Chapter 14: Attention: Where Should We Look?
Mr. Pallas's Cat's Warm Welcome
In the previous chapter, we witnessed the philosophical contest between LSTM and attention — the collision of wisdom between incremental memory and direct access. Today, we dive deep into the core of attention: in this noisy world, where should we look? Attention is not only a technical tool but also the 'eyes' of intelligence — it teaches models how to focus, how to choose, how to understand. Let's take it slow and explore the art of attention.
Core Question: The Art of Focusing
"Professor," Piglet stared at the complex text on the screen, "attention mechanisms let models 'attend to' different parts, but how exactly is this 'attending' implemented? How does the model know 'where to look'?"
It was a winter evening in Kangle Garden at Sun Yat-sen University. The setting sun streamed through the glass windows into the Black Stone House study, casting golden patches of light on the red-brick floor. Outside, a few late-returning birds hopped among the banyan branches, chirping about the day's gains. In the study, a faint wisp of steam rose from the kung fu tea set, and the wall clock ticked steadily, marking each cognitive leap.
By the window, Little Seal said: "That's a fundamental question. In psychology, William James wrote as early as 1890: 'Attention is the spotlight of the mind — grasping one object or train of thought clearly and vividly among several simultaneously present.'"
Mr. Pallas's Cat gently set down his teacup and smiled. "You've raised the essential question of attention. Attention is not passive reception, but active selection. Today, we explore how this 'selection' is implemented mathematically."
Human Attention: The Cognitive Spotlight
Piglet walked to the whiteboard and drew a scene of someone reading.
"Professor, when I read, my eyes jump around — focusing on nouns and verbs, skipping words like 'the' and 'of.' Is that attention at work?"
Little Seal added: "In cognitive science, attention is divided into selective attention (choosing what to attend to) and divided attention (how to allocate cognitive resources). Visual attention research shows we first look at high-contrast, moving, or suddenly-appearing things."
Mr. Pallas's Cat nodded: "Yes, human attention has clear priorities and selectivity. Now we want machines to learn similar wisdom."
He listed the characteristics of human attention on the whiteboard:
- Selectivity: ignore irrelevant information, focus on relevant parts
- Dynamism: adjust focus according to task needs
- Limited capacity: cannot attend to everything simultaneously
- Goal-directedness: can be guided by intention and goals
"The wonder of attention," said Mr. Pallas's Cat, "is that it is both a filter (filtering out noise) and an amplifier (boosting signal). Today, we implement this filter and amplifier mathematically."
Scaled Dot-Product Attention: The Mathematical Spotlight
Outside, the sky grew dark, and warm lamplight filled the Black Stone House.
"Professor," Piglet asked, "we saw the attention formula last chapter, but why 'scaled'? Why 'dot product'?"
Mr. Pallas's Cat walked to the whiteboard and wrote the full formula:
"Let's deconstruct this formula," he said. "
Piglet studied the formula carefully: "
"Exactly," Mr. Pallas's Cat said approvingly. "The dot product
Little Seal looked up from his math book: "Larger variance... would cause gradient problems for softmax?"
"Yes," Mr. Pallas's Cat explained. "The softmax function is sensitive to the magnitude of its inputs. If the dot product variance is large, softmax outputs approach one-hot vectors — some positions near 1, others near 0. This leads to very small gradients and training difficulties."
He demonstrated the scaling effect on the whiteboard:
"Dividing by
The Gentle Decision of Softmax
Mr. Pallas's Cat drew the softmax function curve on the whiteboard.
"The softmax is not only a normalization tool," he said. "It also implements gentle attention allocation — not a hard either/or choice, but a probabilistic soft allocation."
Piglet thought: "Softmax lets attention 'look at multiple places, but focus most on the most relevant'? Rather than 'only looking at one place'?"
"A concise summary," Mr. Pallas's Cat smiled. "The exponential function in softmax amplifies differences — higher similarity gets higher weight, but other positions still receive small weights. This allows the model to maintain a certain 'breadth of attention.'"
Little Seal added: "This makes sense cognitively. Human attention also has a focus and a periphery — we concentrate on important information but can still perceive the background."
"Yes," said Mr. Pallas's Cat. "The attention weight matrix
Orthogonal Computation Graphs: Seeing Attention's Focus
Mr. Pallas's Cat turned on the projector, and a neatly structured computation graph appeared on the screen.

"This is the orthogonal computation graph of the attention mechanism," Mr. Pallas's Cat said, pointing at the diagram. "We can see how attention progressively focuses from the input
Piglet carefully examined the layered structure in the diagram: "The input
"Yes," Mr. Pallas's Cat explained. "This graph clearly shows the information flow of attention:"
- Feature extraction layer:
extract features from different perspectives from the input - Relevance computation layer:
computes the relevance between all pairs of positions - Attention allocation layer: softmax converts relevance into a probability distribution
- Information integration layer: attention weights combine the value vectors
through weighted summation
Little Seal reflected: "This computational flow is strikingly similar to the cognitive process of human attention: extract features -> compute relevance -> allocate attention -> integrate information."
"That is precisely the charm of attention," said Mr. Pallas's Cat. "A simple mathematical formula captures a complex cognitive process."
Causal Attention's Temporal Constraint
Mr. Pallas's Cat drew a lower triangle on the attention matrix.
