Chapter 13: The Contest Between Forgetting and Causality
Mr. Pallas's Cat's Warm Welcome
In the previous chapter, we explored LSTM's chains of memory — achieving selective memory through gating mechanisms. But memory has more than one form. Today, we answer a crucial question: which is better — incremental memory or direct access? When LSTM's forget gate meets the causal attention of attention mechanisms, what sparks of thought will fly? Let's take it slow and explore the contest between forgetting and causality.
Core Question: Two Philosophies of Memory
"Professor," Piglet pointed at two different network architectures on the screen, "LSTM incrementally updates memory through a forget gate, but attention mechanisms seem to directly 'see' all historical information. Which approach is smarter?"
It was a winter afternoon in Kangle Garden at Sun Yat-sen University. Sunlight streamed through the glass windows into the Black Stone House study, casting warm patches of light on the red-brick floor. Outside, sparrows hopped among the banyan branches, chirping about the day's catch. Inside, steam rose from the gongfu tea set; the wall clock ticked away, marking every collision of ideas.
By the window, Little Seal said: "That's a profound comparison. Historically, there are two main theories of memory mechanisms: incremental integration and direct access. LSTM represents the former; attention mechanisms represent the latter."
Mr. Pallas's Cat gently set down his teacup and smiled. "You've raised the core philosophical question of sequence modeling. Memory is not a single process, but a collaboration of multiple mechanisms. Today, we compare these two different philosophies of memory."
Incremental Memory: The Wisdom and Limits of LSTM
Piglet walked to the whiteboard and drew LSTM's structure.
"Professor, LSTM carries long-term memory through the cell state
Little Seal added: "From a cognitive science perspective, incremental memory resembles 'working memory' — limited capacity, requiring constant updating. But humans also have 'long-term memory' that can store vast amounts of information and access it directly."
Mr. Pallas's Cat nodded: "Yes, LSTM's limitations lie in information capacity and access efficiency."
He wrote LSTM's key equation on the whiteboard:
"Look at this update formula," he said. "The cell state
- Information decay: even if the forget gate
is close to 1, information gradually blurs over time - Limited capacity:
has a fixed dimension and cannot store unlimited information - Indirect access: to retrieve early information, you must propagate through many time steps
Piglet thought: "So LSTM is like... a diary that is constantly rewritten? Each time you update only the current page, but old pages gradually fade?"
"A vivid analogy," Mr. Pallas's Cat smiled. "LSTM's incremental memory is well-suited for local dependencies — the association between current information and recent history. But for long-range dependencies, information must 'travel' far through time and may be lost along the way."
Revisiting Vanishing Gradients
Mr. Pallas's Cat drew a gradient propagation diagram for a long sequence on the whiteboard.
Time step 1 ← Time step 2 ← ... ← Time step 100"Even though LSTM alleviates vanishing gradients," he explained, "gradients still decay when propagating through long sequences. More importantly, error signals can be diluted — the adjustment signal for early time steps gets overwritten by later updates."
Little Seal mused: "It's like... in a long game of telephone, the original message is easily distorted?"
"Exactly," said Mr. Pallas's Cat. "LSTM's gating mechanism is an ingenious engineering solution, but it may not be the optimal cognitive model. Human memory seems able to directly access important moments from the past."
Causal Attention: The Attention Revolution
Outside, the sky grew dark, and warm lamplight filled the Black Stone House.
"Professor," Piglet asked, "if LSTM is 'incremental memory,' what is the attention mechanism?"
Mr. Pallas's Cat walked to the whiteboard and wrote the core idea of attention:
At each moment, directly compute relevance with all historical moments
He drew a diagram of attention on the whiteboard:
At time t, attend to: time 1, time 2, ..., time t"The key innovation of the attention mechanism," Mr. Pallas's Cat explained, "is breaking free from the constraints of temporal order. At time
Little Seal studied the diagram carefully: "It's like... having perfect memory? You can instantly recall any past moment?"
"More precisely," Mr. Pallas's Cat corrected, "it is selective recall. The attention mechanism computes a 'relevance score' between each historical moment and the current moment, then combines historical information through weighted summation."
He wrote the scaled dot-product attention formula on the whiteboard:
where:
(Query): the current moment's "inquiry" — what you want to know (Key): historical moments' "keys" — what information is available (Value): historical moments' "values" — the specific content
Piglet studied the formula carefully: "
"Precise understanding," Mr. Pallas's Cat said approvingly. "The attention mechanism achieves content-addressable memory: directly accessing relevant history (
The Constraint of Causal Attention
Mr. Pallas's Cat prominently wrote the word "causal" on the whiteboard.
