D2:AI 应用的数据层
Easy Data x AI 课程 · 术篇 · 第二期
上一期你学会了 Tool Use——大模型和外部数据之间的桥梁。这一期,我们来回答桥对面的问题:那个“外部数据”,到底应该用什么样的数据库来承载?
本期课程涉及的代码,均在 https://github.com/datawhalechina/easy-data-x-ai 项目的 code 目录中(欢迎大家 star 和参与课程共建)。
承接 P2,通往 D3
P2 把 RAG 拆成数据准备、查询分析、检索、融合重排、上下文生成、评估反馈六个阶段。D2 先把数据准备和多路检索打牢;下一篇 D3 再补齐动态路由、引用校验、失败重试和 60 条离线评测。
# ============================================================
# 示例代码简介:从 d2_1 到 d2_5 的演进
#
# d2_1 数据写入 → 文档切分、向量化并写入 seekdb
# d2_2 向量搜索 → 纯向量搜索示例
# d2_3 混合搜索 → 向量 + 全文 + 结构化过滤
# d2_4 对比实验 → 纯向量 vs 混合搜索结果对比
# d2_5 分块对比 → 语义分块 / 动态 overlap / 父子 chunk 策略实验
# ============================================================复制
.env.example为.env,并在.env文件中填写你的真实 API Key,即可直接执行对应章节的示例代码。推荐大家可以通过在硅基流动上注册账号,获取 API 密钥,使用免费 Embedding 模型
BAAI/bge-m3来体验向量化和检索。
cd easy-data-x-ai/code
# 安装依赖
pip install --upgrade -r requirements.txt
# 复制 .env.example 为 .env
cp .env.example .env
# 在 .env 文件中填写你的真实 API Key
vim .env
# 运行示例代码
python D2/d2_1_ingest.py开场:桥的另一端是什么?
D1 讲了一件关键的事:Tool Use 让大模型从“只能说”变成了“能做事”。通过 Tool Use,Agent 可以调用外部工具、查询数据库、获取实时信息。你已经跑通了一个最小示例——定义一个查询知识库的 tool,让模型调用它,处理返回结果。
很好。但这里有一个被很多开发者忽略的问题:
桥搭好了,桥对面应该放什么?
你的 Agent 要查知识库——用什么数据库存?用什么方式查?你可能第一反应是“用个向量数据库不就行了”。毕竟现在满世界都在讲 Embedding、向量搜索、语义检索。
但如果你真的上手做过一个 AI 应用,你大概率会撞上一个让你困惑的问题:向量搜索好像很聪明,但有些时候又蠢得离谱。
今天这节课,我们来搞清楚这个问题。
第零部分:数据进库之前——切分与向量化
在讨论"用什么数据库"之前,有一个更基础的问题:原始文档怎么变成可以被检索的数据?
这个过程分两步:切分(Chunking) 和 向量化(Embedding)。
切分:把长文档变成可检索的片段
一篇技术文档可能有几千字。如果把整篇文档作为一个检索单元,有两个问题:
- 向量化一整篇文档,语义会被"稀释"——一个向量很难同时代表文档里所有话题
- 检索命中后,把几千字全塞给模型,浪费 Token,也干扰模型的注意力
正确的做法是把文档切成若干语义完整的小片段,每个片段单独向量化、单独存储。
# 简单的按字符数切分示例(带重叠)
def chunk_document(text: str, chunk_size: int = 500, overlap: int = 50) -> list[str]:
"""
将长文档切分为带重叠的小片段
overlap(重叠)确保片段边界处的语义不丢失
"""
chunks = []
start = 0
while start < len(text):
end = start + chunk_size
chunks.append(text[start:end])
start += chunk_size - overlap # 每次前进 chunk_size - overlap
return chunks切分策略没有银弹,但有几条实用原则:
| 原则 | 说明 |
|---|---|
| 按语义边界切 | 优先在段落、标题处切,不要在句子中间断开 |
| 片段不要太长 | 500~800 字是常见范围,太长语义稀释,太短上下文不足 |
| 保留重叠 | 相邻片段保留 50~100 字的重叠,避免关键信息落在边界 |
| 保留元数据 | 每个片段记录来源文档、章节、更新时间等,用于后续结构化过滤 |
上面这套固定大小 + 固定 overlap 的分块方式,足够帮你跑通第一个 RAG 原型。但当你把知识库从几十条 FAQ 扩展到几百页技术手册,很快就会碰到一类新问题:检索召回对了,上下文却断了——或者反过来,上下文完整,检索却找不到精确片段。
下面三种进阶策略,就是针对这类边界场景设计的。它们不替代基础分块,而是在你确认基础方案遇到瓶颈之后的升级选项。
进阶 Chunking 策略
策略一:语义分块(Semantic Chunking)
固定大小分块有一个先天缺陷:它按字符数切,不管语义边界在哪。比如一段关于「错误码 E-4012」的说明,可能被切成两半:前半段进了 chunk A,后半段进了 chunk B。用户问「E-4012 怎么解决」,检索可能只命中半句话。
语义分块的思路是:先按句子切开,给每个句子算 Embedding,再比较相邻句子的余弦相似度。当相似度出现「异常下跌」,说明话题发生了跳变,则可以在那插入断点,把前后句子分到不同 chunk。
# 语义分块的核心逻辑(简化示意)
sentences = split_sentences(long_document)
embeddings = embed_batch(sentences) # 每句一个向量
# 计算相邻句相似度,在跌幅超过阈值处切分
similarities = [cosine(embeddings[i], embeddings[i+1]) for i in range(len(sentences)-1)]
breakpoints = find_breakpoints(similarities, percentile=95) # 第 95 分位视为话题跳变
chunks = group_sentences(sentences, breakpoints)那「异常下跌」到底多大算异常?如果写死一个固定数值(比如相似度跌幅超过 0.3 就切),不同类型文档的表现会差很多——技术手册整体跌幅偏小,可能几乎不切;散文整体跌幅偏大,又可能切得太碎。更稳妥的做法是用 percentile 阈值:先把这篇文档里所有相邻句的相似度跌幅排个序,取第 95 分位作为切分线——只有跌幅排进全文最靠前的 5%,才判定为话题跳变。这样阈值跟着当前文档自己的分布走,而不是硬套一个全局常数。
LangChain 的 SemanticChunker(位于 langchain-experimental 包)目前默认就是这套 percentile 方案,分位值 95,与上面代码示意一致。实际调参时常在 90–95 之间微调:切得太碎就调高,话题粘连就调低。这与 NAACL 2025 论文 Is Semantic Chunking Worth the Computational Cost? 中 breakpoint-based 语义分块器的思路一致。
但代价也实实在在:入库时需要对每个句子调用一次 Embedding API。一篇 500 页的文档可能产生数万次 API 调用,计算成本远高于固定分块。2025–2026 年的多项 benchmark(如 Yoke Agent 的分块评测)显示:
- 对 Markdown / 技术文档 这类结构清晰的内容,带 overlap 的递归分块往往就能拿到很好的效果,语义分块提升有限
- 对 话题频繁切换的散文、新闻、会议纪要,语义分块通常能带来 2–5 个点的 Recall 提升
- 阈值没调好会导致过度碎片化(平均 chunk 只有几十个 token),检索精度反而下降
所以语义分块适用于结构不清晰、话题跳跃的长文,作为「基础分块效果不够好」时的优化手段。
策略二:动态 Overlap(Dynamic Overlap)
固定 overlap 有一个隐含假设:文档每个位置的「边界风险」是一样的。实际上并非如此——章节标题、段落换行、表格前后的语义密度完全不同。在标题处切一刀,丢上下文的概率远高于段落中间。
动态 overlap 的做法是:保持 chunk 大小基本不变,但根据内容特征动态调整重叠量:
| 区域类型 | overlap 策略 | 原因 |
|---|---|---|
| 同质段落内部 | 较小 overlap(如 10%) | 减少冗余,降低存储和检索噪声 |
| 段落边界、标题行附近 | 较大 overlap(如 25–30%) | 保护跨边界的完整语义 |
| 代码块、表格前后 | 适当加大 overlap | 避免结构信息被切断 |
# 动态 overlap 示意:边界附近加大重叠
boundaries = detect_boundaries(text) # 段落空行、Markdown 标题等
