 3: 差有界性
函数
则称
为了证明这些结果,需要引入一些新的数学工具。
定义 4: 离散鞅
若离散随机变量序列(随机过程)
则称序列
引理 2: Azuma-Hoeffding 定理
对于鞅
证明
首先,若
因此,由恒等式
由于
迭代上不等式可得:
当
原不等式得证。
1.17 Bernstein 不等式
考虑
证明
首先,我们需要将矩条件(Moment Condition)转换为亚指数条件(Sub-exponential Condition),以便进一步推导,即:
矩条件: 对于随机变量
,其 -阶中心矩 满足如下条件: 其中:
- 中心矩:随机变量
的 阶中心矩为 ,表示 偏离其期望值的 次幂的期望值。中心矩用于衡量随机变量的分布形状,尤其是描述其尾部行为。当 时,中心矩即为随机变量的方差。 是阶乘项,随着 增大迅速增长。 是一个修正因子,其中 为常数,用以控制高阶矩的增长速率。 表示随机变量 的方差,它作为标准的离散度量来标定中心矩的大小。
- 中心矩:随机变量
亚指数条件: 给定随机变量
,其均值为 ,方差为 ,则其偏离均值的随机变量 的矩母函数(MGF)满足如下不等式: 其中:
- 矩母函数:这是一个重要的工具,用于控制随机变量的尾部概率。矩母函数的形式是
,它通过调整 来捕捉不同程度的偏差行为。 - 方差主导项:不等式右边的表达式包含一个方差主导的项
,类似于高斯分布的尾部特性,表明当 较小时, 的偏差行为主要由其方差控制,尾部概率呈现指数衰减。 - 修正项
:该项显示,当 接近 时,尾部偏差的控制变得更加复杂。这种形式通常出现在亚指数条件中,意味着随机变量的尾部行为介于高斯分布和重尾分布之间,尾部衰减较慢但仍比重尾分布快。
- 矩母函数:这是一个重要的工具,用于控制随机变量的尾部概率。矩母函数的形式是
- 步骤 1:中心化随机变量
设:
我们的目标是对
- 步骤 2:展开指数矩
将 MGF 展开为幂级数(Taylor展开):
由于
- 步骤 3:使用矩条件对中心矩进行上界
根据矩条件:
因此:
- 步骤 4:代入 MGF 展开式
将上界代入 MGF 展开式:
通过令
- 步骤 5:求解几何级数的和
当
因此:
- 步骤 6:应用指数不等式
使用不等式
这与亚指数条件相符:
接下来我们完成在给定矩条件下的Bernstein 不等式的证明,即:
陈述:
给定
则对于任意
- 步骤 1:定义单侧 Bernstein 条件
首先,回顾对于参数
其中
根据矩条件,我们已经证明
因此,
- 步骤 2:应用 Chernoff 界
考虑
我们的目标是对概率
使用Chernoff 界:
- 步骤 3:对和的矩母函数进行上界
由于
因此:
- 步骤 4:对
进行优化