"In sequence modeling," he said, "we typically use causal attention: time
He drew a lower-triangular matrix on the attention diagram:
[• 0 0 0] time 1 can only see itself
[• • 0 0] time 2 can see 1,2
[• • • 0] time 3 can see 1,2,3
[• • • •] time 4 can see 1,2,3,4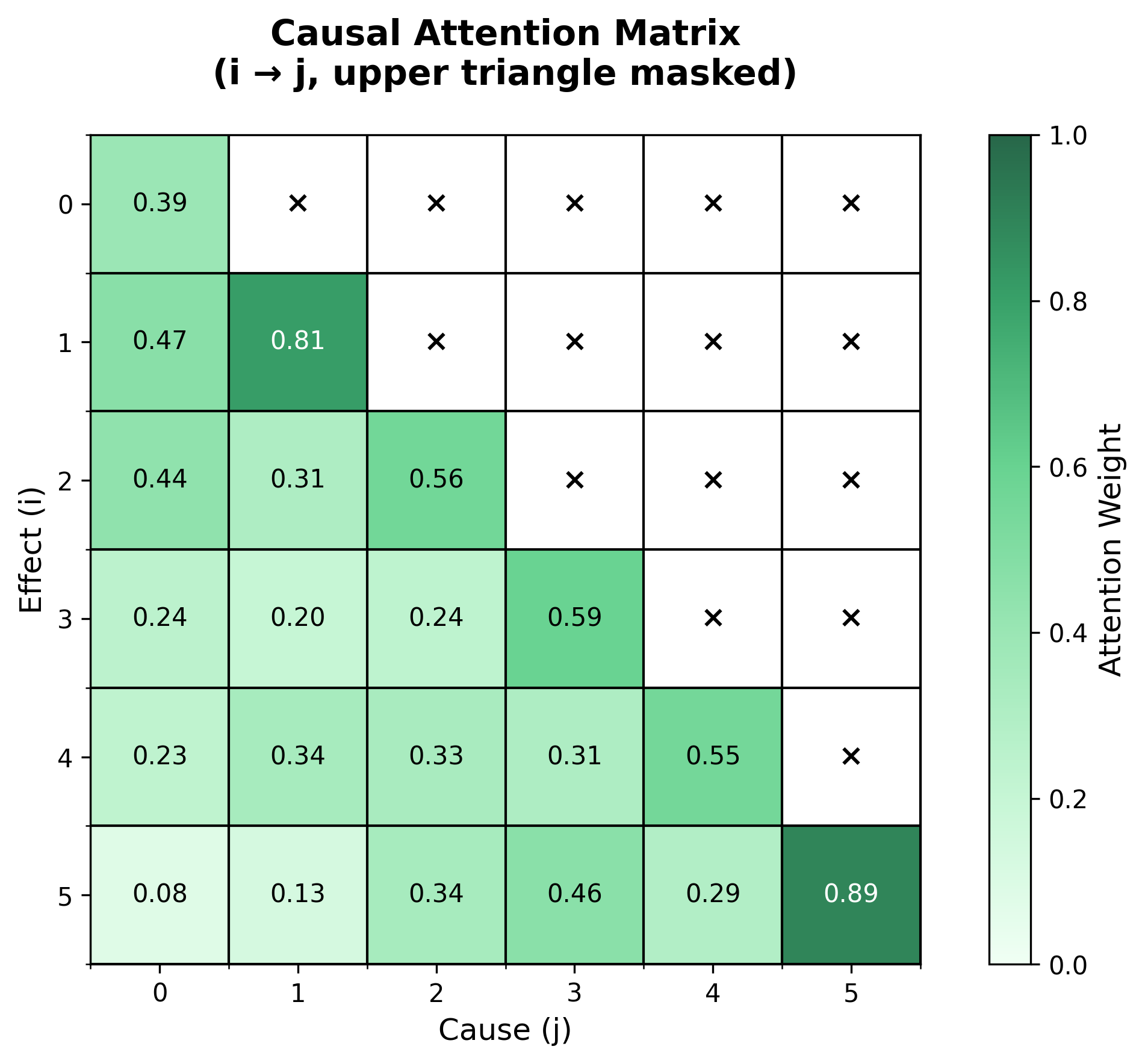
"This causal constraint," Mr. Pallas's Cat explained, "guarantees the autoregressive property of sequence generation: when predicting the next token, you can only use already-generated tokens."
Little Seal thought: "It's like... when writing, you can only look back at what you've already written, not peek ahead at the outline?"
"A good analogy," said Mr. Pallas's Cat. "Causal attention preserves temporal ordering while enabling direct access to history. This is its fundamental distinction from LSTM."
Orthogonal Computation Graphs: Seeing Two Kinds of Memory Flow
Mr. Pallas's Cat turned on the projector, and two neat computation graphs appeared side by side on the screen.

