
第3章:复杂性分析
Edit: 王茂霖,李一飞,詹好,赵志民
本章前言
在机器学习理论中,复杂性分析与计算理论中的算法复杂度类似,是衡量模型和假设空间能力的关键指标。复杂性越高,模型的表达能力越强,但同时也意味着过拟合的风险增加。因此,研究假设空间的复杂性有助于理解模型的泛化能力。
3.1 【概念解释】VC维
VC维(Vapnik-Chervonenkis 维度)是衡量假设空间
VC维的定义如下:
其中,
例子:对于假设空间
3.2 【概念解释】Natarajan维
在多分类问题中,我们使用Natarajan维来描述假设空间的复杂性。Natarajan维是能被假设空间
当类别数
对于更一般的
随着样本数
3.3 【概念解释】Rademacher复杂度
VC维和Natarajan维均未考虑数据分布的影响,而Rademacher复杂度则引入了数据分布因素。它通过考察数据的几何结构和信噪比等特性,提供了更紧的泛化误差界。
函数空间
其中
假设空间
3.4 【概念解释】shattering 概念的可视化
Shattering是指假设空间能够实现样本集上所有对分的能力。以下通过二维空间
示例:对于二维空间
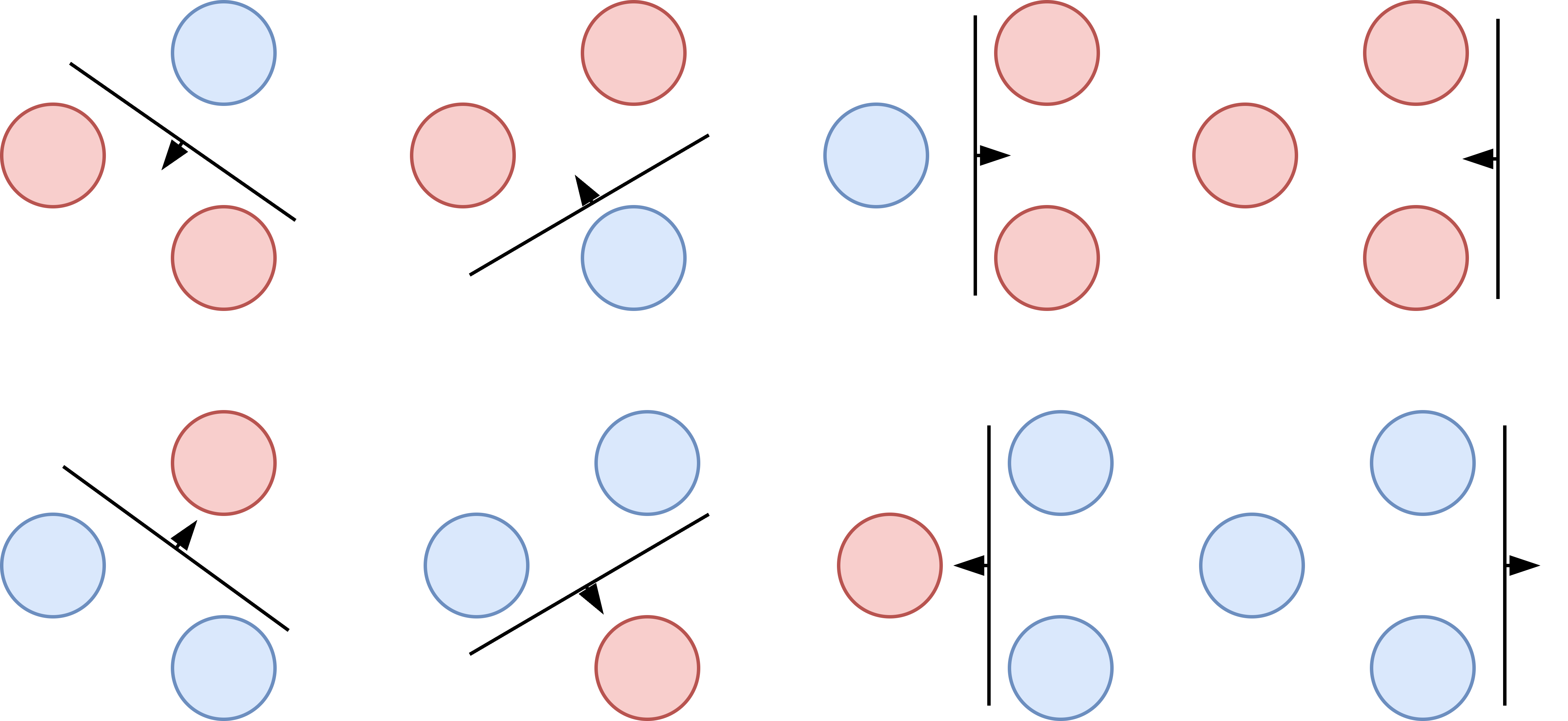
因此,线性分类器在