while start < len(text):
end = start + chunk_size
overlap = max_overlap if near_boundary(end, boundaries) else base_overlap
start += chunk_size - overlapWeaviate(开源向量数据库厂商)2024 年发布的技术博客 Chunking Strategies to Improve LLM RAG Pipeline Performance 将这类方法归为 Adaptive Chunking,即不换分块算法,只让 overlap 和步长随内容结构自适应。Yoke Agent 团队在 2026 年初做的分块策略对比实验(Benchmarking chunking strategies on a real corpus )显示,在 512 token 分块上仅增加 64 token 的 overlap,Recall 就能提升约 4 个百分点,与换用更大 Embedding 模型的收益同量级,但入库成本几乎为零。这个实验证明了动态 overlap 的高性价比。
动态 overlap 的适用的是已经有固定大小分块、不想引入 Embedding 额外开销,但边界召回率不理想的场景。这是三种策略里性价比最高的升级路径。
策略三:父子 Chunk(Parent-Child / Small-to-Big)
前两种策略解决的是「怎么切」。父子 chunk 解决的是另一个矛盾:
- 小块检索精准,但塞给 LLM 时上下文不够——半句话说不清来龙去脉
- 大块上下文完整,但向量语义被「稀释」,检索时找不到精确片段
父子 chunk 的核心思路是把索引粒度和返回粒度解耦:
原始文档
└── 父 chunk(500 字,存入 docstore,不建向量索引)
├── 子 chunk A(120 字,建向量索引)
├── 子 chunk B(120 字,建向量索引)
└── 子 chunk C(120 字,建向量索引)
查询时:用子 chunk 做向量检索 → 命中后取 parent_id → 返回父 chunk 给 LLM业界把这套做法叫做 small-to-big retrieval(检索用小块、生成用大块)或 parent-document retrieval(按父文档返回上下文)。名字不同,核心都是把“搜到什么”和“给 LLM 什么”分开。LangChain 的 ParentDocumentRetriever、LlamaIndex 的 HierarchicalNodeParser + AutoMergingRetriever 走的都是这条路:向量库只索引子块,父块存在独立的 docstore 里按 ID 关联,检索命中子块后再取回父块。LlamaIndex 还支持多层级合并,子块命中比例够高时才升级为更大的父块,比 LangChain 的两层方案更灵活一些。
# 父子分块的数据关系
parents = parent_child_chunk(
long_document,
parent_size=500, # 给 LLM 的上下文单位
child_size=120, # 向量检索单位
)
# 入库时只索引子块,但元数据里带上 parent_id 和 parent_text
for parent in parents:
for child in parent.children:
vector_db.add(
text=child.text,
metadata={"parent_id": parent.parent_id, "parent_text": parent.text}
)
# 检索时:命中子块 → 返回父块文本
results = vector_db.query(query)
context_for_llm = [r.metadata["parent_text"] for r in results]在需要多跳推理或跨段落理解的场景(如「比较 E-4011 和 E-4012 的处理差异」),父子 chunk 的优势尤其明显:子块帮你定位到精确段落,父块给 LLM 足够的上下文做综合回答。社区 benchmark 普遍报告 15–30% 的答案完整度提升,代价是 LLM 侧 token 消耗随父块大小同比增加。
当文档有清晰章节结构、查询需要完整上下文才能回答、且你愿意用更多 LLM token 换更好答案的生产系统的时候,可以使用考虑使用父子分块。
三种策略怎么选?
不要试图找一个永远最优的策略,chunk 大小、overlap、分块算法都没有标准答案,得根据你自己的文档和查询试出来。下面是一张实用的决策表,可供参考:
| 你的情况 | 推荐策略 | 理由 |
|---|---|---|
| 刚起步 / 文档量小 | 固定 overlap(d2_1 默认方案) | 简单、零额外成本、足够跑通 |
| Markdown / API 文档 / 结构清晰 | 固定 overlap + 按标题预切 | 结构信号比语义 Embedding 更可靠 |
| 边界处经常丢上下文 | 动态 overlap | 成本最低的有效升级 |
| 话题跳跃的无结构长文 | 语义分块 | 按语义边界切,避免硬切 |
| 检索准但 LLM 答不全 | 父子 chunk | 小块检索 + 大块生成 |
| 多种文档类型混合 | 按文档类型路由不同策略 | 异构语料没有 one-size-fits-all |
最新的研究趋势也在朝「自适应」方向走——2026 年的 Query-Adaptive Semantic Chunking(QASC)尝试把用户查询意图融入分块阶段,在特定场景下比固定语义分块再高 8–12 个百分点。但对大多数团队来说,先用 d2_5 跑一轮对比实验,比追新论文更有价值。
动手对比:d2_5 实验
课程代码 d2_5_chunking_compare.py 用一份多章节的数据库运维手册,对四种策略(固定 overlap 基线 + 上述三种高级策略)跑同一组查询,统计 Recall@3:
cd easy-data-x-ai/code
python D2/d2_5_chunking_compare.py你会看到类似下面的输出(具体数字因检索后端、Embedding 模型和阈值设置会有波动):
策略 块数 均长 Recall@3
--------------------------------------------
固定 overlap 5 186字 80%
动态 overlap 6 185字 80%
父子 chunk 9 104字 80%
语义分块 7 310字 80% # 需 API Key数字因 Embedding 模型和阈值设置会有波动,但实验想说明的趋势是稳定的:
- 固定 overlap 在章节边界处容易丢召回:执行计划分析这类跨段信息被切散后,Top-3 里凑不齐完整答案
- 动态 overlap 用极低成本改善了边界召回:只在标题和段落边界加大重叠,不需要额外 API 调用
- 语义分块让每个 chunk 更完整:每个块围绕单一话题,均长更大、块数更少,适合话题切换频繁的手册
- 父子 chunk 用子块精准定位、父块补全上下文:Recall 未必最高,但返回给 LLM 的上下文最完整,适合后续生成环节
语义分块需要配置 SILICONFLOW_API_KEY(与课程 Embedding 示例一致)。没有 API Key 时脚本会跳过语义分块,其余三种策略仍可正常运行。
另外请分清两个阶段:seekdb 嵌入式模式不可用时,脚本只会把检索后端降级为内存词项匹配,不影响语义分块阶段调用硅基流动 Embedding API。也就是说,配置了 API Key 后,即便本地没有可用的 seekdb,语义分块对比仍会执行。
实践建议:chunk 策略、chunk 大小、overlap 和 Embedding 模型一样,都值得你在自己的数据上对比试出来。拿 20–50 条真实 query 跑一轮 Recall@K,比看任何排行榜都靠谱。这一点和接下来将讨论的 Embedding 选型的思路完全一致。
向量化:把文字变成数字
切分完成后,每个片段需要通过 Embedding 模型转换为向量——一串浮点数,代表这段文字的语义位置。
import os
from openai import OpenAI
# 使用硅基流动的 Embedding API(兼容 OpenAI 格式)
client = OpenAI(
api_key=os.environ["SILICONFLOW_API_KEY"],
base_url="https://api.siliconflow.cn/v1"
)
def embed(text: str) -> list[float]:
"""将一段文字转换为向量"""
response = client.embeddings.create(
model="BAAI/bge-m3", # 硅基流动提供的免费 Embedding 模型
input=text
)
return response.data[0].embedding
# 示例
vector = embed("错误码 E-4012 表示数据库连接超时")
print(f"向量维度:{len(vector)}") # 输出:向量维度:1024Embedding 模型不需要你自己训练,直接调用 API 即可。上面这段代码能跑通,说明向量化这一步没有技术门槛。但真正上线一个 RAG 系统时,很多人会卡在一个更实际的问题上:
模型那么多,到底选哪个?