"In sequence tasks," he said, "we use causal attention: position
He wrote the causal mask on the whiteboard:
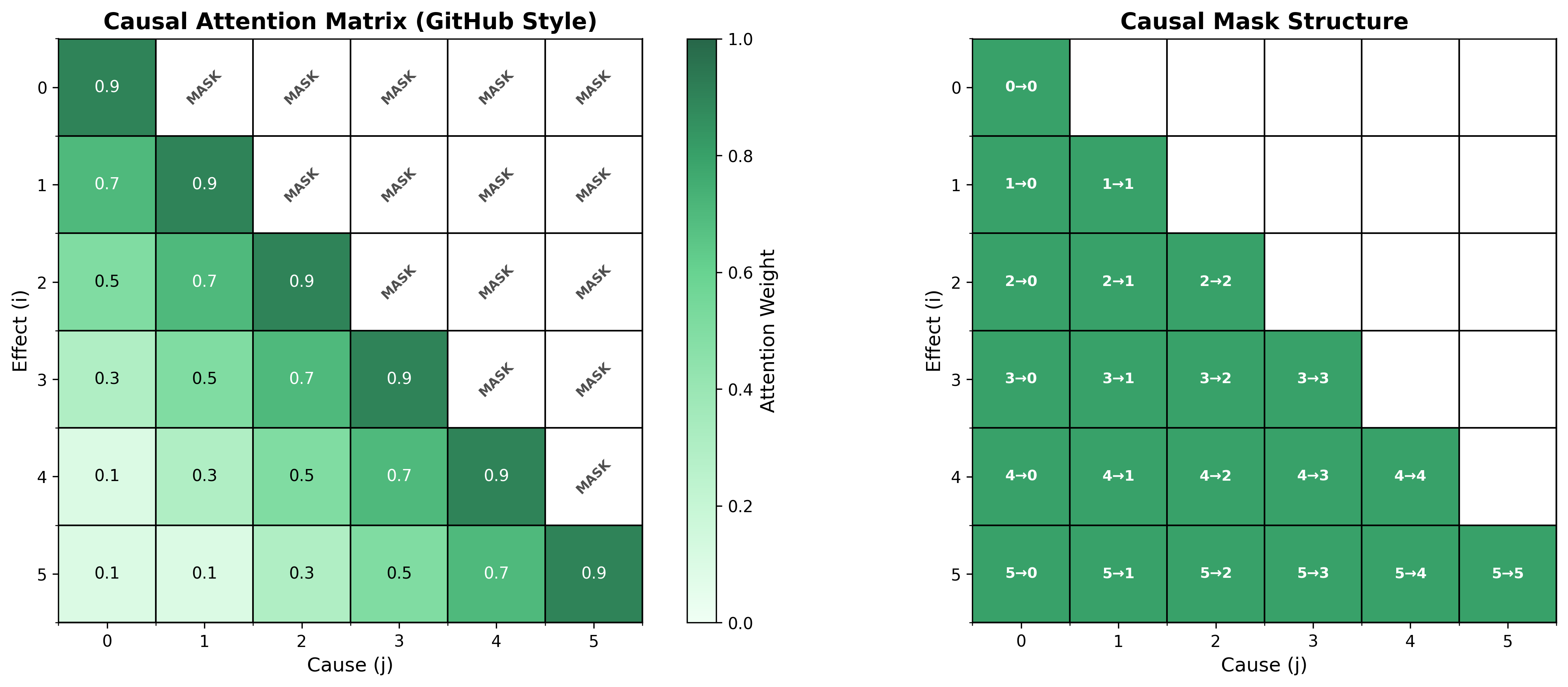
Piglet understood the design: "This ensures temporal ordering? The model cannot 'peek' at future information?"
"Exactly," said Mr. Pallas's Cat. "Causal attention is the foundation of autoregressive generation — when predicting the next token, you can only use tokens that have already been generated."
Little Seal thought: "But doesn't this also mean... information from early positions might be ignored by later positions? Because later positions have more history to look at?"
"Good observation," said Mr. Pallas's Cat. "This introduces a challenge of attention: positional bias. Later positions tend to attend to recent history and may overlook important early information. We need mechanisms to balance this bias."
Multi-Head Attention: The Wisdom of Multiple Perspectives
Outside, the night deepened, and the lights of boats on the Pearl River sparkled like stars.
"Professor," Piglet asked, "why do we need 'multi-head' attention? Isn't one head enough?"
Mr. Pallas's Cat walked to the whiteboard and drew a multi-perspective observation scene.
"Imagine you're looking at a painting," he said. "You can view it from a color perspective, a shape perspective, a texture perspective, a composition perspective. Each perspective sees different patterns."
Little Seal added: "In cognitive science, this is called multi-cue integration. We understand the world through multiple senses and multiple feature channels."
Mr. Pallas's Cat nodded: "Multi-head attention implements similar multi-perspective processing. Each head learns a different 'attention pattern.'"
He wrote the multi-head attention formula on the whiteboard:
where:
Piglet studied the formula carefully: "So each head has its own weight matrices
"Yes," said Mr. Pallas's Cat. "The key to multi-head attention is the decomposition of the representation space. Splitting a high-dimensional space into multiple subspaces, each attending to different features."
Head Diversity: Division of Labor and Cooperation
Mr. Pallas's Cat displayed a visualization of multi-head attention weights.
"In a trained model," he said, "different heads indeed learn different attention patterns:"
- Syntactic heads: attend to grammatical structure (e.g., subject-verb relations)
- Semantic heads: attend to semantically related words
- Positional heads: attend to relative positions (previous/next word)
- Rare-word heads: especially attend to rare or key words
Little Seal studied the visualization carefully: "Some heads focus locally (adjacent words), others globally (distant words)? This division of labor resembles different brain regions?"