"On the left is LSTM's computation graph," Mr. Pallas's Cat said, pointing. "Notice the horizontal flow of the cell state

"On the right is the attention mechanism's computation graph," he continued. "Notice the parallel computation of Query
Piglet compared the two diagrams: "LSTM is a 'serial assembly line'; attention is a 'parallel query'? One like a production line, the other like a search engine?"
"A concise summary," Mr. Pallas's Cat smiled. "LSTM's computation is temporally recurrent:
Little Seal mused: "This parallelism brings efficiency advantages? Transformers train faster than RNNs/LSTMs?"
"Yes," said Mr. Pallas's Cat. "But more importantly, the difference in modeling capacity. Attention mechanisms can capture dependencies at arbitrary distances, unconstrained by temporal intervals."
Comparing Memory Capacity
Mr. Pallas's Cat listed the capacity characteristics of both mechanisms on the whiteboard:
LSTM:
- Memory capacity: Fixed (hidden state dimension)
- Access method: Sequential scan (linear in time)
- Long-range dependency: May decay
- Parallelism: Limited (temporal recurrence)
Attention mechanism:
- Memory capacity: Sequence length (theoretically unlimited)
- Access method: Direct access (constant time)
- Long-range dependency: Perfectly preserved
- Parallelism: Highly parallel
| LSTM | Attention | |
|---|---|---|
| Memory capacity | Fixed (hidden state dimension) | Sequence length (theoretically unlimited) |
| Access method | Sequential scan (linear in time) | Direct access (constant time) |
| Long-range dependency | May decay | Perfectly preserved |
| Parallelism | Limited (temporal recurrence) | Highly parallel |
Piglet thought: "So attention is theoretically more powerful? But what's the cost in practice?"
"Good question," Mr. Pallas's Cat said. "The cost of attention is computational complexity: an
Mental Model: Balancing Two Philosophies of Memory
Little Seal took a philosophy book from the shelf. "Professor, this reminds me of the historical debate between 'empiricism' and 'rationalism.'"
"Good connection," said Mr. Pallas's Cat. "LSTM is like empiricism — knowledge accumulates incrementally from experience. Attention is like rationalism — directly grasping relationships through reasoning."
He wrote the mental models on the whiteboard:
Mental Model: Dual Processing of Memory
Incremental integration (LSTM philosophy):
- Information is gradually absorbed and updated over time
- Emphasizes process and evolution
- Suitable for learning local patterns and temporal dynamics
Direct access (Attention philosophy):
- Directly extracts relevant information as needed
- Emphasizes structure and relationships
- Suitable for capturing long-range dependencies and structured patterns
"These two mechanisms," Mr. Pallas's Cat explained, "are not mutually exclusive but complementary. In fact, modern architectures like the Transformer use both attention (capturing long-range dependencies) and feedforward networks (processing local patterns)."
Piglet thought: "So the best solution might be... combining both? Using attention for large-scale structure and other mechanisms for local details?"
"Exactly," Mr. Pallas's Cat answered. "This is the design wisdom of deep learning: there is no silver bullet, only trade-offs. Different problems require different inductive biases."
The Value and Limits of Forgetting
Mr. Pallas's Cat focused the discussion on "forgetting" on the whiteboard.
"LSTM's forget gate embodies the wisdom of active forgetting," he said. "But the attention mechanism's 'perfect memory' also has its costs."
He listed the pros and cons of forgetting:
Benefits of forgetting:
- Prevents overfitting: forgets irrelevant details, focuses on core patterns
- Computationally efficient: need not store all history
- Prevents catastrophic interference: new knowledge doesn't completely overwrite old
Costs of forgetting:
- Information loss: may forget important information
- Long-range dependency difficulty: early information may be completely lost
- Breaks historical continuity: loses the complete record of temporal evolution
Little Seal added: "In cognitive science, forgetting is not only a defect but also cognitive optimization. The brain needs to forget most information to focus on important patterns."
"Yes," said Mr. Pallas's Cat. "LSTM's forget gate is a computational realization of this cognitive optimization. But the attention mechanism proposes an alternative: store everything, but attend selectively."