OpenAI 的 text-embedding-3、智源的 bge-m3、阿里的 Qwen3-Embedding、通义的 text-embedding-v3、Google 的 Gemini Embedding……名字一长串,MTEB 排行榜上今天第一明天又换。本课程示例默认使用 BAAI/bge-m3,它在硅基流动上免费可用,中英文效果均衡,还支持 8192 token 的长文本输入,适合学习阶段零成本跑通全流程。
但这只是教学用的默认答案,并非所有场景的最优解。下面这套选型框架,帮你在进入生产环境时做出自己的判断。
Embedding 模型选型指南
先搞懂两个评测概念
在对比模型之前,先明确两个你会反复遇到的术语。
MTEB 排行榜(Massive Text Embedding Benchmark)是目前最权威的 Embedding 模型公开评测。它把模型放到检索、分类、聚类、语义相似度等上百个标准任务上跑分,然后给出综合排名。做 RAG 检索时,重点看 Retrieval 子任务的得分,不要只看总分。MTEB 也有局限:它主要测纯文本、短文本,不覆盖多模态检索、跨语言检索、维度压缩(MRL)和长文档大海捞针等生产场景,所以排行榜适合缩小候选范围,不能替代你自己的实测。
Recall@K 对比是更贴近业务的验证方式。做法是:准备 20–50 条真实业务查询,标注每条查询应该命中的文档(Ground Truth),分别用不同 Embedding 模型做检索,看正确答案出现在前 K 条结果里的比例。例如 50 条查询里有 42 条的正确答案出现在 Top-3 里,就是 Recall@3 = 84%。通常同时看 Recall@1(最严格,看第一条是否命中)和 Recall@5(更宽松),以及 MRR(第一个正确结果排在第几位,排得越靠前越好)。MTEB 反映的是通用能力,Recall@K 反映的是业务数据上的实际效果。
四个核心维度
确定评测方法后,按以下四个维度缩小候选范围:中英文能力、多模态支持、成本、延迟。
维度一:中英文能力
Embedding 模型的语言偏好,直接决定你的知识库能不能被正确理解。
| 模型 | 类型 | 中文 | 英文 | 多语言 | 最大输入 | 适合场景 |
|---|---|---|---|---|---|---|
BAAI/bge-m3 | 开源 API | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | 100+ 语言 | 8192 tokens | 中英文混合知识库,课程默认推荐 |
BAAI/bge-large-zh-v1.5 | 开源 API | ⭐⭐⭐⭐⭐ | ⭐⭐ | 中文为主 | 512 tokens | 纯中文短文本,轻量快速 |
netease-youdao/bce-embedding-base_v1 | 开源 API | ⭐⭐⭐⭐ | ⭐⭐⭐ | 中英双语 | 512 tokens | 中英双语 FAQ、客服知识库 |
Qwen/Qwen3-Embedding-8B | 开源 API | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | 100+ 语言 | 32768 tokens | 追求最高检索质量、长文档场景 |
通义 text-embedding-v3/v4 | 商业 API | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | 多语言 | 8192 tokens | 国内 API、中文优化、数据合规 |
jina-embeddings-v3/v4 | 商业 API | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | 多语言 | 8192 tokens | 多语言检索、多模态(v4 支持图文 PDF) |
text-embedding-3-small | 商业 API | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | 多语言 | 8191 tokens | 海外部署、英文为主、快速接入 |
text-embedding-3-large | 商业 API | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | 多语言 | 8191 tokens | 英文高质量检索,成本更高 |
Gemini Embedding 2 | 商业 API | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | 100+ 语言 | 32K+ tokens | 跨语言最强、长文档、五种模态 |
几个值得注意的判断:
- 中文为主:
bge-m3、bge-large-zh-v1.5、通义 embedding 系列在中文检索上普遍优于 OpenAI 的text-embedding-3系列。实测中,中文企业文档场景下bge-m3和通义 v3 的 Hit@5 普遍在 90% 以上,而text-embedding-3-small约 85%。 - 英文为主或出海业务:
text-embedding-3-large、Gemini Embedding、Voyage 系列在英文基准上更成熟。国内团队如果数据可以出境、追求零运维,这是省心的选择。 - 中英混合或多语言:
bge-m3是目前开源阵营里多语言能力最均衡的之一,支持 100+ 语言,且单一模型覆盖所有语种,不需要按语言维护多套索引。跨语言检索(中文 query 查英文文档)场景下,Gemini Embedding 表现最好;Qwen3-Embedding系列在 MTEB 多语言榜单上分数也很高。 - 长文档片段:如果你的 chunk 经常超过 500 字(比如整段技术方案、长篇 FAQ),优先选支持 8192 token 以上的模型(
bge-m3、Qwen3-Embedding系列)。bge-large-zh-v1.5虽然中文效果好,但最大输入只有 512 tokens,长文本会被截断,语义丢失严重。轻量模型(137M 参数的nomic-embed-text)在 4000 字以上的文档中准确率会明显下滑。
维度二:多模态支持
到目前为止,我们讨论的都是纯文本 Embedding,输入是文字,输出是向量。但真实业务里,知识库不只有文字:
- 产品手册里的架构图、流程图
- 财报 PDF 中的表格和图表
- 扫描件、截图里的文字和排版信息
这些内容的语义,纯文本 Embedding 是抓不住的。你需要多模态 Embedding,能同时理解文字和图像。
目前主流有三条技术路线:
| 路线 | 代表模型 | 原理 | 优势 | 劣势 |
|---|---|---|---|---|
| 图片描述 + 文本索引 | CLIP 系列 | 图片先转文字描述,再走文本 Embedding | 实现简单,生态成熟 | 图表、表格、排版信息大量丢失 |
| 统一多模态向量 | Cohere Embed v4、Qwen3-VL-Embedding、Gemini Embedding 2 | 图文输入同一模型,输出单一向量 | 工程简单,支持图文混合查询 | 对复杂版式文档的细粒度匹配有限 |
| 页面级多向量检索 | ColPali、ColNomic、ColQwen 系列 | 把 PDF 页面当图片,输出 token 级多向量 | 表格/图表/排版召回率最高 | 存储和检索成本高,工程复杂度高 |
怎么选?