"A good analogy," said Mr. Pallas's Cat. "Multi-head attention achieves functional specialization. Different heads are responsible for different 'cognitive functions,' ultimately integrated into a unified understanding."
Piglet thought: "But how do we ensure the heads truly divide the labor, rather than doing the same thing?"
"This is achieved through random initialization and training pressure," Mr. Pallas's Cat explained. "Random initialization lets heads start from different points, and the training objective (such as language modeling) encourages diversity — because diversity helps better predict the next word."
Head Importance Analysis
Mr. Pallas's Cat displayed research results on head importance on the whiteboard.
"Research shows," he said, "that different heads contribute differently to model performance. Some heads are 'critical heads' — removing them causes a large performance drop. Others are 'redundant heads' — removing them has little impact."
He listed the typical patterns of heads on the whiteboard:
- Local heads: attend to adjacent words (window size 2–5)
- Global heads: attend to the entire sequence
- Specific-pattern heads: attend to particular syntactic patterns (e.g., preposition-noun)
- Filler heads: attend to filler symbols (e.g., periods, commas)
"Interestingly," said Mr. Pallas's Cat, "the model learns these patterns automatically, without us explicitly specifying them. This reflects the power of learning — discovering useful attention patterns from data."
Self-Attention, Cross-Attention, and Encoder-Decoder Attention
Moonlight streamed like water outside, spilling over the red-brick buildings of Kangle Garden.
"Professor," Piglet asked, "besides scaled dot-product attention, what other attention variants are there?"
Mr. Pallas's Cat walked to the whiteboard and drew three attention architectures.
"Attention has three main forms," he said, "corresponding to different application scenarios:"
1. Self-Attention
"In self-attention,
Piglet understood the design: "Self-attention lets each word 'see' all other words, building a global understanding?"
"Exactly," said Mr. Pallas's Cat. "Self-attention is the core of the Transformer encoder — it builds a global representation of the sequence."
2. Cross-Attention
where
"Cross-attention is used for modeling relationships between sequences," Mr. Pallas's Cat explained. "For example, in machine translation, target-language words (
Little Seal added: "This simulates the 'alignment' process in translation — finding which source word each target word corresponds to."
3. Encoder-Decoder Attention
Mr. Pallas's Cat drew the complete Transformer architecture.
"In the standard encoder-decoder Transformer," he said, "there are three types of attention:"
- Encoder self-attention: relationships within the source language
- Decoder self-attention: relationships within the target language (with causal constraint)
- Encoder-Decoder attention: cross-attention from source language to target language
"This three-layer attention structure," Mr. Pallas's Cat summarized, "realizes a complete information flow from local to global, from source to target."
Mental Model: Attention as a Cognitive Architecture
Little Seal pulled a cognitive architecture book from the shelf. "Professor, this reminds me of the attention mechanisms in ACT-R (Adaptive Control of Thought—Rational) theory."
"A good connection," said Mr. Pallas's Cat. "Attention realizes several core functions of cognitive architectures."
He wrote on the whiteboard:
Mental Model: The Fourfold Cognitive Functions of Attention
- Information filtering (selectivity): ignore irrelevant information, reduce cognitive load
- Feature binding (integration): combine scattered features into holistic representations
- Relation discovery (association): discover semantic and syntactic relationships between elements
- Resource allocation (optimization): allocate limited computational resources to important tasks
"These four functions," Mr. Pallas's Cat explained, "correspond to the core needs of an intelligent system. Attention is not an add-on feature, but a necessary component of intelligence."
Piglet thought: "So attention is not just 'where to look,' but 'how to understand'? It determines how information is organized and interpreted?"
"A concise summary," Mr. Pallas's Cat answered. "Attention shapes the formation of representations. By choosing what to attend to and how, the model builds its mental representation of the world."
Attention and the Connection to Consciousness
Mr. Pallas's Cat wrote the word "Consciousness" on the whiteboard.
"In philosophy and cognitive science," he said, "attention and consciousness have a close relationship. William James said: 'Consciousness appears to be in the act of choosing.'"
Little Seal reflected: "Attention is the 'gateway' to consciousness? Only information that is attended to can enter consciousness?"
"This is an active area of research," said Mr. Pallas's Cat. "In machine learning, we don't need to solve the hard problem of consciousness. But attention does provide models with the capacity for information selection — and that is the cornerstone of intelligent behavior."
Key Takeaways
Mr. Pallas's Cat's Summary: The Art of Attention
- The essence of selectivity: attention is the mathematical realization of information selection — using softmax to convert relevance into probability distributions, achieving the cognitive leap from "what is there" to "what to look at"
- The wisdom of scaled dot-product: dividing by
solves the variance problem of high-dimensional dot products — embodying the engineering insight that "details determine success or failure" - The philosophy of multi-head division of labor: multi-head attention achieves functional specialization through representation space decomposition — different heads learn different attention patterns, finally integrated into unified understanding
- Causal temporal constraints: causal attention preserves temporal ordering through lower-triangular masking — the foundation of autoregressive generation — embodying the sequential logic of "the past determines the future"
- Mapping to cognitive functions: attention realizes the four cognitive functions of filtering, binding, discovering, and allocating — a core component of intelligent systems
Code Practice: Complete Attention System in Python
"Let's implement a complete attention system in Python," said Mr. Pallas's Cat, "from basic attention to multi-head attention, all the way to practical applications."