Key Takeaways
Mr. Pallas's Cat's Summary: The Wisdom of Memory Philosophy
- Two memory paradigms: LSTM represents incremental memory (temporally recurrent updates); attention represents direct-access memory (content-addressable access) — two fundamental philosophies of sequence processing
- The value of incremental integration: LSTM achieves selective memory and forgetting through gating — suitable for learning temporal dynamics and local patterns — embodying the cognitive model of "memory as process"
- The revolution of direct access: attention mechanisms break free from temporal constraints, enabling dependency modeling at arbitrary distances — embodying the structured thinking of "memory as relationship"
- The necessity of causal constraints: in sequence generation, causal attention preserves temporal ordering — can only access the past, not the future — maintaining the validity of autoregressive generation
- Trade-offs and complementarity: there is no absolutely superior architecture — only inductive biases suited to the problem; the best solution is often a combination of multiple mechanisms
Code Practice: Implementing Attention in Python
"Let's use Python to practice attention mechanisms," said Mr. Pallas's Cat, "and compare its different way of thinking with LSTM."
Scaled Dot-Product Attention
import numpy as np
import matplotlib.pyplot as plt
def scaled_dot_product_attention(Q, K, V, mask=None):
"""Scaled dot-product attention
Args:
Q: query matrix (batch_size, seq_len_q, d_k)
K: key matrix (batch_size, seq_len_k, d_k)
V: value matrix (batch_size, seq_len_v, d_v)
mask: attention mask (optional)
Returns:
attention output, attention weights
"""
# Compute dot-product attention scores
d_k = K.shape[-1]
scores = np.matmul(Q, K.transpose(0, 2, 1)) # (batch_size, seq_len_q, seq_len_k)
# Scale
scores = scores / np.sqrt(d_k)
# Apply mask (if provided)
if mask is not None:
scores = scores + (mask * -1e9) # set masked positions to negative infinity
# Softmax normalization to obtain attention weights
attention_weights = softmax(scores, axis=-1) # (batch_size, seq_len_q, seq_len_k)
# Weighted sum of value vectors
output = np.matmul(attention_weights, V) # (batch_size, seq_len_q, d_v)
return output, attention_weights
def softmax(x, axis=-1):
"""Stable softmax implementation"""
x_exp = np.exp(x - np.max(x, axis=axis, keepdims=True))
return x_exp / np.sum(x_exp, axis=axis, keepdims=True)
def causal_mask(seq_len):
"""Create causal attention mask (lower triangular matrix)
Ensures position i can only attend to positions j (j <= i)
"""
mask = np.triu(np.ones((seq_len, seq_len)), k=1) # upper triangle (excluding diagonal) is 1
return mask # positions with 1 need to be masked
# Scaled dot-product attention demo
print("Scaled Dot-Product Attention Demo:")
print("=" * 60)
# Create test data
batch_size = 2
seq_len = 5
d_k = d_v = 8
# Randomly initialize Q, K, V
np.random.seed(42)
Q = np.random.randn(batch_size, seq_len, d_k)
K = np.random.randn(batch_size, seq_len, d_k)
V = np.random.randn(batch_size, seq_len, d_v)
print(f"Input shapes:")
print(f" Q (query): {Q.shape}")
print(f" K (key): {K.shape}")
print(f" V (value): {V.shape}")
# Attention without mask
output_no_mask, attn_weights_no_mask = scaled_dot_product_attention(Q, K, V)
print(f"\nUnmasked attention output shape: {output_no_mask.shape}")
print(f"Unmasked attention weights shape: {attn_weights_no_mask.shape}")
# Causal mask attention
causal_mask_matrix = causal_mask(seq_len)
print(f"\nCausal mask matrix (seq_len={seq_len}):")
print(causal_mask_matrix)
# Apply causal mask
output_causal, attn_weights_causal = scaled_dot_product_attention(
Q, K, V, mask=causal_mask_matrix
)
print(f"\nCausal attention output shape: {output_causal.shape}")
# Visualize attention weights
def visualize_attention_weights(attn_weights, title, sample_idx=0):
"""Visualize attention weight matrices"""
plt.figure(figsize=(12, 5))
# Subplot 1: Unmasked attention
plt.subplot(1, 2, 1)
im1 = plt.imshow(attn_weights_no_mask[sample_idx], cmap='viridis')
plt.colorbar(im1, label='Attention Weight')
plt.xlabel('Key Position (j)')
plt.ylabel('Query Position (i)')
plt.title(f'{title} — Unmasked')
# Add grid lines
plt.grid(True, which='both', color='white', linewidth=0.5, alpha=0.3)
# Subplot 2: Causal masked attention
plt.subplot(1, 2, 2)
im2 = plt.imshow(attn_weights_causal[sample_idx], cmap='viridis')
plt.colorbar(im2, label='Attention Weight')
plt.xlabel('Key Position (j)')
plt.ylabel('Query Position (i)')
plt.title(f'{title} — Causal Mask')