- 知识库几乎全是纯文本(API 文档、Wiki、Markdown):不需要多模态,
bge-m3足够。 - 偶尔有几张配图,配图信息不重要:可以先用纯文本方案,图片用 OCR 或 VLM 生成描述后入库。
- 大量 PDF、扫描件、图表密集型文档(财报、论文、产品规格书):考虑 ColPali 风格的页面级检索,或 Cohere Embed v4 /
Qwen3-VL-Embedding统一向量方案。 - 想快速体验图文混合检索:硅基流动已支持
Qwen/Qwen3-VL-Embedding-8B,输入可以是文本、图片 URL 或图文混合列表,和本课程的 OpenAI 兼容调用方式一致。
# 多模态 Embedding 示例:文本 + 图片混合输入
response = client.embeddings.create(
model="Qwen/Qwen3-VL-Embedding-8B",
input=[
"这张架构图展示了系统的三层设计",
{"image": "https://example.com/architecture.png"}
]
)多模态选型还有一个技术指标值得留意:模态间隙(Modality Gap),衡量文本向量和图片向量在同一个向量空间里是否足够接近。间隙越小,图文混合检索越准确。实测中,Qwen3-VL-Embedding-2B 的模态间隙远低于 Gemini,在跨模态检索上甚至能超过部分闭源 API。
需要提醒的是:多模态 Embedding 不能替代混合搜索。即便用了多模态模型,精确匹配(版本号、错误码、函数名)仍然需要全文搜索兜底,这一点和 D2 后面讲的混合检索逻辑完全一致。
维度三:成本
Embedding 的成本很容易被低估。建知识库时,你要把所有文档的所有 chunk 都向量化一遍;每次用户查询,还要再给 query 算一次向量。调用量往往远超 LLM 对话。
| 模型 | 计费方式 | 参考价格 | 月 1000 万 token 估算 |
|---|---|---|---|
BAAI/bge-m3(硅基流动) | API 免费 | ¥0 | ¥0 |
BAAI/bge-large-zh-v1.5(硅基流动) | API 免费 | ¥0 | ¥0 |
Qwen/Qwen3-Embedding-8B(硅基流动) | 按量付费 | 以平台公示为准 | 需查最新定价 |
通义 text-embedding-v3 | 按 token | ≈ ¥0.7 / 百万 token | ≈ ¥7 |
text-embedding-3-small(OpenAI) | 按 token | ≈ ¥0.14 / 百万 token | ≈ ¥1.4 |
text-embedding-3-large(OpenAI) | 按 token | ≈ ¥0.88 / 百万 token | ≈ ¥8.8 |
自部署 bge-m3 | 服务器固定成本 | GPU 实例月租 | ≈ ¥500–2000 / 月(视规模) |
成本决策的关键不在单价,而在调用量级、向量维度和部署方式:
- 学习 / 原型阶段:硅基流动免费 API +
bge-m3,零成本跑通全流程,这也是本课程的选择。 - 月调用量 < 500 万 token:继续用免费或低价 API 最划算,不值得为省几块钱自建 GPU。
- 月调用量 > 5000 万 token,或数据不能出内网:评估自部署。开源模型(
bge-m3、Qwen3-Embedding)自托管后,边际调用成本趋近于零,但你需要承担 GPU 运维。 - 向量维度直接影响存储成本:这不是选模型时最显眼的一个参数,却是对账单影响最大的之一。
| 维度 | 单向量大小 | 100 万条数据存储 | 典型模型 | 适合场景 |
|---|---|---|---|---|
| 384 维 | ≈ 1.5 KB | ≈ 1.5 GB | all-MiniLM-L6-v2 | 数据量小、边缘部署、FAQ |
| 768 维 | ≈ 3 KB | ≈ 3 GB | bge-base-zh-v1.5 | 10 万–100 万条,工程均衡 |
| 1024 维 | ≈ 4 KB | ≈ 4 GB | bge-m3、通义 v3 | 高精度中文 RAG,课程默认 |
| 3072 维 | ≈ 12 KB | ≈ 12 GB | text-embedding-3-large | 英文高精度,存储成本高 |
维度选择的本质是取舍:精度、存储、检索速度三者不可兼得。盲目追 3072 维,MTEB 检索分数可能只比 1024 维高 2–3 个点,但存储和检索成本翻倍。部分模型支持 MRL 降维(Matryoshka Representation Learning),如 Qwen3 系列可降到 256 维,通义和 OpenAI 也支持 dimensions 参数裁剪,在精度损失可控的前提下降低存储开销。注意:MRL 效果因模型训练策略而异,降维前最好在自己的数据上验证。
维度四:延迟
延迟分两个场景:入库(批量向量化) 和 查询(在线 Embedding)。
| 模型 | 参数量 | 单条延迟(API) | 单条延迟(自部署 GPU) | 吞吐量特点 |
|---|---|---|---|---|
bge-large-zh-v1.5 | 326M | 30–80 ms | 10–30 ms | 轻量,适合高频在线查询 |
bce-embedding-base_v1 | 279M | 30–80 ms | 10–30 ms | 与 bge-large-zh 同级 |
bge-m3 | 568M | 50–150 ms | 20–50 ms | 中等,质量与速度均衡 |
Qwen3-Embedding-0.6B | 600M | 50–150 ms | 15–40 ms | 小参数达到接近 8B 的质量 |
Qwen3-Embedding-8B | 8B | 200–500 ms | 50–150 ms | 质量最高,不适合毫秒级在线场景 |
text-embedding-3-small | 闭源 | 80–200 ms(含网络) | 不适用 | 受 API 网络波动影响 |
延迟选型原则:
- 在线查询延迟敏感(用户实时提问、Agent 多轮对话):选 600M 参数以下的模型(
bge-m3、bge-large-zh),单条 Embedding 控制在 100 ms 以内。 - 离线批量入库(知识库夜间重建、全量 re-index):可以用更大模型(
Qwen3-Embedding-8B),质量优先,延迟不敏感。批量入库时一次传入多条文本(而非逐条调用),吞吐量可以提升一个数量级。 - API vs 自部署:海外 API(OpenAI、Cohere)从国内调用通常有 80–200 ms 的网络开销;国内 API(硅基流动、通义)或自部署能把这个开销降到 30–80 ms。
- 没有 GPU 的本地环境:可以用 Ollama 跑
nomic-embed-text(137M 参数),CPU 即可运行,适合开发调试,但不适合生产级精度要求。
几个容易被忽略的工程细节
选完模型,还有几个直接影响检索效果的细节:
1. 入库和查询必须用同一个模型。 这是最多人踩的坑:知识库写入时用模型 A,查询时换了模型 B,两个向量空间不一致,检索结果会断崖式下降。换模型意味着全量 re-index。
2. 查询和文档的编码方式可能不同。 以 bge-m3 为例,编码查询时应加检索前缀(prompt_name="query"),编码文档时不加。Jina 系列则用 task="retrieval.query" 和 task="retrieval.passage" 区分角色。这不是可选项,是模型训练时就设计好的使用方式。
# BGE-M3 的正确用法:查询和文档分开编码
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("BAAI/bge-m3")
doc_embeddings = model.encode(documents, normalize_embeddings=True)
query_embeddings = model.encode(queries, normalize_embeddings=True, prompt_name="query")3. bge-m3 自带三种检索模式。 除了常规的稠密向量(Dense),它还支持稀疏向量(Sparse,类似 BM25 的关键词匹配)和多向量(ColBERT 风格的细粒度匹配)。这意味着 bge-m3 一个模型就能做语义与关键词的混合检索,和 D2 后面讲的混合搜索是同一个思路,只是发生在 Embedding 层而非数据库层。
4. Embedding 负责初筛,Reranker 负责精排。 工业级 RAG 的常见架构是:Embedding 召回 Top-50~100 候选,再用 Reranker 模型(如 BAAI/bge-reranker-v2-m3)精排到 Top-10。实测中,加上 Reranker 后准确率可以从 78% 提升到 91%。Embedding 选型解决的是找得到的问题,Reranker 解决的是排得准的问题。
5. 缓存和批量处理能省 80% 的成本。 对文本内容做哈希作为缓存 key,相同 chunk 不重复计算 Embedding;批量入库时一次传入几十上百条文本,比逐条调用 API 高效得多。
选型决策:四步走
把四个维度合在一起,可以按下面的流程快速决策:
你的知识库是什么类型?