为了找到最紧的界,我们需要对
对
然而,直接求解该方程较为复杂。我们可以选择:
此时
- 步骤 5:将最优的
代入界中
将
在第二项中简化分母:
现在,代入回去:
因此:
- 步骤 6:回到样本均值
回忆:
因此:
由于
1.18 Azuma–Hoeffding(Azuma)不等式
对于均值为
证明
构造指数鞅
考虑参数
,构造如下的指数鞅: 我们需要证明
是一个超鞅。 验证鞅性质
对于任意
,有 由于
,并且 (鞅性质),可以应用 Hoeffding 引理得到: 因此,
这表明
是一个超鞅。 应用鞅不等式
由于
是一个超鞅,且 ,根据超鞅的性质,有 对于事件
,有 我们令
,由于 蕴含了 ,所以: 结合已知的
,应用 Markov 不等式可得: 因此,我们得到:
优化参数
为了得到最优的上界,选择
使得表达式 最小化。对 求导并取零: 代入得:
这即是 Azuma 不等式的上侧不等式。
下侧不等式的证明
对于下侧不等式,可以类似地考虑
作为鞅,应用相同的方法得到: 因此,Azuma 不等式得证。
1.19 Slud 不等式
若
其中
证明
二项随机变量
令
根据正态分布不等式(定理 21),有:
代入可得:
1.20 上界不等式之加性公式
若
证明
假设
从而
因为这对于每一个
这里我们使用了
值得注意的是,该不等式在(4.33)中利用过两次,且原推导并没有用到 Jensen 不等式的任何性质。
另外,加性公式有几个常见的变形,例如:
该不等式在(4.29)中出现过。
1.21 正态分布不等式
若
证明
令
因此:
让我们考虑更一般的积分形式:
此时
此时,有:
因此,有:
进一步,我们可以得到:
1.22 AM-GM 不等式
算术平均数和几何平均数的不等式,简称 AM-GM 不等式。该不等式指出非负实数序列的算术平均数大于等于该序列的几何平均数,当且仅当序列中的每个数相同时,等号成立。形式上,对于非负实数序列
其几何平均值定义为:
则 AM-GM 不等式成立:
证明
我们可以通过 Jensen 不等式来证明 AM-GM 不等式。首先,我们考虑函数
即:
当取
1.23 Young 不等式
对于任意
当且仅当
证明
我们可以通过 Jensen 不等式来证明 Young 不等式。首先,当
当且仅当
1.24 Bayes 定理
贝叶斯定理是概率论中的一个重要定理,它描述了在已知某些条件下更新事件概率的数学方法。贝叶斯定理的公式为:
其中:
是在事件 B 发生的情况下事件 A 发生的后验概率。 是在事件 A 发生的情况下事件 B 发生的似然函数。 是事件 A 的先验概率。 是事件 B 的边缘概率。
证明
根据条件概率的定义,事件 A 在事件 B 发生下的条件概率