Full Attention Module Implementation
import numpy as np
import matplotlib.pyplot as plt
class AttentionModule:
"""Complete attention module (including positional encoding, masking, etc.)"""
def __init__(self, d_model, num_heads, max_seq_len=512):
"""Initialize the attention module
Args:
d_model: model dimension
num_heads: number of attention heads
max_seq_len: maximum sequence length (for positional encoding)
"""
assert d_model % num_heads == 0, "d_model must be divisible by num_heads"
self.d_model = d_model
self.num_heads = num_heads
self.depth = d_model // num_heads
self.max_seq_len = max_seq_len
# Attention weights
self.W_q = np.random.randn(d_model, d_model) * 0.01
self.W_k = np.random.randn(d_model, d_model) * 0.01
self.W_v = np.random.randn(d_model, d_model) * 0.01
self.W_o = np.random.randn(d_model, d_model) * 0.01
# Positional encoding (sine and cosine)
self.positional_encoding = self.create_positional_encoding(max_seq_len, d_model)
def create_positional_encoding(self, max_seq_len, d_model):
"""Create sinusoidal positional encoding"""
positional_encoding = np.zeros((max_seq_len, d_model))
for pos in range(max_seq_len):
for i in range(0, d_model, 2):
# Sine wave
positional_encoding[pos, i] = np.sin(pos / (10000 ** (2 * i / d_model)))
# Cosine wave
if i + 1 < d_model:
positional_encoding[pos, i + 1] = np.cos(pos / (10000 ** (2 * i / d_model)))
return positional_encoding
def scaled_dot_product_attention(self, Q, K, V, mask=None):
"""Scaled dot-product attention"""
d_k = K.shape[-1]
scores = np.matmul(Q, K.transpose(0, 1, 3, 2)) # Adjust dimension order
# Scale
scores = scores / np.sqrt(d_k)
# Apply mask
if mask is not None:
scores = scores + (mask * -1e9)
# softmax
attention_weights = self.softmax(scores, axis=-1)
# Weighted output
output = np.matmul(attention_weights, V)
return output, attention_weights
def softmax(self, x, axis=-1):
"""Stable softmax implementation"""
x_exp = np.exp(x - np.max(x, axis=axis, keepdims=True))
return x_exp / np.sum(x_exp, axis=axis, keepdims=True)
def split_heads(self, x, batch_size):
"""Split into multiple heads"""
x = x.reshape(batch_size, -1, self.num_heads, self.depth)
return x.transpose(0, 2, 1, 3) # (batch_size, num_heads, seq_len, depth)
def combine_heads(self, x, batch_size):
"""Combine multiple heads"""
x = x.transpose(0, 2, 1, 3) # (batch_size, seq_len, num_heads, depth)
return x.reshape(batch_size, -1, self.d_model)
def forward(self, x, mask=None, use_positional_encoding=True):
"""Forward pass
Args:
x: input sequence (batch_size, seq_len, d_model)
mask: attention mask
use_positional_encoding: whether to use positional encoding
"""
batch_size, seq_len, _ = x.shape
# Add positional encoding
if use_positional_encoding and seq_len <= self.max_seq_len:
x = x + self.positional_encoding[:seq_len]
# Linear transformations
Q = np.matmul(x, self.W_q) # (batch_size, seq_len, d_model)
K = np.matmul(x, self.W_k)
V = np.matmul(x, self.W_v)
# Split heads
Q = self.split_heads(Q, batch_size) # (batch_size, num_heads, seq_len, depth)
K = self.split_heads(K, batch_size)
V = self.split_heads(V, batch_size)
# Scaled dot-product attention
scaled_attention, attention_weights = self.scaled_dot_product_attention(Q, K, V, mask)
# Combine heads
scaled_attention = self.combine_heads(scaled_attention, batch_size) # (batch_size, seq_len, d_model)
# Output linear transformation
output = np.matmul(scaled_attention, self.W_o) # (batch_size, seq_len, d_model)
return output, attention_weights
def create_causal_mask(self, seq_len):
"""Create causal attention mask"""
mask = np.triu(np.ones((seq_len, seq_len)), k=1) # Upper triangle is 1
return mask # Positions with 1 need to be masked
def create_padding_mask(self, sequences, pad_token_id=0):
"""Create padding mask (for variable-length sequences)"""
mask = (sequences == pad_token_id).astype(float)
return mask[:, np.newaxis, np.newaxis, :] # Broadcast to attention score shape
# Full attention module demo
print("Full Attention Module Demo:")
print("=" * 60)
# Create attention module
d_model = 64
num_heads = 8
attention_module = AttentionModule(d_model=d_model, num_heads=num_heads, max_seq_len=100)
print(f"Attention module configuration:")
print(f" Model dimension (d_model): {d_model}")
print(f" Number of heads (num_heads): {num_heads}")
print(f" Per-head dimension (depth): {d_model // num_heads}")
print(f" Maximum sequence length: {attention_module.max_seq_len}")
print(f" Positional encoding shape: {attention_module.positional_encoding.shape}")
# Test data
batch_size = 2
seq_len = 20
x_input = np.random.randn(batch_size, seq_len, d_model)
print(f"\nInput data shape: {x_input.shape}")
# Unmasked attention
output_no_mask, attn_weights_no_mask = attention_module.forward(
x_input, mask=None, use_positional_encoding=True
)
print(f"Unmasked output shape: {output_no_mask.shape}")
print(f"Attention weights shape: {attn_weights_no_mask.shape}")
# Causal masked attention
causal_mask = attention_module.create_causal_mask(seq_len)
output_causal, attn_weights_causal = attention_module.forward(
x_input, mask=causal_mask, use_positional_encoding=True
)
print(f"\nCausal masked output shape: {output_causal.shape}")
# Visualize positional encoding
def visualize_positional_encoding(pe, title="Positional Encoding"):
"""Visualize positional encoding"""
fig, axes = plt.subplots(1, 2, figsize=(14, 6))