├── 几乎全是纯文本
│ ├── 中文为主 → bge-m3(免费 API)或 通义 v3(国内 API)
│ ├── 英文为主 → text-embedding-3-small / Voyage-3
│ └── 多语言混合 → bge-m3 或 Qwen3-Embedding 系列
│
├── 包含大量 PDF / 图表 / 扫描件
│ ├── 追求最高召回 → ColPali / ColNomic 页面级多向量检索
│ └── 追求工程简单 → Qwen3-VL-Embedding 或 Gemini Embedding 2
│
调用量级和数据合规?
├── 学习 / 原型 / 月调用 < 500 万 token → 硅基流动免费 bge-m3
├── 数据不能出内网 → 自部署 bge-m3 或 Qwen3-Embedding
└── 月调用 > 5000 万 token → 评估自部署,长期成本更低
延迟要求?
├── 在线实时查询 → bge-m3 / bge-large-zh(< 100 ms)
└── 离线批量入库 → 可用 Qwen3-Embedding-8B 追求更高质量
最后一步(所有路径都适用):
→ 用 20-50 条真实 query 跑 Recall@K + MRR 对比
→ 搭配 Reranker 做精排
→ 确认入库和查询使用同一模型最后一条建议,比看任何排行榜都重要:用你自己的文档跑一轮对比实验。拿 20–50 条真实业务查询,分别用 2–3 个候选模型做向量化 + 检索,看 Top-3 命中率和 MRR。排行榜反映通用能力,你的业务数据反映实际效果。
本课程选择 bge-m3 作为默认模型,是因为它在中英文能力、成本(免费)、延迟(中等)、API 易用性四个维度上取得了最好的学习体验平衡。但当你进入生产环境,上面这套选型框架会帮你找到更适合自己业务的模型。
切分 + 向量化完成后,数据才真正准备好进入数据库。接下来的问题才是:用什么数据库存,用什么方式查?
第一部分:传统数据库为什么不够用
先说一件你可能已经直觉感受到但没有系统想过的事。
传统数据库——无论是 MySQL、PostgreSQL 还是 MongoDB——它们的设计哲学是精确匹配。你告诉数据库“找 id=123 的记录”,它帮你找到;你告诉它“找 name='张三' 的用户”,它帮你找到。整个查询逻辑建立在一个前提上:你知道你要找什么,而且你能精确描述它。
# 传统数据库的典型查询
cursor.execute("SELECT * FROM products WHERE id = 123")
cursor.execute("SELECT * FROM users WHERE name = '张三'")这在传统应用里没问题。用户搜商品,用商品 ID;查订单,用订单号;找客户,用手机号。一切都是精确的。
但 AI 应用面对的是一个完全不同的场景。用户不会说“找 id=123 的文档”,用户会说:
- “我们上个月讨论过的那个性能优化方案是什么?”
- “有没有关于用户权限设计的最佳实践?”
- “帮我找一下和数据库迁移相关的文档”
这些查询的共同特点是:用户用自然语言描述他想要的东西,而不是给出精确的匹配条件。他不知道文档的 ID,不知道标题的确切措辞,甚至不知道那份文档到底叫什么——他只知道“大概是关于什么的”。
传统数据库对这种查询无能为力。你没法写一条 SQL 来“找意思最接近的段落”。
这就是 AI 应用和传统应用在数据层面上的根本错位:传统数据库做的是精确匹配,AI 应用需要的是语义匹配。

第二部分:向量搜索——聪明,但没有你以为的那么聪明
为了解决语义匹配的问题,行业引入了向量搜索。
原理不复杂。大模型(或者专门的 Embedding 模型)可以把一段文字变成一个高维向量——一串数字。意思相近的文字,向量也相近。所以“查找和这个问题最相关的段落”就变成了“找到向量空间中距离最近的几个点”。
# 向量搜索的基本逻辑
query_embedding = embed("用户权限设计的最佳实践")
results = vector_db.search(query_embedding, top_k=5)
# 返回语义上最相近的 5 个文档段落这确实很厉害。用户问“权限设计”,向量搜索能找到标题叫“访问控制架构”的文档——因为它们语义相近。传统关键词搜索就做不到这一点,因为“权限设计”和“访问控制架构”之间没有一个共同的关键词。
但问题来了。