同样地,事件 B 在事件 A 发生下的条件概率
通过这两个公式可以得到联合概率
以及:
由于联合概率的性质,我们可以将上述两个等式等同:
将上述等式两边同时除以
通过先验和后验的更新过程,贝叶斯统计提供了一种动态的、不断修正认知的不确定性量化方法。
1.25 广义二项式定理
广义二项式定理(Generalized Binomial Theorem)是二项式定理的扩展:
其中我们令
证明
首先代入定义,易证:
我们从特殊情况
通过使用幂级数收敛半径的商式来证明这一点,由于绝对值的连续性使我们可以先在绝对值内部计算极限,可得:
因此我们有一个为 1 的收敛半径。这种收敛使我们能够在
如果我们将我们正在考虑的级数定义的函数记为
上式的推导使用了前述引理。
现在定义
对于一般的
收敛性由假设
1.26 Stirling 公式
Stirling 公式是用于近似计算阶乘的一种公式,即使在
其中,
证明
我们令:
且
其中:
此时:
易证
此时:
接下来我们对
令
对上式两边同时进行积分,我们有:
如果我们令
将两式相加,我们有:
回到我们的问题,我们令
因此:
且
易证
因此:
我们令:
那么易得:
带入
可得:
令
1.27 散度定理
散度定理(Divergence Theorem),也称为高斯定理(Gauss's Theorem),是向量分析中的重要定理,它将体积积分和曲面积分联系起来。
具体而言,如果考虑一个
其中:
是向量场 的散度。 是体积元素。 是边界表面的面积元素。 是边界的单位外法向量。
体积积分计算的是在
1.28 分离超平面定理
如果有两个不相交的非空凸集,则存在一个超平面能够将它们完全分隔开,这个超平面叫做分离超平面(Separating Hyperplane)。形式上,设
对所有
进一步,如果这两个集合都是闭集,并且至少其中一个是紧致的,那么这种分离可以是严格的,即存在
在不同情况下,我们可以通过调整
| A | B | ||
|---|---|---|---|
| 闭紧集 | 闭集 | ||
| 闭集 | 闭紧集 | ||
| 开集 | 闭集 | ||
| 开集 | 开集 |
在支持向量机的背景下,最佳分离超平面(或最大边缘超平面)是分离两个点凸包并且与两者等距的超平面。
证明
证明基于以下引理:
设
我们给出引理的证明:
令
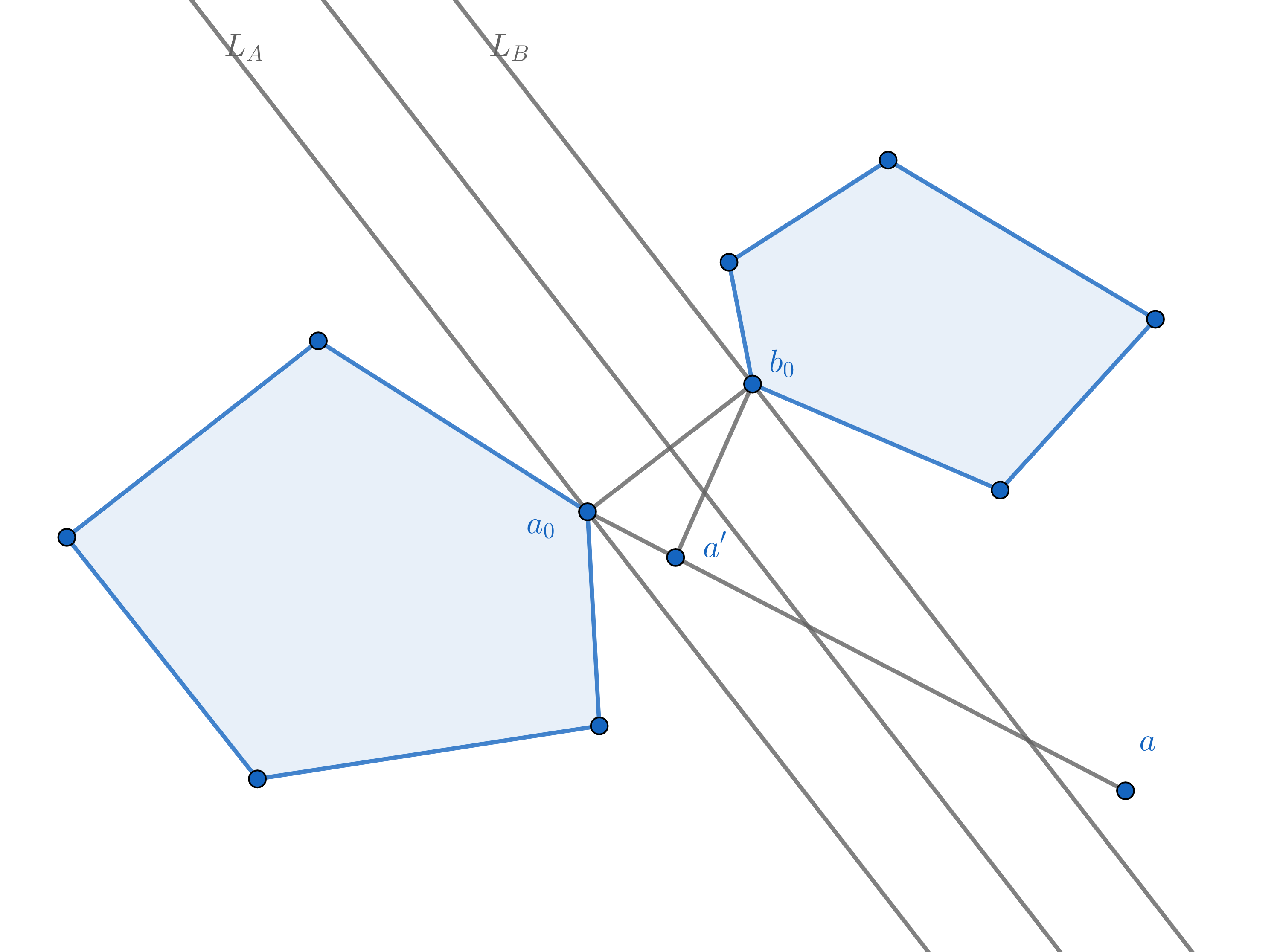
不失一般性地,假设
代数上,超平面
假设存在某个
1.29 支撑超平面定理
对于一个凸集,支撑超平面(Supporting Hyperplane)是与凸集边界切线的超平面,即它“支撑”了凸集,使得所有的凸集内的点都位于支撑超平面的一侧。形式上,若
证明
定义
设