# Heatmap
im1 = axes[0].imshow(pe[:50, :].T, cmap='RdBu', aspect='auto')
axes[0].set_xlabel('Position (pos)')
axes[0].set_ylabel('Dimension (i)')
axes[0].set_title(f'{title} - Heatmap (first 50 positions)')
plt.colorbar(im1, ax=axes[0])
# Sine/cosine wave visualization
axes[1].plot(pe[:100, 0], label='Dimension 0 (sin)', linewidth=2)
axes[1].plot(pe[:100, 1], label='Dimension 1 (cos)', linewidth=2)
axes[1].plot(pe[:100, 2], label='Dimension 2 (sin)', linewidth=2)
axes[1].plot(pe[:100, 3], label='Dimension 3 (cos)', linewidth=2)
axes[1].set_xlabel('Position (pos)')
axes[1].set_ylabel('Encoding value')
axes[1].set_title(f'{title} - Sine/Cosine Waves')
axes[1].legend()
axes[1].grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig(f'/tmp/{title.lower().replace(" ", "_")}.png', dpi=150, bbox_inches='tight')
plt.close()
print(f"{title} visualization saved to /tmp/{title.lower().replace(' ', '_')}.png")
# Run visualization
visualize_positional_encoding(attention_module.positional_encoding, "Sinusoidal Positional Encoding")
# Analyze positional encoding properties
print("\nPositional Encoding Property Analysis:")
print("=" * 60)
pe = attention_module.positional_encoding
print(f"Positional encoding shape: {pe.shape}")
print(f"Positional encoding range: [{pe.min():.3f}, {pe.max():.3f}]")
print(f"Positional encoding mean: {pe.mean():.6f} (close to 0)")
print(f"Positional encoding std: {pe.std():.6f}")
# Check positional encoding uniqueness
pos1 = pe[10] # Encoding at position 10
pos2 = pe[20] # Encoding at position 20
pos3 = pe[30] # Encoding at position 30
similarity_12 = np.dot(pos1, pos2) / (np.linalg.norm(pos1) * np.linalg.norm(pos2))
similarity_13 = np.dot(pos1, pos3) / (np.linalg.norm(pos1) * np.linalg.norm(pos3))
similarity_23 = np.dot(pos2, pos3) / (np.linalg.norm(pos2) * np.linalg.norm(pos3))
print(f"\nPositional encoding similarities:")
print(f" Position 10 vs Position 20: {similarity_12:.4f}")
print(f" Position 10 vs Position 30: {similarity_13:.4f}")
print(f" Position 20 vs Position 30: {similarity_23:.4f}")
print(f" Interpretation: similarity should decrease as positional distance increases")Attention Pattern Analysis Tool
class AttentionAnalyzer:
"""Attention pattern analysis tool"""
def __init__(self):
pass
def analyze_attention_patterns(self, attention_weights, sequence=None, sample_idx=0):
"""Analyze attention patterns"""
batch_size, num_heads, seq_len_q, seq_len_k = attention_weights.shape
print(f"Attention Pattern Analysis (sample {sample_idx}):")
print("=" * 60)
print(f" Batch size: {batch_size}")
print(f" Number of heads: {num_heads}")
print(f" Query sequence length: {seq_len_q}")
print(f" Key sequence length: {seq_len_k}")
# Analyze attention pattern for each head
head_patterns = []
for h in range(num_heads):
head_weights = attention_weights[sample_idx, h]
# Compute attention distribution statistics
entropy = self.compute_attention_entropy(head_weights)
concentration = self.compute_attention_concentration(head_weights)
diagonal_strength = self.compute_diagonal_strength(head_weights)
local_focus = self.compute_local_focus(head_weights, window_size=3)
pattern_type = self.classify_attention_pattern(
entropy, concentration, diagonal_strength, local_focus
)
head_patterns.append({
'head_idx': h,
'entropy': entropy,
'concentration': concentration,
'diagonal_strength': diagonal_strength,
'local_focus': local_focus,
'pattern_type': pattern_type
})
# Print analysis results
print(f"\nAttention Head Pattern Classification:")
pattern_counts = {}
for pattern in head_patterns:
ptype = pattern['pattern_type']
pattern_counts[ptype] = pattern_counts.get(ptype, 0) + 1
if pattern['head_idx'] < 5: # Only print first 5 heads
print(f" Head {pattern['head_idx']}: {ptype:15s} "
f"entropy={pattern['entropy']:.3f} concentration={pattern['concentration']:.3f}")
print(f"\nPattern Distribution:")
for ptype, count in pattern_counts.items():
print(f" {ptype:15s}: {count} heads ({count/num_heads*100:.1f}%)")
# Visualize typical patterns
self.visualize_typical_patterns(attention_weights[sample_idx], head_patterns, sequence)
return head_patterns
def compute_attention_entropy(self, attention_matrix):
"""Compute entropy of attention distribution (measure of spread)"""
# Compute entropy for each row, then average
entropies = []
for i in range(attention_matrix.shape[0]):
row = attention_matrix[i]
# Avoid log(0)
row = np.clip(row, 1e-10, 1.0)
entropy = -np.sum(row * np.log(row))
entropies.append(entropy)
return np.mean(entropies)
def compute_attention_concentration(self, attention_matrix):
"""Compute attention concentration (average of maximum weights)"""
max_weights = np.max(attention_matrix, axis=1)
return np.mean(max_weights)
def compute_diagonal_strength(self, attention_matrix):
"""Compute diagonal strength (degree of self-attention)"""
seq_len = min(attention_matrix.shape[0], attention_matrix.shape[1])
diagonal_weights = [attention_matrix[i, i] for i in range(seq_len)]
return np.mean(diagonal_weights)
def compute_local_focus(self, attention_matrix, window_size=3):
"""Compute local focus (degree of attending to nearby positions)"""
seq_len = attention_matrix.shape[0]
local_weights = []
for i in range(seq_len):
# Define local window
start = max(0, i - window_size)
end = min(seq_len, i + window_size + 1)