向量搜索的软肋
试想这个场景:你的知识库里有大量的错误码文档。用户遇到了一个问题,搜索:
“错误码 E-4012 的解决方案”
向量搜索会怎么做?它会把“错误码 E-4012 的解决方案”这句话变成一个向量,然后在向量空间中找最近的几个点。
结果它返回了什么?
- E-4011 的解决方案
- E-4013 的解决方案
- E-4010 的解决方案
因为在向量空间中,“E-4011”“E-4012”“E-4013”这几个字符串的语义表示非常接近——它们都是“错误码”,都是“E-40xx 系列”,在语义上几乎没有区别。但用户需要的是精确匹配 E-4012,差一位数字就是完全不同的错误。
这不是个例。向量搜索在以下场景中都容易“犯蠢”:
| 查询内容 | 向量搜索的问题 |
|---|---|
| 产品型号 “OB-4.2.1” | 可能返回 OB-3.x 或 OB-4.1.0 的文档 |
| API 参数名 “max_retries” | 可能返回关于 “retry_count” 的文档 |
| 版本号 “v2.3.1” | 可能返回 v2.3.0 或 v2.4.0 的内容 |
| 配置项 “enable_ssl_verify” | 可能返回关于 SSL 证书的通用讨论 |
| 精确数字“超时时间 30 秒” | 可能返回“超时时间 60 秒”的文档 |
你注意到规律了吗?凡是需要精确匹配的内容——专有名词、型号编号、版本号、配置项名称、精确数值——向量搜索都不可靠。
为什么?因为 Embedding 模型在训练时学到的是“语义”,不是“字面”。“E-4012”和“E-4013”在语义空间中就是“差不多的东西”,模型无法理解“差一位数字意味着完全不同的错误”。这不是模型不够好的问题——这是向量搜索这个方法论的固有边界。
这不是一个模型问题,是一个搜索策略问题。
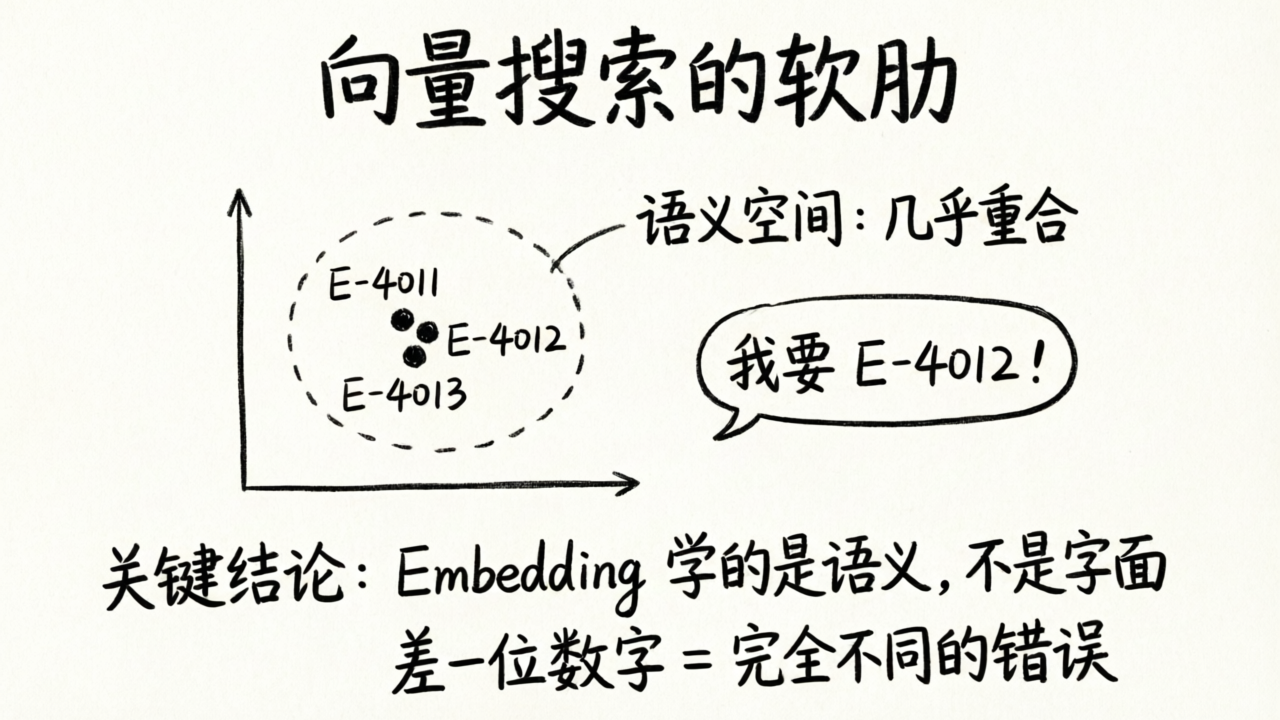
用个类比来说:向量搜索就像一个理解力很强但不太较真的同事。你问他“那个 E-4012 的文档在哪”,他会说“E-40 什么什么的嘛,我记得大概在这一带”——他抓住了大意,但搞混了细节。而你需要的是一个既懂大意又能精确定位的人。
第三部分:混合搜索——你需要的完整方案
既然向量搜索擅长语义理解但搞不定精确匹配,而传统的全文搜索(关键词匹配)擅长精确匹配但不懂语义——答案就呼之欲出了:
两个都要。
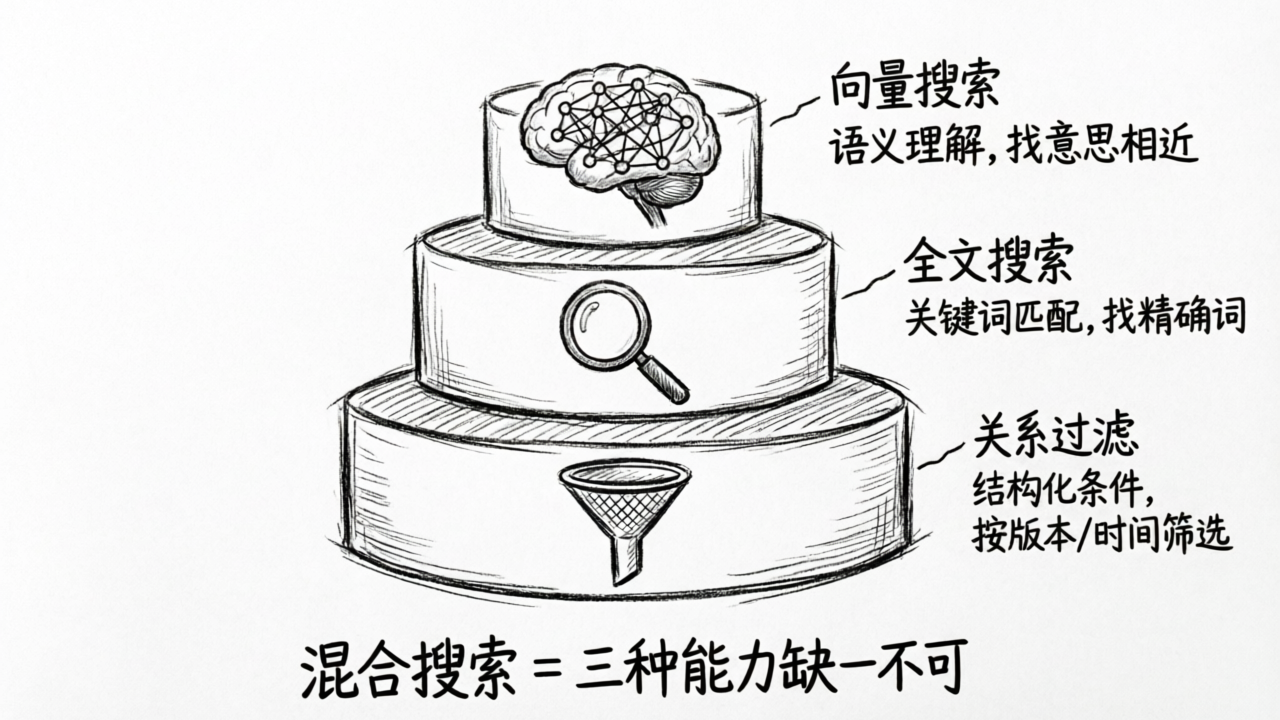
这就是混合搜索(Hybrid Search)的核心逻辑:
- 向量搜索负责语义理解:“找意思最接近的内容”
- 全文搜索负责关键词匹配:“找包含这个确切词的内容”
- 关系过滤负责结构化条件:“只在最近更新的文档中找”“只在产品 A 的文档中找”
三种能力组合起来,才是一个 AI 应用数据层需要的完整检索覆盖。
回到那个错误码的例子:
| 搜索策略 | 搜索“错误码 E-4012 的解决方案”的结果 |
|---|---|
| 纯向量搜索 | 返回 E-4011、E-4013 等“语义相近”的文档 |
| 纯全文搜索 | 精确匹配到 E-4012,但如果用户措辞不精确就找不到 |
| 混合搜索 | 精确匹配 E-4012(全文搜索命中)+ 相关错误处理指南(向量搜索补充) |
再看另一个场景。用户搜索“怎么优化数据库查询性能”:
| 搜索策略 | 结果 |
|---|---|
| 纯向量搜索 | 找到关于“查询优化”“索引设计”“执行计划分析”的文档——语义命中 ✓ |
| 纯全文搜索 | 只找到标题或内容中包含“数据库查询性能”这几个字的文档——遗漏大量相关内容 |
| 混合搜索 | 两者的结果融合——既有精确命中,也有语义扩展 |
这不是一个“哪个更好”的选择题。这是一个“两种能力分别覆盖不同场景”的工程现实。 任何只用其中一种的方案,都有明显的盲区。
而关系过滤则解决的是另一类需求:你不只想搜“性能优化”,你还想限定“只搜 OB-4.x 版本的文档”或者“只搜最近三个月更新的内容”。这是一个结构化条件,需要传统的关系查询能力。
三种能力,缺一不可。
第四部分:三个厨房的问题
理解了混合搜索的必要性,接下来你面对一个工程选择:怎么实现它?
