DSSM Tutorial
1. Model Overview and Use Cases
DSSM (Deep Structured Semantic Model), proposed by Microsoft at CIKM 2013, is the classic two-tower retrieval model. It maps users and items into the same embedding space with separate DNN towers and uses cosine similarity or dot product to compute matching scores. It is one of the most common base models in the retrieval stage of recommendation systems.
Paper: Learning Deep Structured Semantic Models for Web Search using Clickthrough Data
Model Architecture
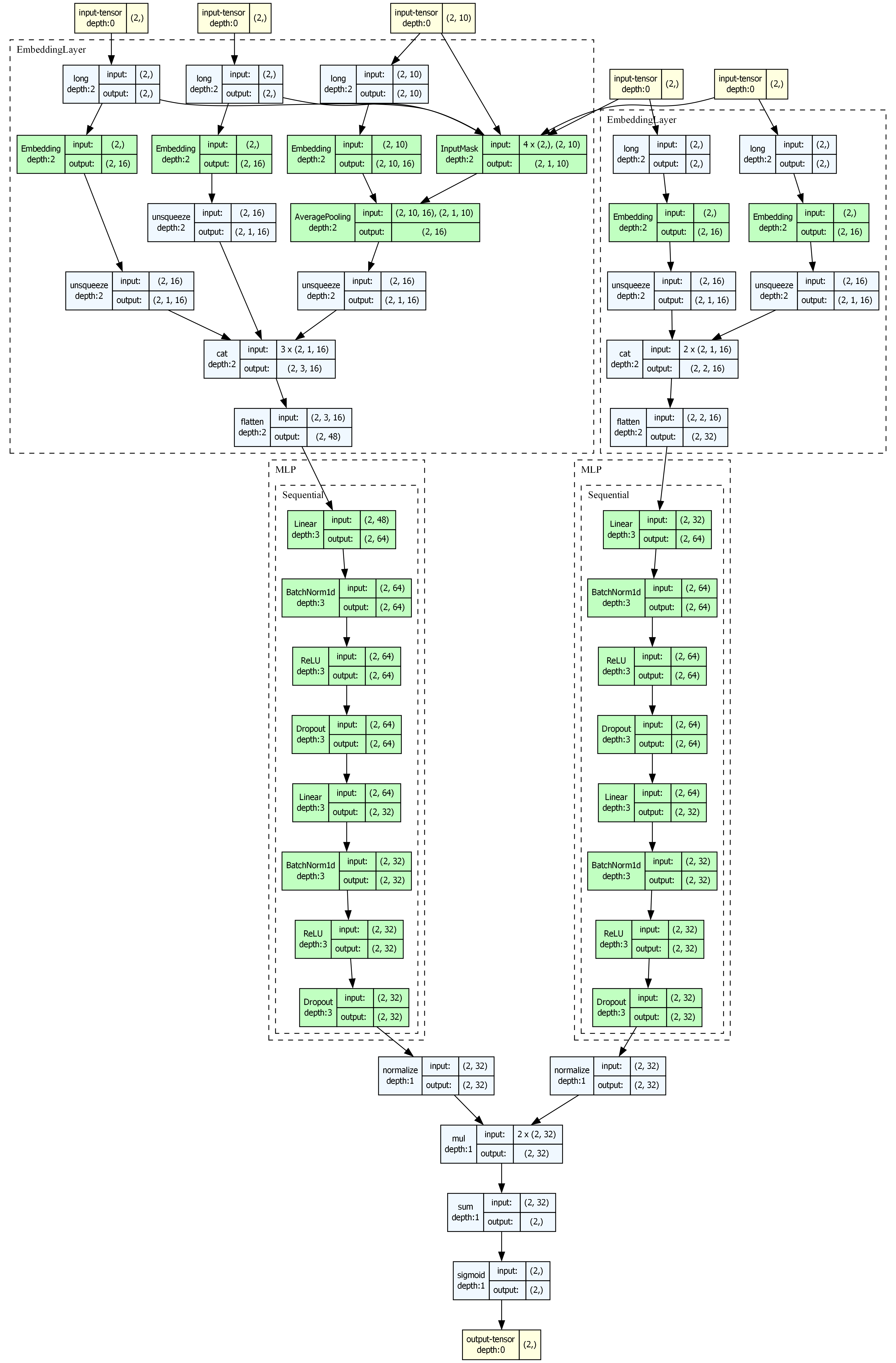
- User Tower: maps user features to a user embedding
- Item Tower: maps item features to an item embedding
- Similarity: computes user-item matching scores with cosine similarity or dot product
Suitable Scenarios
- Retrieval stage of recommendation systems
- Large candidate sets with vector search
- Search relevance matching
- Online systems that precompute item vectors offline
2. Data Preparation and Preprocessing
This example uses the sampled MovieLens-1M dataset.