# Add grid lines
plt.grid(True, which='both', color='white', linewidth=0.5, alpha=0.3)
plt.tight_layout()
plt.savefig(f'/tmp/attention_weights_{title.lower().replace(" ", "_")}.png',
dpi=150, bbox_inches='tight')
plt.close()
print(f"Attention weight visualization saved to /tmp/attention_weights_{title.lower().replace(' ', '_')}.png")
# Run visualization
visualize_attention_weights(attn_weights_no_mask, "Attention Weights", sample_idx=0)
# Analyze the impact of causal constraints
print("\nCausal Attention Analysis:")
print("=" * 60)
# Check if causal constraint is enforced
sample_idx = 0
causal_violations = 0
for i in range(seq_len):
for j in range(seq_len):
if j > i and attn_weights_causal[sample_idx, i, j] > 1e-6:
causal_violations += 1
print(f"Causal constraint check:")
print(f" Sequence length: {seq_len}")
print(f" Attention matrix size: {seq_len}×{seq_len}")
print(f" Upper triangle positions (future positions): {seq_len*(seq_len-1)//2}")
print(f" Causal violations: {causal_violations}")
print(f" Causal constraint: {'PASS' if causal_violations == 0 else 'FAIL'}")
# Compare attention patterns at different positions
print(f"\nAttention distribution at different query positions (sample 0):")
for i in [0, 2, 4]: # examine positions 0, 2, 4
attention_to_past = attn_weights_causal[sample_idx, i, :i+1].sum() # can only see the past
attention_to_self = attn_weights_causal[sample_idx, i, i] # attention to itself
print(f" Position {i}: total attention=1.0, attention to past={attention_to_past:.3f}, self-attention={attention_to_self:.3f}")Multi-Head Attention
class MultiHeadAttention:
"""Multi-head attention mechanism"""
def __init__(self, d_model, num_heads):
"""Initialize multi-head attention
Args:
d_model: model dimension
num_heads: number of attention heads
"""
assert d_model % num_heads == 0, "d_model must be divisible by num_heads"
self.d_model = d_model
self.num_heads = num_heads
self.depth = d_model // num_heads
# Linear transformation layers
self.W_q = np.random.randn(d_model, d_model) * 0.01
self.W_k = np.random.randn(d_model, d_model) * 0.01
self.W_v = np.random.randn(d_model, d_model) * 0.01
self.W_o = np.random.randn(d_model, d_model) * 0.01
def split_heads(self, x, batch_size):
"""Split the last dimension into (num_heads, depth)"""
x = x.reshape(batch_size, -1, self.num_heads, self.depth)
return x.transpose(0, 2, 1, 3) # (batch_size, num_heads, seq_len, depth)
def combine_heads(self, x, batch_size):
"""Combine attention heads"""
x = x.transpose(0, 2, 1, 3) # (batch_size, seq_len, num_heads, depth)
return x.reshape(batch_size, -1, self.d_model)
def forward(self, q, k, v, mask=None):
"""Forward pass"""
batch_size = q.shape[0]
# Linear transformations
q = np.matmul(q, self.W_q) # (batch_size, seq_len, d_model)
k = np.matmul(k, self.W_k)
v = np.matmul(v, self.W_v)
# Split heads
q = self.split_heads(q, batch_size) # (batch_size, num_heads, seq_len_q, depth)
k = self.split_heads(k, batch_size) # (batch_size, num_heads, seq_len_k, depth)
v = self.split_heads(v, batch_size) # (batch_size, num_heads, seq_len_v, depth)
# Scaled dot-product attention (each head independently)
scaled_attention, attention_weights = scaled_dot_product_attention(q, k, v, mask)
# Combine heads
scaled_attention = self.combine_heads(scaled_attention, batch_size)
# Output linear transformation
output = np.matmul(scaled_attention, self.W_o) # (batch_size, seq_len, d_model)
return output, attention_weights
# Multi-head attention demo
print("\nMulti-Head Attention Demo:")
print("=" * 60)
# Create multi-head attention layer
d_model = 64
num_heads = 8
mha = MultiHeadAttention(d_model=d_model, num_heads=num_heads)
print(f"Multi-Head Attention Configuration:")
print(f" Model dimension (d_model): {d_model}")
print(f" Number of heads (num_heads): {num_heads}")
print(f" Dimension per head (depth): {d_model // num_heads}")
print(f" Total parameters: {4 * d_model * d_model}") # W_q, W_k, W_v, W_o
# Test data
batch_size = 3
seq_len = 10
test_q = np.random.randn(batch_size, seq_len, d_model)
test_k = np.random.randn(batch_size, seq_len, d_model)
test_v = np.random.randn(batch_size, seq_len, d_model)
print(f"\nTest data shapes:")
print(f" Q: {test_q.shape}")
print(f" K: {test_k.shape}")
print(f" V: {test_v.shape}")
# Forward pass (no mask)
output_mha, attn_weights_mha = mha.forward(test_q, test_k, test_v)
print(f"\nMulti-head attention output shape: {output_mha.shape}")
print(f"Attention weights shape: {attn_weights_mha.shape} # (batch_size, num_heads, seq_len, seq_len)")
# Visualize attention patterns across different heads
def visualize_multihead_attention(attn_weights, title, sample_idx=0):