目前行业中最常见的做法是这样的:
- 用一个向量数据库(比如 Pinecone、Milvus)做语义检索
- 用一个搜索引擎(比如 Elasticsearch)做全文检索
- 用一个关系数据库(比如 PostgreSQL)做结构化查询和数据管理
然后,在应用层写胶水代码,把三个系统的查询结果合并起来。
# "三个系统拼凑"的典型代码
vector_results = pinecone.query(embedding, top_k=10)
fulltext_results = elasticsearch.search({"query": {"match": {"content": query}}})
metadata = postgres.execute("SELECT * FROM docs WHERE updated_at > '2025-01-01'")
# 然后手动合并三个系统的结果……
final_results = merge_results(vector_results, fulltext_results, metadata)这段代码能跑通吗?能。但让我用一个类比来说明为什么这不是个好方案。
三个厨房
想象你开了一家餐厅。出于某种历史原因,你有三个独立的厨房:
- 冷菜厨房在一楼,有自己的食材仓库和库存系统
- 热菜厨房在二楼,也有自己的一套食材管理
- 甜点厨房在三楼,同样独立运作
每来一位客人点餐,你需要:
- 把订单拆成三份,分别送到三个厨房
- 三个厨房各自准备各自的部分
- 有人负责跑上跑下,确认三个厨房的进度
- 最后把三个厨房的出品凑成一桌菜端给客人
- 如果客人说“冷菜不要香菜”——你得确保这个信息传达到了冷菜厨房,而不是被热菜厨房拦截了
三个厨房都能正常做菜,但协调成本是灾难性的。食材在三个仓库之间重复存放,有的食材一楼用完了二楼还有但没人知道。菜品之间的搭配靠前台经理人工协调,忙的时候难免出错。一楼厨房升级了设备,二楼三楼还在用旧的——三个系统的版本管理各自独立。
这就是同时维护三套数据系统的真实体验。
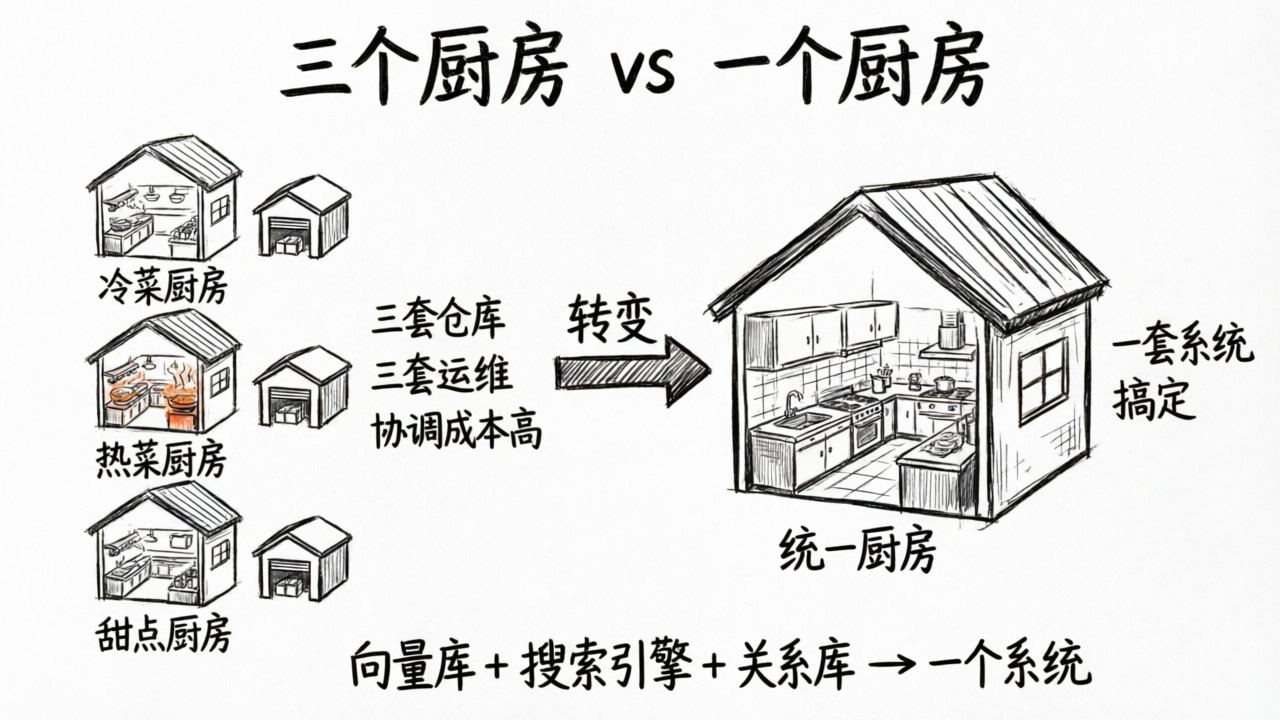
向量数据库、搜索引擎、关系数据库——三个独立系统,三套部署、三套运维、三套 API、三个数据同步流程。你得保证同一份文档在三个系统中的数据是一致的;你得在应用层写大量代码来合并三个系统的查询结果;任何一个系统出了问题,你的检索就是残缺的。
这不是正常状态。这是行业从“传统应用”过渡到“AI 应用”过程中的临时方案。就像那三个厨房——它不是你设计的,是历史遗留的,你一直在凑合着用。
正确的做法是什么?一个厨房,所有菜都能做。
我们的思考
我们做 seekdb 的出发点,就是上面这个判断。
AI 应用的数据层不应该是三个系统拼在一起。向量库管语义,搜索引擎管关键词,关系库管结构化数据,然后在应用层写胶水代码协调三个系统的结果——这不仅增加运维复杂度,还导致检索结果难以有机整合。一个系统用相关性分数排序,另一个系统用 BM25 分数排序,第三个系统用时间排序——你怎么把三套排序逻辑合成一个统一的结果排名?光这一件事就够你头疼一阵了。
正确的做法是在一个系统里原生支持三种检索能力。不是三个引擎拼起来假装一个,是一个引擎天生就能同时处理向量数据、全文数据和关系数据。
seekdb 就是基于这个判断做的。当你创建一个数据集合时,你可以同时声明向量索引和全文索引。查询的时候,一条语句同时执行语义搜索、关键词搜索和结构化过滤——结果在引擎内部有机融合,而不是在应用层手动拼接。
用我们内部常说的一句话:
你做得对的方式也恰好是最简单的方式。
一个系统搞定,不仅架构更简洁,效果也更好。因为引擎内部可以让向量分数和全文分数做联合排序,而不是在外面做事后合并——后者永远丢信息。
光说不练假把式。我们来看看实际跑起来到底有多快。
五分钟跑通:你的第一个混合搜索
下面这段代码可以在你的笔记本电脑上直接运行。五分钟内,你就能体验一个同时支持向量搜索和全文搜索的 AI 数据层。
第一步:安装
# 终端运行
# pip install pyseekdb第二步:创建集合并写入数据
from pyseekdb import SeekDB
db = SeekDB()
# 创建一个支持向量和全文搜索的集合
db.create_collection(
name="knowledge_base",
vector_column="content", # 对 content 列建向量索引
fulltext_columns=["content"] # 对 content 列建全文索引
)
# 准备示例文档
docs = [
{
"content": "错误码 E-4012 表示数据库连接超时。解决方案:检查网络配置,确认数据库服务端口是否开放,建议超时时间设置为 30 秒。",
"category": "error_codes",
"version": "4.2"
},
{
"content": "错误码 E-4013 表示认证失败。解决方案:检查用户名和密码是否正确,确认账户是否被锁定。",
"category": "error_codes",
"version": "4.2"
},
{
"content": "数据库查询性能优化指南:合理使用索引可以将查询速度提升 10 倍以上。建议对高频查询的 WHERE 条件列建立索引。",
"category": "best_practices",
"version": "4.2"
},
{
"content": "访问控制架构设计:基于 RBAC 模型实现用户权限管理,支持角色继承和细粒度的资源级权限控制。",
"category": "architecture",
"version": "4.1"
},
{
"content": "OB-4.2.1 版本新特性:支持在线 DDL 操作、改进了并行查询引擎、修复了分区表在特定条件下的数据倾斜问题。",
"category": "release_notes",
"version": "4.2.1"
},
]
# 写入数据
db.insert(collection_name="knowledge_base", documents=docs)第三步:执行混合查询
# 混合查询:同时使用向量搜索 + 全文搜索
results = db.hybrid_search(
collection_name="knowledge_base",
query_text="错误码 E-4012 的解决方案",
top_k=3
)
for r in results:
print(f"[相关度: {r['score']:.3f}]")
print(r["content"])
print("---")运行这段代码,你会看到 E-4012 的文档被精确排在第一位——不是因为它“语义最相近”(E-4013 语义上也很近),而是因为全文搜索精确匹配了“E-4012”这个关键词,和向量搜索的语义分数一起参与了排序。
现在试试另一个查询:
# 语义查询:用户的措辞和文档标题完全不同
results = db.hybrid_search(
collection_name="knowledge_base",
query_text="怎么设计用户权限",
top_k=3
)
for r in results:
print(f"[相关度: {r['score']:.3f}]")
print(r["content"])