2.1 Load and Process Data
import os
import pandas as pd
import torch
from sklearn.preprocessing import LabelEncoder
from torch_rechub.basic.features import SparseFeature, SequenceFeature
from torch_rechub.utils.data import MatchDataGenerator, df_to_dict
from torch_rechub.utils.match import gen_model_input, generate_seq_feature_match
# Load the sampled MovieLens data
data = pd.read_csv("examples/matching/data/ml-1m/ml-1m_sample.csv")
# Define discrete features
sparse_cols = ["user_id", "movie_id", "gender", "age", "occupation", "zip"]
for col in sparse_cols:
data[col] = LabelEncoder().fit_transform(data[col])2.2 Feature Encoding
# Split user / item profile tables
user_profile = data[["user_id", "gender", "age", "occupation", "zip"]].drop_duplicates("user_id")
item_profile = data[["movie_id"]].drop_duplicates("movie_id")2.3 Build Sequence Features and Training Data
# Generate sequence features and negative samples
train, test = generate_seq_feature_match(
data,
user_col="user_id",
item_col="movie_id",
time_col="timestamp",
item_attribute_cols=[],
sample_method=0,
mode=0,
)
# Build model inputs
train_user_input, train_item_input, y_train = gen_model_input(
train,
user_profile,
seq_max_len=50,
)
test_user_input, test_item_input, y_test = gen_model_input(
test,
user_profile,
seq_max_len=50,
)2.4 Define Features
# User features = user profile + historical behavior sequence
# DSSM does not model complex temporal relations directly. Instead, it
# compresses the history sequence into a fixed user representation first.
user_features = [
SparseFeature("user_id", vocab_size=data["user_id"].max() + 1, embed_dim=16),
SparseFeature("gender", vocab_size=data["gender"].max() + 1, embed_dim=8),
SparseFeature("age", vocab_size=data["age"].max() + 1, embed_dim=8),
SparseFeature("occupation", vocab_size=data["occupation"].max() + 1, embed_dim=8),
SparseFeature("zip", vocab_size=data["zip"].max() + 1, embed_dim=8),
SequenceFeature("hist_movie_id", vocab_size=data["movie_id"].max() + 1, embed_dim=16, pooling="mean"),
]
# Item features
item_features = [
SparseFeature("movie_id", vocab_size=data["movie_id"].max() + 1, embed_dim=16),
]
# Full item data used for retrieval evaluation
all_item = df_to_dict(item_profile)2.5 Create DataLoaders
dg = MatchDataGenerator(x=train_user_input, y=y_train)
train_dl, test_dl, item_dl = dg.generate_dataloader(
x_test=test_user_input,
y_test=y_test,
item_dataset=all_item,
batch_size=256,
num_workers=0, # set 0 in Windows / notebook environments
)3. Model Configuration and Parameter Notes
3.1 Create the Model
from torch_rechub.models.matching import DSSM
model = DSSM(
user_features=user_features,
item_features=item_features,
user_params={"dims": [256, 128, 64], "activation": "prelu"},
item_params={"dims": [256, 128, 64], "activation": "prelu"},
temperature=0.02,
)3.2 Parameter Details
user_params/item_params: tower structure for the user and item encoderstemperature: scales the similarity logits during training- The last hidden dimensions of the two towers should match
4. Training Process and Code Example
4.1 Train the Model
from torch_rechub.trainers import MatchTrainer
os.makedirs("./saved/dssm", exist_ok=True)
trainer = MatchTrainer(
model,
mode=0,
optimizer_params={"lr": 1e-4, "weight_decay": 1e-6},
n_epoch=5,
device="cpu",
model_path="./saved/dssm",
)
trainer.fit(train_dl)4.2 Training Mode Notes
mode=0: point-wise / pair-wise style training suitable for DSSM- User and item embeddings are learned in a shared space for later ANN retrieval
5. Evaluation and Result Analysis
5.1 Generate Embeddings and Evaluate
# Generate user embeddings
user_embedding = trainer.inference_embedding(model=trainer.model, mode="user", data_loader=test_dl)
# Generate item embeddings
item_embedding = trainer.inference_embedding(model=trainer.model, mode="item", data_loader=item_dl)5.2 Recall@K Evaluation
You can reuse the helper functions in examples/matching/movielens_utils.py to compute Recall@K, HitRate@K, and related retrieval metrics.