# Compute attention weights within the window
window_weight = np.sum(attention_matrix[i, start:end])
local_weights.append(window_weight)
return np.mean(local_weights)
def classify_attention_pattern(self, entropy, concentration, diagonal_strength, local_focus):
"""Classify attention pattern"""
if diagonal_strength > 0.7:
return "self-focused"
elif local_focus > 0.8:
return "locally-focused"
elif concentration > 0.5 and entropy < 1.0:
return "concentrated"
elif entropy > 2.0:
return "distributed"
else:
return "mixed"
def visualize_typical_patterns(self, attention_weights, head_patterns, sequence=None, max_heads=6):
"""Visualize typical attention patterns"""
num_heads = attention_weights.shape[0]
# Select heads with different patterns
selected_heads = []
pattern_seen = set()
for pattern in head_patterns:
ptype = pattern['pattern_type']
if ptype not in pattern_seen and len(selected_heads) < max_heads:
selected_heads.append(pattern['head_idx'])
pattern_seen.add(ptype)
# If not enough, supplement with other heads
if len(selected_heads) < max_heads:
for pattern in head_patterns:
if pattern['head_idx'] not in selected_heads and len(selected_heads) < max_heads:
selected_heads.append(pattern['head_idx'])
# Visualization
fig, axes = plt.subplots(2, 3, figsize=(15, 10))
axes = axes.flatten()
for idx, head_idx in enumerate(selected_heads[:6]):
ax = axes[idx]
head_weights = attention_weights[head_idx]
im = ax.imshow(head_weights, cmap='viridis', aspect='auto', vmin=0, vmax=1)
# Add text labels (if sequence is provided)
if sequence is not None and len(sequence) <= 20:
ax.set_xticks(range(len(sequence)))
ax.set_yticks(range(len(sequence)))
ax.set_xticklabels(sequence, rotation=45, fontsize=8)
ax.set_yticklabels(sequence, fontsize=8)
ax.set_xlabel('Key Position')
ax.set_ylabel('Query Position')
# Get pattern info for this head
pattern_info = next(p for p in head_patterns if p['head_idx'] == head_idx)
pattern_type = pattern_info['pattern_type']
ax.set_title(f'Head {head_idx}: {pattern_type}\n'
f'entropy={pattern_info["entropy"]:.2f} concentration={pattern_info["concentration"]:.2f}')
ax.grid(True, which='both', color='white', linewidth=0.5, alpha=0.3)
# Add colorbar
plt.colorbar(im, ax=ax, fraction=0.046, pad=0.04)
# Hide unused subplots
for idx in range(len(selected_heads), 6):
axes[idx].axis('off')
plt.suptitle('Multi-Head Attention Typical Pattern Analysis', fontsize=14)
plt.tight_layout()
plt.savefig('/tmp/attention_patterns_analysis.png', dpi=150, bbox_inches='tight')
plt.close()
print(f"Attention pattern analysis visualization saved to /tmp/attention_patterns_analysis.png")
# Run attention analysis
print("\nAttention Pattern Analysis Demo:")
print("=" * 60)
# Create analyzer
analyzer = AttentionAnalyzer()
# Analyze unmasked attention
print("Analyzing unmasked attention patterns:")
head_patterns_no_mask = analyzer.analyze_attention_patterns(
attn_weights_no_mask,
sample_idx=0,
sequence=[f"w{i}" for i in range(min(20, seq_len))]
)
# Analyze causal attention
print("\nAnalyzing causal attention patterns:")
head_patterns_causal = analyzer.analyze_attention_patterns(
attn_weights_causal,
sample_idx=0,
sequence=[f"w{i}" for i in range(min(20, seq_len))]
)
# Compare the impact of the two mask types
print("\nComparison of Mask Impact on Attention Patterns:")
print("=" * 60)
# Select the same head for comparison
head_idx = 0 # Compare the first head
no_mask_pattern = head_patterns_no_mask[head_idx]
causal_pattern = head_patterns_causal[head_idx]
print(f"Head {head_idx} pattern changes:")
print(f" Pattern: {no_mask_pattern['pattern_type']} -> {causal_pattern['pattern_type']}")
print(f" Entropy: {no_mask_pattern['entropy']:.3f} -> {causal_pattern['entropy']:.3f} "
f"(change: {causal_pattern['entropy'] - no_mask_pattern['entropy']:+.3f})")
print(f" Concentration: {no_mask_pattern['concentration']:.3f} -> {causal_pattern['concentration']:.3f} "
f"(change: {causal_pattern['concentration'] - no_mask_pattern['concentration']:+.3f})")
print(f" Diagonal strength: {no_mask_pattern['diagonal_strength']:.3f} -> {causal_pattern['diagonal_strength']:.3f}")
print(f" Local focus: {no_mask_pattern['local_focus']:.3f} -> {causal_pattern['local_focus']:.3f}")
print(f"\nExpected effects of causal masking:")
print(f" 1. Reduced entropy (attention more focused, since future positions are masked)")
print(f" 2. Increased diagonal strength (more self-attention, since no future to look at)")
print(f" 3. Increased local focus (forced to attend more to recent history)")Attention in Practical Applications
def attention_in_text_classification():
"""Demonstration of attention applied to text classification"""
# Simulate a text classification task
class TextClassifierWithAttention:
"""Text classifier with attention"""
def __init__(self, vocab_size, embedding_dim, d_model, num_heads, num_classes):
"""Initialize classifier"""
# Word embedding layer
self.embedding = np.random.randn(vocab_size, embedding_dim) * 0.01
# Attention layer
self.attention = AttentionModule(d_model=d_model, num_heads=num_heads)
# Classification layer
self.W_classify = np.random.randn(d_model, num_classes) * 0.01
self.b_classify = np.zeros((1, num_classes))
self.d_model = d_model
self.embedding_dim = embedding_dim
# Projection layer (if dimension adjustment is needed)
if embedding_dim != d_model:
self.W_proj = np.random.randn(embedding_dim, d_model) * 0.01
else:
self.W_proj = None
def forward(self, token_ids, attention_mask=None):
"""Forward pass"""
batch_size, seq_len = token_ids.shape
# Word embedding
embedded = np.zeros((batch_size, seq_len, self.embedding_dim))
for b in range(batch_size):
for t in range(seq_len):
token_id = token_ids[b, t]
embedded[b, t] = self.embedding[token_id]
# Project to d_model dimension (if needed)
if self.W_proj is not None:
embedded = np.matmul(embedded, self.W_proj)
# Attention layer
if attention_mask is not None:
# Convert attention_mask to attention mask format
attn_mask = attention_mask[:, np.newaxis, np.newaxis, :]
attn_mask = (1 - attn_mask) * -1e9 # Pad positions set to negative infinity
else:
attn_mask = None
attended, attention_weights = self.attention.forward(
embedded, mask=attn_mask, use_positional_encoding=True
)
# Pooling (using attention-weighted average)
# Compute sequence importance weights
importance_weights = self.compute_importance_weights(attended)
# Weighted average pooling
pooled = np.sum(attended * importance_weights[:, :, np.newaxis], axis=1)
# Classification
logits = np.matmul(pooled, self.W_classify) + self.b_classify
return logits, attention_weights, importance_weights
def compute_importance_weights(self, attended):
"""Compute importance weights for each position in the sequence"""
# Simple method: use a forward pass through a final linear layer
# More complex method: use a separate attention layer
batch_size, seq_len, d_model = attended.shape
# Use simple linear transformation + softmax
W_importance = np.random.randn(d_model, 1) * 0.01
importance_scores = np.matmul(attended, W_importance) # (batch_size, seq_len, 1)
importance_scores = importance_scores.reshape(batch_size, seq_len)
# softmax normalization
exp_scores = np.exp(importance_scores - np.max(importance_scores, axis=1, keepdims=True))
importance_weights = exp_scores / np.sum(exp_scores, axis=1, keepdims=True)
return importance_weights
print("Attention in Text Classification Demo:")
print("=" * 60)
# Simulated data
vocab_size = 1000
embedding_dim = 128
d_model = 64
num_heads = 4
num_classes = 3
# Create classifier
classifier = TextClassifierWithAttention(
vocab_size=vocab_size,
embedding_dim=embedding_dim,
d_model=d_model,
num_heads=num_heads,
num_classes=num_classes
)
print(f"Classifier configuration:")
print(f" Vocabulary size: {vocab_size}")
print(f" Embedding dimension: {embedding_dim}")
print(f" Model dimension: {d_model}")
print(f" Number of attention heads: {num_heads}")
print(f" Number of classes: {num_classes}")
# Simulated input
batch_size = 4
seq_len = 25
# Generate random token IDs (simulating text)
token_ids = np.random.randint(0, vocab_size-10, (batch_size, seq_len))
# Create attention mask (simulating padding)
attention_mask = np.ones((batch_size, seq_len))
for b in range(batch_size):
# Randomly set some padding positions
pad_start = np.random.randint(seq_len-5, seq_len)
attention_mask[b, pad_start:] = 0
print(f"\nInput data:")
print(f" token_ids shape: {token_ids.shape}")
print(f" attention_mask shape: {attention_mask.shape}")
print(f" Ratio of valid tokens: {attention_mask.sum() / attention_mask.size:.1%}")
# Forward pass
logits, attn_weights, importance_weights = classifier.forward(token_ids, attention_mask)
print(f"\nOutput results:")
print(f" logits shape: {logits.shape}")
print(f" attention weights shape: {attn_weights.shape}")
print(f" importance weights shape: {importance_weights.shape}")
# Visualize importance weights
sample_idx = 0
plt.figure(figsize=(12, 4))
# Subplot 1: Attention weights (first head)
plt.subplot(1, 2, 1)
im1 = plt.imshow(attn_weights[sample_idx, 0], cmap='viridis', aspect='auto')
plt.colorbar(im1, label='Attention Weight')
plt.xlabel('Key Position')
plt.ylabel('Query Position')
plt.title(f'Attention Weights - Head 0 (sample {sample_idx})')
# Add valid token boundary
valid_len = int(attention_mask[sample_idx].sum())
plt.axvline(x=valid_len-0.5, color='red', linestyle='--', linewidth=2, label='Valid token boundary')
plt.axhline(y=valid_len-0.5, color='red', linestyle='--', linewidth=2)
plt.legend()
# Subplot 2: Importance weights
plt.subplot(1, 2, 2)
positions = range(seq_len)
plt.bar(positions, importance_weights[sample_idx], alpha=0.7)
plt.axvline(x=valid_len-0.5, color='red', linestyle='--', linewidth=2, label='Valid token boundary')
plt.xlabel('Position')
plt.ylabel('Importance Weight')
plt.title(f'Sequence Importance Weights (sample {sample_idx})')
plt.legend()
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig('/tmp/attention_text_classification.png', dpi=150, bbox_inches='tight')
plt.close()
print(f"\nText classification attention visualization saved to /tmp/attention_text_classification.png")
# Analyze the relationship between attention and importance
print(f"\nAttention and Importance Analysis:")
print("=" * 60)
# Compute correlation between attention weights and importance weights
attention_matrix = attn_weights[sample_idx, 0] # First head
importance_vector = importance_weights[sample_idx]
# Compute average attention per query position
avg_attention_per_query = np.mean(attention_matrix, axis=1) # Average attention allocation per query position
# Compute correlation
correlation = np.corrcoef(avg_attention_per_query[:valid_len], importance_vector[:valid_len])[0, 1]
print(f" Effective sequence length: {valid_len}")