print("---")这次你会看到“访问控制架构设计”的文档被找到了——尽管用户说的是“用户权限”,文档写的是“访问控制架构”,两者之间没有共同的关键词。这是向量搜索的功劳,它理解了语义上的等价性。
一个查询,两种搜索能力同时工作,结果在引擎内部融合。 你不需要写任何合并逻辑,不需要维护多个系统,不需要操心数据同步。
加上结构化过滤
# 混合查询 + 结构化过滤:只在 4.2 版本的文档中搜索
results = db.hybrid_search(
collection_name="knowledge_base",
query_text="性能优化",
top_k=3,
filters={"version": "4.2"}
)向量搜索 + 全文搜索 + 关系过滤,三种能力在一条查询中完成。这就是“一个厨房,所有菜都能做”的实际体验。
对比一下:纯向量搜索 vs 混合搜索
为了让你直观感受差距,我们跑一个简单的对比实验。同样的数据,同样的查询,分别用纯向量搜索和混合搜索,看看结果有什么不同。
# 纯向量搜索
vector_only = db.vector_search(
collection_name="knowledge_base",
query_text="错误码 E-4012",
top_k=3
)
# 混合搜索
hybrid = db.hybrid_search(
collection_name="knowledge_base",
query_text="错误码 E-4012",
top_k=3
)
print("=== 纯向量搜索结果 ===")
for i, r in enumerate(vector_only):
print(f"{i+1}. {r['content'][:50]}...")
print("\n=== 混合搜索结果 ===")
for i, r in enumerate(hybrid):
print(f"{i+1}. {r['content'][:50]}...")你大概率会看到类似这样的对比:
| 排名 | 纯向量搜索 | 混合搜索 |
|---|---|---|
| 1 | E-4013 认证失败(语义最近) | E-4012 连接超时(精确命中) |
| 2 | E-4012 连接超时 | E-4013 认证失败(语义补充) |
| 3 | 查询性能优化(也沾点边) | OB-4.2.1 版本新特性 |
纯向量搜索把 E-4013 排在了 E-4012 前面——因为在向量空间中它们几乎一样近,排序带有随机性。但混合搜索因为有全文搜索的精确匹配信号,把 E-4012 精准地推到了第一位。
一个错误码搞错,如果这个结果直接被 Agent 用来回答用户,用户得到的就是错误的解决方案。这不是“效果差一点”的问题,是“对和错”的问题。
这就是 D3 会更深入展开的对比实验。在 D3 中,你会用更大规模的真实数据、更多样的查询类型来做系统性对比。到时候你会发现,在包含专有名词、版本号、技术术语的查询中,混合搜索和纯向量搜索的差距是肉眼可见的。
回到全局:这件事在整个课程中的位置
让我们把视野拉回来,看看今天讲的内容在整个 Dev 路径中处于什么位置。
D1 你学会了 Tool Use——Agent 和外部世界交互的桥梁。今天你搭建了桥对面的数据层——一个能同时做语义检索、关键词匹配和结构化过滤的系统。
D3 你会把这两者连起来:用 Tool Use 让 Agent 调用 seekdb 的混合检索,构建一个完整的 Agentic RAG 系统,并通过对比实验亲眼看到数据层选型对最终效果的影响。
D4 你会在同一个数据层上构建记忆系统——记忆的存储、检索、降权,底层用的也是今天讲的这套混合检索能力。
一条主线贯穿始终:Agent 的每一项能力,拆到底都是数据的存储与检索。
这节课要留下的印象
如果这节课的所有内容你只记住一句话,记住这句:
AI 应用的数据层需要同时处理语义检索和精确检索——这是工程现实。一个系统搞定,比三个系统拼凑不仅更简单,效果也更好。

课后行动
跑通 Notebook:运行本模块的代码,五分钟内完成你的第一个混合查询。确认向量搜索和全文搜索各自的命中情况。
跑分块对比实验:运行
d2_5_chunking_compare.py,观察固定 overlap、语义分块、动态 overlap、父子 chunk 四种策略的 Recall@3 差异。如果配置了 API Key,四种策略都会跑;否则先对比后三种中的两个(动态 overlap + 父子 chunk)。换成你自己的数据:这才是关键一步。找几份你实际项目中的文档——产品文档、API 文档、内部 Wiki,什么都行。把它们存入 seekdb,然后用你日常工作中会问的问题去查询。感受一下:
- 哪些查询是向量搜索命中、全文搜索没命中的?(语义理解的价值)
- 哪些查询是全文搜索命中、向量搜索漏掉或排错的?(精确匹配的价值)
- 有没有查询是两者结合才给出最佳结果的?
带着你的观察进入下一期。D3 会在更大的数据规模上做系统性的对比实验——你会用数据证明“混合检索不是可选优化,是基本要求”这个判断。
延伸阅读
如果你对本期提到的概念想做进一步了解,以下是一些推荐资源:
- Embedding 模型选型与评测:MTEB Leaderboard,全球主流的 Embedding 模型评测基准,做 RAG 检索时重点看 Retrieval 子任务得分;MMEB Leaderboard,多模态 Embedding 评测;硅基流动 Embedding API 文档,本课程使用的 API 平台,支持
bge-m3、Qwen3-Embedding及多模态Qwen3-VL-Embedding等模型 - Chunking 策略与评测:Weaviate · Chunking Strategies for RAG,涵盖固定分块、语义分块、自适应 overlap 等策略的系统梳理;Firecrawl · Best Chunking Strategies for RAG in 2026,七种策略的代码示例与选型建议;NAACL 2025 · Is Semantic Chunking Worth the Computational Cost?,语义分块计算成本与效果的学术评测;LangChain SemanticChunker API,percentile 阈值语义分块的工程实现
- 向量搜索的原理:What are Vector Embeddings?,Pinecone 的入门教程,直观解释了 Embedding 和向量搜索的工作方式
- BM25 与全文检索:Understanding BM25,Elastic 的技术博客,解释了全文搜索背后的经典算法
- RRF 融合算法:混合搜索中如何将向量分数和全文分数合并为统一排名,Reciprocal Rank Fusion 是业界常用的方案——D3 的延伸阅读会展开这个话题
- seekdb 官方文档:完整的 API 参考、数据类型支持和混合查询的工程细节
下一期预告:D3 · Agentic RAG 实战——把 D1 的 Tool Use 和 D2 的数据层连起来,构建一个知识库问答系统。重头戏是一组对比实验:同样的查询,纯向量检索和混合检索的结果差距有多大?不需要看论文——跑一次实验就明白了。
欢迎各位老师在 https://github.com/datawhalechina/easy-data-x-ai 参与课程共建。
也欢迎各位老师加入 Data x AI 交流群~