"""Visualize different heads of multi-head attention"""
num_heads = attn_weights.shape[1]
seq_len = attn_weights.shape[2]
fig, axes = plt.subplots(2, 4, figsize=(16, 8))
axes = axes.flatten()
for h in range(min(num_heads, 8)): # display at most 8 heads
ax = axes[h]
im = ax.imshow(attn_weights[sample_idx, h], cmap='viridis', vmin=0, vmax=1)
ax.set_xlabel('Key Position')
ax.set_ylabel('Query Position')
ax.set_title(f'Head {h+1}')
ax.grid(True, which='both', color='white', linewidth=0.5, alpha=0.3)
# Remove extra subplots
for h in range(min(num_heads, 8), 8):
axes[h].axis('off')
plt.suptitle(f'{title} — Multi-Head Attention Patterns (Sample {sample_idx})', fontsize=14)
plt.tight_layout()
plt.savefig(f'/tmp/multihead_attention_{title.lower().replace(" ", "_")}.png',
dpi=150, bbox_inches='tight')
plt.close()
print(f"Multi-head attention visualization saved to /tmp/multihead_attention_{title.lower().replace(' ', '_')}.png")
# Run visualization
visualize_multihead_attention(attn_weights_mha, "Multi-Head Attention", sample_idx=0)
# Analyze attention diversity across heads
print("\nMulti-Head Attention Diversity Analysis:")
print("=" * 60)
sample_idx = 0
head_diversity = np.zeros((num_heads, num_heads))
# Compute similarity between heads
for i in range(num_heads):
for j in range(num_heads):
if i != j:
# Compute cosine similarity between two heads' attention weights
head_i = attn_weights_mha[sample_idx, i].flatten()
head_j = attn_weights_mha[sample_idx, j].flatten()
similarity = np.dot(head_i, head_j) / (np.linalg.norm(head_i) * np.linalg.norm(head_j))
head_diversity[i, j] = similarity
print(f"Average similarity between attention heads: {np.mean(head_diversity[np.triu_indices(num_heads, k=1)]):.4f}")
print(f"Minimum similarity between attention heads: {np.min(head_diversity[np.triu_indices(num_heads, k=1)]):.4f}")
print(f"Maximum similarity between attention heads: {np.max(head_diversity[np.triu_indices(num_heads, k=1)]):.4f}")
print(f"\nInterpretation:")
print(f" Similarity close to 1: heads attend to similar patterns")
print(f" Similarity close to 0: heads attend to different patterns")
print(f" Higher diversity (lower similarity) is usually better — different heads capture different features")LSTM vs Attention: A Comparison Experiment
def compare_lstm_vs_attention():
"""Compare LSTM vs Attention on a simple task"""
# Create a simple sequence copying task
def create_copy_task_data(num_samples, seq_len, vocab_size=10):
"""Create sequence copying task data"""
X = np.zeros((num_samples, seq_len, vocab_size))
y = np.zeros((num_samples, seq_len, vocab_size))
for i in range(num_samples):
# Generate random sequence
sequence = np.random.randint(0, vocab_size-1, seq_len//2)
# Input: separator + sequence
for t in range(seq_len//2):
X[i, t, sequence[t]] = 1 # sequence part
X[i, seq_len//2, vocab_size-1] = 1 # separator
# Output: blank + sequence (delayed copy)
for t in range(seq_len//2 + 1, seq_len):
y[i, t, sequence[t - seq_len//2 - 1]] = 1
return X, y
print("LSTM vs Attention Comparison Experiment (Sequence Copying Task):")
print("=" * 60)
# Generate data
seq_len = 20
vocab_size = 10
X_train, y_train = create_copy_task_data(1000, seq_len, vocab_size)
X_test, y_test = create_copy_task_data(200, seq_len, vocab_size)
print(f"Task description: Copy the first half of the sequence to the second half")
print(f"Sequence length: {seq_len} (first half {seq_len//2} + separator + second half {seq_len//2-1})")
print(f"Vocabulary size: {vocab_size}")
print(f"Training samples: {X_train.shape[0]}, Test samples: {X_test.shape[0]}")
# Simple LSTM model
class SimpleLSTMModel:
def __init__(self, input_size, hidden_size, output_size):
# Reuse LSTMCell from Chapter 12
self.lstm_cell = LSTMCell(input_size, hidden_size)
self.W_out = np.random.randn(hidden_size, output_size) * 0.01
self.b_out = np.zeros((1, output_size))
self.hidden_size = hidden_size
def forward(self, X):
"""Forward pass through entire sequence"""
batch_size, seq_len, input_size = X.shape
h = np.zeros((batch_size, self.hidden_size))
c = np.zeros((batch_size, self.hidden_size))
outputs = []
for t in range(seq_len):
h, c, _ = self.lstm_cell.forward(X[:, t, :], h, c)
output_t = np.matmul(h, self.W_out) + self.b_out
outputs.append(output_t)
return np.stack(outputs, axis=1) # (batch_size, seq_len, output_size)
# Simple attention model
class SimpleAttentionModel:
def __init__(self, input_size, d_model):
self.d_model = d_model
self.W_q = np.random.randn(input_size, d_model) * 0.01