6. Tuning Suggestions
6.1 Key Tuning Points
- Tune the final embedding dimension first
- Keep user / item tower depths balanced
- Use a slightly smaller learning rate when the towers become deeper
6.2 Vector Retrieval and Deployment
Option 1: Annoy (lightweight, good for prototyping)
from torch_rechub.utils.ann import AnnoyIndexer
# Build an Annoy index
annoy = AnnoyIndexer(dim=item_embedding.shape[-1], metric="angular")
annoy.build(item_embedding)
# Query Top-10 items for a single user vector
topk = annoy.search(user_embedding[0], topk=10)Option 2: Faiss (high performance, GPU support)
import faiss
import numpy as np
# Make sure embeddings are float32 numpy arrays
item_embedding = np.asarray(item_embedding, dtype="float32")
user_embedding = np.asarray(user_embedding, dtype="float32")
# Build a Faiss index
index = faiss.IndexFlatIP(item_embedding.shape[-1])
index.add(item_embedding)
# Query Top-10
scores, indices = index.search(user_embedding[:1], 10)Option 3: Milvus (distributed, production-oriented)
Use Milvus when you need persistent, scalable vector retrieval in a production system.
Using the New Serving API (Builder / Indexer)
You can also use the factory-style serving utilities in Torch-RecHub to create an index builder for "annoy", "faiss", or "milvus" and keep the retrieval code path consistent across backends.
7. Model Visualization
Install Dependencies
- Python package:
pip install torchview graphviz - System graphviz:
- Ubuntu:
sudo apt-get install graphviz - macOS:
brew install graphviz - Windows:
choco install graphviz
- Ubuntu:
Visualize the DSSM Model
from torch_rechub.utils.visualize import visualize_model
# Automatically generate inputs and render inline in Jupyter
visualize_model(model, save_dir="./visualization", model_name="dssm")DSSM Architecture
The static two-tower structure is especially suitable for architecture visualization and deployment-oriented communication.
8. ONNX Export
Export the Full Model
trainer.export_onnx("./saved/dssm/dssm.onnx", data_loader=test_dl, dynamic_batch=True)Export User Tower and Item Tower Separately
User tower export is useful for online real-time inference; item tower export is useful for offline batch embedding generation.
Run Inference with ONNX Runtime
import onnxruntime as ort
# Load the exported model
session = ort.InferenceSession("./saved/dssm/dssm.onnx", providers=["CPUExecutionProvider"])
print(session.get_inputs())9. FAQ and Troubleshooting
Q1: Must the last hidden dimensions of the user tower and item tower be the same?
Yes. Both towers must output embeddings in the same vector space.
Q2: How do I include user behavior sequences?
Add a SequenceFeature to user_features, usually with pooling="mean" or another sequence aggregation strategy.
Q3: How should DSSM be deployed online?
The standard pattern is offline item embedding generation + ANN index construction + online user embedding inference + vector retrieval.
Q4: What happens if temperature is too small?
Training can become unstable and the logits can be overly sharp.
Q5: How should I choose between Annoy, Faiss, and Milvus?
Use Annoy for lightweight local prototypes, Faiss for high-performance single-node retrieval, and Milvus for scalable production indexing.
Full Example
The code blocks above form a complete runnable example. For a full MovieLens-based training script, see examples/matching/run_ml_dssm.py.