print(f" Attention spread (entropy): {analyzer.compute_attention_entropy(attention_matrix[:valid_len, :valid_len]):.3f}")
print(f" Importance weight spread (entropy): {analyzer.compute_attention_entropy(importance_vector[:valid_len].reshape(1, -1)):.3f}")
print(f" Attention-importance correlation: {correlation:.3f}")
print(f"\nInterpretation:")
print(f" Correlation near 1: positions the model attends to are also the ones it considers important")
print(f" Correlation near 0: attention and importance judgments are unrelated")
print(f" Expected in practice: moderate positive correlation, indicating some consistency")
# Run text classification demo
attention_in_text_classification()"Remember," Mr. Pallas's Cat summarized, "attention is the eye of intelligence — it teaches models how to see the world, how to select information, how to build relationships. From the mathematical elegance of scaled dot-product to the cognitive wisdom of multi-head division of labor, attention mechanisms show how simple principles can give rise to complex capabilities. Most importantly, attention reminds us: intelligence is not passive reception, but active construction; understanding is not copying the world, but creating meaning. On this path, choice matters more than reception, and relationships more than elements."
Mr. Pallas's Cat's Reflection Questions
Hands-On Exploration (for Piglet)
- Attention variants: implement different attention variants (linear attention, sparse attention, local attention). Compare their computational complexity and effectiveness.
- Visualization tool: develop an interactive attention visualization tool for uploading text and exploring attention patterns.
- Attention distillation: train a large model, then use attention distillation to train a small model. Can the small model learn the large model's attention patterns?
Historical Investigation (for Little Seal)
- Cross-disciplinary origins: research the development of attention across psychology, neuroscience, and computer vision. How did these fields influence each other?
- The Transformer revolution's social impact: investigate how the Transformer architecture changed the AI research ecosystem — from papers to open source to industry.
- Neuroscience validation: is there neuroscientific evidence that the brain uses attention-like mechanisms? What have fMRI and EEG studies found?
Comprehensive Reflection
- Philosophical reflection: does the "selectivity" of attention mechanisms imply an epistemological stance — that knowledge is not objective reflection but active construction?
- Ethical challenge: attention mechanisms let models "focus" on certain information, which may amplify bias. How do we design "fair attention"?
- Creative exercise: design a "meta-attention" mechanism that lets the model learn to adjust its own attention strategy. How would you design the reward function?
- Extreme challenge: prove that attention mechanisms can approximate any sequence-to-sequence function (universal approximation theorem). What conditions are needed?
Coming Up Next
The fragrance of tea lingered in the Black Stone House. Night grew deep and quiet.
"Today we dove deep into the art of attention," said Mr. Pallas's Cat. "We saw how attention becomes the 'eyes' of the model. But eyes alone are not enough — how do we organize these eyes into a complete 'visual system'?"
Piglet asked curiously: "Organizing eyes? Like... stacking multiple attention layers?"
"Yes," Mr. Pallas's Cat explained. "In the next chapter, we explore the encoder-decoder stack — understanding how Transformers build powerful sequence-to-sequence models through multiple layers of attention and feedforward networks."
Little Seal flipped through his notebook. "This leads to the core architecture of modern AI. Historically, how did the encoder-decoder structure evolve from simple Seq2Seq to the Transformer?"
Mr. Pallas's Cat smiled: "We'll take it slow. See you in the next chapter."
Piglet's note: I implemented a complete attention module with positional encoding, multi-head attention, and causal masking. The most fascinating part is positional encoding — the sinusoidal waves truly provide a unique identifier for each position! Visualization shows different heads attend to different patterns: some local, some syntactic, some focusing on keywords. Attention really is the model's "eyes."
Little Seal's note: I researched the history of attention and was struck by its simplicity and power. The 2017 Transformer paper was only 8 pages, yet changed the AI field. Most profound is the design of positional encoding — using sine and cosine functions to encode absolute position while enabling relative position computation. The beauty of mathematical simplicity.
Mr. Pallas's Cat's closing words: Attention teaches a fundamental lesson about intelligent design: perception begins with selection, understanding begins with relationships. In this mechanism, we see the perfect union of mathematics and cognition — simple dot products and softmax realizing complex selection and integration. Most importantly, it reminds us: good design often arises from insight into the essence of a problem, not from piling up techniques. On this path, insight matters more than skill, understanding more than memorization. We'll take it slow — understanding is what matters most.