self.W_k = np.random.randn(input_size, d_model) * 0.01
self.W_v = np.random.randn(input_size, d_model) * 0.01
self.W_out = np.random.randn(d_model, input_size) * 0.01
self.b_out = np.zeros((1, input_size))
def forward(self, X):
"""Forward pass (using causal attention)"""
batch_size, seq_len, input_size = X.shape
# Linear transformations to obtain Q, K, V
Q = np.matmul(X, self.W_q) # (batch_size, seq_len, d_model)
K = np.matmul(X, self.W_k)
V = np.matmul(X, self.W_v)
# Causal attention
causal_mask_matrix = causal_mask(seq_len)
output, _ = scaled_dot_product_attention(Q, K, V, mask=causal_mask_matrix)
# Output layer
output = np.matmul(output, self.W_out) + self.b_out
return output
# Training function (simplified, for demo purposes)
def train_model_simple(model, X, y, epochs=10, lr=0.01):
"""Simplified training function (demo purposes)"""
losses = []
for epoch in range(epochs):
# Forward pass
predictions = model.forward(X)
# Compute loss (cross-entropy)
exp_pred = np.exp(predictions - np.max(predictions, axis=-1, keepdims=True))
probs = exp_pred / np.sum(exp_pred, axis=-1, keepdims=True)
loss = -np.mean(y * np.log(probs + 1e-8))
losses.append(loss)
if epoch % 5 == 0:
# Compute accuracy
pred_labels = np.argmax(predictions, axis=-1)
true_labels = np.argmax(y, axis=-1)
accuracy = np.mean(pred_labels == true_labels)
print(f" Epoch {epoch}: loss={loss:.4f}, accuracy={accuracy:.2%}")
return losses, predictions
# Train and compare
hidden_size = 32
d_model = 32
print("\nTraining LSTM model:")
lstm_model = SimpleLSTMModel(input_size=vocab_size, hidden_size=hidden_size, output_size=vocab_size)
lstm_losses, lstm_preds = train_model_simple(lstm_model, X_train[:100], y_train[:100], epochs=20)
print("\nTraining Attention model:")
attention_model = SimpleAttentionModel(input_size=vocab_size, d_model=d_model)
attn_losses, attn_preds = train_model_simple(attention_model, X_train[:100], y_train[:100], epochs=20)
# Visualize comparison
plt.figure(figsize=(10, 6))
plt.plot(lstm_losses, 'b-', linewidth=2, label='LSTM')
plt.plot(attn_losses, 'r-', linewidth=2, label='Attention')
plt.xlabel('Training Epoch')
plt.ylabel('Cross-Entropy Loss')
plt.title('LSTM vs Attention Training Curves on Sequence Copying Task')
plt.legend()
plt.grid(True, alpha=0.3)
plt.savefig('/tmp/lstm_vs_attention_training.png', dpi=150, bbox_inches='tight')
plt.close()
print(f"\nTraining curves saved to /tmp/lstm_vs_attention_training.png")
# Analyze model behavior
print("\nModel Behavior Analysis:")
print("=" * 60)
# Test on a sample
test_sample_idx = 0
lstm_test_pred = lstm_model.forward(X_test[test_sample_idx:test_sample_idx+1])
attn_test_pred = attention_model.forward(X_test[test_sample_idx:test_sample_idx+1])
# Decode sequences
def decode_sequence(one_hot_seq):
"""Decode one-hot sequence to indices"""
return np.argmax(one_hot_seq, axis=-1)
input_seq = decode_sequence(X_test[test_sample_idx])
target_seq = decode_sequence(y_test[test_sample_idx])
lstm_pred_seq = decode_sequence(lstm_test_pred[0])
attn_pred_seq = decode_sequence(attn_test_pred[0])
print(f"Input sequence: {input_seq}")
print(f"Target sequence: {target_seq}")
print(f"LSTM prediction: {lstm_pred_seq}")
print(f"Attention prediction: {attn_pred_seq}")
# Compute accuracy
lstm_acc = np.mean(lstm_pred_seq == target_seq)
attn_acc = np.mean(attn_pred_seq == target_seq)
print(f"\nSingle sample accuracy:")
print(f" LSTM: {lstm_acc:.2%}")
print(f" Attention: {attn_acc:.2%}")
# Task analysis
print(f"\nTask difficulty analysis:")
print(f" - Sequence copying requires remembering the first half and reproducing it in the second half")
print(f" - Key challenge: long-range dependency (need to recall across the separator)")
print(f" - LSTM advantage: maintains memory through cell state")
print(f" - Attention advantage: directly accesses historical information")
print(f" - Expectation: attention may perform better on this task")
# Run comparison experiment
compare_lstm_vs_attention()Mr. Pallas's Cat summarized: "The contest between LSTM and attention is not about winning or losing — it is a philosophical dialogue. LSTM represents the wisdom of incremental memory — information slowly settles, filters, and updates through time. Attention represents the revolution of direct access — instantly extracting relevant information as needed. Most importantly, this contest teaches us: good architecture design arises from deep understanding of the problem's nature, not from blindly following technological trends. On this path, thinking matters more than code, and understanding more than implementation."
Mr. Pallas's Cat's Reflection Questions
Hands-On Exploration (for Piglet)
- Attention variants: implement different attention variants (local attention, sparse attention). Compare their computational efficiency and effectiveness with full attention.
- Hybrid architecture: design an LSTM + attention hybrid model. Let LSTM handle local patterns and attention capture long-range dependencies. How does it perform?
- Attention visualization: train an attention model on real text data and visualize the attention weights. Which words does the model attend to? Why?
Historical Investigation (for Little Seal)
- Origins of attention: research the origins of attention mechanisms in neuroscience and psychology. How did it transform from a cognitive concept into a computational tool?
- The Transformer revolution: investigate the historical background of the 2017 "Attention Is All You Need" paper. Why did this paper spark an AI revolution?
- Architecture evolution: draw a timeline of architecture evolution from simple RNNs to LSTMs to Transformers. What core problem did each breakthrough solve?
Integrated Reflection
- Philosophical reflection: what different epistemologies do LSTM's "gradual forgetting" and attention's "perfect memory" reflect? In human cognition, which mode are we closer to?
- Ethical challenge: attention mechanisms allow models to "focus" on different parts of the input. This brings interpretability advantages, but could also be used to manipulate attention. How can we ensure attention fairness?
- Creative exercise: design a "learnable forgetting" mechanism that lets the model dynamically adjust its forgetting rate. How would you design this mechanism?
- Limit challenge: prove that attention mechanisms can simulate any LSTM (theoretically). How many heads are needed? How many layers? What does this demonstrate?
Coming Up Next
The fragrance of tea filled the Black Stone House; the night was deep and still.
"Today we explored the contest between forgetting and causality," said Mr. Pallas's Cat. "We witnessed the collision of two philosophies of memory. But attention mechanisms go further — how do they teach models 'where to look'?"
Piglet asked curiously: "'Where to look'? Like... choosing a point of focus in a complex scene?"
"Yes," Mr. Pallas's Cat explained. "In the next chapter, we dive deeper into Attention: In This Noisy World, Where Should We Look? — understanding how attention becomes the 'eyes' of modern AI."
Little Seal flipped through his notebook. "This leads to the core question of perception and cognition. Historically, how did attention mechanisms evolve from computer vision to natural language processing?"
Mr. Pallas's Cat smiled: "We'll take it slow. See you in the next chapter."
Piglet's note: I implemented attention and compared it with LSTM. On the sequence copying task, attention indeed learned long-range dependencies faster! But I also noticed the attention weight matrix is large (sequence length squared), so there's a real computational cost for long sequences. Most interesting was multi-head attention — different heads indeed attend to different patterns: some local, some global.
Little Seal's note: I researched the history of attention mechanisms and was amazed by its multidisciplinary origins. In psychology, William James systematically studied attention as early as 1890. In computer vision, attention mechanisms were first used for image processing. The simplicity of the Transformer paper is striking — based entirely on attention, no RNNs/CNNs needed, yet more powerful. The power of simplicity.
Mr. Pallas's Cat's closing words: The contest between LSTM and attention teaches a profound lesson about intelligent design: there is no absolute optimum, only appropriate trade-offs. Incremental memory suits temporal flow; direct access suits structured relationships. Most importantly, it reminds us: technological progress is not about replacement, but about enriching our toolbox. On this path, diversity matters more than uniformity, understanding more than application. We'll take it slow — understanding is what matters most.